16 KiB
本章涵盖以下内容:
- 计算训练集和验证集的损失,以评估训练过程中大型语言模型生成文本的质量
- 实现训练函数并预训练大语言模型
- 保存和加载模型权重以便继续训练大语言模型
- 从OpenAI加载预训练权重
在之前的章节中,我们实现了数据采样、注意力机制,并编写了 LLM 的架构。本章的核心是实现训练函数并对 LLM 进行预训练,详见图 5.1。
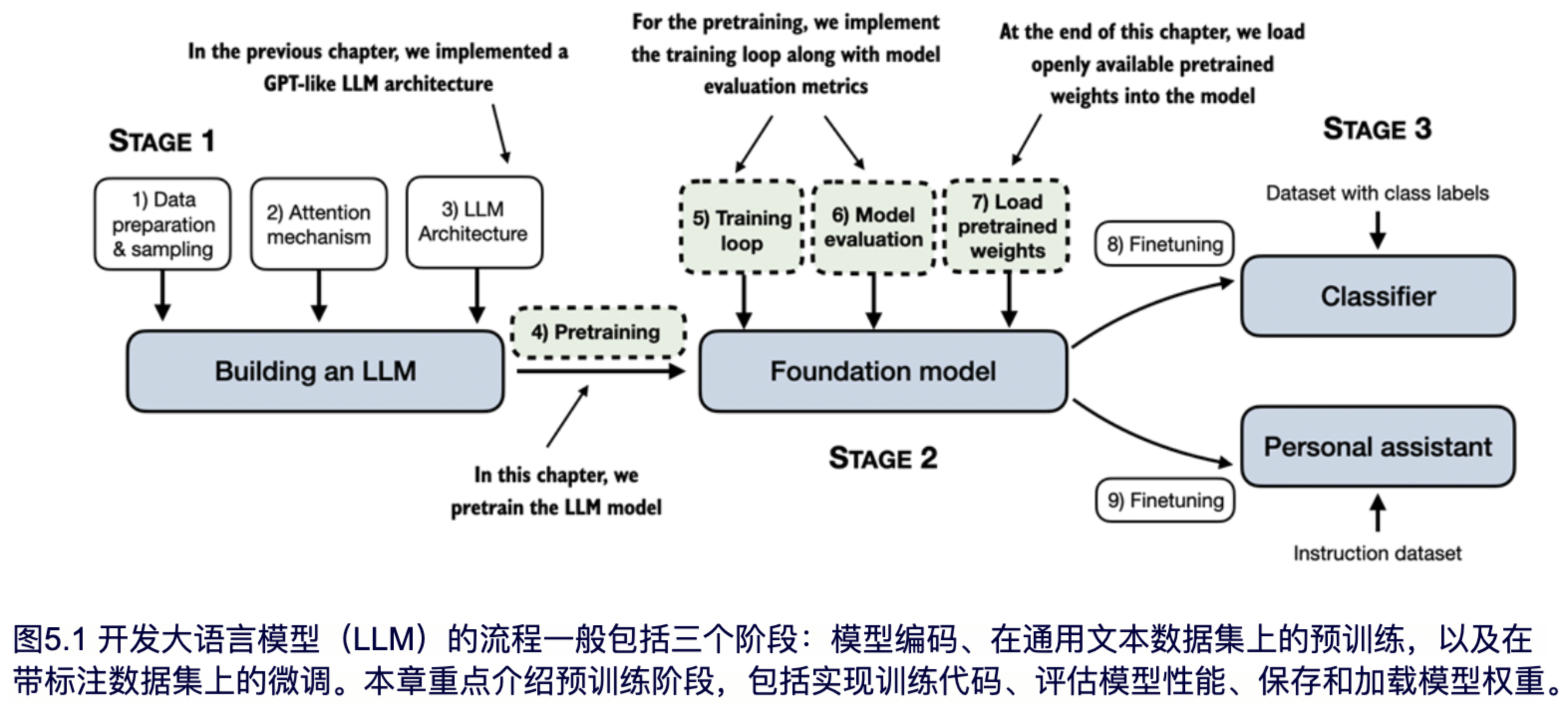
如图5.1所示,我们还将学习基本的模型评估技术,以衡量生成文本的质量,这是在训练过程中优化大语言模型的必要条件。此外,我们将讨论如何加载预训练权重,以便为接下来的微调提供坚实的基础。
[!NOTE]
权重参数
在大语言模型(LLM)和其他深度学习模型中,权重指的是可以通过训练过程调整的参数,通常也被称为权重参数或直接称为参数。在 PyTorch 等框架中,这些权重通常存储在各层(如线性层)中,举例来说,我们在第 3 章实现的多头注意力模块和第 4 章实现的GPT模型中就使用了线性层。在初始化一个层(例如,
new_layer = torch.nn.Linear(...))后,我们可以通过.weight属性访问其权重,例如new_layer.weight。此外,出于便利性,PyTorch还允许通过model.parameters()方法直接访问模型的所有可训练参数,包括权重和偏置,我们将在后续实现模型训练时使用该方法。
5.1 生成式文本模型的评估
本章开篇,我们将基于上一章的代码设置 LLM 进行文本生成,并讨论如何对生成文本质量进行评估的基本方法。我们在本节以及本章剩余部分讨论的内容已在图5.2中概述。
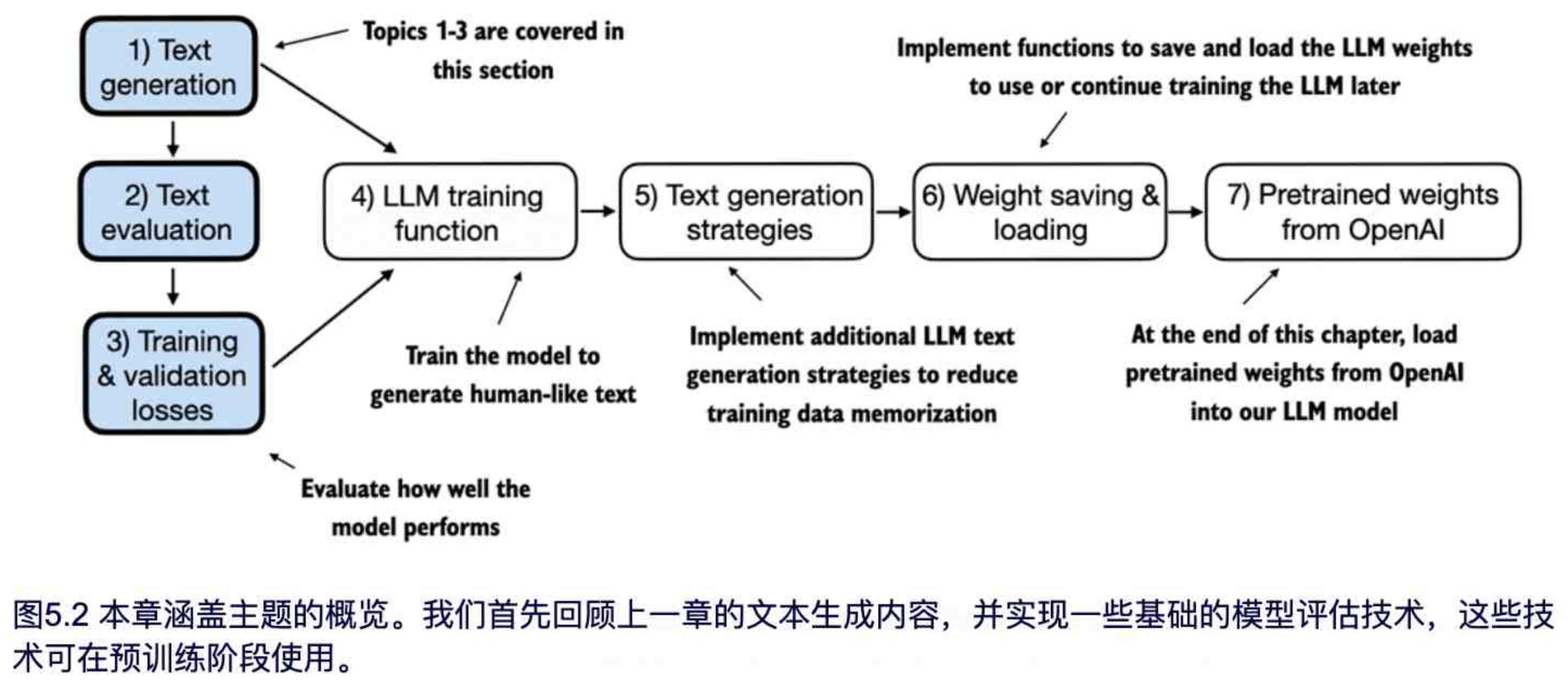
如图 5.2 所示,接下来的小节我们首先简要回顾上一章末尾的文本生成过程,然后深入探讨文本评估及训练和验证损失的计算方法。
5.1.1 使用 GPT 生成文本
