2.1 KiB
2.1 KiB
本章涵盖以下内容:
- LLM 指令微调过程概述
- 为监督式指令微调准备数据集
- 批量组织指令数据
- 评估 LLM 通过指令遵循生成的内容质量
- 评估一个经过指令微调的 LLM
在之前的章节中,我们实现了 LLM 架构,完成了预训练,并将外部的预训练权重导入模型。然后,在上一章中,我们专注于对 LLM 进行特定分类任务的微调,即区分出正常短信和垃圾短信短信。在本章中,我们将介绍如何微调 LLM 以遵循人类指令(见图 7.1),这是开发用于聊天机器人、个人助理和其他对话任务的 LLM 的主要技术之一。
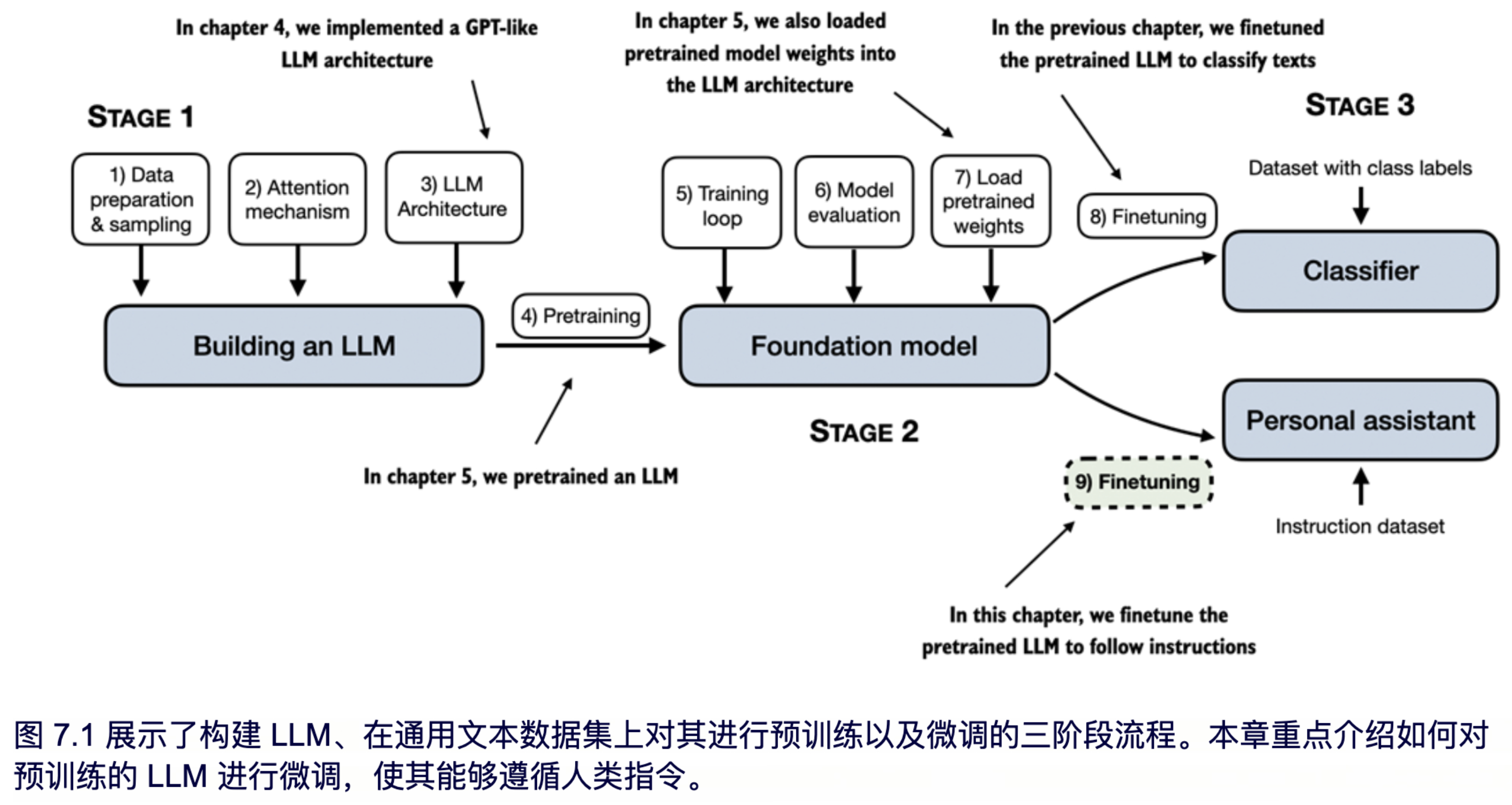
图 7.1 展示了微调大型语言模型的两种主要方式:用于分类任务的微调(步骤 8)和用于指令遵循的微调(步骤 9)。上一章中我们已实现了步骤 8,本章将重点讲解如何使用指令数据集微调 LLM,具体过程将在下一节进一步说明。
