+
+
+
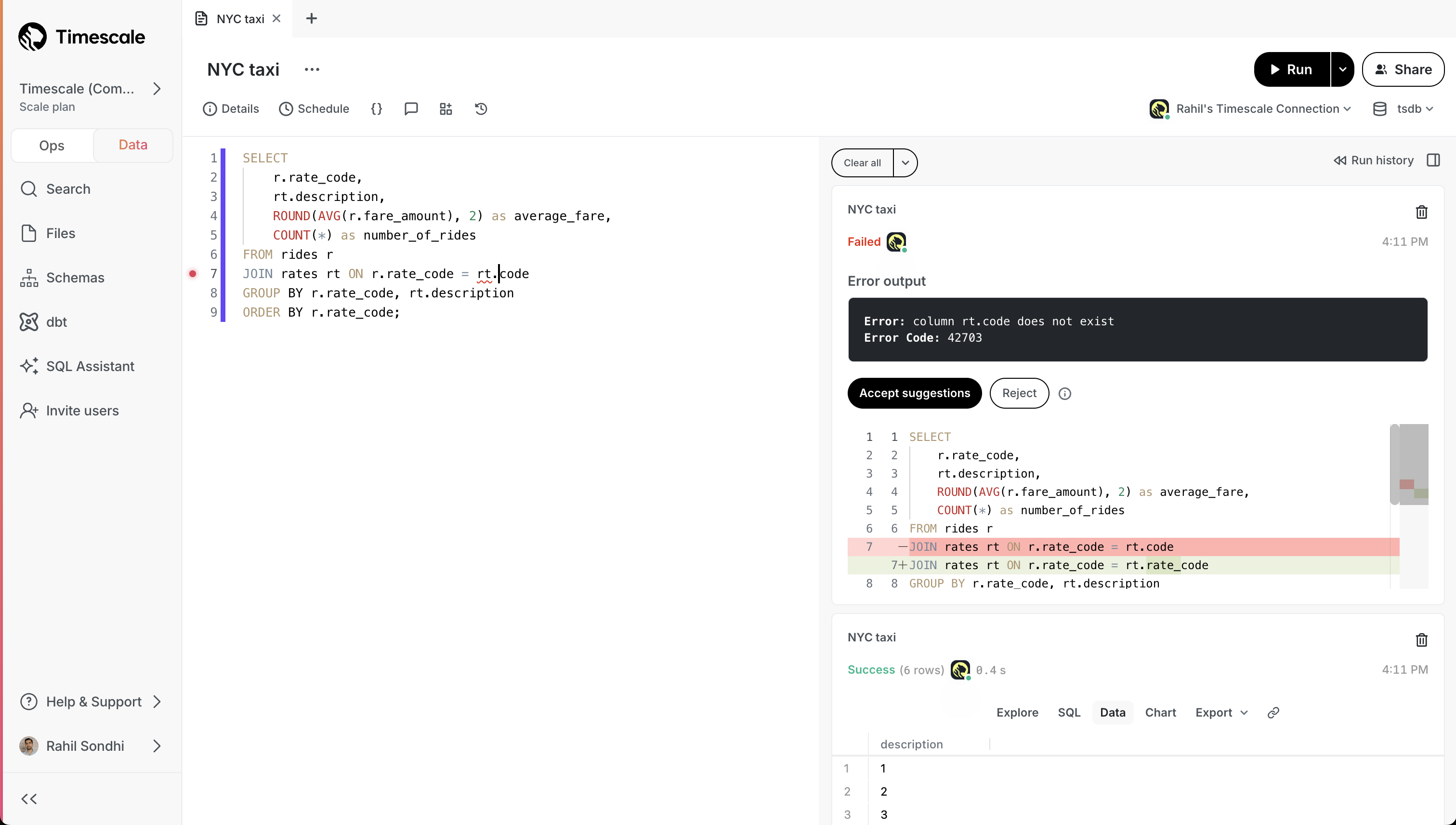
+- **Error resolution**: when you run into an error, SQL Assistant proposes a recommended fix that you can choose to accept.
+
+
+
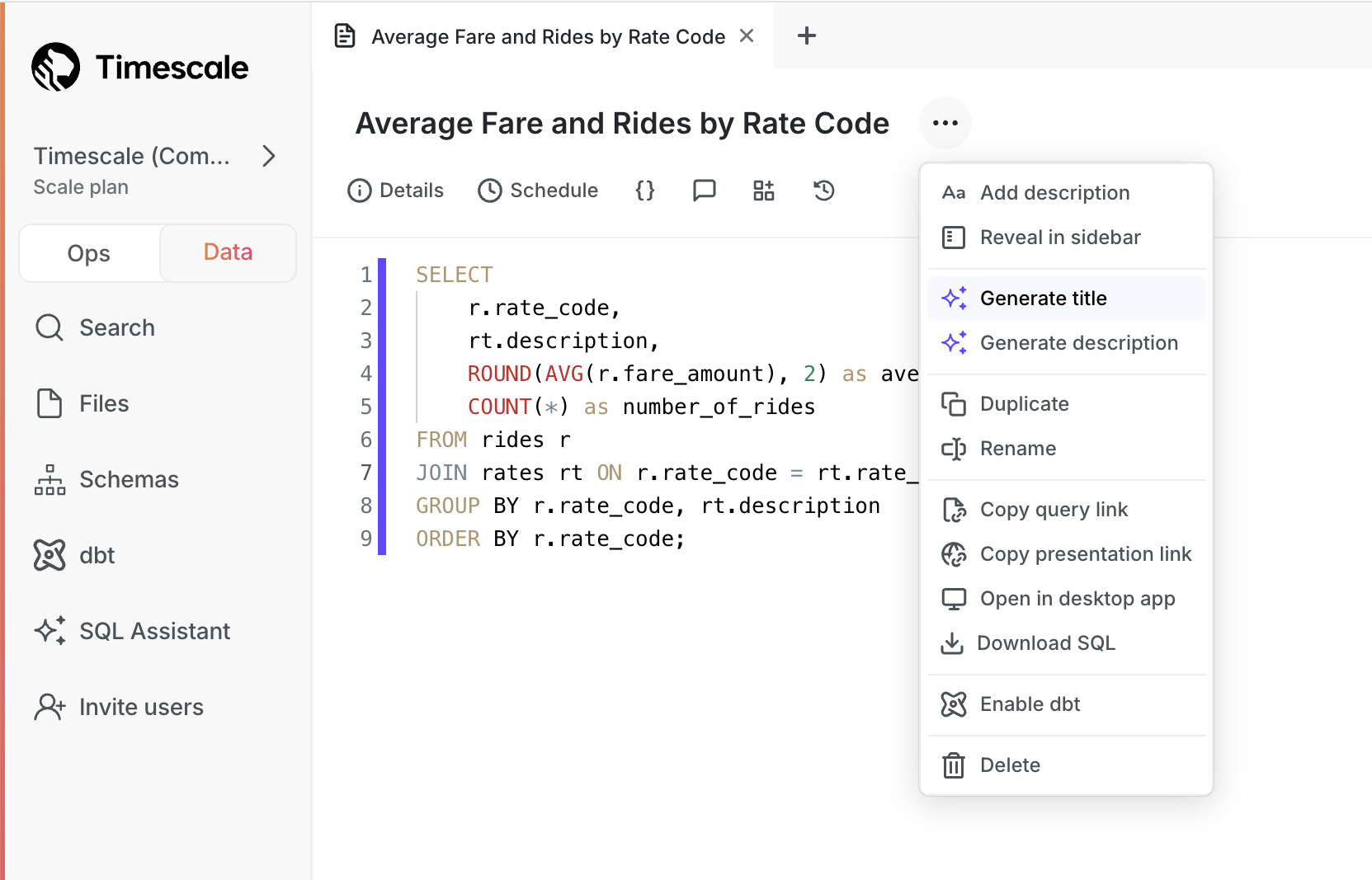
+- **Generate titles and descriptions**: click a button and SQL Assistant generates a title and description for your query. No more untitled queries!
+
+
+
+See our [blog post](https://www.tigerdata.com/blog/postgres-gui-sql-assistant/) or [docs](https://docs.tigerdata.com/getting-started/latest/run-queries-from-console/#sql-assistant) for full details!
+
+### 🏄 TimescaleDB v2.17 - performance improvements for analytical queries and continuous aggregate refreshes
+
+Starting this week, all new services created on Timescale Cloud use [TimescaleDB v2.17](https://github.com/timescale/timescaledb/releases/tag/2.17.0). Existing services are upgraded gradually during their maintenance windows.
+
+TimescaleDB v2.17 significantly improves the performance of [continuous aggregate refreshes](https://docs.timescale.com/use-timescale/latest/continuous-aggregates/refresh-policies/), and contains performance improvements for [analytical queries and delete operations](https://docs.timescale.com/use-timescale/latest/compression/modify-compressed-data/) over compressed hypertables.
+
+Best practice is to upgrade at the next available opportunity.
+
+Highlighted features in TimescaleDB v2.17 are:
+
+* Significant performance improvements for continuous aggregate policies:
+
+* Continuous aggregate refresh now uses `merge` instead of deleting old materialized data and re-inserting.
+
+* Continuous aggregate policies are now more lightweight, use less system resources, and complete faster. This update:
+
+* Decreases dramatically the amount of data that must be written on the continuous aggregate in the presence of a small number of changes
+ * Reduces the i/o cost of refreshing a continuous aggregate
+ * Generates fewer Write-Ahead Logs (`WAL`)
+
+* Increased performance for real-time analytical queries over compressed hypertables:
+
+* We are excited to introduce additional Single Instruction, Multiple Data (SIMD) vectorization optimization to TimescaleDB. This release supports vectorized execution for queries that _group by_ using the `segment_by` column(s), and _aggregate_ using the `sum`, `count`, `avg`, `min`, and `max` basic aggregate functions.
+
+* Stay tuned for more to come in follow-up releases! Support for grouping on additional columns, filtered aggregation, vectorized expressions, and `time_bucket` is coming soon.
+
+* Improved performance of deletes on compressed hypertables when a large amount of data is affected.
+
+This improvement speeds up operations that delete whole segments by skipping the decompression step. It is enabled for all deletes that filter by the `segment_by` column(s).
+
+Timescale Cloud's [Enterprise plan](https://docs.timescale.com/about/latest/pricing-and-account-management/#features-included-in-each-pricing-plan) is now HIPAA (Health Insurance Portability and Accountability Act) compliant. This allows organizations to securely manage and analyze sensitive healthcare data, ensuring they meet regulatory requirements while building compliant applications.
+
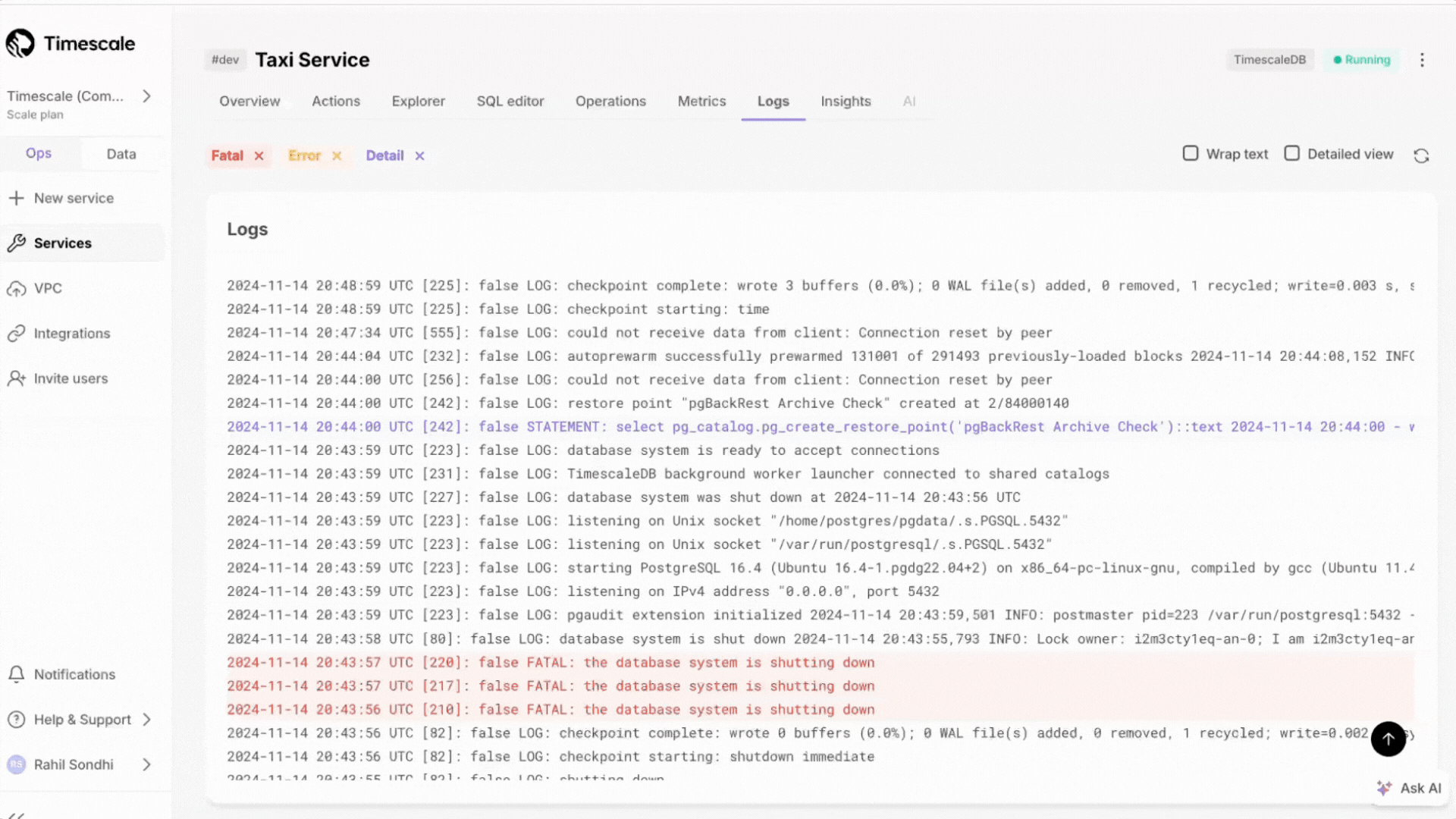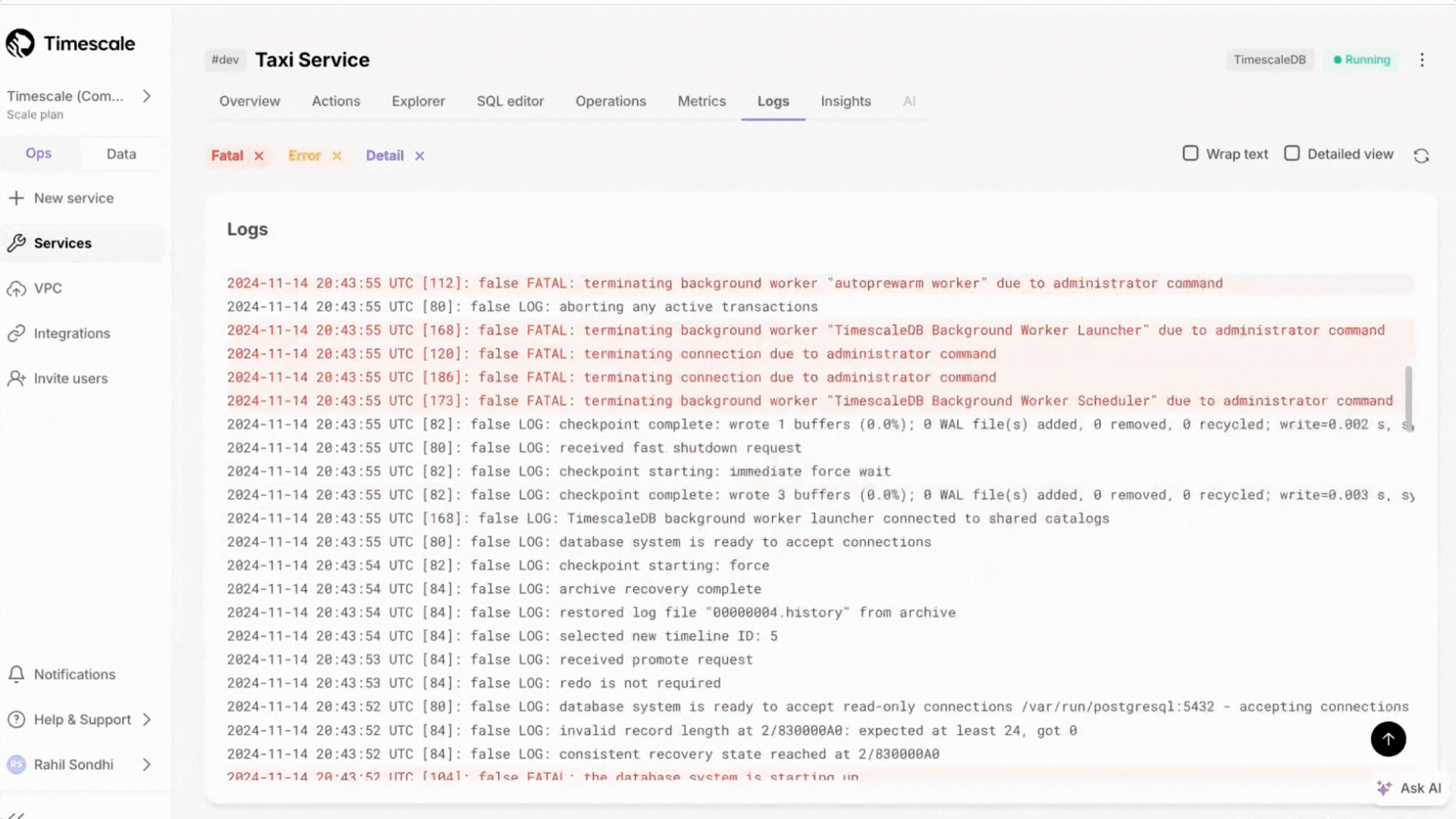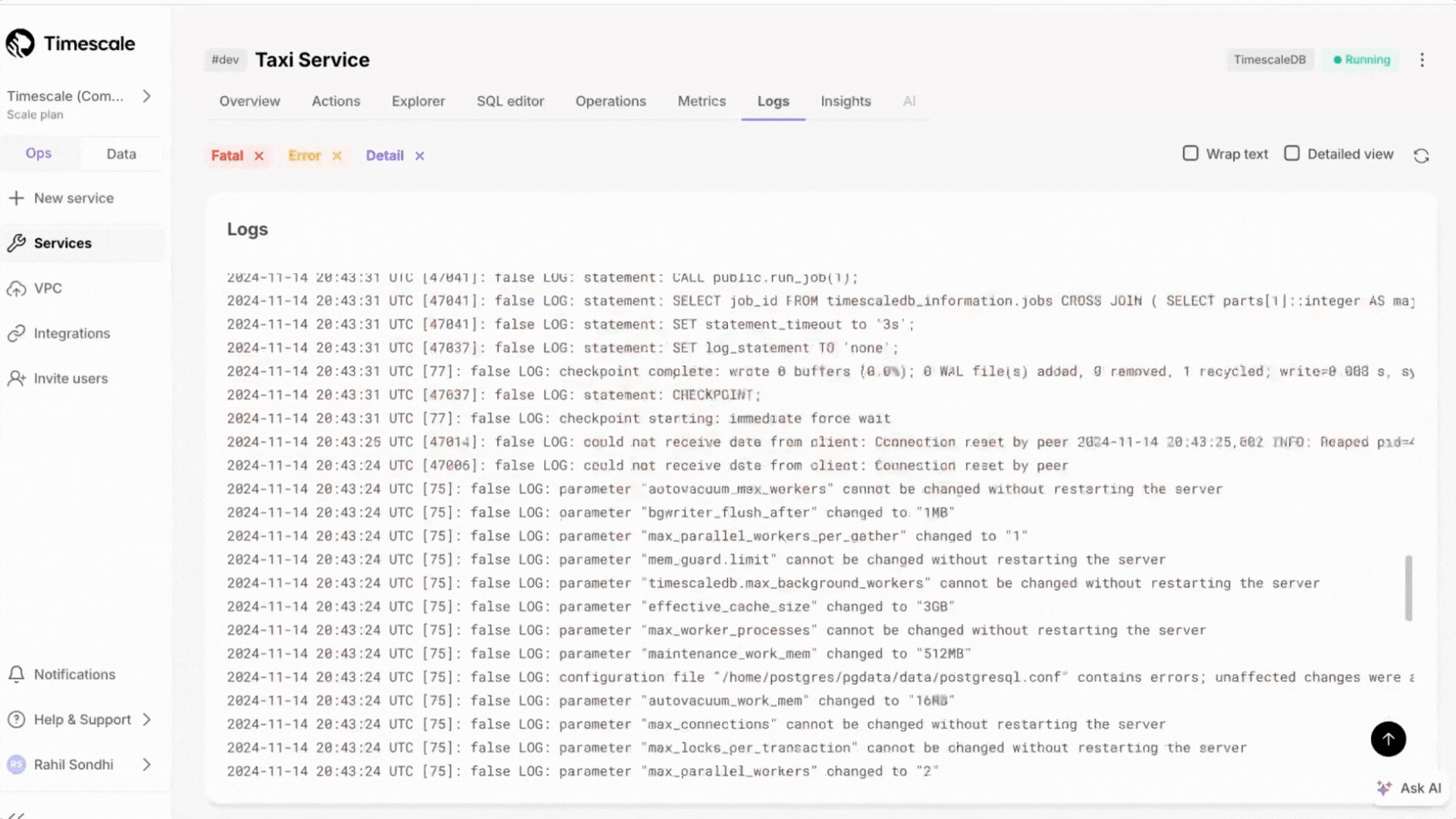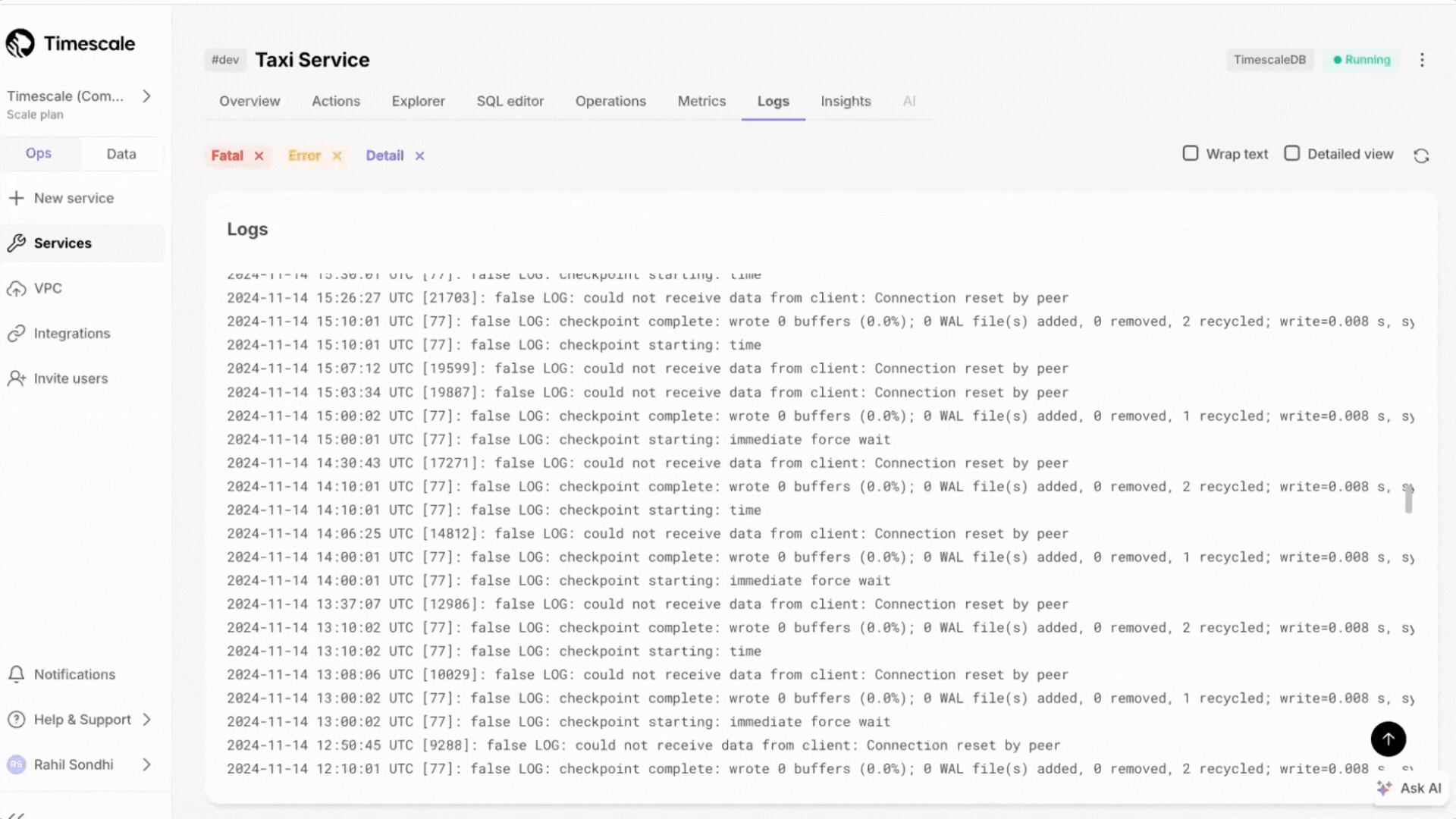
+### Expanded logging within Timescale Console
+
+Customers can now access more than just the most recent 500 logs within the Timescale Console. We've updated the user experience, including scrollbar with infinite scrolling capabilities.
+
+
+
+## ✨ Connect to Timescale from .NET Stack and check status of recent jobs
+
+
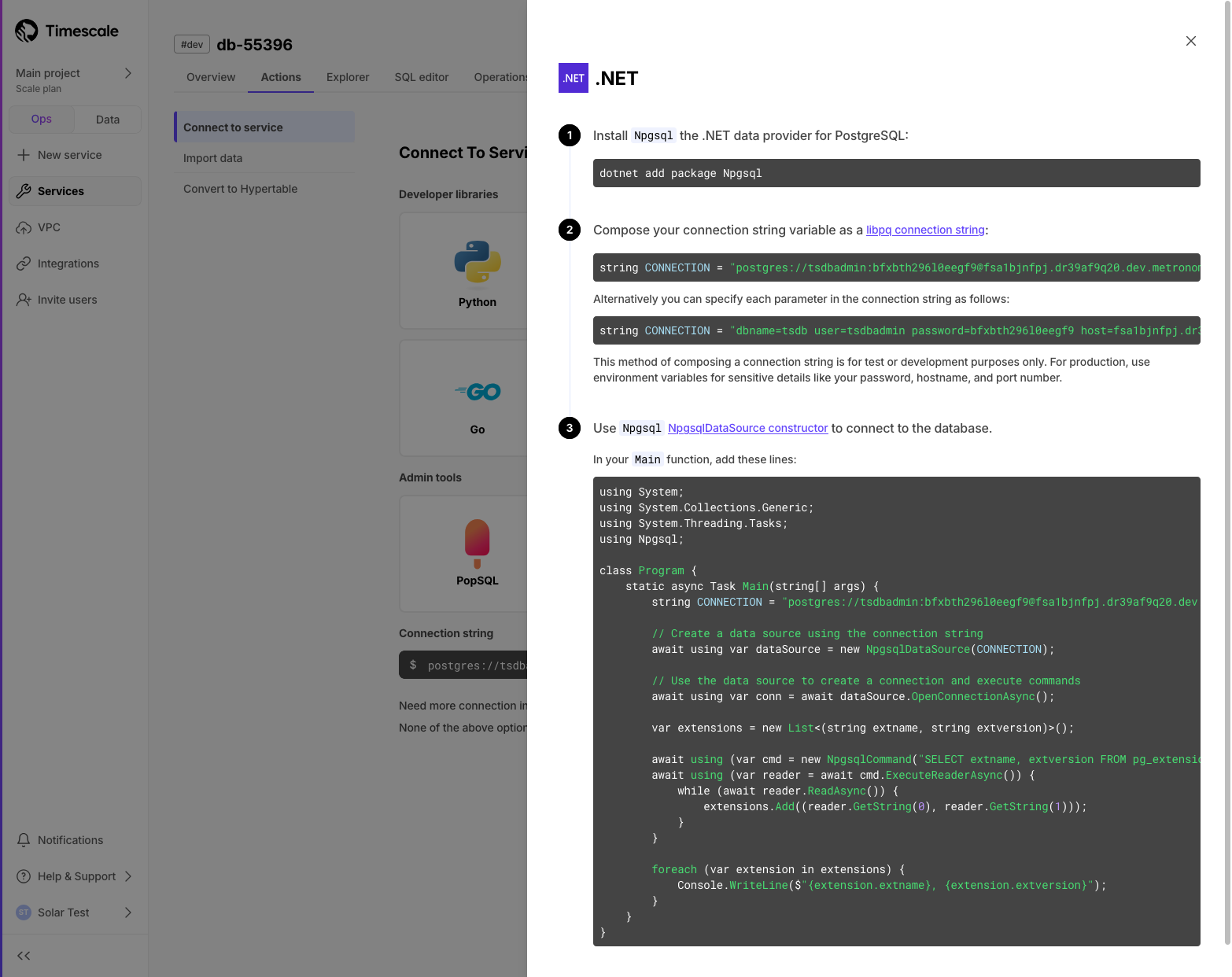
+### Connect to Timescale with your .NET stack
+We've added instructions for connecting to Timescale using your .NET workflow. In Console after service creation, or in the **Actions** tab, you can now select .NET from the developer library list. The guide demonstrates how to use Npgsql to integrate Timescale with your existing software stack.
+
+
+
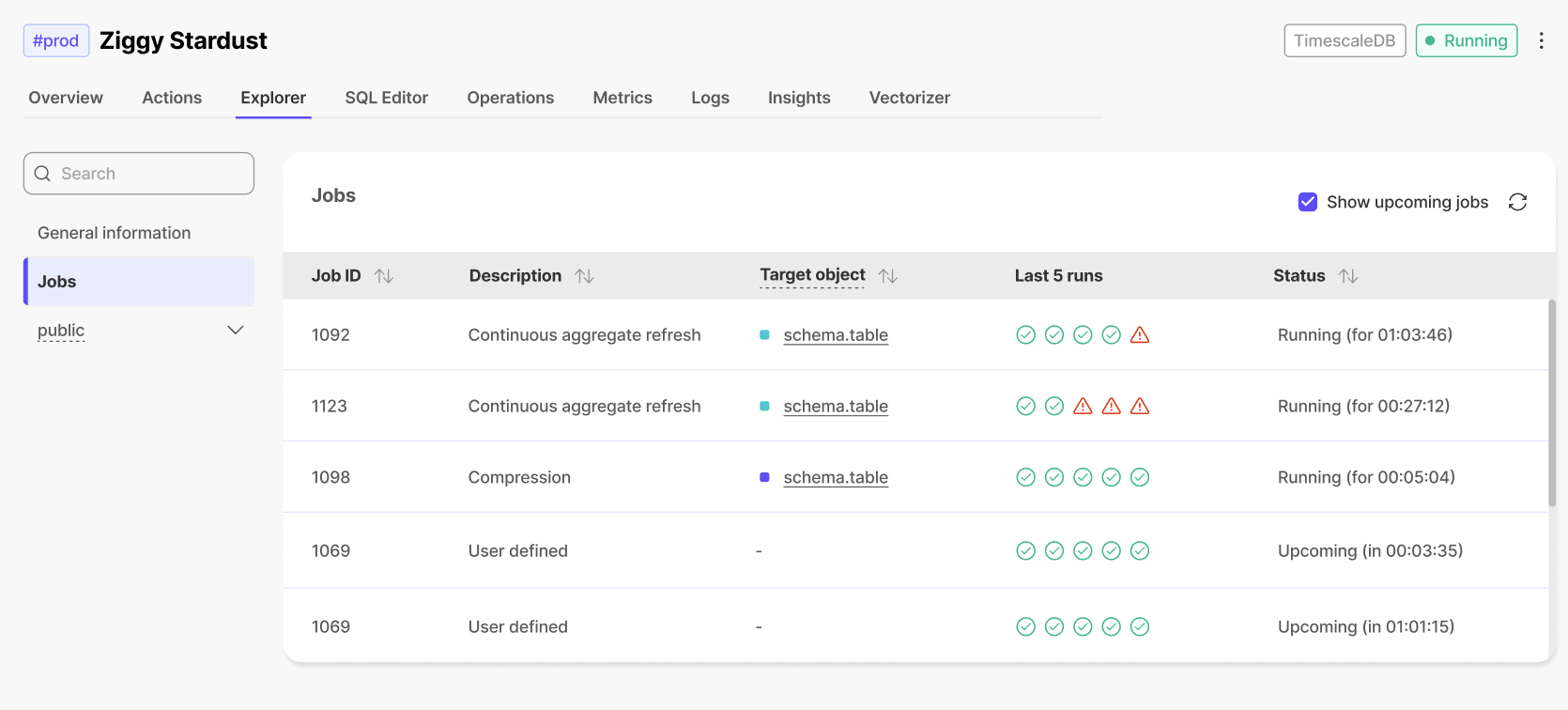
+### ✅ Last 5 jobs status
+In the **Jobs** section of the **Explorer**, users can now see the status (completed/failed) of the last 5 runs of each job.
+
+
+
+## 🎃 New AI, data integration, and performance enhancements
+
+
+### Pgai Vectorizer: vector embeddings as database indexes (early access)
+This early access feature enables you to automatically create, update, and maintain embeddings as your data changes. Just like an index, Timescale handles all the complexity: syncing, versioning, and cleanup happen automatically.
+This means no manual tracking, zero maintenance burden, and the freedom to rapidly experiment with different embedding models and chunking strategies without building new pipelines.
+Navigate to the AI tab in your service overview and follow the instructions to add your OpenAI API key and set up your first vectorizer or read our [guide to automate embedding generation with pgai Vectorizer](https://github.com/timescale/pgai/blob/main/docs/vectorizer/overview.md) for more details.
+
+
+
+### Postgres-to-Postgres foreign data wrappers:
+Fetch and query data from multiple Postgres databases, including time-series data in hypertables, directly within Timescale Cloud using [foreign data wrappers (FDW)](https://docs.timescale.com/use-timescale/latest/schema-management/foreign-data-wrappers/). No more complicated ETL processes or external tools—just seamless integration right within your SQL editor. This feature is ideal for developers who manage multiple Postgres and time-series instances and need quick, easy access to data across databases.
+
+### Faster queries over tiered data
+This release adds support for runtime chunk exclusion for queries that need to access [tiered storage](https://docs.timescale.com/use-timescale/latest/data-tiering/). Chunk exclusion now works with queries that use stable expressions in the `WHERE` clause. The most common form of this type of query is:
+
+For more info on queries with immutable/stable/volatile filters, check our blog post on [Implementing constraint exclusion for faster query performance](https://www.timescale.com/blog/implementing-constraint-exclusion-for-faster-query-performance/).
+
+If you no longer want to use tiered storage for a particular hypertable, you can now disable tiering and drop the associated tiering metadata on the hypertable with a call to [disable_tiering function](https://docs.timescale.com/use-timescale/latest/data-tiering/enabling-data-tiering/#disable-tiering).
+
+### Chunk interval recommendations
+Timescale Console now shows recommendations for services with too many small chunks in their hypertables.
+Recommendations for new intervals that improve service performance are displayed for each underperforming service and hypertable. Users can then change their chunk interval and boost performance within Timescale Console.
+
+
+
+## 💡 Help with hypertables and faster notebooks
+
+
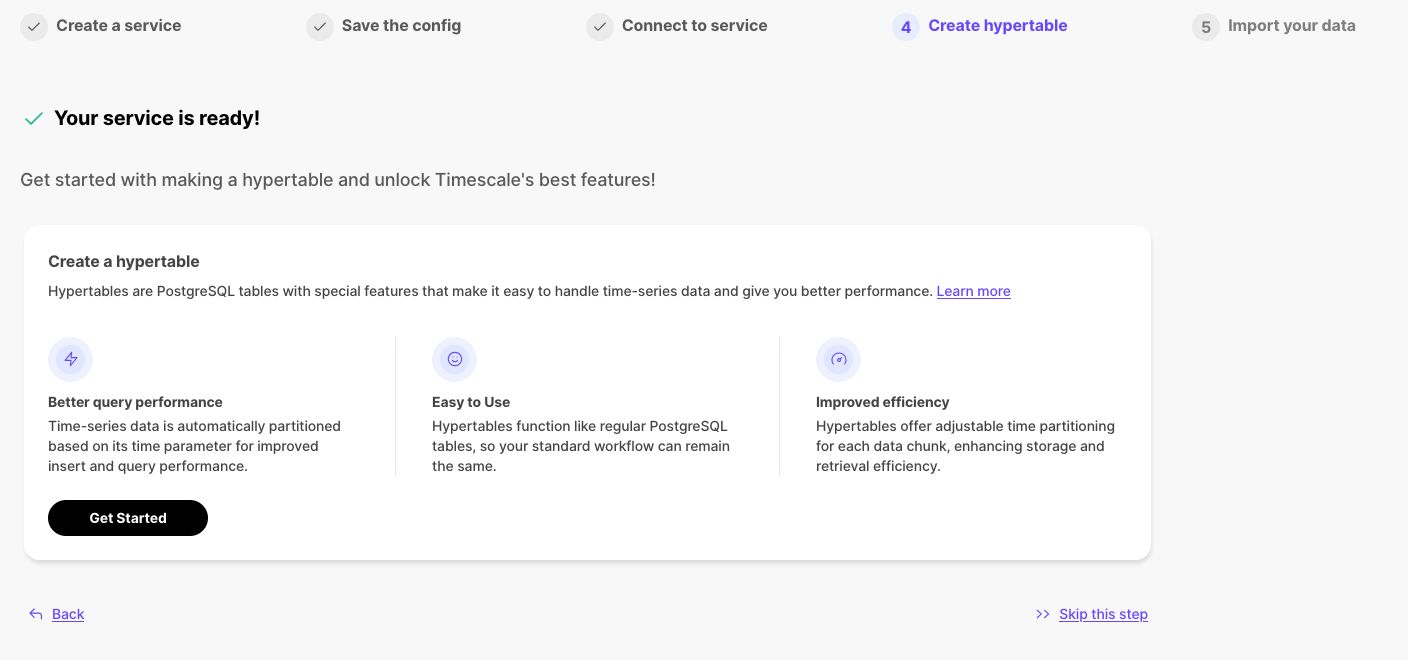
+### 🧙Hypertable creation wizard
+After creating a service, users can now create a hypertable directly in Timescale Console by first creating a table, then converting it into a hypertable. This is possible using the in-console SQL editor. All standard hypertable configuration options are supported, along with any customization of the underlying table schema.
+
+
+### 🍭 PopSQL Notebooks
+The newest version of Data Mode Notebooks is now waaaay faster. Why? We've incorporated the newly developed v3 of our query engine that currently powers Timescale Console's SQL Editor. Check out the difference in query response times.
+
+## ✨ Production-Ready Low-Downtime Migrations, MySQL Import, Actions Tab, and Current Lock Contention Visibility in SQL Editor
+
+
+### 🏗️ Live Migrations v1.0 Release
+
+Last year, we began developing a solution for low-downtime migration from Postgres and TimescaleDB. Since then, this solution has evolved significantly, featuring enhanced functionality, improved reliability, and performance optimizations. We're now proud to announce that **live migration is production-ready** with the release of version 1.0.
+
+Many of our customers have successfully migrated databases to Timescale using [live migration](https://docs.timescale.com/migrate/latest/live-migration/), with some databases as large as a few terabytes in size.
+
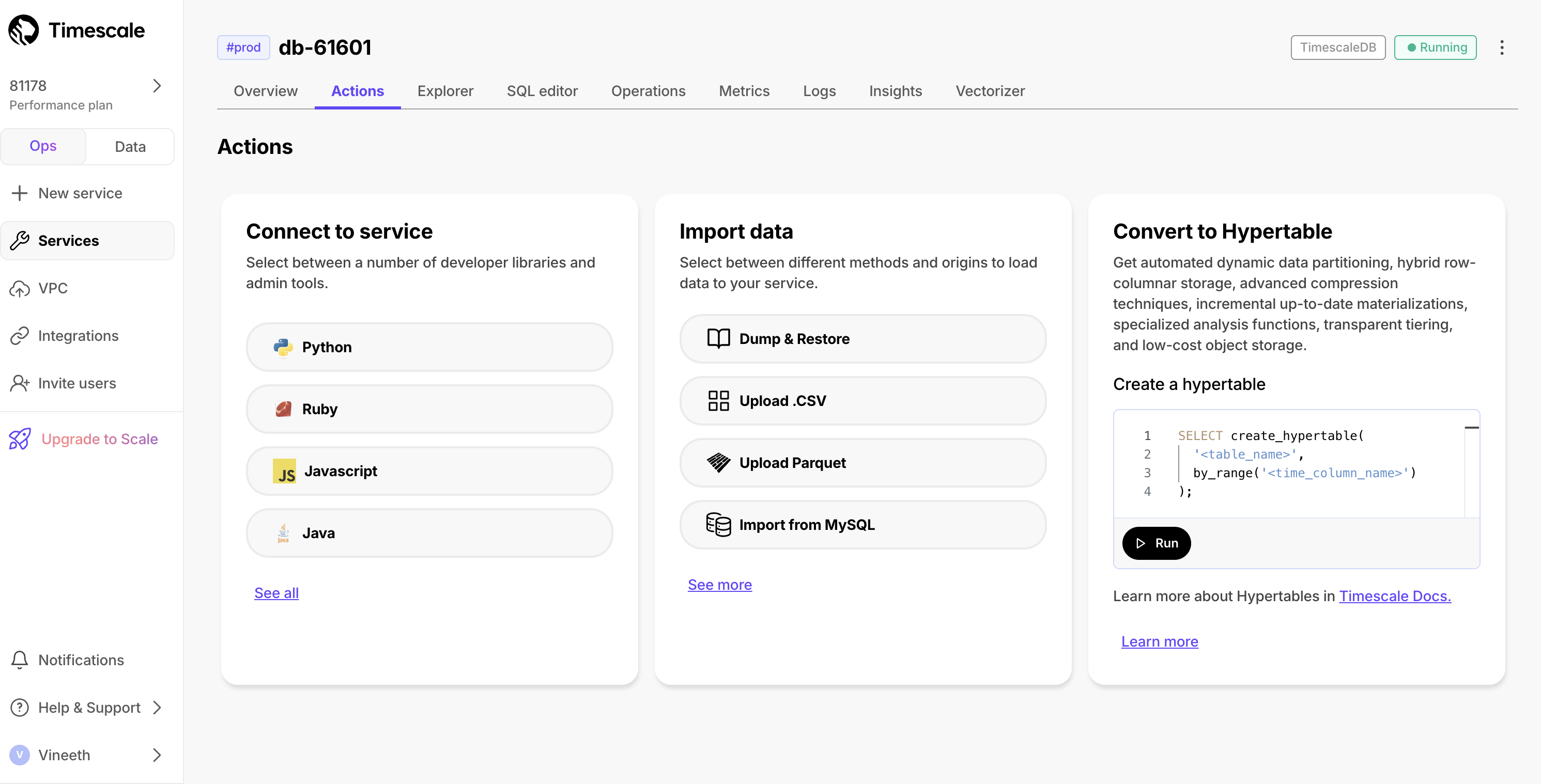
+As part of the service creation flow, we offer the following:
+
+- Connect to services from different sources
+- Import and migrate data from various sources
+- Create hypertables
+
+Previously, these actions were only visible during the service creation process and couldn't be accessed later. Now, these actions are **persisted within the service**, allowing users to leverage them on-demand whenever they're ready to perform these tasks.
+
+
+
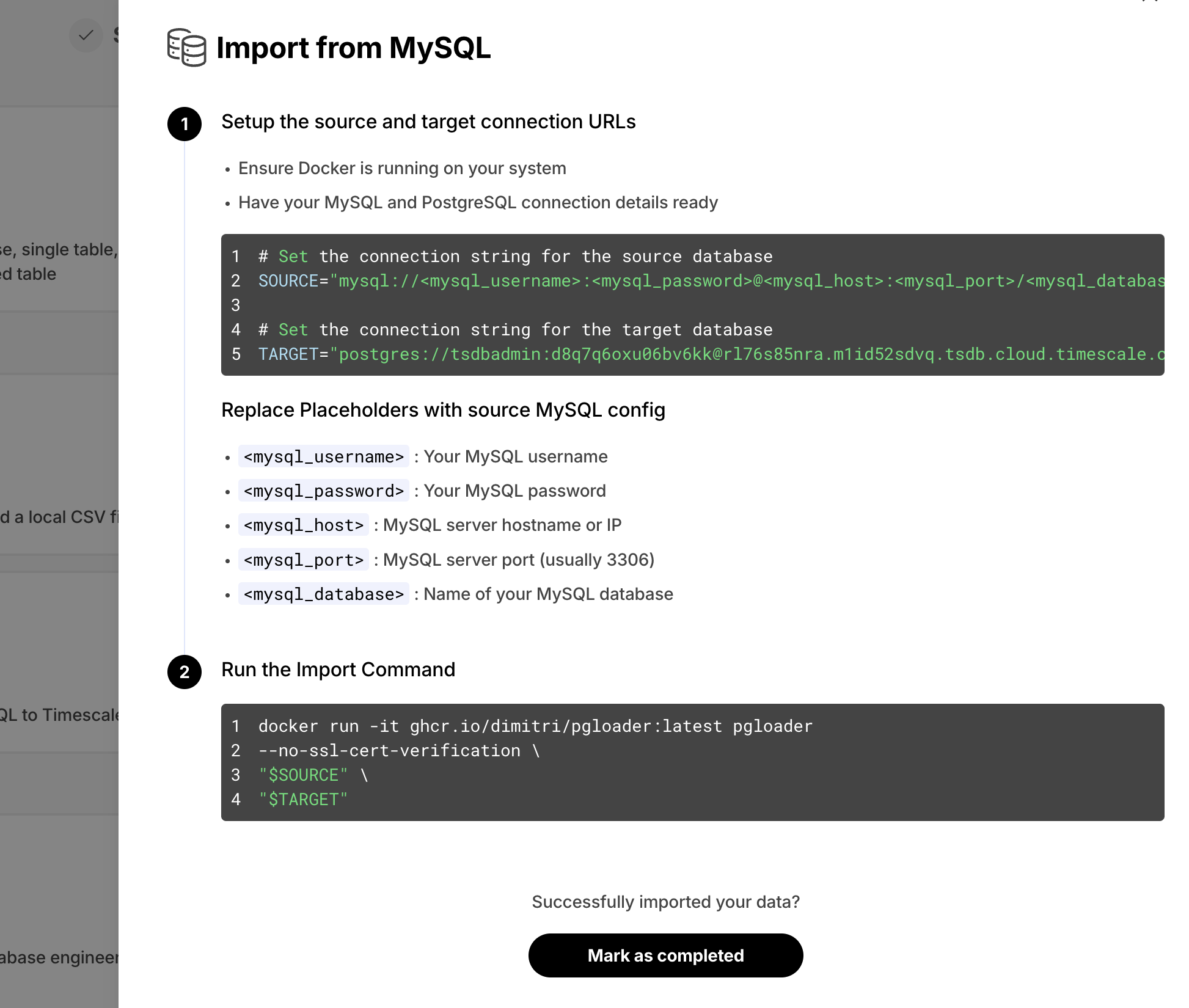
+### 🧭 Import Data from MySQL
+
+We've noticed users struggling to convert their MySQL schema and data into their Timescale Cloud services. This was due to the semantic differences between MySQL and Postgres. To simplify this process, we now offer **easy-to-follow instructions** to import data from MySQL to Timescale Cloud. This feature is available as part of the data import wizard, under the **Import from MySQL** option.
+
+
+
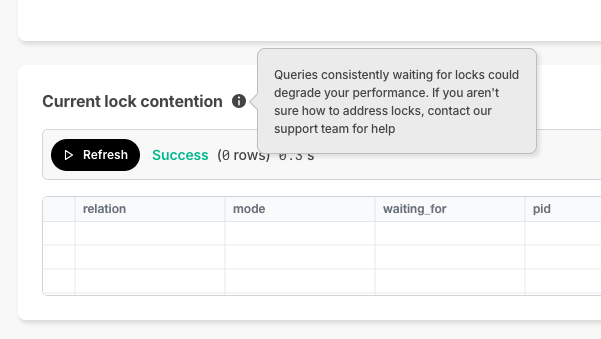
+### 🔐 Current Lock Contention
+
+In Timescale Console, we offer the SQL editor so you can directly querying your service. As a new improvement, **if a query is waiting on locks and can't complete execution**, Timescale Console now displays the current lock contention in the results section .
+
+
+
+## CIDR & VPC Updates
+
+
+
+Timescale now supports multiple CIDRs on the customer VPC. Customers who want to take advantage of multiple CIDRs will need to recreate their peering.
+
+## 🤝 New modes in Timescale Console: Ops and Data mode, and Console based Parquet File Import
+
+
+
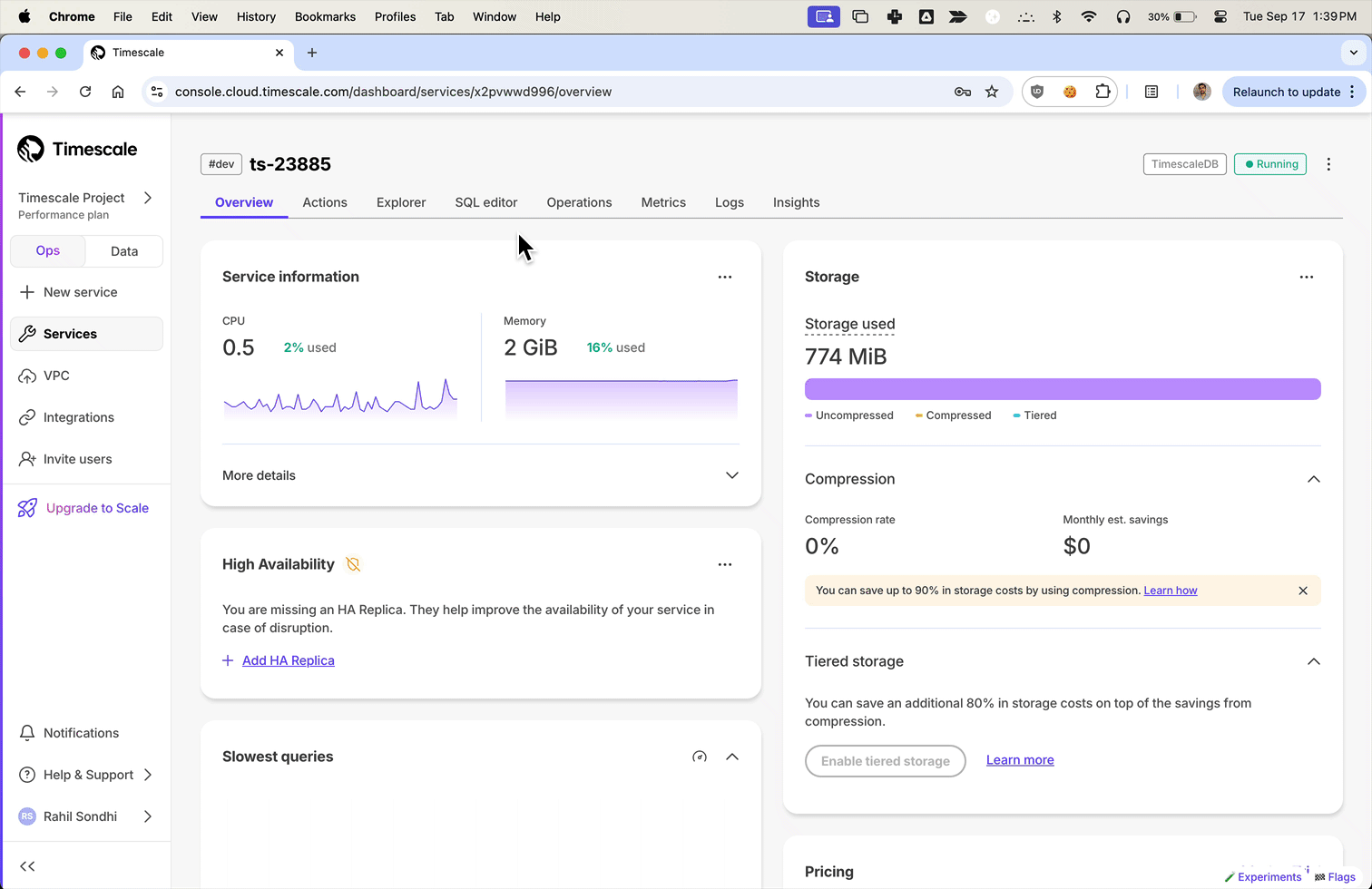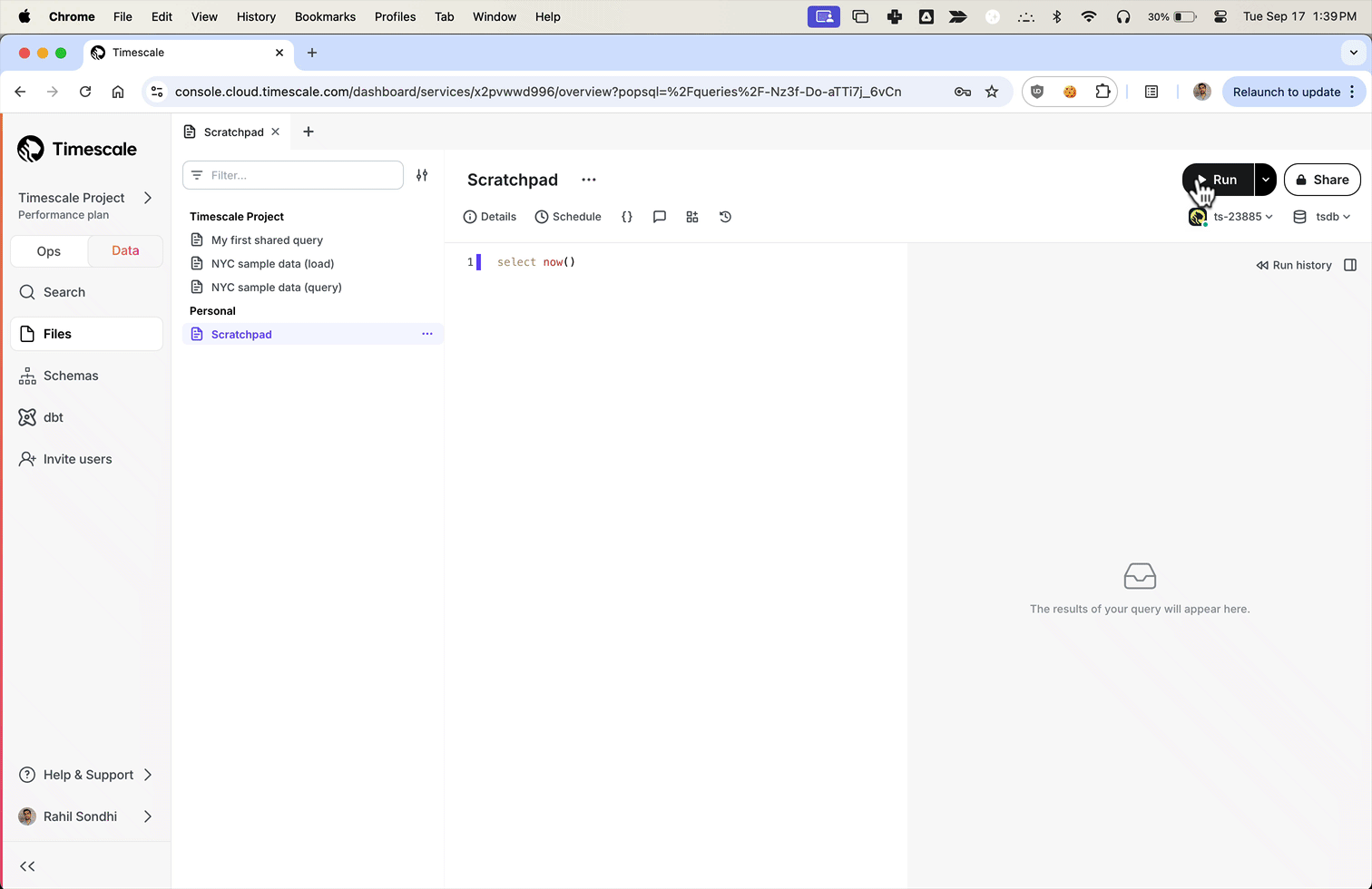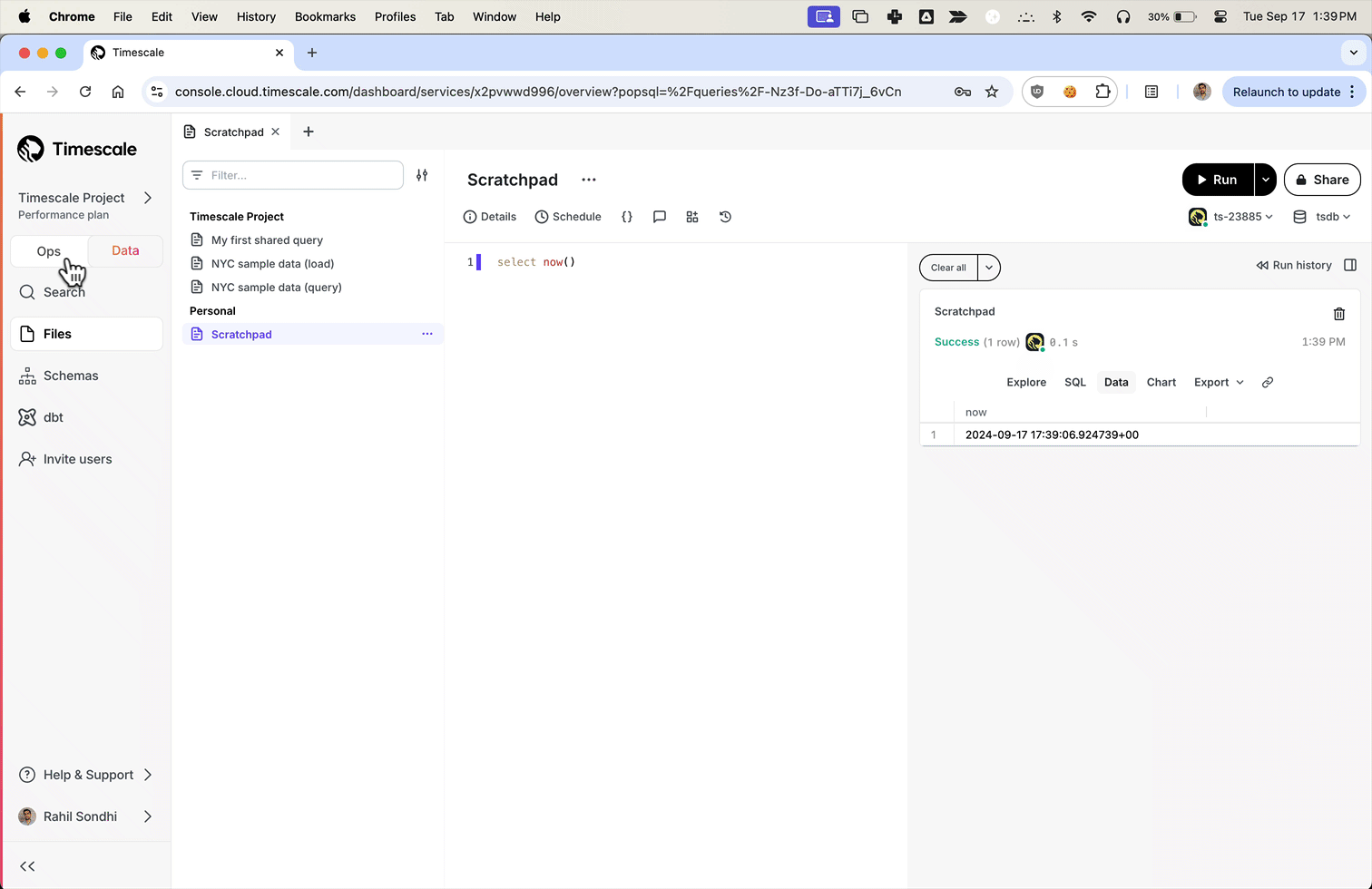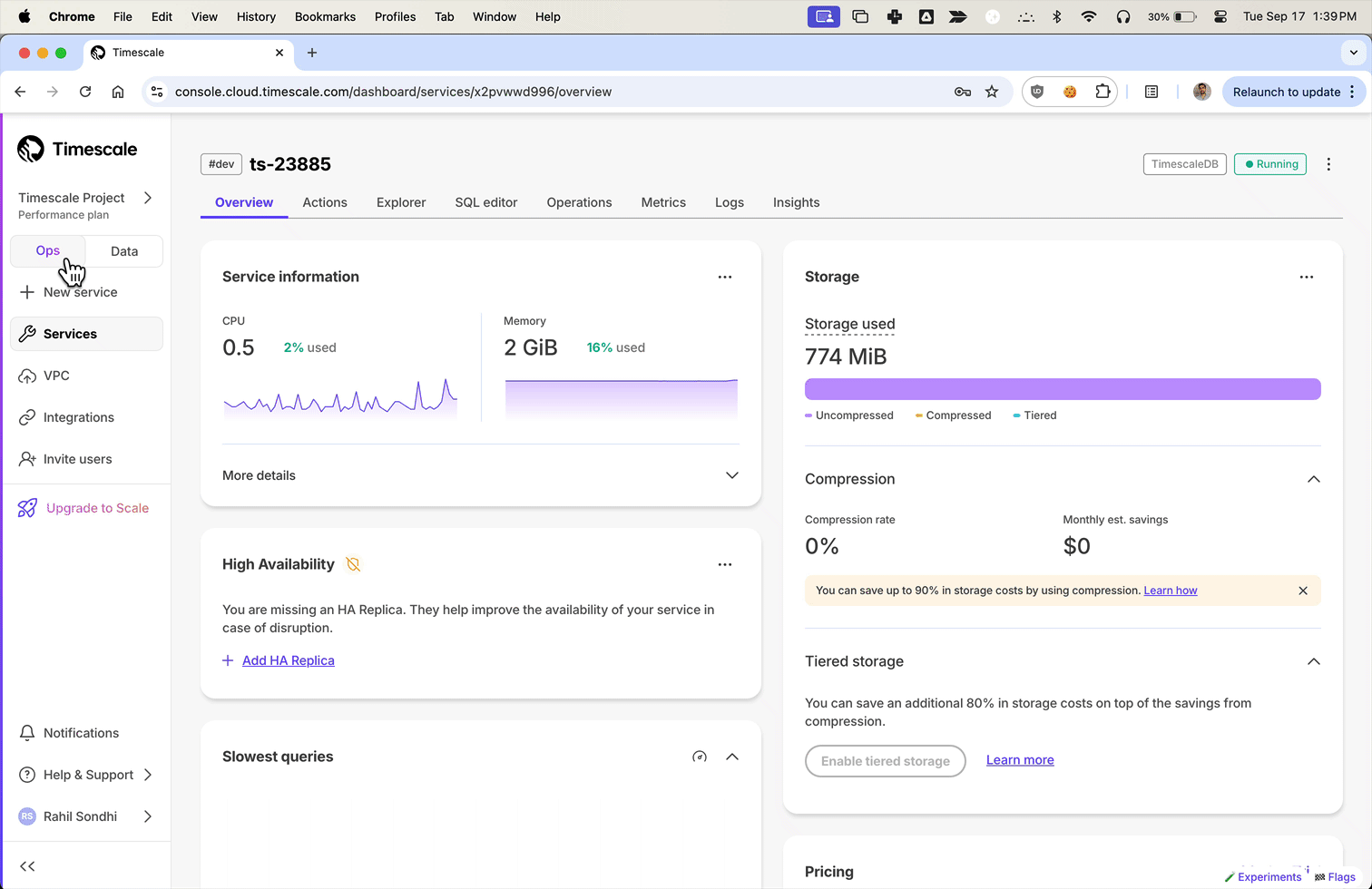
+We've been listening to your feedback and noticed that Timescale Console users have diverse needs. Some of you are focused on operational tasks like adding replicas or changing parameters, while others are diving deep into data analysis to gather insights.
+
+**To better serve you, we've introduced new modes to the Timescale Console UI—tailoring the experience based on what you're trying to accomplish.**
+
+Ops mode is where you can manage your services, add replicas, configure compression, change parameters, and so on.
+
+Data mode is the full PopSQL experience: write queries with autocomplete, visualize data with charts and dashboards, schedule queries and dashboards to create alerts or recurring reports, share queries and dashboards, and more.
+
+Try it today and let us know what you think!