在本节中,我们会先通过对 LLM 的设置简要回顾一下第四章中实现的文本生成过程。在开始这项工作之前,我们首先使用第 4 章中的 GPTModel 类和 GPT_CONFIG_124M 配置字典初始化 GPT 模型,在本章的后续章节会对其进行评估和训练。
import torch
from chapter04 import GPTModel
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 256, #A
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1, #B
"qkv_bias": False
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval()
#A 我们将上下文长度从1024个token缩短到256个token
#B 将 dropout 设置为 0 是一种常见的做法
在 GPT_CONFIG_124M 配置字典中,我们唯一的调整是将上下文长度(context_length)减少到 256 个 token。此项调整降低了模型训练的计算需求,使得可以在普通笔记本电脑上进行训练。
参数量为 1.24 亿的 GPT-2 模型最初被配置为可处理最多 1024 个 token。本章结束时,我们将更新上下文大小设置,并加载预训练权重,使模型能够支持 1024-token 的上下文长度。
在 GPT 模型实例中,我们使用了上一章介绍的 generate_text_simple 函数,并引入了两个实用函数 text_to_token_ids 和 token_ids_to_text,用于在文本和 token 表示之间进行转换。这是本章将会用到的一个技术。图 5.3 展示了这个过程,以便更清楚地说明。
我们通过前一章节中介绍的 generate_text_simple 函数来使用 GPTmodel 实例,同时引入了两个实用函数:text_to_token_ids 和token_ids_to_text。这些函数简化了文本与 token 表示之间的转换,本章中我们将多次使用这种技术。为了更清楚地理解这一过程,图 5.3 展示了这一流程,在深入代码之前,我们先通过图示帮助理解。
