5.9 KiB
本章涵盖以下内容:
- 大语言模型(LLMs)背后基本概念的高级解释
- 对大语言模型(如 ChatGPT 平台上使用的模型)所源自的 Transformer 架构的深入了解
- 从零开始构建大语言模型的计划
大型语言模型 (LLMs),如 OpenAI 的 ChatGPT,是近年来发展起来的深度神经网络模型。这些模型为自然语言处理 (NLP) 开辟了一个新时代。在大型语言模型出现之前,传统方法在电子邮件垃圾分类等分类任务中表现良好,但通常在需要复杂理解和生成能力的语言任务上表现不佳,例如解析详细指令、进行上下文分析,或生成连贯且符合上下文的原创文本。例如,早期的语言模型无法根据关键词列表撰写电子邮件,而这个任务对现代 LLMs 来说却非常简单。
LLMs 具备理解、生成和解释人类语言的卓越能力。然而,我们需要澄清的是,当我们说语言模型“理解”时,并不是说它们具有人类的意识或理解能力,而是指它们能够以看起来连贯且符合上下文的方式处理和生成文本
得益于深度学习的进展,深度学习是机器学习和人工智能 (AI) 的一个子集,主要关注神经网络,LLMs 在海量文本数据上进行训练。这使得 LLMs 能够捕捉到比以往方法更深层的上下文信息和人类语言的细微差别。因此,LLMs 在各种自然语言处理 (NLP) 任务中的表现得到了显著提升,包括文本翻译、情感分析、问答等。
当代 LLMs 与早期 NLP 模型之间的另一个重要区别在于,早期的 NLP 模型通常是为特定任务而设计的,例如文本分类、语言翻译等。虽然这些早期模型在其特定应用中表现出色,但 LLMs 在各种自然语言处理 (NLP) 任务中展现了更广泛的能力。
LLMs 的成功可以归因于支撑 LLMs 的 transformer 架构,以及 LLMs 训练所用的海量数据。这使得它们能够捕捉到多种语言的细微差别、上下文和模式,而这些都是难以手动编码的。
这种转向基于 transformer 架构的模型和大规模训练数据集来训练 LLMs,已经从根本上改变了自然语言处理 (NLP) 领域,为理解和与人类语言互动提供了更强大的工具。
从本章开始,我们将奠定实现本书主要目标的基础:通过逐步在代码中实现一个基于 transformer 架构的类似 ChatGPT 的 LLM,以帮助理解 LLMs。
1.1 LLM 是什么?
LLM(大型语言模型)是一个旨在理解、生成和响应人类文本的神经网络。这些模型是深度神经网络,在海量文本数据上训练,有时涵盖了互联网上大部分公开可用的文本。