7.1 指令遵循微调简介
在第 5 章中,我们看到,对 LLM 的预训练是一种逐词生成的学习过程。预训练后,LLM 具备根据输入片段补全文本的能力,可以完成句子或生成段落。
然而,预训练的 LLM 在处理特定指令时往往表现不佳,例如,“修正该文本的语法”或“将该文本转换为被动语态”。我们将在第 7.5 节中详细讨论一个具体示例,演示如何加载预训练模型并基于其进行指令微调。
本章将专注于提升 LLM 遵循指令并生成理想回答的能力,如图 7.2 所示。

在本章的剩余部分,我们将逐步实现指令微调过程,首先从数据集准备开始,如图 7.3 所示。
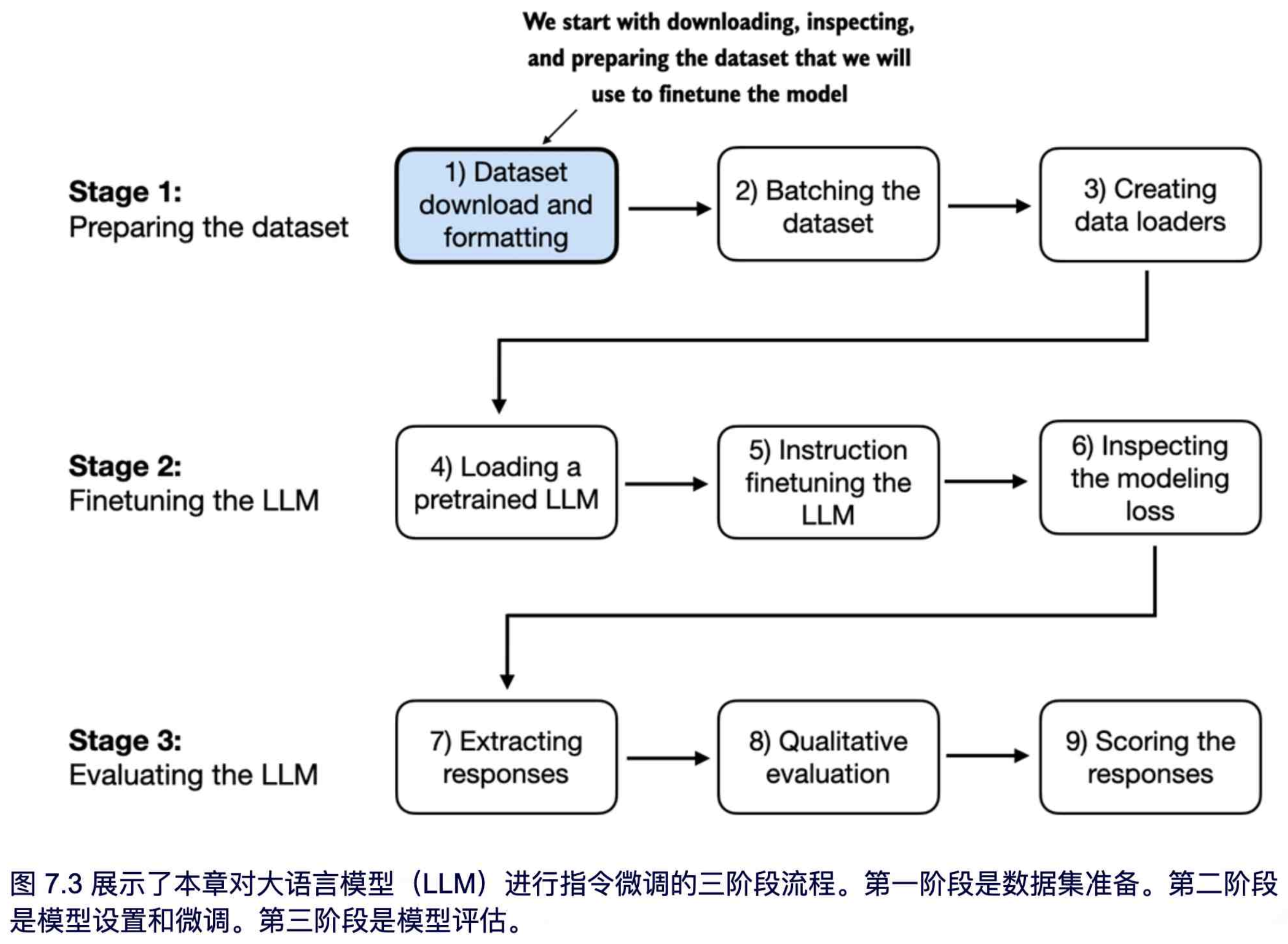
数据集准备是指令微调中的关键环节,本章的大部分内容都将围绕这一过程展开。下一节将开始实现下载和格式化数据集的代码,如图 7.3 所示,这是数据集准备过程的第一步。