+
+
+
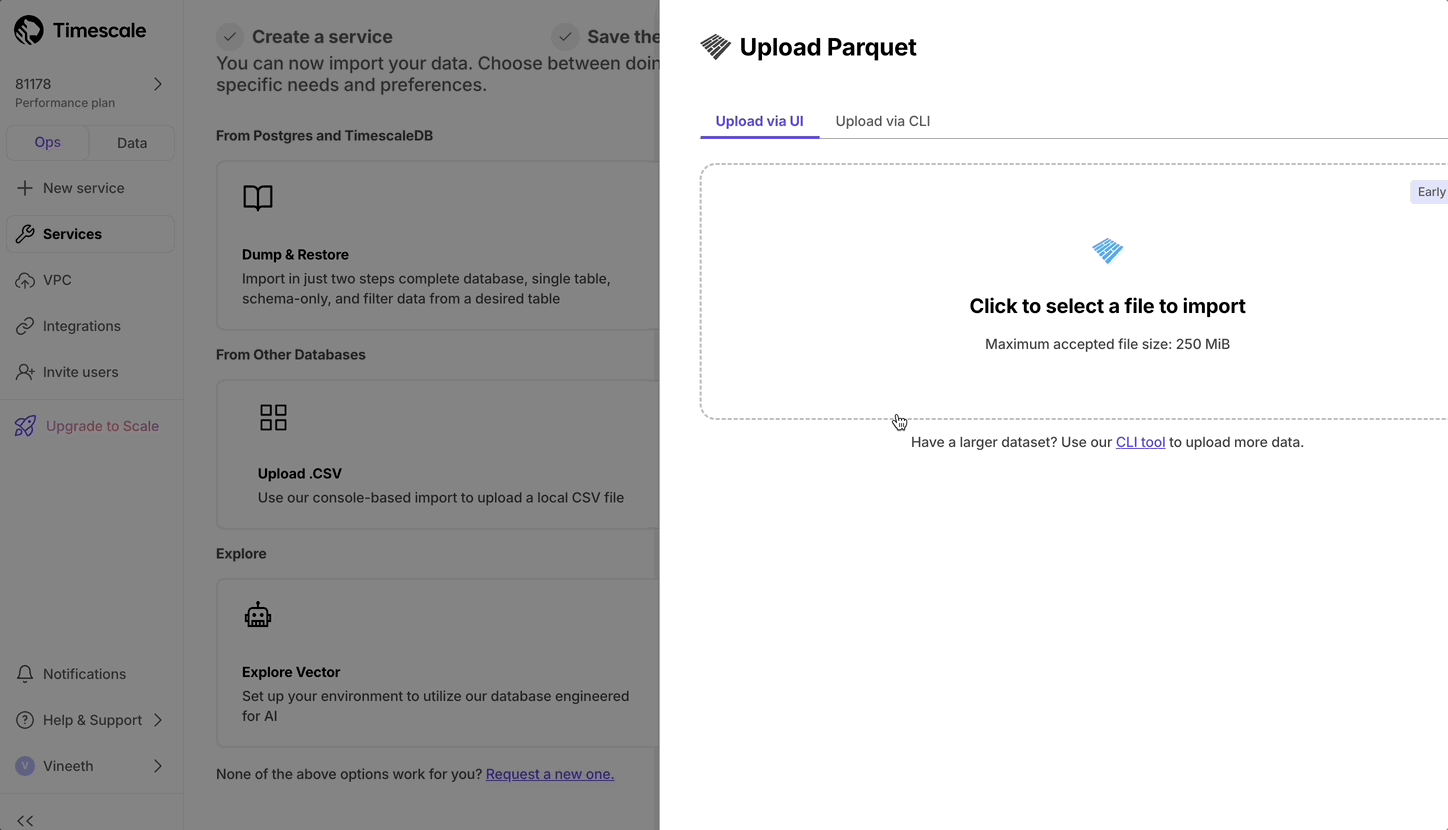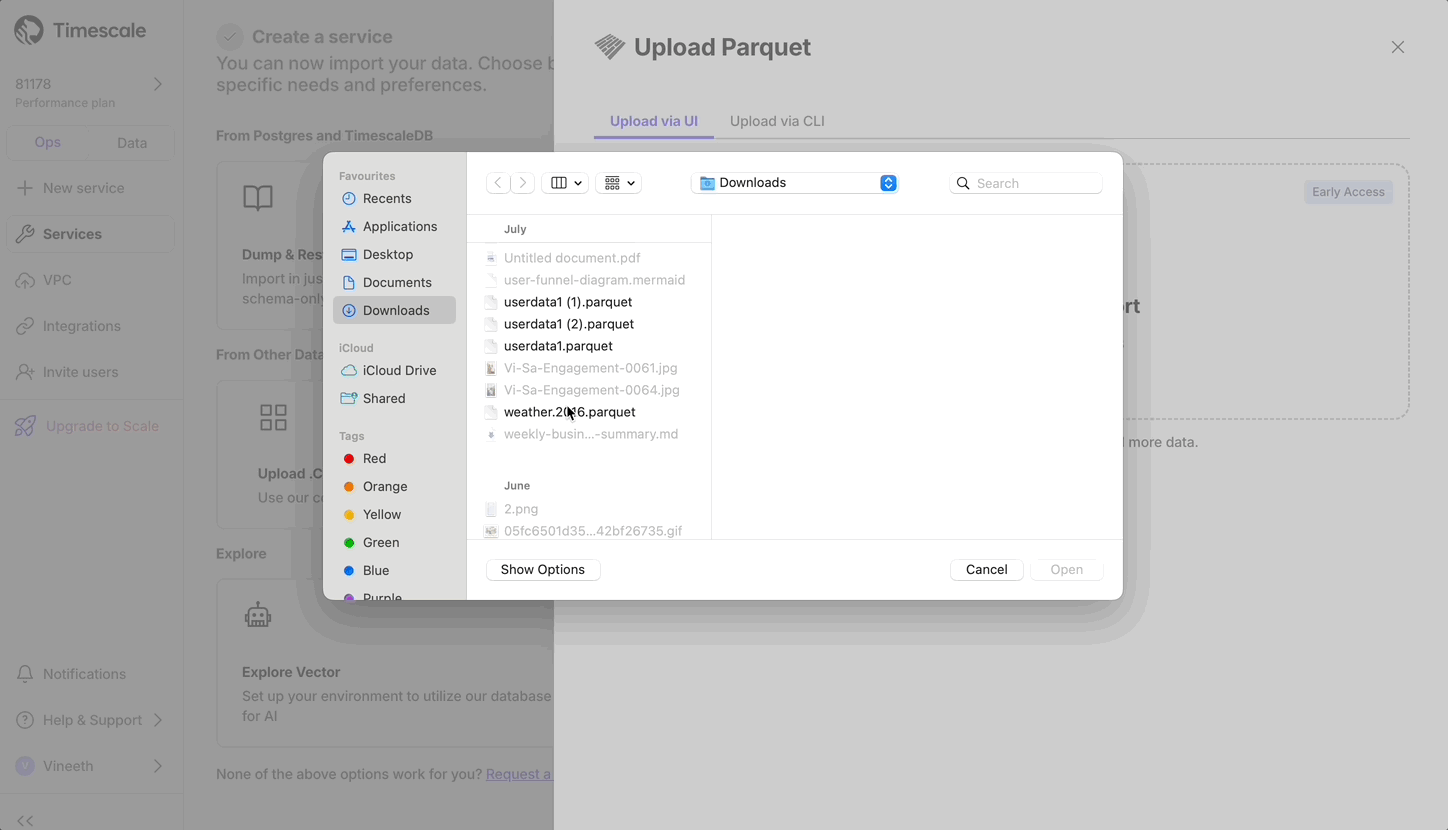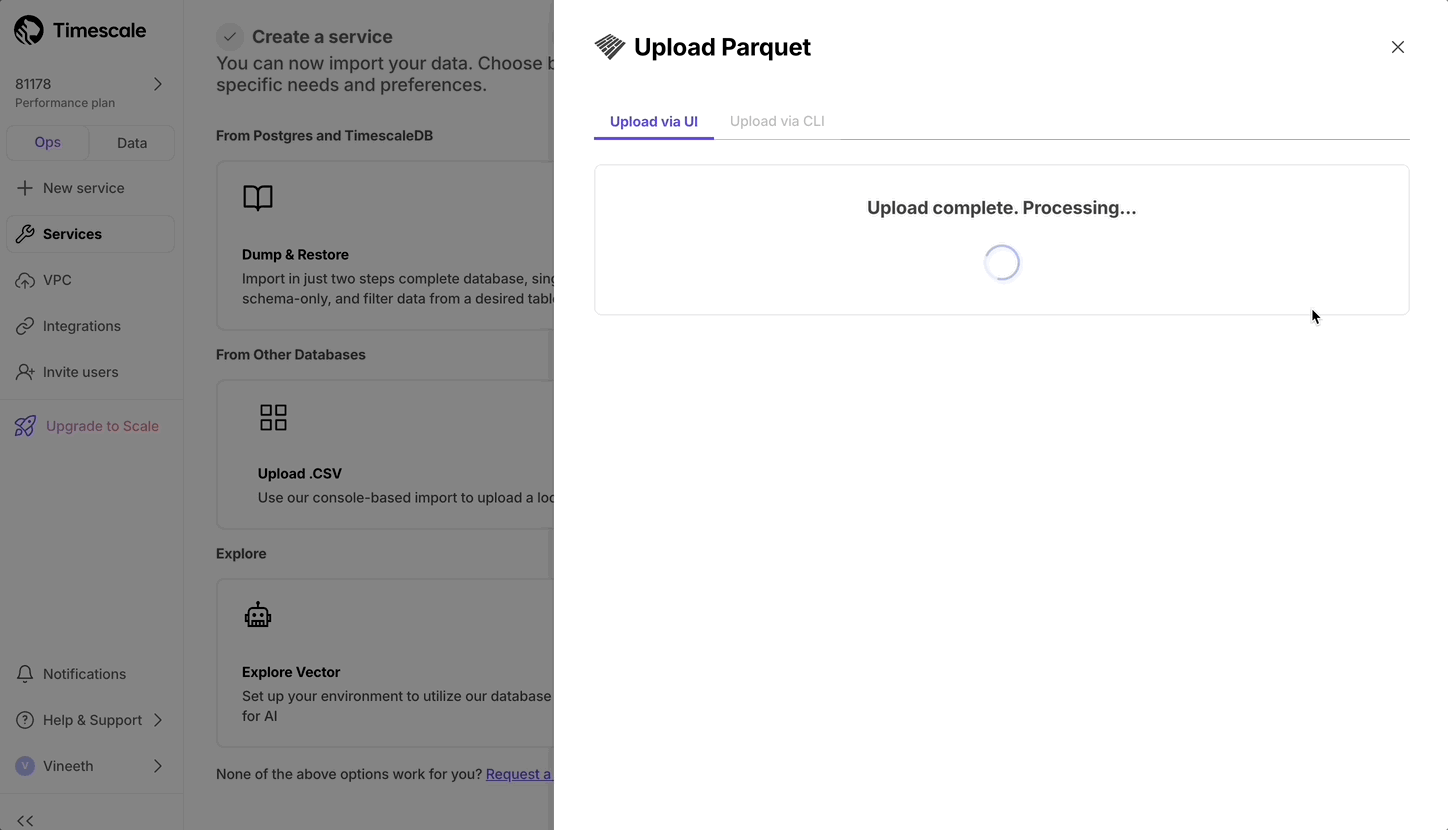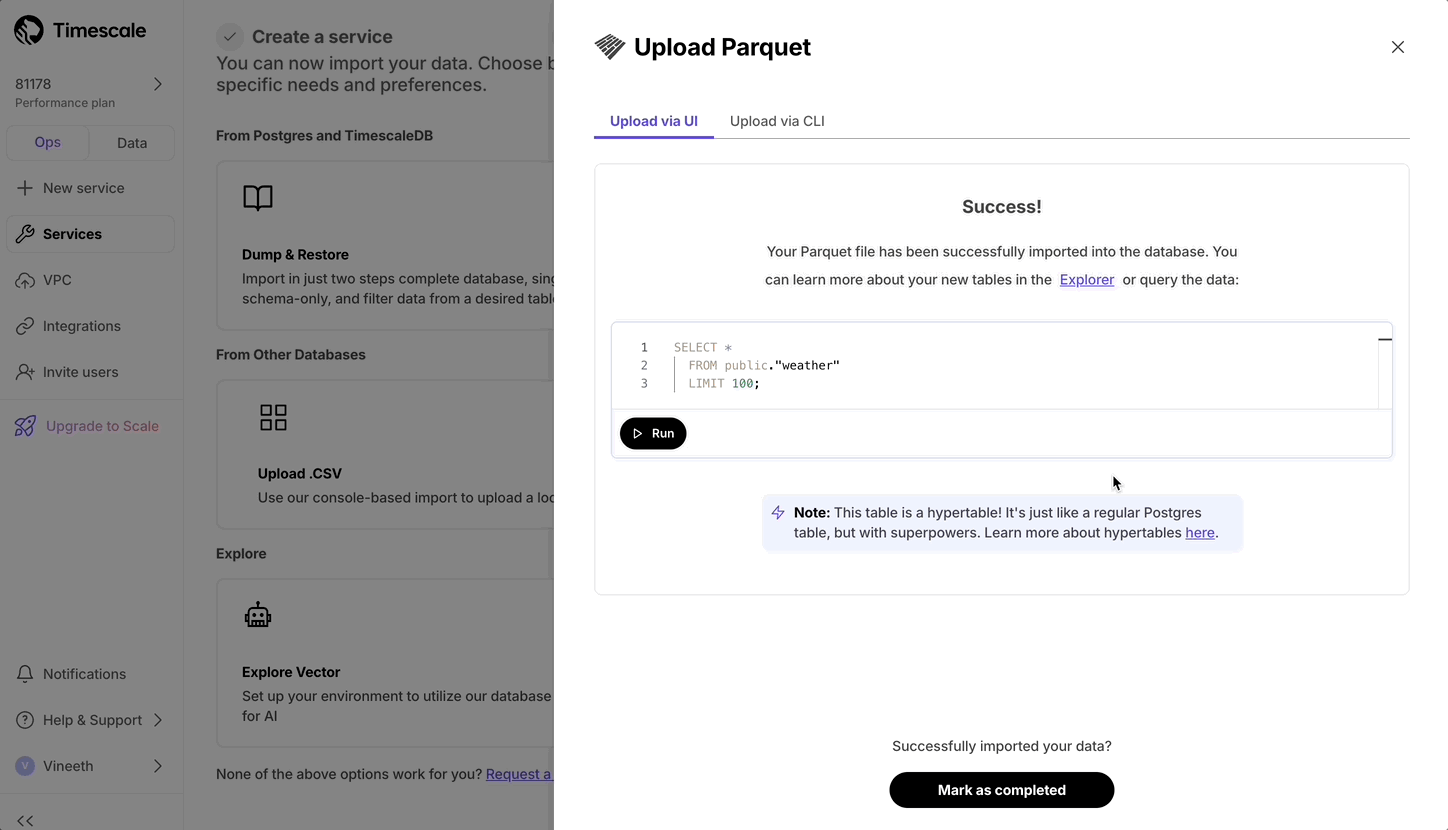
+## Console based Parquet File Import
+
+Now users can upload from Parquet to Timescale Cloud by uploading the file from their local file system. For files larger than 250 MB, or if you want to do it yourself, follow the three-step process to upload Parquet files to Timescale.
+
+
+
+### SQL editor improvements
+
+* In the Ops mode SQL editor, you can now highlight a statement to run a specific statement.
+
+## High availability, usability, and migrations improvements
+
+
+### Multiple HA replicas
+
+Scale and Enterprise customers can now configure two new multiple high availability (HA) replica options directly through Timescale Console:
+
+* Two HA replicas (both asynchronous) - our highest availability configuration.
+* Two HA replicas (one asynchronous, one synchronous) - our highest data integrity configuration.
+
+Previously, Timescale offered only a single synchronous replica for customers seeking high availability. The single HA option is still available.
+
+
+
+
+
+For more details on multiple HA replicas, see [Manage high availability](https://docs.timescale.com/use-timescale/latest/ha-replicas/high-availability/).
+
+### Other improvements
+
+* In the Console SQL editor, we now indicate if your database session is healthy or has been disconnected. If it's been disconnected, the session will reconnect on your next query execution.
+
+
+
+* Released live-migration v0.0.26 and then v0.0.27 which includes multiple performance improvements and bugfixes as well as better support for Postgres 12.
+
+## One-click SQL statement execution from Timescale Console, and session support in the SQL editor
+
+
+### One-click SQL statement execution from Timescale Console
+
+Now you can simply click to run SQL statements in various places in the Console. This requires that the [SQL Editor][sql-editor] is enabled for the service.
+
+* Enable Continuous Aggregates from the CAGGs wizard by clicking **Run** below the SQL statement.
+
+
+* Enable database extensions by clicking **Run** below the SQL statement.
+
+
+* Query data instantly with a single click in the Console after successfully uploading a CSV file.
+
+
+### Session support in the SQL editor
+
+Last week we announced the new in-console SQL editor. However, there was a limitation where a new database session was created for each query execution.
+
+Today we removed that limitation and added support for keeping one database session for each user logged in, which means you can do things like start transactions:
+
+Or work with temporary tables:
+
+Or use the `set` command:
+
+## 😎 Query your database directly from the Console and enhanced data import and migration options
+
+
+### SQL Editor in Timescale Console
+We've added a new tab to the service screen that allows users to query their database directly, without having to leave the console interface.
+
+* For existing services on Timescale, this is an opt-in feature. For all newly created services, the SQL Editor will be enabled by default.
+* Users can disable the SQL Editor at any time by toggling the option under the Operations tab.
+* The editor supports all DML and DDL operations (any single-statement SQL query), but doesn't support multiple SQL statements in a single query.
+
+
+
+### Enhanced Data Import Options for Quick Evaluation
+After service creation, we now offer a dedicated section for data import, including options to import from Postgres as a source or from CSV files.
+
+The enhanced Postgres import instructions now offer several options: single table import, schema-only import, partial data import (allowing selection of a specific time range), and complete database import. Users can execute any of these data imports with just one or two simple commands provided in the data import section.
+
+
+
+### Improvements to Live migration
+We've released v0.0.25 of Live migration that includes the following improvements:
+* Support migrating tsdb on non public schema to public schema
+* Pre-migration compatibility checks
+* Docker compose build fixes
+
+## 🛠️ Improved tooling in Timescale Cloud and new AI and Vector extension releases
+
+
+### CSV import
+We have added a CSV import tool to the Timescale Console. For all TimescaleDB services, after service creation you can:
+* Choose a local file
+* Select the name of the data collection to be uploaded (default is file name)
+* Choose data types for each column
+* Upload the file as a new hypertable within your service
+Look for the `Import data from .csv` tile in the `Import your data` step of service creation.
+
+
+
+### Replica lag
+Customers now have more visibility into the state of replicas running on Timescale Cloud. We’ve released a new parameter called Replica Lag within the Service Overview for both Read and High Availability Replicas. Replica lag is measured in bytes against the current state of the primary database. For questions or concerns about the relative lag state of your replica, reach out to Customer Support.
+
+
+
+### Adjust chunk interval
+Customers can now adjust their chunk interval for their hypertables and continuous aggregates through the Timescale UI. In the Explorer, select the corresponding hypertable you would like to adjust the chunk interval for. Under *Chunk information*, you can change the chunk interval. Note that this only changes the chunk interval going forward, and does not retroactively change existing chunks.
+
+
+
+### CloudWatch permissions via role assumption
+We've released permission granting via role assumption to CloudWatch. Role assumption is both more secure and more convenient for customers who no longer need to rotate credentials and update their exporter config.
+
+For more details take a look at [our documentation][integrations].
+
+

+
+### Two-factor authentication (2FA) indicator
+We’ve added a 2FA status column to the Members page, allowing customers to easily see whether each project member has 2FA enabled or disabled.
+
+
+
+### Anthropic and Cohere integrations in pgai
+The pgai extension v0.3.0 now supports embedding creation and LLM reasoning using models from Anthropic and Cohere. For details and examples, see [this post for pgai and Cohere](https://www.timescale.com/blog/build-search-and-rag-systems-on-postgresql-using-cohere-and-pgai/), and [this post for pgai and Anthropic](https://www.timescale.com/blog/use-anthropic-claude-sonnet-3-5-in-postgresql-with-pgai/).
+
+### pgvectorscale extension: ARM builds and improved recall for low dimensional vectors
+pgvectorscale extension [v0.3.0](https://github.com/timescale/pgvectorscale/releases/tag/0.3.0) adds support for ARM processors and improves recall when using StreamingDiskANN indexes with low dimensionality vectors. We recommend updating to this version if you are self-hosting.
+
+## 🏄 Optimizations for compressed data and extended join support in continuous aggregates
+
+
+TimescaleDB v2.16.0 contains significant performance improvements when working with compressed data, extended join
+support in continuous aggregates, and the ability to define foreign keys from regular tables towards hypertables.
+We recommend upgrading at the next available opportunity.
+
+Any new service created on Timescale Cloud starting today uses TimescaleDB v2.16.0.
+
+In TimescaleDB v2.16.0 we:
+
+* Introduced multiple performance focused optimizations for data manipulation operations (DML) over compressed chunks.
+
+Improved upsert performance by more than 100x in some cases and more than 500x in some update/delete scenarios.
+
+* Added the ability to define chunk skipping indexes on non-partitioning columns of compressed hypertables.
+
+TimescaleDB v2.16.0 extends chunk exclusion to use these skipping (sparse) indexes when queries filter on the relevant columns,
+ and prune chunks that do not include any relevant data for calculating the query response.
+
+* Offered new options for use cases that require foreign keys defined.
+
+You can now add foreign keys from regular tables towards hypertables. We have also removed
+ some really annoying locks in the reverse direction that blocked access to referenced tables
+ while compression was running.
+
+* Extended Continuous Aggregates to support more types of analytical queries.
+
+More types of joins are supported, additional equality operators on join clauses, and
+ support for joins between multiple regular tables.
+
+**Highlighted features in this release**
+
+* Improved query performance through chunk exclusion on compressed hypertables.
+
+You can now define chunk skipping indexes on compressed chunks for any column with one of the following
+ integer data types: `smallint`, `int`, `bigint`, `serial`, `bigserial`, `date`, `timestamp`, `timestamptz`.
+
+After calling `enable_chunk_skipping` on a column, TimescaleDB tracks the min and max values for
+ that column, using this information to exclude chunks for queries filtering on that
+ column, where no data would be found.
+
+* Improved upsert performance on compressed hypertables.
+
+By using index scans to verify constraints during inserts on compressed chunks, TimescaleDB speeds
+ up some ON CONFLICT clauses by more than 100x.
+
+* Improved performance of updates, deletes, and inserts on compressed hypertables.
+
+By filtering data while accessing the compressed data and before decompressing, TimescaleDB has
+ improved performance for updates and deletes on all types of compressed chunks, as well as inserts
+ into compressed chunks with unique constraints.
+
+By signaling constraint violations without decompressing, or decompressing only when matching
+ records are found in the case of updates, deletes and upserts, TimescaleDB v2.16.0 speeds
+ up those operations more than 1000x in some update/delete scenarios, and 10x for upserts.
+
+* You can add foreign keys from regular tables to hypertables, with support for all types of cascading options.
+ This is useful for hypertables that partition using sequential IDs, and need to reference these IDs from other tables.
+
+* Lower locking requirements during compression for hypertables with foreign keys
+
+Advanced foreign key handling removes the need for locking referenced tables when new chunks are compressed.
+ DML is no longer blocked on referenced tables while compression runs on a hypertable.
+
+* Improved support for queries on Continuous Aggregates
+
+`INNER/LEFT` and `LATERAL` joins are now supported. Plus, you can now join with multiple regular tables,
+ and have more than one equality operator on join clauses.
+
+**Postgres 13 support removal announcement**
+
+Following the deprecation announcement for Postgres 13 in TimescaleDB v2.13,
+Postgres 13 is no longer supported in TimescaleDB v2.16.
+
+The currently supported Postgres major versions are 14, 15, and 16.
+
+## 📦 Performance, packaging and stability improvements for Timescale Cloud
+
+
+### New plans
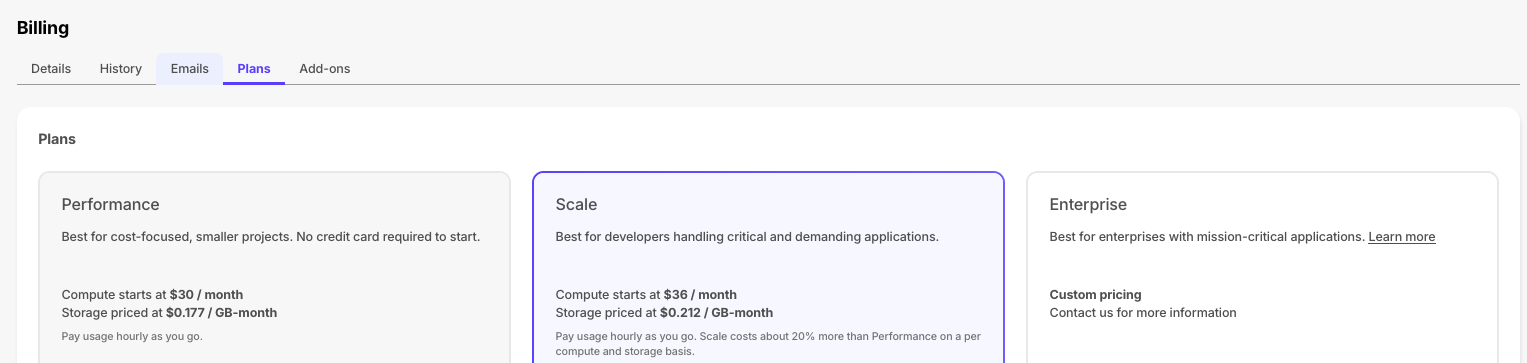
+To support evolving customer needs, Timescale Cloud now offers three plans to provide more value, flexibility, and efficiency.
+- **Performance:** for cost-focused, smaller projects. No credit card required to start.
+- **Scale:** for developers handling critical and demanding apps.
+- **Enterprise:** for enterprises with mission-critical apps.
+
+Each plan continues to bill based on hourly usage, primarily for compute you run and storage you consume. You can upgrade or downgrade between Performance and Scale plans via the Console UI at any time. More information about the specifics and differences between these pricing plans can be found [here in the docs](https://docs.timescale.com/about/latest/pricing-and-account-management/).
+
+
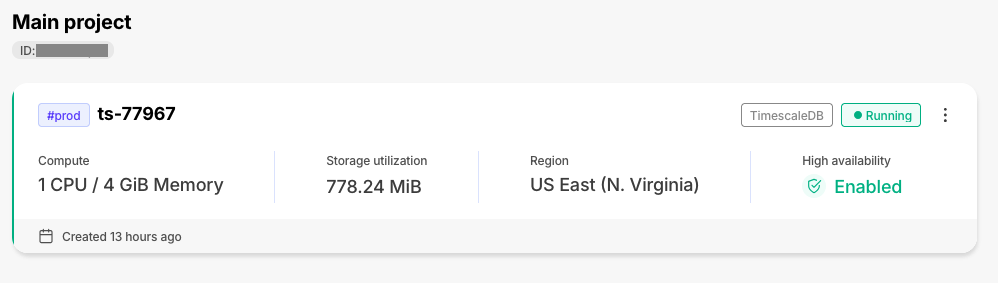
+### Improvements to the Timescale Console
+The individual tiles on the services page have been enhanced with new information, including high-availability status. This will let you better assess the state of your services at a glance.
+
+
+### Live migration release v0.0.24
+Improvements:
+- Automatic retries are now available for the initial data copy of the migration
+- Now uses pgcopydb for initial data copy for PG to TSDB migrations also (already did for TS to TS) which has a significant performance boost.
+- Fixes issues with TimescaleDB v2.13.x migrations
+- Support for chunk mapping for hypertables with custom schema and table prefixes
+
+## ⚡ Performance and stability improvements for Timescale Cloud and TimescaleDB
+
+
+The following improvements have been made to Timescale products:
+
+- **Timescale Cloud**:
+ - The connection pooler has been updated and now avoids multiple reloads
+ - The tsdbadmin user can now grant the following roles to other users: `pg_checkpoint`,`pg_monitor`,`pg_signal_backend`,`pg_read_all_stats`,`pg_stat_scan_tables`
+ - Timescale Console is far more reliable.
+
+- **TimescaleDB**
+ - The TimescaleDB v2.15.3 patch release improves handling of multiple unique indexes in a compressed INSERT,
+ removes the recheck of ORDER when querying compressed data, improves memory management in DML functions, improves
+ the tuple lock acquisition for tiered chunks on replicas, and fixes an issue with ORDER BY/GROUP BY in our
+ HashAggregate optimization on PG16. For more information, see the [release note](https://github.com/timescale/timescaledb/releases/tag/2.15.3).
+ - The TimescaleDB v2.15.2 patch release improves sort pushdown for partially compressed chunks, and compress_chunk with
+ a primary space partition. The metadata function is removed from the update script, and hash partitioning on a
+ primary column is disallowed. For more information, see the [release note](https://github.com/timescale/timescaledb/releases/tag/2.15.2).
+
+## ⚡ Performance improvements for live migration to Timescale Cloud
+
+
+The following improvements have been made to the Timescale [live-migration docker image](https://hub.docker.com/r/timescale/live-migration/tags):
+
+- Table-based filtering is now available during live migration.
+- Improvements to pbcopydb increase performance and remove unhelpful warning messages.
+- The user notification log enables you to always select the most recent release for a migration run.
+
+For improved stability and new features, update to the latest [timescale/live-migration](https://hub.docker.com/r/timescale/live-migration/tags) docker image. To learn more, see the [live migration docs](https://docs.timescale.com/migrate/latest/live-migration/).
+
+## 🦙Ollama integration in pgai
+
+
+
+Ollama is now integrated with [pgai](https://github.com/timescale/pgai).
+
+Ollama is the easiest and most popular way to get up and running with open-source
+language models. Think of Ollama as _Docker for LLMs_, enabling easy access and usage
+of a variety of open-source models like Llama 3, Mistral, Phi 3, Gemma, and more.
+
+With the pgai extension integrated in your database, embed Ollama AI into your app using
+SQL. For example:
+
+To learn more, see the [pgai Ollama documentation](https://github.com/timescale/pgai/blob/main/docs/vectorizer/quick-start.md).
+
+## 🧙 Compression Wizard
+
+
+
+The compression wizard is now available on Timescale Cloud. Select a hypertable and be guided through enabling compression through the UI!
+
+To access the compression wizard, navigate to `Explorer`, and select the hypertable you would like to compress. In the top right corner, hover where it says `Compression off`, and open the wizard. You will then be guided through the process of configuring compression for your hypertable, and can compress it directly through the UI.
+
+
+
+## 🏎️💨 High Performance AI Apps With pgvectorscale
+
+
+
+The [vectorscale extension][pgvectorscale] is now available on [Timescale Cloud][signup].
+
+pgvectorscale complements pgvector, the open-source vector data extension for Postgres, and introduces the
+following key innovations for pgvector data:
+
+- A new index type called StreamingDiskANN, inspired by the DiskANN algorithm, based on research from Microsoft.
+- Statistical Binary Quantization: developed by Timescale researchers, This compression method improves on
+ standard Binary Quantization.
+
+On benchmark dataset of 50 million Cohere embeddings (768 dimensions each), Postgres with pgvector and
+pgvectorscale achieves 28x lower p95 latency and 16x higher query throughput compared to Pinecone's storage
+optimized (s1) index for approximate nearest neighbor queries at 99% recall, all at 75% less cost when
+self-hosted on AWS EC2.
+
+To learn more, see the [pgvectorscale documentation][pgvectorscale].
+
+## 🧐Integrate AI Into Your Database Using pgai
+
+
+
+The [pgai extension][pgai] is now available on [Timescale Cloud][signup].
+
+pgai brings embedding and generation AI models closer to the database. With pgai, you can now do the following directly
+from within Postgres in a SQL query:
+
+* Create embeddings for your data.
+* Retrieve LLM chat completions from models like OpenAI GPT4o.
+* Reason over your data and facilitate use cases like classification, summarization, and data enrichment on your existing relational data in Postgres.
+
+To learn more, see the [pgai documentation][pgai].
+
+## 🐅Continuous Aggregate and Hypertable Improvements for TimescaleDB
+
+
+The 2.15.x releases contains performance improvements and bug fixes. Highlights in these releases are:
+
+- Continuous Aggregate now supports `time_bucket` with origin and/or offset.
+- Hypertable compression has the following improvements:
+ - Recommend optimized defaults for segment by and order by when configuring compression through analysis of table configuration and statistics.
+ - Added planner support to check more kinds of WHERE conditions before decompression.
+ This reduces the number of rows that have to be decompressed.
+ - You can now use minmax sparse indexes when you compress columns with btree indexes.
+ - Vectorize filters in the WHERE clause that contain text equality operators and LIKE expressions.
+
+To learn more, see the [TimescaleDB release notes](https://github.com/timescale/timescaledb/releases).
+
+## 🔍 Database Audit Logging with pgaudit
+
+
+The [Postgres Audit extension(pgaudit)](https://github.com/pgaudit/pgaudit/) is now available on [Timescale Cloud][signup].
+pgaudit provides detailed database session and object audit logging in the Timescale
+Cloud logs.
+
+If you have strict security and compliance requirements and need to log all operations
+on the database level, pgaudit can help. You can also export these audit logs to
+[Amazon CloudWatch](https://aws.amazon.com/cloudwatch/).
+
+To learn more, see the [pgaudit documentation](https://github.com/pgaudit/pgaudit/).
+
+## 🌡 International System of Unit Support with postgresql-unit
+
+
+The [SI Units for Postgres extension(unit)](https://github.com/df7cb/postgresql-unit) provides support for the
+[ISU](https://en.wikipedia.org/wiki/International_System_of_Units) in [Timescale Cloud][signup].
+
+You can use Timescale Cloud to solve day-to-day questions. For example, to see what 50°C is in °F, run the following
+query in your Timescale Cloud service:
+
+To learn more, see the [postgresql-unit documentation](https://github.com/df7cb/postgresql-unit).
+
+===== PAGE: https://docs.tigerdata.com/about/timescaledb-editions/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+SELECT * FROM hypertable WHERE timestamp_col > now() - '100 days'::interval
+```
+
+Example 2 (unknown):
+```unknown
+begin;
+insert into users (name, email) values ('john doe', 'john@example.com');
+abort; -- nothing inserted
+```
+
+Example 3 (unknown):
+```unknown
+create temporary table temp_users (email text);
+insert into temp_sales (email) values ('john@example.com');
+-- table will automatically disappear after your session ends
+```
+
+Example 4 (unknown):
+```unknown
+set search_path to 'myschema', 'public';
+```
+
+---
+
+## Create a compression policy
+
+**URL:** llms-txt#create-a-compression-policy
+
+**Contents:**
+- Enable a compression policy
+ - Enabling compression
+- View current compression policy
+- Pause compression policy
+- Remove compression policy
+- Disable compression
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by
Optimize your data for real-time analytics.
+
+You can enable compression on individual hypertables, by declaring which column
+you want to segment by.
+
+## Enable a compression policy
+
+This page uses an example table, called `example`, and segments it by the
+`device_id` column. Every chunk that is more than seven days old is then marked
+to be automatically compressed. The source data is organized like this:
+
+|time|device_id|cpu|disk_io|energy_consumption|
+|-|-|-|-|-|
+|8/22/2019 0:00|1|88.2|20|0.8|
+|8/22/2019 0:05|2|300.5|30|0.9|
+
+### Enabling compression
+
+1. At the `psql` prompt, alter the table:
+
+1. Add a compression policy to compress chunks that are older than seven days:
+
+For more information, see the API reference for
+[`ALTER TABLE (compression)`][alter-table-compression] and
+[`add_compression_policy`][add_compression_policy].
+
+## View current compression policy
+
+To view the compression policy that you've set:
+
+For more information, see the API reference for [`timescaledb_information.jobs`][timescaledb_information-jobs].
+
+## Pause compression policy
+
+To disable a compression policy temporarily, find the corresponding job ID and then call `alter_job` to pause it:
+
+## Remove compression policy
+
+To remove a compression policy, use `remove_compression_policy`:
+
+For more information, see the API reference for
+[`remove_compression_policy`][remove_compression_policy].
+
+## Disable compression
+
+You can disable compression entirely on individual hypertables. This command
+works only if you don't currently have any compressed chunks:
+
+If your hypertable contains compressed chunks, you need to
+[decompress each chunk][decompress-chunks] individually before you can turn off
+compression.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/modify-compressed-data/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER TABLE example SET (
+ timescaledb.compress,
+ timescaledb.compress_segmentby = 'device_id'
+ );
+```
+
+Example 2 (sql):
+```sql
+SELECT add_compression_policy('example', INTERVAL '7 days');
+```
+
+Example 3 (sql):
+```sql
+SELECT * FROM timescaledb_information.jobs
+ WHERE proc_name='policy_compression';
+```
+
+Example 4 (sql):
+```sql
+SELECT * FROM timescaledb_information.jobs where proc_name = 'policy_compression' AND relname = 'example'
+```
+
+---
+
+## Compress your data using hypercore
+
+**URL:** llms-txt#compress-your-data-using-hypercore
+
+**Contents:**
+- Optimize your data in the columnstore
+- Take advantage of query speedups
+
+Over time you end up with a lot of data. Since this data is mostly immutable, you can compress it
+to save space and avoid incurring additional cost.
+
+TimescaleDB is built for handling event-oriented data such as time-series and fast analytical queries, it comes with support
+of [hypercore][hypercore] featuring the columnstore.
+
+[Hypercore][hypercore] enables you to store the data in a vastly more efficient format allowing
+up to 90x compression ratio compared to a normal Postgres table. However, this is highly dependent
+on the data and configuration.
+
+[Hypercore][hypercore] is implemented natively in Postgres and does not require special storage
+formats. When you convert your data from the rowstore to the columnstore, TimescaleDB uses
+Postgres features to transform the data into columnar format. The use of a columnar format allows a better
+compression ratio since similar data is stored adjacently. For more details on the columnar format,
+see [hypercore][hypercore].
+
+A beneficial side effect of compressing data is that certain queries are significantly faster, since
+less data has to be read into memory.
+
+## Optimize your data in the columnstore
+
+To compress the data in the `transactions` table, do the following:
+
+1. Connect to your Tiger Cloud service
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
+ You can also connect to your service using [psql][connect-using-psql].
+
+1. Convert data to the columnstore:
+
+You can do this either automatically or manually:
+ - [Automatically convert chunks][add_columnstore_policy] in the hypertable to the columnstore at a specific time interval:
+
+- [Manually convert all chunks][convert_to_columnstore] in the hypertable to the columnstore:
+
+## Take advantage of query speedups
+
+Previously, data in the columnstore was segmented by the `block_id` column value.
+This means fetching data by filtering or grouping on that column is
+more efficient. Ordering is set to time descending. This means that when you run queries
+which try to order data in the same way, you see performance benefits.
+
+1. Connect to your Tiger Cloud service
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
+
+1. Run the following query:
+
+Performance speedup is of two orders of magnitude, around 15 ms when compressed in the columnstore and
+ 1 second when decompressed in the rowstore.
+
+===== PAGE: https://docs.tigerdata.com/tutorials/blockchain-query/blockchain-dataset/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL add_columnstore_policy('transactions', after => INTERVAL '1d');
+```
+
+Example 2 (sql):
+```sql
+DO $$
+ DECLARE
+ chunk_name TEXT;
+ BEGIN
+ FOR chunk_name IN (SELECT c FROM show_chunks('transactions') c)
+ LOOP
+ RAISE NOTICE 'Converting chunk: %', chunk_name; -- Optional: To see progress
+ CALL convert_to_columnstore(chunk_name);
+ END LOOP;
+ RAISE NOTICE 'Conversion to columnar storage complete for all chunks.'; -- Optional: Completion message
+ END$$;
+```
+
+Example 3 (sql):
+```sql
+WITH recent_blocks AS (
+ SELECT block_id FROM transactions
+ WHERE is_coinbase IS TRUE
+ ORDER BY time DESC
+ LIMIT 5
+ )
+ SELECT
+ t.block_id, count(*) AS transaction_count,
+ SUM(weight) AS block_weight,
+ SUM(output_total_usd) AS block_value_usd
+ FROM transactions t
+ INNER JOIN recent_blocks b ON b.block_id = t.block_id
+ WHERE is_coinbase IS NOT TRUE
+ GROUP BY t.block_id;
+```
+
+---
+
+## ALTER TABLE (Compression)
+
+**URL:** llms-txt#alter-table-(compression)
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Parameters
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by
ALTER TABLE (Hypercore).
+
+'ALTER TABLE' statement is used to turn on compression and set compression
+options.
+
+By itself, this `ALTER` statement alone does not compress a hypertable. To do so, either create a
+compression policy using the [add_compression_policy][add_compression_policy] function or manually
+compress a specific hypertable chunk using the [compress_chunk][compress_chunk] function.
+
+Configure a hypertable that ingests device data to use compression. Here, if the hypertable
+is often queried about a specific device or set of devices, the compression should be
+segmented using the `device_id` for greater performance.
+
+You can also specify compressed chunk interval without changing other
+compression settings:
+
+To disable the previously set option, set the interval to 0:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`timescaledb.compress`|BOOLEAN|Enable or disable compression|
+
+## Optional arguments
+
+|Name|Type| Description |
+|-|-|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|`timescaledb.compress_orderby`|TEXT| Order used by compression, specified in the same way as the ORDER BY clause in a SELECT query. The default is the descending order of the hypertable's time column. |
+|`timescaledb.compress_segmentby`|TEXT| Column list on which to key the compressed segments. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. The default is no `segment by` columns. |
+|`timescaledb.compress_chunk_time_interval`|TEXT| EXPERIMENTAL: Set compressed chunk time interval used to roll chunks into. This parameter compresses every chunk, and then irreversibly merges it into a previous adjacent chunk if possible, to reduce the total number of chunks in the hypertable. Note that chunks will not be split up during decompression. It should be set to a multiple of the current chunk interval. This option can be changed independently of other compression settings and does not require the `timescaledb.compress` argument. |
+
+|Name|Type|Description|
+|-|-|-|
+|`table_name`|TEXT|Hypertable that supports compression|
+|`column_name`|TEXT|Column used to order by or segment by|
+|`interval`|TEXT|Time interval used to roll compressed chunks into|
+
+===== PAGE: https://docs.tigerdata.com/api/compression/hypertable_compression_stats/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+## Samples
+
+Configure a hypertable that ingests device data to use compression. Here, if the hypertable
+is often queried about a specific device or set of devices, the compression should be
+segmented using the `device_id` for greater performance.
+```
+
+Example 2 (unknown):
+```unknown
+You can also specify compressed chunk interval without changing other
+compression settings:
+```
+
+Example 3 (unknown):
+```unknown
+To disable the previously set option, set the interval to 0:
+```
+
+---
+
+## FAQ and troubleshooting
+
+**URL:** llms-txt#faq-and-troubleshooting
+
+**Contents:**
+- Unsupported in live migration
+- Where can I find logs for processes running during live migration?
+- Source and target databases have different TimescaleDB versions
+- Why does live migration log "no tuple identifier" warning?
+- Set REPLICA IDENTITY on Postgres partitioned tables
+- Can I use read/failover replicas as source database for live migration?
+- Can I use live migration with a Postgres connection pooler like PgBouncer?
+- Can I use Tiger Cloud instance as source for live migration?
+- How can I exclude a schema/table from being replicated in live migration?
+- Large migrations blocked
+
+## Unsupported in live migration
+
+Live migration tooling is currently experimental. You may run into the following shortcomings:
+
+- Live migration does not yet support mutable columnstore compression (`INSERT`, `UPDATE`,
+ `DELETE` on data in the columnstore).
+- By default, numeric fields containing `NaN`/`+Inf`/`-Inf` values are not
+ correctly replicated, and will be converted to `NULL`. A workaround is available, but is not enabled by default.
+
+Should you run into any problems, please open a support request before losing
+any time debugging issues.
+You can open a support request directly from [Tiger Cloud Console][support-link],
+or by email to [support@tigerdata.com](mailto:support@tigerdata.com).
+
+## Where can I find logs for processes running during live migration?
+
+Live migration involves several background processes to manage different stages of
+the migration. The logs of these processes can be helpful for troubleshooting
+unexpected behavior. You can find these logs in the `
/logs` directory.
+
+## Source and target databases have different TimescaleDB versions
+
+When you migrate a [self-hosted][self hosted] or [Managed Service for TimescaleDB (MST)][mst]
+database to Tiger Cloud, the source database and the destination
+[Tiger Cloud service][timescale-service] must run the same version of TimescaleDB.
+
+Before you start [live migration][live migration]:
+
+1. Check the version of TimescaleDB running on the source database and the
+ target Tiger Cloud service:
+
+1. If the version of TimescaleDB on the source database is lower than your Tiger Cloud service, either:
+ - **Downgrade**: reinstall an older version of TimescaleDB on your Tiger Cloud service that matches the source database:
+
+1. Connect to your Tiger Cloud service and check the versions of TimescaleDB available:
+
+2. If an available TimescaleDB release matches your source database:
+
+1. Uninstall TimescaleDB from your Tiger Cloud service:
+
+1. Reinstall the correct version of TimescaleDB:
+
+You may need to reconnect to your Tiger Cloud service using `psql -X` when you're creating the TimescaleDB extension.
+
+- **Upgrade**: for self-hosted databases, [upgrade TimescaleDB][self hosted upgrade] to match your Tiger Cloud service.
+
+## Why does live migration log "no tuple identifier" warning?
+
+Live migration logs a warning `WARNING: no tuple identifier for UPDATE in table`
+when it cannot determine which specific rows should be updated after receiving an
+`UPDATE` statement from the source database during replication. This occurs when tables
+in the source database that receive `UPDATE` statements lack either a `PRIMARY KEY` or
+a `REPLICA IDENTITY` setting. For live migration to successfully replicate `UPDATE` and
+`DELETE` statements, tables must have either a `PRIMARY KEY` or `REPLICA IDENTITY` set
+as a prerequisite.
+
+## Set REPLICA IDENTITY on Postgres partitioned tables
+
+If your Postgres tables use native partitioning, setting `REPLICA IDENTITY` on the
+root (parent) table will not automatically apply it to the partitioned child tables.
+You must manually set `REPLICA IDENTITY` on each partitioned child table.
+
+## Can I use read/failover replicas as source database for live migration?
+
+Live migration does not support replication from read or failover replicas. You must
+provide a connection string that points directly to your source database for
+live migration.
+
+## Can I use live migration with a Postgres connection pooler like PgBouncer?
+
+Live migration does not support connection poolers. You must provide a
+connection string that points directly to your source and target databases
+for live migration to work smoothly.
+
+## Can I use Tiger Cloud instance as source for live migration?
+
+No, Tiger Cloud cannot be used as a source database for live migration.
+
+## How can I exclude a schema/table from being replicated in live migration?
+
+At present, live migration does not allow for excluding schemas or tables from
+replication, but this feature is expected to be added in future releases.
+However, a workaround is available for skipping table data using the `--skip-table-data` flag.
+For more information, please refer to the help text under the `migrate` subcommand.
+
+## Large migrations blocked
+
+Tiger Cloud automatically manages the underlying disk volume. Due to
+platform limitations, it is only possible to resize the disk once every six
+hours. Depending on the rate at which you're able to copy data, you may be
+affected by this restriction. Affected instances are unable to accept new data
+and error with: `FATAL: terminating connection due to administrator command`.
+
+If you intend on migrating more than 400 GB of data to Tiger Cloud, open a
+support request requesting the required storage to be pre-allocated in your
+Tiger Cloud service.
+
+You can open a support request directly from [Tiger Cloud Console][support-link],
+or by email to [support@tigerdata.com](mailto:support@tigerdata.com).
+
+When `pg_dump` starts, it takes an `ACCESS SHARE` lock on all tables which it
+dumps. This ensures that tables aren't dropped before `pg_dump` is able to drop
+them. A side effect of this is that any query which tries to take an
+`ACCESS EXCLUSIVE` lock on a table is be blocked by the `ACCESS SHARE` lock.
+
+A number of Tiger Cloud-internal processes require taking `ACCESS EXCLUSIVE`
+locks to ensure consistency of the data. The following is a non-exhaustive list
+of potentially affected operations:
+
+- converting a chunk into the columnstore/rowstore and back
+- continuous aggregate refresh (before 2.12)
+- create hypertable with foreign keys, truncate hypertable
+- enable hypercore on a hypertable
+- drop chunks
+
+The most likely impact of the above is that background jobs for retention
+policies, columnstore compression policies, and continuous aggregate refresh policies are
+blocked for the duration of the `pg_dump` command. This may have unintended
+consequences for your database performance.
+
+## Dumping with concurrency
+
+When using the `pg_dump` directory format, it is possible to use concurrency to
+use multiple connections to the source database to dump data. This speeds up
+the dump process. Due to the fact that there are multiple connections, it is
+possible for `pg_dump` to end up in a deadlock situation. When it detects a
+deadlock it aborts the dump.
+
+In principle, any query which takes an `ACCESS EXCLUSIVE` lock on a table
+causes such a deadlock. As mentioned above, some common operations which take
+an `ACCESS EXCLUSIVE` lock are:
+- retention policies
+- columnstore compression policies
+- continuous aggregate refresh policies
+
+If you would like to use concurrency nonetheless, turn off all background jobs
+in the source database before running `pg_dump`, and turn them on once the dump
+is complete. If the dump procedure takes longer than the continuous aggregate
+refresh policy's window, you must manually refresh the continuous aggregate in
+the correct time range. For more information, consult the
+[refresh policies documentation].
+
+To turn off the jobs:
+
+## Restoring with concurrency
+
+If the directory format is used for `pg_dump` and `pg_restore`, concurrency can be
+employed to speed up the process. Unfortunately, loading the tables in the
+`timescaledb_catalog` schema concurrently causes errors. Furthermore, the
+`tsdbadmin` user does not have sufficient privileges to turn off triggers in
+this schema. To get around this limitation, load this schema serially, and then
+load the rest of the database concurrently.
+
+## Ownership of background jobs
+
+The `_timescaledb_config.bgw_jobs` table is used to manage background jobs.
+This includes custom jobs, columnstore compression policies, retention
+policies, and continuous aggregate refresh policies. On Tiger Cloud, this table
+has a trigger which ensures that no database user can create or modify jobs
+owned by another database user. This trigger can provide an obstacle for migrations.
+
+If the `--no-owner` flag is used with `pg_dump` and `pg_restore`, all
+objects in the target database are owned by the user that ran
+`pg_restore`, likely `tsdbadmin`.
+
+If all the background jobs in the source database were owned by a user of the
+same name as the user running the restore (again likely `tsdbadmin`), then
+loading the `_timescaledb_config.bgw_jobs` table should work.
+
+If the background jobs in the source were owned by the `postgres` user, they
+are be automatically changed to be owned by the `tsdbadmin` user. In this case,
+one just needs to verify that the jobs do not make use of privileges that the
+`tsdbadmin` user does not possess.
+
+If background jobs are owned by one or more users other than the user
+employed in restoring, then there could be issues. To work around this
+issue, do not dump this table with `pg_dump`. Provide either
+`--exclude-table-data='_timescaledb_config.bgw_job'` or
+`--exclude-table='_timescaledb_config.bgw_job'` to `pg_dump` to skip
+this table. Then, use `psql` and the `COPY` command to dump and
+restore this table with modified values for the `owner` column.
+
+Once the table has been loaded and the restore completed, you may then use SQL
+to adjust the ownership of the jobs and/or the associated stored procedures and
+functions as you wish.
+
+## Extension availability
+
+There are a vast number of Postgres extensions available in the wild.
+Tiger Cloud supports many of the most popular extensions, but not all extensions.
+Before migrating, check that the extensions you are using are supported on
+Tiger Cloud. Consult the [list of supported extensions].
+
+## TimescaleDB extension in the public schema
+
+When self-hosting, the TimescaleDB extension may be installed in an arbitrary
+schema. Tiger Cloud only supports installing the TimescaleDB extension in the
+`public` schema. How to go about resolving this depends heavily on the
+particular details of the source schema and the migration approach chosen.
+
+Tiger Cloud does not support using custom tablespaces. Providing the
+`--no-tablespaces` flag to `pg_dump` and `pg_restore` when
+dumping/restoring the schema results in all objects being in the
+default tablespace as desired.
+
+## Only one database per instance
+
+While Postgres clusters can contain many databases, Tiger Cloud services are
+limited to a single database. When migrating a cluster with multiple databases
+to Tiger Cloud, one can either migrate each source database to a separate
+Tiger Cloud service or "merge" source databases to target schemas.
+
+## Superuser privileges
+
+The `tsdbadmin` database user is the most powerful available on Tiger Cloud, but it
+is not a true superuser. Review your application for use of superuser privileged
+operations and mitigate before migrating.
+
+## Migrate partial continuous aggregates
+
+In order to improve the performance and compatibility of continuous aggregates, TimescaleDB
+v2.7 replaces _partial_ continuous aggregates with _finalized_ continuous aggregates.
+
+To test your database for partial continuous aggregates, run the following query:
+
+If you have partial continuous aggregates in your database, [migrate them][migrate]
+from partial to finalized before you migrate your database.
+
+If you accidentally migrate partial continuous aggregates across Postgres
+versions, you see the following error when you query any continuous aggregates:
+
+===== PAGE: https://docs.tigerdata.com/ai/mcp-server/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+select extversion from pg_extension where extname = 'timescaledb';
+```
+
+Example 2 (sql):
+```sql
+SELECT version FROM pg_available_extension_versions WHERE name = 'timescaledb' ORDER BY 1 DESC;
+```
+
+Example 3 (sql):
+```sql
+DROP EXTENSION timescaledb;
+```
+
+Example 4 (sql):
+```sql
+CREATE EXTENSION timescaledb VERSION '';
+```
+
+---
+
+## Energy consumption data tutorial - set up compression
+
+**URL:** llms-txt#energy-consumption-data-tutorial---set-up-compression
+
+**Contents:**
+- Compression setup
+- Add a compression policy
+- Taking advantage of query speedups
+
+You have now seen how to create a hypertable for your energy consumption
+dataset and query it. When ingesting a dataset like this
+is seldom necessary to update old data and over time the amount of
+data in the tables grows. Over time you end up with a lot of data and
+since this is mostly immutable you can compress it to save space and
+avoid incurring additional cost.
+
+It is possible to use disk-oriented compression like the support
+offered by ZFS and Btrfs but since TimescaleDB is build for handling
+event-oriented data (such as time-series) it comes with support for
+compressing data in hypertables.
+
+TimescaleDB compression allows you to store the data in a vastly more
+efficient format allowing up to 20x compression ratio compared to a
+normal Postgres table, but this is of course highly dependent on the
+data and configuration.
+
+TimescaleDB compression is implemented natively in Postgres and does
+not require special storage formats. Instead it relies on features of
+Postgres to transform the data into columnar format before
+compression. The use of a columnar format allows better compression
+ratio since similar data is stored adjacently. For more details on how
+the compression format looks, you can look at the [compression
+design][compression-design] section.
+
+A beneficial side-effect of compressing data is that certain queries
+are significantly faster since less data has to be read into
+memory.
+
+1. Connect to the Tiger Cloud service that contains the energy
+ dataset using, for example `psql`.
+1. Enable compression on the table and pick suitable segment-by and
+ order-by column using the `ALTER TABLE` command:
+
+Depending on the choice if segment-by and order-by column you can
+ get very different performance and compression ratio. To learn
+ more about how to pick the correct columns, see
+ [here][segment-by-columns].
+1. You can manually compress all the chunks of the hypertable using
+ `compress_chunk` in this manner:
+
+ You can also [automate compression][automatic-compression] by
+ adding a [compression policy][add_compression_policy] which will
+ be covered below.
+
+1. Now that you have compressed the table you can compare the size of
+ the dataset before and after compression:
+
+This shows a significant improvement in data usage:
+
+## Add a compression policy
+
+To avoid running the compression step each time you have some data to
+compress you can set up a compression policy. The compression policy
+allows you to compress data that is older than a particular age, for
+example, to compress all chunks that are older than 8 days:
+
+Compression policies run on a regular schedule, by default once every
+day, which means that you might have up to 9 days of uncompressed data
+with the setting above.
+
+You can find more information on compression policies in the
+[add_compression_policy][add_compression_policy] section.
+
+## Taking advantage of query speedups
+
+Previously, compression was set up to be segmented by `type_id` column value.
+This means fetching data by filtering or grouping on that column will be
+more efficient. Ordering is also set to `created` descending so if you run queries
+which try to order data with that ordering, you should see performance benefits.
+
+For instance, if you run the query example from previous section:
+
+You should see a decent performance difference when the dataset is compressed and
+when is decompressed. Try it yourself by running the previous query, decompressing
+the dataset and running it again while timing the execution time. You can enable
+timing query times in psql by running:
+
+To decompress the whole dataset, run:
+
+On an example setup, speedup performance observed was an order of magnitude,
+30 ms when compressed vs 360 ms when decompressed.
+
+Try it yourself and see what you get!
+
+===== PAGE: https://docs.tigerdata.com/tutorials/financial-ingest-real-time/financial-ingest-dataset/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER TABLE metrics
+ SET (
+ timescaledb.compress,
+ timescaledb.compress_segmentby='type_id',
+ timescaledb.compress_orderby='created DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+SELECT compress_chunk(c) from show_chunks('metrics') c;
+```
+
+Example 3 (sql):
+```sql
+SELECT
+ pg_size_pretty(before_compression_total_bytes) as before,
+ pg_size_pretty(after_compression_total_bytes) as after
+ FROM hypertable_compression_stats('metrics');
+```
+
+Example 4 (sql):
+```sql
+before | after
+ --------+-------
+ 180 MB | 16 MB
+ (1 row)
+```
+
+---
+
+## Tuple decompression limit exceeded by operation
+
+**URL:** llms-txt#tuple-decompression-limit-exceeded-by-operation
+
+
+
+When inserting, updating, or deleting tuples from chunks in the columnstore, it might be necessary to convert tuples to the rowstore. This happens either when you are updating existing tuples or have constraints that need to be verified during insert time. If you happen to trigger a lot of rowstore conversion with a single command, you may end up running out of storage space. For this reason, a limit has been put in place on the number of tuples you can decompress into the rowstore for a single command.
+
+The limit can be increased or turned off (set to 0) like so:
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/caggs-queries-fail/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+-- set limit to a milion tuples
+SET timescaledb.max_tuples_decompressed_per_dml_transaction TO 1000000;
+-- disable limit by setting to 0
+SET timescaledb.max_tuples_decompressed_per_dml_transaction TO 0;
+```
+
+---
+
+## Schema modifications
+
+**URL:** llms-txt#schema-modifications
+
+**Contents:**
+- Add a nullable column
+- Add a column with a default value and a NOT NULL constraint
+- Rename a column
+- Drop a column
+
+You can modify the schema of compressed hypertables in recent versions of
+TimescaleDB.
+
+|Schema modification|Before TimescaleDB 2.1|TimescaleDB 2.1 to 2.5|TimescaleDB 2.6 and above|
+|-|-|-|-|
+|Add a nullable column|❌|✅|✅|
+|Add a column with a default value and a `NOT NULL` constraint|❌|❌|✅|
+|Rename a column|❌|✅|✅|
+|Drop a column|❌|❌|✅|
+|Change the data type of a column|❌|❌|❌|
+
+To perform operations that aren't supported on compressed hypertables, first
+[decompress][decompression] the table.
+
+## Add a nullable column
+
+To add a nullable column:
+
+Note that adding constraints to the new column is not supported before
+TimescaleDB v2.6.
+
+## Add a column with a default value and a NOT NULL constraint
+
+To add a column with a default value and a not-null constraint:
+
+You can drop a column from a compressed hypertable, if the column is not an
+`orderby` or `segmentby` column. To drop a column:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/decompress-chunks/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER TABLE ADD COLUMN ;
+```
+
+Example 2 (sql):
+```sql
+ALTER TABLE conditions ADD COLUMN device_id integer;
+```
+
+Example 3 (sql):
+```sql
+ALTER TABLE ADD COLUMN
+ NOT NULL DEFAULT ;
+```
+
+Example 4 (sql):
+```sql
+ALTER TABLE conditions ADD COLUMN device_id integer
+ NOT NULL DEFAULT 1;
+```
+
+---
+
+## Compression
+
+**URL:** llms-txt#compression
+
+**Contents:**
+- Restrictions
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by Hypercore.
+
+Compression functionality is included in Hypercore.
+
+Before you set up compression, you need to
+[configure the hypertable for compression][configure-compression] and then
+[set up a compression policy][add_compression_policy].
+
+Before you set up compression for the first time, read
+the compression
+[blog post](https://www.tigerdata.com/blog/building-columnar-compression-in-a-row-oriented-database)
+and
+[documentation](https://docs.tigerdata.com/use-timescale/latest/compression/).
+
+You can also [compress chunks manually][compress_chunk], instead of using an
+automated compression policy to compress chunks as they age.
+
+Compressed chunks have the following limitations:
+
+* `ROW LEVEL SECURITY` is not supported on compressed chunks.
+* Creation of unique constraints on compressed chunks is not supported. You
+ can add them by disabling compression on the hypertable and re-enabling
+ after constraint creation.
+
+In general, compressing a hypertable imposes some limitations on the types
+of data modifications that you can perform on data inside a compressed chunk.
+
+This table shows changes to the compression feature, added in different versions
+of TimescaleDB:
+
+|TimescaleDB version|Supported data modifications on compressed chunks|
+|-|-|
+|1.5 - 2.0|Data and schema modifications are not supported.|
+|2.1 - 2.2|Schema may be modified on compressed hypertables. Data modification not supported.|
+|2.3|Schema modifications and basic insert of new data is allowed. Deleting, updating and some advanced insert statements are not supported.|
+|2.11|Deleting, updating and advanced insert statements are supported.|
+
+In TimescaleDB 2.1 and later, you can modify the schema of hypertables that
+have compressed chunks. Specifically, you can add columns to and rename existing
+columns of compressed hypertables.
+
+In TimescaleDB v2.3 and later, you can insert data into compressed chunks
+and to enable compression policies on distributed hypertables.
+
+In TimescaleDB v2.11 and later, you can update and delete compressed data.
+You can also use advanced insert statements like `ON CONFLICT` and `RETURNING`.
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/ =====
+
+---
diff --git a/skills/timescaledb/references/continuous_aggregates.md b/skills/timescaledb/references/continuous_aggregates.md
new file mode 100644
index 0000000..f457d69
--- /dev/null
+++ b/skills/timescaledb/references/continuous_aggregates.md
@@ -0,0 +1,1880 @@
+# Timescaledb - Continuous Aggregates
+
+**Pages:** 21
+
+---
+
+## Permissions error when migrating a continuous aggregate
+
+**URL:** llms-txt#permissions-error-when-migrating-a-continuous-aggregate
+
+
+
+You might get a permissions error when migrating a continuous aggregate from old
+to new format using `cagg_migrate`. The user performing the migration must have
+the following permissions:
+
+* Select, insert, and update permissions on the tables
+ `_timescale_catalog.continuous_agg_migrate_plan` and
+ `_timescale_catalog.continuous_agg_migrate_plan_step`
+* Usage permissions on the sequence
+ `_timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq`
+
+To solve the problem, change to a user capable of granting permissions, and
+grant the following permissions to the user performing the migration:
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/compression-high-cardinality/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan TO ;
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan_step TO ;
+GRANT USAGE ON SEQUENCE _timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq TO ;
+```
+
+---
+
+## CREATE MATERIALIZED VIEW (Continuous Aggregate)
+
+**URL:** llms-txt#create-materialized-view-(continuous-aggregate)
+
+**Contents:**
+- Samples
+- Parameters
+
+The `CREATE MATERIALIZED VIEW` statement is used to create continuous
+aggregates. To learn more, see the
+[continuous aggregate how-to guides][cagg-how-tos].
+
+`` is of the form:
+
+The continuous aggregate view defaults to `WITH DATA`. This means that when the
+view is created, it refreshes using all the current data in the underlying
+hypertable or continuous aggregate. This occurs once when the view is created.
+If you want the view to be refreshed regularly, you can use a refresh policy. If
+you do not want the view to update when it is first created, use the
+`WITH NO DATA` parameter. For more information, see
+[`refresh_continuous_aggregate`][refresh-cagg].
+
+Continuous aggregates have some limitations of what types of queries they can
+support. For more information, see the
+[continuous aggregates section][cagg-how-tos].
+
+TimescaleDB v2.17.1 and greater dramatically decrease the amount
+of data written on a continuous aggregate in the presence of a small number of changes,
+reduce the i/o cost of refreshing a continuous aggregate, and generate fewer Write-Ahead
+Logs (WAL), set the`timescaledb.enable_merge_on_cagg_refresh`
+configuration parameter to `TRUE`. This enables continuous aggregate
+refresh to use merge instead of deleting old materialized data and re-inserting.
+
+For more settings for continuous aggregates, see [timescaledb_information.continuous_aggregates][info-views].
+
+Create a daily continuous aggregate view:
+
+Add a thirty day continuous aggregate on top of the same raw hypertable:
+
+Add an hourly continuous aggregate on top of the same raw hypertable:
+
+|Name|Type|Description|
+|-|-|-|
+|``|TEXT|Name (optionally schema-qualified) of continuous aggregate view to create|
+|``|TEXT|Optional list of names to be used for columns of the view. If not given, the column names are calculated from the query|
+|`WITH` clause|TEXT|Specifies options for the continuous aggregate view|
+|``|TEXT|A `SELECT` query that uses the specified syntax|
+
+Required `WITH` clause options:
+
+|Name|Type|Description|
+|-|-|-|
+|`timescaledb.continuous`|BOOLEAN|If `timescaledb.continuous` is not specified, this is a regular PostgresSQL materialized view|
+
+Optional `WITH` clause options:
+
+|Name|Type| Description |Default value|
+|-|-|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-|
+|`timescaledb.chunk_interval`|INTERVAL| Set the chunk interval. The default value is 10x the original hypertable. |
+|`timescaledb.create_group_indexes`|BOOLEAN| Create indexes on the continuous aggregate for columns in its `GROUP BY` clause. Indexes are in the form `(, time_bucket)` |`TRUE`|
+|`timescaledb.finalized`|BOOLEAN| In TimescaleDB 2.7 and above, use the new version of continuous aggregates, which stores finalized results for aggregate functions. Supports all aggregate functions, including ones that use `FILTER`, `ORDER BY`, and `DISTINCT` clauses. |`TRUE`|
+|`timescaledb.materialized_only`|BOOLEAN| Return only materialized data when querying the continuous aggregate view |`TRUE`|
+| `timescaledb.invalidate_using` | TEXT | Since [TimescaleDB v2.22.0](https://github.com/timescale/timescaledb/releases/tag/2.22.0)Set to `wal` to read changes from the WAL using logical decoding, then update the materialization invalidations for continuous aggregates using this information. This reduces the I/O and CPU needed to manage the hypertable invalidation log. Set to `trigger` to collect invalidations whenever there are inserts, updates, or deletes to a hypertable. This default behaviour uses more resources than `wal`. | `trigger` |
+
+For more information, see the [real-time aggregates][real-time-aggregates] section.
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/alter_materialized_view/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+`` is of the form:
+```
+
+Example 2 (unknown):
+```unknown
+The continuous aggregate view defaults to `WITH DATA`. This means that when the
+view is created, it refreshes using all the current data in the underlying
+hypertable or continuous aggregate. This occurs once when the view is created.
+If you want the view to be refreshed regularly, you can use a refresh policy. If
+you do not want the view to update when it is first created, use the
+`WITH NO DATA` parameter. For more information, see
+[`refresh_continuous_aggregate`][refresh-cagg].
+
+Continuous aggregates have some limitations of what types of queries they can
+support. For more information, see the
+[continuous aggregates section][cagg-how-tos].
+
+TimescaleDB v2.17.1 and greater dramatically decrease the amount
+of data written on a continuous aggregate in the presence of a small number of changes,
+reduce the i/o cost of refreshing a continuous aggregate, and generate fewer Write-Ahead
+Logs (WAL), set the`timescaledb.enable_merge_on_cagg_refresh`
+configuration parameter to `TRUE`. This enables continuous aggregate
+refresh to use merge instead of deleting old materialized data and re-inserting.
+
+For more settings for continuous aggregates, see [timescaledb_information.continuous_aggregates][info-views].