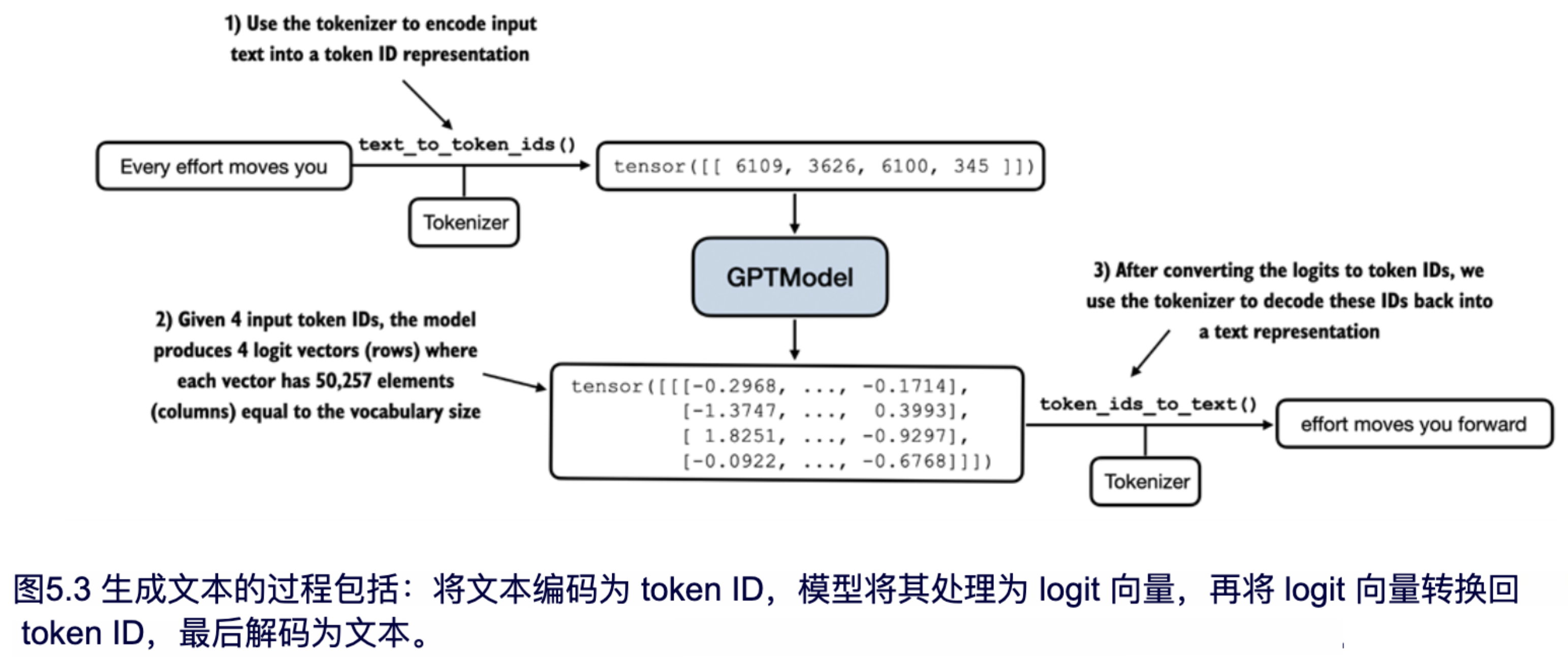
图 5.3 展示了使用 GPT 模型生成文本的三个主要步骤。首先,分词器将输入文本转换为一系列 token ID(在第 2 章中已有讨论)。然后,模型接收这些 token ID 并生成对应的 logits(即词汇表中每个 token 的概率分布,具体见第 4 章)。最后,将 logits 转换回 token ID,分词器将其解码为人类可读的文本,完成从文本输入到文本输出的循环。
我们通过代码来实现上述过程:
# Listing 5.1 Utility functions for text to token ID conversion
import tiktoken
from chapter04 import generate_text_simple
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # remove batch dimension
return tokenizer.decode(flat.tolist())
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
执行代码,模型生成的文本如下:
Output text:
Every effort moves you rentingetic wasnم refres RexMeCHicular stren
从输出可以看出,模型尚未生成连贯的文本,因为它还没有经过训练。为了定义文本的‘连贯性’或‘高质量’,我们需要实现一种数值方法来评估生成的内容。这一方法将帮助我们在训练过程中监控并提升模型的性能。
接下来将介绍如何计算生成内容的损失度量,该损失值会作为训练进展和效果的指示器。此外,在后续关于微调 LLM 的章节中,我们将探讨更多评估模型质量的方法。
5.1.2 文本生成损失的计算
本节将探讨如何通过计算‘文本生成损失’来数值化评估训练过程中生成的文本质量。我们将通过一个实际示例逐步讲解这一主题,首先简要回顾第 2 章的数据加载方式以及第 4 章的generate_text_simple函数如何生成文本。
