7.8 KiB
在本附录中,我们将增强第 5-7 章中涵盖的预训练和微调过程的训练函数。特别是前三部分内容,将涵盖学习率预热、余弦衰减和梯度裁剪等高级技巧。
最后一部分将这些技巧整合到第 5 章中开发的训练函数中,并预训练一个大语言模型 (LLM)。
为使本附录中的代码自成一体,我们重新初始化了在第5章中训练的模型。
import torch
from previous_chapters import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"ctx_len": 256, # Shortened context length (orig: 1024)
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-key-value bias
}
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval()
在初始化模型之后,我们还需要初始化第 5 章中使用的 data loader。首先,我们加载短篇小说《The Verdict》:
import os
import urllib.request
file_path = "the-verdict.txt"
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_mainchapter-code/the-verdict.txt"
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode('utf-8')
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
else:
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
# Next, we load the text_data into the data loaders:
from previous_chapters import create_dataloader_v1
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
torch.manual_seed(123)
train_loader = create_dataloader_v1(
text_data[:split_idx],
batch_size=2,
max_length=GPT_CONFIG_124M["ctx_len"],
stride=GPT_CONFIG_124M["ctx_len"],
drop_last=True,
shuffle=True
)
val_loader = create_dataloader_v1(
text_data[split_idx:],
batch_size=2,
max_length=GPT_CONFIG_124M["ctx_len"],
stride=GPT_CONFIG_124M["ctx_len"],
drop_last=False,
shuffle=False
)
现在我们已经重新实例化了第 5 章中使用的模型和 data loader,接下来一节将介绍我们对训练函数所做的增强。
D.1 学习率预热
我们介绍的第一个技巧是学习率预热。实施学习率预热可以稳定复杂模型(如 LLM)的训练。这个过程包括将学习率从一个非常低的初始值 (initial_lr) 逐渐增加到用户指定的最大值 (peak_lr)。以较小的权重更新开始训练可以降低模型在其训练阶段遇到大的、不稳定的更新的风险。
假设我们计划以 15 个 epoch 训练一个 LLM,初始学习率为 0.0001,并将其增加到最大学习率 0.01。此外,我们定义了 20 个预热步骤,以便在前 20 个训练步骤中将初始学习率从 0.0001 增加到 0.01:
n_epochs = 15
initial_lr = 0.0001
peak_lr = 0.01
warmup_steps = 20
接下来,我们实现一个简单的训练循环模板来演示这个预热过程:
optimizer = torch.optim.AdamW(model.parameters(), weight_decay=0.1)
lr_increment = (peak_lr - initial_lr) / warmup_steps #A
global_step = -1
track_lrs = []
for epoch in range(n_epochs): #B
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
global_step += 1
if global_step < warmup_steps: #C
lr = initial_lr + global_step * lr_increment
else:
lr = peak_lr
for param_group in optimizer.param_groups: #D