+
+## Samples
+
+Create a daily continuous aggregate view:
+```
+
+Example 3 (unknown):
+```unknown
+Add a thirty day continuous aggregate on top of the same raw hypertable:
+```
+
+Example 4 (unknown):
+```unknown
+Add an hourly continuous aggregate on top of the same raw hypertable:
+```
+
+---
+
+## Queries fail when defining continuous aggregates but work on regular tables
+
+**URL:** llms-txt#queries-fail-when-defining-continuous-aggregates-but-work-on-regular-tables
+
+Continuous aggregates do not work on all queries. For example, TimescaleDB does not support window functions on
+continuous aggregates. If you use an unsupported function, you see the following error:
+
+The following table summarizes the aggregate functions supported in continuous aggregates:
+
+| Function, clause, or feature |TimescaleDB 2.6 and earlier|TimescaleDB 2.7, 2.8, and 2.9|TimescaleDB 2.10 and later|
+|------------------------------------------------------------|-|-|-|
+| Parallelizable aggregate functions |✅|✅|✅|
+| [Non-parallelizable SQL aggregates][postgres-parallel-agg] |❌|✅|✅|
+| `ORDER BY` |❌|✅|✅|
+| Ordered-set aggregates |❌|✅|✅|
+| Hypothetical-set aggregates |❌|✅|✅|
+| `DISTINCT` in aggregate functions |❌|✅|✅|
+| `FILTER` in aggregate functions |❌|✅|✅|
+| `FROM` clause supports `JOINS` |❌|❌|✅|
+
+DISTINCT works in aggregate functions, not in the query definition. For example, for the table:
+
+- The following works:
+
+- This does not:
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/caggs-real-time-previously-materialized-not-shown/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ERROR: invalid continuous aggregate view
+ SQL state: 0A000
+```
+
+Example 2 (sql):
+```sql
+CREATE TABLE public.candle(
+symbol_id uuid NOT NULL,
+symbol text NOT NULL,
+"time" timestamp with time zone NOT NULL,
+open double precision NOT NULL,
+high double precision NOT NULL,
+low double precision NOT NULL,
+close double precision NOT NULL,
+volume double precision NOT NULL
+);
+```
+
+Example 3 (sql):
+```sql
+CREATE MATERIALIZED VIEW candles_start_end
+ WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 hour', "time"), COUNT(DISTINCT symbol), first(time, time) as first_candle, last(time, time) as last_candle
+ FROM candle
+ GROUP BY 1;
+```
+
+Example 4 (sql):
+```sql
+CREATE MATERIALIZED VIEW candles_start_end
+ WITH (timescaledb.continuous) AS
+ SELECT DISTINCT ON (symbol)
+ symbol,symbol_id, first(time, time) as first_candle, last(time, time) as last_candle
+ FROM candle
+ GROUP BY symbol_id;
+```
+
+---
+
+## Hierarchical continuous aggregate fails with incompatible bucket width
+
+**URL:** llms-txt#hierarchical-continuous-aggregate-fails-with-incompatible-bucket-width
+
+
+
+If you attempt to create a hierarchical continuous aggregate, you must use
+compatible time buckets. You can't create a continuous aggregate with a
+fixed-width time bucket on top of a continuous aggregate with a variable-width
+time bucket. For more information, see the restrictions section in
+[hierarchical continuous aggregates][h-caggs-restrictions].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/caggs-migrate-permissions/ =====
+
+---
+
+## About data retention with continuous aggregates
+
+**URL:** llms-txt#about-data-retention-with-continuous-aggregates
+
+**Contents:**
+- Data retention on a continuous aggregate itself
+
+You can downsample your data by combining a data retention policy with
+[continuous aggregates][continuous_aggregates]. If you set your refresh policies
+correctly, you can delete old data from a hypertable without deleting it from
+any continuous aggregates. This lets you save on raw data storage while keeping
+summarized data for historical analysis.
+
+To keep your aggregates while dropping raw data, you must be careful about
+refreshing your aggregates. You can delete raw data from the underlying table
+without deleting data from continuous aggregates, so long as you don't refresh
+the aggregate over the deleted data. When you refresh a continuous aggregate,
+TimescaleDB updates the aggregate based on changes in the raw data for the
+refresh window. If it sees that the raw data was deleted, it also deletes the
+aggregate data. To prevent this, make sure that the aggregate's refresh window
+doesn't overlap with any deleted data. For more information, see the following
+example.
+
+As an example, say that you add a continuous aggregate to a `conditions`
+hypertable that stores device temperatures:
+
+This creates a `conditions_summary_daily` aggregate which stores the daily
+temperature per device. The aggregate refreshes every day. Every time it
+refreshes, it updates with any data changes from 7 days ago to 1 day ago.
+
+You should **not** set a 24-hour retention policy on the `conditions`
+hypertable. If you do, chunks older than 1 day are dropped. Then the aggregate
+refreshes based on data changes. Since the data change was to delete data older
+than 1 day, the aggregate also deletes the data. You end up with no data in the
+`conditions_summary_daily` table.
+
+To fix this, set a longer retention policy, for example 30 days:
+
+Now, chunks older than 30 days are dropped. But when the aggregate refreshes, it
+doesn't look for changes older than 30 days. It only looks for changes between 7
+days and 1 day ago. The raw hypertable still contains data for that time period.
+So your aggregate retains the data.
+
+## Data retention on a continuous aggregate itself
+
+You can also apply data retention on a continuous aggregate itself. For example,
+you can keep raw data for 30 days, as mentioned earlier. Meanwhile, you can keep
+daily data for 600 days, and no data beyond that.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/data-retention/about-data-retention/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_summary_daily (day, device, temp)
+WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time), device, avg(temperature)
+ FROM conditions
+ GROUP BY (1, 2);
+
+SELECT add_continuous_aggregate_policy('conditions_summary_daily', '7 days', '1 day', '1 day');
+```
+
+Example 2 (sql):
+```sql
+SELECT add_retention_policy('conditions', INTERVAL '30 days');
+```
+
+---
+
+## Jobs in TimescaleDB
+
+**URL:** llms-txt#jobs-in-timescaledb
+
+TimescaleDB natively includes some job-scheduling policies, such as:
+
+* [Continuous aggregate policies][caggs] to automatically refresh continuous aggregates
+* [Hypercore policies][setup-hypercore] to optimize and compress historical data
+* [Retention policies][retention] to drop historical data
+* [Reordering policies][reordering] to reorder data within chunks
+
+If these don't cover your use case, you can create and schedule custom-defined jobs to run within
+your database. They help you automate periodic tasks that aren't covered by the native policies.
+
+In this section, you see how to:
+
+* [Create and manage jobs][create-jobs]
+* Set up a [generic data retention][generic-retention] policy that applies across all hypertables
+* Implement [automatic moving of chunks between tablespaces][manage-storage]
+* Automatically [downsample and compress][downsample-compress] older chunks
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/security/ =====
+
+---
+
+## Continuous aggregate doesn't refresh with newly inserted historical data
+
+**URL:** llms-txt#continuous-aggregate-doesn't-refresh-with-newly-inserted-historical-data
+
+
+
+Materialized views are generally used with ordered data. If you insert historic
+data, or data that is not related to the current time, you need to refresh
+policies and reevaluate the values that are dragging from past to present.
+
+You can set up an after insert rule for your hypertable or upsert to trigger
+something that can validate what needs to be refreshed as the data is merged.
+
+Let's say you inserted ordered timeframes named A, B, D, and F, and you already
+have a continuous aggregation looking for this data. If you now insert E, you
+need to refresh E and F. However, if you insert C we'll need to refresh C, D, E
+and F.
+
+1. A, B, D, and F are already materialized in a view with all data.
+1. To insert C, split the data into `AB` and `DEF` subsets.
+1. `AB` are consistent and the materialized data is too; you only need to
+ reuse it.
+1. Insert C, `DEF`, and refresh policies after C.
+
+This can use a lot of resources to process, especially if you have any important
+data in the past that also needs to be brought to the present.
+
+Consider an example where you have 300 columns on a single hypertable and use,
+for example, five of them in a continuous aggregation. In this case, it could
+be hard to refresh and would make more sense to isolate these columns in another
+hypertable. Alternatively, you might create one hypertable per metric and
+refresh them independently.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/locf-queries-null-values-not-missing/ =====
+
+---
+
+## Convert continuous aggregates to the columnstore
+
+**URL:** llms-txt#convert-continuous-aggregates-to-the-columnstore
+
+**Contents:**
+- Enable compression on continuous aggregates
+ - Enabling and disabling compression on continuous aggregates
+- Compression policies on continuous aggregates
+
+Continuous aggregates are often used to downsample historical data. If the data is only used for analytical queries
+and never modified, you can compress the aggregate to save on storage.
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by Convert continuous aggregates to the columnstore.
+
+Before version
+[2.18.1](https://github.com/timescale/timescaledb/releases/tag/2.18.1), you can't
+refresh the compressed regions of a continuous aggregate. To avoid conflicts
+between compression and refresh, make sure you set `compress_after` to a larger
+interval than the `start_offset` of your [refresh
+policy](https://docs.tigerdata.com/api/latest/continuous-aggregates/add_continuous_aggregate_policy).
+
+Compression on continuous aggregates works similarly to [compression on
+hypertables][compression]. When compression is enabled and no other options are
+provided, the `segment_by` value will be automatically set to the group by
+columns of the continuous aggregate and the `time_bucket` column will be used as
+the `order_by` column in the compression configuration.
+
+## Enable compression on continuous aggregates
+
+You can enable and disable compression on continuous aggregates by setting the
+`compress` parameter when you alter the view.
+
+### Enabling and disabling compression on continuous aggregates
+
+1. For an existing continuous aggregate, at the `psql` prompt, enable
+ compression:
+
+1. Disable compression:
+
+Disabling compression on a continuous aggregate fails if there are compressed
+chunks associated with the continuous aggregate. In this case, you need to
+decompress the chunks, and then drop any compression policy on the continuous
+aggregate, before you disable compression. For more detailed information, see
+the [decompress chunks][decompress-chunks] section:
+
+## Compression policies on continuous aggregates
+
+Before setting up a compression policy on a continuous aggregate, you should set
+up a [refresh policy][refresh-policy]. The compression policy interval should be
+set so that actively refreshed regions are not compressed. This is to prevent
+refresh policies from failing. For example, consider a refresh policy like this:
+
+With this kind of refresh policy, the compression policy needs the
+`compress_after` parameter greater than the `start_offset` parameter of the
+continuous aggregate policy:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/manual-compression/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER MATERIALIZED VIEW cagg_name set (timescaledb.compress = true);
+```
+
+Example 2 (sql):
+```sql
+ALTER MATERIALIZED VIEW cagg_name set (timescaledb.compress = false);
+```
+
+Example 3 (sql):
+```sql
+SELECT decompress_chunk(c, true) FROM show_chunks('cagg_name') c;
+```
+
+Example 4 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('cagg_name',
+ start_offset => INTERVAL '30 days',
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+---
+
+## Time and continuous aggregates
+
+**URL:** llms-txt#time-and-continuous-aggregates
+
+**Contents:**
+- Declare an explicit timezone
+- Integer-based time
+
+Functions that depend on a local timezone setting inside a continuous aggregate
+are not supported. You cannot adjust to a local time because the timezone setting
+changes from user to user.
+
+To manage this, you can use explicit timezones in the view definition.
+Alternatively, you can create your own custom aggregation scheme for tables that
+use an integer time column.
+
+## Declare an explicit timezone
+
+The most common method of working with timezones is to declare an explicit
+timezone in the view query.
+
+1. At the `psql`prompt, create the view and declare the timezone:
+
+1. Alternatively, you can cast to a timestamp after the view using `SELECT`:
+
+## Integer-based time
+
+Date and time is usually expressed as year-month-day and hours:minutes:seconds.
+Most TimescaleDB databases use a [date/time-type][postgres-date-time] column to
+express the date and time. However, in some cases, you might need to convert
+these common time and date formats to a format that uses an integer. The most
+common integer time is Unix epoch time, which is the number of seconds since the
+Unix epoch of 1970-01-01, but other types of integer-based time formats are
+possible.
+
+These examples use a hypertable called `devices` that contains CPU and disk
+usage information. The devices measure time using the Unix epoch.
+
+To create a hypertable that uses an integer-based column as time, you need to
+provide the chunk time interval. In this case, each chunk is 10 minutes.
+
+1. At the `psql` prompt, create a hypertable and define the integer-based time column and chunk time interval:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+To define a continuous aggregate on a hypertable that uses integer-based time,
+you need to have a function to get the current time in the correct format, and
+set it for the hypertable. You can do this with the
+[`set_integer_now_func`][api-set-integer-now-func]
+function. It can be defined as a regular Postgres function, but needs to be
+[`STABLE`][pg-func-stable],
+take no arguments, and return an integer value of the same type as the time
+column in the table. When you have set up the time-handling, you can create the
+continuous aggregate.
+
+1. At the `psql` prompt, set up a function to convert the time to the Unix epoch:
+
+1. Create the continuous aggregate for the `devices` table:
+
+1. Insert some rows into the table:
+
+This command uses the `tablefunc` extension to generate a normal
+ distribution, and uses the `row_number` function to turn it into a
+ cumulative sequence.
+1. Check that the view contains the correct data:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/materialized-hypertables/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW device_summary
+ WITH (timescaledb.continuous)
+ AS
+ SELECT
+ time_bucket('1 hour', observation_time) AS bucket,
+ min(observation_time AT TIME ZONE 'EST') AS min_time,
+ device_id,
+ avg(metric) AS metric_avg,
+ max(metric) - min(metric) AS metric_spread
+ FROM
+ device_readings
+ GROUP BY bucket, device_id;
+```
+
+Example 2 (sql):
+```sql
+SELECT min_time::timestamp FROM device_summary;
+```
+
+Example 3 (sql):
+```sql
+CREATE TABLE devices(
+ time BIGINT, -- Time in minutes since epoch
+ cpu_usage INTEGER, -- Total CPU usage
+ disk_usage INTEGER, -- Total disk usage
+ PRIMARY KEY (time)
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.chunk_interval='10'
+ );
+```
+
+Example 4 (sql):
+```sql
+CREATE FUNCTION current_epoch() RETURNS BIGINT
+ LANGUAGE SQL STABLE AS $$
+ SELECT EXTRACT(EPOCH FROM CURRENT_TIMESTAMP)::bigint;$$;
+
+ SELECT set_integer_now_func('devices', 'current_epoch');
+```
+
+---
+
+## Create an index on a continuous aggregate
+
+**URL:** llms-txt#create-an-index-on-a-continuous-aggregate
+
+**Contents:**
+- Automatically created indexes
+ - Turn off automatic index creation
+- Manually create and drop indexes
+ - Limitations on created indexes
+
+By default, some indexes are automatically created when you create a continuous
+aggregate. You can change this behavior. You can also manually create and drop
+indexes.
+
+## Automatically created indexes
+
+When you create a continuous aggregate, an index is automatically created for
+each `GROUP BY` column. The index is a composite index, combining the `GROUP BY`
+column with the `time_bucket` column.
+
+For example, if you define a continuous aggregate view with `GROUP BY device,
+location, bucket`, two composite indexes are created: one on `{device, bucket}`
+and one on `{location, bucket}`.
+
+### Turn off automatic index creation
+
+To turn off automatic index creation, set `timescaledb.create_group_indexes` to
+`false` when you create the continuous aggregate.
+
+## Manually create and drop indexes
+
+You can use a regular Postgres statement to create or drop an index on a
+continuous aggregate.
+
+For example, to create an index on `avg_temp` for a materialized hypertable
+named `weather_daily`:
+
+Indexes are created under the `_timescaledb_internal` schema, where the
+continuous aggregate data is stored. To drop the index, specify the schema. For
+example, to drop the index `avg_temp_idx`, run:
+
+### Limitations on created indexes
+
+In TimescaleDB v2.7 and later, you can create an index on any column in the
+materialized view. This includes aggregated columns, such as those storing sums
+and averages. In earlier versions of TimescaleDB, you can't create an index on
+an aggregated column.
+
+You can't create unique indexes on a continuous aggregate, in any of the
+TimescaleDB versions.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/about-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_daily
+ WITH (timescaledb.continuous, timescaledb.create_group_indexes=false)
+ AS
+ ...
+```
+
+Example 2 (sql):
+```sql
+CREATE INDEX avg_temp_idx ON weather_daily (avg_temp);
+```
+
+Example 3 (sql):
+```sql
+DROP INDEX _timescaledb_internal.avg_temp_idx
+```
+
+---
+
+## ALTER MATERIALIZED VIEW (Continuous Aggregate)
+
+**URL:** llms-txt#alter-materialized-view-(continuous-aggregate)
+
+**Contents:**
+- Samples
+- Arguments
+
+You use the `ALTER MATERIALIZED VIEW` statement to modify some of the `WITH`
+clause [options][create_materialized_view] for a continuous aggregate view. You can only set the `continuous` and `create_group_indexes` options when you [create a continuous aggregate][create_materialized_view]. `ALTER MATERIALIZED VIEW` also supports the following
+[Postgres clauses][postgres-alterview] on the continuous aggregate view:
+
+* `RENAME TO`: rename the continuous aggregate view
+* `RENAME [COLUMN]`: rename the continuous aggregate column
+* `SET SCHEMA`: set the new schema for the continuous aggregate view
+* `SET TABLESPACE`: move the materialization of the continuous aggregate view to the new tablespace
+* `OWNER TO`: set a new owner for the continuous aggregate view
+
+- Enable real-time aggregates for a continuous aggregate:
+
+- Enable hypercore for a continuous aggregate Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0):
+
+- Rename a column for a continuous aggregate:
+
+| Name | Type | Default | Required | Description |
+|---------------------------------------------------------------------------|-----------|------------------------------------------------------|----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `view_name` | TEXT | - | ✖ | The name of the continuous aggregate view to be altered. |
+| `timescaledb.materialized_only` | BOOLEAN | `true` | ✖ | Enable real-time aggregation. |
+| `timescaledb.enable_columnstore` | BOOLEAN | `true` | ✖ | Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Enable columnstore. Effectively the same as `timescaledb.compress`. |
+| `timescaledb.compress` | TEXT | Disabled. | ✖ | Enable compression. |
+| `timescaledb.orderby` | TEXT | Descending order on the time column in `table_name`. | ✖ | Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Set the order in which items are used in the columnstore. Specified in the same way as an `ORDER BY` clause in a `SELECT` query. |
+| `timescaledb.compress_orderby` | TEXT | Descending order on the time column in `table_name`. | ✖ | Set the order used by compression. Specified in the same way as the `ORDER BY` clause in a `SELECT` query. |
+| `timescaledb.segmentby` | TEXT | No segementation by column. | ✖ | Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Set the list of columns used to segment data in the columnstore for `table`. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
+| `timescaledb.compress_segmentby` | TEXT | No segementation by column. | ✖ | Set the list of columns used to segment the compressed data. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
+| `column_name` | TEXT | - | ✖ | Set the name of the column to order by or segment by. |
+| `timescaledb.compress_chunk_time_interval` | TEXT | - | ✖ | Reduce the total number of compressed/columnstore chunks for `table`. If you set `compress_chunk_time_interval`, compressed/columnstore chunks are merged with the previous adjacent chunk within `chunk_time_interval` whenever possible. These chunks are irreversibly merged. If you call to [decompress][decompress]/[convert_to_rowstore][convert_to_rowstore], merged chunks are not split up. You can call `compress_chunk_time_interval` independently of other compression settings; `timescaledb.compress`/`timescaledb.enable_columnstore` is not required. |
+| `timescaledb.enable_cagg_window_functions` | BOOLEAN | `false` | ✖ | EXPERIMENTAL: enable window functions on continuous aggregates. Support is experimental, as there is a risk of data inconsistency. For example, in backfill scenarios, buckets could be missed. |
+| `timescaledb.chunk_interval` (formerly `timescaledb.chunk_time_interval`) | INTERVAL | 10x the original hypertable. | ✖ | Set the chunk interval. Renamed in TimescaleDB V2.20. |
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/cagg_migrate/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER MATERIALIZED VIEW contagg_view SET (timescaledb.materialized_only = false);
+```
+
+Example 2 (sql):
+```sql
+ALTER MATERIALIZED VIEW contagg_view SET (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol' );
+```
+
+Example 3 (sql):
+```sql
+ALTER MATERIALIZED VIEW contagg_view RENAME COLUMN old_name TO new_name;
+```
+
+---
+
+## cagg_migrate()
+
+**URL:** llms-txt#cagg_migrate()
+
+**Contents:**
+- Required arguments
+- Optional arguments
+
+Migrate a continuous aggregate from the old format to the new format introduced
+in TimescaleDB 2.7.
+
+TimescaleDB 2.7 introduced a new format for continuous aggregates that improves
+performance. It also makes continuous aggregates compatible with more types of
+SQL queries.
+
+The new format, also called the finalized format, stores the continuous
+aggregate data exactly as it appears in the final view. The old format, also
+called the partial format, stores the data in a partially aggregated state.
+
+Use this procedure to migrate continuous aggregates from the old format to the
+new format.
+
+For more information, see the [migration how-to guide][how-to-migrate].
+
+There are known issues with `cagg_migrate()` in version TimescaleDB 2.8.0.
+Upgrade to version 2.8.1 or above before using it.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`cagg`|`REGCLASS`|The continuous aggregate to migrate|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`override`|`BOOLEAN`|If false, the old continuous aggregate keeps its name. The new continuous aggregate is named `_new`. If true, the new continuous aggregate gets the old name. The old continuous aggregate is renamed `_old`. Defaults to `false`.|
+|`drop_old`|`BOOLEAN`|If true, the old continuous aggregate is deleted. Must be used together with `override`. Defaults to `false`.|
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/drop_materialized_view/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL cagg_migrate (
+ cagg REGCLASS,
+ override BOOLEAN DEFAULT FALSE,
+ drop_old BOOLEAN DEFAULT FALSE
+);
+```
+
+---
+
+## Dropping data
+
+**URL:** llms-txt#dropping-data
+
+**Contents:**
+- Drop a continuous aggregate view
+ - Dropping a continuous aggregate view
+- Drop raw data from a hypertable
+- PolicyVisualizerDownsampling
+
+When you are working with continuous aggregates, you can drop a view, or you can
+drop raw data from the underlying hypertable or from the continuous aggregate
+itself. A combination of [refresh][cagg-refresh] and data retention policies
+can help you downsample your data. This lets you keep historical data at a
+lower granularity than recent data.
+
+However, you should be aware if a retention policy is likely to drop raw data
+from your hypertable that you need in your continuous aggregate.
+
+To simplify the process of setting up downsampling, you can use
+the [visualizer and code generator][visualizer].
+
+## Drop a continuous aggregate view
+
+You can drop a continuous aggregate view using the `DROP MATERIALIZED VIEW`
+command. This command also removes refresh policies defined on the continuous
+aggregate. It does not drop the data from the underlying hypertable.
+
+### Dropping a continuous aggregate view
+
+1. From the `psql`prompt, drop the view:
+
+## Drop raw data from a hypertable
+
+If you drop data from a hypertable used in a continuous aggregate it can lead to
+problems with your continuous aggregate view. In many cases, dropping underlying
+data replaces the aggregate with NULL values, which can lead to unexpected
+results in your view.
+
+You can drop data from a hypertable using `drop_chunks` in the usual way, but
+before you do so, always check that the chunk is not within the refresh window
+of a continuous aggregate that still needs the data. This is also important if
+you are manually refreshing a continuous aggregate. Calling
+`refresh_continuous_aggregate` on a region containing dropped chunks
+recalculates the aggregate without the dropped data.
+
+If a continuous aggregate is refreshing when data is dropped because of a
+retention policy, the aggregate is updated to reflect the loss of data. If you
+need to retain the continuous aggregate after dropping the underlying data, set
+the `start_offset` value of the aggregate policy to a smaller interval than the
+`drop_after` parameter of the retention policy.
+
+For more information, see the
+[data retention documentation][data-retention-with-continuous-aggregates].
+
+## PolicyVisualizerDownsampling
+
+Refer to the installation documentation for detailed setup instructions.
+
+[data-retention-with-continuous-aggregates]:
+ /use-timescale/:currentVersion:/data-retention/data-retention-with-continuous-aggregates
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/migrate/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+DROP MATERIALIZED VIEW view_name;
+```
+
+---
+
+## Continuous aggregates on continuous aggregates
+
+**URL:** llms-txt#continuous-aggregates-on-continuous-aggregates
+
+**Contents:**
+- Create a continuous aggregate on top of another continuous aggregate
+- Use real-time aggregation with hierarchical continuous aggregates
+- Roll up calculations
+- Restrictions
+
+The more data you have, the more likely you are to run a more sophisticated analysis on it. When a simple one-level aggregation is not enough, TimescaleDB lets you create continuous aggregates on top of other continuous aggregates. This way, you summarize data at different levels of granularity, while still saving resources with precomputing.
+
+For example, you might have an hourly continuous aggregate that summarizes minute-by-minute
+data. To get a daily summary, you can create a new continuous aggregate on top
+of your hourly aggregate. This is more efficient than creating the daily
+aggregate on top of the original hypertable, because you can reuse the
+calculations from the hourly aggregate.
+
+This feature is available in TimescaleDB v2.9 and later.
+
+## Create a continuous aggregate on top of another continuous aggregate
+
+Creating a continuous aggregate on top of another continuous aggregate works the
+same way as creating it on top of a hypertable. In your query, select from a
+continuous aggregate rather than from the hypertable, and use the time-bucketed
+column from the existing continuous aggregate as your time column.
+
+For more information, see the instructions for
+[creating a continuous aggregate][create-cagg].
+
+## Use real-time aggregation with hierarchical continuous aggregates
+
+In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+Real-time aggregates always return up-to-date data in response to queries. They accomplish this by
+joining the materialized data in the continuous aggregate with unmaterialized
+raw data from the source table or view.
+
+When continuous aggregates are stacked, each continuous aggregate is only aware
+of the layer immediately below. The joining of unmaterialized data happens
+recursively until it reaches the bottom layer, giving you access to recent data
+down to that layer.
+
+If you keep all continuous aggregates in the stack as real-time aggregates, the
+bottom layer is the source hypertable. That means every continuous aggregate in
+the stack has access to all recent data.
+
+If there is a non-real-time continuous aggregate somewhere in the stack, the
+recursive joining stops at that non-real-time continuous aggregate. Higher-level
+continuous aggregates don't receive any unmaterialized data from lower levels.
+
+For example, say you have the following continuous aggregates:
+
+* A real-time hourly continuous aggregate on the source hypertable
+* A real-time daily continuous aggregate on the hourly continuous aggregate
+* A non-real-time, or materialized-only, monthly continuous aggregate on the
+ daily continuous aggregate
+* A real-time yearly continuous aggregate on the monthly continuous aggregate
+
+Queries on the hourly and daily continuous aggregates include real-time,
+non-materialized data from the source hypertable. Queries on the monthly
+continuous aggregate only return already-materialized data. Queries on the
+yearly continuous aggregate return materialized data from the yearly continuous
+aggregate itself, plus more recent data from the monthly continuous aggregate.
+However, the data is limited to what is already materialized in the monthly
+continuous aggregate, and doesn't get even more recent data from the source
+hypertable. This happens because the materialized-only continuous aggregate
+provides a stopping point, and the yearly continuous aggregate is unaware of any
+layers beyond that stopping point. This is similar to
+[how stacked views work in Postgres][postgresql-views].
+
+To make queries on the yearly continuous aggregate access all recent data, you
+can either:
+
+* Make the monthly continuous aggregate real-time, or
+* Redefine the yearly continuous aggregate on top of the daily continuous
+ aggregate.
+
+ +
+## Roll up calculations
+
+When summarizing already-summarized data, be aware of how stacked calculations
+work. Not all calculations return the correct result if you stack them.
+
+For example, if you take the maximum of several subsets, then take the maximum
+of the maximums, you get the maximum of the entire set. But if you take the
+average of several subsets, then take the average of the averages, that can
+result in a different figure than the average of all the data.
+
+To simplify such calculations when using continuous aggregates on top of
+continuous aggregates, you can use the [hyperfunctions][hyperfunctions] from
+TimescaleDB Toolkit, such as the [statistical aggregates][stats-aggs]. These
+hyperfunctions are designed with a two-step aggregation pattern that allows you
+to roll them up into larger buckets. The first step creates a summary aggregate
+that can be rolled up, just as a maximum can be rolled up. You can store this
+aggregate in your continuous aggregate. Then, you can call an accessor function
+as a second step when you query from your continuous aggregate. This accessor
+takes the stored data from the summary aggregate and returns the final result.
+
+For example, you can create an hourly continuous aggregate using `percentile_agg`
+over a hypertable, like this:
+
+To then stack another daily continuous aggregate over it, you can use a `rollup`
+function, like this:
+
+The `mean` function of the TimescaleDB Toolkit is used to calculate the concrete
+mean value of the rolled up values. The additional `percentile_daily` attribute
+contains the raw rolled up values, which can be used in an additional continuous
+aggregate on top of this continuous aggregate (for example a continuous
+aggregate for the daily values).
+
+For more information and examples about using `rollup` functions to stack
+calculations, see the [percentile approximation API documentation][percentile_agg_api].
+
+There are some restrictions when creating a continuous aggregate on top of
+another continuous aggregate. In most cases, these restrictions are in place to
+ensure valid time-bucketing:
+
+* You can only create a continuous aggregate on top of a finalized continuous
+ aggregate. This new finalized format is the default for all continuous
+ aggregates created since TimescaleDB 2.7. If you need to create a continuous
+ aggregate on top of a continuous aggregate in the old format, you need to
+ [migrate your continuous aggregate][migrate-cagg] to the new format first.
+
+* The time bucket of a continuous aggregate should be greater than or equal to
+ the time bucket of the underlying continuous aggregate. It also needs to be
+ a multiple of the underlying time bucket. For example, you can rebucket an
+ hourly continuous aggregate into a new continuous aggregate with time
+ buckets of 6 hours. You can't rebucket the hourly continuous aggregate into
+ a new continuous aggregate with time buckets of 90 minutes, because 90
+ minutes is not a multiple of 1 hour.
+
+* A continuous aggregate with a fixed-width time bucket can't be created on
+ top of a continuous aggregate with a variable-width time bucket. Fixed-width
+ time buckets are time buckets defined in seconds, minutes, hours, and days,
+ because those time intervals are always the same length. Variable-width time
+ buckets are time buckets defined in months or years, because those time
+ intervals vary by the month or on leap years. This limitation prevents a
+ case such as trying to rebucket monthly buckets into `61 day` buckets, where
+ there is no good mapping between time buckets for month combinations such as
+ July/August (62 days).
+
+Note that even though weeks are fixed-width intervals, you can't use monthly
+ or yearly time buckets on top of weekly time buckets for the same reason.
+ The number of weeks in a month or year is usually not an integer.
+
+However, you can stack a variable-width time bucket on top of a fixed-width
+ time bucket. For example, creating a monthly continuous aggregate on top of
+ a daily continuous aggregate works, and is the one of the main use cases for
+ this feature.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypercore/secondary-indexes/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_hourly
+WITH (timescaledb.continuous)
+AS SELECT
+ time_bucket('1 h'::interval, ts) as bucket,
+ api_id,
+ avg(response_time_ms),
+ percentile_agg(response_time_ms) as percentile_hourly
+FROM response_times
+GROUP BY 1, 2;
+```
+
+Example 2 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_daily
+WITH (timescaledb.continuous)
+AS SELECT
+ time_bucket('1 d'::interval, bucket) as bucket_daily,
+ api_id,
+ mean(rollup(percentile_hourly)) as mean,
+ rollup(percentile_hourly) as percentile_daily
+FROM response_times_hourly
+GROUP BY 1, 2;
+```
+
+---
+
+## Continuous aggregate watermark is in the future
+
+**URL:** llms-txt#continuous-aggregate-watermark-is-in-the-future
+
+**Contents:**
+ - Creating a new continuous aggregate with an explicit refresh window
+
+
+
+Continuous aggregates use a watermark to indicate which time buckets have
+already been materialized. When you query a continuous aggregate, your query
+returns materialized data from before the watermark. It returns real-time,
+non-materialized data from after the watermark.
+
+In certain cases, the watermark might be in the future. If this happens, all
+buckets, including the most recent bucket, are materialized and below the
+watermark. No real-time data is returned.
+
+This might happen if you refresh your continuous aggregate over the time window
+`, NULL`, which materializes all recent data. It might also happen
+if you create a continuous aggregate using the `WITH DATA` option. This also
+implicitly refreshes your continuous aggregate with a window of `NULL, NULL`.
+
+To fix this, create a new continuous aggregate using the `WITH NO DATA` option.
+Then use a policy to refresh this continuous aggregate over an explicit time
+window.
+
+### Creating a new continuous aggregate with an explicit refresh window
+
+1. Create a continuous aggregate using the `WITH NO DATA` option:
+
+1. Refresh the continuous aggregate using a policy with an explicit
+ `end_offset`. For example:
+
+1. Check your new continuous aggregate's watermark to make sure it is in the
+ past, not the future.
+
+Get the ID for the materialization hypertable that contains the actual
+ continuous aggregate data:
+
+1. Use the returned ID to query for the watermark's timestamp:
+
+For TimescaleDB >= 2.12:
+
+For TimescaleDB < 2.12:
+
+If you choose to delete your old continuous aggregate after creating a new one,
+beware of historical data loss. If your old continuous aggregate contained data
+that you dropped from your original hypertable, for example through a data
+retention policy, the dropped data is not included in your new continuous
+aggregate.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/scheduled-jobs-stop-running/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW
+ WITH (timescaledb.continuous)
+ AS SELECT time_bucket('', ),
+ ,
+ ...
+ FROM
+ GROUP BY bucket,
+ WITH NO DATA;
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('',
+ start_offset => INTERVAL '30 day',
+ end_offset => INTERVAL '1 hour',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+Example 3 (sql):
+```sql
+SELECT id FROM _timescaledb_catalog.hypertable
+ WHERE table_name=(
+ SELECT materialization_hypertable_name
+ FROM timescaledb_information.continuous_aggregates
+ WHERE view_name=''
+ );
+```
+
+Example 4 (sql):
+```sql
+SELECT COALESCE(
+ _timescaledb_functions.to_timestamp(_timescaledb_functions.cagg_watermark()),
+ '-infinity'::timestamp with time zone
+ );
+```
+
+---
+
+## About continuous aggregates
+
+**URL:** llms-txt#about-continuous-aggregates
+
+**Contents:**
+- Types of aggregation
+- Continuous aggregates on continuous aggregates
+- Continuous aggregates with a `JOIN` clause
+ - JOIN examples
+- Function support
+- Components of a continuous aggregate
+ - Materialization hypertable
+ - Materialization engine
+ - Invalidation engine
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+## Types of aggregation
+
+There are three main ways to make aggregation easier: materialized views,
+continuous aggregates, and real-time aggregates.
+
+[Materialized views][pg-materialized views] are a standard Postgres function.
+They are used to cache the result of a complex query so that you can reuse it
+later on. Materialized views do not update regularly, although you can manually
+refresh them as required.
+
+[Continuous aggregates][about-caggs] are a TimescaleDB-only feature. They work in
+a similar way to a materialized view, but they are updated automatically in the
+background, as new data is added to your database. Continuous aggregates are
+updated continuously and incrementally, which means they are less resource
+intensive to maintain than materialized views. Continuous aggregates are based
+on hypertables, and you can query them in the same way as you do your other
+tables.
+
+[Real-time aggregates][real-time-aggs] are a TimescaleDB-only feature. They are
+the same as continuous aggregates, but they add the most recent raw data to the
+previously aggregated data to provide accurate and up-to-date results, without
+needing to aggregate data as it is being written.
+
+## Continuous aggregates on continuous aggregates
+
+You can create a continuous aggregate on top of another continuous aggregate.
+This allows you to summarize data at different granularity. For example, you
+might have a raw hypertable that contains second-by-second data. Create a
+continuous aggregate on the hypertable to calculate hourly data. To calculate
+daily data, create a continuous aggregate on top of your hourly continuous
+aggregate.
+
+For more information, see the documentation about
+[continuous aggregates on continuous aggregates][caggs-on-caggs].
+
+## Continuous aggregates with a `JOIN` clause
+
+Continuous aggregates support the following JOIN features:
+
+| Feature | TimescaleDB < 2.10.x | TimescaleDB <= 2.15.x | TimescaleDB >= 2.16.x|
+|-|-|-|-|
+|INNER JOIN|❌|✅|✅|
+|LEFT JOIN|❌|❌|✅|
+|LATERAL JOIN|❌|❌|✅|
+|Joins between **ONE** hypertable and **ONE** standard Postgres table|❌|✅|✅|
+|Joins between **ONE** hypertable and **MANY** standard Postgres tables|❌|❌|✅|
+|Join conditions must be equality conditions, and there can only be **ONE** `JOIN` condition|❌|✅|✅|
+|Any join conditions|❌|❌|✅|
+
+JOINS in TimescaleDB must meet the following conditions:
+
+* Only the changes to the hypertable are tracked, and they are updated in the
+ continuous aggregate when it is refreshed. Changes to standard
+ Postgres table are not tracked.
+* You can use an `INNER`, `LEFT`, and `LATERAL` joins; no other join type is supported.
+* Joins on the materialized hypertable of a continuous aggregate are not supported.
+* Hierarchical continuous aggregates can be created on top of a continuous
+ aggregate with a `JOIN` clause, but cannot themselves have a `JOIN` clause.
+
+Given the following schema:
+
+See the following `JOIN` examples on continuous aggregates:
+
+- `INNER JOIN` on a single equality condition, using the `ON` clause:
+
+- `INNER JOIN` on a single equality condition, using the `ON` clause, with a further condition added in the `WHERE` clause:
+
+- `INNER JOIN` on a single equality condition specified in `WHERE` clause:
+
+- `INNER JOIN` on multiple equality conditions:
+
+TimescaleDB v2.16.x and higher.
+
+- `INNER JOIN` with a single equality condition specified in `WHERE` clause can be combined with further conditions in the `WHERE` clause:
+
+TimescaleDB v2.16.x and higher.
+
+- `INNER JOIN` between a hypertable and multiple Postgres tables:
+
+TimescaleDB v2.16.x and higher.
+
+- `LEFT JOIN` between a hypertable and a Postgres table:
+
+TimescaleDB v2.16.x and higher.
+
+- `LATERAL JOIN` between a hypertable and a subquery:
+
+TimescaleDB v2.16.x and higher.
+
+In TimescaleDB v2.7 and later, continuous aggregates support all Postgres
+aggregate functions. This includes both parallelizable aggregates, such as `SUM`
+and `AVG`, and non-parallelizable aggregates, such as `RANK`.
+
+In TimescaleDB v2.10.0 and later, the `FROM` clause supports `JOINS`, with
+some restrictions. For more information, see the [`JOIN` support section][caggs-joins].
+
+In older versions of TimescaleDB, continuous aggregates only support
+[aggregate functions that can be parallelized by Postgres][postgres-parallel-agg].
+You can work around this by aggregating the other parts of your query in the
+continuous aggregate, then
+[using the window function to query the aggregate][cagg-window-functions].
+
+The following table summarizes the aggregate functions supported in continuous aggregates:
+
+| Function, clause, or feature |TimescaleDB 2.6 and earlier|TimescaleDB 2.7, 2.8, and 2.9|TimescaleDB 2.10 and later|
+|------------------------------------------------------------|-|-|-|
+| Parallelizable aggregate functions |✅|✅|✅|
+| [Non-parallelizable SQL aggregates][postgres-parallel-agg] |❌|✅|✅|
+| `ORDER BY` |❌|✅|✅|
+| Ordered-set aggregates |❌|✅|✅|
+| Hypothetical-set aggregates |❌|✅|✅|
+| `DISTINCT` in aggregate functions |❌|✅|✅|
+| `FILTER` in aggregate functions |❌|✅|✅|
+| `FROM` clause supports `JOINS` |❌|❌|✅|
+
+DISTINCT works in aggregate functions, not in the query definition. For example, for the table:
+
+- The following works:
+
+- This does not:
+
+If you want the old behavior in later versions of TimescaleDB, set the
+`timescaledb.finalized` parameter to `false` when you create your continuous
+aggregate.
+
+## Components of a continuous aggregate
+
+Continuous aggregates consist of:
+
+* Materialization hypertable to store the aggregated data in
+* Materialization engine to aggregate data from the raw, underlying, table to
+ the materialization hypertable
+* Invalidation engine to determine when data needs to be re-materialized, due
+ to changes in the data
+* Query engine to access the aggregated data
+
+### Materialization hypertable
+
+Continuous aggregates take raw data from the original hypertable, aggregate it,
+and store the aggregated data in a materialization hypertable. When you query
+the continuous aggregate view, the aggregated data is returned to you as needed.
+
+Using the same temperature example, the materialization table looks like this:
+
+|day|location|chunk|avg temperature|
+|-|-|-|-|
+|2021/01/01|New York|1|73|
+|2021/01/01|Stockholm|1|70|
+|2021/01/02|New York|2||
+|2021/01/02|Stockholm|2|69|
+
+The materialization table is stored as a TimescaleDB hypertable, to take
+advantage of the scaling and query optimizations that hypertables offer.
+Materialization tables contain a column for each group-by clause in the query,
+and an `aggregate` column for each aggregate in the query.
+
+For more information, see [materialization hypertables][cagg-mat-hypertables].
+
+### Materialization engine
+
+The materialization engine performs two transactions. The first transaction
+blocks all INSERTs, UPDATEs, and DELETEs, determines the time range to
+materialize, and updates the invalidation threshold. The second transaction
+unblocks other transactions, and materializes the aggregates. The first
+transaction is very quick, and most of the work happens during the second
+transaction, to ensure that the work does not interfere with other operations.
+
+### Invalidation engine
+
+Any change to the data in a hypertable could potentially invalidate some
+materialized rows. The invalidation engine checks to ensure that the system does
+not become swamped with invalidations.
+
+Fortunately, time-series data means that nearly all INSERTs and UPDATEs have a
+recent timestamp, so the invalidation engine does not materialize all the data,
+but to a set point in time called the materialization threshold. This threshold
+is set so that the vast majority of INSERTs contain more recent timestamps.
+These data points have never been materialized by the continuous aggregate, so
+there is no additional work needed to notify the continuous aggregate that they
+have been added. When the materializer next runs, it is responsible for
+determining how much new data can be materialized without invalidating the
+continuous aggregate. It then materializes the more recent data and moves the
+materialization threshold forward in time. This ensures that the threshold lags
+behind the point-in-time where data changes are common, and that most INSERTs do
+not require any extra writes.
+
+When data older than the invalidation threshold is changed, the maximum and
+minimum timestamps of the changed rows is logged, and the values are used to
+determine which rows in the aggregation table need to be recalculated. This
+logging does cause some write load, but because the threshold lags behind the
+area of data that is currently changing, the writes are small and rare.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/time/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE locations (
+ id TEXT PRIMARY KEY,
+ name TEXT
+);
+
+CREATE TABLE devices (
+ id SERIAL PRIMARY KEY,
+ location_id TEXT,
+ name TEXT
+);
+
+CREATE TABLE conditions (
+ "time" TIMESTAMPTZ,
+ device_id INTEGER,
+ temperature FLOAT8
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+```
+
+Example 2 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions
+ JOIN devices ON devices.id = conditions.device_id
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+Example 3 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions
+ JOIN devices ON devices.id = conditions.device_id
+ WHERE devices.location_id = 'location123'
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+Example 4 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions, devices
+ WHERE devices.id = conditions.device_id
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+---
+
+## Continuous aggregates
+
+**URL:** llms-txt#continuous-aggregates
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+For more information about using continuous aggregates, see the documentation in [Use Tiger Data products][cagg-docs].
+
+===== PAGE: https://docs.tigerdata.com/api/data-retention/ =====
+
+---
+
+## refresh_continuous_aggregate()
+
+**URL:** llms-txt#refresh_continuous_aggregate()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Refresh all buckets of a continuous aggregate in the refresh window given by
+`window_start` and `window_end`.
+
+A continuous aggregate materializes aggregates in time buckets. For example,
+min, max, average over 1 day worth of data, and is determined by the `time_bucket`
+interval. Therefore, when
+refreshing the continuous aggregate, only buckets that completely fit within the
+refresh window are refreshed. In other words, it is not possible to compute the
+aggregate over, for an incomplete bucket. Therefore, any buckets that do not
+fit within the given refresh window are excluded.
+
+The function expects the window parameter values to have a time type that is
+compatible with the continuous aggregate's time bucket expression—for
+example, if the time bucket is specified in `TIMESTAMP WITH TIME ZONE`, then the
+start and end time should be a date or timestamp type. Note that a continuous
+aggregate using the `TIMESTAMP WITH TIME ZONE` type aligns with the UTC time
+zone, so, if `window_start` and `window_end` is specified in the local time
+zone, any time zone shift relative UTC needs to be accounted for when refreshing
+to align with bucket boundaries.
+
+To improve performance for continuous aggregate refresh, see
+[CREATE MATERIALIZED VIEW ][create_materialized_view].
+
+Refresh the continuous aggregate `conditions` between `2020-01-01` and
+`2020-02-01` exclusive.
+
+Alternatively, incrementally refresh the continuous aggregate `conditions`
+between `2020-01-01` and `2020-02-01` exclusive, working in `12h` intervals:
+
+Force the `conditions` continuous aggregate to refresh between `2020-01-01` and
+`2020-02-01` exclusive, even if the data has already been refreshed.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`continuous_aggregate`|REGCLASS|The continuous aggregate to refresh.|
+|`window_start`|INTERVAL, TIMESTAMPTZ, INTEGER|Start of the window to refresh, has to be before `window_end`.|
+|`window_end`|INTERVAL, TIMESTAMPTZ, INTEGER|End of the window to refresh, has to be after `window_start`.|
+
+You must specify the `window_start` and `window_end` parameters differently,
+depending on the type of the time column of the hypertable. For hypertables with
+`TIMESTAMP`, `TIMESTAMPTZ`, and `DATE` time columns, set the refresh window as
+an `INTERVAL` type. For hypertables with integer-based timestamps, set the
+refresh window as an `INTEGER` type.
+
+A `NULL` value for `window_start` is equivalent to the lowest changed element
+in the raw hypertable of the CAgg. A `NULL` value for `window_end` is
+equivalent to the largest changed element in raw hypertable of the CAgg. As
+changed element tracking is performed after the initial CAgg refresh, running
+CAgg refresh without `window_start` and `window_end` covers the entire time
+range.
+
+Note that it's not guaranteed that all buckets will be updated: refreshes will
+not take place when buckets are materialized with no data changes or with
+changes that only occurred in the secondary table used in the JOIN.
+
+## Optional arguments
+
+|Name|Type| Description |
+|-|-|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `force` | BOOLEAN | Force refresh every bucket in the time range between `window_start` and `window_end`, even when the bucket has already been refreshed. This can be very expensive when a lot of data is refreshed. Default is `FALSE`. |
+| `refresh_newest_first` | BOOLEAN | Set to `FALSE` to refresh the oldest data first. Default is `TRUE`. |
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/remove_policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL refresh_continuous_aggregate('conditions', '2020-01-01', '2020-02-01');
+```
+
+Example 2 (sql):
+```sql
+DO
+$$
+DECLARE
+ refresh_interval INTERVAL = '12h'::INTERVAL;
+ start_timestamp TIMESTAMPTZ = '2020-01-01T00:00:00Z';
+ end_timestamp TIMESTAMPTZ = start_timestamp + refresh_interval;
+BEGIN
+ WHILE start_timestamp < '2020-02-01T00:00:00Z' LOOP
+ CALL refresh_continuous_aggregate('conditions', start_timestamp, end_timestamp);
+ COMMIT;
+ RAISE NOTICE 'finished with timestamp %', end_timestamp;
+ start_timestamp = end_timestamp;
+ end_timestamp = end_timestamp + refresh_interval;
+ END LOOP;
+END
+$$;
+```
+
+Example 3 (sql):
+```sql
+CALL refresh_continuous_aggregate('conditions', '2020-01-01', '2020-02-01', force => TRUE);
+```
+
+---
+
+## DROP MATERIALIZED VIEW (Continuous Aggregate)
+
+**URL:** llms-txt#drop-materialized-view-(continuous-aggregate)
+
+**Contents:**
+- Samples
+- Parameters
+
+Continuous aggregate views can be dropped using the `DROP MATERIALIZED VIEW` statement.
+
+This statement deletes the continuous aggregate and all its internal
+objects. It also removes refresh policies for that
+aggregate. To delete other dependent objects, such as a view
+defined on the continuous aggregate, add the `CASCADE`
+option. Dropping a continuous aggregate does not affect the data in
+the underlying hypertable from which the continuous aggregate is
+derived.
+
+Drop existing continuous aggregate.
+
+|Name|Type|Description|
+|---|---|---|
+| `` | TEXT | Name (optionally schema-qualified) of continuous aggregate view to be dropped.|
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/remove_all_policies/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+## Samples
+
+Drop existing continuous aggregate.
+```
+
+---
+
+## Migrate a continuous aggregate to the new form
+
+**URL:** llms-txt#migrate-a-continuous-aggregate-to-the-new-form
+
+**Contents:**
+- Configure continuous aggregate migration
+- Check on continuous aggregate migration status
+- Troubleshooting
+ - Permissions error when migrating a continuous aggregate
+
+In TimescaleDB v2.7 and later, continuous aggregates use a new format that
+improves performance and makes them compatible with more SQL queries. Continuous
+aggregates created in older versions of TimescaleDB, or created in a new version
+with the option `timescaledb.finalized` set to `false`, use the old format.
+
+To migrate a continuous aggregate from the old format to the new format, you can
+use this procedure. It automatically copies over your data and policies. You can
+continue to use the continuous aggregate while the migration is happening.
+
+Connect to your database and run:
+
+There are known issues with `cagg_migrate()` in version 2.8.0.
+Upgrade to version 2.8.1 or later before using it.
+
+## Configure continuous aggregate migration
+
+The migration procedure provides two boolean configuration parameters,
+`override` and `drop_old`. By default, the name of your new continuous
+aggregate is the name of your old continuous aggregate, with the suffix `_new`.
+
+Set `override` to true to rename your new continuous aggregate with the
+original name. The old continuous aggregate is renamed with the suffix `_old`.
+
+To both rename and drop the old continuous aggregate entirely, set both
+parameters to true. Note that `drop_old` must be used together with
+`override`.
+
+## Check on continuous aggregate migration status
+
+To check the progress of the continuous aggregate migration, query the migration
+planning table:
+
+### Permissions error when migrating a continuous aggregate
+
+You might get a permissions error when migrating a continuous aggregate from old
+to new format using `cagg_migrate`. The user performing the migration must have
+the following permissions:
+
+* Select, insert, and update permissions on the tables
+ `_timescale_catalog.continuous_agg_migrate_plan` and
+ `_timescale_catalog.continuous_agg_migrate_plan_step`
+* Usage permissions on the sequence
+ `_timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq`
+
+To solve the problem, change to a user capable of granting permissions, and
+grant the following permissions to the user performing the migration:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/compression-on-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL cagg_migrate('');
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM _timescaledb_catalog.continuous_agg_migrate_plan_step;
+```
+
+Example 3 (sql):
+```sql
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan TO ;
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan_step TO ;
+GRANT USAGE ON SEQUENCE _timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq TO ;
+```
+
+---
+
+## Refresh continuous aggregates
+
+**URL:** llms-txt#refresh-continuous-aggregates
+
+**Contents:**
+- Prerequisites
+- Change the refresh policy
+- Add concurrent refresh policies
+- Manually refresh a continuous aggregate
+
+Continuous aggregates can have a range of different refresh policies. In
+addition to refreshing the continuous aggregate automatically using a policy,
+you can also refresh it manually.
+
+To follow the procedure on this page you need to:
+
+* Create a [target Tiger Cloud service][create-service].
+
+This procedure also works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Change the refresh policy
+
+Continuous aggregates require a policy for automatic refreshing. You can adjust
+this to suit different use cases. For example, you can have the continuous
+aggregate and the hypertable stay in sync, even when data is removed from the
+hypertable. Alternatively, you could keep source data in the continuous aggregate even after
+it is removed from the hypertable.
+
+You can change the way your continuous aggregate is refreshed by calling
+`add_continuous_aggregate_policy`.
+
+Among others, `add_continuous_aggregate_policy` takes the following arguments:
+
+* `start_offset`: the start of the refresh window relative to when the policy
+ runs
+* `end_offset`: the end of the refresh window relative to when the policy runs
+* `schedule_interval`: the refresh interval in minutes or hours. Defaults to
+ 24 hours.
+
+- If you set the `start_offset` or `end_offset` to `NULL`, the range is open-ended and extends to the beginning or end of time.
+- If you set `end_offset` within the current time bucket, this bucket is excluded from materialization. This is done for the following reasons:
+
+- The current bucket is incomplete and can't be refreshed.
+ - The current bucket gets a lot of writes in the timestamp order, and its aggregate becomes outdated very quickly. Excluding it improves performance.
+
+To include the latest raw data in queries, enable [real-time aggregation][future-watermark].
+
+See the [API reference][api-reference] for the full list of required and optional arguments and use examples.
+
+The policy in the following example ensures that all data in the continuous aggregate is up to date with the hypertable, except for data written within the last hour of wall-clock time. The policy also does not refresh the last time bucket of the continuous aggregate.
+
+Since the policy in this example runs once every hour (`schedule_interval`) while also excluding data within the most recent hour (`end_offset`), it takes up to 2 hours for data written to the hypertable to be reflected in the continuous aggregate. Backfills, which are usually outside the most recent hour of data, will be visible after up to 1 hour depending on when the policy last ran when the data was written.
+
+Because it has an open-ended `start_offset` parameter, any data that is removed
+from the table, for example with a `DELETE` or with `drop_chunks`, is also removed
+from the continuous aggregate view. This means that the continuous aggregate
+always reflects the data in the underlying hypertable.
+
+To changing a refresh policy to use a `NULL` `start_offset`:
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_hourly` that keeps the continuous aggregate up to date, and runs every hour:
+
+If you want to keep data in the continuous aggregate even if it is removed from
+the underlying hypertable, you can set the `start_offset` to match the
+[data retention policy][sec-data-retention] on the source hypertable. For example,
+if you have a retention policy that removes data older than one month, set
+`start_offset` to one month or less. This sets your policy so that it does not
+refresh the dropped data.
+
+1. Connect to your Tiger Cloud service.
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_hourly`
+ that keeps data removed from the hypertable in the continuous aggregate, and
+ runs every hour:
+
+It is important to consider your data retention policies when you're setting up
+continuous aggregate policies. If the continuous aggregate policy window covers
+data that is removed by the data retention policy, the data will be removed when
+the aggregates for those buckets are refreshed. For example, if you have a data
+retention policy that removes all data older than two weeks, the continuous
+aggregate policy will only have data for the last two weeks.
+
+## Add concurrent refresh policies
+
+You can add concurrent refresh policies on each continuous aggregate, as long as their
+start and end offsets don't overlap. For example, to backfill data into older chunks you
+set up one policy that refreshes recent data, and another that refreshes backfilled data.
+
+The first policy in this example is keeps the continuous aggregate up to date with data that was
+inserted in the past day. Any data that was inserted or updated for previous days is refreshed by
+the second policy.
+
+1. Connect to your Tiger Cloud service.
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_daily`
+ to refresh the continuous aggregate with recently inserted data which runs
+ hourly:
+
+2. At the `psql` prompt, create a concurrent policy on
+ `conditions_summary_daily` to refresh the continuous aggregate with
+ backfilled data:
+
+## Manually refresh a continuous aggregate
+
+If you need to manually refresh a continuous aggregate, you can use the
+`refresh` command. This recomputes the data within the window that has changed
+in the underlying hypertable since the last refresh. Therefore, if only a few
+buckets need updating, the refresh runs quickly.
+
+If you have recently dropped data from a hypertable with a continuous aggregate,
+calling `refresh_continuous_aggregate` on a region containing dropped chunks
+recalculates the aggregate without the dropped data. See
+[drop data][cagg-drop-data] for more information.
+
+The `refresh` command takes three arguments:
+
+* The name of the continuous aggregate view to refresh
+* The timestamp of the beginning of the refresh window
+* The timestamp of the end of the refresh window
+
+Only buckets that are wholly within the specified range are refreshed. For
+example, if you specify `2021-05-01', '2021-06-01` the only buckets that are
+refreshed are those up to but not including 2021-06-01. It is possible to
+specify `NULL` in a manual refresh to get an open-ended range, but we do not
+recommend using it, because you could inadvertently materialize a large amount
+of data, slow down your performance, and have unintended consequences on other
+policies like data retention.
+
+To manually refresh a continuous aggregate, use the `refresh` command:
+
+Follow the logic used by automated refresh policies and avoid refreshing time buckets that are likely to have a lot of writes. This means that you should generally not refresh the latest incomplete time bucket. To include the latest raw data in your queries, use [real-time aggregation][real-time-aggregates] instead.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/drop-data/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_hourly',
+ start_offset => NULL,
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_hourly',
+ start_offset => INTERVAL '1 month',
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 3 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_daily',
+ start_offset => INTERVAL '1 day',
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 4 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_daily',
+ start_offset => NULL
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+---
diff --git a/skills/timescaledb/references/getting_started.md b/skills/timescaledb/references/getting_started.md
new file mode 100644
index 0000000..d1b704d
--- /dev/null
+++ b/skills/timescaledb/references/getting_started.md
@@ -0,0 +1,2098 @@
+# Timescaledb - Getting Started
+
+**Pages:** 3
+
+---
+
+## Start coding with Tiger Data
+
+**URL:** llms-txt#start-coding-with-tiger-data
+
+Easily integrate your app with Tiger Cloud or self-hosted TimescaleDB. Use your favorite programming language to connect to your
+Tiger Cloud service, create and manage hypertables, then ingest and query data.
+
+---
+
+## "Quick Start: Ruby and TimescaleDB"
+
+**URL:** llms-txt#"quick-start:-ruby-and-timescaledb"
+
+**Contents:**
+- Prerequisites
+- Connect a Rails app to your service
+- Optimize time-series data in hypertables
+- Insert data your service
+- Reference
+ - Query scopes
+ - TimescaleDB features
+- Next steps
+- Load energy consumption data
+ - 6e. Enable policies that compress data in the target hypertable
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Rails][rails-guide].
+
+## Connect a Rails app to your service
+
+Every Tiger Cloud service is a 100% Postgres database hosted in Tiger Cloud with
+Tiger Data extensions such as TimescaleDB. You connect to your Tiger Cloud service
+from a standard Rails app configured for Postgres.
+
+1. **Create a new Rails app configured for Postgres**
+
+Rails creates and bundles your app, then installs the standard Postgres Gems.
+
+1. **Install the TimescaleDB gem**
+
+1. Open `Gemfile`, add the following line, then save your changes:
+
+1. In Terminal, run the following command:
+
+1. **Connect your app to your Tiger Cloud service**
+
+1. In `/config/database.yml` update the configuration to read securely connect to your Tiger Cloud service
+ by adding `url: <%= ENV['DATABASE_URL'] %>` to the default configuration:
+
+1. Set the environment variable for `DATABASE_URL` to the value of `Service URL` from
+ your [connection details][connection-info]
+
+1. Create the database:
+ - **Tiger Cloud**: nothing to do. The database is part of your Tiger Cloud service.
+ - **Self-hosted TimescaleDB**, create the database for the project:
+
+1. Verify the connection from your app to your Tiger Cloud service:
+
+The result shows the list of extensions in your Tiger Cloud service
+
+| Name | Version | Schema | Description |
+ | -- | -- | -- | -- |
+ | pg_buffercache | 1.5 | public | examine the shared buffer cache|
+ | pg_stat_statements | 1.11 | public | track planning and execution statistics of all SQL statements executed|
+ | plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language|
+ | postgres_fdw | 1.1 | public | foreign-data wrapper for remote Postgres servers|
+ | timescaledb | 2.18.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)|
+ | timescaledb_toolkit | 1.19.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities|
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables designed to simplify and accelerate data analysis. Anything
+you can do with regular Postgres tables, you can do with hypertables - but much faster and more conveniently.
+
+In this section, you use the helpers in the TimescaleDB gem to create and manage a [hypertable][about-hypertables].
+
+1. **Generate a migration to create the page loads table**
+
+This creates the `/db/migrate/_create_page_loads.rb` migration file.
+
+1. **Add hypertable options**
+
+Replace the contents of `/db/migrate/_create_page_loads.rb`
+ with the following:
+
+The `id` column is not included in the table. This is because TimescaleDB requires that any `UNIQUE` or `PRIMARY KEY`
+ indexes on the table include all partitioning columns. In this case, this is the time column. A new
+ Rails model includes a `PRIMARY KEY` index for id by default: either remove the column or make sure that the index
+ includes time as part of a "composite key."
+
+For more information, check the Roby docs around [composite primary keys][rails-compostite-primary-keys].
+
+1. **Create a `PageLoad` model**
+
+Create a new file called `/app/models/page_load.rb` and add the following code:
+
+1. **Run the migration**
+
+## Insert data your service
+
+The TimescaleDB gem provides efficient ways to insert data into hypertables. This section
+shows you how to ingest test data into your hypertable.
+
+1. **Create a controller to handle page loads**
+
+Create a new file called `/app/controllers/application_controller.rb` and add the following code:
+
+1. **Generate some test data**
+
+Use `bin/console` to join a Rails console session and run the following code
+ to define some random page load access data:
+
+1. **Insert the generated data into your Tiger Cloud service**
+
+1. **Validate the test data in your Tiger Cloud service**
+
+This section lists the most common tasks you might perform with the TimescaleDB gem.
+
+The TimescaleDB gem provides several convenient scopes for querying your time-series data.
+
+- Built-in time-based scopes:
+
+- Browser-specific scopes:
+
+- Query continuous aggregates:
+
+This query fetches the average and standard deviation from the performance stats for the `/products` path over the last day.
+
+### TimescaleDB features
+
+The TimescaleDB gem provides utility methods to access hypertable and chunk information. Every model that uses
+the `acts_as_hypertable` method has access to these methods.
+
+#### Access hypertable and chunk information
+
+- View chunk or hypertable information:
+
+- Compress/Decompress chunks:
+
+#### Access hypertable stats
+
+You collect hypertable stats using methods that provide insights into your hypertable's structure, size, and compression
+status:
+
+- Get basic hypertable information:
+
+- Get detailed size information:
+
+#### Continuous aggregates
+
+The `continuous_aggregates` method generates a class for each continuous aggregate.
+
+- Get all the continuous aggregate classes:
+
+- Manually refresh a continuous aggregate:
+
+- Create or drop a continuous aggregate:
+
+Create or drop all the continuous aggregates in the proper order to build them hierarchically. See more about how it
+ works in this [blog post][ruby-blog-post].
+
+Now that you have integrated the ruby gem into your app:
+
+* Learn more about the [TimescaleDB gem](https://github.com/timescale/timescaledb-ruby).
+* Check out the [official docs](https://timescale.github.io/timescaledb-ruby/).
+* Follow the [LTTB][LTTB], [Open AI long-term storage][open-ai-tutorial], and [candlesticks][candlesticks] tutorials.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_add-data-energy/ =====
+
+## Load energy consumption data
+
+When you have your database set up, you can load the energy consumption data
+into the `metrics` hypertable.
+
+This is a large dataset, so it might take a long time, depending on your network
+connection.
+
+1. Download the dataset:
+
+[metrics.csv.gz](https://assets.timescale.com/docs/downloads/metrics.csv.gz)
+
+1. Use your file manager to decompress the downloaded dataset, and take a note
+ of the path to the `metrics.csv` file.
+
+1. At the psql prompt, copy the data from the `metrics.csv` file into
+ your hypertable. Make sure you point to the correct path, if it is not in
+ your current working directory:
+
+1. You can check that the data has been copied successfully with this command:
+
+You should get five records that look like this:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_dump_database_roles/ =====
+
+Tiger Cloud services do not support roles with superuser access. If your SQL
+dump includes roles that have such permissions, you'll need to modify the file
+to be compliant with the security model.
+
+You can use the following `sed` command to remove unsupported statements and
+permissions from your roles.sql file:
+
+This command works only with the GNU implementation of sed (sometimes referred
+to as gsed). For the BSD implementation (the default on macOS), you need to
+add an extra argument to change the `-i` flag to `-i ''`.
+
+To check the sed version, you can use the command `sed --version`. While the
+GNU version explicitly identifies itself as GNU, the BSD version of sed
+generally doesn't provide a straightforward --version flag and simply outputs
+an "illegal option" error.
+
+A brief explanation of this script is:
+
+- `CREATE ROLE "postgres"`; and `ALTER ROLE "postgres"`: These statements are
+ removed because they require superuser access, which is not supported
+ by Timescale.
+
+- `(NO)SUPERUSER` | `(NO)REPLICATION` | `(NO)BYPASSRLS`: These are permissions
+ that require superuser access.
+
+- `GRANTED BY role_specification`: The GRANTED BY clause can also have permissions that
+ require superuser access and should therefore be removed. Note: according to the
+ TimescaleDB documentation, the GRANTOR in the GRANTED BY clause must be the
+ current user, and this clause mainly serves the purpose of SQL compatibility.
+ Therefore, it's safe to remove it.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-debian-based-start/ =====
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_free-plan-beta/ =====
+
+The Free pricing plan and services are currently in beta.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_livesync-configure-source-database/ =====
+
+1. **Tune the Write Ahead Log (WAL) on the Postgres source database**
+
+* [GUC “wal_level” as “logical”](https://www.postgresql.org/docs/current/runtime-config-wal.html#GUC-WAL-LEVEL)
+ * [GUC “max_wal_senders” as 10](https://www.postgresql.org/docs/current/runtime-config-replication.html#GUC-MAX-WAL-SENDERS)
+ * [GUC “wal_sender_timeout” as 0](https://www.postgresql.org/docs/current/runtime-config-replication.html#GUC-WAL-SENDER-TIMEOUT)
+
+This will require a restart of the Postgres source database.
+
+1. **Create a user for the connector and assign permissions**
+
+1. Create ``:
+
+You can use an existing user. However, you must ensure that the user has the following permissions.
+
+1. Grant permissions to create a replication slot:
+
+1. Grant permissions to create a publication:
+
+1. Assign the user permissions on the source database:
+
+If the tables you are syncing are not in the `public` schema, grant the user permissions for each schema you are syncing:
+
+1. On each table you want to sync, make `` the owner:
+
+You can skip this step if the replicating user is already the owner of the tables.
+
+1. **Enable replication `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_datadog-data-exporter/ =====
+
+1. **In Tiger Cloud Console, open [Exporters][console-integrations]**
+1. **Click `New exporter`**
+1. **Select `Metrics` for `Data type` and `Datadog` for provider**
+
+
+
+1. **Choose your AWS region and provide the API key**
+
+The AWS region must be the same for your Tiger Cloud exporter and the Datadog provider.