图 5.4 展示了从输入文本到 LLM 生成文本的整体流程,该流程通过五个步骤实现。
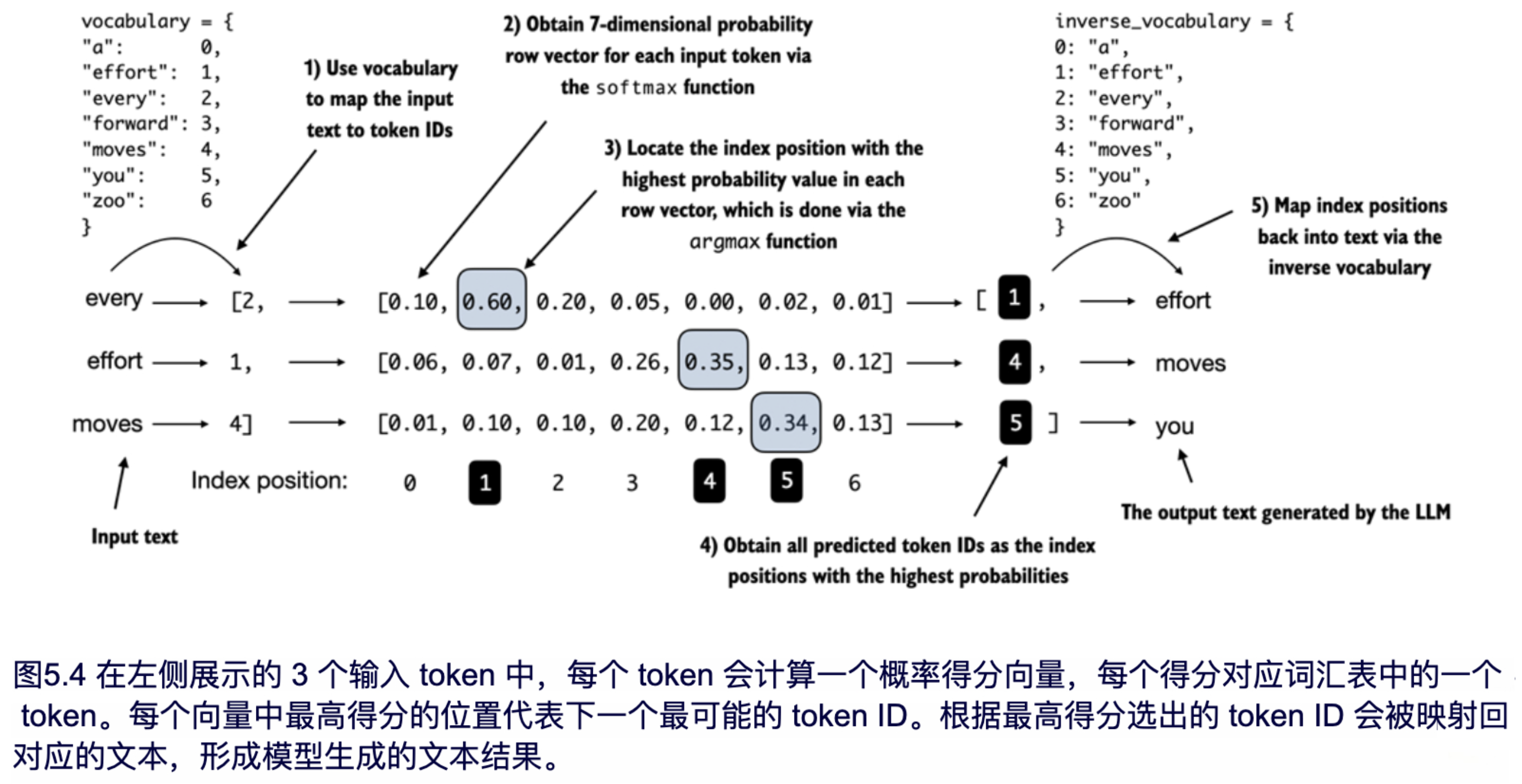
图 5.4 展示了第 4 章中generate_text_simple函数内部的本生成过程。在后续章节中计算生成文本的质量损失之前,我们需要先执行这些初始步骤。
在图 5.4 展示的文本生成过程中,为了便于在一页中展示图像,我们使用了仅包含 7 个 token 的小型词汇表。然而,GPTModel 实际上使用了包含 50,257 个词的大型词汇表,因此在接下来的代码中,token ID 的范围为 0 到 50,256,而不是图示中的 0 到 6。
图 5.4 为了简洁仅展示了一个文本示例 'every effort moves'。在接下来的代码示例中,我们将实现图 5.4 中的步骤,并使用两个输入示例 'every effort moves' 和 'I really like' 作为 GPT 模型的输入。
考虑两个输入样本,它们已经被转换为 token ID,对应图 5.4 中的步骤 1:
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
Matching these inputs, the `targets` contain the token IDs we aim for the model to
produce:
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[107, 588, 11311]]) # " really like chocolate"]
需要注意的是,目标值是输入数据,但向前偏移了一个位置。我们在第 2 章实现数据加载器时已介绍过这一概念。这种偏移策略对于教会模型预测序列中的下一个 token 至关重要。