param_group["lr"] = lr
track_lrs.append(optimizer.param_groups[0]["lr"]) #E
#A 此增量决定了在 20 个预热步骤中的每一步,我们将 initial_lr 增加多少。
#B 执行一个典型的训练循环,在每个 epoch 中遍历训练 loader 中的批次。
#C 如果我们仍在预热阶段,则更新学习率。
#D 将计算出的学习率应用于优化器。
#E 在一个完整的训练循环中,损失和模型更新将在此处计算,为了简单起见,本示例中省略了这些。
运行上述代码后,我们来可视化学习率是如何被上面的训练循环更改,从而验证学习率预热是否按预期工作:
import matplotlib.pyplot as plt
plt.ylabel("Learning rate")
plt.xlabel("Step")
total_training_steps = len(train_loader) * n_epochs
plt.plot(range(total_training_steps), track_lrs);
plt.show()
结果图如图 D.1 所示。
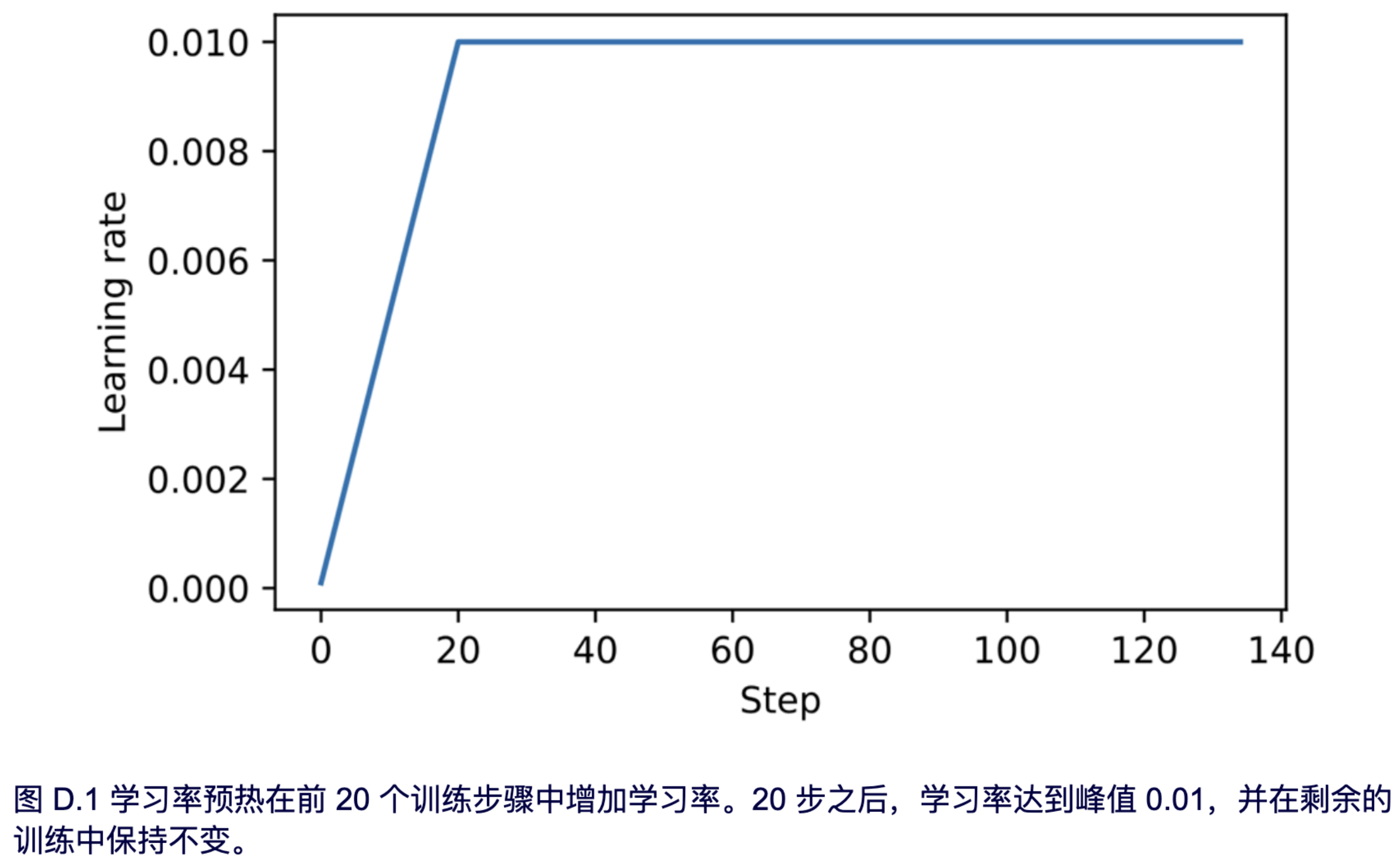
如图 D.1 所示,学习率从一个较低的值开始,并在 20 步内逐步增加,直到在 20 步后达到最大值。
在下一节中,我们将进一步修改学习率,使其在达到最大学习率后下降,这有助于进一步改进模型训练。
D.2 余弦衰减
另一种广泛应用于训练复杂深度神经网络和 LLM 的技术是余弦衰减。此方法在整个训练周期中调整学习率,使其在预热阶段后遵循余弦曲线。
在其流行的变体中,余弦衰减将学习率降低(或衰减)至接近于零,模仿半个余弦周期的轨迹。余弦衰减中学习率的逐渐降低旨在减缓模型更新其权重的速度。这尤其重要,因为它有助于最大限度地降低在训练过程中越过损失最小值的风险,这对于确保训练在其后期阶段的稳定性至关重要。
我们可以修改上一节中的训练循环模板,通过以下方式添加余弦衰减:
import math
min_lr = 0.1 * initial_lr
track_lrs = []
lr_increment = (peak_lr - initial_lr) / warmup_steps
global_step = -1
for epoch in range(n_epochs):
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
global_step += 1
if global_step < warmup_steps:
lr = initial_lr + global_step * lr_increment
else:
progress = ((global_step - warmup_steps) /
(total_training_steps - warmup_steps))
lr = min_lr + (peak_lr - min_lr) * 0.5 * (1 + math.cos(math.pi * progress))
for param_group in optimizer.param_groups:
param_group["lr"] = lr
track_lrs.append(optimizer.param_groups[0]["lr"])
同样,为了验证学习率是否按预期变化,我们绘制学习率的变化曲线:
plt.ylabel("Learning rate")
plt.xlabel("Step")
plt.plot(range(total_training_steps), track_lrs)
plt.show()
学习率曲线如图 D.2 所示。
如图 D.2 所示,学习率以线性预热阶段开始,在前 20 步内增加,直到在 20 步后达到最大值。在 20 步线性预热之后,余弦衰减开始起作用,逐渐降低学习率,直到达到最小值。
D.3 梯度裁剪
在本节中,我们将介绍梯度裁剪,这是另一种用于增强 LLM 训练期间稳定性的重要技术。该方法涉及设置一个阈值,当梯度超过该阈值时,会被缩小到预定的最大幅度。这个过程确保了反向传播期间模型参数的更新保持在一个可控的范围内。
例如,在 PyTorch 的 clip_grad_norm_ 函数中应用 max_norm=1.0 设置可以确保梯度的范数不超过 1.0。这里,“范数”一词表示梯度向量在模型参数空间中的长度或大小的度量,具体指的是 L2 范数,也称为欧几里得范数。
用数学术语来说,对于一个由分量组成的向量 v = [v1, v2, ..., vn],L2 范数描述为:
\text|v|_{2}=\sqrt{v_{1}^{2}+v_{2}^{2}+\ldots+v_{n}^{2}} 这种计算方法也适用于矩阵。例如,考虑以下梯度矩阵:
\text|v|_{2}=\sqrt{v_{1}^{2}+v_{2}^{2}+\ldots+v_{n}^{2}}G=\left[\begin{array}{ll}
1 & 2 \\
2 & 4
\end{array}\right] $$