+
+1. **Set `Site` to your Datadog region, then click `Create exporter`**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_6e_turn_on_compression_policies/ =====
+
+### 6e. Enable policies that compress data in the target hypertable
+
+In the following command, replace `` with the fully qualified table
+name of the target hypertable, for example `public.metrics`:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-redhat-rocky/ =====
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-mst-restart-workers/ =====
+
+On Tiger Cloud and Managed Service for TimescaleDB, restart background workers by doing one of the following:
+
+* Run `SELECT timescaledb_pre_restore()`, followed by `SELECT
+ timescaledb_post_restore()`.
+* Power the service off and on again. This might cause a downtime of a few
+ minutes while the service restores from backup and replays the write-ahead
+ log.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_setup_enable_replication/ =====
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_timescale-cloud-platforms/ =====
+
+You use Tiger Data's open-source products to create your best app from the comfort of your own developer environment.
+
+See the [available services][available-services] and [supported systems][supported-systems].
+
+### Available services
+
+Tiger Data offers the following services for your self-hosted installations:
+
+
+
+
+## Roll up calculations
+
+When summarizing already-summarized data, be aware of how stacked calculations
+work. Not all calculations return the correct result if you stack them.
+
+For example, if you take the maximum of several subsets, then take the maximum
+of the maximums, you get the maximum of the entire set. But if you take the
+average of several subsets, then take the average of the averages, that can
+result in a different figure than the average of all the data.
+
+To simplify such calculations when using continuous aggregates on top of
+continuous aggregates, you can use the [hyperfunctions][hyperfunctions] from
+TimescaleDB Toolkit, such as the [statistical aggregates][stats-aggs]. These
+hyperfunctions are designed with a two-step aggregation pattern that allows you
+to roll them up into larger buckets. The first step creates a summary aggregate
+that can be rolled up, just as a maximum can be rolled up. You can store this
+aggregate in your continuous aggregate. Then, you can call an accessor function
+as a second step when you query from your continuous aggregate. This accessor
+takes the stored data from the summary aggregate and returns the final result.
+
+For example, you can create an hourly continuous aggregate using `percentile_agg`
+over a hypertable, like this:
+
+To then stack another daily continuous aggregate over it, you can use a `rollup`
+function, like this:
+
+The `mean` function of the TimescaleDB Toolkit is used to calculate the concrete
+mean value of the rolled up values. The additional `percentile_daily` attribute
+contains the raw rolled up values, which can be used in an additional continuous
+aggregate on top of this continuous aggregate (for example a continuous
+aggregate for the daily values).
+
+For more information and examples about using `rollup` functions to stack
+calculations, see the [percentile approximation API documentation][percentile_agg_api].
+
+There are some restrictions when creating a continuous aggregate on top of
+another continuous aggregate. In most cases, these restrictions are in place to
+ensure valid time-bucketing:
+
+* You can only create a continuous aggregate on top of a finalized continuous
+ aggregate. This new finalized format is the default for all continuous
+ aggregates created since TimescaleDB 2.7. If you need to create a continuous
+ aggregate on top of a continuous aggregate in the old format, you need to
+ [migrate your continuous aggregate][migrate-cagg] to the new format first.
+
+* The time bucket of a continuous aggregate should be greater than or equal to
+ the time bucket of the underlying continuous aggregate. It also needs to be
+ a multiple of the underlying time bucket. For example, you can rebucket an
+ hourly continuous aggregate into a new continuous aggregate with time
+ buckets of 6 hours. You can't rebucket the hourly continuous aggregate into
+ a new continuous aggregate with time buckets of 90 minutes, because 90
+ minutes is not a multiple of 1 hour.
+
+* A continuous aggregate with a fixed-width time bucket can't be created on
+ top of a continuous aggregate with a variable-width time bucket. Fixed-width
+ time buckets are time buckets defined in seconds, minutes, hours, and days,
+ because those time intervals are always the same length. Variable-width time
+ buckets are time buckets defined in months or years, because those time
+ intervals vary by the month or on leap years. This limitation prevents a
+ case such as trying to rebucket monthly buckets into `61 day` buckets, where
+ there is no good mapping between time buckets for month combinations such as
+ July/August (62 days).
+
+Note that even though weeks are fixed-width intervals, you can't use monthly
+ or yearly time buckets on top of weekly time buckets for the same reason.
+ The number of weeks in a month or year is usually not an integer.
+
+However, you can stack a variable-width time bucket on top of a fixed-width
+ time bucket. For example, creating a monthly continuous aggregate on top of
+ a daily continuous aggregate works, and is the one of the main use cases for
+ this feature.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypercore/secondary-indexes/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_hourly
+WITH (timescaledb.continuous)
+AS SELECT
+ time_bucket('1 h'::interval, ts) as bucket,
+ api_id,
+ avg(response_time_ms),
+ percentile_agg(response_time_ms) as percentile_hourly
+FROM response_times
+GROUP BY 1, 2;
+```
+
+Example 2 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_daily
+WITH (timescaledb.continuous)
+AS SELECT
+ time_bucket('1 d'::interval, bucket) as bucket_daily,
+ api_id,
+ mean(rollup(percentile_hourly)) as mean,
+ rollup(percentile_hourly) as percentile_daily
+FROM response_times_hourly
+GROUP BY 1, 2;
+```
+
+---
+
+## Continuous aggregate watermark is in the future
+
+**URL:** llms-txt#continuous-aggregate-watermark-is-in-the-future
+
+**Contents:**
+ - Creating a new continuous aggregate with an explicit refresh window
+
+
+
+Continuous aggregates use a watermark to indicate which time buckets have
+already been materialized. When you query a continuous aggregate, your query
+returns materialized data from before the watermark. It returns real-time,
+non-materialized data from after the watermark.
+
+In certain cases, the watermark might be in the future. If this happens, all
+buckets, including the most recent bucket, are materialized and below the
+watermark. No real-time data is returned.
+
+This might happen if you refresh your continuous aggregate over the time window
+`, NULL`, which materializes all recent data. It might also happen
+if you create a continuous aggregate using the `WITH DATA` option. This also
+implicitly refreshes your continuous aggregate with a window of `NULL, NULL`.
+
+To fix this, create a new continuous aggregate using the `WITH NO DATA` option.
+Then use a policy to refresh this continuous aggregate over an explicit time
+window.
+
+### Creating a new continuous aggregate with an explicit refresh window
+
+1. Create a continuous aggregate using the `WITH NO DATA` option:
+
+1. Refresh the continuous aggregate using a policy with an explicit
+ `end_offset`. For example:
+
+1. Check your new continuous aggregate's watermark to make sure it is in the
+ past, not the future.
+
+Get the ID for the materialization hypertable that contains the actual
+ continuous aggregate data:
+
+1. Use the returned ID to query for the watermark's timestamp:
+
+For TimescaleDB >= 2.12:
+
+For TimescaleDB < 2.12:
+
+If you choose to delete your old continuous aggregate after creating a new one,
+beware of historical data loss. If your old continuous aggregate contained data
+that you dropped from your original hypertable, for example through a data
+retention policy, the dropped data is not included in your new continuous
+aggregate.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/scheduled-jobs-stop-running/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW
+ WITH (timescaledb.continuous)
+ AS SELECT time_bucket('', ),
+ ,
+ ...
+ FROM
+ GROUP BY bucket,
+ WITH NO DATA;
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('',
+ start_offset => INTERVAL '30 day',
+ end_offset => INTERVAL '1 hour',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+Example 3 (sql):
+```sql
+SELECT id FROM _timescaledb_catalog.hypertable
+ WHERE table_name=(
+ SELECT materialization_hypertable_name
+ FROM timescaledb_information.continuous_aggregates
+ WHERE view_name=''
+ );
+```
+
+Example 4 (sql):
+```sql
+SELECT COALESCE(
+ _timescaledb_functions.to_timestamp(_timescaledb_functions.cagg_watermark()),
+ '-infinity'::timestamp with time zone
+ );
+```
+
+---
+
+## About continuous aggregates
+
+**URL:** llms-txt#about-continuous-aggregates
+
+**Contents:**
+- Types of aggregation
+- Continuous aggregates on continuous aggregates
+- Continuous aggregates with a `JOIN` clause
+ - JOIN examples
+- Function support
+- Components of a continuous aggregate
+ - Materialization hypertable
+ - Materialization engine
+ - Invalidation engine
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+## Types of aggregation
+
+There are three main ways to make aggregation easier: materialized views,
+continuous aggregates, and real-time aggregates.
+
+[Materialized views][pg-materialized views] are a standard Postgres function.
+They are used to cache the result of a complex query so that you can reuse it
+later on. Materialized views do not update regularly, although you can manually
+refresh them as required.
+
+[Continuous aggregates][about-caggs] are a TimescaleDB-only feature. They work in
+a similar way to a materialized view, but they are updated automatically in the
+background, as new data is added to your database. Continuous aggregates are
+updated continuously and incrementally, which means they are less resource
+intensive to maintain than materialized views. Continuous aggregates are based
+on hypertables, and you can query them in the same way as you do your other
+tables.
+
+[Real-time aggregates][real-time-aggs] are a TimescaleDB-only feature. They are
+the same as continuous aggregates, but they add the most recent raw data to the
+previously aggregated data to provide accurate and up-to-date results, without
+needing to aggregate data as it is being written.
+
+## Continuous aggregates on continuous aggregates
+
+You can create a continuous aggregate on top of another continuous aggregate.
+This allows you to summarize data at different granularity. For example, you
+might have a raw hypertable that contains second-by-second data. Create a
+continuous aggregate on the hypertable to calculate hourly data. To calculate
+daily data, create a continuous aggregate on top of your hourly continuous
+aggregate.
+
+For more information, see the documentation about
+[continuous aggregates on continuous aggregates][caggs-on-caggs].
+
+## Continuous aggregates with a `JOIN` clause
+
+Continuous aggregates support the following JOIN features:
+
+| Feature | TimescaleDB < 2.10.x | TimescaleDB <= 2.15.x | TimescaleDB >= 2.16.x|
+|-|-|-|-|
+|INNER JOIN|❌|✅|✅|
+|LEFT JOIN|❌|❌|✅|
+|LATERAL JOIN|❌|❌|✅|
+|Joins between **ONE** hypertable and **ONE** standard Postgres table|❌|✅|✅|
+|Joins between **ONE** hypertable and **MANY** standard Postgres tables|❌|❌|✅|
+|Join conditions must be equality conditions, and there can only be **ONE** `JOIN` condition|❌|✅|✅|
+|Any join conditions|❌|❌|✅|
+
+JOINS in TimescaleDB must meet the following conditions:
+
+* Only the changes to the hypertable are tracked, and they are updated in the
+ continuous aggregate when it is refreshed. Changes to standard
+ Postgres table are not tracked.
+* You can use an `INNER`, `LEFT`, and `LATERAL` joins; no other join type is supported.
+* Joins on the materialized hypertable of a continuous aggregate are not supported.
+* Hierarchical continuous aggregates can be created on top of a continuous
+ aggregate with a `JOIN` clause, but cannot themselves have a `JOIN` clause.
+
+Given the following schema:
+
+See the following `JOIN` examples on continuous aggregates:
+
+- `INNER JOIN` on a single equality condition, using the `ON` clause:
+
+- `INNER JOIN` on a single equality condition, using the `ON` clause, with a further condition added in the `WHERE` clause:
+
+- `INNER JOIN` on a single equality condition specified in `WHERE` clause:
+
+- `INNER JOIN` on multiple equality conditions:
+
+TimescaleDB v2.16.x and higher.
+
+- `INNER JOIN` with a single equality condition specified in `WHERE` clause can be combined with further conditions in the `WHERE` clause:
+
+TimescaleDB v2.16.x and higher.
+
+- `INNER JOIN` between a hypertable and multiple Postgres tables:
+
+TimescaleDB v2.16.x and higher.
+
+- `LEFT JOIN` between a hypertable and a Postgres table:
+
+TimescaleDB v2.16.x and higher.
+
+- `LATERAL JOIN` between a hypertable and a subquery:
+
+TimescaleDB v2.16.x and higher.
+
+In TimescaleDB v2.7 and later, continuous aggregates support all Postgres
+aggregate functions. This includes both parallelizable aggregates, such as `SUM`
+and `AVG`, and non-parallelizable aggregates, such as `RANK`.
+
+In TimescaleDB v2.10.0 and later, the `FROM` clause supports `JOINS`, with
+some restrictions. For more information, see the [`JOIN` support section][caggs-joins].
+
+In older versions of TimescaleDB, continuous aggregates only support
+[aggregate functions that can be parallelized by Postgres][postgres-parallel-agg].
+You can work around this by aggregating the other parts of your query in the
+continuous aggregate, then
+[using the window function to query the aggregate][cagg-window-functions].
+
+The following table summarizes the aggregate functions supported in continuous aggregates:
+
+| Function, clause, or feature |TimescaleDB 2.6 and earlier|TimescaleDB 2.7, 2.8, and 2.9|TimescaleDB 2.10 and later|
+|------------------------------------------------------------|-|-|-|
+| Parallelizable aggregate functions |✅|✅|✅|
+| [Non-parallelizable SQL aggregates][postgres-parallel-agg] |❌|✅|✅|
+| `ORDER BY` |❌|✅|✅|
+| Ordered-set aggregates |❌|✅|✅|
+| Hypothetical-set aggregates |❌|✅|✅|
+| `DISTINCT` in aggregate functions |❌|✅|✅|
+| `FILTER` in aggregate functions |❌|✅|✅|
+| `FROM` clause supports `JOINS` |❌|❌|✅|
+
+DISTINCT works in aggregate functions, not in the query definition. For example, for the table:
+
+- The following works:
+
+- This does not:
+
+If you want the old behavior in later versions of TimescaleDB, set the
+`timescaledb.finalized` parameter to `false` when you create your continuous
+aggregate.
+
+## Components of a continuous aggregate
+
+Continuous aggregates consist of:
+
+* Materialization hypertable to store the aggregated data in
+* Materialization engine to aggregate data from the raw, underlying, table to
+ the materialization hypertable
+* Invalidation engine to determine when data needs to be re-materialized, due
+ to changes in the data
+* Query engine to access the aggregated data
+
+### Materialization hypertable
+
+Continuous aggregates take raw data from the original hypertable, aggregate it,
+and store the aggregated data in a materialization hypertable. When you query
+the continuous aggregate view, the aggregated data is returned to you as needed.
+
+Using the same temperature example, the materialization table looks like this:
+
+|day|location|chunk|avg temperature|
+|-|-|-|-|
+|2021/01/01|New York|1|73|
+|2021/01/01|Stockholm|1|70|
+|2021/01/02|New York|2||
+|2021/01/02|Stockholm|2|69|
+
+The materialization table is stored as a TimescaleDB hypertable, to take
+advantage of the scaling and query optimizations that hypertables offer.
+Materialization tables contain a column for each group-by clause in the query,
+and an `aggregate` column for each aggregate in the query.
+
+For more information, see [materialization hypertables][cagg-mat-hypertables].
+
+### Materialization engine
+
+The materialization engine performs two transactions. The first transaction
+blocks all INSERTs, UPDATEs, and DELETEs, determines the time range to
+materialize, and updates the invalidation threshold. The second transaction
+unblocks other transactions, and materializes the aggregates. The first
+transaction is very quick, and most of the work happens during the second
+transaction, to ensure that the work does not interfere with other operations.
+
+### Invalidation engine
+
+Any change to the data in a hypertable could potentially invalidate some
+materialized rows. The invalidation engine checks to ensure that the system does
+not become swamped with invalidations.
+
+Fortunately, time-series data means that nearly all INSERTs and UPDATEs have a
+recent timestamp, so the invalidation engine does not materialize all the data,
+but to a set point in time called the materialization threshold. This threshold
+is set so that the vast majority of INSERTs contain more recent timestamps.
+These data points have never been materialized by the continuous aggregate, so
+there is no additional work needed to notify the continuous aggregate that they
+have been added. When the materializer next runs, it is responsible for
+determining how much new data can be materialized without invalidating the
+continuous aggregate. It then materializes the more recent data and moves the
+materialization threshold forward in time. This ensures that the threshold lags
+behind the point-in-time where data changes are common, and that most INSERTs do
+not require any extra writes.
+
+When data older than the invalidation threshold is changed, the maximum and
+minimum timestamps of the changed rows is logged, and the values are used to
+determine which rows in the aggregation table need to be recalculated. This
+logging does cause some write load, but because the threshold lags behind the
+area of data that is currently changing, the writes are small and rare.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/time/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE locations (
+ id TEXT PRIMARY KEY,
+ name TEXT
+);
+
+CREATE TABLE devices (
+ id SERIAL PRIMARY KEY,
+ location_id TEXT,
+ name TEXT
+);
+
+CREATE TABLE conditions (
+ "time" TIMESTAMPTZ,
+ device_id INTEGER,
+ temperature FLOAT8
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+```
+
+Example 2 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions
+ JOIN devices ON devices.id = conditions.device_id
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+Example 3 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions
+ JOIN devices ON devices.id = conditions.device_id
+ WHERE devices.location_id = 'location123'
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+Example 4 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_by_day WITH (timescaledb.continuous) AS
+ SELECT time_bucket('1 day', time) AS bucket, devices.name, MIN(temperature), MAX(temperature)
+ FROM conditions, devices
+ WHERE devices.id = conditions.device_id
+ GROUP BY bucket, devices.name
+ WITH NO DATA;
+```
+
+---
+
+## Continuous aggregates
+
+**URL:** llms-txt#continuous-aggregates
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+For more information about using continuous aggregates, see the documentation in [Use Tiger Data products][cagg-docs].
+
+===== PAGE: https://docs.tigerdata.com/api/data-retention/ =====
+
+---
+
+## refresh_continuous_aggregate()
+
+**URL:** llms-txt#refresh_continuous_aggregate()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Refresh all buckets of a continuous aggregate in the refresh window given by
+`window_start` and `window_end`.
+
+A continuous aggregate materializes aggregates in time buckets. For example,
+min, max, average over 1 day worth of data, and is determined by the `time_bucket`
+interval. Therefore, when
+refreshing the continuous aggregate, only buckets that completely fit within the
+refresh window are refreshed. In other words, it is not possible to compute the
+aggregate over, for an incomplete bucket. Therefore, any buckets that do not
+fit within the given refresh window are excluded.
+
+The function expects the window parameter values to have a time type that is
+compatible with the continuous aggregate's time bucket expression—for
+example, if the time bucket is specified in `TIMESTAMP WITH TIME ZONE`, then the
+start and end time should be a date or timestamp type. Note that a continuous
+aggregate using the `TIMESTAMP WITH TIME ZONE` type aligns with the UTC time
+zone, so, if `window_start` and `window_end` is specified in the local time
+zone, any time zone shift relative UTC needs to be accounted for when refreshing
+to align with bucket boundaries.
+
+To improve performance for continuous aggregate refresh, see
+[CREATE MATERIALIZED VIEW ][create_materialized_view].
+
+Refresh the continuous aggregate `conditions` between `2020-01-01` and
+`2020-02-01` exclusive.
+
+Alternatively, incrementally refresh the continuous aggregate `conditions`
+between `2020-01-01` and `2020-02-01` exclusive, working in `12h` intervals:
+
+Force the `conditions` continuous aggregate to refresh between `2020-01-01` and
+`2020-02-01` exclusive, even if the data has already been refreshed.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`continuous_aggregate`|REGCLASS|The continuous aggregate to refresh.|
+|`window_start`|INTERVAL, TIMESTAMPTZ, INTEGER|Start of the window to refresh, has to be before `window_end`.|
+|`window_end`|INTERVAL, TIMESTAMPTZ, INTEGER|End of the window to refresh, has to be after `window_start`.|
+
+You must specify the `window_start` and `window_end` parameters differently,
+depending on the type of the time column of the hypertable. For hypertables with
+`TIMESTAMP`, `TIMESTAMPTZ`, and `DATE` time columns, set the refresh window as
+an `INTERVAL` type. For hypertables with integer-based timestamps, set the
+refresh window as an `INTEGER` type.
+
+A `NULL` value for `window_start` is equivalent to the lowest changed element
+in the raw hypertable of the CAgg. A `NULL` value for `window_end` is
+equivalent to the largest changed element in raw hypertable of the CAgg. As
+changed element tracking is performed after the initial CAgg refresh, running
+CAgg refresh without `window_start` and `window_end` covers the entire time
+range.
+
+Note that it's not guaranteed that all buckets will be updated: refreshes will
+not take place when buckets are materialized with no data changes or with
+changes that only occurred in the secondary table used in the JOIN.
+
+## Optional arguments
+
+|Name|Type| Description |
+|-|-|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `force` | BOOLEAN | Force refresh every bucket in the time range between `window_start` and `window_end`, even when the bucket has already been refreshed. This can be very expensive when a lot of data is refreshed. Default is `FALSE`. |
+| `refresh_newest_first` | BOOLEAN | Set to `FALSE` to refresh the oldest data first. Default is `TRUE`. |
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/remove_policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL refresh_continuous_aggregate('conditions', '2020-01-01', '2020-02-01');
+```
+
+Example 2 (sql):
+```sql
+DO
+$$
+DECLARE
+ refresh_interval INTERVAL = '12h'::INTERVAL;
+ start_timestamp TIMESTAMPTZ = '2020-01-01T00:00:00Z';
+ end_timestamp TIMESTAMPTZ = start_timestamp + refresh_interval;
+BEGIN
+ WHILE start_timestamp < '2020-02-01T00:00:00Z' LOOP
+ CALL refresh_continuous_aggregate('conditions', start_timestamp, end_timestamp);
+ COMMIT;
+ RAISE NOTICE 'finished with timestamp %', end_timestamp;
+ start_timestamp = end_timestamp;
+ end_timestamp = end_timestamp + refresh_interval;
+ END LOOP;
+END
+$$;
+```
+
+Example 3 (sql):
+```sql
+CALL refresh_continuous_aggregate('conditions', '2020-01-01', '2020-02-01', force => TRUE);
+```
+
+---
+
+## DROP MATERIALIZED VIEW (Continuous Aggregate)
+
+**URL:** llms-txt#drop-materialized-view-(continuous-aggregate)
+
+**Contents:**
+- Samples
+- Parameters
+
+Continuous aggregate views can be dropped using the `DROP MATERIALIZED VIEW` statement.
+
+This statement deletes the continuous aggregate and all its internal
+objects. It also removes refresh policies for that
+aggregate. To delete other dependent objects, such as a view
+defined on the continuous aggregate, add the `CASCADE`
+option. Dropping a continuous aggregate does not affect the data in
+the underlying hypertable from which the continuous aggregate is
+derived.
+
+Drop existing continuous aggregate.
+
+|Name|Type|Description|
+|---|---|---|
+| `` | TEXT | Name (optionally schema-qualified) of continuous aggregate view to be dropped.|
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/remove_all_policies/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+## Samples
+
+Drop existing continuous aggregate.
+```
+
+---
+
+## Migrate a continuous aggregate to the new form
+
+**URL:** llms-txt#migrate-a-continuous-aggregate-to-the-new-form
+
+**Contents:**
+- Configure continuous aggregate migration
+- Check on continuous aggregate migration status
+- Troubleshooting
+ - Permissions error when migrating a continuous aggregate
+
+In TimescaleDB v2.7 and later, continuous aggregates use a new format that
+improves performance and makes them compatible with more SQL queries. Continuous
+aggregates created in older versions of TimescaleDB, or created in a new version
+with the option `timescaledb.finalized` set to `false`, use the old format.
+
+To migrate a continuous aggregate from the old format to the new format, you can
+use this procedure. It automatically copies over your data and policies. You can
+continue to use the continuous aggregate while the migration is happening.
+
+Connect to your database and run:
+
+There are known issues with `cagg_migrate()` in version 2.8.0.
+Upgrade to version 2.8.1 or later before using it.
+
+## Configure continuous aggregate migration
+
+The migration procedure provides two boolean configuration parameters,
+`override` and `drop_old`. By default, the name of your new continuous
+aggregate is the name of your old continuous aggregate, with the suffix `_new`.
+
+Set `override` to true to rename your new continuous aggregate with the
+original name. The old continuous aggregate is renamed with the suffix `_old`.
+
+To both rename and drop the old continuous aggregate entirely, set both
+parameters to true. Note that `drop_old` must be used together with
+`override`.
+
+## Check on continuous aggregate migration status
+
+To check the progress of the continuous aggregate migration, query the migration
+planning table:
+
+### Permissions error when migrating a continuous aggregate
+
+You might get a permissions error when migrating a continuous aggregate from old
+to new format using `cagg_migrate`. The user performing the migration must have
+the following permissions:
+
+* Select, insert, and update permissions on the tables
+ `_timescale_catalog.continuous_agg_migrate_plan` and
+ `_timescale_catalog.continuous_agg_migrate_plan_step`
+* Usage permissions on the sequence
+ `_timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq`
+
+To solve the problem, change to a user capable of granting permissions, and
+grant the following permissions to the user performing the migration:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/compression-on-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL cagg_migrate('');
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM _timescaledb_catalog.continuous_agg_migrate_plan_step;
+```
+
+Example 3 (sql):
+```sql
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan TO ;
+GRANT SELECT, INSERT, UPDATE ON TABLE _timescaledb_catalog.continuous_agg_migrate_plan_step TO ;
+GRANT USAGE ON SEQUENCE _timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq TO ;
+```
+
+---
+
+## Refresh continuous aggregates
+
+**URL:** llms-txt#refresh-continuous-aggregates
+
+**Contents:**
+- Prerequisites
+- Change the refresh policy
+- Add concurrent refresh policies
+- Manually refresh a continuous aggregate
+
+Continuous aggregates can have a range of different refresh policies. In
+addition to refreshing the continuous aggregate automatically using a policy,
+you can also refresh it manually.
+
+To follow the procedure on this page you need to:
+
+* Create a [target Tiger Cloud service][create-service].
+
+This procedure also works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Change the refresh policy
+
+Continuous aggregates require a policy for automatic refreshing. You can adjust
+this to suit different use cases. For example, you can have the continuous
+aggregate and the hypertable stay in sync, even when data is removed from the
+hypertable. Alternatively, you could keep source data in the continuous aggregate even after
+it is removed from the hypertable.
+
+You can change the way your continuous aggregate is refreshed by calling
+`add_continuous_aggregate_policy`.
+
+Among others, `add_continuous_aggregate_policy` takes the following arguments:
+
+* `start_offset`: the start of the refresh window relative to when the policy
+ runs
+* `end_offset`: the end of the refresh window relative to when the policy runs
+* `schedule_interval`: the refresh interval in minutes or hours. Defaults to
+ 24 hours.
+
+- If you set the `start_offset` or `end_offset` to `NULL`, the range is open-ended and extends to the beginning or end of time.
+- If you set `end_offset` within the current time bucket, this bucket is excluded from materialization. This is done for the following reasons:
+
+- The current bucket is incomplete and can't be refreshed.
+ - The current bucket gets a lot of writes in the timestamp order, and its aggregate becomes outdated very quickly. Excluding it improves performance.
+
+To include the latest raw data in queries, enable [real-time aggregation][future-watermark].
+
+See the [API reference][api-reference] for the full list of required and optional arguments and use examples.
+
+The policy in the following example ensures that all data in the continuous aggregate is up to date with the hypertable, except for data written within the last hour of wall-clock time. The policy also does not refresh the last time bucket of the continuous aggregate.
+
+Since the policy in this example runs once every hour (`schedule_interval`) while also excluding data within the most recent hour (`end_offset`), it takes up to 2 hours for data written to the hypertable to be reflected in the continuous aggregate. Backfills, which are usually outside the most recent hour of data, will be visible after up to 1 hour depending on when the policy last ran when the data was written.
+
+Because it has an open-ended `start_offset` parameter, any data that is removed
+from the table, for example with a `DELETE` or with `drop_chunks`, is also removed
+from the continuous aggregate view. This means that the continuous aggregate
+always reflects the data in the underlying hypertable.
+
+To changing a refresh policy to use a `NULL` `start_offset`:
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_hourly` that keeps the continuous aggregate up to date, and runs every hour:
+
+If you want to keep data in the continuous aggregate even if it is removed from
+the underlying hypertable, you can set the `start_offset` to match the
+[data retention policy][sec-data-retention] on the source hypertable. For example,
+if you have a retention policy that removes data older than one month, set
+`start_offset` to one month or less. This sets your policy so that it does not
+refresh the dropped data.
+
+1. Connect to your Tiger Cloud service.
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_hourly`
+ that keeps data removed from the hypertable in the continuous aggregate, and
+ runs every hour:
+
+It is important to consider your data retention policies when you're setting up
+continuous aggregate policies. If the continuous aggregate policy window covers
+data that is removed by the data retention policy, the data will be removed when
+the aggregates for those buckets are refreshed. For example, if you have a data
+retention policy that removes all data older than two weeks, the continuous
+aggregate policy will only have data for the last two weeks.
+
+## Add concurrent refresh policies
+
+You can add concurrent refresh policies on each continuous aggregate, as long as their
+start and end offsets don't overlap. For example, to backfill data into older chunks you
+set up one policy that refreshes recent data, and another that refreshes backfilled data.
+
+The first policy in this example is keeps the continuous aggregate up to date with data that was
+inserted in the past day. Any data that was inserted or updated for previous days is refreshed by
+the second policy.
+
+1. Connect to your Tiger Cloud service.
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. Create a new policy on `conditions_summary_daily`
+ to refresh the continuous aggregate with recently inserted data which runs
+ hourly:
+
+2. At the `psql` prompt, create a concurrent policy on
+ `conditions_summary_daily` to refresh the continuous aggregate with
+ backfilled data:
+
+## Manually refresh a continuous aggregate
+
+If you need to manually refresh a continuous aggregate, you can use the
+`refresh` command. This recomputes the data within the window that has changed
+in the underlying hypertable since the last refresh. Therefore, if only a few
+buckets need updating, the refresh runs quickly.
+
+If you have recently dropped data from a hypertable with a continuous aggregate,
+calling `refresh_continuous_aggregate` on a region containing dropped chunks
+recalculates the aggregate without the dropped data. See
+[drop data][cagg-drop-data] for more information.
+
+The `refresh` command takes three arguments:
+
+* The name of the continuous aggregate view to refresh
+* The timestamp of the beginning of the refresh window
+* The timestamp of the end of the refresh window
+
+Only buckets that are wholly within the specified range are refreshed. For
+example, if you specify `2021-05-01', '2021-06-01` the only buckets that are
+refreshed are those up to but not including 2021-06-01. It is possible to
+specify `NULL` in a manual refresh to get an open-ended range, but we do not
+recommend using it, because you could inadvertently materialize a large amount
+of data, slow down your performance, and have unintended consequences on other
+policies like data retention.
+
+To manually refresh a continuous aggregate, use the `refresh` command:
+
+Follow the logic used by automated refresh policies and avoid refreshing time buckets that are likely to have a lot of writes. This means that you should generally not refresh the latest incomplete time bucket. To include the latest raw data in your queries, use [real-time aggregation][real-time-aggregates] instead.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/drop-data/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_hourly',
+ start_offset => NULL,
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_hourly',
+ start_offset => INTERVAL '1 month',
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 3 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_daily',
+ start_offset => INTERVAL '1 day',
+ end_offset => INTERVAL '1 h',
+ schedule_interval => INTERVAL '1 h');
+```
+
+Example 4 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_daily',
+ start_offset => NULL
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+---
diff --git a/skills/timescaledb/references/getting_started.md b/skills/timescaledb/references/getting_started.md
new file mode 100644
index 0000000..d1b704d
--- /dev/null
+++ b/skills/timescaledb/references/getting_started.md
@@ -0,0 +1,2098 @@
+# Timescaledb - Getting Started
+
+**Pages:** 3
+
+---
+
+## Start coding with Tiger Data
+
+**URL:** llms-txt#start-coding-with-tiger-data
+
+Easily integrate your app with Tiger Cloud or self-hosted TimescaleDB. Use your favorite programming language to connect to your
+Tiger Cloud service, create and manage hypertables, then ingest and query data.
+
+---
+
+## "Quick Start: Ruby and TimescaleDB"
+
+**URL:** llms-txt#"quick-start:-ruby-and-timescaledb"
+
+**Contents:**
+- Prerequisites
+- Connect a Rails app to your service
+- Optimize time-series data in hypertables
+- Insert data your service
+- Reference
+ - Query scopes
+ - TimescaleDB features
+- Next steps
+- Load energy consumption data
+ - 6e. Enable policies that compress data in the target hypertable
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Rails][rails-guide].
+
+## Connect a Rails app to your service
+
+Every Tiger Cloud service is a 100% Postgres database hosted in Tiger Cloud with
+Tiger Data extensions such as TimescaleDB. You connect to your Tiger Cloud service
+from a standard Rails app configured for Postgres.
+
+1. **Create a new Rails app configured for Postgres**
+
+Rails creates and bundles your app, then installs the standard Postgres Gems.
+
+1. **Install the TimescaleDB gem**
+
+1. Open `Gemfile`, add the following line, then save your changes:
+
+1. In Terminal, run the following command:
+
+1. **Connect your app to your Tiger Cloud service**
+
+1. In `/config/database.yml` update the configuration to read securely connect to your Tiger Cloud service
+ by adding `url: <%= ENV['DATABASE_URL'] %>` to the default configuration:
+
+1. Set the environment variable for `DATABASE_URL` to the value of `Service URL` from
+ your [connection details][connection-info]
+
+1. Create the database:
+ - **Tiger Cloud**: nothing to do. The database is part of your Tiger Cloud service.
+ - **Self-hosted TimescaleDB**, create the database for the project:
+
+1. Verify the connection from your app to your Tiger Cloud service:
+
+The result shows the list of extensions in your Tiger Cloud service
+
+| Name | Version | Schema | Description |
+ | -- | -- | -- | -- |
+ | pg_buffercache | 1.5 | public | examine the shared buffer cache|
+ | pg_stat_statements | 1.11 | public | track planning and execution statistics of all SQL statements executed|
+ | plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language|
+ | postgres_fdw | 1.1 | public | foreign-data wrapper for remote Postgres servers|
+ | timescaledb | 2.18.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)|
+ | timescaledb_toolkit | 1.19.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities|
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables designed to simplify and accelerate data analysis. Anything
+you can do with regular Postgres tables, you can do with hypertables - but much faster and more conveniently.
+
+In this section, you use the helpers in the TimescaleDB gem to create and manage a [hypertable][about-hypertables].
+
+1. **Generate a migration to create the page loads table**
+
+This creates the `/db/migrate/_create_page_loads.rb` migration file.
+
+1. **Add hypertable options**
+
+Replace the contents of `/db/migrate/_create_page_loads.rb`
+ with the following:
+
+The `id` column is not included in the table. This is because TimescaleDB requires that any `UNIQUE` or `PRIMARY KEY`
+ indexes on the table include all partitioning columns. In this case, this is the time column. A new
+ Rails model includes a `PRIMARY KEY` index for id by default: either remove the column or make sure that the index
+ includes time as part of a "composite key."
+
+For more information, check the Roby docs around [composite primary keys][rails-compostite-primary-keys].
+
+1. **Create a `PageLoad` model**
+
+Create a new file called `/app/models/page_load.rb` and add the following code:
+
+1. **Run the migration**
+
+## Insert data your service
+
+The TimescaleDB gem provides efficient ways to insert data into hypertables. This section
+shows you how to ingest test data into your hypertable.
+
+1. **Create a controller to handle page loads**
+
+Create a new file called `/app/controllers/application_controller.rb` and add the following code:
+
+1. **Generate some test data**
+
+Use `bin/console` to join a Rails console session and run the following code
+ to define some random page load access data:
+
+1. **Insert the generated data into your Tiger Cloud service**
+
+1. **Validate the test data in your Tiger Cloud service**
+
+This section lists the most common tasks you might perform with the TimescaleDB gem.
+
+The TimescaleDB gem provides several convenient scopes for querying your time-series data.
+
+- Built-in time-based scopes:
+
+- Browser-specific scopes:
+
+- Query continuous aggregates:
+
+This query fetches the average and standard deviation from the performance stats for the `/products` path over the last day.
+
+### TimescaleDB features
+
+The TimescaleDB gem provides utility methods to access hypertable and chunk information. Every model that uses
+the `acts_as_hypertable` method has access to these methods.
+
+#### Access hypertable and chunk information
+
+- View chunk or hypertable information:
+
+- Compress/Decompress chunks:
+
+#### Access hypertable stats
+
+You collect hypertable stats using methods that provide insights into your hypertable's structure, size, and compression
+status:
+
+- Get basic hypertable information:
+
+- Get detailed size information:
+
+#### Continuous aggregates
+
+The `continuous_aggregates` method generates a class for each continuous aggregate.
+
+- Get all the continuous aggregate classes:
+
+- Manually refresh a continuous aggregate:
+
+- Create or drop a continuous aggregate:
+
+Create or drop all the continuous aggregates in the proper order to build them hierarchically. See more about how it
+ works in this [blog post][ruby-blog-post].
+
+Now that you have integrated the ruby gem into your app:
+
+* Learn more about the [TimescaleDB gem](https://github.com/timescale/timescaledb-ruby).
+* Check out the [official docs](https://timescale.github.io/timescaledb-ruby/).
+* Follow the [LTTB][LTTB], [Open AI long-term storage][open-ai-tutorial], and [candlesticks][candlesticks] tutorials.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_add-data-energy/ =====
+
+## Load energy consumption data
+
+When you have your database set up, you can load the energy consumption data
+into the `metrics` hypertable.
+
+This is a large dataset, so it might take a long time, depending on your network
+connection.
+
+1. Download the dataset:
+
+[metrics.csv.gz](https://assets.timescale.com/docs/downloads/metrics.csv.gz)
+
+1. Use your file manager to decompress the downloaded dataset, and take a note
+ of the path to the `metrics.csv` file.
+
+1. At the psql prompt, copy the data from the `metrics.csv` file into
+ your hypertable. Make sure you point to the correct path, if it is not in
+ your current working directory:
+
+1. You can check that the data has been copied successfully with this command:
+
+You should get five records that look like this:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_dump_database_roles/ =====
+
+Tiger Cloud services do not support roles with superuser access. If your SQL
+dump includes roles that have such permissions, you'll need to modify the file
+to be compliant with the security model.
+
+You can use the following `sed` command to remove unsupported statements and
+permissions from your roles.sql file:
+
+This command works only with the GNU implementation of sed (sometimes referred
+to as gsed). For the BSD implementation (the default on macOS), you need to
+add an extra argument to change the `-i` flag to `-i ''`.
+
+To check the sed version, you can use the command `sed --version`. While the
+GNU version explicitly identifies itself as GNU, the BSD version of sed
+generally doesn't provide a straightforward --version flag and simply outputs
+an "illegal option" error.
+
+A brief explanation of this script is:
+
+- `CREATE ROLE "postgres"`; and `ALTER ROLE "postgres"`: These statements are
+ removed because they require superuser access, which is not supported
+ by Timescale.
+
+- `(NO)SUPERUSER` | `(NO)REPLICATION` | `(NO)BYPASSRLS`: These are permissions
+ that require superuser access.
+
+- `GRANTED BY role_specification`: The GRANTED BY clause can also have permissions that
+ require superuser access and should therefore be removed. Note: according to the
+ TimescaleDB documentation, the GRANTOR in the GRANTED BY clause must be the
+ current user, and this clause mainly serves the purpose of SQL compatibility.
+ Therefore, it's safe to remove it.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-debian-based-start/ =====
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_free-plan-beta/ =====
+
+The Free pricing plan and services are currently in beta.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_livesync-configure-source-database/ =====
+
+1. **Tune the Write Ahead Log (WAL) on the Postgres source database**
+
+* [GUC “wal_level” as “logical”](https://www.postgresql.org/docs/current/runtime-config-wal.html#GUC-WAL-LEVEL)
+ * [GUC “max_wal_senders” as 10](https://www.postgresql.org/docs/current/runtime-config-replication.html#GUC-MAX-WAL-SENDERS)
+ * [GUC “wal_sender_timeout” as 0](https://www.postgresql.org/docs/current/runtime-config-replication.html#GUC-WAL-SENDER-TIMEOUT)
+
+This will require a restart of the Postgres source database.
+
+1. **Create a user for the connector and assign permissions**
+
+1. Create ``:
+
+You can use an existing user. However, you must ensure that the user has the following permissions.
+
+1. Grant permissions to create a replication slot:
+
+1. Grant permissions to create a publication:
+
+1. Assign the user permissions on the source database:
+
+If the tables you are syncing are not in the `public` schema, grant the user permissions for each schema you are syncing:
+
+1. On each table you want to sync, make `` the owner:
+
+You can skip this step if the replicating user is already the owner of the tables.
+
+1. **Enable replication `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_datadog-data-exporter/ =====
+
+1. **In Tiger Cloud Console, open [Exporters][console-integrations]**
+1. **Click `New exporter`**
+1. **Select `Metrics` for `Data type` and `Datadog` for provider**
+
+
+
+1. **Choose your AWS region and provide the API key**
+
+The AWS region must be the same for your Tiger Cloud exporter and the Datadog provider.
+
+1. **Set `Site` to your Datadog region, then click `Create exporter`**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_6e_turn_on_compression_policies/ =====
+
+### 6e. Enable policies that compress data in the target hypertable
+
+In the following command, replace `` with the fully qualified table
+name of the target hypertable, for example `public.metrics`:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-redhat-rocky/ =====
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-mst-restart-workers/ =====
+
+On Tiger Cloud and Managed Service for TimescaleDB, restart background workers by doing one of the following:
+
+* Run `SELECT timescaledb_pre_restore()`, followed by `SELECT
+ timescaledb_post_restore()`.
+* Power the service off and on again. This might cause a downtime of a few
+ minutes while the service restores from backup and replays the write-ahead
+ log.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_setup_enable_replication/ =====
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_timescale-cloud-platforms/ =====
+
+You use Tiger Data's open-source products to create your best app from the comfort of your own developer environment.
+
+See the [available services][available-services] and [supported systems][supported-systems].
+
+### Available services
+
+Tiger Data offers the following services for your self-hosted installations:
+
+
+
+ | Service type |
+ Description |
+
+
+
+
+ | Self-hosted support |
+ - 24/7 support no matter where you are.
- An experienced global ops and support team that
+ can build and manage Postgres at scale.
+ Want to try it out? See how we can help.
+ |
+
+
+
+
+### Postgres, TimescaleDB support matrix
+
+TimescaleDB and TimescaleDB Toolkit run on Postgres v10, v11, v12, v13, v14, v15, v16, and v17. Currently Postgres 15 and higher are supported.
+
+| TimescaleDB version |Postgres 17|Postgres 16|Postgres 15|Postgres 14|Postgres 13|Postgres 12|Postgres 11|Postgres 10|
+|-----------------------|-|-|-|-|-|-|-|-|
+| 2.22.x |✅|✅|✅|❌|❌|❌|❌|❌|❌|
+| 2.21.x |✅|✅|✅|❌|❌|❌|❌|❌|❌|
+| 2.20.x |✅|✅|✅|❌|❌|❌|❌|❌|❌|
+| 2.17 - 2.19 |✅|✅|✅|✅|❌|❌|❌|❌|❌|
+| 2.16.x |❌|✅|✅|✅|❌|❌|❌|❌|❌|❌|
+| 2.13 - 2.15 |❌|✅|✅|✅|✅|❌|❌|❌|❌|
+| 2.12.x |❌|❌|✅|✅|✅|❌|❌|❌|❌|
+| 2.10.x |❌|❌|✅|✅|✅|✅|❌|❌|❌|
+| 2.5 - 2.9 |❌|❌|❌|✅|✅|✅|❌|❌|❌|
+| 2.4 |❌|❌|❌|❌|✅|✅|❌|❌|❌|
+| 2.1 - 2.3 |❌|❌|❌|❌|✅|✅|✅|❌|❌|
+| 2.0 |❌|❌|❌|❌|❌|✅|✅|❌|❌
+| 1.7 |❌|❌|❌|❌|❌|✅|✅|✅|✅|
+
+We recommend not using TimescaleDB with Postgres 17.1, 16.5, 15.9, 14.14, 13.17, 12.21.
+These minor versions [introduced a breaking binary interface change][postgres-breaking-change] that,
+once identified, was reverted in subsequent minor Postgres versions 17.2, 16.6, 15.10, 14.15, 13.18, and 12.22.
+When you build from source, best practice is to build with Postgres 17.2, 16.6, etc and higher.
+Users of [Tiger Cloud](https://console.cloud.timescale.com/) and platform packages for Linux, Windows, MacOS,
+Docker, and Kubernetes are unaffected.
+
+### Supported operating system
+
+You can deploy TimescaleDB and TimescaleDB Toolkit on the following systems:
+
+| Operation system | Version |
+|---------------------------------|-----------------------------------------------------------------------|
+| Debian | 13 Trixe, 12 Bookworm, 11 Bullseye |
+| Ubuntu | 24.04 Noble Numbat, 22.04 LTS Jammy Jellyfish |
+| Red Hat Enterprise | Linux 9, Linux 8 |
+| Fedora | Fedora 35, Fedora 34, Fedora 33 |
+| Rocky Linux | Rocky Linux 9 (x86_64), Rocky Linux 8 |
+| ArchLinux (community-supported) | Check the [available packages][archlinux-packages] |
+
+| Operation system | Version |
+|---------------------------------------------|------------|
+| Microsoft Windows | 10, 11 |
+| Microsoft Windows Server | 2019, 2020 |
+
+| Operation system | Version |
+|-------------------------------|----------------------------------|
+| macOS | From 10.15 Catalina to 14 Sonoma |
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_install_psql_ec2_instance/ =====
+
+## Install the psql client tools on the intermediary instance
+
+1. Connect to your intermediary EC2 instance. For example:
+
+1. On your intermediary EC2 instance, install the Postgres client.
+
+Keep this terminal open, you need it to connect to the RDS instance for migration.
+
+## Setup secure connectivity between your RDS and EC2 instances
+1. In [https://console.aws.amazon.com/rds/home#databases:](https://console.aws.amazon.com/rds/home#databases:),
+ select the RDS instance to migrate.
+1. Scroll down to `Security group rules (1)` and select the `EC2 Security Group - Inbound` group. The
+ `Security Groups (1)` window opens. Click the `Security group ID`, then click `Edit inbound rules`
+
+ +
+1. On your intermediary EC2 instance, get your local IP address:
+
+ Bear with me on this one, you need this IP address to enable access to your RDS instance,
+1. In `Edit inbound rules`, click `Add rule`, then create a `PostgreSQL`, `TCP` rule granting access
+ to the local IP address for your EC2 instance (told you :-)). Then click `Save rules`.
+
+
+
+1. On your intermediary EC2 instance, get your local IP address:
+
+ Bear with me on this one, you need this IP address to enable access to your RDS instance,
+1. In `Edit inbound rules`, click `Add rule`, then create a `PostgreSQL`, `TCP` rule granting access
+ to the local IP address for your EC2 instance (told you :-)). Then click `Save rules`.
+
+ +
+## Test the connection between your RDS and EC2 instances
+1. In [https://console.aws.amazon.com/rds/home#databases:](https://console.aws.amazon.com/rds/home#databases:),
+ select the RDS instance to migrate.
+1. On your intermediary EC2 instance, use the values of `Endpoint`, `Port`, `Master username`, and `DB name`
+ to create the postgres connectivity string to the `SOURCE` variable.
+
+
+
+## Test the connection between your RDS and EC2 instances
+1. In [https://console.aws.amazon.com/rds/home#databases:](https://console.aws.amazon.com/rds/home#databases:),
+ select the RDS instance to migrate.
+1. On your intermediary EC2 instance, use the values of `Endpoint`, `Port`, `Master username`, and `DB name`
+ to create the postgres connectivity string to the `SOURCE` variable.
+
+ +
+The value of `Master password` was supplied when this Postgres RDS instance was created.
+
+1. Test your connection:
+
+ You are connected to your RDS instance from your intermediary EC2 instance.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_setup_connection_strings/ =====
+
+These variables hold the connection information for the source database and target Tiger Cloud service.
+In Terminal on your migration machine, set the following:
+
+You find the connection information for your Tiger Cloud service in the configuration file you
+downloaded when you created the service.
+
+Avoid using connection strings that route through connection poolers like PgBouncer or similar tools. This tool requires a direct connection to the database to function properly.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_psql-installation-windows/ =====
+
+## Install psql on Windows
+
+The `psql` tool is installed by default on Windows systems when you install
+Postgres, and this is the most effective way to install the tool. These
+instructions use the interactive installer provided by Postgres and
+EnterpriseDB.
+
+### Installing psql on Windows
+
+1. Download and run the Postgres installer from
+ [www.enterprisedb.com][windows-installer].
+1. In the `Select Components` dialog, check `Command Line Tools`, along with
+ any other components you want to install, and click `Next`.
+1. Complete the installation wizard to install the package.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_run_live_migration/ =====
+
+1. **Pull the live-migration docker image to you migration machine**
+
+To list the available commands, run:
+
+ To see the available flags for each command, run `--help` for that command. For example:
+
+1. **Create a snapshot image of your source database in your Tiger Cloud service**
+
+This process checks that you have tuned your source database and target service correctly for replication,
+ then creates a snapshot of your data on the migration machine:
+
+Live-migration supplies information about updates you need to make to the source database and target service. For example:
+
+If you have warnings, stop live-migration, make the suggested changes and start again.
+
+1. **Synchronize data between your source database and your Tiger Cloud service**
+
+This command migrates data from the snapshot to your Tiger Cloud service, then streams
+ transactions from the source to the target.
+
+If the source Postgres version is 17 or later, you need to pass additional
+ flag `-e PGVERSION=17` to the `migrate` command.
+
+After migrating the schema, live-migration prompts you to create hypertables for tables that
+ contain time-series data in your Tiger Cloud service. Run `create_hypertable()` to convert these
+ table. For more information, see the [Hypertable docs][Hypertable docs].
+
+During this process, you see the migration process:
+
+If `migrate` stops add `--resume` to start from where it left off.
+
+Once the data in your target Tiger Cloud service has almost caught up with the source database,
+ you see the following message:
+
+Wait until `replay_lag` is down to a few kilobytes before you move to the next step. Otherwise, data
+ replication may not have finished.
+
+1. **Start app downtime**
+
+1. Stop your app writing to the source database, then let the the remaining transactions
+ finish to fully sync with the target. You can use tools like the `pg_top` CLI or
+ `pg_stat_activity` to view the current transaction on the source database.
+
+1. Stop Live-migration.
+
+Live-migration continues the remaining work. This includes copying
+ TimescaleDB metadata, sequences, and run policies. When the migration completes,
+ you see the following message:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_experimental/ =====
+
+Experimental features could have bugs. They might not be backwards compatible,
+and could be removed in future releases. Use these features at your own risk, and
+do not use any experimental features in production.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_compression-intro/ =====
+
+Compressing your time-series data allows you to reduce your chunk size by more
+than 90%. This saves on storage costs, and keeps your queries operating at
+lightning speed.
+
+When you enable compression, the data in your hypertable is compressed chunk by
+chunk. When the chunk is compressed, multiple records are grouped into a single
+row. The columns of this row hold an array-like structure that stores all the
+data. This means that instead of using lots of rows to store the data, it stores
+the same data in a single row. Because a single row takes up less disk space
+than many rows, it decreases the amount of disk space required, and can also
+speed up your queries.
+
+For example, if you had a table with data that looked a bit like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|12:00:01|A|SSD|70.11|13.4|
+|12:00:01|B|HDD|69.70|20.5|
+|12:00:02|A|SSD|70.12|13.2|
+|12:00:02|B|HDD|69.69|23.4|
+|12:00:03|A|SSD|70.14|13.0|
+|12:00:03|B|HDD|69.70|25.2|
+
+You can convert this to a single row in array form, like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[SSD, HDD, SSD, HDD, SSD, HDD]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|[13.4, 20.5, 13.2, 23.4, 13.0, 25.2]|
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-only/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with real-time analytics enabled.
+
+You need your [connection details][connection-info].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypercore_manual_workflow/ =====
+
+1. **Stop the jobs that are automatically adding chunks to the columnstore**
+
+Retrieve the list of jobs from the [timescaledb_information.jobs][informational-views] view
+ to find the job you need to [alter_job][alter_job].
+
+1. **Convert a chunk to update back to the rowstore**
+
+1. **Update the data in the chunk you added to the rowstore**
+
+Best practice is to structure your [INSERT][insert] statement to include appropriate
+ partition key values, such as the timestamp. TimescaleDB adds the data to the correct chunk:
+
+1. **Convert the updated chunks back to the columnstore**
+
+1. **Restart the jobs that are automatically converting chunks to the columnstore**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dump_roles_schema_data_mst/ =====
+
+1. **Dump the roles from your source database**
+
+Export your role-based security hierarchy. `` has the same value as `` in `source`.
+ I know, it confuses me as well.
+
+MST does not allow you to export passwords with roles. You assign passwords to these roles
+ when you have uploaded them to your Tiger Cloud service.
+
+1. **Remove roles with superuser access**
+
+Tiger Cloud services do not support roles with superuser access. Run the following script
+ to remove statements, permissions and clauses that require superuser permissions from `roles.sql`:
+
+1. **Dump the source database schema and data**
+
+The `pg_dump` flags remove superuser access and tablespaces from your data. When you run
+ `pgdump`, check the run time, [a long-running `pg_dump` can cause issues][long-running-pgdump].
+
+To dramatically reduce the time taken to dump the source database, using multiple connections. For more information,
+ see [dumping with concurrency][dumping-with-concurrency] and [restoring with concurrency][restoring-with-concurrency].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_migrate_data_timescaledb/ =====
+
+## Migrate your data, then start downtime
+2. **Pull the live-migration docker image to you migration machine**
+
+To list the available commands, run:
+
+ To see the available flags for each command, run `--help` for that command. For example:
+
+1. **Create a snapshot image of your source database in your Tiger Cloud service**
+
+This process checks that you have tuned your source database and target service correctly for replication,
+ then creates a snapshot of your data on the migration machine:
+
+Live-migration supplies information about updates you need to make to the source database and target service. For example:
+
+If you have warnings, stop live-migration, make the suggested changes and start again.
+
+1. **Synchronize data between your source database and your Tiger Cloud service**
+
+This command migrates data from the snapshot to your Tiger Cloud service, then streams
+ transactions from the source to the target.
+
+If the source Postgres version is 17 or later, you need to pass additional
+ flag `-e PGVERSION=17` to the `migrate` command.
+
+During this process, you see the migration process:
+
+If `migrate` stops add `--resume` to start from where it left off.
+
+Once the data in your target Tiger Cloud service has almost caught up with the source database,
+ you see the following message:
+
+Wait until `replay_lag` is down to a few kilobytes before you move to the next step. Otherwise, data
+ replication may not have finished.
+
+1. **Start app downtime**
+
+1. Stop your app writing to the source database, then let the the remaining transactions
+ finish to fully sync with the target. You can use tools like the `pg_top` CLI or
+ `pg_stat_activity` to view the current transaction on the source database.
+
+1. Stop Live-migration.
+
+Live-migration continues the remaining work. This includes copying
+ TimescaleDB metadata, sequences, and run policies. When the migration completes,
+ you see the following message:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-account-only/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Data account][create-account].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_set_up_database_first_steps/ =====
+
+1. **Take the applications that connect to the source database offline**
+
+The duration of the migration is proportional to the amount of data stored in your database. By
+ disconnection your app from your database you avoid and possible data loss.
+
+1. **Set your connection strings**
+
+These variables hold the connection information for the source database and target Tiger Cloud service:
+
+You find the connection information for your Tiger Cloud service in the configuration file you
+ downloaded when you created the service.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-redhat/ =====
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_chunk-interval/ =====
+
+Postgres builds the index on the fly during ingestion. That means that to build a new entry on the index,
+a significant portion of the index needs to be traversed during every row insertion. When the index does not fit
+into memory, it is constantly flushed to disk and read back. This wastes IO resources which would otherwise
+be used for writing the heap/WAL data to disk.
+
+The default chunk interval is 7 days. However, best practice is to set `chunk_interval` so that prior to processing,
+the indexes for chunks currently being ingested into fit within 25% of main memory. For example, on a system with 64
+GB of memory, if index growth is approximately 2 GB per day, a 1-week chunk interval is appropriate. If index growth is
+around 10 GB per day, use a 1-day interval.
+
+You set `chunk_interval` when you [create a hypertable][hypertable-create-table], or by calling
+[`set_chunk_time_interval`][chunk_interval] on an existing hypertable.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_tune_source_database_mst/ =====
+
+1. **Enable live-migration to replicate `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_tutorials_hypertable_intro/ =====
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypertable-intro/ =====
+
+Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
+
+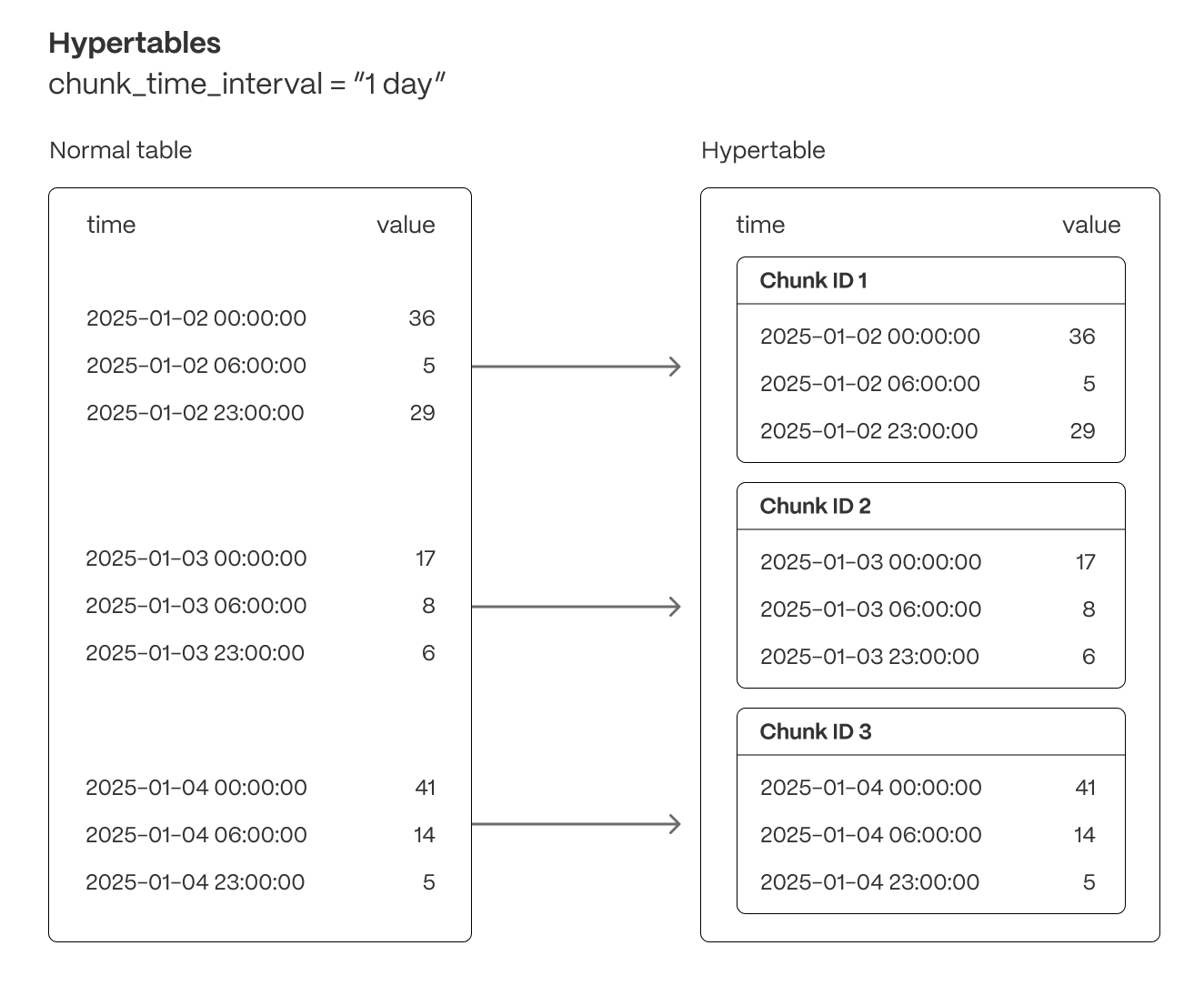
+
+Hypertables offer the following benefits:
+
+- **Efficient data management with [automated partitioning by time][chunk-size]**: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
+
+- **Better performance with [strategic indexing][hypertable-indexes]**: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
+
+- **Faster queries with [chunk skipping][chunk-skipping]**: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
+
+- **Advanced data analysis with [hyperfunctions][hyperfunctions]**: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+
+To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.
+
+Inheritance is not supported for hypertables and may lead to unexpected behavior.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_kubernetes-install-self-hosted/ =====
+
+Running TimescaleDB on Kubernetes is similar to running Postgres. This procedure outlines the steps for a non-distributed system.
+
+To connect your Kubernetes cluster to self-hosted TimescaleDB running in the cluster:
+
+1. **Create a default namespace for Tiger Data components**
+
+1. Create the Tiger Data namespace:
+
+1. Set this namespace as the default for your session:
+
+For more information, see [Kubernetes Namespaces][kubernetes-namespace].
+
+1. **Set up a persistent volume claim (PVC) storage**
+
+To manually set up a persistent volume and claim for self-hosted Kubernetes, run the following command:
+
+1. **Deploy TimescaleDB as a StatefulSet**
+
+By default, the [TimescaleDB Docker image][timescale-docker-image] you are installing on Kubernetes uses the
+ default Postgres database, user and password. To deploy TimescaleDB on Kubernetes, run the following command:
+
+1. **Allow applications to connect by exposing TimescaleDB within Kubernetes**
+
+1. **Create a Kubernetes secret to store the database credentials**
+
+1. **Deploy an application that connects to TimescaleDB**
+
+1. **Test the database connection**
+
+1. Create and run a pod to verify database connectivity using your [connection details][connection-info] saved in `timescale-secret`:
+
+1. Launch the Postgres interactive shell within the created `test-pod`:
+
+You see the Postgres interactive terminal.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-migrate-permissions/ =====
+
+You might get a permissions error when migrating a continuous aggregate from old
+to new format using `cagg_migrate`. The user performing the migration must have
+the following permissions:
+
+* Select, insert, and update permissions on the tables
+ `_timescale_catalog.continuous_agg_migrate_plan` and
+ `_timescale_catalog.continuous_agg_migrate_plan_step`
+* Usage permissions on the sequence
+ `_timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq`
+
+To solve the problem, change to a user capable of granting permissions, and
+grant the following permissions to the user performing the migration:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_candlestick_intro/ =====
+
+The financial sector regularly uses [candlestick charts][charts] to visualize
+the price change of an asset. Each candlestick represents a time period, such as
+one minute or one hour, and shows how the asset's price changed during that time.
+
+Candlestick charts are generated from the open, high, low, close, and volume
+data for each financial asset during the time period. This is often abbreviated
+as OHLCV:
+
+* Open: opening price
+* High: highest price
+* Low: lowest price
+* Close: closing price
+* Volume: volume of transactions
+
+===== PAGE: https://docs.tigerdata.com/_partials/_start-coding-java/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the [Java Development Kit (JDK)][jdk].
+* Install the [PostgreSQL JDBC driver][pg-jdbc-driver].
+
+All code in this quick start is for Java 16 and later. If you are working
+with older JDK versions, use legacy coding techniques.
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to your service using an application in
+a single file. You can use any of your favorite build tools, including `gradle`
+or `maven`.
+
+1. Create a directory containing a text file called `Main.java`, with this content:
+
+1. From the command line in the current directory, run the application:
+
+If the command is successful, `Hello, World!` line output is printed
+ to your console.
+
+1. Import the PostgreSQL JDBC driver. If you are using a dependency manager,
+ include the [PostgreSQL JDBC Driver][pg-jdbc-driver-dependency] as a
+ dependency.
+
+1. Download the [JAR artifact of the JDBC Driver][pg-jdbc-driver-artifact] and
+ save it with the `Main.java` file.
+
+1. Import the `JDBC Driver` into the Java application and display a list of
+ available drivers for the check:
+
+1. Run all the examples:
+
+If the command is successful, a string similar to
+ `org.postgresql.Driver@7f77e91b` is printed to your console. This means that you
+ are ready to connect to TimescaleDB from Java.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for JDBC.
+
+* password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+For more information about creating connection strings, see the [JDBC documentation][pg-jdbc-driver-conn-docs].
+
+This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+If the command is successful, a string similar to
+ `{ApplicationName=PostgreSQL JDBC Driver}` is printed to your console.
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+1. Create a statement, execute the query you created in the previous step, and
+ check that the table was created successfully:
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+1. Create a statement, execute the query you created in the previous step:
+
+The `by_range` and `by_hash` dimension builder is an addition to TimescaleDB 2.13.
+
+1. Execute the two statements you created, and commit your changes to the
+ database:
+
+You can insert data into your hypertables in several different ways. In this
+section, you can insert single rows, or insert by batches of rows.
+
+1. Open a connection to the database, use prepared statements to formulate the
+ `INSERT` SQL statement, then execute the statement:
+
+If you want to insert a batch of rows by using a batching mechanism. In this
+example, you generate some sample time-series data to insert into the
+`sensor_data` hypertable:
+
+1. Insert batches of rows:
+
+This section covers how to execute queries against your database.
+
+## Execute queries on TimescaleDB
+
+1. Define the SQL query you'd like to run on the database. This example
+ combines time-series and relational data. It returns the average values for
+ every 15 minute interval for sensors with specific type and location.
+
+1. Execute the query with the prepared statement and read out the result set for
+ all `a`-type sensors located on the `floor`:
+
+If the command is successful, you'll see output like this:
+
+Now that you're able to connect, read, and write to a TimescaleDB instance from
+your Java application, and generate the scaffolding necessary to build a new
+application from an existing TimescaleDB instance, be sure to check out these
+advanced TimescaleDB tutorials:
+
+* [Continuous Aggregates][continuous-aggregates]
+* [Migrate Your own Data][migrate]
+
+## Complete code samples
+
+This section contains complete code samples.
+
+### Complete code sample
+
+### Execute more complex queries
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_self_postgres_implement_migration_path/ =====
+
+You cannot upgrade TimescaleDB and Postgres at the same time. You upgrade each product in
+the following steps:
+
+1. **Upgrade TimescaleDB**
+
+1. **If your migration path dictates it, upgrade Postgres**
+
+Follow the procedure in [Upgrade Postgres][upgrade-pg]. The version of TimescaleDB installed
+ in your Postgres deployment must be the same before and after the Postgres upgrade.