当我们将两个输入示例(每个包含三个 token)输入模型,以计算它们的 logit 向量后,再应用 Softmax 函数将这些 logit 值转换为概率分数,这对应于图 5.4 中的步骤 2:
with torch.no_grad(): #A
logits = model(inputs)
probas = torch.softmax(logits, dim=-1) # Probability of each token in vocabulary
print(probas.shape)
#A 禁用梯度跟踪,因为我们尚未进行训练
生成的概率得分张量(probas)的维度如下:
torch.Size([2, 3, 50257])
第一个数字 2 表示输入中的两个样本(行),即批次大小。第二个数字 3 表示每个样本包含的 token 数量。最后一个数字表示嵌入维度的大小,通常由词汇表大小决定,前面章节已讨论。
通过 softmax 函数将 logits 转换为概率后,第 4 章的 generate_text_simple 函数会将概率分数进一步转换回文本,这一过程在图 5.4 的步骤 3 到步骤 5 中进行了展示。
接下来,通过对概率得分应用 argmax 函数,可以得到对应的 token ID(实现步骤 3 和 步骤 4):
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
print("Token IDs:\n", token_ids)
假设我们有 2 个输入样本,每个样本包含 3 个 token。在对概率分数应用 argmax 函数后(对应图 5.4 的第 3 步),会得到 2 组输出,每组包含 3 个预测的 token ID:
Token IDs:
tensor([[[16657], # First batch
[ 339],
[42826]],
[[49906], # Second batch
[29669],
[41751]]])
最后,步骤 5 将 token ID 转换回文本:
print(f"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")
