19 KiB
本章涵盖以下内容:
- 为大语言模型的训练准备文本数据集
- 将文本分割成词和子词token
- 字节对编码(Byte Pair Encoding,BPE):一种更为高级的文本分词技术
- 使用滑动窗口方法采样训练示例
- 将tokens转换为向量,输入到大语言模型中
在上一章中,我们介绍了大语言模型(LLMs)的基本结构,并了解到它们基于海量的文本数据集进行预训练。我们特别关注的是仅使用通用 Transformer 架构中解码器部分的 LLMs,这也是 ChatGPT 和其他流行的类似 GPT 的 LLM 所依赖的模型。
在预训练阶段,LLMs 逐字处理文本。通过使用下一个单词预测任务训练拥有数百万到数十亿参数的 LLMs,最终能够生成具有出色能力的模型。这些模型随后可以进一步微调,以遵循指令或执行特定目标任务。然而,在我们接下来几章中实现和训练 LLMs 之前,我们需要准备训练数据集,这也是本章的重点,如图 2.1 所示。
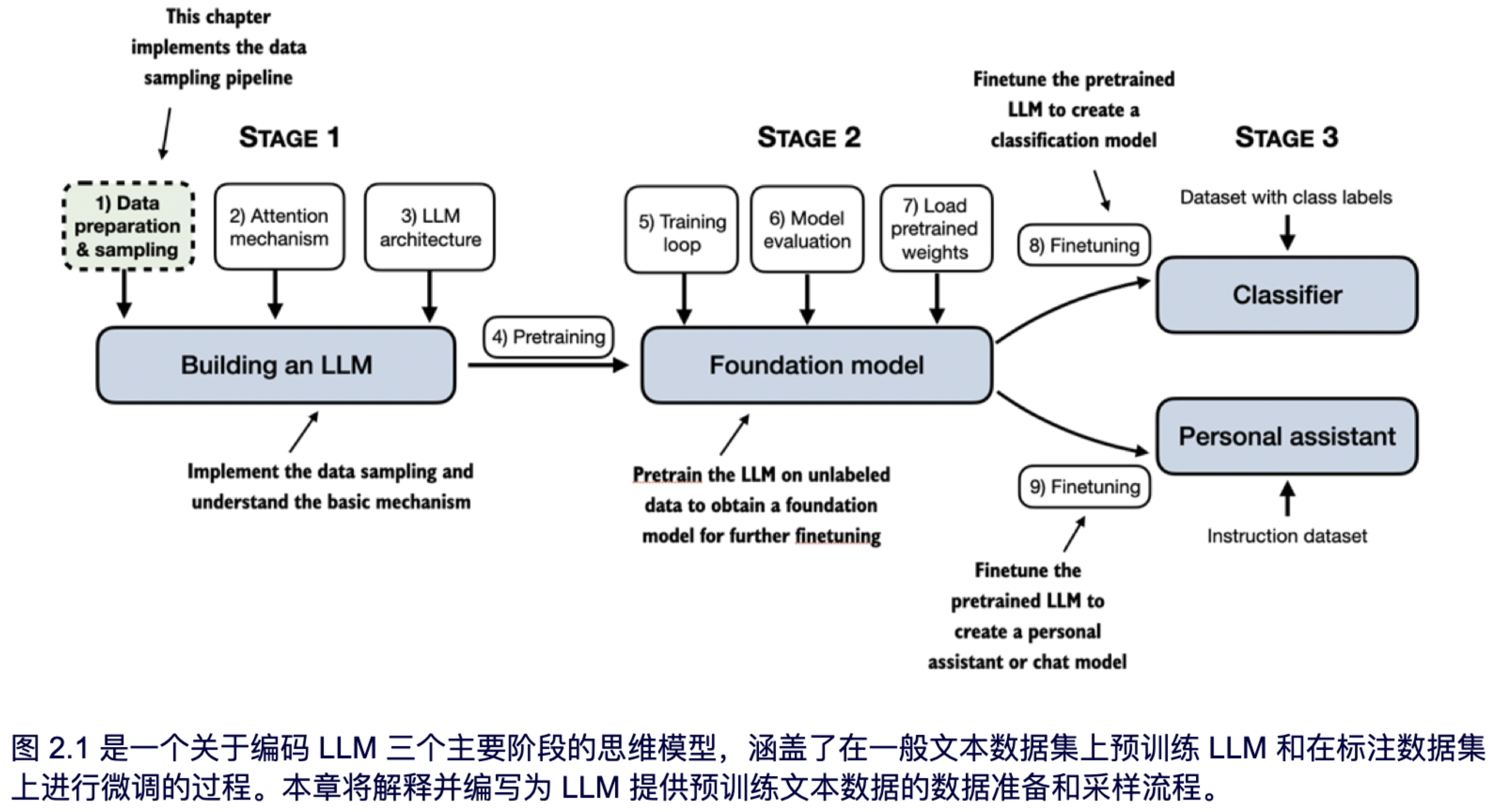
在本章中,您将学习如何为训练 LLM 准备输入文本。这包括将文本拆分为单个单词和子词token,并将这些token编码为 LLM 的向量表示。您还将了解一些先进的token分割方案,比如字节对编码,这种方法在像 GPT 这样的流行 LLM 中得到应用。最后,我们将实现一个采样和数据加载策略,以生成后续章节中训练 LLM 所需的输入输出对。
2.1 理解词嵌入
深度神经网络模型,包括 LLM,往往无法直接处理原始文本。这是因为文本是分类数据,它与实现和训练神经网络所需的数学运算不兼容。因此,我们需要一种方法将单词表示为连续值向量。(对计算中向量和张量不熟悉的读者,可以在附录 A 的 A2.2 节中了解更多关于张量的内容。)
将数据转换为向量格式的过程通常被称为嵌入(embedding)。我们可以通过特定的神经网络层或其他预训练的神经网络模型来对不同类型的数据进行嵌入,比如视频、音频和文本,如图 2.2 所示。
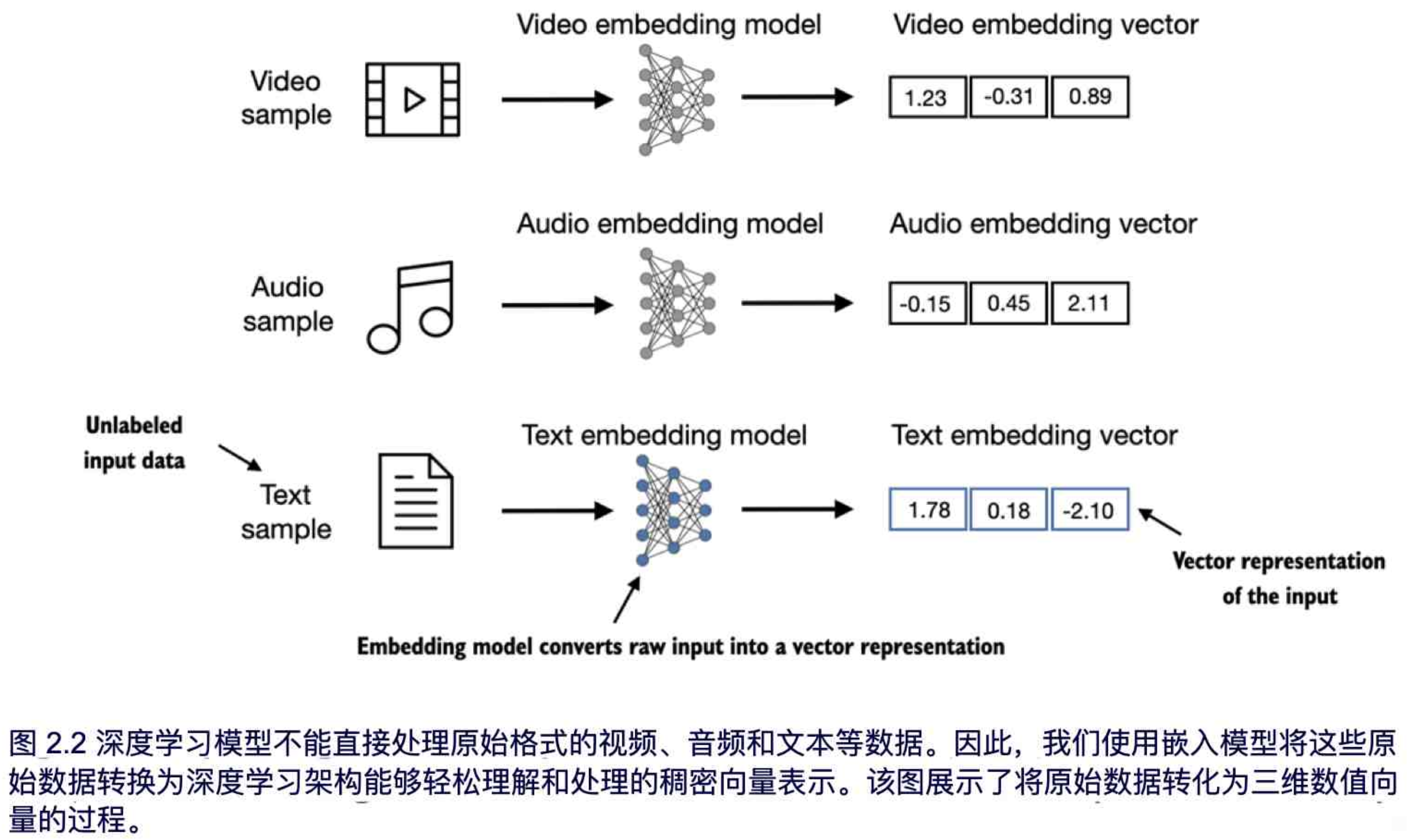
如图 2.2 所示,我们可以使用嵌入模型来处理多种不同的数据格式。然而,值得注意的是,不同的数据格式需要使用不同的嵌入模型。例如,专为文本设计的嵌入模型并不适用于音频或视频数据的嵌入。