+
+1. **If your migration path dictates it, upgrade TimescaleDB again**
+
+1. **Check that you have upgraded to the correct version of TimescaleDB**
+
+Postgres returns something like:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_validate_production_load/ =====
+
+Now that dual-writes have been in place for a while, the target database should
+be holding up to production write traffic. Now would be the right time to
+determine if the target database can serve all production traffic (both reads
+_and_ writes). How exactly this is done is application-specific and up to you
+to determine.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-no-connection/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with real-time analytics enabled.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_import_prerequisites/ =====
+
+Best practice is to use an [Ubuntu EC2 instance][create-ec2-instance] hosted in the same region as your
+Tiger Cloud service as a migration machine. That is, the machine you run the commands on to move your
+data from your source database to your target Tiger Cloud service.
+
+Before you migrate your data:
+
+- Create a target [Tiger Cloud service][created-a-database-service-in-timescale].
+
+Each Tiger Cloud service has a single database that supports the
+ [most popular extensions][all-available-extensions]. Tiger Cloud services do not support tablespaces,
+ and there is no superuser associated with a service.
+ Best practice is to create a Tiger Cloud service with at least 8 CPUs for a smoother experience. A higher-spec instance
+ can significantly reduce the overall migration window.
+
+- To ensure that maintenance does not run during the process, [adjust the maintenance window][adjust-maintenance-window].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypercore-intro-short/ =====
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-intro/ =====
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_kubernetes-prereqs/ =====
+
+- Install [self-managed Kubernetes][kubernetes-install] or sign up for a Kubernetes [Turnkey Cloud Solution][kubernetes-managed].
+- Install [kubectl][kubectl] for command-line interaction with your cluster.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_high-availability-setup/ =====
+
+1. In [Tiger Cloud Console][cloud-login], select the service to enable replication for.
+1. Click `Operations`, then select `High availability`.
+1. Choose your replication strategy, then click `Change configuration`.
+
+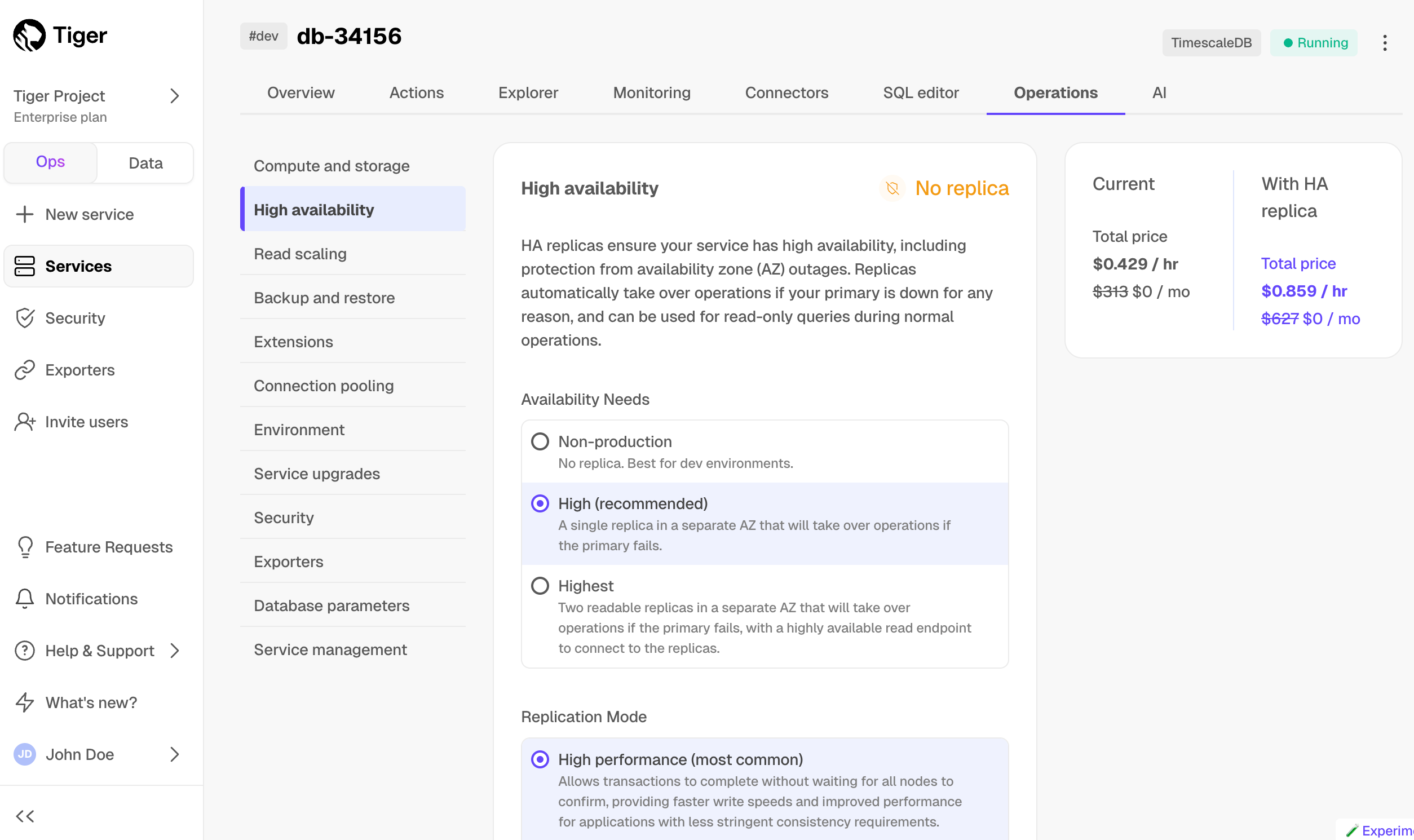
+
+1. In `Change high availability configuration`, click `Change config`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_vpc-limitations/ =====
+
+* You **can attach**:
+ * Up to 50 Customer VPCs to a Peering VPC.
+ * A Tiger Cloud service to a single Peering VPC at a time.
+ The service and the Peering VPC must be in the same AWS region. However, you can peer a Customer VPC and a Peering VPC that are in different regions.
+ * Multiple Tiger Cloud services to the same Peering VPC.
+* You **cannot attach** a Tiger Cloud service to multiple Peering VPCs at the same time.
+
+The number of Peering VPCs you can create in your project depends on your [pricing plan][pricing-plans].
+ If you need another Peering VPC, either contact [support@tigerdata.com](mailto:support@tigerdata.com) or change your pricing plan in [Tiger Cloud Console][console-login].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_integration-apache-kafka-install/ =====
+
+1. **Extract the Kafka binaries to a local folder**
+
+From now on, the folder where you extracted the Kafka binaries is called ``.
+
+1. **Configure and run Apache Kafka**
+
+Use the `-daemon` flag to run this process in the background.
+
+1. **Create Kafka topics**
+
+In another Terminal window, navigate to , then call `kafka-topics.sh` and create the following topics:
+ - `accounts`: publishes JSON messages that are consumed by the timescale-sink connector and inserted into your Tiger Cloud service.
+ - `deadletter`: stores messages that cause errors and that Kafka Connect workers cannot process.
+
+1. **Test that your topics are working correctly**
+ 1. Run `kafka-console-producer` to send messages to the `accounts` topic:
+
+ 1. Send some events. For example, type the following:
+
+ 1. In another Terminal window, navigate to , then run `kafka-console-consumer` to consume the events you just sent:
+
+ You see
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_tune_source_database_awsrds/ =====
+
+Updating parameters on a Postgres instance will cause an outage. Choose a time that will cause the least issues to tune this database.
+
+1. **Update the DB instance parameter group for your source database**
+
+1. In [https://console.aws.amazon.com/rds/home#databases:][databases],
+ select the RDS instance to migrate.
+
+1. Click `Configuration`, scroll down and note the `DB instance parameter group`, then click `Parameter groups`
+
+
+
+The value of `Master password` was supplied when this Postgres RDS instance was created.
+
+1. Test your connection:
+
+ You are connected to your RDS instance from your intermediary EC2 instance.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_setup_connection_strings/ =====
+
+These variables hold the connection information for the source database and target Tiger Cloud service.
+In Terminal on your migration machine, set the following:
+
+You find the connection information for your Tiger Cloud service in the configuration file you
+downloaded when you created the service.
+
+Avoid using connection strings that route through connection poolers like PgBouncer or similar tools. This tool requires a direct connection to the database to function properly.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_psql-installation-windows/ =====
+
+## Install psql on Windows
+
+The `psql` tool is installed by default on Windows systems when you install
+Postgres, and this is the most effective way to install the tool. These
+instructions use the interactive installer provided by Postgres and
+EnterpriseDB.
+
+### Installing psql on Windows
+
+1. Download and run the Postgres installer from
+ [www.enterprisedb.com][windows-installer].
+1. In the `Select Components` dialog, check `Command Line Tools`, along with
+ any other components you want to install, and click `Next`.
+1. Complete the installation wizard to install the package.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_run_live_migration/ =====
+
+1. **Pull the live-migration docker image to you migration machine**
+
+To list the available commands, run:
+
+ To see the available flags for each command, run `--help` for that command. For example:
+
+1. **Create a snapshot image of your source database in your Tiger Cloud service**
+
+This process checks that you have tuned your source database and target service correctly for replication,
+ then creates a snapshot of your data on the migration machine:
+
+Live-migration supplies information about updates you need to make to the source database and target service. For example:
+
+If you have warnings, stop live-migration, make the suggested changes and start again.
+
+1. **Synchronize data between your source database and your Tiger Cloud service**
+
+This command migrates data from the snapshot to your Tiger Cloud service, then streams
+ transactions from the source to the target.
+
+If the source Postgres version is 17 or later, you need to pass additional
+ flag `-e PGVERSION=17` to the `migrate` command.
+
+After migrating the schema, live-migration prompts you to create hypertables for tables that
+ contain time-series data in your Tiger Cloud service. Run `create_hypertable()` to convert these
+ table. For more information, see the [Hypertable docs][Hypertable docs].
+
+During this process, you see the migration process:
+
+If `migrate` stops add `--resume` to start from where it left off.
+
+Once the data in your target Tiger Cloud service has almost caught up with the source database,
+ you see the following message:
+
+Wait until `replay_lag` is down to a few kilobytes before you move to the next step. Otherwise, data
+ replication may not have finished.
+
+1. **Start app downtime**
+
+1. Stop your app writing to the source database, then let the the remaining transactions
+ finish to fully sync with the target. You can use tools like the `pg_top` CLI or
+ `pg_stat_activity` to view the current transaction on the source database.
+
+1. Stop Live-migration.
+
+Live-migration continues the remaining work. This includes copying
+ TimescaleDB metadata, sequences, and run policies. When the migration completes,
+ you see the following message:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_experimental/ =====
+
+Experimental features could have bugs. They might not be backwards compatible,
+and could be removed in future releases. Use these features at your own risk, and
+do not use any experimental features in production.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_compression-intro/ =====
+
+Compressing your time-series data allows you to reduce your chunk size by more
+than 90%. This saves on storage costs, and keeps your queries operating at
+lightning speed.
+
+When you enable compression, the data in your hypertable is compressed chunk by
+chunk. When the chunk is compressed, multiple records are grouped into a single
+row. The columns of this row hold an array-like structure that stores all the
+data. This means that instead of using lots of rows to store the data, it stores
+the same data in a single row. Because a single row takes up less disk space
+than many rows, it decreases the amount of disk space required, and can also
+speed up your queries.
+
+For example, if you had a table with data that looked a bit like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|12:00:01|A|SSD|70.11|13.4|
+|12:00:01|B|HDD|69.70|20.5|
+|12:00:02|A|SSD|70.12|13.2|
+|12:00:02|B|HDD|69.69|23.4|
+|12:00:03|A|SSD|70.14|13.0|
+|12:00:03|B|HDD|69.70|25.2|
+
+You can convert this to a single row in array form, like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[SSD, HDD, SSD, HDD, SSD, HDD]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|[13.4, 20.5, 13.2, 23.4, 13.0, 25.2]|
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-only/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with real-time analytics enabled.
+
+You need your [connection details][connection-info].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypercore_manual_workflow/ =====
+
+1. **Stop the jobs that are automatically adding chunks to the columnstore**
+
+Retrieve the list of jobs from the [timescaledb_information.jobs][informational-views] view
+ to find the job you need to [alter_job][alter_job].
+
+1. **Convert a chunk to update back to the rowstore**
+
+1. **Update the data in the chunk you added to the rowstore**
+
+Best practice is to structure your [INSERT][insert] statement to include appropriate
+ partition key values, such as the timestamp. TimescaleDB adds the data to the correct chunk:
+
+1. **Convert the updated chunks back to the columnstore**
+
+1. **Restart the jobs that are automatically converting chunks to the columnstore**
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dump_roles_schema_data_mst/ =====
+
+1. **Dump the roles from your source database**
+
+Export your role-based security hierarchy. `` has the same value as `` in `source`.
+ I know, it confuses me as well.
+
+MST does not allow you to export passwords with roles. You assign passwords to these roles
+ when you have uploaded them to your Tiger Cloud service.
+
+1. **Remove roles with superuser access**
+
+Tiger Cloud services do not support roles with superuser access. Run the following script
+ to remove statements, permissions and clauses that require superuser permissions from `roles.sql`:
+
+1. **Dump the source database schema and data**
+
+The `pg_dump` flags remove superuser access and tablespaces from your data. When you run
+ `pgdump`, check the run time, [a long-running `pg_dump` can cause issues][long-running-pgdump].
+
+To dramatically reduce the time taken to dump the source database, using multiple connections. For more information,
+ see [dumping with concurrency][dumping-with-concurrency] and [restoring with concurrency][restoring-with-concurrency].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_migrate_data_timescaledb/ =====
+
+## Migrate your data, then start downtime
+2. **Pull the live-migration docker image to you migration machine**
+
+To list the available commands, run:
+
+ To see the available flags for each command, run `--help` for that command. For example:
+
+1. **Create a snapshot image of your source database in your Tiger Cloud service**
+
+This process checks that you have tuned your source database and target service correctly for replication,
+ then creates a snapshot of your data on the migration machine:
+
+Live-migration supplies information about updates you need to make to the source database and target service. For example:
+
+If you have warnings, stop live-migration, make the suggested changes and start again.
+
+1. **Synchronize data between your source database and your Tiger Cloud service**
+
+This command migrates data from the snapshot to your Tiger Cloud service, then streams
+ transactions from the source to the target.
+
+If the source Postgres version is 17 or later, you need to pass additional
+ flag `-e PGVERSION=17` to the `migrate` command.
+
+During this process, you see the migration process:
+
+If `migrate` stops add `--resume` to start from where it left off.
+
+Once the data in your target Tiger Cloud service has almost caught up with the source database,
+ you see the following message:
+
+Wait until `replay_lag` is down to a few kilobytes before you move to the next step. Otherwise, data
+ replication may not have finished.
+
+1. **Start app downtime**
+
+1. Stop your app writing to the source database, then let the the remaining transactions
+ finish to fully sync with the target. You can use tools like the `pg_top` CLI or
+ `pg_stat_activity` to view the current transaction on the source database.
+
+1. Stop Live-migration.
+
+Live-migration continues the remaining work. This includes copying
+ TimescaleDB metadata, sequences, and run policies. When the migration completes,
+ you see the following message:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-account-only/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Data account][create-account].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_set_up_database_first_steps/ =====
+
+1. **Take the applications that connect to the source database offline**
+
+The duration of the migration is proportional to the amount of data stored in your database. By
+ disconnection your app from your database you avoid and possible data loss.
+
+1. **Set your connection strings**
+
+These variables hold the connection information for the source database and target Tiger Cloud service:
+
+You find the connection information for your Tiger Cloud service in the configuration file you
+ downloaded when you created the service.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_install-self-hosted-redhat/ =====
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_chunk-interval/ =====
+
+Postgres builds the index on the fly during ingestion. That means that to build a new entry on the index,
+a significant portion of the index needs to be traversed during every row insertion. When the index does not fit
+into memory, it is constantly flushed to disk and read back. This wastes IO resources which would otherwise
+be used for writing the heap/WAL data to disk.
+
+The default chunk interval is 7 days. However, best practice is to set `chunk_interval` so that prior to processing,
+the indexes for chunks currently being ingested into fit within 25% of main memory. For example, on a system with 64
+GB of memory, if index growth is approximately 2 GB per day, a 1-week chunk interval is appropriate. If index growth is
+around 10 GB per day, use a 1-day interval.
+
+You set `chunk_interval` when you [create a hypertable][hypertable-create-table], or by calling
+[`set_chunk_time_interval`][chunk_interval] on an existing hypertable.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_tune_source_database_mst/ =====
+
+1. **Enable live-migration to replicate `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_tutorials_hypertable_intro/ =====
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypertable-intro/ =====
+
+Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
+
+
+
+Hypertables offer the following benefits:
+
+- **Efficient data management with [automated partitioning by time][chunk-size]**: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
+
+- **Better performance with [strategic indexing][hypertable-indexes]**: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
+
+- **Faster queries with [chunk skipping][chunk-skipping]**: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
+
+- **Advanced data analysis with [hyperfunctions][hyperfunctions]**: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+
+To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.
+
+Inheritance is not supported for hypertables and may lead to unexpected behavior.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_kubernetes-install-self-hosted/ =====
+
+Running TimescaleDB on Kubernetes is similar to running Postgres. This procedure outlines the steps for a non-distributed system.
+
+To connect your Kubernetes cluster to self-hosted TimescaleDB running in the cluster:
+
+1. **Create a default namespace for Tiger Data components**
+
+1. Create the Tiger Data namespace:
+
+1. Set this namespace as the default for your session:
+
+For more information, see [Kubernetes Namespaces][kubernetes-namespace].
+
+1. **Set up a persistent volume claim (PVC) storage**
+
+To manually set up a persistent volume and claim for self-hosted Kubernetes, run the following command:
+
+1. **Deploy TimescaleDB as a StatefulSet**
+
+By default, the [TimescaleDB Docker image][timescale-docker-image] you are installing on Kubernetes uses the
+ default Postgres database, user and password. To deploy TimescaleDB on Kubernetes, run the following command:
+
+1. **Allow applications to connect by exposing TimescaleDB within Kubernetes**
+
+1. **Create a Kubernetes secret to store the database credentials**
+
+1. **Deploy an application that connects to TimescaleDB**
+
+1. **Test the database connection**
+
+1. Create and run a pod to verify database connectivity using your [connection details][connection-info] saved in `timescale-secret`:
+
+1. Launch the Postgres interactive shell within the created `test-pod`:
+
+You see the Postgres interactive terminal.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-migrate-permissions/ =====
+
+You might get a permissions error when migrating a continuous aggregate from old
+to new format using `cagg_migrate`. The user performing the migration must have
+the following permissions:
+
+* Select, insert, and update permissions on the tables
+ `_timescale_catalog.continuous_agg_migrate_plan` and
+ `_timescale_catalog.continuous_agg_migrate_plan_step`
+* Usage permissions on the sequence
+ `_timescaledb_catalog.continuous_agg_migrate_plan_step_step_id_seq`
+
+To solve the problem, change to a user capable of granting permissions, and
+grant the following permissions to the user performing the migration:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_candlestick_intro/ =====
+
+The financial sector regularly uses [candlestick charts][charts] to visualize
+the price change of an asset. Each candlestick represents a time period, such as
+one minute or one hour, and shows how the asset's price changed during that time.
+
+Candlestick charts are generated from the open, high, low, close, and volume
+data for each financial asset during the time period. This is often abbreviated
+as OHLCV:
+
+* Open: opening price
+* High: highest price
+* Low: lowest price
+* Close: closing price
+* Volume: volume of transactions
+
+===== PAGE: https://docs.tigerdata.com/_partials/_start-coding-java/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the [Java Development Kit (JDK)][jdk].
+* Install the [PostgreSQL JDBC driver][pg-jdbc-driver].
+
+All code in this quick start is for Java 16 and later. If you are working
+with older JDK versions, use legacy coding techniques.
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to your service using an application in
+a single file. You can use any of your favorite build tools, including `gradle`
+or `maven`.
+
+1. Create a directory containing a text file called `Main.java`, with this content:
+
+1. From the command line in the current directory, run the application:
+
+If the command is successful, `Hello, World!` line output is printed
+ to your console.
+
+1. Import the PostgreSQL JDBC driver. If you are using a dependency manager,
+ include the [PostgreSQL JDBC Driver][pg-jdbc-driver-dependency] as a
+ dependency.
+
+1. Download the [JAR artifact of the JDBC Driver][pg-jdbc-driver-artifact] and
+ save it with the `Main.java` file.
+
+1. Import the `JDBC Driver` into the Java application and display a list of
+ available drivers for the check:
+
+1. Run all the examples:
+
+If the command is successful, a string similar to
+ `org.postgresql.Driver@7f77e91b` is printed to your console. This means that you
+ are ready to connect to TimescaleDB from Java.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for JDBC.
+
+* password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+For more information about creating connection strings, see the [JDBC documentation][pg-jdbc-driver-conn-docs].
+
+This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+If the command is successful, a string similar to
+ `{ApplicationName=PostgreSQL JDBC Driver}` is printed to your console.
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+1. Create a statement, execute the query you created in the previous step, and
+ check that the table was created successfully:
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+1. Create a statement, execute the query you created in the previous step:
+
+The `by_range` and `by_hash` dimension builder is an addition to TimescaleDB 2.13.
+
+1. Execute the two statements you created, and commit your changes to the
+ database:
+
+You can insert data into your hypertables in several different ways. In this
+section, you can insert single rows, or insert by batches of rows.
+
+1. Open a connection to the database, use prepared statements to formulate the
+ `INSERT` SQL statement, then execute the statement:
+
+If you want to insert a batch of rows by using a batching mechanism. In this
+example, you generate some sample time-series data to insert into the
+`sensor_data` hypertable:
+
+1. Insert batches of rows:
+
+This section covers how to execute queries against your database.
+
+## Execute queries on TimescaleDB
+
+1. Define the SQL query you'd like to run on the database. This example
+ combines time-series and relational data. It returns the average values for
+ every 15 minute interval for sensors with specific type and location.
+
+1. Execute the query with the prepared statement and read out the result set for
+ all `a`-type sensors located on the `floor`:
+
+If the command is successful, you'll see output like this:
+
+Now that you're able to connect, read, and write to a TimescaleDB instance from
+your Java application, and generate the scaffolding necessary to build a new
+application from an existing TimescaleDB instance, be sure to check out these
+advanced TimescaleDB tutorials:
+
+* [Continuous Aggregates][continuous-aggregates]
+* [Migrate Your own Data][migrate]
+
+## Complete code samples
+
+This section contains complete code samples.
+
+### Complete code sample
+
+### Execute more complex queries
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_self_postgres_implement_migration_path/ =====
+
+You cannot upgrade TimescaleDB and Postgres at the same time. You upgrade each product in
+the following steps:
+
+1. **Upgrade TimescaleDB**
+
+1. **If your migration path dictates it, upgrade Postgres**
+
+Follow the procedure in [Upgrade Postgres][upgrade-pg]. The version of TimescaleDB installed
+ in your Postgres deployment must be the same before and after the Postgres upgrade.
+
+1. **If your migration path dictates it, upgrade TimescaleDB again**
+
+1. **Check that you have upgraded to the correct version of TimescaleDB**
+
+Postgres returns something like:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_validate_production_load/ =====
+
+Now that dual-writes have been in place for a while, the target database should
+be holding up to production write traffic. Now would be the right time to
+determine if the target database can serve all production traffic (both reads
+_and_ writes). How exactly this is done is application-specific and up to you
+to determine.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-no-connection/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with real-time analytics enabled.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_import_prerequisites/ =====
+
+Best practice is to use an [Ubuntu EC2 instance][create-ec2-instance] hosted in the same region as your
+Tiger Cloud service as a migration machine. That is, the machine you run the commands on to move your
+data from your source database to your target Tiger Cloud service.
+
+Before you migrate your data:
+
+- Create a target [Tiger Cloud service][created-a-database-service-in-timescale].
+
+Each Tiger Cloud service has a single database that supports the
+ [most popular extensions][all-available-extensions]. Tiger Cloud services do not support tablespaces,
+ and there is no superuser associated with a service.
+ Best practice is to create a Tiger Cloud service with at least 8 CPUs for a smoother experience. A higher-spec instance
+ can significantly reduce the overall migration window.
+
+- To ensure that maintenance does not run during the process, [adjust the maintenance window][adjust-maintenance-window].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypercore-intro-short/ =====
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-intro/ =====
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_kubernetes-prereqs/ =====
+
+- Install [self-managed Kubernetes][kubernetes-install] or sign up for a Kubernetes [Turnkey Cloud Solution][kubernetes-managed].
+- Install [kubectl][kubectl] for command-line interaction with your cluster.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_high-availability-setup/ =====
+
+1. In [Tiger Cloud Console][cloud-login], select the service to enable replication for.
+1. Click `Operations`, then select `High availability`.
+1. Choose your replication strategy, then click `Change configuration`.
+
+
+
+1. In `Change high availability configuration`, click `Change config`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_vpc-limitations/ =====
+
+* You **can attach**:
+ * Up to 50 Customer VPCs to a Peering VPC.
+ * A Tiger Cloud service to a single Peering VPC at a time.
+ The service and the Peering VPC must be in the same AWS region. However, you can peer a Customer VPC and a Peering VPC that are in different regions.
+ * Multiple Tiger Cloud services to the same Peering VPC.
+* You **cannot attach** a Tiger Cloud service to multiple Peering VPCs at the same time.
+
+The number of Peering VPCs you can create in your project depends on your [pricing plan][pricing-plans].
+ If you need another Peering VPC, either contact [support@tigerdata.com](mailto:support@tigerdata.com) or change your pricing plan in [Tiger Cloud Console][console-login].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_integration-apache-kafka-install/ =====
+
+1. **Extract the Kafka binaries to a local folder**
+
+From now on, the folder where you extracted the Kafka binaries is called ``.
+
+1. **Configure and run Apache Kafka**
+
+Use the `-daemon` flag to run this process in the background.
+
+1. **Create Kafka topics**
+
+In another Terminal window, navigate to , then call `kafka-topics.sh` and create the following topics:
+ - `accounts`: publishes JSON messages that are consumed by the timescale-sink connector and inserted into your Tiger Cloud service.
+ - `deadletter`: stores messages that cause errors and that Kafka Connect workers cannot process.
+
+1. **Test that your topics are working correctly**
+ 1. Run `kafka-console-producer` to send messages to the `accounts` topic:
+
+ 1. Send some events. For example, type the following:
+
+ 1. In another Terminal window, navigate to , then run `kafka-console-consumer` to consume the events you just sent:
+
+ You see
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_live_tune_source_database_awsrds/ =====
+
+Updating parameters on a Postgres instance will cause an outage. Choose a time that will cause the least issues to tune this database.
+
+1. **Update the DB instance parameter group for your source database**
+
+1. In [https://console.aws.amazon.com/rds/home#databases:][databases],
+ select the RDS instance to migrate.
+
+1. Click `Configuration`, scroll down and note the `DB instance parameter group`, then click `Parameter groups`
+
+ +
+1. Click `Create parameter group`, fill in the form with the following values, then click `Create`.
+ - **Parameter group name** - whatever suits your fancy.
+ - **Description** - knock yourself out with this one.
+ - **Engine type** - `PostgreSQL`
+ - **Parameter group family** - the same as `DB instance parameter group` in your `Configuration`.
+ 1. In `Parameter groups`, select the parameter group you created, then click `Edit`.
+ 1. Update the following parameters, then click `Save changes`.
+ - `rds.logical_replication` set to `1`: record the information needed for logical decoding.
+ - `wal_sender_timeout` set to `0`: disable the timeout for the sender process.
+
+1. In RDS, navigate back to your [databases][databases], select the RDS instance to migrate, and click `Modify`.
+
+1. Scroll down to `Database options`, select your new parameter group, and click `Continue`.
+ 1. Click `Apply immediately` or choose a maintenance window, then click `Modify DB instance`.
+
+Changing parameters will cause an outage. Wait for the database instance to reboot before continuing.
+ 1. Verify that the settings are live in your database.
+
+1. **Enable replication `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_foreign-data-wrappers/ =====
+
+You use Postgres foreign data wrappers (FDWs) to query external data sources from a Tiger Cloud service. These external data sources can be one of the following:
+
+- Other Tiger Cloud services
+- Postgres databases outside of Tiger Cloud
+
+If you are using VPC peering, you can create FDWs in your Customer VPC to query a service in your Tiger Cloud project. However, you can't create FDWs in your Tiger Cloud services to query a data source in your Customer VPC. This is because Tiger Cloud VPC peering uses AWS PrivateLink for increased security. See [VPC peering documentation][vpc-peering] for additional details.
+
+Postgres FDWs are particularly useful if you manage multiple Tiger Cloud services with different capabilities, and need to seamlessly access and merge regular and time-series data.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Query another data source
+
+To query another data source:
+
+You create Postgres FDWs with the `postgres_fdw` extension, which is enabled by default in Tiger Cloud.
+
+1. **Connect to your service**
+
+See [how to connect][connect].
+
+1. **Create a server**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Create user mapping**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Import a foreign schema (recommended) or create a foreign table**
+
+- Import the whole schema:
+
+- Alternatively, import a limited number of tables:
+
+- Create a foreign table. Skip if you are importing a schema:
+
+A user with the `tsdbadmin` role assigned already has the required `USAGE` permission to create Postgres FDWs. You can enable another user, without the `tsdbadmin` role assigned, to query foreign data. To do so, explicitly grant the permission. For example, for a new `grafana` user:
+
+You create Postgres FDWs with the `postgres_fdw` extension. See [documenation][enable-fdw-docs] on how to enable it.
+
+1. **Connect to your database**
+
+Use [`psql`][psql] to connect to your database.
+
+1. **Create a server**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Create user mapping**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Import a foreign schema (recommended) or create a foreign table**
+
+- Import the whole schema:
+
+- Alternatively, import a limited number of tables:
+
+- Create a foreign table. Skip if you are importing a schema:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cookbook-iot/ =====
+
+This section contains recipes for IoT issues:
+
+### Work with columnar IoT data
+
+Narrow and medium width tables are a great way to store IoT data. A lot of reasons are outlined in
+[Designing Your Database Schema: Wide vs. Narrow Postgres Tables][blog-wide-vs-narrow].
+
+One of the key advantages of narrow tables is that the schema does not have to change when you add new
+sensors. Another big advantage is that each sensor can sample at different rates and times. This helps
+support things like hysteresis, where new values are written infrequently unless the value changes by a
+certain amount.
+
+#### Narrow table format example
+
+Working with narrow table data structures presents a few challenges. In the IoT world one concern is that
+many data analysis approaches - including machine learning as well as more traditional data analysis -
+require that your data is resampled and synchronized to a common time basis. Fortunately, TimescaleDB provides
+you with [hyperfunctions][hyperfunctions] and other tools to help you work with this data.
+
+An example of a narrow table format is:
+
+| ts | sensor_id | value |
+|-------------------------|-----------|-------|
+| 2024-10-31 11:17:30.000 | 1007 | 23.45 |
+
+Typically you would couple this with a sensor table:
+
+| sensor_id | sensor_name | units |
+|-----------|--------------|--------------------------|
+| 1007 | temperature | degreesC |
+| 1012 | heat_mode | on/off |
+| 1013 | cooling_mode | on/off |
+| 1041 | occupancy | number of people in room |
+
+A medium table retains the generic structure but adds columns of various types so that you can
+use the same table to store float, int, bool, or even JSON (jsonb) data:
+
+| ts | sensor_id | d | i | b | t | j |
+|-------------------------|-----------|-------|------|------|------|------|
+| 2024-10-31 11:17:30.000 | 1007 | 23.45 | null | null | null | null |
+| 2024-10-31 11:17:47.000 | 1012 | null | null | TRUE | null | null |
+| 2024-10-31 11:18:01.000 | 1041 | null | 4 | null | null | null |
+
+To remove all-null entries, use an optional constraint such as:
+
+#### Get the last value of every sensor
+
+There are several ways to get the latest value of every sensor. The following examples use the
+structure defined in [Narrow table format example][setup-a-narrow-table-format] as a reference:
+
+- [SELECT DISTINCT ON][select-distinct-on]
+- [JOIN LATERAL][join-lateral]
+
+##### SELECT DISTINCT ON
+
+If you have a list of sensors, the easy way to get the latest value of every sensor is to use
+`SELECT DISTINCT ON`:
+
+The common table expression (CTE) used above is not strictly necessary. However, it is an elegant way to join
+to the sensor list to get a sensor name in the output. If this is not something you care about,
+you can leave it out:
+
+It is important to take care when down-selecting this data. In the previous examples,
+the time that the query would scan back was limited. However, if there any sensors that have either
+not reported in a long time or in the worst case, never reported, this query devolves to a full table scan.
+In a database with 1000+ sensors and 41 million rows, an unconstrained query takes over an hour.
+
+An alternative to [SELECT DISTINCT ON][select-distinct-on] is to use a `JOIN LATERAL`. By selecting your entire
+sensor list from the sensors table rather than pulling the IDs out using `SELECT DISTINCT`, `JOIN LATERAL` can offer
+some improvements in performance:
+
+Limiting the time range is important, especially if you have a lot of data. Best practice is to use these
+kinds of queries for dashboards and quick status checks. To query over a much larger time range, encapsulate
+the previous example into a materialized query that refreshes infrequently, perhaps once a day.
+
+Shoutout to **Christopher Piggott** for this recipe.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_from_timescaledb_version/ =====
+
+It is very important that the version of the TimescaleDB extension is the same
+in the source and target databases. This requires upgrading the TimescaleDB
+extension in the source database before migrating.
+
+You can determine the version of TimescaleDB in the target database with the
+following command:
+
+To update the TimescaleDB extension in your source database, first ensure that
+the desired version is installed from your package repository. Then you can
+upgrade the extension with the following query:
+
+For more information and guidance, consult the [Upgrade TimescaleDB] page.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_since_2_18_0/ =====
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+===== PAGE: https://docs.tigerdata.com/_partials/_add-data-nyctaxis/ =====
+
+When you have your database set up, you can load the taxi trip data into the
+`rides` hypertable.
+
+This is a large dataset, so it might take a long time, depending on your network
+connection.
+
+1. Download the dataset:
+
+[nyc_data.tar.gz](https://assets.timescale.com/docs/downloads/nyc_data.tar.gz)
+
+1. Use your file manager to decompress the downloaded dataset, and take a note
+ of the path to the `nyc_data_rides.csv` file.
+
+1. At the psql prompt, copy the data from the `nyc_data_rides.csv` file into
+ your hypertable. Make sure you point to the correct path, if it is not in
+ your current working directory:
+
+You can check that the data has been copied successfully with this command:
+
+You should get five records that look like this:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-create-service/ =====
+
+### Create a Tiger Cloud service
+
+
+
+1. Click `Create parameter group`, fill in the form with the following values, then click `Create`.
+ - **Parameter group name** - whatever suits your fancy.
+ - **Description** - knock yourself out with this one.
+ - **Engine type** - `PostgreSQL`
+ - **Parameter group family** - the same as `DB instance parameter group` in your `Configuration`.
+ 1. In `Parameter groups`, select the parameter group you created, then click `Edit`.
+ 1. Update the following parameters, then click `Save changes`.
+ - `rds.logical_replication` set to `1`: record the information needed for logical decoding.
+ - `wal_sender_timeout` set to `0`: disable the timeout for the sender process.
+
+1. In RDS, navigate back to your [databases][databases], select the RDS instance to migrate, and click `Modify`.
+
+1. Scroll down to `Database options`, select your new parameter group, and click `Continue`.
+ 1. Click `Apply immediately` or choose a maintenance window, then click `Modify DB instance`.
+
+Changing parameters will cause an outage. Wait for the database instance to reboot before continuing.
+ 1. Verify that the settings are live in your database.
+
+1. **Enable replication `DELETE` and`UPDATE` operations**
+
+Replica identity assists data replication by identifying the rows being modified. Your options are that
+ each table and hypertable in the source database should either have:
+- **A primary key**: data replication defaults to the primary key of the table being replicated.
+ Nothing to do.
+- **A viable unique index**: each table has a unique, non-partial, non-deferrable index that includes only columns
+ marked as `NOT NULL`. If a UNIQUE index does not exist, create one to assist the migration. You can delete if after
+ migration.
+
+For each table, set `REPLICA IDENTITY` to the viable unique index:
+
+- **No primary key or viable unique index**: use brute force.
+
+For each table, set `REPLICA IDENTITY` to `FULL`:
+
+ For each `UPDATE` or `DELETE` statement, Postgres reads the whole table to find all matching rows. This results
+ in significantly slower replication. If you are expecting a large number of `UPDATE` or `DELETE` operations on the table,
+ best practice is to not use `FULL`.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_foreign-data-wrappers/ =====
+
+You use Postgres foreign data wrappers (FDWs) to query external data sources from a Tiger Cloud service. These external data sources can be one of the following:
+
+- Other Tiger Cloud services
+- Postgres databases outside of Tiger Cloud
+
+If you are using VPC peering, you can create FDWs in your Customer VPC to query a service in your Tiger Cloud project. However, you can't create FDWs in your Tiger Cloud services to query a data source in your Customer VPC. This is because Tiger Cloud VPC peering uses AWS PrivateLink for increased security. See [VPC peering documentation][vpc-peering] for additional details.
+
+Postgres FDWs are particularly useful if you manage multiple Tiger Cloud services with different capabilities, and need to seamlessly access and merge regular and time-series data.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Query another data source
+
+To query another data source:
+
+You create Postgres FDWs with the `postgres_fdw` extension, which is enabled by default in Tiger Cloud.
+
+1. **Connect to your service**
+
+See [how to connect][connect].
+
+1. **Create a server**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Create user mapping**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Import a foreign schema (recommended) or create a foreign table**
+
+- Import the whole schema:
+
+- Alternatively, import a limited number of tables:
+
+- Create a foreign table. Skip if you are importing a schema:
+
+A user with the `tsdbadmin` role assigned already has the required `USAGE` permission to create Postgres FDWs. You can enable another user, without the `tsdbadmin` role assigned, to query foreign data. To do so, explicitly grant the permission. For example, for a new `grafana` user:
+
+You create Postgres FDWs with the `postgres_fdw` extension. See [documenation][enable-fdw-docs] on how to enable it.
+
+1. **Connect to your database**
+
+Use [`psql`][psql] to connect to your database.
+
+1. **Create a server**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Create user mapping**
+
+Run the following command using your [connection details][connection-info]:
+
+1. **Import a foreign schema (recommended) or create a foreign table**
+
+- Import the whole schema:
+
+- Alternatively, import a limited number of tables:
+
+- Create a foreign table. Skip if you are importing a schema:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cookbook-iot/ =====
+
+This section contains recipes for IoT issues:
+
+### Work with columnar IoT data
+
+Narrow and medium width tables are a great way to store IoT data. A lot of reasons are outlined in
+[Designing Your Database Schema: Wide vs. Narrow Postgres Tables][blog-wide-vs-narrow].
+
+One of the key advantages of narrow tables is that the schema does not have to change when you add new
+sensors. Another big advantage is that each sensor can sample at different rates and times. This helps
+support things like hysteresis, where new values are written infrequently unless the value changes by a
+certain amount.
+
+#### Narrow table format example
+
+Working with narrow table data structures presents a few challenges. In the IoT world one concern is that
+many data analysis approaches - including machine learning as well as more traditional data analysis -
+require that your data is resampled and synchronized to a common time basis. Fortunately, TimescaleDB provides
+you with [hyperfunctions][hyperfunctions] and other tools to help you work with this data.
+
+An example of a narrow table format is:
+
+| ts | sensor_id | value |
+|-------------------------|-----------|-------|
+| 2024-10-31 11:17:30.000 | 1007 | 23.45 |
+
+Typically you would couple this with a sensor table:
+
+| sensor_id | sensor_name | units |
+|-----------|--------------|--------------------------|
+| 1007 | temperature | degreesC |
+| 1012 | heat_mode | on/off |
+| 1013 | cooling_mode | on/off |
+| 1041 | occupancy | number of people in room |
+
+A medium table retains the generic structure but adds columns of various types so that you can
+use the same table to store float, int, bool, or even JSON (jsonb) data:
+
+| ts | sensor_id | d | i | b | t | j |
+|-------------------------|-----------|-------|------|------|------|------|
+| 2024-10-31 11:17:30.000 | 1007 | 23.45 | null | null | null | null |
+| 2024-10-31 11:17:47.000 | 1012 | null | null | TRUE | null | null |
+| 2024-10-31 11:18:01.000 | 1041 | null | 4 | null | null | null |
+
+To remove all-null entries, use an optional constraint such as:
+
+#### Get the last value of every sensor
+
+There are several ways to get the latest value of every sensor. The following examples use the
+structure defined in [Narrow table format example][setup-a-narrow-table-format] as a reference:
+
+- [SELECT DISTINCT ON][select-distinct-on]
+- [JOIN LATERAL][join-lateral]
+
+##### SELECT DISTINCT ON
+
+If you have a list of sensors, the easy way to get the latest value of every sensor is to use
+`SELECT DISTINCT ON`:
+
+The common table expression (CTE) used above is not strictly necessary. However, it is an elegant way to join
+to the sensor list to get a sensor name in the output. If this is not something you care about,
+you can leave it out:
+
+It is important to take care when down-selecting this data. In the previous examples,
+the time that the query would scan back was limited. However, if there any sensors that have either
+not reported in a long time or in the worst case, never reported, this query devolves to a full table scan.
+In a database with 1000+ sensors and 41 million rows, an unconstrained query takes over an hour.
+
+An alternative to [SELECT DISTINCT ON][select-distinct-on] is to use a `JOIN LATERAL`. By selecting your entire
+sensor list from the sensors table rather than pulling the IDs out using `SELECT DISTINCT`, `JOIN LATERAL` can offer
+some improvements in performance:
+
+Limiting the time range is important, especially if you have a lot of data. Best practice is to use these
+kinds of queries for dashboards and quick status checks. To query over a much larger time range, encapsulate
+the previous example into a materialized query that refreshes infrequently, perhaps once a day.
+
+Shoutout to **Christopher Piggott** for this recipe.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_from_timescaledb_version/ =====
+
+It is very important that the version of the TimescaleDB extension is the same
+in the source and target databases. This requires upgrading the TimescaleDB
+extension in the source database before migrating.
+
+You can determine the version of TimescaleDB in the target database with the
+following command:
+
+To update the TimescaleDB extension in your source database, first ensure that
+the desired version is installed from your package repository. Then you can
+upgrade the extension with the following query:
+
+For more information and guidance, consult the [Upgrade TimescaleDB] page.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_since_2_18_0/ =====
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+===== PAGE: https://docs.tigerdata.com/_partials/_add-data-nyctaxis/ =====
+
+When you have your database set up, you can load the taxi trip data into the
+`rides` hypertable.
+
+This is a large dataset, so it might take a long time, depending on your network
+connection.
+
+1. Download the dataset:
+
+[nyc_data.tar.gz](https://assets.timescale.com/docs/downloads/nyc_data.tar.gz)
+
+1. Use your file manager to decompress the downloaded dataset, and take a note
+ of the path to the `nyc_data_rides.csv` file.
+
+1. At the psql prompt, copy the data from the `nyc_data_rides.csv` file into
+ your hypertable. Make sure you point to the correct path, if it is not in
+ your current working directory:
+
+You can check that the data has been copied successfully with this command:
+
+You should get five records that look like this:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-create-service/ =====
+
+### Create a Tiger Cloud service
+
+
+ -
+
+ Sign in to the{" "}
+ Tiger Cloud Console and click Create service.
+
+
+ -
+
+ Choose if you want a Time-series or Dynamic Postgres service.
+
+
+ {props.demoData && (
+ -
+
+ Click Get started to create your service with demo data, and
+ launch the Allmilk Factory interactive demo. You can exit
+ the demo at any time, and revisit it from the same point later on. You
+ can also re-run the demo after you have completed it.
+
+  +
+
+ )}
+ -
+
+ Click Download the cheatsheet to download an SQL file that
+ contains the login details for your new service. You can also copy the
+ details directly from this page. When you have copied your password,
+ click I stored my password, go to service overview
+ at the bottom of the page.
+
+
+ -
+
+ When your service is ready to use, is shows a green Running
+ label in the Service Overview. You also receive an email confirming that
+ your service is ready to use.
+
+
+
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-real-time-historical-data-refreshes/ =====
+
+Real-time aggregates automatically add the most recent data when you query your
+continuous aggregate. In other words, they include data _more recent than_ your
+last materialized bucket.
+
+If you add new _historical_ data to an already-materialized bucket, it won't be
+reflected in a real-time aggregate. You should wait for the next scheduled
+refresh, or manually refresh by calling `refresh_continuous_aggregate`. You can
+think of real-time aggregates as being eventually consistent for historical
+data.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_awsrds_connect_intermediary/ =====
+
+## Create an intermediary EC2 Ubuntu instance
+1. In [https://console.aws.amazon.com/rds/home#databases:][databases],
+ select the RDS/Aurora Postgres instance to migrate.
+1. Click `Actions` > `Set up EC2 connection`.
+ Press `Create EC2 instance` and use the following settings:
+ - **AMI**: Ubuntu Server.
+ - **Key pair**: use an existing pair or create a new one that you will use to access the intermediary machine.
+ - **VPC**: by default, this is the same as the database instance.
+ - **Configure Storage**: adjust the volume to at least the size of RDS/Aurora Postgres instance you are migrating from.
+ You can reduce the space used by your data on Tiger Cloud using [Hypercore][hypercore].
+1. Click `Lauch instance`. AWS creates your EC2 instance, then click `Connect to instance` > `SSH client`.
+ Follow the instructions to create the connection to your intermediary EC2 instance.
+
+## Install the psql client tools on the intermediary instance
+
+1. Connect to your intermediary EC2 instance. For example:
+
+1. On your intermediary EC2 instance, install the Postgres client.
+
+Keep this terminal open, you need it to connect to the RDS/Aurora Postgres instance for migration.
+
+## Set up secure connectivity between your RDS/Aurora Postgres and EC2 instances
+
+1. In [https://console.aws.amazon.com/rds/home#databases:][databases],
+ select the RDS/Aurora Postgres instance to migrate.
+1. Scroll down to `Security group rules (1)` and select the `EC2 Security Group - Inbound` group. The
+ `Security Groups (1)` window opens. Click the `Security group ID`, then click `Edit inbound rules`
+
+
+
+1. On your intermediary EC2 instance, get your local IP address:
+
+ Bear with me on this one, you need this IP address to enable access to your RDS/Aurora Postgres instance.
+1. In `Edit inbound rules`, click `Add rule`, then create a `PostgreSQL`, `TCP` rule granting access
+ to the local IP address for your EC2 instance (told you :-)). Then click `Save rules`.
+
+
+
+## Test the connection between your RDS/Aurora Postgres and EC2 instances
+
+1. In [https://console.aws.amazon.com/rds/home#databases:][databases],
+ select the RDS/Aurora Postgres instance to migrate.
+1. On your intermediary EC2 instance, use the values of `Endpoint`, `Port`, `Master username`, and `DB name`
+ to create the postgres connectivity string to the `SOURCE` variable.
+
+
+
+The value of `Master password` was supplied when this RDS/Aurora Postgres instance was created.
+
+1. Test your connection:
+
+ You are connected to your RDS/Aurora Postgres instance from your intermediary EC2 instance.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_transit-gateway/ =====
+
+1. **Create a Peering VPC in [Tiger Cloud Console][console-login]**
+
+1. In `Security` > `VPC`, click `Create a VPC`:
+
+
+
+1. Choose your region and IP range, name your VPC, then click `Create VPC`:
+
+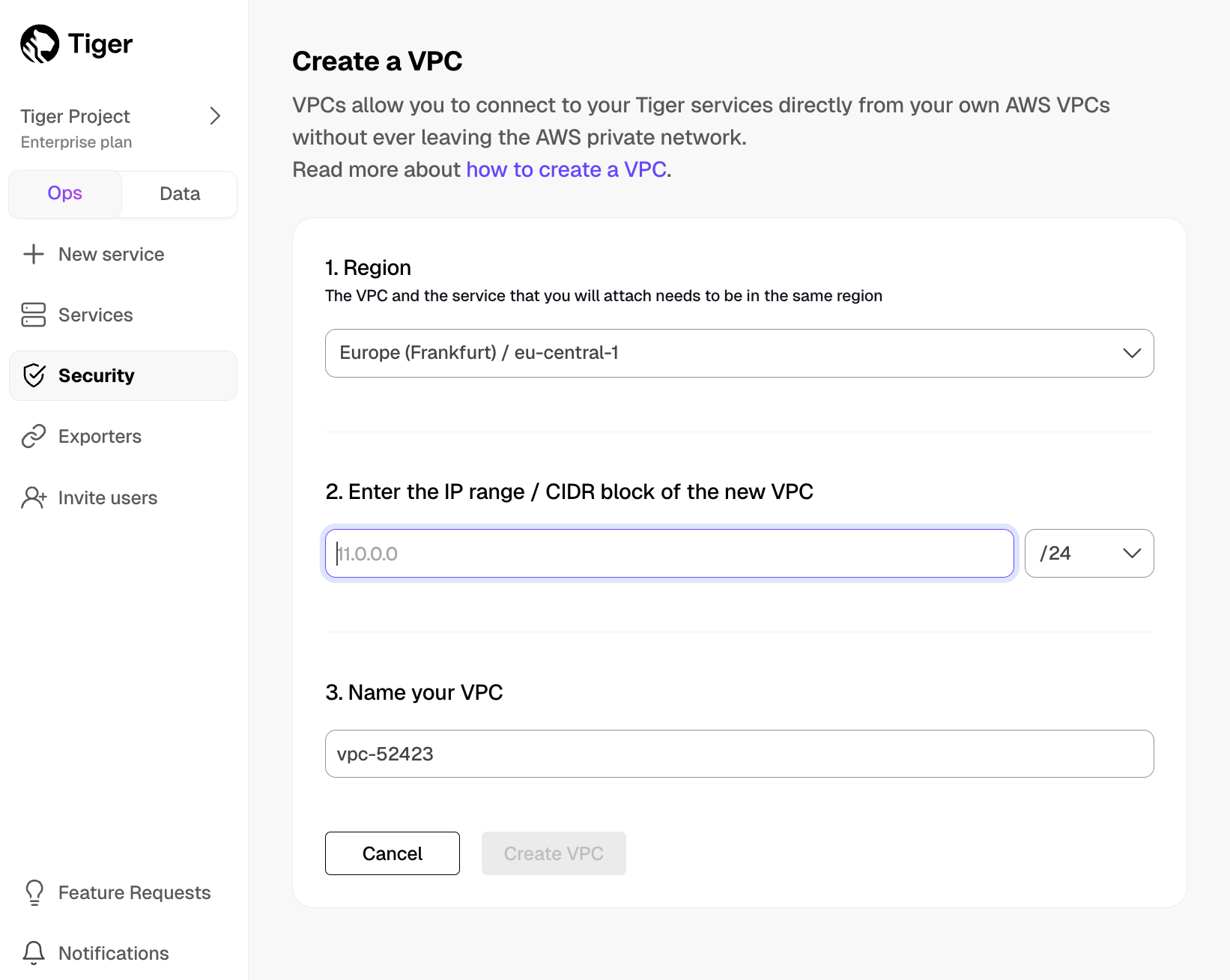
+
+Your service and Peering VPC must be in the same AWS region. The number of Peering VPCs you can create in your project depends on your [pricing plan][pricing-plans]. If you need another Peering VPC, either contact [support@tigerdata.com](mailto:support@tigerdata.com) or change your plan in [Tiger Cloud Console][console-login].
+
+1. Add a peering connection:
+
+1. In the `VPC Peering` column, click `Add`.
+ 1. Provide your AWS account ID, Transit Gateway ID, CIDR ranges, and AWS region. Tiger Cloud creates a new isolated connection for every unique Transit Gateway ID.
+
+
+
+1. Click `Add connection`.
+
+1. **Accept and configure peering connection in your AWS account**
+
+Once your peering connection appears as `Processing`, you can accept and configure it in AWS:
+
+1. Accept the peering request coming from Tiger Cloud. The request can take up to 5 min to arrive. Within 5 more minutes after accepting, the peering should appear as `Connected` in Tiger Cloud Console.
+
+1. Configure at least the following in your AWS account networking:
+
+- Your subnet route table to route traffic to your Transit Gateway for the Peering VPC CIDRs.
+ - Your Transit Gateway route table to route traffic to the newly created Transit Gateway peering attachment for the Peering VPC CIDRs.
+ - Security groups to allow outbound TCP 5432.
+
+1. **Attach a Tiger Cloud service to the Peering VPC In [Tiger Cloud Console][console-services]**
+
+1. Select the service you want to connect to the Peering VPC.
+ 1. Click `Operations` > `Security` > `VPC`.
+ 1. Select the VPC, then click `Attach VPC`.
+
+You cannot attach a Tiger Cloud service to multiple Tiger Cloud VPCs at the same time.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-intro-short/ =====
+
+A Tiger Cloud service is a single optimised Postgres instance extended with innovations in the database engine such as
+TimescaleDB, in a cloud infrastructure that delivers speed without sacrifice.
+
+A Tiger Cloud service is a radically faster Postgres database for transactional, analytical, and agentic
+workloads at scale.
+
+It’s not a fork. It’s not a wrapper. It is Postgres—extended with innovations in the database
+engine and cloud infrastructure to deliver speed (10-1000x faster at scale) without sacrifice.
+A Tiger Cloud service brings together the familiarity and reliability of Postgres with the performance of
+purpose-built engines.
+
+Tiger Cloud is the fastest Postgres cloud. It includes everything you need
+to run Postgres in a production-reliable, scalable, observable environment.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_since_2_22_0/ =====
+
+Since [TimescaleDB v2.22.0](https://github.com/timescale/timescaledb/releases/tag/2.22.0)
+
+===== PAGE: https://docs.tigerdata.com/_partials/_integration-prereqs/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud_self_configuration/ =====
+
+Please refer to the [Grand Unified Configuration (GUC) parameters][gucs] for a complete list.
+
+### `timescaledb.max_background_workers (int)`
+
+Max background worker processes allocated to TimescaleDB. Set to at least 1 +
+the number of databases loaded with the TimescaleDB extension in a Postgres instance. Default value is 16.
+
+## Tiger Cloud service tuning
+
+### `timescaledb.disable_load (bool)`
+Disable the loading of the actual extension
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_step2/ =====
+
+## 2. Modify the application to write to the target database
+
+How exactly to do this is dependent on the language that your application is
+written in, and on how exactly your ingestion and application function. In the
+simplest case, you simply execute two inserts in parallel. In the general case,
+you must think about how to handle the failure to write to either the source or
+target database, and what mechanism you want to or can build to recover from
+such a failure.
+
+Should your time-series data have foreign-key references into a plain table,
+you must ensure that your application correctly maintains the foreign key
+relations. If the referenced column is a `*SERIAL` type, the same row inserted
+into the source and target _may not_ obtain the same autogenerated id. If this
+happens, the data backfilled from the source to the target is internally
+inconsistent. In the best case it causes a foreign key violation, in the worst
+case, the foreign key constraint is maintained, but the data references the
+wrong foreign key. To avoid these issues, best practice is to follow
+[live migration].
+
+You may also want to execute the same read queries on the source and target
+database to evaluate the correctness and performance of the results which the
+queries deliver. Bear in mind that the target database spends a certain amount
+of time without all data being present, so you should expect that the results
+are not the same for some period (potentially a number of days).
+
+===== PAGE: https://docs.tigerdata.com/_partials/_timescaledb_supported_linux/ =====
+
+| Operation system | Version |
+|---------------------------------|-----------------------------------------------------------------------|
+| Debian | 13 Trixe, 12 Bookworm, 11 Bullseye |
+| Ubuntu | 24.04 Noble Numbat, 22.04 LTS Jammy Jellyfish |
+| Red Hat Enterprise | Linux 9, Linux 8 |
+| Fedora | Fedora 35, Fedora 34, Fedora 33 |
+| Rocky Linux | Rocky Linux 9 (x86_64), Rocky Linux 8 |
+| ArchLinux (community-supported) | Check the [available packages][archlinux-packages] |
+
+===== PAGE: https://docs.tigerdata.com/_partials/_add-data-twelvedata-stocks/ =====
+
+## Load financial data
+
+This tutorial uses real-time stock trade data, also known as tick data, from
+[Twelve Data][twelve-data]. A direct download link is provided below.
+
+To ingest data into the tables that you created, you need to download the
+dataset and copy the data to your database.
+
+1. Download the `real_time_stock_data.zip` file. The file contains two `.csv`
+ files; one with company information, and one with real-time stock trades for
+ the past month. Download:
+
+[real_time_stock_data.zip](https://assets.timescale.com/docs/downloads/get-started/real_time_stock_data.zip)
+
+1. In a new terminal window, run this command to unzip the `.csv` files:
+
+1. At the `psql` prompt, use the `COPY` command to transfer data into your
+ Tiger Cloud service. If the `.csv` files aren't in your current directory,
+ specify the file paths in these commands:
+
+Because there are millions of rows of data, the `COPY` process could take a
+ few minutes depending on your internet connection and local client
+ resources.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypercore_policy_workflow/ =====
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. **Enable columnstore on a hypertable**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+* [Use `CREATE TABLE` for a hypertable][hypertable-create-table]
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+* [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
+
+ Before you say `huh`, a continuous aggregate is a specialized hypertable.
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+Create a [columnstore_policy][add_columnstore_policy] that automatically converts chunks in a hypertable to the columnstore at a specific time interval. For example, convert yesterday's crypto trading data to the columnstore:
+
+TimescaleDB is optimized for fast updates on compressed data in the columnstore. To modify data in the
+ columnstore, use standard SQL.
+
+1. **Check the columnstore policy**
+
+1. View your data space saving:
+
+When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than
+ 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved:
+
+You see something like:
+
+| before | after |
+ |---------|--------|
+ | 194 MB | 24 MB |
+
+1. View the policies that you set or the policies that already exist:
+
+See [timescaledb_information.jobs][informational-views].
+
+1. **Pause a columnstore policy**
+
+See [alter_job][alter_job].
+
+1. **Restart a columnstore policy**
+
+See [alter_job][alter_job].
+
+1. **Remove a columnstore policy**
+
+See [remove_columnstore_policy][remove_columnstore_policy].
+
+1. **Disable columnstore**
+
+If your table has chunks in the columnstore, you have to
+ [convert the chunks back to the rowstore][convert_to_rowstore] before you disable the columnstore.
+
+ See [alter_table_hypercore][alter_table_hypercore].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dual_write_switch_production_workload/ =====
+
+Once you've validated that all the data is present, and that the target
+database can handle the production workload, the final step is to switch to the
+target database as your primary. You may want to continue writing to the source
+database for a period, until you are certain that the target database is
+holding up to all production traffic.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_dump_roles_schema_data_multi_node/ =====
+
+1. **Dump the roles from your source database**
+
+Export your role-based security hierarchy. If you only use the default `postgres` role, this step is not
+ necessary.
+
+MST does not allow you to export passwords with roles. You assign passwords to these roles
+ when you have uploaded them to your Tiger Cloud service.
+
+1. **Remove roles with superuser access**
+
+Tiger Cloud services do not support roles with superuser access. Run the following script
+ to remove statements, permissions and clauses that require superuser permissions from `roles.sql`:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cloud-create-connect-tutorials/ =====
+
+A service in Tiger Cloud is a cloud instance which contains your database.
+Each service contains a single database, named `tsdb`.
+You can connect to a service from your local system using the `psql`
+command-line utility. If you've used Postgres before, you might already have
+`psql` installed. If not, check out the [installing psql][install-psql] section.
+
+1. In the [Tiger Cloud Console][timescale-portal], click `Create service`.
+1. Click `Download the cheatsheet` to download an SQL file that contains the
+ login details for your new service. You can also copy the details directly
+ from this page. When you have copied your password,
+ click `I stored my password, go to service overview` at the bottom of the page.
+
+When your service is ready to use, is shows a green `Running` label in the
+ `Service Overview`. You also receive an email confirming that your service
+ is ready to use.
+1. On your local system, at the command prompt, connect to the service using
+ the `Service URL` from the SQL file that you downloaded. When you are
+ prompted, enter the password:
+
+If your connection is successful, you'll see a message like this, followed
+ by the `psql` prompt:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_integration-prereqs-cloud-only/ =====
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need your [connection details][connection-info].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_grafana-connect/ =====
+
+## Connect Grafana to Tiger Cloud
+
+To visualize the results of your queries, enable Grafana to read the data in your service:
+
+1. **Log in to Grafana**
+
+In your browser, log in to either:
+ - Self-hosted Grafana: at `http://localhost:3000/`. The default credentials are `admin`, `admin`.
+ - Grafana Cloud: use the URL and credentials you set when you created your account.
+1. **Add your service as a data source**
+ 1. Open `Connections` > `Data sources`, then click `Add new data source`.
+ 1. Select `PostgreSQL` from the list.
+ 1. Configure the connection:
+ - `Host URL`, `Database name`, `Username`, and `Password`
+
+Configure using your [connection details][connection-info]. `Host URL` is in the format `:`.
+ - `TLS/SSL Mode`: select `require`.
+ - `PostgreSQL options`: enable `TimescaleDB`.
+ - Leave the default setting for all other fields.
+
+1. Click `Save & test`.
+
+Grafana checks that your details are set correctly.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_prereqs-cloud-project-and-self/ =====
+
+To follow the procedure on this page you need to:
+
+* Create a [Tiger Data account][create-account].
+
+This procedure also works for [self-hosted TimescaleDB][enable-timescaledb].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_caggs-function-support/ =====
+
+The following table summarizes the aggregate functions supported in continuous aggregates:
+
+| Function, clause, or feature |TimescaleDB 2.6 and earlier|TimescaleDB 2.7, 2.8, and 2.9|TimescaleDB 2.10 and later|
+|------------------------------------------------------------|-|-|-|
+| Parallelizable aggregate functions |✅|✅|✅|
+| [Non-parallelizable SQL aggregates][postgres-parallel-agg] |❌|✅|✅|
+| `ORDER BY` |❌|✅|✅|
+| Ordered-set aggregates |❌|✅|✅|
+| Hypothetical-set aggregates |❌|✅|✅|
+| `DISTINCT` in aggregate functions |❌|✅|✅|
+| `FILTER` in aggregate functions |❌|✅|✅|
+| `FROM` clause supports `JOINS` |❌|❌|✅|
+
+DISTINCT works in aggregate functions, not in the query definition. For example, for the table:
+
+- The following works:
+
+- This does not:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_psql-installation-macports/ =====
+
+#### Installing psql using MacPorts
+
+1. Install the latest version of `libpqxx`:
+
+1. [](#)View the files that were installed by `libpqxx`:
+
+===== PAGE: https://docs.tigerdata.com/_partials/_toolkit-install-update-redhat-base/ =====
+
+To follow this procedure:
+
+- [Install TimescaleDB][red-hat-install].
+- Create a TimescaleDB repository in your `yum` `repo.d` directory.
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `yum` package manager.
+
+1. Set up the repository:
+
+1. Update your local repository list:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_cookbook-hypertables/ =====
+
+## Hypertable recipes
+
+This section contains recipes about hypertables.
+
+### Remove duplicates from an existing hypertable
+
+Looking to remove duplicates from an existing hypertable? One method is to run a `PARTITION BY` query to get
+`ROW_NUMBER()` and then the `ctid` of rows where `row_number>1`. You then delete these rows. However,
+you need to check `tableoid` and `ctid`. This is because `ctid` is not unique and might be duplicated in
+different chunks. The following code example took 17 hours to process a table with 40 million rows:
+
+Shoutout to **Mathias Ose** and **Christopher Piggott** for this recipe.
+
+### Get faster JOIN queries with Common Table Expressions
+
+Imagine there is a query that joins a hypertable to another table on a shared key:
+
+If you run `EXPLAIN` on this query, you see that the query planner performs a `NestedJoin` between these two tables, which means querying the hypertable multiple times. Even if the hypertable is well indexed, if it is also large, the query will be slow. How do you force a once-only lookup? Use materialized Common Table Expressions (CTEs).
+
+If you split the query into two parts using CTEs, you can `materialize` the hypertable lookup and force Postgres to perform it only once.
+
+Now if you run `EXPLAIN` once again, you see that this query performs only one lookup. Depending on the size of your hypertable, this could result in a multi-hour query taking mere seconds.
+
+Shoutout to **Rowan Molony** for this recipe.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_experimental-private-beta/ =====
+
+This feature is experimental and offered as part of a private beta. Do not use
+this feature in production.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypershift-alternatively/ =====
+
+Alternatively, if you have data in an existing database, you can migrate it
+directly into your new Tiger Cloud service using hypershift. For more information
+about hypershift, including instructions for how to migrate your data, see the
+[Migrate and sync data to Tiger Cloud][migrate].
+
+===== PAGE: https://docs.tigerdata.com/_partials/_timescaledb_supported_windows/ =====
+
+| Operation system | Version |
+|---------------------------------------------|------------|
+| Microsoft Windows | 10, 11 |
+| Microsoft Windows Server | 2019, 2020 |
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_post_data_dump_source_schema/ =====
+
+- `--section=post-data` is used to dump post-data items include definitions of
+ indexes, triggers, rules, and constraints other than validated check
+ constraints.
+
+- `--snapshot` is used to specified the synchronized [snapshot][snapshot] when
+ making a dump of the database.
+
+- `--no-tablespaces` is required because Tiger Cloud does not support
+ tablespaces other than the default. This is a known limitation.
+
+- `--no-owner` is required because Tiger Cloud's `tsdbadmin` user is not a
+ superuser and cannot assign ownership in all cases. This flag means that
+ everything is owned by the user used to connect to the target, regardless of
+ ownership in the source. This is a known limitation.
+
+- `--no-privileges` is required because the `tsdbadmin` user for your Tiger Cloud service is not a
+ superuser and cannot assign privileges in all cases. This flag means that
+ privileges assigned to other users must be reassigned in the target database
+ as a manual clean-up task. This is a known limitation.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_create-hypertable/ =====
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+To create a hypertable:
+
+1. **Connect to your service**
+
+In Tiger Cloud Console, click `Data`, then select a service.
+
+1. **Create a Postgres table**
+
+Copy the following into your query, then click `Run`:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+You see the result immediately:
+
+
+
+===== PAGE: https://docs.tigerdata.com/_partials/_migrate_pre_data_dump_source_schema/ =====
+
+- `--section=pre-data` is used to dump only the definition of tables,
+ sequences, check constraints and inheritance hierarchy. It excludes
+ indexes, foreign key constraints, triggers and rules.
+
+- `--snapshot` is used to specified the synchronized [snapshot][snapshot] when
+ making a dump of the database.
+
+- `--no-tablespaces` is required because Tiger Cloud does not support
+ tablespaces other than the default. This is a known limitation.
+
+- `--no-owner` is required because Tiger Cloud's `tsdbadmin` user is not a
+ superuser and cannot assign ownership in all cases. This flag means that
+ everything is owned by the user used to connect to the target, regardless of
+ ownership in the source. This is a known limitation.