When we decode these tokens, we find that these output tokens are quite different from
the target tokens we want the model to generate:
Targets batch 1: effort moves you
Outputs batch 1: Armed heNetflix
模型生成的文本与目标文本不同,因为它尚未经过训练。接下来,我们将通过‘损失’来数值化评估模型生成文本的质量(详见图 5.4)。这不仅有助于衡量生成文本的质量,还为实现训练函数提供了基础,训练函数主要通过更新模型权重来改善生成文本的质量。
文本评估过程的一部分(如图 5.5 所示)是衡量生成的 token 与正确预测目标之间的差距。本章后面实现的训练函数将利用这些信息来调整模型权重,使生成的文本更接近(或理想情况下完全匹配)目标文本。
模型训练的目标是提高正确目标 token ID 所在位置的 softmax 概率,如图 5.6 所示。接下来的部分中,我们还会将该 softmax 概率作为评价指标,用于对模型生成的输出进行数值化评估:正确位置上的概率越高,模型效果越好。
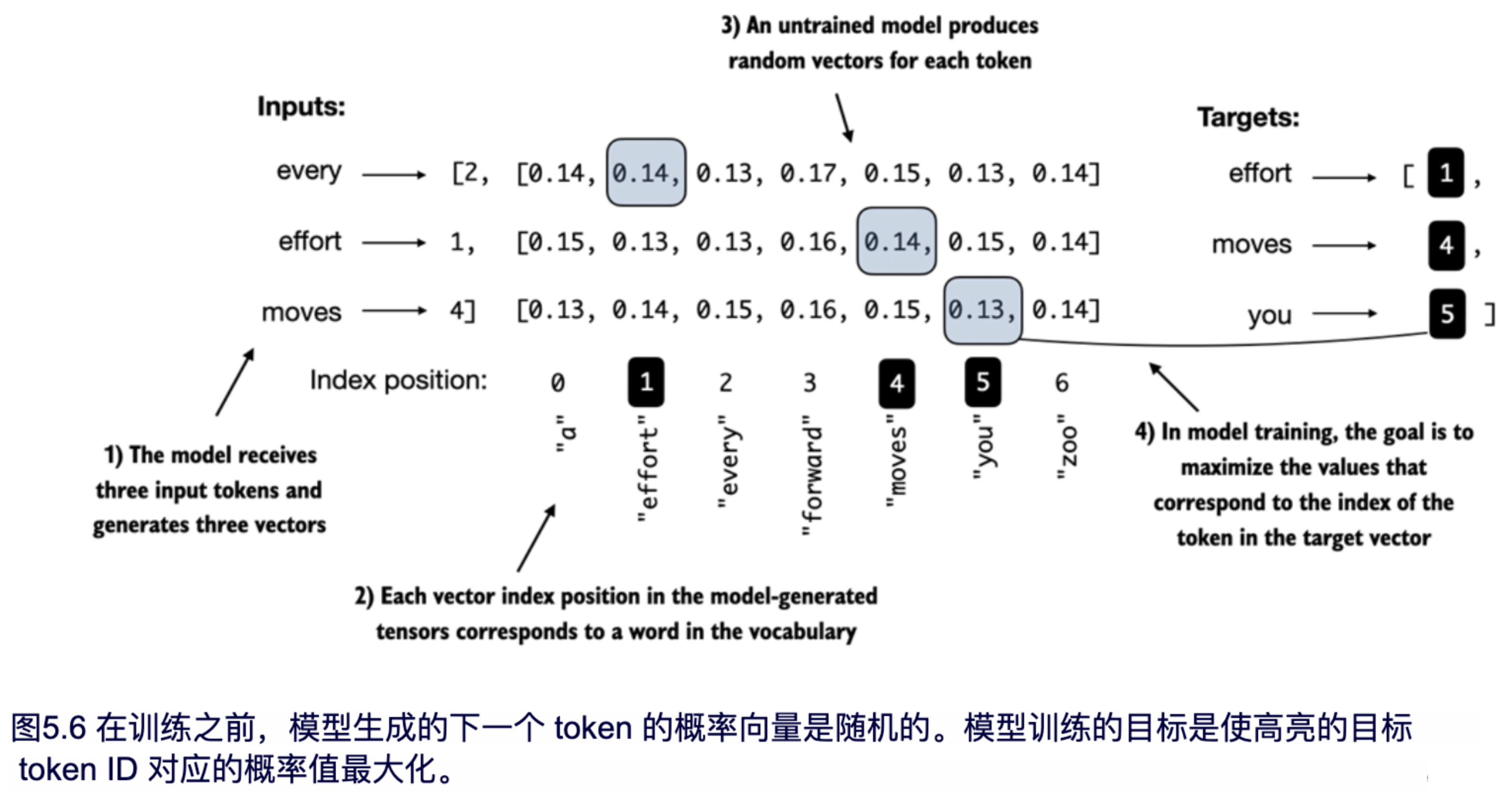
请注意,图 5.6 使用了一个包含 7 个 token 的简化词汇表,以便所有内容可以在一张图中展示。这意味着 softmax 的初始随机值会在 1/7 左右(约 0.14)。
然而,我们为 GPT-2 模型使用的词汇表包含 50,257 个 token,因此每个 token 的初始概率大约只有 0.00002(即 1/50,257)。
对于这两个输入文本,我们可以通过以下代码打印与目标 token 对应的初始 softmax 概率得分:
text_idx = 0
target_probas_1 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0, 1, 2], targets[text_idx]]