[!TIP]
个人思考: 不同格式的数据源(如文本、图像、音频、视频)在处理和嵌入时,需要不同的模型和技术,原因在于它们的数据结构、特征和处理方式各不相同,因此需要针对性的方法将这些不同的数据类型转换为适合神经网络处理的向量表示。以下总结了不同数据源在嵌入时的一些区别:
数据类型 数据特征 嵌入模型 主要特征 文本 离散的、序列化的符号数据 Word2Vec, GloVe, BERT, GPT 等 语义关系、上下文理解 图像 二维像素网格,具有空间特征 CNN(ResNet、VGG)、ViT 形状、纹理、颜色等视觉特征 音频 一维时序信号 CNN+频谱图、RNN、Transformer 频率、音调、时序依赖 视频 时空序列数据 3D CNN、RNN+CNN、Video Transformer 时空特征、动作捕捉
嵌入的本质是将离散对象(如单词、图像或整个文档)映射到连续向量空间中的点。嵌入的主要目的是将非数值数据转换为神经网络能够处理的格式。
虽然单词嵌入是最常用的文本嵌入形式,但也存在句子、段落或整篇文档的嵌入。句子和段落嵌入常被用于检索增强生成技术。检索增强生成结合了文本生成与从外部知识库中检索相关信息的过程,这是一种超出本书讨论范围的技术。由于我们希望训练类似于GPT的LLM,这些模型以逐字的方式生成文本,因此本章将重点放在单词嵌入上。
[!TIP]
个人思考: 这里聊一下检索增强技术(RAG),目前已经广泛应用于特定领域的知识问答场景。尽管GPT在文本生成任务重表现强大,但它们依赖的是预训练的知识,这以为着它们的回答依赖于模型在预训练阶段学习到的信息。这就导致了几个问题:
- 知识的有效性: 模型的知识基于它的预训练数据,因此无法获取最新的信息。比如,GPT-3 的知识截止到 2021 年,无法回答最新的事件或发展。
- 模型大小的限制: 即使是大型模型,所能存储和运用的知识也是有限的。如果任务涉及特定领域(如医学、法律、科学研究),模型在预训练阶段可能没有涵盖足够的信息。
- 生成的准确性: 生成模型可能会凭空编造信息(即“幻觉现象”),导致生成内容不准确或虚假。