+
+- `--no-privileges` is required because the `tsdbadmin` user for your Tiger Cloud service is not a
+ superuser and cannot assign privileges in all cases. This flag means that
+ privileges assigned to other users must be reassigned in the target database
+ as a manual clean-up task. This is a known limitation.
+
+===== PAGE: https://docs.tigerdata.com/_partials/_hypertable-detailed-size-api/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+rails new my_app -d=postgresql
+ cd my_app
+```
+
+Example 2 (ruby):
+```ruby
+gem 'timescaledb'
+```
+
+Example 3 (bash):
+```bash
+bundle install
+```
+
+Example 4 (yaml):
+```yaml
+default: &default
+ adapter: postgresql
+ encoding: unicode
+ pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
+ url: <%= ENV['DATABASE_URL'] %>
+```
+
+---
+
+## ===== PAGE: https://docs.tigerdata.com/getting-started/try-key-features-timescale-products/ =====
+
+**URL:** llms-txt#=====-page:-https://docs.tigerdata.com/getting-started/try-key-features-timescale-products/-=====
+
+---
diff --git a/skills/timescaledb/references/hyperfunctions.md b/skills/timescaledb/references/hyperfunctions.md
new file mode 100644
index 0000000..b52cd3d
--- /dev/null
+++ b/skills/timescaledb/references/hyperfunctions.md
@@ -0,0 +1,1628 @@
+# Timescaledb - Hyperfunctions
+
+**Pages:** 34
+
+---
+
+## stddev_y() | stddev_x()
+
+**URL:** llms-txt#stddev_y()-|-stddev_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/corr/ =====
+
+---
+
+## timescaledb_information.job_stats
+
+**URL:** llms-txt#timescaledb_information.job_stats
+
+**Contents:**
+- Samples
+- Available columns
+
+Shows information and statistics about jobs run by the automation framework.
+This includes jobs set up for user defined actions and jobs run by policies
+created to manage data retention, continuous aggregates, columnstore, and
+other automation policies. (See [policies][actions]).
+The statistics include information useful for administering jobs and determining
+whether they ought be rescheduled, such as: when and whether the background job
+used to implement the policy succeeded and when it is scheduled to run next.
+
+Get job success/failure information for a specific hypertable.
+
+Get information about continuous aggregate policy related statistics
+
+
+|Name|Type|Description|
+|---|---|---|
+|`hypertable_schema` | TEXT | Schema name of the hypertable |
+|`hypertable_name` | TEXT | Table name of the hypertable |
+|`job_id` | INTEGER | The id of the background job created to implement the policy |
+|`last_run_started_at`| TIMESTAMP WITH TIME ZONE | Start time of the last job|
+|`last_successful_finish`| TIMESTAMP WITH TIME ZONE | Time when the job completed successfully|
+|`last_run_status` | TEXT | Whether the last run succeeded or failed |
+|`job_status`| TEXT | Status of the job. Valid values are 'Running', 'Scheduled' and 'Paused'|
+|`last_run_duration`| INTERVAL | Duration of last run of the job|
+|`next_start` | TIMESTAMP WITH TIME ZONE | Start time of the next run |
+|`total_runs` | BIGINT | The total number of runs of this job|
+|`total_successes` | BIGINT | The total number of times this job succeeded |
+|`total_failures` | BIGINT | The total number of times this job failed |
+
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/continuous_aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT job_id, total_runs, total_failures, total_successes
+ FROM timescaledb_information.job_stats
+ WHERE hypertable_name = 'test_table';
+
+ job_id | total_runs | total_failures | total_successes
+--------+------------+----------------+-----------------
+ 1001 | 1 | 0 | 1
+ 1004 | 1 | 0 | 1
+(2 rows)
+```
+
+---
+
+## percentile_agg()
+
+**URL:** llms-txt#percentile_agg()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/mean/ =====
+
+---
+
+## x_intercept()
+
+**URL:** llms-txt#x_intercept()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/determination_coeff/ =====
+
+---
+
+## approx_percentile_rank()
+
+**URL:** llms-txt#approx_percentile_rank()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/error/ =====
+
+---
+
+## mean()
+
+**URL:** llms-txt#mean()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/approx_percentile/ =====
+
+---
+
+## Hyperfunctions
+
+**URL:** llms-txt#hyperfunctions
+
+**Contents:**
+- Learn hyperfunction basics and install TimescaleDB Toolkit
+- Browse hyperfunctions and TimescaleDB Toolkit features by category
+
+Real-time analytics demands more than basic SQL functions, efficient computation becomes essential as datasets grow in size and complexity. That’s where TimescaleDB hyperfunctions come in: high-performance, SQL-native functions purpose-built for time-series analysis. They are designed to process, aggregate, and analyze large volumes of data with maximum efficiency while maintaining consistently high performance. With hyperfunctions, you can run sophisticated analytical queries and extract meaningful insights in real time.
+
+Hyperfunctions introduce partial aggregation, letting TimescaleDB store intermediate states instead of raw data or final results. These partials can be merged later for rollups (consolidation), eliminating costly reprocessing and slashing compute overhead, especially when paired with continuous aggregates.
+
+Take tracking p95 latency across thousands of app instances as an example:
+
+- With standard SQL, every rollup requires rescanning and resorting massive datasets.
+- With TimescaleDB, the `percentile_agg` hyperfunction stores a compact state per minute, which you simply merge to get hourly or daily percentiles—no full reprocess needed.
+
+
+
+The result? Scalable, real-time percentile analytics that deliver fast, accurate insights across high-ingest, high-resolution data, while keeping resource use lean.
+
+Tiger Cloud includes all hyperfunctions by default, while self-hosted TimescaleDB includes a subset of them. To include all hyperfunctions with TimescaleDB, install the [TimescaleDB Toolkit][install-toolkit] Postgres extension on your self-hosted Postgres deployment.
+
+For more information, read the [hyperfunctions blog post][hyperfunctions-blog].
+
+## Learn hyperfunction basics and install TimescaleDB Toolkit
+
+* [Learn about hyperfunctions][about-hyperfunctions] to understand how they
+ work before using them.
+* Install the [TimescaleDB Toolkit extension][install-toolkit] to access more
+ hyperfunctions on self-hosted TimescaleDB.
+
+## Browse hyperfunctions and TimescaleDB Toolkit features by category
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/hyperloglog/ =====
+
+---
+
+## Troubleshooting hyperfunctions and TimescaleDB Toolkit
+
+**URL:** llms-txt#troubleshooting-hyperfunctions-and-timescaledb-toolkit
+
+**Contents:**
+- Updating the Toolkit extension fails with an error saying `no update path`
+
+This section contains some ideas for troubleshooting common problems experienced
+with hyperfunctions and Toolkit.
+
+
+
+## Updating the Toolkit extension fails with an error saying `no update path`
+
+In some cases, when you create the extension, or use the `ALTER EXTENSION timescaledb_toolkit UPDATE` command to
+update the Toolkit extension, it might fail with an error like this:
+
+This occurs if the list of available extensions does not include the version you
+are trying to upgrade to, and it can occur if the package was not installed
+correctly in the first place. To correct the problem, install the upgrade
+package, restart Postgres, verify the version, and then attempt the update
+again.
+
+#### Troubleshooting Toolkit setup
+
+1. If you're installing Toolkit from a package, check your package manager's
+ local repository list. Make sure the TimescaleDB repository is available and
+ contains Toolkit. For instructions on adding the TimescaleDB repository, see
+ the installation guides:
+ * [Debian/Ubuntu installation guide][deb-install]
+ * [RHEL/CentOS installation guide][rhel-install]
+1. Update your local repository list with `apt update` or `yum update`.
+1. Restart your Postgres service.
+1. Check that the right version of Toolkit is among your available extensions:
+
+The result should look like this:
+
+1. Retry `CREATE EXTENSION` or `ALTER EXTENSION`.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/time-weighted-average/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ERROR: extension "timescaledb_toolkit" has no update path from version "1.2" to version "1.3"
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM pg_available_extensions
+ WHERE name = 'timescaledb_toolkit';
+```
+
+Example 3 (unknown):
+```unknown
+-[ RECORD 1 ]-----+--------------------------------------------------------------------------------------
+ name | timescaledb_toolkit
+ default_version | 1.6.0
+ installed_version | 1.6.0
+ comment | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
+```
+
+---
+
+## Analytics on transport and geospatial data
+
+**URL:** llms-txt#analytics-on-transport-and-geospatial-data
+
+**Contents:**
+- Prerequisites
+- Optimize time-series data in hypertables
+- Optimize your data for real-time analytics
+- Connect Grafana to Tiger Cloud
+- Monitor performance over time
+- Optimize revenue potential
+ - Set up your data for geospatial queries
+ - Visualize the area where you can make the most money
+
+Real-time analytics refers to the process of collecting, analyzing, and interpreting data instantly as it
+is generated. This approach enables you track and monitor activity, and make decisions based on real-time
+insights on data stored in a Tiger Cloud service.
+
+
+
+This page shows you how to integrate [Grafana][grafana-docs] with a Tiger Cloud service and make insights based on visualization
+of data optimized for size and speed in the columnstore.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install and run [self-managed Grafana][grafana-self-managed], or sign up for [Grafana Cloud][grafana-cloud].
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+1. **Import time-series data into a hypertable**
+
+1. Unzip [nyc_data.tar.gz](https://assets.timescale.com/docs/downloads/nyc_data.tar.gz) to a ``.
+
+This test dataset contains historical data from New York's yellow taxi network.
+
+To import up to 100GB of data directly from your current Postgres-based database,
+ [migrate with downtime][migrate-with-downtime] using native Postgres tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by Tiger Data. To add data from non-Postgres
+ data sources, see [Import and ingest data][data-ingest].
+
+1. In Terminal, navigate to `` and update the following string with [your connection details][connection-info]
+ to connect to your service.
+
+1. Create an optimized hypertable for your time-series data:
+
+1. Create a [hypertable][hypertables-section] with [hypercore][hypercore] enabled by default for your
+ time-series data using [CREATE TABLE][hypertable-create-table]. For [efficient queries][secondary-indexes]
+ on data in the columnstore, remember to `segmentby` the column you will use most often to filter your data.
+
+In your sql client, run the following command:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+1. Add another dimension to partition your hypertable more efficiently:
+
+1. Create an index to support efficient queries by vendor, rate code, and passenger count:
+
+1. Create Postgres tables for relational data:
+
+1. Add a table to store the payment types data:
+
+1. Add a table to store the rates data:
+
+1. Upload the dataset to your service
+
+1. **Have a quick look at your data**
+
+You query hypertables in exactly the same way as you would a relational Postgres table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [Tiger Cloud Console][portal-data-mode] for all your Tiger Cloud services.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [Tiger Cloud Console][portal-ops-mode] for a Tiger Cloud service.
+ - **psql**: easily run queries on your Tiger Cloud services or self-hosted TimescaleDB deployment from Terminal.
+
+For example:
+ - Display the number of rides for each fare type:
+
+ This simple query runs in 3 seconds. You see something like:
+
+| rate_code | num_trips |
+ |-----------------|-----------|
+ |1 | 2266401|
+ |2 | 54832|
+ |3 | 4126|
+ |4 | 967|
+ |5 | 7193|
+ |6 | 17|
+ |99 | 42|
+
+- To select all rides taken in the first week of January 2016, and return the total number of trips taken for each rate code:
+
+ On this large amount of data, this analytical query on data in the rowstore takes about 59 seconds. You see something like:
+
+| description | num_trips |
+ |-----------------|-----------|
+ | group ride | 17 |
+ | JFK | 54832 |
+ | Nassau or Westchester | 967 |
+ | negotiated fare | 7193 |
+ | Newark | 4126 |
+ | standard rate | 2266401 |
+
+## Optimize your data for real-time analytics
+
+When TimescaleDB converts a chunk to the columnstore, it automatically creates a different schema for your
+data. TimescaleDB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
+you write to and read from the columstore.
+
+To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
+to the columnstore:
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
+ You can also connect to your serviceusing [psql][connect-using-psql].
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+For example, convert data older than 8 days old to the columstore:
+
+ See [add_columnstore_policy][add_columnstore_policy].
+
+The data you imported for this tutorial is from 2016, it was already added to the columnstore by default. However,
+ you get the idea. To see the space savings in action, follow [Try the key Tiger Data features][try-timescale-features].
+
+Just to hit this one home, by converting cooling data to the columnstore, you have increased the speed of your analytical
+queries by a factor of 10, and reduced storage by up to 90%.
+
+## Connect Grafana to Tiger Cloud
+
+To visualize the results of your queries, enable Grafana to read the data in your service:
+
+1. **Log in to Grafana**
+
+In your browser, log in to either:
+ - Self-hosted Grafana: at `http://localhost:3000/`. The default credentials are `admin`, `admin`.
+ - Grafana Cloud: use the URL and credentials you set when you created your account.
+1. **Add your service as a data source**
+ 1. Open `Connections` > `Data sources`, then click `Add new data source`.
+ 1. Select `PostgreSQL` from the list.
+ 1. Configure the connection:
+ - `Host URL`, `Database name`, `Username`, and `Password`
+
+Configure using your [connection details][connection-info]. `Host URL` is in the format `:`.
+ - `TLS/SSL Mode`: select `require`.
+ - `PostgreSQL options`: enable `TimescaleDB`.
+ - Leave the default setting for all other fields.
+
+1. Click `Save & test`.
+
+Grafana checks that your details are set correctly.
+
+## Monitor performance over time
+
+A Grafana dashboard represents a view into the performance of a system, and each dashboard consists of one or
+more panels, which represent information about a specific metric related to that system.
+
+To visually monitor the volume of taxi rides over time:
+
+1. **Create the dashboard**
+
+1. On the `Dashboards` page, click `New` and select `New dashboard`.
+
+1. Click `Add visualization`.
+ 1. Select the data source that connects to your Tiger Cloud service.
+ The `Time series` visualization is chosen by default.
+ 
+ 1. In the `Queries` section, select `Code`, then select `Time series` in `Format`.
+ 1. Select the data range for your visualization:
+ the data set is from 2016. Click the date range above the panel and set:
+ - From:
+ - To:
+
+1. **Combine TimescaleDB and Grafana functionality to analyze your data**
+
+Combine a TimescaleDB [time_bucket][use-time-buckets], with the Grafana `_timefilter()` function to set the
+ `pickup_datetime` column as the filtering range for your visualizations.
+
+ This query groups the results by day and orders them by time.
+
+
+
+1. **Click `Save dashboard`**
+
+## Optimize revenue potential
+
+Having all this data is great but how do you use it? Monitoring data is useful to check what
+has happened, but how can you analyse this information to your advantage? This section explains
+how to create a visualization that shows how you can maximize potential revenue.
+
+### Set up your data for geospatial queries
+
+To add geospatial analysis to your ride count visualization, you need geospatial data to work out which trips
+originated where. As TimescaleDB is compatible with all Postgres extensions, use [PostGIS][postgis] to slice
+data by time and location.
+
+1. Connect to your [Tiger Cloud service][in-console-editors] and add the PostGIS extension:
+
+1. Add geometry columns for pick up and drop off locations:
+
+1. Convert the latitude and longitude points into geometry coordinates that work with PostGIS:
+
+This updates 10,906,860 rows of data on both columns, it takes a while. Coffee is your friend.
+
+### Visualize the area where you can make the most money
+
+In this section you visualize a query that returns rides longer than 5 miles for
+trips taken within 2 km of Times Square. The data includes the distance travelled and
+is `GROUP BY` `trip_distance` and location so that Grafana can plot the data properly.
+
+This enables you to see where a taxi driver is most likely to pick up a passenger who wants a longer ride,
+and make more money.
+
+1. **Create a geolocalization dashboard**
+
+1. In Grafana, create a new dashboard that is connected to your Tiger Cloud service data source with a Geomap
+ visualization.
+
+1. In the `Queries` section, select `Code`, then select the Time series `Format`.
+
+
+
+1. To find rides longer than 5 miles in Manhattan, paste the following query:
+
+You see a world map with a dot on New York.
+ 1. Zoom into your map to see the visualization clearly.
+
+1. **Customize the visualization**
+
+1. In the Geomap options, under `Map Layers`, click `+ Add layer` and select `Heatmap`.
+ You now see the areas where a taxi driver is most likely to pick up a passenger who wants a
+ longer ride, and make more money.
+
+
+
+You have integrated Grafana with a Tiger Cloud service and made insights based on visualization of
+your data.
+
+===== PAGE: https://docs.tigerdata.com/tutorials/real-time-analytics-energy-consumption/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+psql -d "postgres://:@:/?sslmode=require"
+```
+
+Example 2 (sql):
+```sql
+CREATE TABLE "rides"(
+ vendor_id TEXT,
+ pickup_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
+ dropoff_datetime TIMESTAMP WITHOUT TIME ZONE NOT NULL,
+ passenger_count NUMERIC,
+ trip_distance NUMERIC,
+ pickup_longitude NUMERIC,
+ pickup_latitude NUMERIC,
+ rate_code INTEGER,
+ dropoff_longitude NUMERIC,
+ dropoff_latitude NUMERIC,
+ payment_type INTEGER,
+ fare_amount NUMERIC,
+ extra NUMERIC,
+ mta_tax NUMERIC,
+ tip_amount NUMERIC,
+ tolls_amount NUMERIC,
+ improvement_surcharge NUMERIC,
+ total_amount NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='pickup_datetime',
+ tsdb.create_default_indexes=false,
+ tsdb.segmentby='vendor_id',
+ tsdb.orderby='pickup_datetime DESC'
+ );
+```
+
+Example 3 (sql):
+```sql
+SELECT add_dimension('rides', by_hash('payment_type', 2));
+```
+
+Example 4 (sql):
+```sql
+CREATE INDEX ON rides (vendor_id, pickup_datetime DESC);
+ CREATE INDEX ON rides (rate_code, pickup_datetime DESC);
+ CREATE INDEX ON rides (passenger_count, pickup_datetime DESC);
+```
+
+---
+
+## variance_y() | variance_x()
+
+**URL:** llms-txt#variance_y()-|-variance_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/skewness_y_x/ =====
+
+---
+
+## approx_percentile()
+
+**URL:** llms-txt#approx_percentile()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/num_vals/ =====
+
+---
+
+## sum()
+
+**URL:** llms-txt#sum()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/stats_agg/ =====
+
+---
+
+## sum_y() | sum_x()
+
+**URL:** llms-txt#sum_y()-|-sum_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/kurtosis_y_x/ =====
+
+---
+
+## About TimescaleDB hyperfunctions
+
+**URL:** llms-txt#about-timescaledb-hyperfunctions
+
+**Contents:**
+- Available hyperfunctions
+- Function pipelines
+- Toolkit feature development
+- Contribute to TimescaleDB Toolkit
+
+TimescaleDB hyperfunctions are a specialized set of functions that power real-time analytics on time series and events.
+IoT devices, IT systems, marketing analytics, user behavior, financial metrics, cryptocurrency - these are only a few examples of domains where
+hyperfunctions can make a huge difference. Hyperfunctions provide you with meaningful, actionable insights in real time.
+
+Tiger Cloud includes all hyperfunctions by default, while self-hosted TimescaleDB includes a subset of them. For
+additional hyperfunctions, install the [TimescaleDB Toolkit][install-toolkit] Postgres extension.
+
+## Available hyperfunctions
+
+Here is a list of all the hyperfunctions provided by TimescaleDB. Hyperfunctions
+with a tick in the `Toolkit` column require an installation of TimescaleDB Toolkit for self-hosted deployments. Hyperfunctions
+with a tick in the `Experimental` column are still under development.
+
+Experimental features could have bugs. They might not be backwards compatible,
+and could be removed in future releases. Use these features at your own risk, and
+do not use any experimental features in production.
+
+When you upgrade the `timescaledb` extension, the experimental schema is removed
+by default. To use experimental features after an upgrade, you need to add the
+experimental schema again.
+
+
+
+For more information about each of the API calls listed in this table, see the
+[hyperfunction API documentation][api-hyperfunctions].
+
+## Function pipelines
+
+Function pipelines are an experimental feature, designed to radically improve
+the developer ergonomics of analyzing data in Postgres and SQL, by applying
+principles from functional programming and popular tools like Python's Pandas,
+and PromQL.
+
+SQL is the best language for data analysis, but it is not perfect, and at times
+can get quite unwieldy. For example, this query gets data from the last day from
+the measurements table, sorts the data by the time column, calculates the delta
+between the values, takes the absolute value of the delta, and then takes the
+sum of the result of the previous steps:
+
+You can express the same query with a function pipeline like this:
+
+Function pipelines are completely SQL compliant, meaning that any tool that
+speaks SQL is able to support data analysis using function pipelines.
+
+For more information about how function pipelines work, read our
+[blog post][blog-function-pipelines].
+
+## Toolkit feature development
+
+TimescaleDB Toolkit features are developed in the open. As features are developed
+they are categorized as experimental, beta, stable, or deprecated. This
+documentation covers the stable features, but more information on our
+experimental features in development can be found in the
+[Toolkit repository][gh-docs].
+
+## Contribute to TimescaleDB Toolkit
+
+We want and need your feedback! What are the frustrating parts of analyzing
+time-series data? What takes far more code than you feel it should? What runs
+slowly, or only runs quickly after many rewrites? We want to solve
+community-wide problems and incorporate as much feedback as possible.
+
+* Join the [discussion][gh-discussions].
+* Check out the [proposed features][gh-proposed].
+* Explore the current [feature requests][gh-requests].
+* Add your own [feature request][gh-newissue].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/approx-count-distincts/ =====
+
+**Examples:**
+
+Example 1 (SQL):
+```SQL
+SELECT device id,
+sum(abs_delta) as volatility
+FROM (
+ SELECT device_id,
+abs(val - lag(val) OVER last_day) as abs_delta
+FROM measurements
+WHERE ts >= now()-'1 day'::interval) calc_delta
+GROUP BY device_id;
+```
+
+Example 2 (SQL):
+```SQL
+SELECT device_id,
+ timevector(ts, val) -> sort() -> delta() -> abs() -> sum() as volatility
+FROM measurements
+WHERE ts >= now()-'1 day'::interval
+GROUP BY device_id;
+```
+
+---
+
+## kurtosis()
+
+**URL:** llms-txt#kurtosis()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/num_vals/ =====
+
+---
+
+## num_vals()
+
+**URL:** llms-txt#num_vals()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/intro/ =====
+
+Estimate the value at a given percentile, or the percentile rank of a given
+value, using the UddSketch algorithm. This estimation is more memory- and
+CPU-efficient than an exact calculation using Postgres's `percentile_cont` and
+`percentile_disc` functions.
+
+`uddsketch` is one of two advanced percentile approximation aggregates provided
+in TimescaleDB Toolkit. It produces stable estimates within a guaranteed
+relative error.
+
+The other advanced percentile approximation aggregate is [`tdigest`][tdigest],
+which is more accurate at extreme quantiles, but is somewhat dependent on input
+order.
+
+If you aren't sure which aggregate to use, try the default percentile estimation
+method, [`percentile_agg`][percentile_agg]. It uses the `uddsketch` algorithm
+with some sensible defaults.
+
+For more information about percentile approximation algorithms, see the
+[algorithms overview][algorithms].
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/approx_percentile_rank/ =====
+
+---
+
+## Last observation carried forward
+
+**URL:** llms-txt#last-observation-carried-forward
+
+Last observation carried forward (LOCF) is a form of linear interpolation used
+to fill gaps in your data. It takes the last known value and uses it as a
+replacement for the missing data.
+
+For more information about gapfilling and interpolation API calls, see the
+[hyperfunction API documentation][hyperfunctions-api-gapfilling].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/stats-aggs/ =====
+
+---
+
+## kurtosis_y() | kurtosis_x()
+
+**URL:** llms-txt#kurtosis_y()-|-kurtosis_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/x_intercept/ =====
+
+---
+
+## average_y() | average_x()
+
+**URL:** llms-txt#average_y()-|-average_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/intercept/ =====
+
+---
+
+## Real-time analytics with Tiger Cloud and Grafana
+
+**URL:** llms-txt#real-time-analytics-with-tiger-cloud-and-grafana
+
+**Contents:**
+- Prerequisites
+- Optimize time-series data in hypertables
+- Optimize your data for real-time analytics
+- Write fast analytical queries
+- Connect Grafana to Tiger Cloud
+- Visualize energy consumption
+
+Energy providers understand that customers tend to lose patience when there is not enough power for them
+to complete day-to-day activities. Task one is keeping the lights on. If you are transitioning to renewable energy,
+it helps to know when you need to produce energy so you can choose a suitable energy source.
+
+Real-time analytics refers to the process of collecting, analyzing, and interpreting data instantly as it is generated.
+This approach enables you to track and monitor activity, make the decisions based on real-time insights on data stored in
+a Tiger Cloud service and keep those lights on.
+
+[Grafana][grafana-docs] is a popular data visualization tool that enables you to create customizable dashboards
+and effectively monitor your systems and applications.
+
+
+
+This page shows you how to integrate Grafana with a Tiger Cloud service and make insights based on visualization of
+data optimized for size and speed in the columnstore.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install and run [self-managed Grafana][grafana-self-managed], or sign up for [Grafana Cloud][grafana-cloud].
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+1. **Import time-series data into a hypertable**
+
+1. Unzip [metrics.csv.gz](https://assets.timescale.com/docs/downloads/metrics.csv.gz) to a ``.
+
+This test dataset contains energy consumption data.
+
+To import up to 100GB of data directly from your current Postgres based database,
+ [migrate with downtime][migrate-with-downtime] using native Postgres tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by Tiger Data. To add data from non-Postgres
+ data sources, see [Import and ingest data][data-ingest].
+
+1. In Terminal, navigate to `` and update the following string with [your connection details][connection-info]
+ to connect to your service.
+
+1. Create an optimized hypertable for your time-series data:
+
+1. Create a [hypertable][hypertables-section] with [hypercore][hypercore] enabled by default for your
+ time-series data using [CREATE TABLE][hypertable-create-table]. For [efficient queries][secondary-indexes]
+ on data in the columnstore, remember to `segmentby` the column you will use most often to filter your data.
+
+In your sql client, run the following command:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+1. Upload the dataset to your service
+
+1. **Have a quick look at your data**
+
+You query hypertables in exactly the same way as you would a relational Postgres table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [Tiger Cloud Console][portal-data-mode] for all your Tiger Cloud services.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [Tiger Cloud Console][portal-ops-mode] for a Tiger Cloud service.
+ - **psql**: easily run queries on your Tiger Cloud services or self-hosted TimescaleDB deployment from Terminal.
+
+On this amount of data, this query on data in the rowstore takes about 3.6 seconds. You see something like:
+
+| Time | value |
+ |------------------------------|-------|
+ | 2023-05-29 22:00:00+00 | 23.1 |
+ | 2023-05-28 22:00:00+00 | 19.5 |
+ | 2023-05-30 22:00:00+00 | 25 |
+ | 2023-05-31 22:00:00+00 | 8.1 |
+
+## Optimize your data for real-time analytics
+
+When TimescaleDB converts a chunk to the columnstore, it automatically creates a different schema for your
+data. TimescaleDB creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
+you write to and read from the columstore.
+
+To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data
+to the columnstore:
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
+ You can also connect to your service using [psql][connect-using-psql].
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+For example, 60 days after the data was added to the table:
+
+ See [add_columnstore_policy][add_columnstore_policy].
+
+1. **Faster analytical queries on data in the columnstore**
+
+Now run the analytical query again:
+
+ On this amount of data, this analytical query on data in the columnstore takes about 250ms.
+
+Just to hit this one home, by converting cooling data to the columnstore, you have increased the speed of your analytical
+queries by a factor of 10, and reduced storage by up to 90%.
+
+## Write fast analytical queries
+
+Aggregation is a way of combining data to get insights from it. Average, sum, and count are all examples of simple
+aggregates. However, with large amounts of data aggregation slows things down, quickly. Continuous aggregates
+are a kind of hypertable that is refreshed automatically in the background as new data is added, or old data is
+modified. Changes to your dataset are tracked, and the hypertable behind the continuous aggregate is automatically
+updated in the background.
+
+By default, querying continuous aggregates provides you with real-time data. Pre-aggregated data from the materialized
+view is combined with recent data that hasn't been aggregated yet. This gives you up-to-date results on every query.
+
+You create continuous aggregates on uncompressed data in high-performance storage. They continue to work
+on [data in the columnstore][test-drive-enable-compression]
+and [rarely accessed data in tiered storage][test-drive-tiered-storage]. You can even
+create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+
+1. **Monitor energy consumption on a day-to-day basis**
+
+1. Create a continuous aggregate `kwh_day_by_day` for energy consumption:
+
+1. Add a refresh policy to keep `kwh_day_by_day` up-to-date:
+
+1. **Monitor energy consumption on an hourly basis**
+
+1. Create a continuous aggregate `kwh_hour_by_hour` for energy consumption:
+
+1. Add a refresh policy to keep the continuous aggregate up-to-date:
+
+1. **Analyze your data**
+
+Now you have made continuous aggregates, it could be a good idea to use them to perform analytics on your data.
+ For example, to see how average energy consumption changes during weekdays over the last year, run the following query:
+
+You see something like:
+
+| day | ordinal | value |
+ | --- | ------- | ----- |
+ | Mon | 2 | 23.08078714975423 |
+ | Sun | 1 | 19.511430831944395 |
+ | Tue | 3 | 25.003118897837307 |
+ | Wed | 4 | 8.09300571759772 |
+
+## Connect Grafana to Tiger Cloud
+
+To visualize the results of your queries, enable Grafana to read the data in your service:
+
+1. **Log in to Grafana**
+
+In your browser, log in to either:
+ - Self-hosted Grafana: at `http://localhost:3000/`. The default credentials are `admin`, `admin`.
+ - Grafana Cloud: use the URL and credentials you set when you created your account.
+1. **Add your service as a data source**
+ 1. Open `Connections` > `Data sources`, then click `Add new data source`.
+ 1. Select `PostgreSQL` from the list.
+ 1. Configure the connection:
+ - `Host URL`, `Database name`, `Username`, and `Password`
+
+Configure using your [connection details][connection-info]. `Host URL` is in the format `:`.
+ - `TLS/SSL Mode`: select `require`.
+ - `PostgreSQL options`: enable `TimescaleDB`.
+ - Leave the default setting for all other fields.
+
+1. Click `Save & test`.
+
+Grafana checks that your details are set correctly.
+
+## Visualize energy consumption
+
+A Grafana dashboard represents a view into the performance of a system, and each dashboard consists of one or
+more panels, which represent information about a specific metric related to that system.
+
+To visually monitor the volume of energy consumption over time:
+
+1. **Create the dashboard**
+
+1. On the `Dashboards` page, click `New` and select `New dashboard`.
+
+1. Click `Add visualization`, then select the data source that connects to your Tiger Cloud service and the `Bar chart`
+ visualization.
+
+
+ 1. In the `Queries` section, select `Code`, then run the following query based on your continuous aggregate:
+
+This query averages the results for households in a specific time zone by hour and orders them by time.
+ Because you use a continuous aggregate, this data is always correct in real time.
+
+
+
+You see that energy consumption is highest in the evening and at breakfast time. You also know that the wind
+ drops off in the evening. This data proves that you need to supply a supplementary power source for peak times,
+ or plan to store energy during the day for peak times.
+
+1. **Click `Save dashboard`**
+
+You have integrated Grafana with a Tiger Cloud service and made insights based on visualization of your data.
+
+===== PAGE: https://docs.tigerdata.com/tutorials/simulate-iot-sensor-data/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+psql -d "postgres://:@:/?sslmode=require"
+```
+
+Example 2 (sql):
+```sql
+CREATE TABLE "metrics"(
+ created timestamp with time zone default now() not null,
+ type_id integer not null,
+ value double precision not null
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='created',
+ tsdb.segmentby = 'type_id',
+ tsdb.orderby = 'created DESC'
+ );
+```
+
+Example 3 (sql):
+```sql
+\COPY metrics FROM metrics.csv CSV;
+```
+
+Example 4 (sql):
+```sql
+SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",
+ round((last(value, created) - first(value, created)) * 100.) / 100. AS value
+ FROM metrics
+ WHERE type_id = 5
+ GROUP BY 1;
+```
+
+---
+
+## stats_agg() (one variable)
+
+**URL:** llms-txt#stats_agg()-(one-variable)
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/average/ =====
+
+---
+
+## rollup()
+
+**URL:** llms-txt#rollup()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/approx_percentile_array/ =====
+
+---
+
+## Percentile approximation
+
+**URL:** llms-txt#percentile-approximation
+
+In general, percentiles are useful for understanding the distribution of data.
+The fiftieth percentile is the point at which half of your data is greater and
+half is lesser. The tenth percentile is the point at which 90% of the data is
+greater, and 10% is lesser. The ninety-ninth percentile is the point at which 1%
+is greater, and 99% is lesser.
+
+The fiftieth percentile, or median, is often a more useful measure than the average,
+especially when your data contains outliers. Outliers can dramatically change
+the average, but do not affect the median as much. For example, if you have
+three rooms in your house and two of them are 40℉ (4℃) and one is 130℉ (54℃),
+the average room temperature is 70℉ (21℃), which doesn't tell you much. However,
+the fiftieth percentile temperature is 40℉ (4℃), which tells you that at least half
+your rooms are at refrigerator temperatures (also, you should probably get your
+heating checked!)
+
+Percentiles are sometimes avoided because calculating them requires more CPU and
+memory than an average or other aggregate measures. This is because an exact
+computation of the percentile needs the full dataset as an ordered list.
+TimescaleDB uses approximation algorithms to calculate a percentile without
+requiring all of the data. This also makes them more compatible with continuous
+aggregates. By default, TimescaleDB uses `uddsketch`, but you can also choose to
+use `tdigest`. For more information about these algorithms, see the
+[advanced aggregation methods][advanced-agg] documentation.
+
+Technically, a percentile divides a group into 100 equally sized pieces, while a
+quantile divides a group into an arbitrary number of pieces. Because we don't
+always use exactly 100 buckets, "quantile" is the more technically correct term
+in this case. However, we use the word "percentile" because it's a more common
+word for this type of function.
+
+* For more information about how percentile approximation works, read our
+ [percentile approximation blog][blog-percentile-approx].
+* For more information about percentile approximation API calls, see the
+ [hyperfunction API documentation][hyperfunctions-api-approx-percentile].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/advanced-agg/ =====
+
+---
+
+## stats_agg() (two variables)
+
+**URL:** llms-txt#stats_agg()-(two-variables)
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/average_y_x/ =====
+
+---
+
+## skewness()
+
+**URL:** llms-txt#skewness()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/rolling/ =====
+
+---
+
+## rolling()
+
+**URL:** llms-txt#rolling()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/slope/ =====
+
+---
+
+## uddsketch()
+
+**URL:** llms-txt#uddsketch()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/uddsketch/percentile_agg/ =====
+
+---
+
+## determination_coeff()
+
+**URL:** llms-txt#determination_coeff()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/variance_y_x/ =====
+
+---
+
+## approx_percentile_array()
+
+**URL:** llms-txt#approx_percentile_array()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/counter_agg/delta/ =====
+
+---
+
+## Tiger Data architecture for real-time analytics
+
+**URL:** llms-txt#tiger-data-architecture-for-real-time-analytics
+
+**Contents:**
+- Introduction
+ - What is real-time analytics?
+ - Tiger Cloud: real-time analytics from Postgres
+- Data model
+ - Efficient data partitioning
+ - Row-columnar storage
+ - Columnar storage layout
+ - Data mutability
+- Query optimizations
+ - Skip unnecessary data
+
+Tiger Data has created a powerful application database for real-time analytics on time-series data. It integrates seamlessly
+with the Postgres ecosystem and enhances it with automatic time-based partitioning, hybrid row-columnar storage, and vectorized execution—enabling high-ingest performance, sub-second queries, and full SQL support at scale.
+
+Tiger Cloud offers managed database services that provide a stable and reliable environment for your
+applications. Each service is based on a Postgres database instance and the TimescaleDB extension.
+
+By making use of incrementally updated materialized views and advanced analytical functions, TimescaleDB reduces compute overhead and improves query efficiency. Developers can continue using familiar SQL workflows and tools, while benefiting from a database purpose-built for fast, scalable analytics.
+
+This document outlines the architectural choices and optimizations that power TimescaleDB and Tiger Cloud’s performance and
+scalability while preserving Postgres’s reliability and transactional guarantees.
+
+Want to read this whitepaper from the comfort of your own computer?
+
+
+ [Tiger Data architecture for real-time analytics (PDF)](https://assets.timescale.com/docs/downloads/tigerdata-whitepaper.pdf)
+
+
+### What is real-time analytics?
+
+Real-time analytics enables applications to process and query data as it is generated and as it accumulates, delivering immediate and ongoing insights for decision-making. Unlike traditional analytics, which relies on batch processing and delayed reporting, real-time analytics supports *both* instant queries on fresh data and fast exploration of historical trends—powering applications with sub-second query performance across vast, continuously growing datasets.
+
+Many modern applications depend on real-time analytics to drive critical functionality:
+
+* **IoT monitoring systems** track sensor data over time, identifying long-term performance patterns while still surfacing anomalies as they arise. This allows businesses to optimize maintenance schedules, reduce costs, and improve reliability.
+* **Financial and business intelligence platforms** analyze both current and historical data to detect trends, assess risk, and uncover opportunities—from tracking stock performance over a day, week, or year to identifying spending patterns across millions of transactions.
+* **Interactive customer dashboards** empower users to explore live and historical data in a seamless experience—whether it's a SaaS product providing real-time analytics on business operations, a media platform analyzing content engagement, or an e-commerce site surfacing personalized recommendations based on recent and past behavior.
+
+Real-time analytics isn't just about reacting to the latest data, although that is critically important. It's also about delivering fast, interactive, and scalable insights across all your data, enabling better decision-making and richer user experiences. Unlike traditional ad-hoc analytics used by analysts, real-time analytics powers applications—driving dynamic dashboards, automated decisions, and user-facing insights at scale.
+
+To achieve this, real-time analytics systems must meet several key requirements:
+
+* **Low-latency queries** ensure sub-second response times even under high load, enabling fast insights for dashboards, monitoring, and alerting.
+* **Low-latency ingest** minimizes the lag between when data is created and when it becomes available for analysis, ensuring fresh and accurate insights.
+* **Data mutability** allows for efficient updates, corrections, and backfills, ensuring analytics reflect the most accurate state of the data.
+* **Concurrency and scalability** enable systems to handle high query volumes and growing workloads without degradation in performance.
+* **Seamless access to both recent and historical data** ensures fast queries across time, whether analyzing live, streaming data, or running deep historical queries on days or months of information.
+* **Query flexibility** provides full SQL support, allowing for complex queries with joins, filters, aggregations, and analytical functions.
+
+### Tiger Cloud: real-time analytics from Postgres
+
+Tiger Cloud is a high-performance database that brings real-time analytics to applications. It combines fast queries,
+high ingest performance, and full SQL support—all while ensuring scalability and reliability. Tiger Cloud extends Postgres with the TimescaleDB extension. It enables sub-second queries on vast amounts of incoming data while providing optimizations designed for continuously updating datasets.
+
+Tiger Cloud achieves this through the following optimizations:
+
+* **Efficient data partitioning:** automatically and transparently partitioning data into chunks, ensuring fast queries, minimal indexing overhead, and seamless scalability
+* **Row-columnar storage:** providing the flexibility of a row store for transactions and the performance of a column store for analytics
+* **Optimized query execution: **using techniques like chunk and batch exclusion, columnar storage, and vectorized execution to minimize latency
+* **Continuous aggregates:** precomputing analytical results for fast insights without expensive reprocessing
+* **Cloud-native operation: **compute/compute separation, elastic usage-based storage, horizontal scale out, data tiering to object storage
+* **Operational simplicity: **offering high availability, connection pooling, and automated backups for reliable and scalable real-time applications
+
+With Tiger Cloud, developers can build low-latency, high-concurrency applications that seamlessly handle streaming data, historical queries, and real-time analytics while leveraging the familiarity and power of Postgres.
+
+Today's applications demand a database that can handle real-time analytics and transactional queries without sacrificing speed, flexibility, or SQL compatibility (including joins between tables). TimescaleDB achieves this with **hypertables**, which provide an automatic partitioning engine, and **hypercore**, a hybrid row-columnar storage engine designed to deliver high-performance queries and efficient compression (up to 95%) within Postgres.
+
+### Efficient data partitioning
+
+TimescaleDB provides hypertables, a table abstraction that automatically partitions data into chunks in real time (using time stamps or incrementing IDs) to ensure fast queries and predictable performance as datasets grow. Unlike traditional relational databases that require manual partitioning, hypertables automate all aspects of partition management, keeping locking minimal even under high ingest load.
+
+At ingest time, hypertables ensure that Postgres can deal with a constant stream of data without suffering from table bloat and index degradation by automatically partitioning data across time. Because each chunk is ordered by time and has its own indexes and storage, writes are usually isolated to small, recent chunks—keeping index sizes small, improving cache locality, and reducing the overhead of vacuum and background maintenance operations. This localized write pattern minimizes write amplification and ensures consistently high ingest performance, even as total data volume grows.
+
+At query time, hypertables efficiently exclude irrelevant chunks from the execution plan when the partitioning column is used in a `WHERE` clause. This architecture ensures fast query execution, avoiding the gradual slowdowns that affect non-partitioned tables as they accumulate millions of rows. Chunk-local indexes keep indexing overhead minimal, ensuring index operations scans remain efficient regardless of dataset size.
+
+
+ +
+
+Hypertables are the foundation for all of TimescaleDB’s real-time analytics capabilities. They enable seamless data ingestion, high-throughput writes, optimized query execution, and chunk-based lifecycle management—including automated data retention (drop a chunk) and data tiering (move a chunk to object storage).
+
+### Row-columnar storage
+
+Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore, ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+### Columnar storage layout
+
+TimescaleDB’s columnar storage layout optimizes analytical query performance by structuring data efficiently on disk, reducing scan times, and maximizing compression rates. Unlike traditional row-based storage, where data is stored sequentially by row, columnar storage organizes and compresses data by column, allowing queries to retrieve only the necessary fields in batches rather than scanning entire rows. But unlike many column store implementations, TimescaleDB’s columnstore supports full mutability—inserts, upserts, updates, and deletes, even at the individual record level—with transactional guarantees. Data is also immediately visible to queries as soon as it is written.
+
+
+
+
+
+Hypertables are the foundation for all of TimescaleDB’s real-time analytics capabilities. They enable seamless data ingestion, high-throughput writes, optimized query execution, and chunk-based lifecycle management—including automated data retention (drop a chunk) and data tiering (move a chunk to object storage).
+
+### Row-columnar storage
+
+Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore, ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+### Columnar storage layout
+
+TimescaleDB’s columnar storage layout optimizes analytical query performance by structuring data efficiently on disk, reducing scan times, and maximizing compression rates. Unlike traditional row-based storage, where data is stored sequentially by row, columnar storage organizes and compresses data by column, allowing queries to retrieve only the necessary fields in batches rather than scanning entire rows. But unlike many column store implementations, TimescaleDB’s columnstore supports full mutability—inserts, upserts, updates, and deletes, even at the individual record level—with transactional guarantees. Data is also immediately visible to queries as soon as it is written.
+
+
+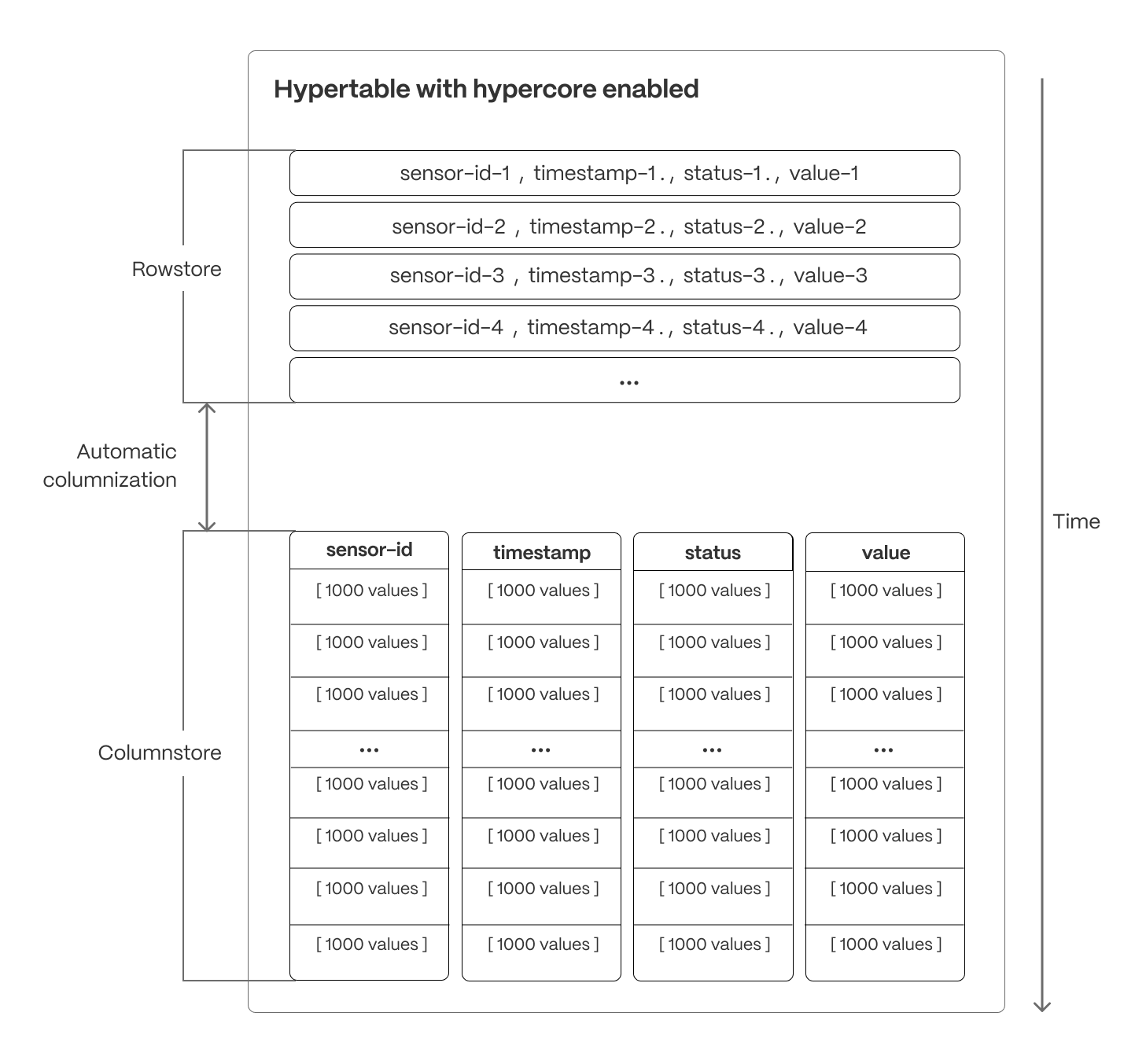 +
+
+#### Columnar batches
+
+TimescaleDB uses columnar collocation and columnar compression within row-based storage to optimize analytical query performance while maintaining full Postgres compatibility. This approach ensures efficient storage, high compression ratios, and rapid query execution.
+
+
+
+
+
+#### Columnar batches
+
+TimescaleDB uses columnar collocation and columnar compression within row-based storage to optimize analytical query performance while maintaining full Postgres compatibility. This approach ensures efficient storage, high compression ratios, and rapid query execution.
+
+
+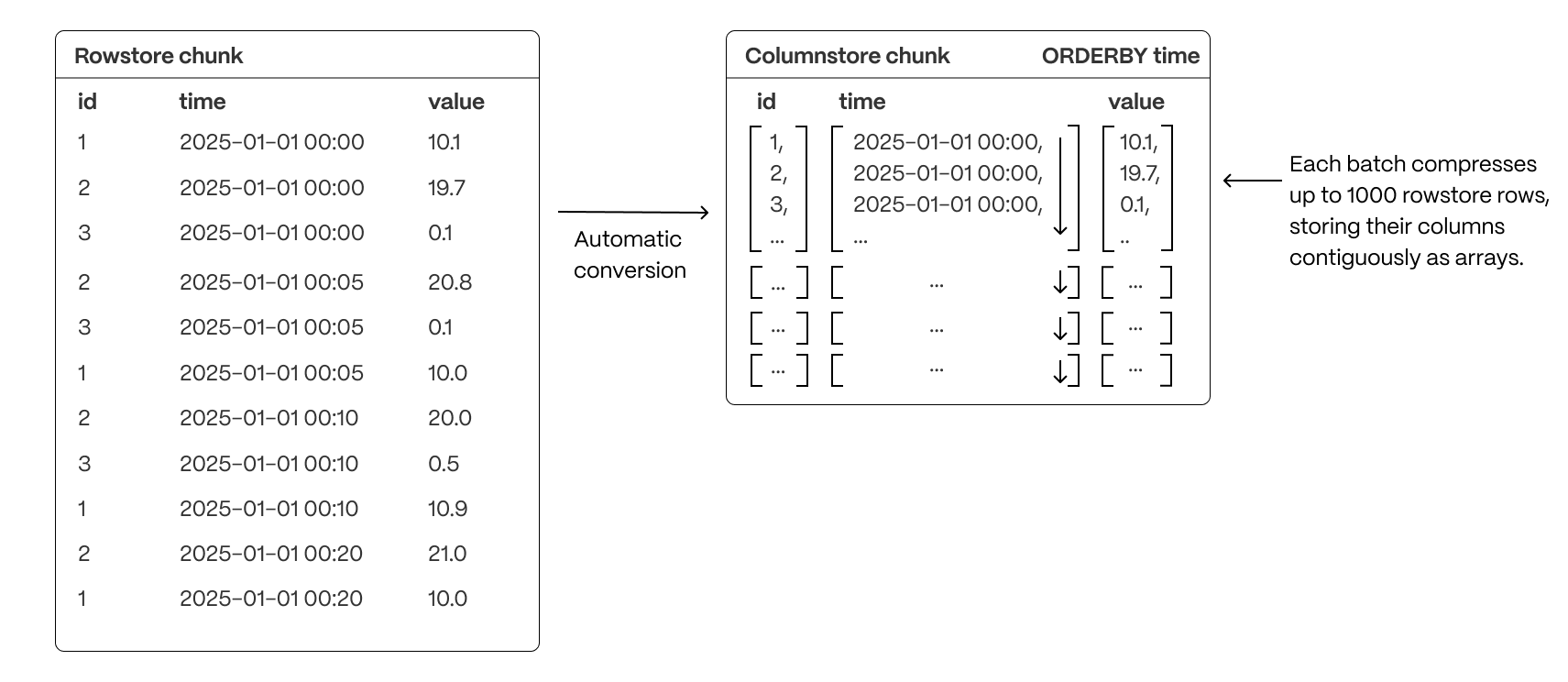 +
+
+A rowstore chunk is converted to a columnstore chunk by successfully grouping together sets of rows (typically up to 1000) into a single batch, then converting the batch into columnar form.
+
+Each compressed batch does the following:
+
+* Encapsulates columnar data in compressed arrays of up to 1,000 values per column, stored as a single entry in the underlying compressed table
+* Uses a column-major format within the batch, enabling efficient scans by co-locating values of the same column and allowing the selection of individual columns without reading the entire batch
+* Applies advanced compression techniques at the column level, including run-length encoding, delta encoding, and Gorilla compression, to significantly reduce storage footprint (by up to 95%) and improve I/O performance.
+
+While the chunk interval of rowstore and columnstore batches usually remains the same, TimescaleDB can also combine columnstore batches so they use a different chunk interval.
+
+This architecture provides the benefits of columnar storage—optimized scans, reduced disk I/O, and improved analytical performance—while seamlessly integrating with Postgres’s row-based execution model.
+
+#### Segmenting and ordering data
+
+To optimize query performance, TimescaleDB allows explicit control over how data is physically organized within columnar storage. By structuring data effectively, queries can minimize disk reads and execute more efficiently, using vectorized execution for parallel batch processing where possible.
+
+
+
+
+
+A rowstore chunk is converted to a columnstore chunk by successfully grouping together sets of rows (typically up to 1000) into a single batch, then converting the batch into columnar form.
+
+Each compressed batch does the following:
+
+* Encapsulates columnar data in compressed arrays of up to 1,000 values per column, stored as a single entry in the underlying compressed table
+* Uses a column-major format within the batch, enabling efficient scans by co-locating values of the same column and allowing the selection of individual columns without reading the entire batch
+* Applies advanced compression techniques at the column level, including run-length encoding, delta encoding, and Gorilla compression, to significantly reduce storage footprint (by up to 95%) and improve I/O performance.
+
+While the chunk interval of rowstore and columnstore batches usually remains the same, TimescaleDB can also combine columnstore batches so they use a different chunk interval.
+
+This architecture provides the benefits of columnar storage—optimized scans, reduced disk I/O, and improved analytical performance—while seamlessly integrating with Postgres’s row-based execution model.
+
+#### Segmenting and ordering data
+
+To optimize query performance, TimescaleDB allows explicit control over how data is physically organized within columnar storage. By structuring data effectively, queries can minimize disk reads and execute more efficiently, using vectorized execution for parallel batch processing where possible.
+
+
+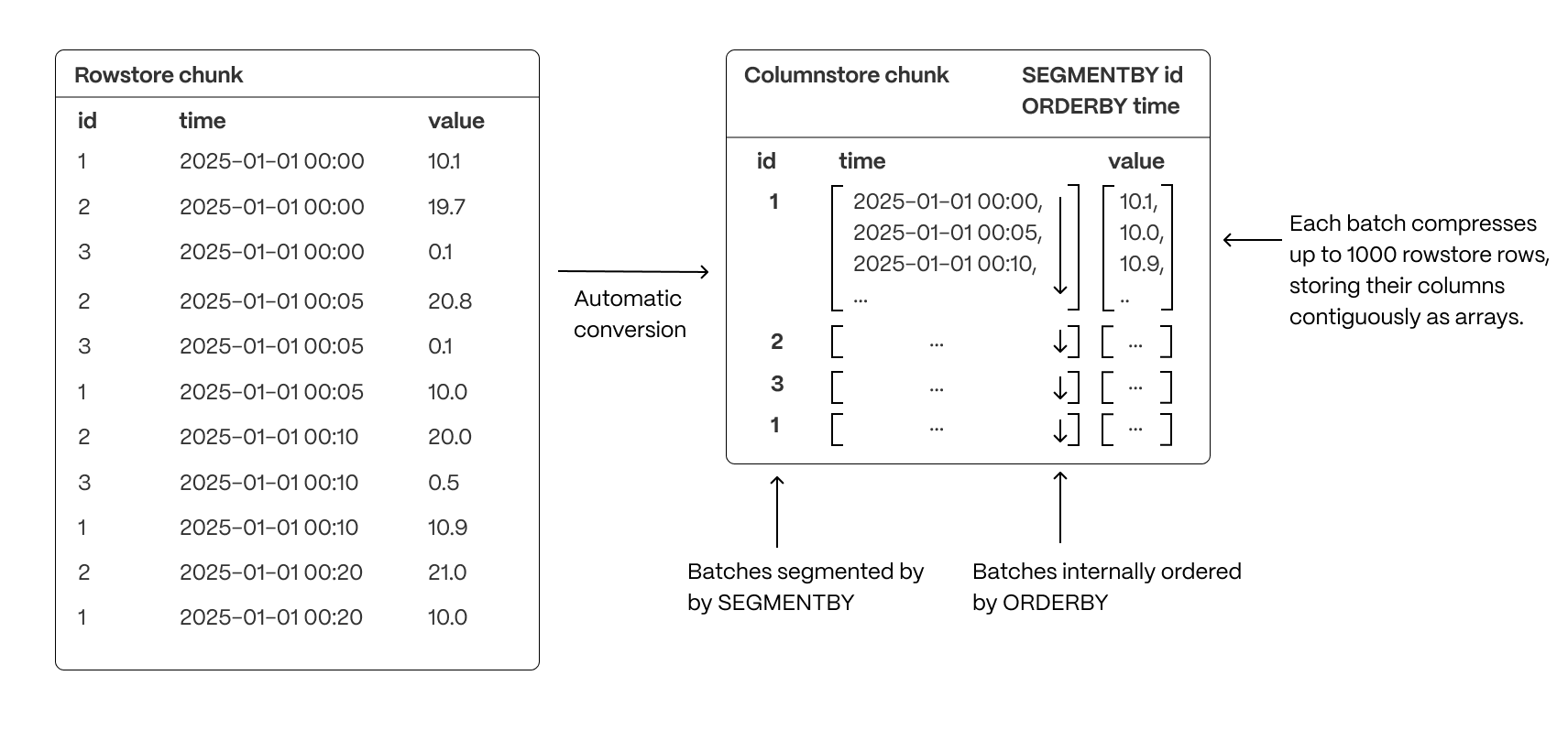 +
+
+* **Group related data together to improve scan efficiency**: organizing rows into logical segments ensures that queries filtering by a specific value only scan relevant data sections. For example, in the above, querying for a specific ID is particularly fast. *(Implemented with
+
+
+* **Group related data together to improve scan efficiency**: organizing rows into logical segments ensures that queries filtering by a specific value only scan relevant data sections. For example, in the above, querying for a specific ID is particularly fast. *(Implemented with SEGMENTBY.)*
+* **Sort data within segments to accelerate range queries**: defining a consistent order reduces the need for post-query sorting, making time-based queries and range scans more efficient. *(Implemented with ORDERBY.)*
+* **Reduce disk reads and maximize vectorized execution**: a well-structured storage layout enables efficient batch processing (Single Instruction, Multiple Data, or SIMD vectorization) and parallel execution, optimizing query performance.
+
+By combining segmentation and ordering, TimescaleDB ensures that columnar queries are not only fast but also resource-efficient, enabling high-performance real-time analytics.
+
+Traditional databases force a trade-off between fast updates and efficient analytics. Fully immutable storage is impractical in real-world applications, where data needs to change. Asynchronous mutability—where updates only become visible after batch processing—introduces delays that break real-time workflows. In-place mutability, while theoretically ideal, is prohibitively slow in columnar storage, requiring costly decompression, segmentation, ordering, and recompression cycles.
+
+Hypercore navigates these trade-offs with a hybrid approach that enables immediate updates without modifying compressed columnstore data in place. By staging changes in an interim rowstore chunk, hypercore allows updates and deletes to happen efficiently while preserving the analytical performance of columnar storage.
+
+
+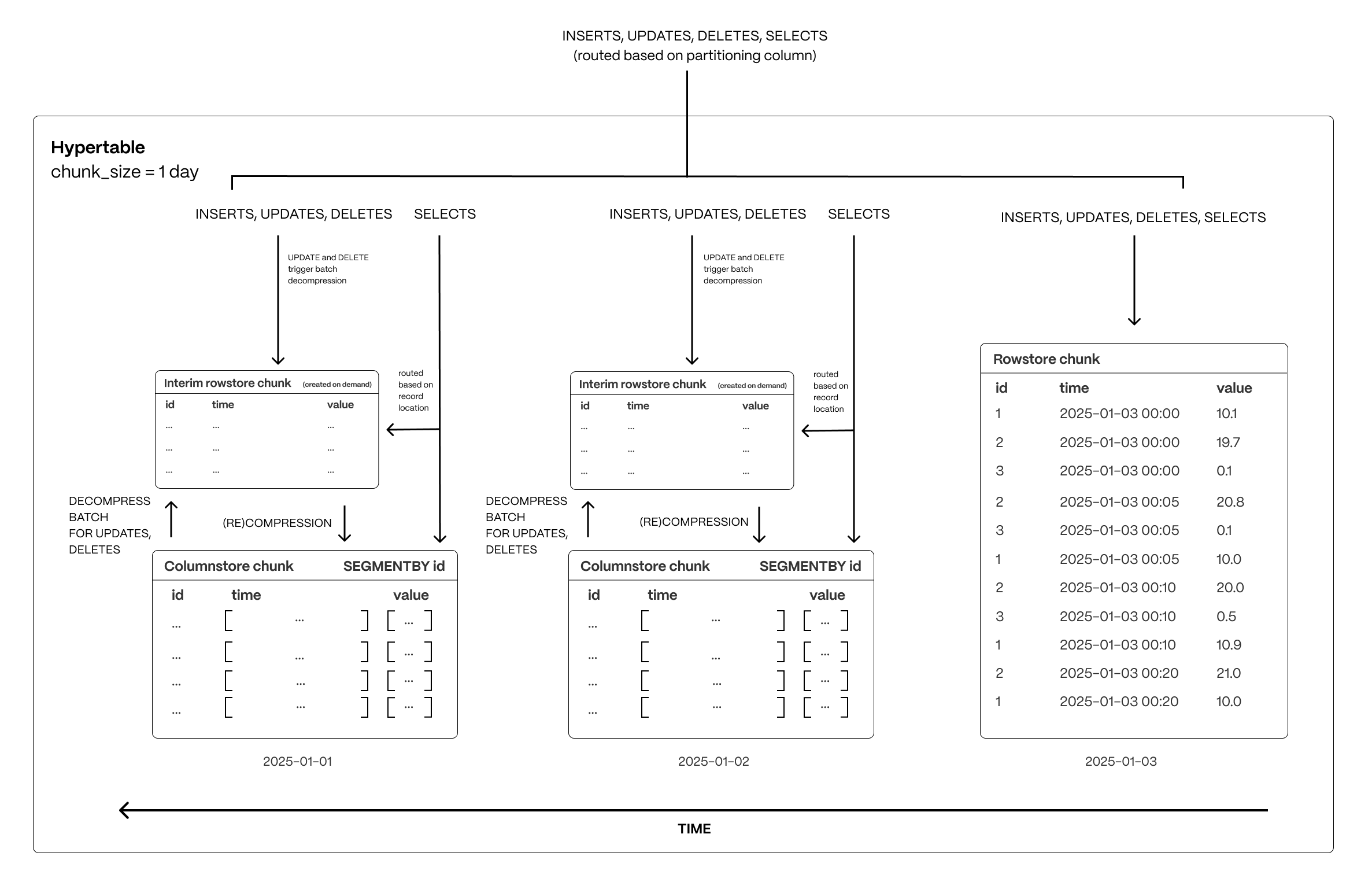 +
+
+#### Real-time writes without delays
+
+All new data which is destined for a columnstore chunk is first written to an interim rowstore chunk, ensuring high-speed ingestion and immediate queryability. Unlike fully columnar systems that require ingestion to go through compression pipelines, hypercore allows fresh data to remain in a fast row-based structure before being later compressed into columnar format in ordered batches as normal.
+
+Queries transparently access both the rowstore and columnstore chunks, meaning applications always see the latest data instantly, regardless of its storage format.
+
+#### Efficient updates and deletes without performance penalties
+
+When modifying or deleting existing data, hypercore avoids the inefficiencies of both asynchronous updates and in-place modifications. Instead of modifying compressed storage directly, affected batches are decompressed and staged in the interim rowstore chunk, where changes are applied immediately.
+
+These modified batches remain in row storage until they are recompressed and reintegrated into the columnstore (which happens automatically via a background process). This approach ensures updates are immediately visible, but without the expensive overhead of decompressing and rewriting entire chunks. This approach avoids:
+
+* The rigidity of immutable storage, which requires workarounds like versioning or copy-on-write strategies
+* The delays of asynchronous updates, where modified data is only visible after batch processing
+* The performance hit of in-place mutability, which makes compressed storage prohibitively slow for frequent updates
+* The restrictions some databases have on not altering the segmentation or ordering keys
+
+## Query optimizations
+
+Real-time analytics isn’t just about raw speed—it’s about executing queries efficiently, reducing unnecessary work, and maximizing performance. TimescaleDB optimizes every step of the query lifecycle to ensure that queries scan only what’s necessary, make use of data locality, and execute in parallel for sub-second response times over large datasets.
+
+### Skip unnecessary data
+
+TimescaleDB minimizes the amount of data a query touches, reducing I/O and improving execution speed:
+
+#### Primary partition exclusion (row and columnar)
+
+Queries automatically skip irrelevant partitions (chunks) based on the primary partitioning key (usually a timestamp), ensuring they only scan relevant data.
+
+
+
+
+
+#### Real-time writes without delays
+
+All new data which is destined for a columnstore chunk is first written to an interim rowstore chunk, ensuring high-speed ingestion and immediate queryability. Unlike fully columnar systems that require ingestion to go through compression pipelines, hypercore allows fresh data to remain in a fast row-based structure before being later compressed into columnar format in ordered batches as normal.
+
+Queries transparently access both the rowstore and columnstore chunks, meaning applications always see the latest data instantly, regardless of its storage format.
+
+#### Efficient updates and deletes without performance penalties
+
+When modifying or deleting existing data, hypercore avoids the inefficiencies of both asynchronous updates and in-place modifications. Instead of modifying compressed storage directly, affected batches are decompressed and staged in the interim rowstore chunk, where changes are applied immediately.
+
+These modified batches remain in row storage until they are recompressed and reintegrated into the columnstore (which happens automatically via a background process). This approach ensures updates are immediately visible, but without the expensive overhead of decompressing and rewriting entire chunks. This approach avoids:
+
+* The rigidity of immutable storage, which requires workarounds like versioning or copy-on-write strategies
+* The delays of asynchronous updates, where modified data is only visible after batch processing
+* The performance hit of in-place mutability, which makes compressed storage prohibitively slow for frequent updates
+* The restrictions some databases have on not altering the segmentation or ordering keys
+
+## Query optimizations
+
+Real-time analytics isn’t just about raw speed—it’s about executing queries efficiently, reducing unnecessary work, and maximizing performance. TimescaleDB optimizes every step of the query lifecycle to ensure that queries scan only what’s necessary, make use of data locality, and execute in parallel for sub-second response times over large datasets.
+
+### Skip unnecessary data
+
+TimescaleDB minimizes the amount of data a query touches, reducing I/O and improving execution speed:
+
+#### Primary partition exclusion (row and columnar)
+
+Queries automatically skip irrelevant partitions (chunks) based on the primary partitioning key (usually a timestamp), ensuring they only scan relevant data.
