1.2 KiB
1.2 KiB
本章涵盖以下内容:
- 探讨在神经网络中使用注意力机制的原因
- 介绍一个基本的自注意力框架,并逐步深入到改进的自注意力机制
- 实现一个因果注意力模块,使 LLM 能够一次生成一个token
- 使用 dropout 随机掩盖部分注意力权重,以减少过拟合
在上一章中,你学习了如何准备输入文本以训练 LLM。这包括将文本拆分为单个单词和子词token,这些token可以被编码为向量表示,即所谓的嵌入,以供 LLM 使用。
在本章中,我们将关注 LLM 架构中的重要组成部分,即注意力机制,如图 3.1 所示。
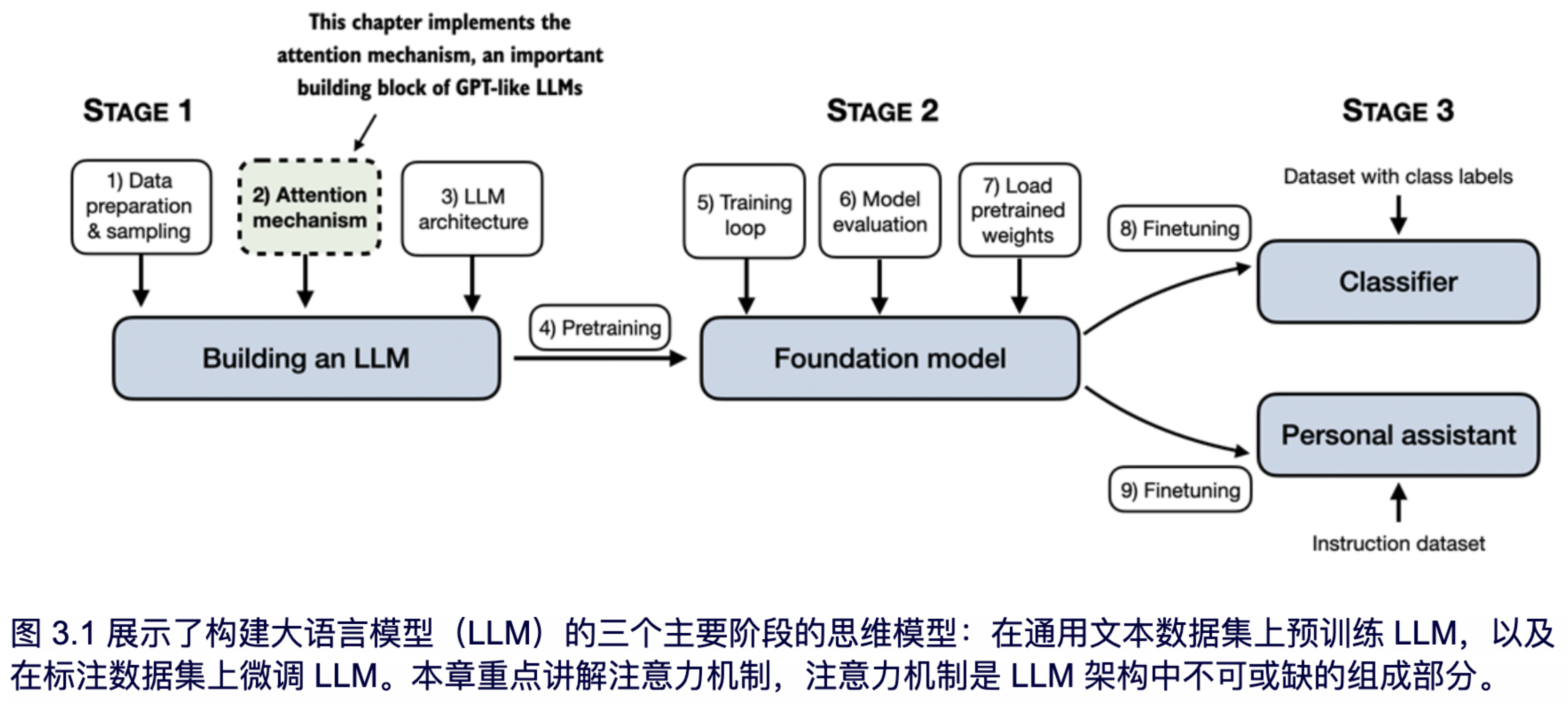
注意力机制是一个复杂的话题,因此我们将专门用一整章来讨论它。我们主要会将注意力机制独立来研究,关注其内部的工作原理。在下一章中,我们将编写环绕自注意力机制的 LLM 其他部分的代码,以便观察它的实际应用,并创建一个能够生成文本的模型。
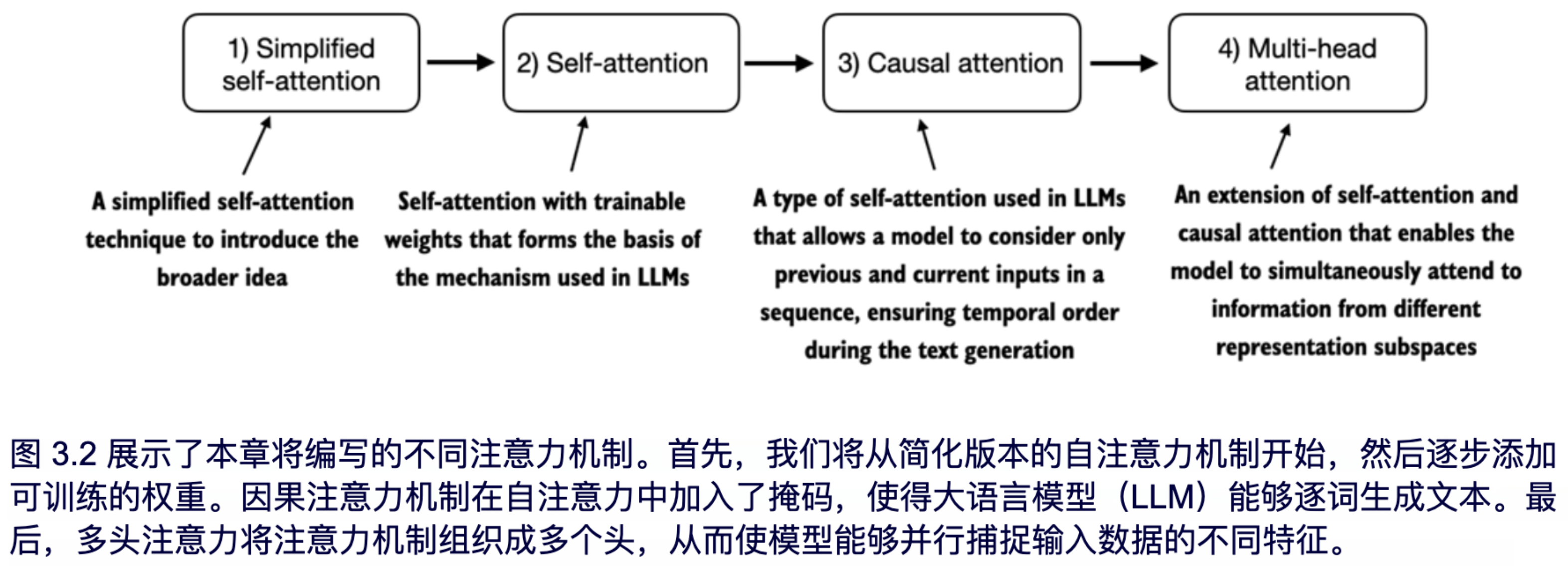
本章中,我们将实现四种不同的注意力机制变体,如图 3.2 所示。