print("Text 2:", target_probas_2)
每个批次中 3 个目标 token ID 的概率如下:
Text 1: tensor([7.4541e-05, 3.1061e-05, 1.1563e-05])
Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])
训练 LLM 的目标是最大化这些概率值,使其尽量接近 1。这样可以确保 LLM 始终选择目标 token —— 即句中的下一个词,作为生成的下一个 token。
[!NOTE]
反向传播
如何最大化目标 token 的 softmax 概率值?整体思路是通过更新模型权重,使模型在生成目标 token 时输出更高的概率值。权重更新通过一种称为反向传播的过程来实现,这是一种训练深度神经网络的标准技术(关于反向传播和模型训练的更多细节可见附录 A 的 A.3 至 A.7 节)。
反向传播需要一个损失函数,该函数用于计算模型预测输出与实际目标输出之间的差异(此处指与目标 token ID 对应的概率)。这个损失函数用于衡量模型预测与目标值的偏差程度。
在本节接下来的部分中,我们将针对target_probas_1和target_probas_2的概率得分计算损失。图 5.7 展示了主要步骤。

由于我们已经完成了图 5.7 中列出的步骤 1-3,得到了 target_probas_1 和 target_probas_2,现在进行第 4 步,对这些概率得分取对数:
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
print(log_probas)
计算结果如下:
tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])
在数学优化中,处理概率得分的对数比直接处理概率得分更为简便。该主题超出本书的讨论范围,但我在一个讲座中对此进行了详细讲解,链接位于附录 B 的参考部分。
[!TIP]
个人思考: 在继续接下里的计算之前,我们首先来探讨一下,对数在损失函数的应用中到底有什么作用。