而检索增强技术正是为了解决上述不足,它大致原理为将外部知识库(如文档、数据库、互联网等)进行向量化后存入到向量数据库中。当用户提交一个查询时,首先将这个查询也编码成一个向量,然后去承载外部知识库的向量数据种检索(检索技术有很多种)与问题相关的信息。检索到的信息被作为额外的上下文信息输入到LLM中,LLM会将这些外部信息与原始输入结合起来,以更准确和丰富的内容生成回答。想要进一步了解RAG技术及其应用,可以参考:RAG 专区
生成单词嵌入的算法和框架有很多。其中,Word2Vec是较早且最受欢迎的项目之一。Word2Vec通过预测给定目标词的上下文或反之,训练神经网络架构以生成单词嵌入。Word2Vec的核心思想是,出现在相似上下文中的词通常具有相似的含义。因此,当将单词投影到二维空间进行可视化时,可以看到相似的词汇聚在一起,如图2.3所示。
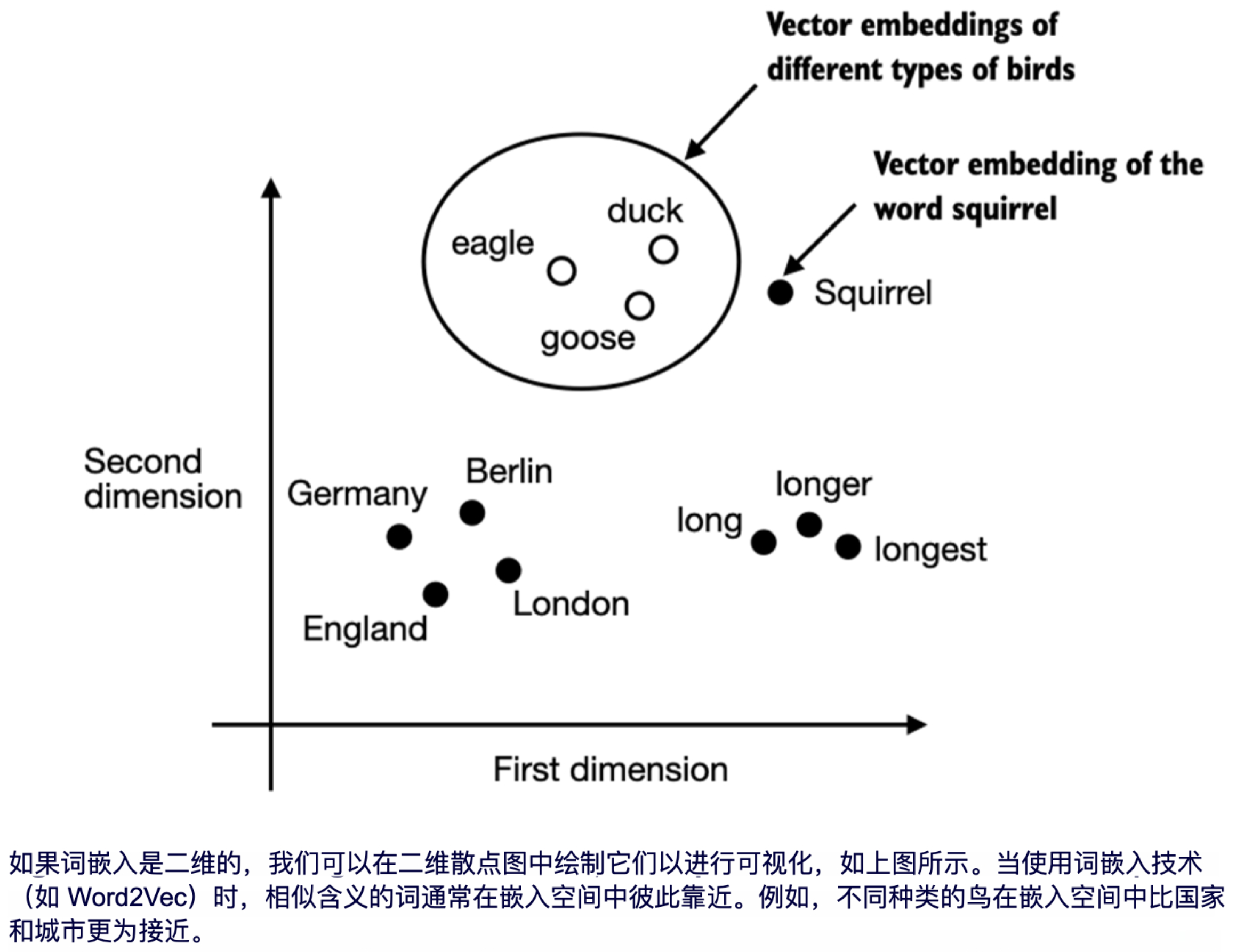
词嵌入可以具有不同的维度,从一维到数千维。如图2.3所示,我们可以选择二维词嵌入进行可视化。更高的维度可能捕捉到更细微的关系,但代价是计算效率的降低。
虽然我们可以使用预训练模型(例如 Word2Vec)为机器学习模型生成嵌入,但 LLMs 通常会生成自己的嵌入,这些嵌入是输入层的一部分,并在训练过程中进行更新。将嵌入作为 LLM 训练的一部分进行优化,而不直接使用 Word2Vec,有一个明确的优势,就是嵌入能够针对特定的任务和数据进行优化。我们将在本章后面实现这样的嵌入层。此外,LLMs 还能够创建上下文化的输出嵌入,这一点我们将在第三章中讨论。
高维嵌入在可视化中面临挑战,因为我们的感官感知和常见的图形表示本质上只限于三维或更少的维度,这也是图 2.3 采用二维散点图展示二维嵌入的原因。然而,在处理 LLMs 时,我们通常使用的嵌入的维度远高于图 2.3 所示的维度。对于 GPT-2 和 GPT-3,嵌入的大小(通常称为模型隐状态的维度)会根据具体的模型变体和大小而有所不同。这是性能与效率之间的权衡。以具体示例为例,最小的 GPT-2 模型(117M 和 125M 参数)使用 768 维的嵌入大小,而最大的 GPT-3 模型(175B 参数)则使用 12,288 维的嵌入大小。
本章接下来的部分将系统地介绍准备 LLM 使用的嵌入所需的步骤,这些步骤包括将文本拆分为单词、将单词转换为token,以及将token转化为嵌入向量。
2.2 文本分词
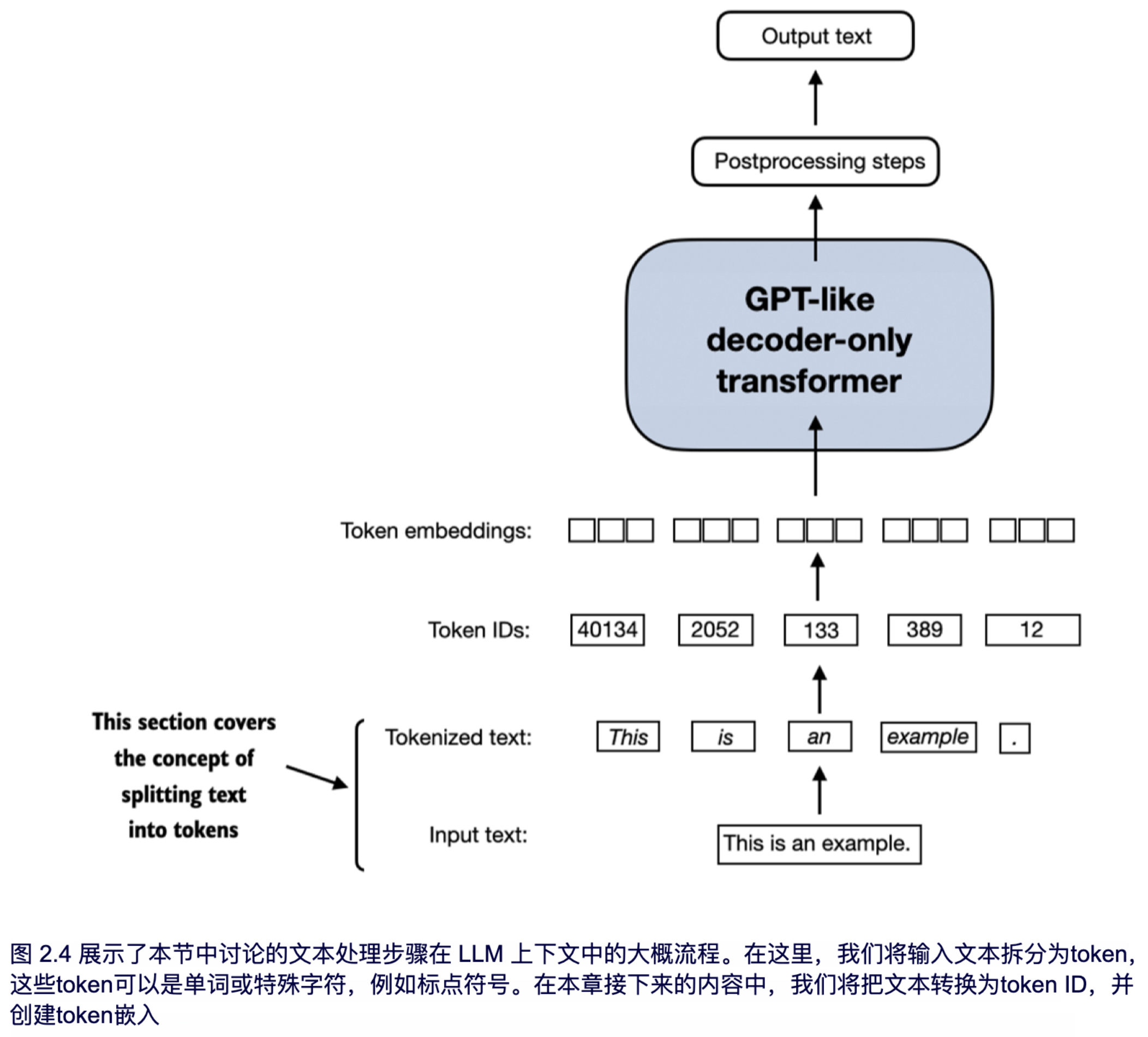