+
+
+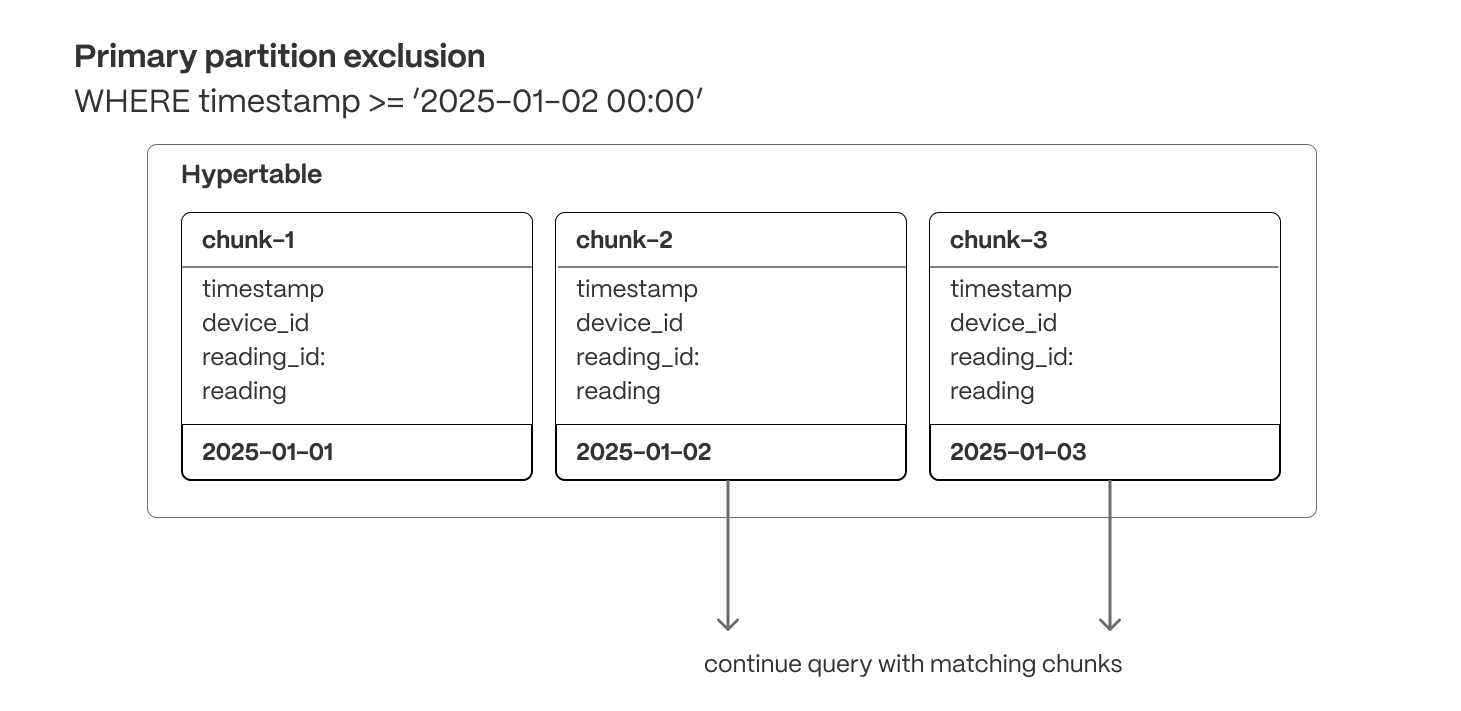 +
+
+#### Secondary partition exclusion (columnar)
+
+Min/max metadata allows queries filtering on correlated dimensions (e.g., `order_id` or secondary timestamps) to exclude chunks that don’t contain relevant data.
+
+
+
+
+
+#### Secondary partition exclusion (columnar)
+
+Min/max metadata allows queries filtering on correlated dimensions (e.g., `order_id` or secondary timestamps) to exclude chunks that don’t contain relevant data.
+
+
+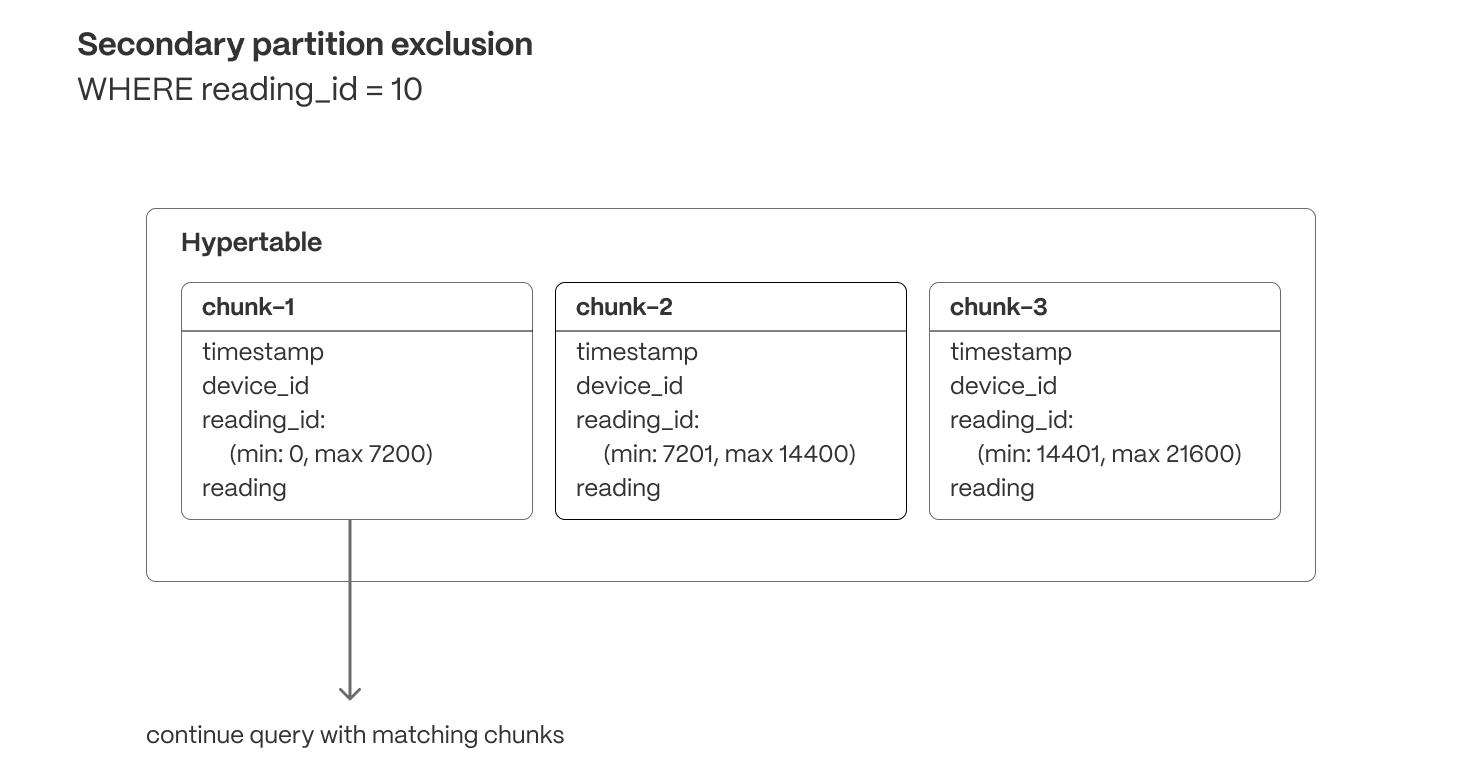 +
+
+#### Postgres indexes (row and columnar)
+
+Unlike many databases, TimescaleDB supports sparse indexes on columnstore data, allowing queries to efficiently locate specific values within both row-based and compressed columnar storage. These indexes enable fast lookups, range queries, and filtering operations that further reduce unnecessary data scans.
+
+
+
+
+
+#### Postgres indexes (row and columnar)
+
+Unlike many databases, TimescaleDB supports sparse indexes on columnstore data, allowing queries to efficiently locate specific values within both row-based and compressed columnar storage. These indexes enable fast lookups, range queries, and filtering operations that further reduce unnecessary data scans.
+
+
+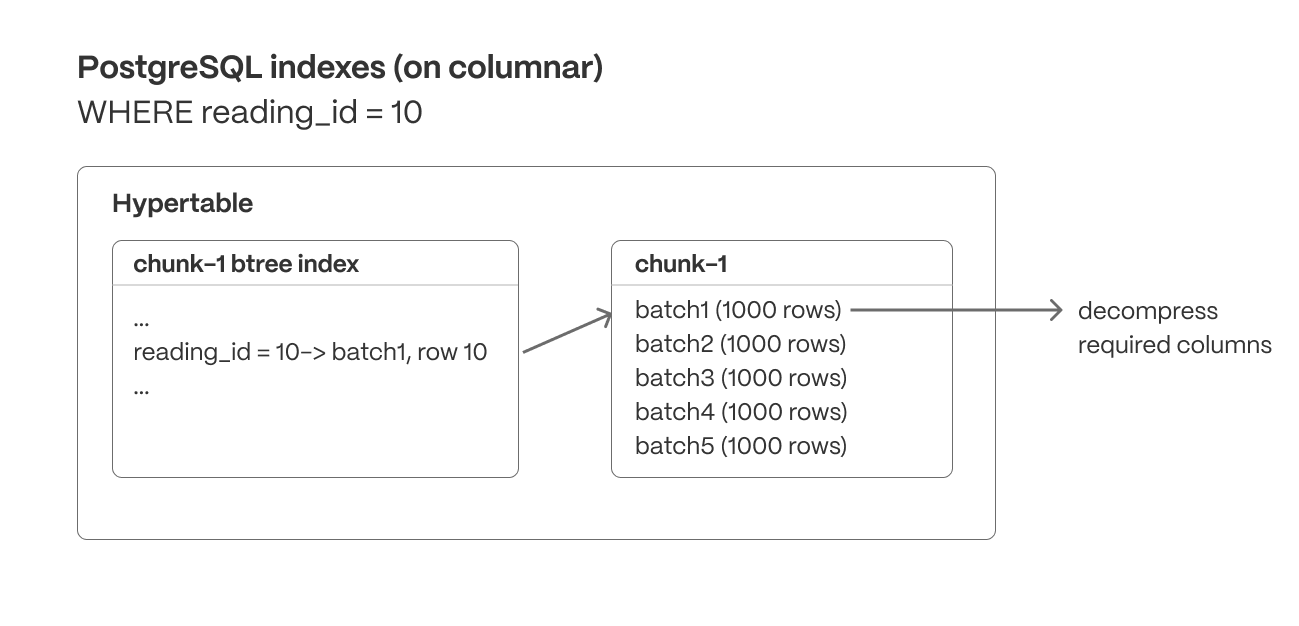 +
+
+#### Batch-level filtering (columnar)
+
+Within each chunk, compressed columnar batches are organized using `SEGMENTBY` keys and ordered by `ORDERBY` columns. Indexes and min/max metadata can be used to quickly exclude batches that don’t match the query criteria.
+
+
+
+
+
+#### Batch-level filtering (columnar)
+
+Within each chunk, compressed columnar batches are organized using `SEGMENTBY` keys and ordered by `ORDERBY` columns. Indexes and min/max metadata can be used to quickly exclude batches that don’t match the query criteria.
+
+
+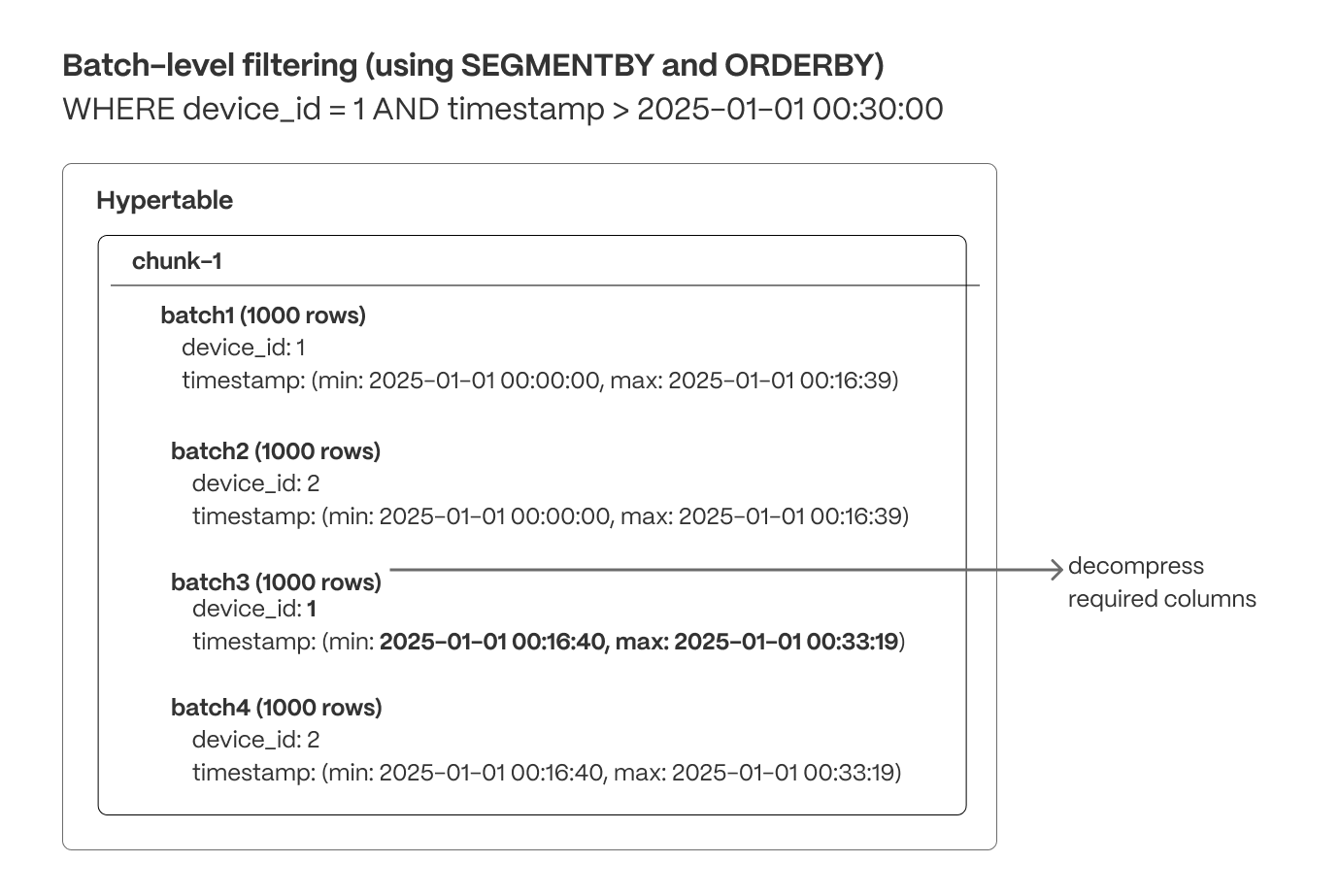 +
+
+### Maximize locality
+
+Organizing data for efficient access ensures queries are read in the most optimal order, reducing unnecessary random reads and reducing scans of unneeded data.
+
+
+
+
+
+### Maximize locality
+
+Organizing data for efficient access ensures queries are read in the most optimal order, reducing unnecessary random reads and reducing scans of unneeded data.
+
+
+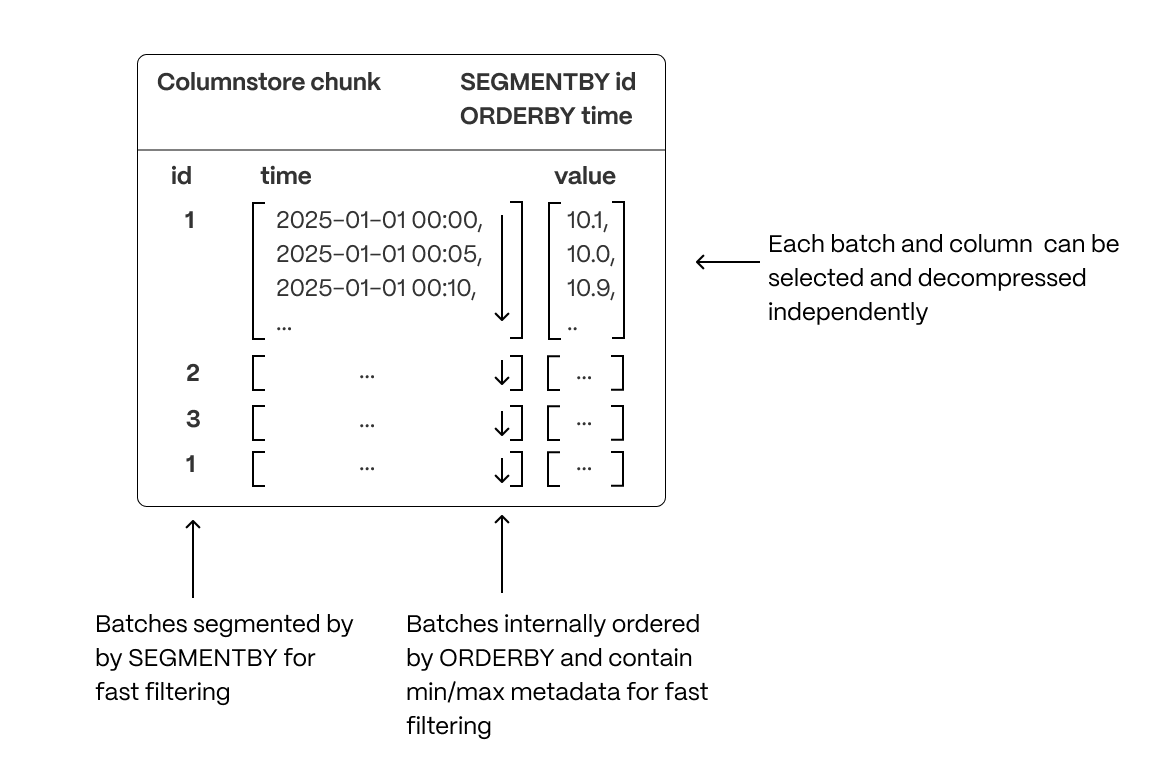 +
+
+* **Segmentation**: Columnar batches are grouped using `SEGMENTBY` to keep related data together, improving scan efficiency.
+* **Ordering**: Data within each batch is physically sorted using `ORDERBY`, increasing scan efficiency (and reducing I/O operations), enabling efficient range queries, and minimizing post-query sorting.
+* **Column selection**: Queries read only the necessary columns, reducing disk I/O, decompression overhead, and memory usage.
+
+### Parallelize execution
+
+Once a query is scanning only the required columnar data in the optimal order, TimescaleDB is able to maximize performance through parallel execution. As well as using multiple workers, TimescaleDB accelerates columnstore query execution by using Single Instruction, Multiple Data (SIMD) vectorization, allowing modern CPUs to process multiple data points in parallel.
+
+
+
+
+
+* **Segmentation**: Columnar batches are grouped using `SEGMENTBY` to keep related data together, improving scan efficiency.
+* **Ordering**: Data within each batch is physically sorted using `ORDERBY`, increasing scan efficiency (and reducing I/O operations), enabling efficient range queries, and minimizing post-query sorting.
+* **Column selection**: Queries read only the necessary columns, reducing disk I/O, decompression overhead, and memory usage.
+
+### Parallelize execution
+
+Once a query is scanning only the required columnar data in the optimal order, TimescaleDB is able to maximize performance through parallel execution. As well as using multiple workers, TimescaleDB accelerates columnstore query execution by using Single Instruction, Multiple Data (SIMD) vectorization, allowing modern CPUs to process multiple data points in parallel.
+
+
+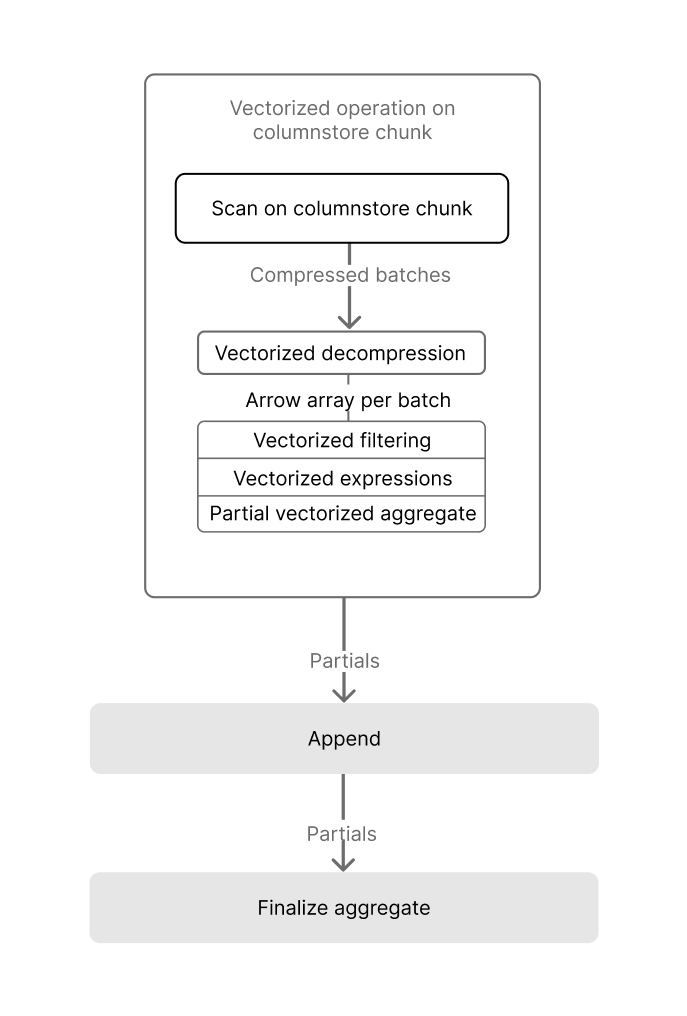 +
+
+The TimescaleDB implementation of SIMD vectorization currently allows:
+
+* **Vectorized decompression**, which efficiently restores compressed data into a usable form for analysis.
+* **Vectorized filtering**, which rapidly applies filter conditions across data sets.
+* **Vectorized aggregation**, which performs aggregate calculations, such as sum or average, across multiple data points concurrently.
+
+## Accelerating queries with continuous aggregates
+
+Aggregating large datasets in real time can be expensive, requiring repeated scans and calculations that strain CPU and I/O. While some databases attempt to brute-force these queries at runtime, compute and I/O are always finite resources—leading to high latency, unpredictable performance, and growing infrastructure costs as data volume increases.
+
+**Continuous aggregates**, the TimescaleDB implementation of incrementally updated materialized views, solve this
+by shifting computation from every query run to a single, asynchronous step after data is ingested. Only the time buckets that receive new or modified data are updated, and queries read precomputed results instead of scanning raw data—dramatically improving performance and efficiency.
+
+
+
+
+
+The TimescaleDB implementation of SIMD vectorization currently allows:
+
+* **Vectorized decompression**, which efficiently restores compressed data into a usable form for analysis.
+* **Vectorized filtering**, which rapidly applies filter conditions across data sets.
+* **Vectorized aggregation**, which performs aggregate calculations, such as sum or average, across multiple data points concurrently.
+
+## Accelerating queries with continuous aggregates
+
+Aggregating large datasets in real time can be expensive, requiring repeated scans and calculations that strain CPU and I/O. While some databases attempt to brute-force these queries at runtime, compute and I/O are always finite resources—leading to high latency, unpredictable performance, and growing infrastructure costs as data volume increases.
+
+**Continuous aggregates**, the TimescaleDB implementation of incrementally updated materialized views, solve this
+by shifting computation from every query run to a single, asynchronous step after data is ingested. Only the time buckets that receive new or modified data are updated, and queries read precomputed results instead of scanning raw data—dramatically improving performance and efficiency.
+
+
+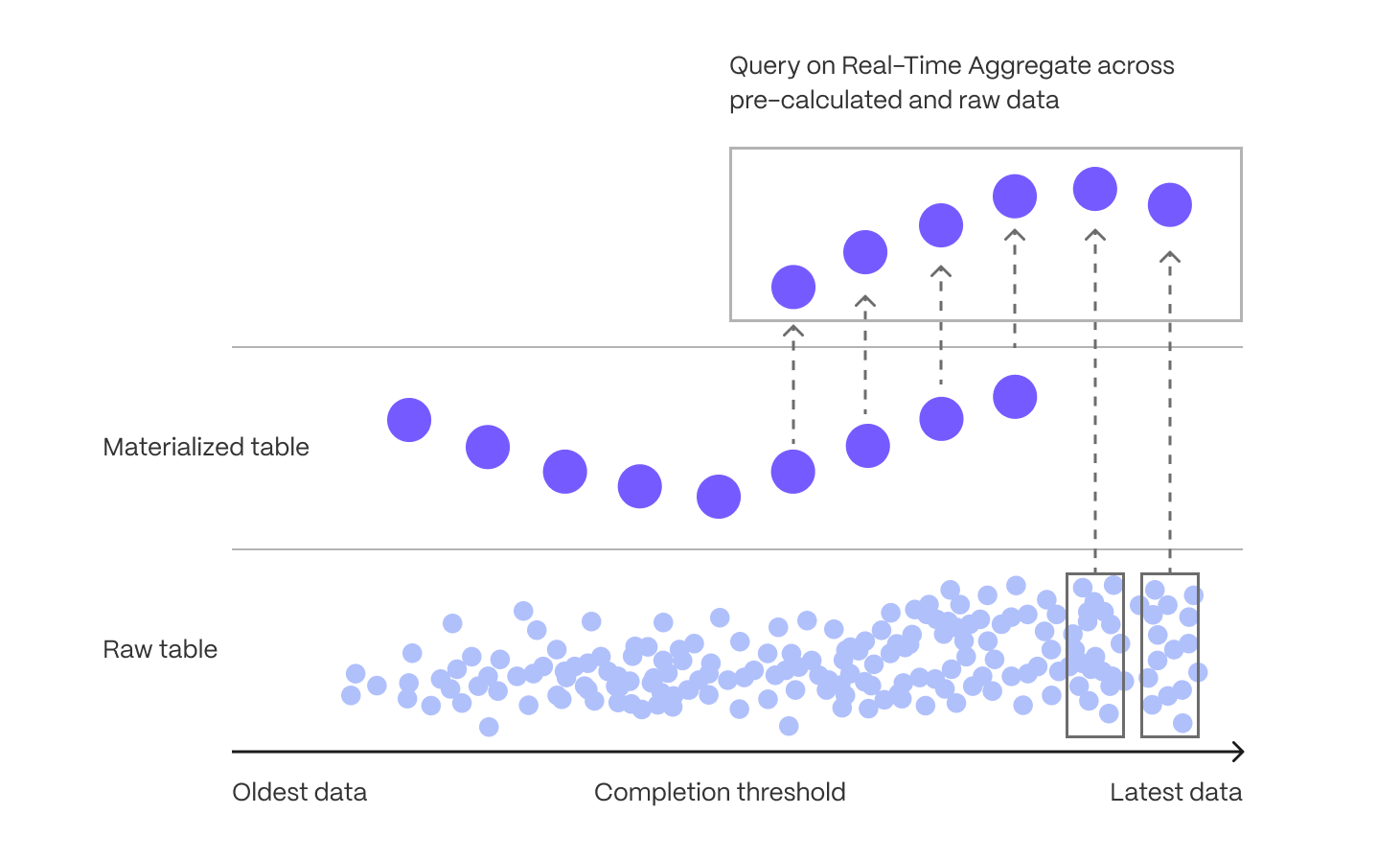 +
+
+When you know the types of queries you'll need ahead of time, continuous aggregates allow you to pre-aggregate data along meaningful time intervals—such as per-minute, hourly, or daily summaries—delivering instant results without on-the-fly computation.
+
+Continuous aggregates also avoid the time-consuming and error-prone process of maintaining manual rollups, while continuing to offer data mutability to support efficient updates, corrections, and backfills. Whenever new data is inserted or modified in chunks which have been materialized, TimescaleDB stores invalidation records reflecting that these results are stale and need to be recomputed. Then, an asynchronous process re-computes regions that include invalidated data, and updates the materialized results. TimescaleDB tracks the lineage and dependencies between continuous aggregates and their underlying data, to ensure the continuous aggregates are regularly kept up-to-date. This happens in a resource-efficient manner, and where multiple invalidations can be coalesced into a single refresh (as opposed to refreshing any dependencies at write time, such as via a trigger-based approach).
+
+Continuous aggregates themselves are stored in hypertables, and they can be converted to columnar storage for compression, and raw data can be dropped, reducing storage footprint and processing cost. Continuous aggregates also support hierarchical rollups (e.g., hourly to daily to monthly) and real-time mode, which merges precomputed results with the latest ingested data to ensure accurate, up-to-date analytics.
+
+This architecture enables scalable, low-latency analytics while keeping resource usage predictable—ideal for dashboards, monitoring systems, and any workload with known query patterns.
+
+### Hyperfunctions for real-time analytics
+
+Real-time analytics requires more than basic SQL functions—efficient computation is essential as datasets grow in size and complexity. Hyperfunctions, available through the `timescaledb_toolkit` extension, provide high-performance, SQL-native functions tailored for time-series analysis. These include advanced tools for gap-filling, percentile estimation, time-weighted averages, counter correction, and state tracking, among others.
+
+A key innovation of hyperfunctions is their support for partial aggregation, which allows TimescaleDB to store intermediate computational states rather than just final results. These partials can later be merged to compute rollups efficiently, avoiding expensive reprocessing of raw data and reducing compute overhead. This is especially effective when combined with continuous aggregates.
+
+Consider a real-world example: monitoring request latencies across thousands of application instances. You might want to compute p95 latency per minute, then roll that up into hourly and daily percentiles for dashboards or alerts. With traditional SQL, calculating percentiles requires a full scan and sort of all underlying data—making multi-level rollups computationally expensive.
+
+With TimescaleDB, you can use the `percentile_agg` hyperfunction in a continuous aggregate to compute and store a partial aggregation state for each minute. This state efficiently summarizes the distribution of latencies for that time bucket, without storing or sorting all individual values. Later, to produce an hourly or daily percentile, you simply combine the stored partials—no need to reprocess the raw latency values.
+
+This approach provides a scalable, efficient solution for percentile-based analytics. By combining hyperfunctions with continuous aggregates, TimescaleDB enables real-time systems to deliver fast, resource-efficient insights across high-ingest, high-resolution datasets—without sacrificing accuracy or flexibility.
+
+## Cloud-native architecture
+
+Real-time analytics requires a scalable, high-performance, and cost-efficient database that can handle high-ingest rates and low-latency queries without overprovisioning. Tiger Cloud is designed for elasticity, enabling independent scaling of storage and compute, workload isolation, and intelligent data tiering.
+
+### Independent storage and compute scaling
+
+Real-time applications generate continuous data streams while requiring instant querying of both fresh and historical data. Traditional databases force users to pre-provision fixed storage, leading to unnecessary costs or unexpected limits. Tiger Cloud eliminates this constraint by dynamically scaling storage based on actual usage:
+
+* Storage expands and contracts automatically as data is added or deleted, avoiding manual intervention.
+* Usage-based billing ensures costs align with actual storage consumption, eliminating large upfront allocations.
+* Compute can be scaled independently to optimize query execution, ensuring fast analytics across both recent and historical data.
+
+With this architecture, databases grow alongside data streams, enabling seamless access to real-time and historical insights while efficiently managing storage costs.
+
+### Workload isolation for real-time performance
+
+Balancing high-ingest rates and low-latency analytical queries on the same system can create contention, slowing down performance. Tiger Cloud mitigates this by allowing read and write workloads to scale independently:
+
+* The primary database efficiently handles both ingestion and real-time rollups without disruption.
+* Read replicas scale query performance separately, ensuring fast analytics even under heavy workloads.
+
+
+
+
+
+When you know the types of queries you'll need ahead of time, continuous aggregates allow you to pre-aggregate data along meaningful time intervals—such as per-minute, hourly, or daily summaries—delivering instant results without on-the-fly computation.
+
+Continuous aggregates also avoid the time-consuming and error-prone process of maintaining manual rollups, while continuing to offer data mutability to support efficient updates, corrections, and backfills. Whenever new data is inserted or modified in chunks which have been materialized, TimescaleDB stores invalidation records reflecting that these results are stale and need to be recomputed. Then, an asynchronous process re-computes regions that include invalidated data, and updates the materialized results. TimescaleDB tracks the lineage and dependencies between continuous aggregates and their underlying data, to ensure the continuous aggregates are regularly kept up-to-date. This happens in a resource-efficient manner, and where multiple invalidations can be coalesced into a single refresh (as opposed to refreshing any dependencies at write time, such as via a trigger-based approach).
+
+Continuous aggregates themselves are stored in hypertables, and they can be converted to columnar storage for compression, and raw data can be dropped, reducing storage footprint and processing cost. Continuous aggregates also support hierarchical rollups (e.g., hourly to daily to monthly) and real-time mode, which merges precomputed results with the latest ingested data to ensure accurate, up-to-date analytics.
+
+This architecture enables scalable, low-latency analytics while keeping resource usage predictable—ideal for dashboards, monitoring systems, and any workload with known query patterns.
+
+### Hyperfunctions for real-time analytics
+
+Real-time analytics requires more than basic SQL functions—efficient computation is essential as datasets grow in size and complexity. Hyperfunctions, available through the `timescaledb_toolkit` extension, provide high-performance, SQL-native functions tailored for time-series analysis. These include advanced tools for gap-filling, percentile estimation, time-weighted averages, counter correction, and state tracking, among others.
+
+A key innovation of hyperfunctions is their support for partial aggregation, which allows TimescaleDB to store intermediate computational states rather than just final results. These partials can later be merged to compute rollups efficiently, avoiding expensive reprocessing of raw data and reducing compute overhead. This is especially effective when combined with continuous aggregates.
+
+Consider a real-world example: monitoring request latencies across thousands of application instances. You might want to compute p95 latency per minute, then roll that up into hourly and daily percentiles for dashboards or alerts. With traditional SQL, calculating percentiles requires a full scan and sort of all underlying data—making multi-level rollups computationally expensive.
+
+With TimescaleDB, you can use the `percentile_agg` hyperfunction in a continuous aggregate to compute and store a partial aggregation state for each minute. This state efficiently summarizes the distribution of latencies for that time bucket, without storing or sorting all individual values. Later, to produce an hourly or daily percentile, you simply combine the stored partials—no need to reprocess the raw latency values.
+
+This approach provides a scalable, efficient solution for percentile-based analytics. By combining hyperfunctions with continuous aggregates, TimescaleDB enables real-time systems to deliver fast, resource-efficient insights across high-ingest, high-resolution datasets—without sacrificing accuracy or flexibility.
+
+## Cloud-native architecture
+
+Real-time analytics requires a scalable, high-performance, and cost-efficient database that can handle high-ingest rates and low-latency queries without overprovisioning. Tiger Cloud is designed for elasticity, enabling independent scaling of storage and compute, workload isolation, and intelligent data tiering.
+
+### Independent storage and compute scaling
+
+Real-time applications generate continuous data streams while requiring instant querying of both fresh and historical data. Traditional databases force users to pre-provision fixed storage, leading to unnecessary costs or unexpected limits. Tiger Cloud eliminates this constraint by dynamically scaling storage based on actual usage:
+
+* Storage expands and contracts automatically as data is added or deleted, avoiding manual intervention.
+* Usage-based billing ensures costs align with actual storage consumption, eliminating large upfront allocations.
+* Compute can be scaled independently to optimize query execution, ensuring fast analytics across both recent and historical data.
+
+With this architecture, databases grow alongside data streams, enabling seamless access to real-time and historical insights while efficiently managing storage costs.
+
+### Workload isolation for real-time performance
+
+Balancing high-ingest rates and low-latency analytical queries on the same system can create contention, slowing down performance. Tiger Cloud mitigates this by allowing read and write workloads to scale independently:
+
+* The primary database efficiently handles both ingestion and real-time rollups without disruption.
+* Read replicas scale query performance separately, ensuring fast analytics even under heavy workloads.
+
+
+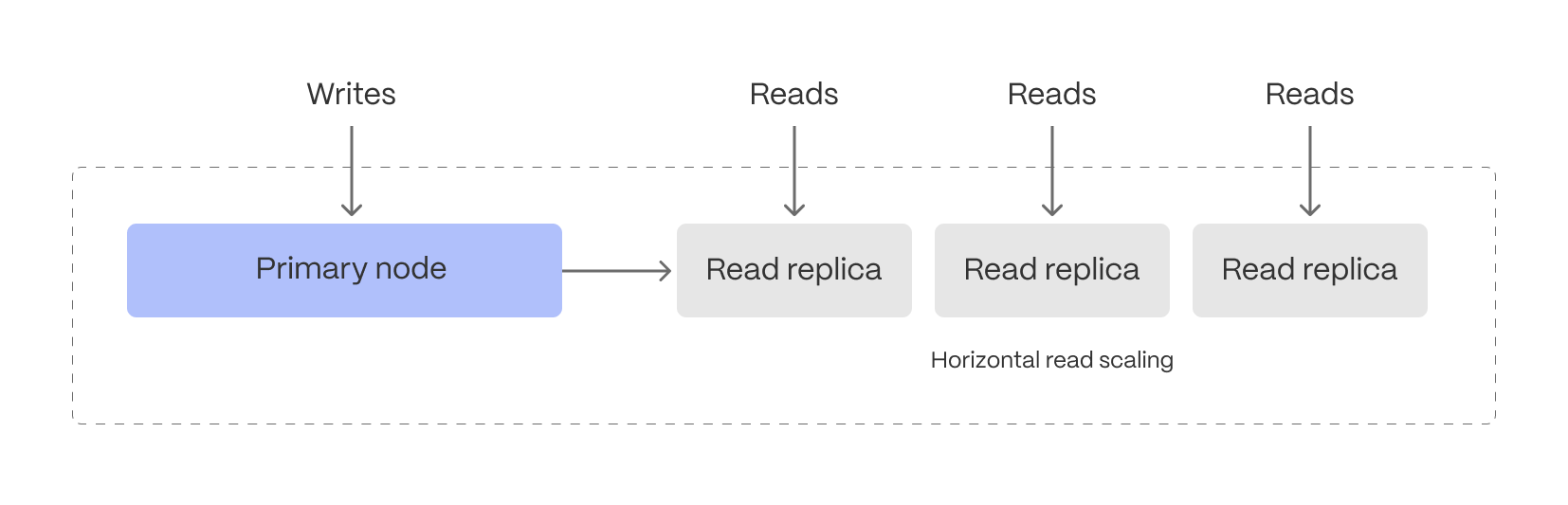 +
+
+This separation ensures that frequent queries on fresh data don’t interfere with ingestion, making it easier to support live monitoring, anomaly detection, interactive dashboards, and alerting systems.
+
+### Intelligent data tiering for cost-efficient real-time analytics
+
+Not all real-time data is equally valuable—recent data is queried constantly, while older data is accessed less frequently. Tiger Cloud can be configured to automatically tier data to cheaper bottomless object storage, ensuring that hot data remains instantly accessible, while historical data is still available.
+
+
+
+
+
+This separation ensures that frequent queries on fresh data don’t interfere with ingestion, making it easier to support live monitoring, anomaly detection, interactive dashboards, and alerting systems.
+
+### Intelligent data tiering for cost-efficient real-time analytics
+
+Not all real-time data is equally valuable—recent data is queried constantly, while older data is accessed less frequently. Tiger Cloud can be configured to automatically tier data to cheaper bottomless object storage, ensuring that hot data remains instantly accessible, while historical data is still available.
+
+
+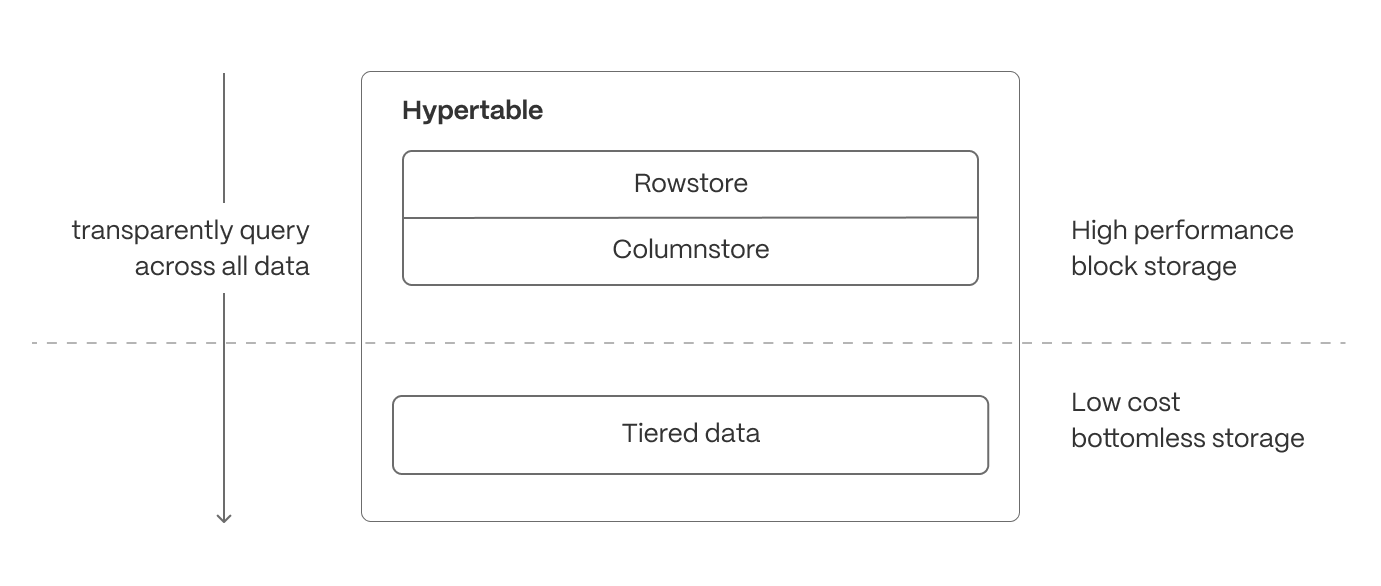 +
+
+* **Recent, high-velocity data** stays in high-performance storage for ultra-fast queries.
+* **Older, less frequently accessed data** is automatically moved to cost-efficient object storage but remains queryable and available for building continuous aggregates.
+
+While many systems support this concept of data cooling, TimescaleDB ensures that the data can still be queried from the same hypertable regardless of its current location. For real-time analytics, this means applications can analyze live data streams without worrying about storage constraints, while still maintaining access to long-term trends when needed.
+
+### Cloud-native database observability
+
+Real-time analytics doesn’t just require fast queries—it requires the ability to understand why queries are fast or slow, where resources are being used, and how performance changes over time. That’s why Tiger Cloud is built with deep observability features, giving developers and operators full visibility into their database workloads.
+
+At the core of this observability is Insights, Tiger Cloud’s built-in query monitoring tool. Insights captures
+per-query
+statistics from our whole fleet in real time, showing you exactly how your database is behaving under load. It tracks key metrics like execution time, planning time, number of rows read and returned, I/O usage, and buffer cache hit rates—not just for the database as a whole, but for each individual query.
+
+Insights lets you do the following:
+
+* Identify slow or resource-intensive queries instantly
+* Spot long-term performance regressions or trends
+* Understand query patterns and how they evolve over time
+* See the impact of schema changes, indexes, or continuous aggregates on workload performance
+* Monitor and compare different versions of the same query to optimize execution
+
+All this is surfaced through an intuitive interface, available directly in Tiger Cloud, with no instrumentation or external monitoring infrastructure required.
+
+Beyond query-level visibility, Tiger Cloud also exposes metrics around service resource consumption, compression, continuous aggregates, and data tiering, allowing you to track how data moves through the system—and how those background processes impact storage and query performance.
+
+Together, these observability features give you the insight and control needed to operate a real-time analytics database at scale, with confidence, clarity, and performance you can trust**.**
+
+## Ensuring reliability and scalability
+
+Maintaining high availability, efficient resource utilization, and data durability is essential for real-time applications. Tiger Cloud provides robust operational features to ensure seamless performance under varying workloads.
+
+* **High-availability (HA) replicas**: deploy multi-AZ HA replicas to provide fault tolerance and ensure minimal downtime. In the event of a primary node failure, replicas are automatically promoted to maintain service continuity.
+* **Connection pooling**: optimize database connections by efficiently managing and reusing them, reducing overhead and improving performance for high-concurrency applications.
+* **Backup and recovery**: leverage continuous backups, Point-in-Time Recovery (PITR), and automated snapshotting to protect against data loss. Restore data efficiently to minimize downtime in case of failures or accidental deletions.
+
+These operational capabilities ensure Tiger Cloud remains reliable, scalable, and resilient, even under demanding real-time workloads.
+
+Real-time analytics is critical for modern applications, but traditional databases struggle to balance high-ingest performance, low-latency queries, and flexible data mutability. Tiger Cloud extends Postgres to solve this challenge, combining automatic partitioning, hybrid row-columnar storage, and intelligent compression to optimize both transactional and analytical workloads.
+
+With continuous aggregates, hyperfunctions, and advanced query optimizations, Tiger Cloud ensures sub-second queries
+even on massive datasets that combine current and historic data. Its cloud-native architecture further enhances scalability with independent compute and storage scaling, workload isolation, and cost-efficient data tiering—allowing applications to handle real-time and historical queries seamlessly.
+
+For developers, this means building high-performance, real-time analytics applications without sacrificing SQL compatibility, transactional guarantees, or operational simplicity.
+
+Tiger Cloud delivers the best of Postgres, optimized for real-time analytics.
+
+===== PAGE: https://docs.tigerdata.com/about/pricing-and-account-management/ =====
+
+---
+
+## stddev()
+
+**URL:** llms-txt#stddev()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/rollup/ =====
+
+---
+
+## Approximate percentiles
+
+**URL:** llms-txt#approximate-percentiles
+
+**Contents:**
+- Run an approximate percentage query
+ - Running an approximate percentage query
+
+TimescaleDB uses approximation algorithms to calculate a percentile without
+requiring all of the data. This also makes them more compatible with continuous
+aggregates.
+
+By default, TimescaleDB Toolkit uses `uddsketch`, but you can also choose to use
+`tdigest`. For more information about these algorithms, see the
+[advanced aggregation methods][advanced-agg] documentation.
+
+## Run an approximate percentage query
+
+In this procedure, we use an example table called `response_times` that contains
+information about how long a server takes to respond to API calls.
+
+### Running an approximate percentage query
+
+1. At the `psql` prompt, create a continuous aggregate that computes the
+ daily aggregates:
+
+1. Re-aggregate the aggregate to get the last 30 days, and look for the
+ ninety-fifth percentile:
+
+1. You can also create an alert:
+
+For more information about percentile approximation API calls, see the
+[hyperfunction API documentation][hyperfunctions-api-approx-percentile].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_daily
+ WITH (timescaledb.continuous)
+ AS SELECT
+ time_bucket('1 day'::interval, ts) as bucket,
+ percentile_agg(response_time_ms)
+ FROM response_times
+ GROUP BY 1;
+```
+
+Example 2 (sql):
+```sql
+SELECT approx_percentile(0.95, percentile_agg) as threshold
+ FROM response_times_daily
+ WHERE bucket >= time_bucket('1 day'::interval, now() - '30 days'::interval);
+```
+
+Example 3 (sql):
+```sql
+WITH t as (SELECT approx_percentile(0.95, percentile_agg(percentile_agg)) as threshold
+ FROM response_times_daily
+ WHERE bucket >= time_bucket('1 day'::interval, now() - '30 days'::interval))
+
+ SELECT count(*)
+ FROM response_times
+ WHERE ts > now()- '1 minute'::interval
+ AND response_time_ms > (SELECT threshold FROM t);
+```
+
+---
+
+## skewness_y() | skewness_x()
+
+**URL:** llms-txt#skewness_y()-|-skewness_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/num_vals/ =====
+
+---
+
+## covariance()
+
+**URL:** llms-txt#covariance()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/rolling/ =====
+
+---
diff --git a/skills/timescaledb/references/hypertables.md b/skills/timescaledb/references/hypertables.md
new file mode 100644
index 0000000..0c0eb83
--- /dev/null
+++ b/skills/timescaledb/references/hypertables.md
@@ -0,0 +1,7899 @@
+# Timescaledb - Hypertables
+
+**Pages:** 103
+
+---
+
+## chunks_detailed_size()
+
+**URL:** llms-txt#chunks_detailed_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get information about the disk space used by the chunks belonging to a
+hypertable, returning size information for each chunk table, any
+indexes on the chunk, any toast tables, and the total size associated
+with the chunk. All sizes are reported in bytes.
+
+If the function is executed on a distributed hypertable, it returns
+disk space usage information as a separate row per node. The access
+node is not included since it doesn't have any local chunk data.
+
+Additional metadata associated with a chunk can be accessed
+via the `timescaledb_information.chunks` view.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Name of the hypertable |
+
+|Column|Type|Description|
+|---|---|---|
+|chunk_schema| TEXT | Schema name of the chunk |
+|chunk_name| TEXT | Name of the chunk|
+|table_bytes|BIGINT | Disk space used by the chunk table|
+|index_bytes|BIGINT | Disk space used by indexes|
+|toast_bytes|BIGINT | Disk space of toast tables|
+|total_bytes|BIGINT | Total disk space used by the chunk, including all indexes and TOAST data|
+|node_name| TEXT | Node for which size is reported, applicable only to distributed hypertables|
+
+If executed on a relation that is not a hypertable, the function
+returns `NULL`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/create_hypertable_old/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM chunks_detailed_size('dist_table')
+ ORDER BY chunk_name, node_name;
+
+ chunk_schema | chunk_name | table_bytes | index_bytes | toast_bytes | total_bytes | node_name
+-----------------------+-----------------------+-------------+-------------+-------------+-------------+-----------------------
+ _timescaledb_internal | _dist_hyper_1_1_chunk | 8192 | 32768 | 0 | 40960 | data_node_1
+ _timescaledb_internal | _dist_hyper_1_2_chunk | 8192 | 32768 | 0 | 40960 | data_node_2
+ _timescaledb_internal | _dist_hyper_1_3_chunk | 8192 | 32768 | 0 | 40960 | data_node_3
+```
+
+---
+
+## add_columnstore_policy()
+
+**URL:** llms-txt#add_columnstore_policy()
+
+**Contents:**
+- Samples
+- Arguments
+
+Create a [job][job] that automatically moves chunks in a hypertable to the columnstore after a
+specific time interval.
+
+You enable the columnstore a hypertable or continuous aggregate before you create a columnstore policy.
+You do this by calling `CREATE TABLE` for hypertables and `ALTER MATERIALIZED VIEW` for continuous aggregates. When
+columnstore is enabled, [bloom filters][bloom-filters] are enabled by default, and every new chunk has a bloom index.
+If you converted chunks to columnstore using TimescaleDB v2.19.3 or below, to enable bloom filters on that data you have
+to convert those chunks to the rowstore, then convert them back to the columnstore.
+
+Bloom indexes are not retrofitted, meaning that the existing chunks need to be fully recompressed to have the bloom
+indexes present. Please check out the PR description for more in-depth explanations of how bloom filters in
+TimescaleDB work.
+
+To view the policies that you set or the policies that already exist,
+see [informational views][informational-views], to remove a policy, see [remove_columnstore_policy][remove_columnstore_policy].
+
+A columnstore policy is applied on a per-chunk basis. If you remove an existing policy and then add a new one, the new policy applies only to the chunks that have not yet been converted to columnstore. The existing chunks in the columnstore remain unchanged. This means that chunks with different columnstore settings can co-exist in the same hypertable.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To create a columnstore job:
+
+1. **Enable columnstore**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+* [Use `CREATE TABLE` for a hypertable][hypertable-create-table]
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+* [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
+
+1. **Add a policy to move chunks to the columnstore at a specific time interval**
+
+* 60 days after the data was added to the table:
+
+ * 3 months prior to the moment you run the query:
+
+* With an integer-based time column:
+
+* Older than eight weeks:
+
+* Control the time your policy runs:
+
+When you use a policy with a fixed schedule, TimescaleDB uses the `initial_start` time to compute the
+ next start time. When TimescaleDB finishes executing a policy, it picks the next available time on the
+ schedule,
+ skipping any candidate start times that have already passed.
+
+When you set the `next_start` time, it only changes the start time of the next immediate execution. It does not
+ change the computation of the next scheduled execution after that next execution. To change the schedule so a
+ policy starts at a specific time, you need to set `initial_start`. To change the next immediate
+ execution, you need to set `next_start`. For example, to modify a policy to execute on a fixed schedule 15 minutes past the hour, and every
+ hour, you need to set both `initial_start` and `next_start` using `alter_job`:
+
+1. **View the policies that you set or the policies that already exist**
+
+See [timescaledb_information.jobs][informational-views].
+
+Calls to `add_columnstore_policy` require either `after` or `created_before`, but cannot have both.
+
+
+
+
+| Name | Type | Default | Required | Description |
+|-------------------------------|--|------------------------------------------------------------------------------------------------------------------------------|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `hypertable` |REGCLASS| - | ✔ | Name of the hypertable or continuous aggregate to run this [job][job] on. |
+| `after` |INTERVAL or INTEGER| - | ✖ | Add chunks containing data older than `now - {after}::interval` to the columnstore.
+
+
+* **Recent, high-velocity data** stays in high-performance storage for ultra-fast queries.
+* **Older, less frequently accessed data** is automatically moved to cost-efficient object storage but remains queryable and available for building continuous aggregates.
+
+While many systems support this concept of data cooling, TimescaleDB ensures that the data can still be queried from the same hypertable regardless of its current location. For real-time analytics, this means applications can analyze live data streams without worrying about storage constraints, while still maintaining access to long-term trends when needed.
+
+### Cloud-native database observability
+
+Real-time analytics doesn’t just require fast queries—it requires the ability to understand why queries are fast or slow, where resources are being used, and how performance changes over time. That’s why Tiger Cloud is built with deep observability features, giving developers and operators full visibility into their database workloads.
+
+At the core of this observability is Insights, Tiger Cloud’s built-in query monitoring tool. Insights captures
+per-query
+statistics from our whole fleet in real time, showing you exactly how your database is behaving under load. It tracks key metrics like execution time, planning time, number of rows read and returned, I/O usage, and buffer cache hit rates—not just for the database as a whole, but for each individual query.
+
+Insights lets you do the following:
+
+* Identify slow or resource-intensive queries instantly
+* Spot long-term performance regressions or trends
+* Understand query patterns and how they evolve over time
+* See the impact of schema changes, indexes, or continuous aggregates on workload performance
+* Monitor and compare different versions of the same query to optimize execution
+
+All this is surfaced through an intuitive interface, available directly in Tiger Cloud, with no instrumentation or external monitoring infrastructure required.
+
+Beyond query-level visibility, Tiger Cloud also exposes metrics around service resource consumption, compression, continuous aggregates, and data tiering, allowing you to track how data moves through the system—and how those background processes impact storage and query performance.
+
+Together, these observability features give you the insight and control needed to operate a real-time analytics database at scale, with confidence, clarity, and performance you can trust**.**
+
+## Ensuring reliability and scalability
+
+Maintaining high availability, efficient resource utilization, and data durability is essential for real-time applications. Tiger Cloud provides robust operational features to ensure seamless performance under varying workloads.
+
+* **High-availability (HA) replicas**: deploy multi-AZ HA replicas to provide fault tolerance and ensure minimal downtime. In the event of a primary node failure, replicas are automatically promoted to maintain service continuity.
+* **Connection pooling**: optimize database connections by efficiently managing and reusing them, reducing overhead and improving performance for high-concurrency applications.
+* **Backup and recovery**: leverage continuous backups, Point-in-Time Recovery (PITR), and automated snapshotting to protect against data loss. Restore data efficiently to minimize downtime in case of failures or accidental deletions.
+
+These operational capabilities ensure Tiger Cloud remains reliable, scalable, and resilient, even under demanding real-time workloads.
+
+Real-time analytics is critical for modern applications, but traditional databases struggle to balance high-ingest performance, low-latency queries, and flexible data mutability. Tiger Cloud extends Postgres to solve this challenge, combining automatic partitioning, hybrid row-columnar storage, and intelligent compression to optimize both transactional and analytical workloads.
+
+With continuous aggregates, hyperfunctions, and advanced query optimizations, Tiger Cloud ensures sub-second queries
+even on massive datasets that combine current and historic data. Its cloud-native architecture further enhances scalability with independent compute and storage scaling, workload isolation, and cost-efficient data tiering—allowing applications to handle real-time and historical queries seamlessly.
+
+For developers, this means building high-performance, real-time analytics applications without sacrificing SQL compatibility, transactional guarantees, or operational simplicity.
+
+Tiger Cloud delivers the best of Postgres, optimized for real-time analytics.
+
+===== PAGE: https://docs.tigerdata.com/about/pricing-and-account-management/ =====
+
+---
+
+## stddev()
+
+**URL:** llms-txt#stddev()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-one-variable/rollup/ =====
+
+---
+
+## Approximate percentiles
+
+**URL:** llms-txt#approximate-percentiles
+
+**Contents:**
+- Run an approximate percentage query
+ - Running an approximate percentage query
+
+TimescaleDB uses approximation algorithms to calculate a percentile without
+requiring all of the data. This also makes them more compatible with continuous
+aggregates.
+
+By default, TimescaleDB Toolkit uses `uddsketch`, but you can also choose to use
+`tdigest`. For more information about these algorithms, see the
+[advanced aggregation methods][advanced-agg] documentation.
+
+## Run an approximate percentage query
+
+In this procedure, we use an example table called `response_times` that contains
+information about how long a server takes to respond to API calls.
+
+### Running an approximate percentage query
+
+1. At the `psql` prompt, create a continuous aggregate that computes the
+ daily aggregates:
+
+1. Re-aggregate the aggregate to get the last 30 days, and look for the
+ ninety-fifth percentile:
+
+1. You can also create an alert:
+
+For more information about percentile approximation API calls, see the
+[hyperfunction API documentation][hyperfunctions-api-approx-percentile].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hyperfunctions/index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW response_times_daily
+ WITH (timescaledb.continuous)
+ AS SELECT
+ time_bucket('1 day'::interval, ts) as bucket,
+ percentile_agg(response_time_ms)
+ FROM response_times
+ GROUP BY 1;
+```
+
+Example 2 (sql):
+```sql
+SELECT approx_percentile(0.95, percentile_agg) as threshold
+ FROM response_times_daily
+ WHERE bucket >= time_bucket('1 day'::interval, now() - '30 days'::interval);
+```
+
+Example 3 (sql):
+```sql
+WITH t as (SELECT approx_percentile(0.95, percentile_agg(percentile_agg)) as threshold
+ FROM response_times_daily
+ WHERE bucket >= time_bucket('1 day'::interval, now() - '30 days'::interval))
+
+ SELECT count(*)
+ FROM response_times
+ WHERE ts > now()- '1 minute'::interval
+ AND response_time_ms > (SELECT threshold FROM t);
+```
+
+---
+
+## skewness_y() | skewness_x()
+
+**URL:** llms-txt#skewness_y()-|-skewness_x()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/num_vals/ =====
+
+---
+
+## covariance()
+
+**URL:** llms-txt#covariance()
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/stats_agg-two-variables/rolling/ =====
+
+---
diff --git a/skills/timescaledb/references/hypertables.md b/skills/timescaledb/references/hypertables.md
new file mode 100644
index 0000000..0c0eb83
--- /dev/null
+++ b/skills/timescaledb/references/hypertables.md
@@ -0,0 +1,7899 @@
+# Timescaledb - Hypertables
+
+**Pages:** 103
+
+---
+
+## chunks_detailed_size()
+
+**URL:** llms-txt#chunks_detailed_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get information about the disk space used by the chunks belonging to a
+hypertable, returning size information for each chunk table, any
+indexes on the chunk, any toast tables, and the total size associated
+with the chunk. All sizes are reported in bytes.
+
+If the function is executed on a distributed hypertable, it returns
+disk space usage information as a separate row per node. The access
+node is not included since it doesn't have any local chunk data.
+
+Additional metadata associated with a chunk can be accessed
+via the `timescaledb_information.chunks` view.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Name of the hypertable |
+
+|Column|Type|Description|
+|---|---|---|
+|chunk_schema| TEXT | Schema name of the chunk |
+|chunk_name| TEXT | Name of the chunk|
+|table_bytes|BIGINT | Disk space used by the chunk table|
+|index_bytes|BIGINT | Disk space used by indexes|
+|toast_bytes|BIGINT | Disk space of toast tables|
+|total_bytes|BIGINT | Total disk space used by the chunk, including all indexes and TOAST data|
+|node_name| TEXT | Node for which size is reported, applicable only to distributed hypertables|
+
+If executed on a relation that is not a hypertable, the function
+returns `NULL`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/create_hypertable_old/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM chunks_detailed_size('dist_table')
+ ORDER BY chunk_name, node_name;
+
+ chunk_schema | chunk_name | table_bytes | index_bytes | toast_bytes | total_bytes | node_name
+-----------------------+-----------------------+-------------+-------------+-------------+-------------+-----------------------
+ _timescaledb_internal | _dist_hyper_1_1_chunk | 8192 | 32768 | 0 | 40960 | data_node_1
+ _timescaledb_internal | _dist_hyper_1_2_chunk | 8192 | 32768 | 0 | 40960 | data_node_2
+ _timescaledb_internal | _dist_hyper_1_3_chunk | 8192 | 32768 | 0 | 40960 | data_node_3
+```
+
+---
+
+## add_columnstore_policy()
+
+**URL:** llms-txt#add_columnstore_policy()
+
+**Contents:**
+- Samples
+- Arguments
+
+Create a [job][job] that automatically moves chunks in a hypertable to the columnstore after a
+specific time interval.
+
+You enable the columnstore a hypertable or continuous aggregate before you create a columnstore policy.
+You do this by calling `CREATE TABLE` for hypertables and `ALTER MATERIALIZED VIEW` for continuous aggregates. When
+columnstore is enabled, [bloom filters][bloom-filters] are enabled by default, and every new chunk has a bloom index.
+If you converted chunks to columnstore using TimescaleDB v2.19.3 or below, to enable bloom filters on that data you have
+to convert those chunks to the rowstore, then convert them back to the columnstore.
+
+Bloom indexes are not retrofitted, meaning that the existing chunks need to be fully recompressed to have the bloom
+indexes present. Please check out the PR description for more in-depth explanations of how bloom filters in
+TimescaleDB work.
+
+To view the policies that you set or the policies that already exist,
+see [informational views][informational-views], to remove a policy, see [remove_columnstore_policy][remove_columnstore_policy].
+
+A columnstore policy is applied on a per-chunk basis. If you remove an existing policy and then add a new one, the new policy applies only to the chunks that have not yet been converted to columnstore. The existing chunks in the columnstore remain unchanged. This means that chunks with different columnstore settings can co-exist in the same hypertable.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To create a columnstore job:
+
+1. **Enable columnstore**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+* [Use `CREATE TABLE` for a hypertable][hypertable-create-table]
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+* [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
+
+1. **Add a policy to move chunks to the columnstore at a specific time interval**
+
+* 60 days after the data was added to the table:
+
+ * 3 months prior to the moment you run the query:
+
+* With an integer-based time column:
+
+* Older than eight weeks:
+
+* Control the time your policy runs:
+
+When you use a policy with a fixed schedule, TimescaleDB uses the `initial_start` time to compute the
+ next start time. When TimescaleDB finishes executing a policy, it picks the next available time on the
+ schedule,
+ skipping any candidate start times that have already passed.
+
+When you set the `next_start` time, it only changes the start time of the next immediate execution. It does not
+ change the computation of the next scheduled execution after that next execution. To change the schedule so a
+ policy starts at a specific time, you need to set `initial_start`. To change the next immediate
+ execution, you need to set `next_start`. For example, to modify a policy to execute on a fixed schedule 15 minutes past the hour, and every
+ hour, you need to set both `initial_start` and `next_start` using `alter_job`:
+
+1. **View the policies that you set or the policies that already exist**
+
+See [timescaledb_information.jobs][informational-views].
+
+Calls to `add_columnstore_policy` require either `after` or `created_before`, but cannot have both.
+
+
+
+
+| Name | Type | Default | Required | Description |
+|-------------------------------|--|------------------------------------------------------------------------------------------------------------------------------|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `hypertable` |REGCLASS| - | ✔ | Name of the hypertable or continuous aggregate to run this [job][job] on. |
+| `after` |INTERVAL or INTEGER| - | ✖ | Add chunks containing data older than `now - {after}::interval` to the columnstore.
Use an object type that matchs the time column type in `hypertable`: TIMESTAMP, TIMESTAMPTZ, or DATE: use an INTERVAL type.- Integer-based timestamps : set an integer type using the [integer_now_func][set_integer_now_func].
`after` is mutually exclusive with `created_before`. |
+| `created_before` |INTERVAL| NULL | ✖ | Add chunks with a creation time of `now() - created_before` to the columnstore.
`created_before` is - Not supported for continuous aggregates.
- Mutually exclusive with `after`.
|
+| `schedule_interval` |INTERVAL| 12 hours when [chunk_time_interval][chunk_time_interval] >= `1 day` for `hypertable`. Otherwise `chunk_time_interval` / `2`. | ✖ | Set the interval between the finish time of the last execution of this policy and the next start. |
+| `initial_start` |TIMESTAMPTZ| The interval from the finish time of the last execution to the [next_start][next-start]. | ✖ | Set the time this job is first run. This is also the time that `next_start` is calculated from. |
+| `next_start` |TIMESTAMPTZ| -| ✖ | Set the start time of the next immediate execution. It does not change the computation of the next scheduled time after the next execution. |
+| `timezone` |TEXT| UTC. However, daylight savings time(DST) changes may shift this alignment. | ✖ | Set to a valid time zone to mitigate DST shifting. If `initial_start` is set, subsequent executions of this policy are aligned on `initial_start`. |
+| `if_not_exists` |BOOLEAN| `false` | ✖ | Set to `true` so this job fails with a warning rather than an error if a columnstore policy already exists on `hypertable` |
+
+
+
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/hypertable_columnstore_settings/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby='symbol',
+ tsdb.orderby='time DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+ALTER MATERIALIZED VIEW assets_candlestick_daily set (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol' );
+```
+
+Example 3 (unknown):
+```unknown
+* 3 months prior to the moment you run the query:
+```
+
+Example 4 (unknown):
+```unknown
+* With an integer-based time column:
+```
+
+---
+
+## Create distributed hypertables
+
+**URL:** llms-txt#create-distributed-hypertables
+
+**Contents:**
+ - Creating a distributed hypertable
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+If you have a [multi-node environment][multi-node], you can create a distributed
+hypertable across your data nodes. First create a standard Postgres table, and
+then convert it into a distributed hypertable.
+
+You need to set up your multi-node cluster before creating a distributed
+hypertable. To set up multi-node, see the
+[multi-node section](https://docs.tigerdata.com/self-hosted/latest/multinode-timescaledb/).
+
+### Creating a distributed hypertable
+
+1. On the access node of your multi-node cluster, create a standard
+ [Postgres table][postgres-createtable]:
+
+1. Convert the table to a distributed hypertable. Specify the name of the table
+ you want to convert, the column that holds its time values, and a
+ space-partitioning parameter.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/distributed-hypertables/foreign-keys/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+ );
+```
+
+Example 2 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location');
+```
+
+---
+
+## show_chunks()
+
+**URL:** llms-txt#show_chunks()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Get list of chunks associated with a hypertable.
+
+Function accepts the following required and optional arguments. These arguments
+have the same semantics as the `drop_chunks` [function][drop_chunks].