为什么要用概率的对数
在 LLM 中,概率得分通常是小于1的数(例如0.1、0.05等),直接用这些数进行计算和优化可能会面临一些问题。比如,如果多个概率相乘,结果会变得非常小,甚至接近0。这种情况称为“数值下溢”(Numerical Underflow),可能导致计算不稳定。
我们有三个概率值,分别为0.2、0.1和0.05。如果我们计算这些值的乘积,结果是:
0.2×0.1×0.05=0.001这个值非常小,尤其在深度学习或概率模型中,我们通常会有成千上万个概率需要相乘,这样会导致最终的乘积接近0甚至为0,造成数值计算的不稳定性。
如果我们对这些概率值取对数,然后相加,而不是直接相乘,我们可以避免这个问题。例如,对这三个值取自然对数(logarithm)后再相加:
ln(0.2)+ln(0.1)+ln(0.05)≈−1.6094+(−2.3026)+(−2.9957)=−6.9077虽然这个和也是负数,但它不会像直接相乘的结果那样接近于0,避免了数值下溢的问题。对数的累加性质允许我们将原本的累乘操作转换为累加,使得计算更加稳定和高效。
归属概率在损失函数中的作用
GPT模型训练的目标是最大化正确目标 token 的概率,通常,我们会使用交叉熵损失来衡量模型预测与实际目标之间的差异。对于一个目标 token 序列
` y=(y1,y2,…,yn) `,GPT会生成一个对应的预测概率分布` P(y∣x) `,其中 x 是模型的输入。交叉熵损失的公式:
在计算交叉熵损失时,我们希望最大化模型分配给每个正确目标token的概率。交叉熵损失的数学公式为:
\text { Loss }=-\sum_{t=1}^{T} \ln P\left(y_{t} \mid x, \theta\right)其中:
- T 是序列长度
- yt 是在位置 ttt 上的目标token
- P(yt∣x,θ) 是模型在参数 θ 下对目标token yt 的条件概率
在公式中,对每个token的概率 P(yt∣x,θ) 取对数,将乘积形式的联合概率转换为求和形式,有助于避免数值下溢,同时简化优化过程。