本节将讨论如何将输入文本拆分为单个token,这是创建 LLM 嵌入所需的预处理步骤。这些token可以是单个单词或特殊字符,包括标点符号,具体如图 2.4 所示。
我们即将用于 LLM 训练的文本数据集是一部由 Edith Wharton 创作的短篇小说《判决》,该作品已在网上公开,因此允许用于 LLM 训练任务。该文本可在 Wikisource 上找到,网址是 https://en.wikisource.org/wiki/The_Verdict,您可以将其复制并粘贴到文本文件中。我已将其复制到名为 "the-verdict.txt" 的文本文件中,以便使用 Python 的标准文件读取工具进行加载。
# Listing 2.1 Reading in a short story as text sample into Python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
另外,您可以在本书的 GitHub 仓库中找到名为 "the-verdict.txt" 的文件,网址是 https://github.com/rasbt/LLMs-from-scratch/tree/main/ch02/01_main-chapter-code
便于演示的目的,print命令输出文件的总字符数以及前100个字符。
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so
it was no
我们的目标是将这篇 20,479 个字符的短篇小说拆分为单词和特殊字符,然后在接下来的章节中将这些token转换为 LLM 训练所需的嵌入。
[!NOTE]
样本规模
请注意,在处理 LLM 时,通常会处理数百万篇文章和数十万本书——也就是几 GB 的文本。然而,为了教学目的,使用像单本书这样的小文本样本就足够了,这样可以阐明文本处理步骤的主要思想,并能够在消费级硬件上合理地运行。
要如何做才能最好地拆分这段文本以获得token列表呢?为此,我们来进行一个小小的探讨,使用 Python 的正则表达式库 re 进行说明。(请注意,您不需要学习或记住任何正则表达式语法,因为在本章后面我们将使用一个预构建的分词器。)
使用一些简单的示例文本,我们可以使用 re.split 命令,按照以下语法拆分文本中的空白字符:
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
执行结果是一个包含单词、空白和标点符号的列表:
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
请注意,上述简单的分词方案仅仅用于将示例文本拆分为单个单词,然而有些单词仍然与我们希望单独列出的标点符号相连。我们也无需将所有文本转换为小写字母,因为大写字母有助于 LLM 区分专有名词和普通名词,理解句子结构,并学习生成正确的大写文本。
让我们修改正则表达式,将空白字符(\s)、逗号和句点([,.])单独拆分出来:
result = re.split(r'([,.]|\s)', text)
print(result)
我们可以看到,单词和标点符号现在已经成为单独一项,跟我们预期一致:
['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']
一个剩余的小问题是列表仍然包含空白字符。我们可以安全地按如下方式删除这些多余的字符:
result = [item for item in result if item.strip()]
print(result)
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
[!NOTE]
关于是否删除空白字符的探讨
在开发一个简单的分词器时,是否将空白字符编码为单独的字符,或者直接将其删除,取决于我们的应用和需求。删除空白字符可以减少内存和计算资源的消耗。然而,如果我们训练的模型对文本的确切结构敏感(例如,Python 代码对缩进和空格非常敏感),那么保留空白字符就很有用。在这里,为了简化和缩短分词化输出,我们选择删除空白字符。稍后,我们将切换到一个包含空白字符的分词化方案。
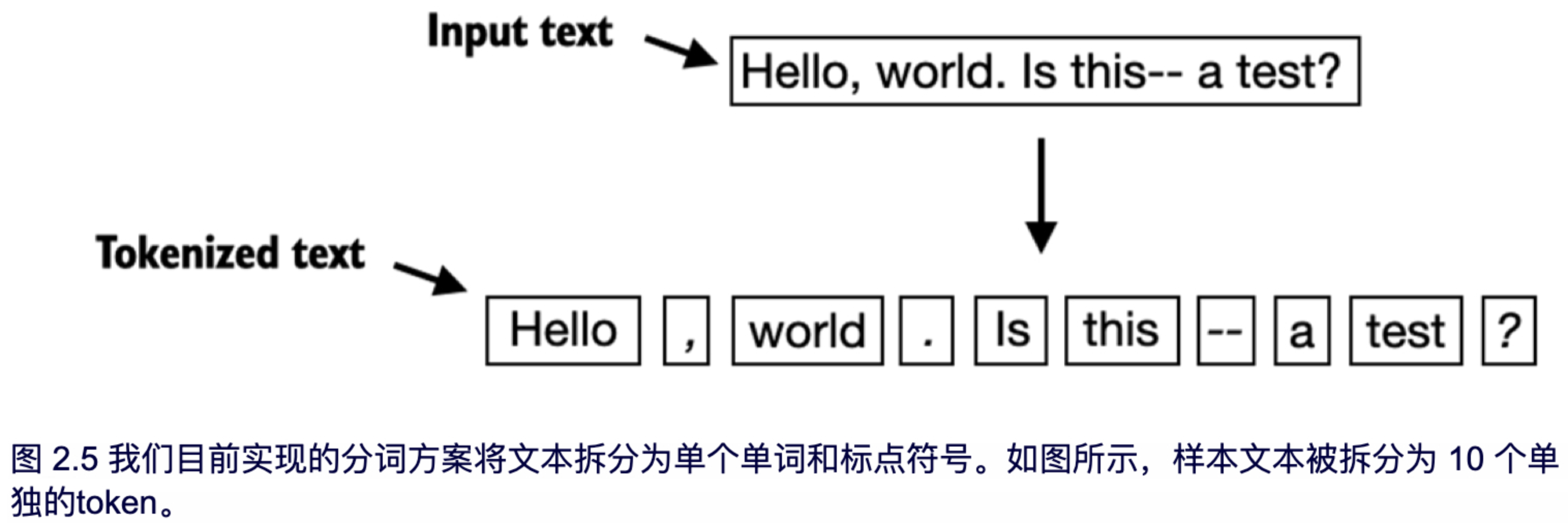
我们上面设计的分词方案在简单的示例文本中表现良好。让我们进一步修改它,使其能够处理其他类型的标点符号,如问号、引号,以及在 Edith Wharton 短篇小说的前 100 个字符中看到的双破折号,还有其他特殊字符:
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