“大型语言模型”中的“大型”指的是模型的参数规模和用于训练的庞大数据集。这类模型通常包含数十亿甚至数百亿的参数,这些参数是网络中的可调节权重,训练过程中通过优化来预测序列中的下一个单词。预测下一个单词是合理的,因为这利用了语言的序列特性,帮助模型理解文本中的上下文、结构和关系。然而,这项任务非常简单,因此许多研究人员对其能够产生如此强大的模型感到惊讶。我们将在后面的章节中逐步讨论并实现下一个单词的训练过程。
LLMs 采用了一种称为 transformer 的架构(在第 1.4 节中将详细讨论),这使得它们在做预测时能够对输入的不同部分进行选择性关注,因此特别擅长处理人类语言的细微差别和复杂性。
由于 LLMs 能够生成文本,因此它们通常被称为一种生成式人工智能 (AI),常缩写为生成 AI 或 GenAI。如图 1.1 所示,人工智能涵盖了创造能执行类似人类智能任务的更广泛领域,包括理解语言、识别模式和做出决策,并包括机器学习和深度学习等子领域。
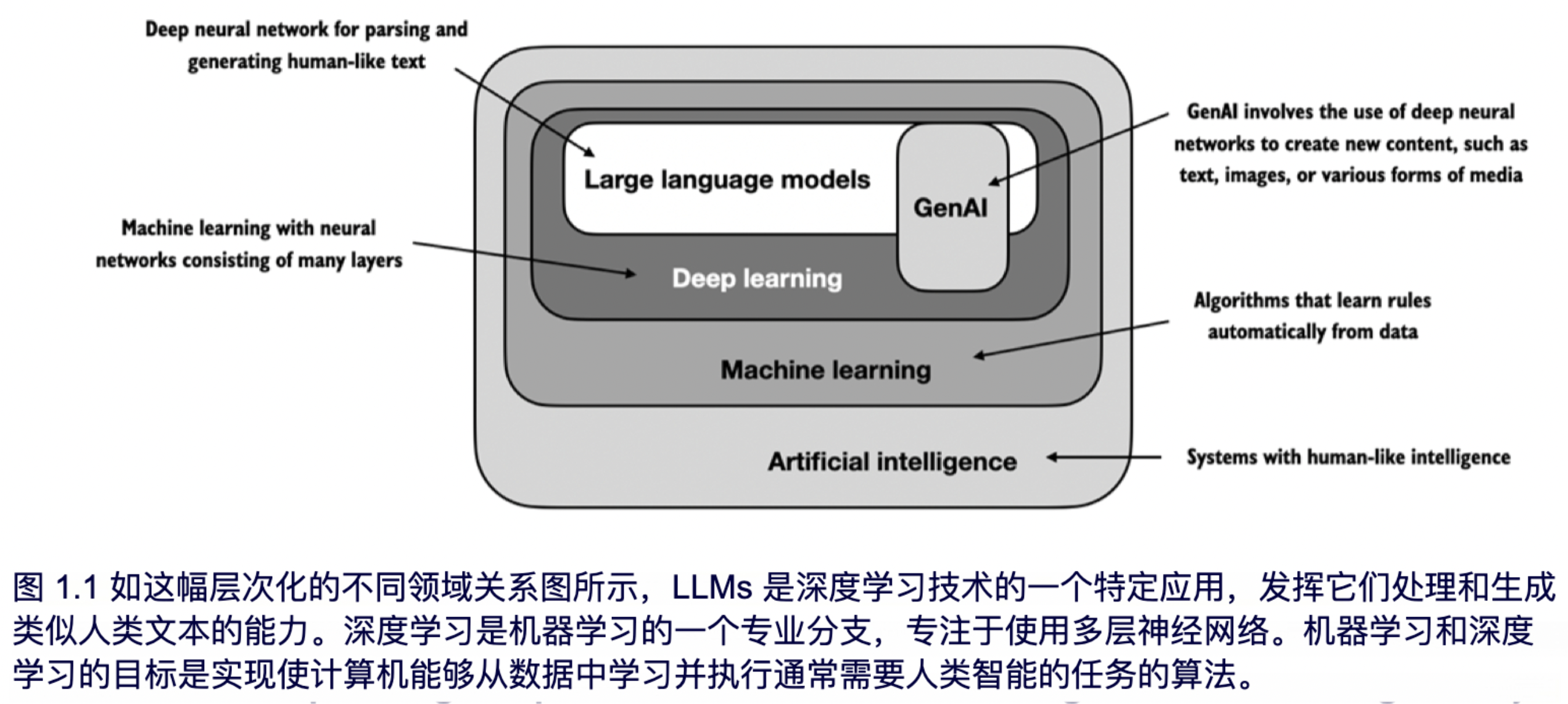
用于实现人工智能的算法是机器学习领域的核心。机器学习具体涉及开发可以从数据中学习并基于数据做出预测或决策的算法,而不需要明确的编程。举例来说,垃圾邮件过滤器就是机器学习的一个实际应用。与其手动编写规则来识别垃圾邮件,不如将标记为垃圾邮件和合法邮件的电子邮件示例输入给机器学习算法。通过最小化训练数据集上的预测误差,模型能够学习识别垃圾邮件的模式和特征,从而将新邮件分类为垃圾邮件或合法邮件。
如图 1.1 所示,深度学习是机器学习的一个子集,专注于使用三层或更多层的神经网络(即深度神经网络)来建模数据中的复杂模式和抽象。与深度学习不同,传统机器学习需要手动提取特征。这意味着人类专家需要识别并选择最相关的特征供模型使用。
虽然当前人工智能领域主要由机器学习和深度学习主导,但它也涵盖了其他方法,例如基于规则的系统、遗传算法、专家系统、模糊逻辑和符号推理。
回到垃圾邮件分类的例子,在传统机器学习中,人类专家会手动提取电子邮件文本中的特征,例如某些触发词的频率(“奖品”、“获胜”、“免费”)、感叹号的数量、全大写单词的使用,或者是否存在可疑链接。基于这些专家定义的特征创建的数据集随后用于训练模型。与传统机器学习不同,深度学习不需要手动提取特征,这意味着人类专家不需要为深度学习模型识别和选择最相关的特征。(不过,无论是在传统机器学习还是深度学习的垃圾邮件分类中,仍然需要收集标签,如垃圾邮件或非垃圾邮件,而这些标签需要由专家或用户进行收集。)
接下来的章节将介绍 LLMs 能解决的问题、LLMs 面临的挑战,以及我们将在本书中实现的一般 LLM 架构。