执行后输出如下:
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
如图 2.5 所示,我们的分词方案现在能够成功处理文本中的各种特殊字符。
现在我们已经有了一个基本的分词器,接下来让我们将其应用于艾迪丝·沃顿的整篇短篇小说:
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(len(preprocessed))
上述代码的输出是4690,这是小说的token数量(不包含空白字符)。
让我们检查一下前30个token:
print(preprocessed[:30])
生成的输出显示,我们的分词器似乎很好地处理了文本,因为所有单词和特殊字符都被很好地分开了:
['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
2.3 将 tokens 转换为token IDs
在前一章节中,我们将艾迪丝·华顿的短篇小说分词为单独的token。在本节中,我们将把这些token从字符串转换为整形,以生成所谓的token ID。这一步是将token ID 转换为嵌入向量的中间步骤。
为了将先前生成的token映射到token ID,我们首先需要构建一个词汇表。这个词汇表定义了每个独特单词和特殊字符与唯一整数的映射,如图 2.6 所示。
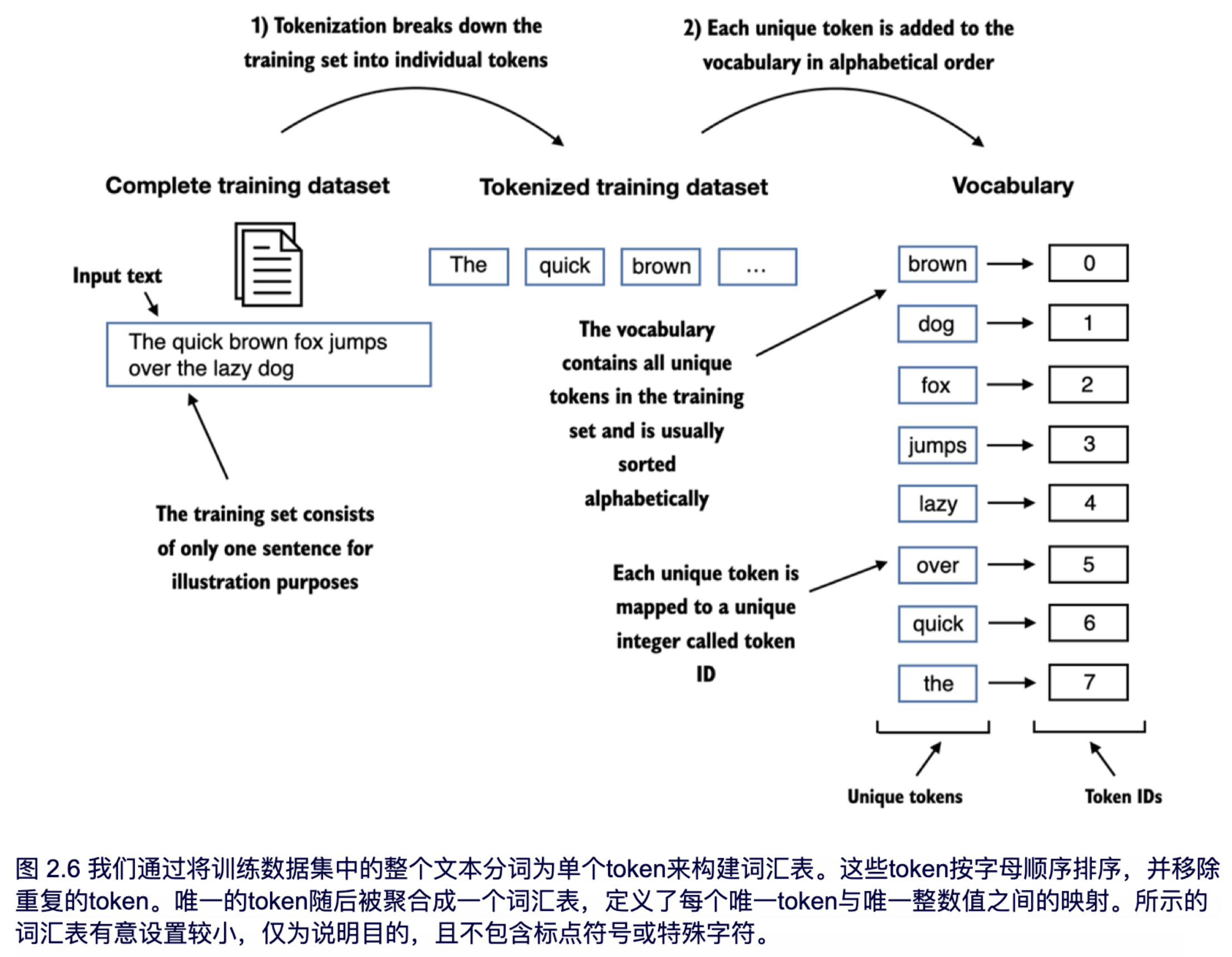
在前一章节中,我们将艾迪丝·华顿的短篇小说进行分词,并将其存储在名为 preprocessed 的 Python 变量中。现在,让我们创建一个包含所有唯一token的列表,并按字母顺序对其进行排序,以确定词汇表的大小:
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
print(vocab_size)
在通过上述代码确定词汇表的大小为 1,130 后,我们通过以下代码创建词汇表并打印其前 51 个条目以便于说明:
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i > 50:
break
输出如下:
('!', 0)
('"', 1)
("'", 2)
...
('Her', 49)
('Hermia', 50)
根据输出可知,词汇表包含了与唯一整数标签相关联的单个token。我们接下来的目标是利用这个词汇表,将新文本转换为token ID,如图 2.7 所示。
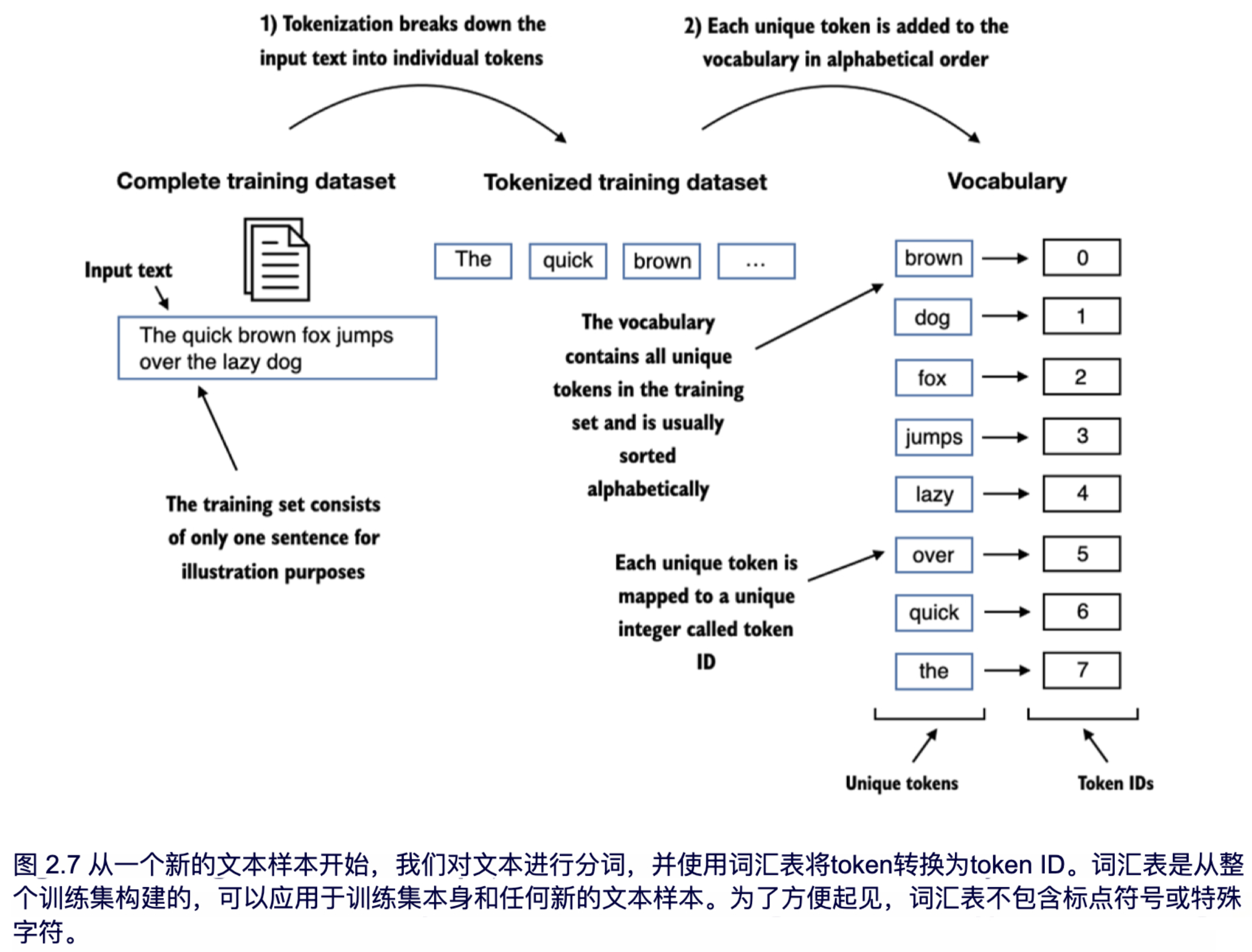
在本书后面,当我们想将 LLM 的输出从数字转换回文本时,我们还需要一种将token ID 转换为文本的方法。为此,我们可以创建一个词汇表的反向版本,将token ID 映射回相应的文本token。
让我们在 Python 中实现一个完整的分词器类,其中包含一个 encode 方法,该方法将文本拆分为token,并通过词汇表进行token字符串到整数(token ID)的映射,以通过词汇表生成token ID。此外,我们还将实现一个 decode 方法,该方法进行整数到字符串的反向映射,将token ID 转换回文本。
该分词器的代码实现如下:
# Listing 2.3 Implementing a simple text tokenizer
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab #A
self.int_to_str = {i:s for s,i in vocab.items()} #B
def encode(self, text): #C
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids): #D
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) #E
return text
#A 将词汇表作为类属性存储,以方便在 encode 和 decode 方法中访问
#B 创建一个反向词汇表,将token ID 映射回原始的文本token
#C 将输入文本转换为token ID
#D 将token ID 还原为文本
#E 在指定的标点符号前去掉空格
使用上述的 SimpleTokenizerV1 Python 类,我们现在可以使用现有的词汇表实例化新的分词器对象,并利用这些对象对文本进行编码和解码,如图 2.8 所示。
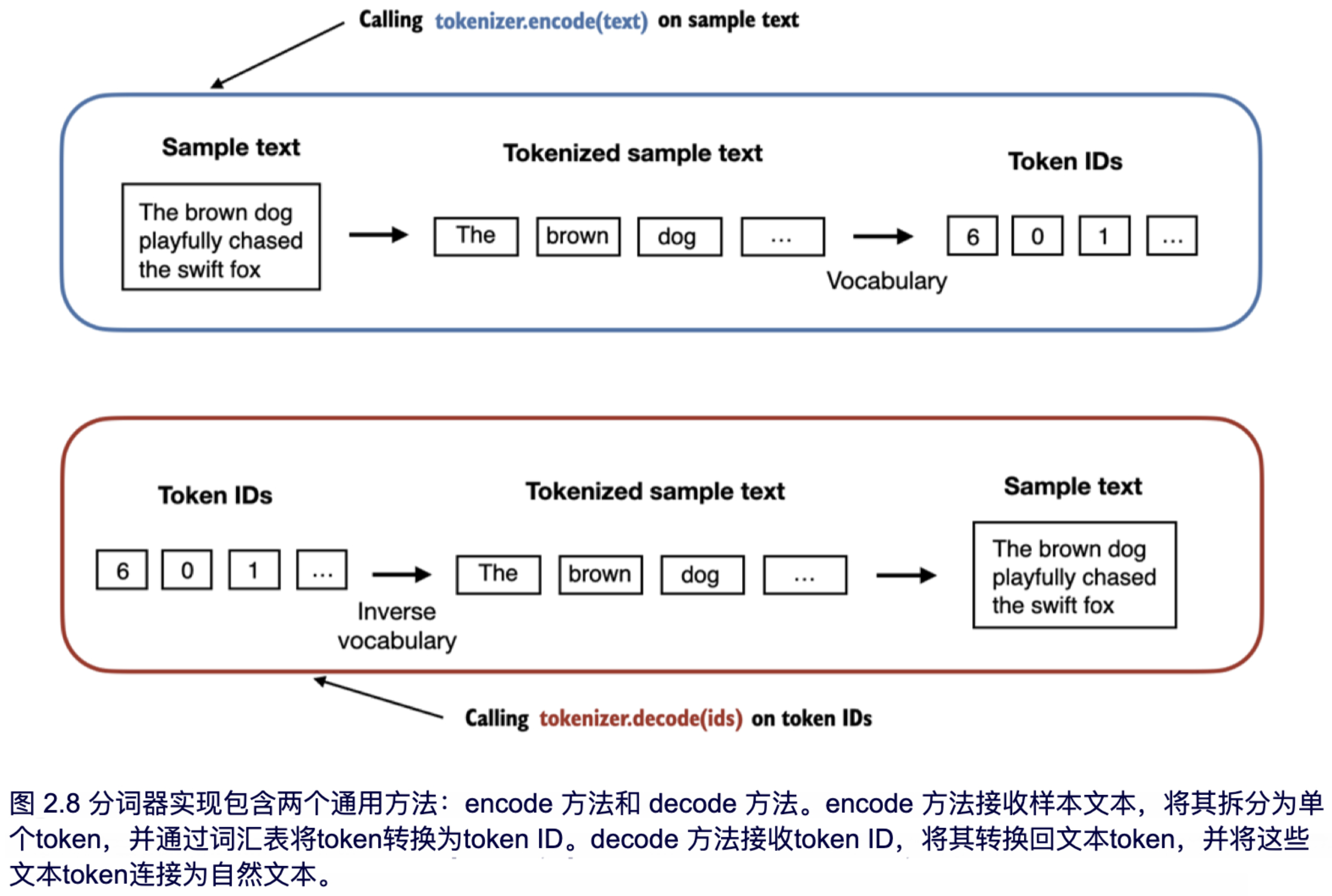
让我们通过 SimpleTokenizerV1 类实例化一个新的分词器对象,并对艾迪丝·华顿的短篇小说中的一段文本进行分词,以便在实践中进行尝试:
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
上面的代码打印出以下token ID:
下来,让我们看看能否通过 decode 方法将这些token ID 转换回文本:
print(tokenizer.decode(ids))
输出如下:
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
根据以上的输出,我们可以看到 decode 方法成功将token ID 转换回了原始文本。
到目前为止,一切都很顺利。我们实现了一个分词器,能够根据训练集中的片段对文本进行分词和去分词。现在让我们将其应用于训练集中未包含的新文本样本:
text = "Hello, do you like tea?"
print(tokenizer.encode(text))
执行上述代码将导致以下错误:
...
KeyError: 'Hello'
问题在于短篇小说《裁决》中没有使用“Hello”这个词。因此,它不包含在词汇中。这突显了在处理大型语言模型时,需要考虑大型和多样化的训练集以扩展词汇的必要性。
在下一节中,我们将进一步测试分词器在包含未知词汇的文本上的表现,并且我们还将讨论可以用于在训练期间为LLM提供更多上下文的额外特殊tokens。