+
+Get list of all chunks associated with a table:
+
+Get all chunks from hypertable `conditions` older than 3 months:
+
+Get all chunks from hypertable `conditions` created before 3 months:
+
+Get all chunks from hypertable `conditions` created in the last 1 month:
+
+Get all chunks from hypertable `conditions` before 2017:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`relation`|REGCLASS|Hypertable or continuous aggregate from which to select chunks.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`older_than`|ANY|Specification of cut-off point where any chunks older than this timestamp should be shown.|
+|`newer_than`|ANY|Specification of cut-off point where any chunks newer than this timestamp should be shown.|
+|`created_before`|ANY|Specification of cut-off point where any chunks created before this timestamp should be shown.|
+|`created_after`|ANY|Specification of cut-off point where any chunks created after this timestamp should be shown.|
+
+The `older_than` and `newer_than` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ older_than` and similarly `now() - newer_than`. An error is returned if an
+ INTERVAL is supplied and the time column is not one of a TIMESTAMP,
+ TIMESTAMPTZ, or DATE.
+
+* **timestamp, date, or integer type:** The cut-off point is explicitly given
+ as a TIMESTAMP / TIMESTAMPTZ / DATE or as a SMALLINT / INT / BIGINT. The
+ choice of timestamp or integer must follow the type of the hypertable's time
+ column.
+
+The `created_before` and `created_after` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ created_before` and similarly `now() - created_after`. This uses
+ the chunk creation time for the filtering.
+
+* **timestamp, date, or integer type:** The cut-off point is
+ explicitly given as a `TIMESTAMP` / `TIMESTAMPTZ` / `DATE` or as a
+ `SMALLINT` / `INT` / `BIGINT`. The choice of integer value
+ must follow the type of the hypertable's partitioning column. Otherwise
+ the chunk creation time is used for the filtering.
+
+When both `older_than` and `newer_than` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `newer_than => 4 months` and `older_than => 3
+months` shows all chunks between 3 and 4 months old.
+Similarly, specifying `newer_than => '2017-01-01'` and `older_than
+=> '2017-02-01'` shows all chunks between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+When both `created_before` and `created_after` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `created_after`=> 4 months` and `created_before`=> 3
+months` shows all chunks created between 3 and 4 months from now.
+Similarly, specifying `created_after`=> '2017-01-01'` and `created_before`
+=> '2017-02-01'` shows all chunks created between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+The `created_before`/`created_after` parameters cannot be used together with
+`older_than`/`newer_than`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/merge_chunks/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT show_chunks('conditions');
+```
+
+Example 2 (sql):
+```sql
+SELECT show_chunks('conditions', older_than => INTERVAL '3 months');
+```
+
+Example 3 (sql):
+```sql
+SELECT show_chunks('conditions', created_before => INTERVAL '3 months');
+```
+
+Example 4 (sql):
+```sql
+SELECT show_chunks('conditions', created_after => INTERVAL '1 month');
+```
+
+---
+
+## Optimize time-series data in hypertables
+
+**URL:** llms-txt#optimize-time-series-data-in-hypertables
+
+**Contents:**
+- Prerequisites
+- Create a hypertable
+- Speed up data ingestion
+- Optimize cooling data in the columnstore
+- Alter a hypertable
+ - Add a column to a hypertable
+ - Rename a hypertable
+- Drop a hypertable
+
+Hypertables are designed for real-time analytics, they are Postgres tables that automatically partition your data by
+time. Typically, you partition hypertables on columns that hold time values.
+[Best practice is to use `timestamptz`][timestamps-best-practice] column type. However, you can also partition on
+`date`, `integer`, `timestamp` and [UUIDv7][uuidv7_functions] types.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Create a hypertable
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will use
+most often to filter your data:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+To convert an existing table with data in it, call `create_hypertable` on that table with
+[`migrate_data` to `true`][api-create-hypertable-arguments]. However, if you have a lot of data, this may take a long time.
+
+## Speed up data ingestion
+
+When you set `timescaledb.enable_direct_compress_copy` your data gets compressed in memory during ingestion with `COPY` statements.
+By writing the compressed batches immediately in the columnstore, the IO footprint is significantly lower.
+Also, the [columnstore policy][add_columnstore_policy] you set is less important, `INSERT` already produces compressed chunks.
+
+Please note that this feature is a **tech preview** and not production-ready.
+Using this feature could lead to regressed query performance and/or storage ratio, if the ingested batches are not
+correctly ordered or are of too high cardinality.
+
+To enable in-memory data compression during ingestion:
+
+**Important facts**
+- High cardinality use cases do not produce good batches and lead to degreaded query performance.
+- The columnstore is optimized to store 1000 records per batch, which is the optimal format for ingestion per segment by.
+- WAL records are written for the compressed batches rather than the individual tuples.
+- Currently only `COPY` is support, `INSERT` will eventually follow.
+- Best results are achieved for batch ingestion with 1000 records or more, upper boundary is 10.000 records.
+- Continous Aggregates are **not** supported at the moment.
+
+## Optimize cooling data in the columnstore
+
+As the data cools and becomes more suited for analytics, [add a columnstore policy][add_columnstore_policy] so your data
+is automatically converted to the columnstore after a specific time interval. This columnar format enables fast
+scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space.
+In the columnstore conversion, hypertable chunks are compressed by up to 98%, and organized for efficient,
+large-scale queries. This columnar format enables fast scanning and aggregation, optimizing performance for analytical
+workloads.
+
+To optimize your data, add a columnstore policy:
+
+You can also manually [convert chunks][convert_to_columnstore] in a hypertable to the columnstore.
+
+## Alter a hypertable
+
+You can alter a hypertable, for example to add a column, by using the Postgres
+[`ALTER TABLE`][postgres-altertable] command. This works for both regular and
+distributed hypertables.
+
+### Add a column to a hypertable
+
+You add a column to a hypertable using the `ALTER TABLE` command. In this
+example, the hypertable is named `conditions` and the new column is named
+`humidity`:
+
+If the column you are adding has the default value set to `NULL`, or has no
+default value, then adding a column is relatively fast. If you set the default
+to a non-null value, it takes longer, because it needs to fill in this value for
+all existing rows of all existing chunks.
+
+### Rename a hypertable
+
+You can change the name of a hypertable using the `ALTER TABLE` command. In this
+example, the hypertable is called `conditions`, and is being changed to the new
+name, `weather`:
+
+Drop a hypertable using a standard Postgres [`DROP TABLE`][postgres-droptable]
+command:
+
+All data chunks belonging to the hypertable are deleted.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypertables/improve-query-performance/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby = 'device',
+ tsdb.orderby = 'time DESC'
+);
+```
+
+Example 2 (sql):
+```sql
+SET timescaledb.enable_direct_compress_copy=on;
+```
+
+Example 3 (sql):
+```sql
+CALL add_columnstore_policy('conditions', after => INTERVAL '1d');
+```
+
+Example 4 (sql):
+```sql
+ALTER TABLE conditions
+ ADD COLUMN humidity DOUBLE PRECISION NULL;
+```
+
+---
+
+## add_reorder_policy()
+
+**URL:** llms-txt#add_reorder_policy()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Create a policy to reorder the rows of a hypertable's chunks on a specific index. The policy reorders the rows for all chunks except the two most recent ones, because these are still getting writes. By default, the policy runs every 24 hours. To change the schedule, call [alter_job][alter_job] and adjust `schedule_interval`.
+
+You can have only one reorder policy on each hypertable.
+
+For manual reordering of individual chunks, see [reorder_chunk][reorder_chunk].
+
+When a chunk's rows have been reordered by a policy, they are not reordered
+by subsequent runs of the same policy. If you write significant amounts of data into older chunks that have
+already been reordered, re-run [reorder_chunk][reorder_chunk] on them. If you have changed a lot of older chunks, it is better to drop and recreate the policy.
+
+Creates a policy to reorder chunks by the existing `(device_id, time)` index every 24 hours.
+This applies to all chunks except the two most recent ones.
+
+## Required arguments
+
+|Name|Type| Description |
+|-|-|--------------------------------------------------------------|
+|`hypertable`|REGCLASS| Hypertable to create the policy for |
+|`index_name`|TEXT| Existing hypertable index by which to order the rows on disk |
+
+## Optional arguments
+
+|Name|Type| Description |
+|-|-|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|`if_not_exists`|BOOLEAN| Set to `true` to avoid an error if the `reorder_policy` already exists. A notice is issued instead. Defaults to `false`. |
+|`initial_start`|TIMESTAMPTZ| Controls when the policy first runs and how its future run schedule is calculated. - If omitted or set to
NULL (default): - The first run is scheduled at
now() + schedule_interval (defaults to 24 hours). - The next run is scheduled at one full
schedule_interval after the end of the previous run.
- If set:
- The first run is at the specified time.
- The next run is scheduled as
initial_start + schedule_interval regardless of when the previous run ends.
|
+|`timezone`|TEXT| A valid time zone. If `initial_start` is also specified, subsequent runs of the reorder policy are aligned on its initial start. However, daylight savings time (DST) changes might shift this alignment. Set to a valid time zone if this is an issue you want to mitigate. If omitted, UTC bucketing is performed. Defaults to `NULL`. |
+
+|Column|Type|Description|
+|-|-|-|
+|`job_id`|INTEGER|TimescaleDB background job ID created to implement this policy|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/hypertable_detailed_size/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_reorder_policy('conditions', 'conditions_device_id_time_idx');
+```
+
+---
+
+## split_chunk()
+
+**URL:** llms-txt#split_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Split a large chunk at a specific point in time. If you do not specify the timestamp to split at, `chunk`
+is split equally.
+
+* Split a chunk at a specific time:
+
+* Split a chunk in two:
+
+For example, If the chunk duration is, 24 hours, the following command splits `chunk_1` into
+ two chunks of 12 hours each.
+
+## Required arguments
+
+|Name|Type| Required | Description |
+|---|---|---|----------------------------------|
+| `chunk` | REGCLASS | ✔ | Name of the chunk to split. |
+| `split_at` | `TIMESTAMPTZ`| ✖ |Timestamp to split the chunk at. |
+
+This function returns void.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/attach_chunk/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL split_chunk('chunk_1', split_at => '2025-03-01 00:00');
+```
+
+Example 2 (sql):
+```sql
+CALL split_chunk('chunk_1');
+```
+
+---
+
+## timescaledb_information.chunk_columnstore_settings
+
+**URL:** llms-txt#timescaledb_information.chunk_columnstore_settings
+
+**Contents:**
+- Samples
+- Returns
+
+Retrieve the compression settings for each chunk in the columnstore.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To retrieve information about settings:
+
+- **Show settings for all chunks in the columnstore**:
+
+* **Find all chunk columnstore settings for a specific hypertable**:
+
+| Name | Type | Description |
+|--|--|--|--|--|
+|`hypertable`|`REGCLASS`| The name of the hypertable in the columnstore. |
+|`chunk`|`REGCLASS`| The name of the chunk in the `hypertable`. |
+|`segmentby`|`TEXT`| The list of columns used to segment the `hypertable`. |
+|`orderby`|`TEXT`| The list of columns used to order the data in the `hypertable`, along with the ordering and `NULL` ordering information. |
+|`index`| `TEXT` | The sparse index details. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/add_columnstore_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM timescaledb_information.chunk_columnstore_settings
+```
+
+Example 2 (sql):
+```sql
+hypertable | chunk | segmentby | orderby
+ ------------+-------+-----------+---------
+ measurements | _timescaledb_internal._hyper_1_1_chunk| | "time" DESC
+```
+
+Example 3 (sql):
+```sql
+SELECT *
+ FROM timescaledb_information.chunk_columnstore_settings
+ WHERE hypertable::TEXT LIKE 'metrics';
+```
+
+Example 4 (sql):
+```sql
+hypertable | chunk | segmentby | orderby
+ ------------+-------+-----------+---------
+ metrics | _timescaledb_internal._hyper_2_3_chunk | metric_id | "time"
+```
+
+---
+
+## Alter and drop distributed hypertables
+
+**URL:** llms-txt#alter-and-drop-distributed-hypertables
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+You can alter and drop distributed hypertables in the same way as standard
+hypertables. To learn more, see:
+
+* [Altering hypertables][alter]
+* [Dropping hypertables][drop]
+
+When you alter a distributed hypertable, or set privileges on it, the commands
+are automatically applied across all data nodes. For more information, see the
+section on
+[multi-node administration][multinode-admin].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/distributed-hypertables/create-distributed-hypertables/ =====
+
+---
+
+## Can't create unique index on hypertable, or can't create hypertable with unique index
+
+**URL:** llms-txt#can't-create-unique-index-on-hypertable,-or-can't-create-hypertable-with-unique-index
+
+
+
+You might get a unique index and partitioning column error in 2 situations:
+
+* When creating a primary key or unique index on a hypertable
+* When creating a hypertable from a table that already has a unique index or
+ primary key
+
+For more information on how to fix this problem, see the
+[section on creating unique indexes on hypertables][unique-indexes].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/explain/ =====
+
+---
+
+## merge_chunks()
+
+**URL:** llms-txt#merge_chunks()
+
+**Contents:**
+- Since2180
+- Samples
+- Arguments
+
+Merge two or more chunks into one.
+
+The partition boundaries for the new chunk is the union of all partitions of the merged chunks.
+The new chunk retains the name, constraints, and triggers of the _first_ chunk in the partition order.
+
+You can only merge chunks that have directly adjacent partitions. It is not possible to merge
+chunks that have another chunk, or an empty range between them in any of the partitioning
+dimensions.
+
+Chunk merging has the following limitations. You cannot:
+
+* Merge chunks with tiered data
+* Read or write from the chunks while they are being merged
+
+Refer to the installation documentation for detailed setup instructions.
+
+- Merge more than two chunks:
+
+You can merge either two chunks, or an arbitrary number of chunks specified as an array of chunk identifiers.
+When you call `merge_chunks`, you must specify either `chunk1` and `chunk2`, or `chunks`. You cannot use both
+arguments.
+
+| Name | Type | Default | Required | Description |
+|--------------------|-------------|--|--|------------------------------------------------|
+| `chunk1`, `chunk2` | REGCLASS | - | ✖ | The two chunk to merge in partition order |
+| `chunks` | REGCLASS[] |- | ✖ | The array of chunks to merge in partition order |
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/add_dimension/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL merge_chunks('_timescaledb_internal._hyper_1_1_chunk', '_timescaledb_internal._hyper_1_2_chunk');
+```
+
+Example 2 (sql):
+```sql
+CALL merge_chunks('{_timescaledb_internal._hyper_1_1_chunk, _timescaledb_internal._hyper_1_2_chunk, _timescaledb_internal._hyper_1_3_chunk}');
+```
+
+---
+
+## disable_chunk_skipping()
+
+**URL:** llms-txt#disable_chunk_skipping()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Disable range tracking for a specific column in a hypertable **in the columnstore**.
+
+In this sample, you convert the `conditions` table to a hypertable with
+partitioning on the `time` column. You then specify and enable additional
+columns to track ranges for. You then disable range tracking:
+
+Best practice is to enable range tracking on columns which are correlated to the
+ partitioning column. In other words, enable tracking on secondary columns that are
+ referenced in the `WHERE` clauses in your queries.
+ Use this API to disable range tracking on columns when the query patterns don't
+ use this secondary column anymore.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable that the column belongs to|
+|`column_name`|TEXT|Column to disable tracking range statistics for|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`if_not_exists`|BOOLEAN|Set to `true` so that a notice is sent when ranges are not being tracked for a column. By default, an error is thrown|
+
+|Column|Type|Description|
+|-|-|-|
+|`hypertable_id`|INTEGER|ID of the hypertable in TimescaleDB.|
+|`column_name`|TEXT|Name of the column range tracking is disabled for|
+|`disabled`|BOOLEAN|Returns `true` when tracking is disabled. `false` when `if_not_exists` is `true` and the entry was
+not removed|
+
+To `disable_chunk_skipping()`, you must have first called [enable_chunk_skipping][enable_chunk_skipping]
+and enabled range tracking on a column in the hypertable.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/remove_reorder_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time');
+SELECT enable_chunk_skipping('conditions', 'device_id');
+SELECT disable_chunk_skipping('conditions', 'device_id');
+```
+
+---
+
+## Optimize your data for real-time analytics
+
+**URL:** llms-txt#optimize-your-data-for-real-time-analytics
+
+**Contents:**
+- Prerequisites
+- Optimize your data with columnstore policies
+- Reference
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+When you convert chunks from the rowstore to the columnstore, multiple records are grouped into a single row.
+The columns of this row hold an array-like structure that stores all the data. For example, data in the following
+rowstore chunk:
+
+| Timestamp | Device ID | Device Type | CPU |Disk IO|
+|---|---|---|---|---|
+|12:00:01|A|SSD|70.11|13.4|
+|12:00:01|B|HDD|69.70|20.5|
+|12:00:02|A|SSD|70.12|13.2|
+|12:00:02|B|HDD|69.69|23.4|
+|12:00:03|A|SSD|70.14|13.0|
+|12:00:03|B|HDD|69.70|25.2|
+
+Is converted and compressed into arrays in a row in the columnstore:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[SSD, HDD, SSD, HDD, SSD, HDD]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|[13.4, 20.5, 13.2, 23.4, 13.0, 25.2]|
+
+Because a single row takes up less disk space, you can reduce your chunk size by up to 98%, and can also
+speed up your queries. This saves on storage costs, and keeps your queries operating at lightning speed.
+
+For an in-depth explanation of how hypertables and hypercore work, see the [Data model][data-model].
+
+This page shows you how to get the best results when you set a policy to automatically convert chunks in a hypertable
+from the rowstore to the columnstore.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with real-time analytics enabled.
+
+You need your [connection details][connection-info].
+
+The code samples in this page use the [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip) data from [this key features tutorial][ingest-data].
+
+## Optimize your data with columnstore policies
+
+The compression ratio and query performance of data in the columnstore is dependent on the order and structure of your
+data. Rows that change over a dimension should be close to each other. With time-series data, you `orderby` the time
+dimension. For example, `Timestamp`:
+
+| Timestamp | Device ID | Device Type | CPU |Disk IO|
+|---|---|---|---|---|
+|12:00:01|A|SSD|70.11|13.4|
+
+This ensures that records are compressed and accessed in the same order. However, you would always have to
+access the data using the time dimension, then filter all the rows using other criteria. To make your queries more
+efficient, you segment your data based on the following:
+
+- The way you want to access it. For example, to rapidly access data about a
+single device, you `segmentby` the `Device ID` column. This enables you to run much faster analytical queries on
+data in the columnstore.
+- The compression rate you want to achieve. The [lower the cardinality][cardinality-blog] of the `segmentby` column, the better compression results you get.
+
+When TimescaleDB converts a chunk to the columnstore, it automatically creates a different schema for your
+data. It also creates and uses custom indexes to incorporate the `segmentby` and `orderby` parameters when
+you write to and read from the columnstore.
+
+To set up your hypercore automation:
+
+1. **Connect to your Tiger Cloud service**
+
+In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. You can also connect to your service using [psql][connect-using-psql].
+
+1. **Enable columnstore on a hypertable**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+* [Use `CREATE TABLE` for a hypertable][hypertable-create-table]
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+* [Use `ALTER MATERIALIZED VIEW` for a continuous aggregate][compression_continuous-aggregate]
+
+ Before you say `huh`, a continuous aggregate is a specialized hypertable.
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+Create a [columnstore_policy][add_columnstore_policy] that automatically converts chunks in a hypertable to the columnstore at a specific time interval. For example, convert yesterday's crypto trading data to the columnstore:
+
+TimescaleDB is optimized for fast updates on compressed data in the columnstore. To modify data in the
+ columnstore, use standard SQL.
+
+1. **Check the columnstore policy**
+
+1. View your data space saving:
+
+When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than
+ 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved:
+
+You see something like:
+
+| before | after |
+ |---------|--------|
+ | 194 MB | 24 MB |
+
+1. View the policies that you set or the policies that already exist:
+
+See [timescaledb_information.jobs][informational-views].
+
+1. **Pause a columnstore policy**
+
+See [alter_job][alter_job].
+
+1. **Restart a columnstore policy**
+
+See [alter_job][alter_job].
+
+1. **Remove a columnstore policy**
+
+See [remove_columnstore_policy][remove_columnstore_policy].
+
+1. **Disable columnstore**
+
+If your table has chunks in the columnstore, you have to
+ [convert the chunks back to the rowstore][convert_to_rowstore] before you disable the columnstore.
+
+ See [alter_table_hypercore][alter_table_hypercore].
+
+For integers, timestamps, and other integer-like types, data is compressed using [delta encoding][delta],
+[delta-of-delta][delta-delta], [simple-8b][simple-8b], and [run-length encoding][run-length]. For columns with few
+repeated values, [XOR-based][xor] and [dictionary compression][dictionary] is used. For all other types,
+[dictionary compression][dictionary] is used.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypercore/compression-methods/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby='symbol',
+ tsdb.orderby='time DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+ALTER MATERIALIZED VIEW assets_candlestick_daily set (
+ timescaledb.enable_columnstore = true,
+ timescaledb.segmentby = 'symbol' );
+```
+
+Example 3 (unknown):
+```unknown
+TimescaleDB is optimized for fast updates on compressed data in the columnstore. To modify data in the
+ columnstore, use standard SQL.
+
+1. **Check the columnstore policy**
+
+ 1. View your data space saving:
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than
+ 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved:
+```
+
+Example 4 (unknown):
+```unknown
+You see something like:
+
+ | before | after |
+ |---------|--------|
+ | 194 MB | 24 MB |
+
+ 1. View the policies that you set or the policies that already exist:
+```
+
+---
+
+## Triggers
+
+**URL:** llms-txt#triggers
+
+**Contents:**
+- Create a trigger
+ - Creating a trigger
+
+TimescaleDB supports the full range of Postgres triggers. Creating, altering,
+or dropping triggers on a hypertable propagates the changes to all of the
+underlying chunks.
+
+This example creates a new table called `error_conditions` with the same schema
+as `conditions`, but that only stores records which are considered errors. An
+error, in this case, is when an application sends a `temperature` or `humidity`
+reading with a value that is greater than or equal to 1000.
+
+### Creating a trigger
+
+1. Create a function that inserts erroneous data into the `error_conditions`
+ table:
+
+1. Create a trigger that calls this function whenever a new row is inserted
+ into the hypertable:
+
+1. All data is inserted into the `conditions` table, but rows that contain errors
+ are also added to the `error_conditions` table.
+
+TimescaleDB supports the full range of triggers, including `BEFORE INSERT`,
+`AFTER INSERT`, `BEFORE UPDATE`, `AFTER UPDATE`, `BEFORE DELETE`, and
+`AFTER DELETE`. For more information, see the
+[Postgres docs][postgres-createtrigger].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/foreign-data-wrappers/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE OR REPLACE FUNCTION record_error()
+ RETURNS trigger AS $record_error$
+ BEGIN
+ IF NEW.temperature >= 1000 OR NEW.humidity >= 1000 THEN
+ INSERT INTO error_conditions
+ VALUES(NEW.time, NEW.location, NEW.temperature, NEW.humidity);
+ END IF;
+ RETURN NEW;
+ END;
+ $record_error$ LANGUAGE plpgsql;
+```
+
+Example 2 (sql):
+```sql
+CREATE TRIGGER record_error
+ BEFORE INSERT ON conditions
+ FOR EACH ROW
+ EXECUTE PROCEDURE record_error();
+```
+
+---
+
+## copy_chunk()
+
+**URL:** llms-txt#copy_chunk()
+
+**Contents:**
+- Required arguments
+- Required settings
+- Failures
+- Sample usage
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+TimescaleDB allows you to copy existing chunks to a new location within a
+multi-node environment. This allows each data node to work both as a primary for
+some chunks and backup for others. If a data node fails, its chunks already
+exist on other nodes that can take over the responsibility of serving them.
+
+Experimental features could have bugs. They might not be backwards compatible,
+and could be removed in future releases. Use these features at your own risk, and
+do not use any experimental features in production.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`chunk`|REGCLASS|Name of chunk to be copied|
+|`source_node`|NAME|Data node where the chunk currently resides|
+|`destination_node`|NAME|Data node where the chunk is to be copied|
+
+When copying a chunk, the destination data node needs a way to
+authenticate with the data node that holds the source chunk. It is
+currently recommended to use a [password file][password-config] on the
+data node.
+
+The `wal_level` setting must also be set to `logical` or higher on
+data nodes from which chunks are copied. If you are copying or moving
+many chunks in parallel, you can increase `max_wal_senders` and
+`max_replication_slots`.
+
+When a copy operation fails, it sometimes creates objects and metadata on
+the destination data node. It can also hold a replication slot open on the
+source data node. To clean up these objects and metadata, use
+[`cleanup_copy_chunk_operation`][cleanup_copy_chunk].
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/alter_data_node/ =====
+
+---
+
+## hypertable_detailed_size()
+
+**URL:** llms-txt#hypertable_detailed_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get detailed information about disk space used by a hypertable or
+continuous aggregate, returning size information for the table
+itself, any indexes on the table, any toast tables, and the total
+size of all. All sizes are reported in bytes. If the function is
+executed on a distributed hypertable, it returns size information
+as a separate row per node, including the access node.
+
+When a continuous aggregate name is provided, the function
+transparently looks up the backing hypertable and returns its statistics
+instead.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get the size information for a hypertable.
+
+The access node is listed without a user-given node name. Normally,
+the access node holds no data, but still maintains, for example, index
+information that occupies a small amount of disk space.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Hypertable or continuous aggregate to show detailed size of. |
+
+|Column|Type|Description|
+|-|-|-|
+|table_bytes|BIGINT|Disk space used by main_table (like `pg_relation_size(main_table)`)|
+|index_bytes|BIGINT|Disk space used by indexes|
+|toast_bytes|BIGINT|Disk space of toast tables|
+|total_bytes|BIGINT|Total disk space used by the specified table, including all indexes and TOAST data|
+|node_name|TEXT|For distributed hypertables, this is the user-given name of the node for which the size is reported. `NULL` is returned for the access node and non-distributed hypertables.|
+
+If executed on a relation that is not a hypertable, the function
+returns `NULL`.
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/show_policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+-- disttable is a distributed hypertable --
+SELECT * FROM hypertable_detailed_size('disttable') ORDER BY node_name;
+
+ table_bytes | index_bytes | toast_bytes | total_bytes | node_name
+-------------+-------------+-------------+-------------+-------------
+ 16384 | 40960 | 0 | 57344 | data_node_1
+ 8192 | 24576 | 0 | 32768 | data_node_2
+ 0 | 8192 | 0 | 8192 |
+```
+
+---
+
+## Limitations
+
+**URL:** llms-txt#limitations
+
+**Contents:**
+- Hypertable limitations
+
+While TimescaleDB generally offers capabilities that go beyond what
+Postgres offers, there are some limitations to using hypertables.
+
+## Hypertable limitations
+
+* Time dimensions (columns) used for partitioning cannot have NULL values.
+* Unique indexes must include all columns that are partitioning dimensions.
+* `UPDATE` statements that move values between partitions (chunks) are not
+ supported. This includes upserts (`INSERT ... ON CONFLICT UPDATE`).
+* Foreign key constraints from a hypertable referencing another hypertable are not supported.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/tigerlake/ =====
+
+---
+
+## remove_retention_policy()
+
+**URL:** llms-txt#remove_retention_policy()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Remove a policy to drop chunks of a particular hypertable.
+
+Removes the existing data retention policy for the `conditions` table.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `relation` | REGCLASS | Name of the hypertable or continuous aggregate from which to remove the policy |
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `if_exists` | BOOLEAN | Set to true to avoid throwing an error if the policy does not exist. Defaults to false.|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/create_table/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT remove_retention_policy('conditions');
+```
+
+---
+
+## show_tablespaces()
+
+**URL:** llms-txt#show_tablespaces()
+
+**Contents:**
+- Samples
+- Required arguments
+
+Show the tablespaces attached to a hypertable.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Hypertable to show attached tablespaces for.|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/disable_chunk_skipping/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM show_tablespaces('conditions');
+
+ show_tablespaces
+------------------
+ disk1
+ disk2
+```
+
+---
+
+## Hypertables and chunks
+
+**URL:** llms-txt#hypertables-and-chunks
+
+**Contents:**
+- The hypertable workflow
+
+Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
+
+
+
+Hypertables offer the following benefits:
+
+- **Efficient data management with [automated partitioning by time][chunk-size]**: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
+
+- **Better performance with [strategic indexing][hypertable-indexes]**: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
+
+- **Faster queries with [chunk skipping][chunk-skipping]**: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
+
+- **Advanced data analysis with [hyperfunctions][hyperfunctions]**: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+
+To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.
+
+Inheritance is not supported for hypertables and may lead to unexpected behavior.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+## The hypertable workflow
+
+Best practice for using a hypertable is to:
+
+1. **Create a hypertable**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+1. **Set the columnstore policy**
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby = 'device',
+ tsdb.orderby = 'time DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+CALL add_columnstore_policy('conditions', after => INTERVAL '1d');
+```
+
+---
+
+## Create foreign keys in a distributed hypertable
+
+**URL:** llms-txt#create-foreign-keys-in-a-distributed-hypertable
+
+**Contents:**
+- Creating foreign keys in a distributed hypertable
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Tables and values referenced by a distributed hypertable must be present on the
+access node and all data nodes. To create a foreign key from a distributed
+hypertable, use [`distributed_exec`][distributed_exec] to first create the
+referenced table on all nodes.
+
+## Creating foreign keys in a distributed hypertable
+
+1. Create the referenced table on the access node.
+1. Use [`distributed_exec`][distributed_exec] to create the same table on all
+ data nodes and update it with the correct data.
+1. Create a foreign key from your distributed hypertable to your referenced
+ table.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/distributed-hypertables/triggers/ =====
+
+---
+
+## CREATE TABLE
+
+**URL:** llms-txt#create-table
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Create a [hypertable][hypertable-docs] partitioned on a single dimension with [columnstore][hypercore] enabled, or
+create a standard Postgres relational table.
+
+A hypertable is a specialized Postgres table that automatically partitions your data by time. All actions that work on a
+Postgres table, work on hypertables. For example, [ALTER TABLE][alter_table_hypercore] and [SELECT][sql-select]. By default,
+a hypertable is partitioned on the time dimension. To add secondary dimensions to a hypertable, call
+[add_dimension][add-dimension]. To convert an existing relational table into a hypertable, call
+[create_hypertable][create_hypertable].
+
+As the data cools and becomes more suited for analytics, [add a columnstore policy][add_columnstore_policy] so your data
+is automatically converted to the columnstore after a specific time interval. This columnar format enables fast
+scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space.
+In the columnstore conversion, hypertable chunks are compressed by up to 98%, and organized for efficient,
+large-scale queries. This columnar format enables fast scanning and aggregation, optimizing performance for analytical
+workloads. You can also manually [convert chunks][convert_to_columnstore] in a hypertable to the columnstore.
+
+Hypertable to hypertable foreign keys are not allowed, all other combinations are permitted.
+
+The [columnstore][hypercore] settings are applied on a per-chunk basis. You can change the settings by calling [ALTER TABLE][alter_table_hypercore] without first converting the entire hypertable back to the [rowstore][hypercore]. The new settings apply only to the chunks that have not yet been converted to columnstore, the existing chunks in the columnstore do not change. Similarly, if you [remove an existing columnstore policy][remove_columnstore_policy] and then [add a new one][add_columnstore_policy], the new policy applies only to the unconverted chunks. This means that chunks with different columnstore settings can co-exist in the same hypertable.
+
+TimescaleDB calculates default columnstore settings for each chunk when it is created. These settings apply to each chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string.
+
+`CREATE TABLE` extends the standard Postgres [CREATE TABLE][pg-create-table]. This page explains the features and
+arguments specific to TimescaleDB.
+
+Since [TimescaleDB v2.20.0](https://github.com/timescale/timescaledb/releases/tag/2.20.0)
+
+- **Create a hypertable partitioned on the time dimension and enable columnstore**:
+
+1. Create the hypertable:
+
+1. Enable hypercore by adding a columnstore policy:
+
+- **Create a hypertable partitioned on the time with fewer chunks based on time interval**:
+
+- **Create a hypertable partitioned using [UUIDv7][uuidv7_functions]**:
+
+- **Enable data compression during ingestion**:
+
+When you set `timescaledb.enable_direct_compress_copy` your data gets compressed in memory during ingestion with `COPY` statements.
+By writing the compressed batches immediately in the columnstore, the IO footprint is significantly lower.
+Also, the [columnstore policy][add_columnstore_policy] you set is less important, `INSERT` already produces compressed chunks.
+
+Please note that this feature is a **tech preview** and not production-ready.
+Using this feature could lead to regressed query performance and/or storage ratio, if the ingested batches are not
+correctly ordered or are of too high cardinality.
+
+To enable in-memory data compression during ingestion:
+
+**Important facts**
+- High cardinality use cases do not produce good batches and lead to degreaded query performance.
+- The columnstore is optimized to store 1000 records per batch, which is the optimal format for ingestion per segment by.
+- WAL records are written for the compressed batches rather than the individual tuples.
+- Currently only `COPY` is support, `INSERT` will eventually follow.
+- Best results are achieved for batch ingestion with 1000 records or more, upper boundary is 10.000 records.
+- Continous Aggregates are **not** supported at the moment.
+
+1. Create a hypertable:
+
+ 1. Copy data into the hypertable:
+ You achieve the highest insert rate using binary format. CSV and text format are also supported.
+
+- **Create a Postgres relational table**:
+
+| Name | Type | Default | Required | Description |
+|--------------------------------|------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `tsdb.hypertable` |BOOLEAN| `true` | ✖ | Create a new [hypertable][hypertable-docs] for time-series data rather than a standard Postgres relational table. |
+| `tsdb.partition_column` |TEXT| `true` | ✖ | Set the time column to automatically partition your time-series data by. |
+| `tsdb.chunk_interval` |TEXT| `7 days` | ✖ | Change this to better suit your needs. For example, if you set `chunk_interval` to 1 day, each chunk stores data from the same day. Data from different days is stored in different chunks. |
+| `tsdb.create_default_indexes` | BOOLEAN | `true` | ✖ | Set to `false` to not automatically create indexes.
The default indexes are: - On all hypertables, a descending index on `partition_column`
- On hypertables with space partitions, an index on the space parameter and `partition_column`
|
+| `tsdb.associated_schema` |REGCLASS| `_timescaledb_internal` | ✖ | Set the schema name for internal hypertable tables. |
+| `tsdb.associated_table_prefix` |TEXT| `_hyper` | ✖ | Set the prefix for the names of internal hypertable chunks. |
+| `tsdb.orderby` |TEXT| Descending order on the time column in `table_name`. | ✖| The order in which items are used in the columnstore. Specified in the same way as an `ORDER BY` clause in a `SELECT` query. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. |
+| `tsdb.segmentby` |TEXT| TimescaleDB looks at [`pg_stats`](https://www.postgresql.org/docs/current/view-pg-stats.html) and determines an appropriate column based on the data cardinality and distribution. If `pg_stats` is not available, TimescaleDB looks for an appropriate column from the existing indexes. | ✖| Set the list of columns used to segment data in the columnstore for `table`. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
+|`tsdb.sparse_index`| TEXT | TimescaleDB evaluates the columns you already have indexed, checks which data types are a good fit for sparse indexing, then creates a sparse index as an optimization. | ✖ | Configure the sparse indexes for compressed chunks. Requires setting `tsdb.orderby`. Supported index types include: `bloom()`: a probabilistic index, effective for `=` filters. Cannot be applied to `tsdb.orderby` columns. `minmax()`: stores min/max values for each compressed chunk. Setting `tsdb.orderby` automatically creates an implicit min/max sparse index on the `orderby` column. Define multiple indexes using a comma-separated list. You can set only one index per column. Set to an empty string to avoid using sparse indexes and explicitly disable the default behavior. |
+
+TimescaleDB returns a simple message indicating success or failure.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/drop_chunks/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby='symbol',
+ tsdb.orderby='time DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
+```
+
+Example 3 (sql):
+```sql
+CREATE TABLE IF NOT EXISTS hypertable_control_chunk_interval(
+ time int4 NOT NULL,
+ device text,
+ value float
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.chunk_interval=3453
+ );
+```
+
+Example 4 (sql):
+```sql
+-- For optimal compression on the ID column, first enable UUIDv7 compression
+ SET enable_uuid_compression=true;
+ -- Then create your table
+ CREATE TABLE events (
+ id uuid PRIMARY KEY DEFAULT generate_uuidv7(),
+ payload jsonb
+ ) WITH (tsdb.hypertable, tsdb.partition_column = 'id');
+```
+
+---
+
+## Dropping chunks times out
+
+**URL:** llms-txt#dropping-chunks-times-out
+
+
+
+When you drop a chunk, it requires an exclusive lock. If a chunk is being
+accessed by another session, you cannot drop the chunk at the same time. If a
+drop chunk operation can't get the lock on the chunk, then it times out and the
+process fails. To resolve this problem, check what is locking the chunk. In some
+cases, this could be caused by a continuous aggregate or other process accessing
+the chunk. When the drop chunk operation can get an exclusive lock on the chunk,
+it completes as expected.
+
+For more information about locks, see the
+[Postgres lock monitoring documentation][pg-lock-monitoring].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/hypertables-unique-index-partitioning/ =====
+
+---
+
+## Create a data retention policy
+
+**URL:** llms-txt#create-a-data-retention-policy
+
+**Contents:**
+- Add a data retention policy
+ - Adding a data retention policy
+- Remove a data retention policy
+- See scheduled data retention jobs
+
+Automatically drop data once its time value ages past a certain interval. When
+you create a data retention policy, TimescaleDB automatically schedules a
+background job to drop old chunks.
+
+## Add a data retention policy
+
+Add a data retention policy by using the
+[`add_retention_policy`][add_retention_policy] function.
+
+### Adding a data retention policy
+
+1. Choose which hypertable you want to add the policy to. Decide how long
+ you want to keep data before dropping it. In this example, the hypertable
+ named `conditions` retains the data for 24 hours.
+1. Call `add_retention_policy`:
+
+A data retention policy only allows you to drop chunks based on how far they are
+in the past. To drop chunks based on how far they are in the future,
+[manually drop chunks](https://docs.tigerdata.com/use-timescale/latest/data-retention/manually-drop-chunks).
+
+## Remove a data retention policy
+
+Remove an existing data retention policy by using the
+[`remove_retention_policy`][remove_retention_policy] function. Pass it the name
+of the hypertable to remove the policy from.
+
+## See scheduled data retention jobs
+
+To see your scheduled data retention jobs and their job statistics, query the
+[`timescaledb_information.jobs`][timescaledb_information.jobs] and
+[`timescaledb_information.job_stats`][timescaledb_information.job_stats] tables.
+For example:
+
+The results look like this:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/data-retention/manually-drop-chunks/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_retention_policy('conditions', INTERVAL '24 hours');
+```
+
+Example 2 (sql):
+```sql
+SELECT remove_retention_policy('conditions');
+```
+
+Example 3 (sql):
+```sql
+SELECT j.hypertable_name,
+ j.job_id,
+ config,
+ schedule_interval,
+ job_status,
+ last_run_status,
+ last_run_started_at,
+ js.next_start,
+ total_runs,
+ total_successes,
+ total_failures
+ FROM timescaledb_information.jobs j
+ JOIN timescaledb_information.job_stats js
+ ON j.job_id = js.job_id
+ WHERE j.proc_name = 'policy_retention';
+```
+
+Example 4 (sql):
+```sql
+-[ RECORD 1 ]-------+-----------------------------------------------
+hypertable_name | conditions
+job_id | 1000
+config | {"drop_after": "5 years", "hypertable_id": 14}
+schedule_interval | 1 day
+job_status | Scheduled
+last_run_status | Success
+last_run_started_at | 2022-05-19 16:15:11.200109+00
+next_start | 2022-05-20 16:15:11.243531+00
+total_runs | 1
+total_successes | 1
+total_failures | 0
+```
+
+---
+
+## chunk_columnstore_stats()
+
+**URL:** llms-txt#chunk_columnstore_stats()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Retrieve statistics about the chunks in the columnstore
+
+`chunk_columnstore_stats` returns the size of chunks in the columnstore, these values are computed when you call either:
+- [add_columnstore_policy][add_columnstore_policy]: create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a
+ specific time interval.
+- [convert_to_columnstore][convert_to_columnstore]: manually add a specific chunk in a hypertable to the columnstore.
+
+Inserting into a chunk in the columnstore does not change the chunk size. For more information about how to compute
+chunk sizes, see [chunks_detailed_size][chunks_detailed_size].
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To retrieve statistics about chunks:
+
+- **Show the status of the first two chunks in the `conditions` hypertable**:
+
+ Returns:
+
+- **Use `pg_size_pretty` to return a more human friendly format**:
+
+| Name | Type | Default | Required | Description |
+|--|--|--|--|--|
+|`hypertable`|`REGCLASS`|-|✖| The name of a hypertable |
+
+|Column|Type| Description |
+|-|-|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|`chunk_schema`|TEXT| Schema name of the chunk. |
+|`chunk_name`|TEXT| Name of the chunk. |
+|`compression_status`|TEXT| Current compression status of the chunk. |
+|`before_compression_table_bytes`|BIGINT| Size of the heap before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_index_bytes`|BIGINT| Size of all the indexes before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_toast_bytes`|BIGINT| Size the TOAST table before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_total_bytes`|BIGINT| Size of the entire chunk table (`before_compression_table_bytes` + `before_compression_index_bytes` + `before_compression_toast_bytes`) before compression. Returns `NULL` if `compression_status` == `Uncompressed`.|
+|`after_compression_table_bytes`|BIGINT| Size of the heap after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_index_bytes`|BIGINT| Size of all the indexes after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_toast_bytes`|BIGINT| Size the TOAST table after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_total_bytes`|BIGINT| Size of the entire chunk table (`after_compression_table_bytes` + `after_compression_index_bytes `+ `after_compression_toast_bytes`) after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`node_name`|TEXT| **DEPRECATED**: nodes the chunk is located on, applicable only to distributed hypertables. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/convert_to_rowstore/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM chunk_columnstore_stats('conditions')
+ ORDER BY chunk_name LIMIT 2;
+```
+
+Example 2 (sql):
+```sql
+-[ RECORD 1 ]------------------+----------------------
+ chunk_schema | _timescaledb_internal
+ chunk_name | _hyper_1_1_chunk
+ compression_status | Uncompressed
+ before_compression_table_bytes |
+ before_compression_index_bytes |
+ before_compression_toast_bytes |
+ before_compression_total_bytes |
+ after_compression_table_bytes |
+ after_compression_index_bytes |
+ after_compression_toast_bytes |
+ after_compression_total_bytes |
+ node_name |
+ -[ RECORD 2 ]------------------+----------------------
+ chunk_schema | _timescaledb_internal
+ chunk_name | _hyper_1_2_chunk
+ compression_status | Compressed
+ before_compression_table_bytes | 8192
+ before_compression_index_bytes | 32768
+ before_compression_toast_bytes | 0
+ before_compression_total_bytes | 40960
+ after_compression_table_bytes | 8192
+ after_compression_index_bytes | 32768
+ after_compression_toast_bytes | 8192
+ after_compression_total_bytes | 49152
+ node_name |
+```
+
+Example 3 (sql):
+```sql
+SELECT pg_size_pretty(after_compression_total_bytes) AS total
+ FROM chunk_columnstore_stats('conditions')
+ WHERE compression_status = 'Compressed';
+```
+
+Example 4 (sql):
+```sql
+-[ RECORD 1 ]--+------
+ total | 48 kB
+```
+
+---
+
+## timescaledb_information.dimensions
+
+**URL:** llms-txt#timescaledb_information.dimensions
+
+**Contents:**
+- Samples
+- Available columns
+
+Returns information about the dimensions of a hypertable. Hypertables can be
+partitioned on a range of different dimensions. By default, all hypertables are
+partitioned on time, but it is also possible to partition on other dimensions in
+addition to time.
+
+For hypertables that are partitioned solely on time,
+`timescaledb_information.dimensions` returns a single row of metadata. For
+hypertables that are partitioned on more than one dimension, the call returns a
+row for each dimension.
+
+For time-based dimensions, the metadata returned indicates the integer datatype,
+such as BIGINT, INTEGER, or SMALLINT, and the time-related datatype, such as
+TIMESTAMPTZ, TIMESTAMP, or DATE. For space-based dimension, the metadata
+returned specifies the number of `num_partitions`.
+
+If the hypertable uses time data types, the `time_interval` column is defined.
+Alternatively, if the hypertable uses integer data types, the `integer_interval`
+and `integer_now_func` columns are defined.
+
+Get information about the dimensions of hypertables.
+
+The `by_range` and `by_hash` dimension builders are an addition to TimescaleDB 2.13.
+
+Get information about dimensions of a hypertable that has two time-based dimensions.
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable_schema`|TEXT|Schema name of the hypertable|
+|`hypertable_name`|TEXT|Table name of the hypertable|
+|`dimension_number`|BIGINT|Dimension number of the hypertable, starting from 1|
+|`column_name`|TEXT|Name of the column used to create this dimension|
+|`column_type`|REGTYPE|Type of the column used to create this dimension|
+|`dimension_type`|TEXT|Is this a time based or space based dimension|
+|`time_interval`|INTERVAL|Time interval for primary dimension if the column type is a time datatype|
+|`integer_interval`|BIGINT|Integer interval for primary dimension if the column type is an integer datatype|
+|`integer_now_func`|TEXT|`integer_now`` function for primary dimension if the column type is an integer datatype|
+|`num_partitions`|SMALLINT|Number of partitions for the dimension|
+
+The `time_interval` and `integer_interval` columns are not applicable for space
+based dimensions.
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/job_errors/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+-- Create a range and hash partitioned hypertable
+CREATE TABLE dist_table(time timestamptz, device int, temp float);
+SELECT create_hypertable('dist_table', by_range('time', INTERVAL '7 days'));
+SELECT add_dimension('dist_table', by_hash('device', 3));
+
+SELECT * from timescaledb_information.dimensions
+ ORDER BY hypertable_name, dimension_number;
+
+-[ RECORD 1 ]-----+-------------------------
+hypertable_schema | public
+hypertable_name | dist_table
+dimension_number | 1
+column_name | time
+column_type | timestamp with time zone
+dimension_type | Time
+time_interval | 7 days
+integer_interval |
+integer_now_func |
+num_partitions |
+-[ RECORD 2 ]-----+-------------------------
+hypertable_schema | public
+hypertable_name | dist_table
+dimension_number | 2
+column_name | device
+column_type | integer
+dimension_type | Space
+time_interval |
+integer_interval |
+integer_now_func |
+num_partitions | 2
+```
+
+---
+
+## About Tiger Cloud storage tiers
+
+**URL:** llms-txt#about-tiger-cloud-storage-tiers
+
+**Contents:**
+- High-performance storage
+- Low-cost storage
+
+The tiered storage architecture in Tiger Cloud includes a high-performance storage tier and a low-cost object storage tier. You use the high-performance tier for data that requires quick access, and the object tier for rarely used historical data. Tiering policies move older data asynchronously and periodically from high-performance to low-cost storage, sparing you the need to do it manually. Chunks from a single hypertable, including compressed chunks, can stretch across these two storage tiers.
+
+
+
+## High-performance storage
+
+High-performance storage is where your data is stored by default, until you [enable tiered storage][manage-tiering] and [move older data to the low-cost tier][move-data]. In the high-performance storage, your data is stored in the block format and optimized for frequent querying. The [hypercore row-columnar storage engine][hypercore] available in this tier is designed specifically for real-time analytics. It enables you to compress the data in the high-performance storage by up to 90%, while improving performance. Coupled with other optimizations, Tiger Cloud high-performance storage makes sure your data is always accessible and your queries run at lightning speed.
+
+Tiger Cloud high-performance storage comes in the following types:
+
+- **Standard** (default): based on [AWS EBS gp3][aws-gp3] and designed for general workloads. Provides up to 16 TB of storage and 16,000 IOPS.
+- **Enhanced**: based on [EBS io2][ebs-io2] and designed for high-scale, high-throughput workloads. Provides up to 64 TB of storage and 32,000 IOPS.
+
+[See the differences][aws-storage-types] in the underlying AWS storage. You [enable enhanced storage][enable-enhanced] as needed in Tiger Cloud Console.
+
+
+
+Once you [enable tiered storage][manage-tiering], you can start moving rarely used data to the object tier. The object tier is based on AWS S3 and stores your data in the [Apache Parquet][parquet] format. Within a Parquet file, a set of rows is grouped together to form a row group. Within a row group, values for a single column across multiple rows are stored together. The original size of the data in your service, compressed or uncompressed, does not correspond directly to its size in S3. A compressed hypertable may even take more space in S3 than it does in Tiger Cloud.
+
+Apache Parquet allows for more efficient scans across longer time periods, and Tiger Cloud uses other metadata and query optimizations to reduce the amount of data that needs to be fetched to satisfy a query, such as:
+
+- **Chunk skipping**: exclude the chunks that fall outside the query time window.
+- **Row group skipping**: identify the row groups within the Parquet object that satisfy the query.
+- **Column skipping**: fetch only columns that are requested by the query.
+
+The following query is against a tiered dataset and illustrates the optimizations:
+
+`EXPLAIN` illustrates which chunks are being pulled in from the object storage tier:
+
+1. Fetch data from chunks 42, 43, and 44 from the object storage tier.
+1. Skip row groups and limit the fetch to a subset of the offsets in the
+ Parquet object that potentially match the query filter. Only fetch the data
+ for `device_uuid`, `sensor_id`, and `observed_at` as the query needs only these 3 columns.
+
+The object storage tier is more than an archiving solution. It is also:
+
+- **Cost-effective:** store high volumes of data at a lower cost. You pay only for what you store, with no extra cost for queries.
+- **Scalable:** scale past the restrictions of even the enhanced high-performance storage tier.
+- **Online:** your data is always there and can be [queried when needed][querying-tiered-data].
+
+By default, tiered data is not included when you query from a Tiger Cloud service. To access tiered data, you [enable tiered reads][querying-tiered-data] for a query, a session, or even for all sessions. After you enable tiered reads, when you run regular SQL queries, a behind-the-scenes process transparently pulls data from wherever it's located: the standard high-performance storage tier, the object storage tier, or both. You can `JOIN` against tiered data, build views, and even define continuous aggregates on it. In fact, because the implementation of continuous aggregates also uses hypertables, they can be tiered to low-cost storage as well.
+
+For low-cost storage, Tiger Data charges only for the size of your data in S3 in the Apache Parquet format, regardless of whether it was compressed in Tiger Cloud before tiering. There are no additional expenses, such as data transfer or compute.
+
+The low-cost storage tier comes with the following limitations:
+
+- **Limited schema modifications**: some schema modifications are not allowed
+ on hypertables with tiered chunks.
+
+_Allowed_ modifications include: renaming the hypertable, adding columns
+ with `NULL` defaults, adding indexes, changing or renaming the hypertable
+ schema, and adding `CHECK` constraints. For `CHECK` constraints, only
+ untiered data is verified.
+ Columns can also be deleted, but you cannot subsequently add a new column
+ to a tiered hypertable with the same name as the now-deleted column.
+
+_Disallowed_ modifications include: adding a column with non-`NULL`
+ defaults, renaming a column, changing the data type of a
+ column, and adding a `NOT NULL` constraint to the column.
+
+- **Limited data changes**: you cannot insert data into, update, or delete a
+ tiered chunk. These limitations take effect as soon as the chunk is
+ scheduled for tiering.
+
+- **Inefficient query planner filtering for non-native data types**: the query
+ planner speeds up reads from our object storage tier by using metadata
+ to filter out columns and row groups that don't satisfy the query. This works for all
+ native data types, but not for non-native types, such as `JSON`, `JSONB`,
+ and `GIS`.
+
+* **Latency**: S3 has higher access latency than local storage. This can affect the
+ execution time of queries in latency-sensitive environments, especially
+ lighter queries.
+
+* **Number of dimensions**: you cannot use tiered storage with hypertables
+ partitioned on more than one dimension. Make sure your hypertables are
+ partitioned on time only, before you enable tiered storage.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/security/overview/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+EXPLAIN ANALYZE
+SELECT count(*) FROM
+( SELECT device_uuid, sensor_id FROM public.device_readings
+ WHERE observed_at > '2023-08-28 00:00+00' and observed_at < '2023-08-29 00:00+00'
+ GROUP BY device_uuid, sensor_id ) q;
+ QUERY PLAN
+
+-------------------------------------------------------------------------------------------------
+ Aggregate (cost=7277226.78..7277226.79 rows=1 width=8) (actual time=234993.749..234993.750 rows=1 loops=1)
+ -> HashAggregate (cost=4929031.23..7177226.78 rows=8000000 width=68) (actual time=184256.546..234913.067 rows=1651523 loops=1)
+ Group Key: osm_chunk_1.device_uuid, osm_chunk_1.sensor_id
+ Planned Partitions: 128 Batches: 129 Memory Usage: 20497kB Disk Usage: 4429832kB
+ -> Foreign Scan on osm_chunk_1 (cost=0.00..0.00 rows=92509677 width=68) (actual time=345.890..128688.459 rows=92505457 loops=1)
+ Filter: ((observed_at > '2023-08-28 00:00:00+00'::timestamp with time zone) AND (observed_at < '2023-08-29 00:00:00+00'::timestamp with t
+ime zone))
+ Rows Removed by Filter: 4220
+ Match tiered objects: 3
+ Row Groups:
+ _timescaledb_internal._hyper_1_42_chunk: 0-74
+ _timescaledb_internal._hyper_1_43_chunk: 0-29
+ _timescaledb_internal._hyper_1_44_chunk: 0-71
+ S3 requests: 177
+ S3 data: 224423195 bytes
+ Planning Time: 6.216 ms
+ Execution Time: 235372.223 ms
+(16 rows)
+```
+
+---
+
+## Create a continuous aggregate
+
+**URL:** llms-txt#create-a-continuous-aggregate
+
+**Contents:**
+- Create a continuous aggregate
+ - Creating a continuous aggregate
+- Choosing an appropriate bucket interval
+- Using the WITH NO DATA option
+ - Creating a continuous aggregate with the WITH NO DATA option
+- Create a continuous aggregate with a JOIN
+- Query continuous aggregates
+ - Querying a continuous aggregate
+- Use continuous aggregates with mutable functions: experimental
+- Use continuous aggregates with window functions: experimental
+
+Creating a continuous aggregate is a two-step process. You need to create the
+view first, then enable a policy to keep the view refreshed. You can create the
+view on a hypertable, or on top of another continuous aggregate. You can have
+more than one continuous aggregate on each source table or view.
+
+Continuous aggregates require a `time_bucket` on the time partitioning column of
+the hypertable.
+
+By default, views are automatically refreshed. You can adjust this by setting
+the [WITH NO DATA](#using-the-with-no-data-option) option. Additionally, the
+view can not be a [security barrier view][postgres-security-barrier].
+
+Continuous aggregates use hypertables in the background, which means that they
+also use chunk time intervals. By default, the continuous aggregate's chunk time
+interval is 10 times what the original hypertable's chunk time interval is. For
+example, if the original hypertable's chunk time interval is 7 days, the
+continuous aggregates that are on top of it have a 70 day chunk time
+interval.
+
+## Create a continuous aggregate
+
+In this example, we are using a hypertable called `conditions`, and creating a
+continuous aggregate view for daily weather data. The `GROUP BY` clause must
+include a `time_bucket` expression which uses time dimension column of the
+hypertable. Additionally, all functions and their arguments included in
+`SELECT`, `GROUP BY`, and `HAVING` clauses must be
+[immutable][postgres-immutable].
+
+### Creating a continuous aggregate
+
+1. At the `psql`prompt, create the materialized view:
+
+To create a continuous aggregate within a transaction block, use the [WITH NO DATA option][with-no-data].
+
+To improve continuous aggregate performance, [set `timescaledb.invalidate_using = 'wal'`][create_materialized_view] Since [TimescaleDB v2.22.0](https://github.com/timescale/timescaledb/releases/tag/2.22.0).
+
+1. Create a policy to refresh the view every hour:
+
+You can use most Postgres aggregate functions in continuous aggregations. To
+see what Postgres features are supported, check the
+[function support table][cagg-function-support].
+
+## Choosing an appropriate bucket interval
+
+Continuous aggregates require a `time_bucket` on the time partitioning column of
+the hypertable. The time bucket allows you to define a time interval, instead of
+having to use specific timestamps. For example, you can define a time bucket as
+five minutes, or one day.
+
+You can't use [time_bucket_gapfill][api-time-bucket-gapfill] directly in a
+continuous aggregate. This is because you need access to previous data to
+determine the gapfill content, which isn't yet available when you create the
+continuous aggregate. You can work around this by creating the continuous
+aggregate using [`time_bucket`][api-time-bucket], then querying the continuous
+aggregate using `time_bucket_gapfill`.
+
+## Using the WITH NO DATA option
+
+By default, when you create a view for the first time, it is populated with
+data. This is so that the aggregates can be computed across the entire
+hypertable. If you don't want this to happen, for example if the table is very
+large, or if new data is being continuously added, you can control the order in
+which the data is refreshed. You can do this by adding a manual refresh with
+your continuous aggregate policy using the `WITH NO DATA` option.
+
+The `WITH NO DATA` option allows the continuous aggregate to be created
+instantly, so you don't have to wait for the data to be aggregated. Data begins
+to populate only when the policy begins to run. This means that only data newer
+than the `start_offset` time begins to populate the continuous aggregate. If you
+have historical data that is older than the `start_offset` interval, you need to
+manually refresh the history up to the current `start_offset` to allow real-time
+queries to run efficiently.
+
+### Creating a continuous aggregate with the WITH NO DATA option
+
+1. At the `psql` prompt, create the view:
+
+1. Manually refresh the view:
+
+## Create a continuous aggregate with a JOIN
+
+In TimescaleDB V2.10 and later, with Postgres v12 or later, you can
+create a continuous aggregate with a query that also includes a `JOIN`. For
+example:
+
+For more information about creating a continuous aggregate with a `JOIN`,
+including some additional restrictions, see the
+[about continuous aggregates section](https://docs.tigerdata.com/use-timescale/latest/continuous-aggregates/about-continuous-aggregates/#continuous-aggregates-with-a-join-clause).
+
+## Query continuous aggregates
+
+When you have created a continuous aggregate and set a refresh policy, you can
+query the view with a `SELECT` query. You can only specify a single hypertable
+in the `FROM` clause. Including more hypertables, tables, views, or subqueries
+in your `SELECT` query is not supported. Additionally, make sure that the
+hypertable you are querying does not have
+[row-level-security policies][postgres-rls]
+enabled.
+
+### Querying a continuous aggregate
+
+1. At the `psql` prompt, query the continuous aggregate view called
+ `conditions_summary_hourly` for the average, minimum, and maximum
+ temperatures for the first quarter of 2021 recorded by device 5:
+
+1. Alternatively, query the continuous aggregate view called
+ `conditions_summary_hourly` for the top 20 largest metric spreads in that
+ quarter:
+
+## Use continuous aggregates with mutable functions: experimental
+
+Mutable functions have experimental supported in the continuous aggregate query definition. Mutable functions are enabled
+by default. However, if you use them in a materialized query a warning is returned.
+
+When using non-immutable functions you have to ensure these functions produce consistent results across
+continuous aggregate refresh runs. For example, if a function depends on the current time zone you have
+to ensure all your continuous aggregate refreshes run with a consistent setting for this.
+
+## Use continuous aggregates with window functions: experimental
+
+Window functions have experimental supported in the continuous aggregate query definition. Window functions are disabled
+ by default. To enable them, set `timescaledb.enable_cagg_window_functions` to `true`.
+
+Support is experimental, there is a risk of data inconsistency. For example, in backfill scenarios, buckets could be missed.
+
+### Create a window function
+
+To use a window function in a continuous aggregate:
+
+1. Create a simple table with to store a value at a specific time:
+
+1. Enable window functions.
+
+As window functions are experimental, in order to create continuous aggregates with window functions.
+ you have to `enable_cagg_window_functions`.
+
+1. Bucket your data by `time` and calculate the delta between time buckets using the `lag` window function:
+
+Window functions must stay within the time bucket. Any query that tries to look beyond the current
+ time bucket will produce incorrect results around the refresh boundaries.
+
+ Window functions that partition by time_bucket should be safe even with LAG()/LEAD()
+
+### Window function workaround for older versions of TimescaleDB
+
+For TimescaleDB v2.19.3 and below, continuous aggregates do not support window functions. To work around this:
+
+1. Create a simple table with to store a value at a specific time:
+
+1. Create a continuous aggregate that does not use a window function:
+
+1. Use the `lag` window function on your continuous aggregate at query time:
+
+This speeds up your query by calculating the aggregation ahead of time. The
+ delta is calculated at query time.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/hierarchical-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE MATERIALIZED VIEW conditions_summary_daily
+ WITH (timescaledb.continuous) AS
+ SELECT device,
+ time_bucket(INTERVAL '1 day', time) AS bucket,
+ AVG(temperature),
+ MAX(temperature),
+ MIN(temperature)
+ FROM conditions
+ GROUP BY device, bucket;
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('conditions_summary_daily',
+ start_offset => INTERVAL '1 month',
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+Example 3 (sql):
+```sql
+CREATE MATERIALIZED VIEW cagg_rides_view
+ WITH (timescaledb.continuous) AS
+ SELECT vendor_id,
+ time_bucket('1h', pickup_datetime) AS hour,
+ count(*) total_rides,
+ avg(fare_amount) avg_fare,
+ max(trip_distance) as max_trip_distance,
+ min(trip_distance) as min_trip_distance
+ FROM rides
+ GROUP BY vendor_id, time_bucket('1h', pickup_datetime)
+ WITH NO DATA;
+```
+
+Example 4 (sql):
+```sql
+CALL refresh_continuous_aggregate('cagg_rides_view', NULL, localtimestamp - INTERVAL '1 week');
+```
+
+---
+
+## ALTER TABLE (hypercore)
+
+**URL:** llms-txt#alter-table-(hypercore)
+
+**Contents:**
+- Samples
+- Arguments
+
+Enable the columnstore or change the columnstore settings for a hypertable. The settings are applied on a per-chunk basis. You do not need to convert the entire hypertable back to the rowstore before changing the settings. The new settings apply only to the chunks that have not yet been converted to columnstore, the existing chunks in the columnstore do not change. This means that chunks with different columnstore settings can co-exist in the same hypertable.
+
+TimescaleDB calculates default columnstore settings for each chunk when it is created. These settings apply to each chunk, and not the entire hypertable. To explicitly disable the defaults, set a setting to an empty string. To remove the current configuration and re-enable the defaults, call `ALTER TABLE RESET ();`.
+
+After you have enabled the columnstore, either:
+- [add_columnstore_policy][add_columnstore_policy]: create a [job][job] that automatically moves chunks in a hypertable to the columnstore at a
+ specific time interval.
+- [convert_to_columnstore][convert_to_columnstore]: manually add a specific chunk in a hypertable to the columnstore.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To enable the columnstore:
+
+- **Configure a hypertable that ingests device data to use the columnstore**:
+
+In this example, the `metrics` hypertable is often queried about a specific device or set of devices.
+ Segment the hypertable by `device_id` to improve query performance.
+
+- **Specify the chunk interval without changing other columnstore settings**:
+
+- Set the time interval when chunks are added to the columnstore:
+
+- To disable the option you set previously, set the interval to 0:
+
+| Name | Type | Default | Required | Description |
+|-------|---------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------|--------------|
+| `table_name` | TEXT | - | ✖ | The hypertable to enable columstore for. |
+| `timescaledb.enable_columnstore` | BOOLEAN | `true` | ✖ | Set to `false` to disable columnstore. |
+| `timescaledb.compress_orderby` | TEXT | Descending order on the time column in `table_name`. | ✖ | The order in which items are used in the columnstore. Specified in the same way as an `ORDER BY` clause in a `SELECT` query. Setting `timescaledb.compress_orderby` automatically creates an implicit min/max sparse index on the `orderby` column. |
+| `timescaledb.compress_segmentby` | TEXT | TimescaleDB looks at [`pg_stats`](https://www.postgresql.org/docs/current/view-pg-stats.html) and determines an appropriate column based on the data cardinality and distribution. If `pg_stats` is not available, TimescaleDB looks for an appropriate column from the existing indexes. | ✖ | Set the list of columns used to segment data in the columnstore for `table`. An identifier representing the source of the data such as `device_id` or `tags_id` is usually a good candidate. |
+| `column_name` | TEXT | - | ✖ | The name of the column to `orderby` or `segmentby`. |
+|`timescaledb.sparse_index`| TEXT | TimescaleDB evaluates the columns you already have indexed, checks which data types are a good fit for sparse indexing, then creates a sparse index as an optimization. | ✖ | Configure the sparse indexes for compressed chunks. Requires setting `timescaledb.compress_orderby`. Supported index types include: `bloom()`: a probabilistic index, effective for `=` filters. Cannot be applied to `timescaledb.compress_orderby` columns. `minmax()`: stores min/max values for each compressed chunk. Setting `timescaledb.compress_orderby` automatically creates an implicit min/max sparse index on the `orderby` column. Define multiple indexes using a comma-separated list. You can set only one index per column. Set to an empty string to avoid using sparse indexes and explicitly disable the default behavior. To remove the current sparse index configuration and re-enable default sparse index selection, call `ALTER TABLE your_table_name RESET (timescaledb.sparse_index);`. |
+| `timescaledb.compress_chunk_time_interval` | TEXT | - | ✖ | EXPERIMENTAL: reduce the total number of chunks in the columnstore for `table`. If you set `compress_chunk_time_interval`, chunks added to the columnstore are merged with the previous adjacent chunk within `chunk_time_interval` whenever possible. These chunks are irreversibly merged. If you call [convert_to_rowstore][convert_to_rowstore], merged chunks are not split up. You can call `compress_chunk_time_interval` independently of other compression settings; `timescaledb.enable_columnstore` is not required. |
+| `interval` | TEXT | - | ✖ | Set to a multiple of the [chunk_time_interval][chunk_time_interval] for `table`. |
+| `ALTER` | TEXT | | ✖ | Set a specific column in the columnstore to be `NOT NULL`. |
+| `ADD CONSTRAINT` | TEXT | | ✖ | Add `UNIQUE` constraints to data in the columnstore. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/chunk_columnstore_stats/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER TABLE metrics SET(
+ timescaledb.enable_columnstore,
+ timescaledb.orderby = 'time DESC',
+ timescaledb.segmentby = 'device_id');
+```
+
+Example 2 (sql):
+```sql
+ALTER TABLE metrics SET (timescaledb.compress_chunk_time_interval = '24 hours');
+```
+
+Example 3 (sql):
+```sql
+ALTER TABLE metrics SET (timescaledb.compress_chunk_time_interval = '0');
+```
+
+---
+
+## chunk_compression_stats()
+
+**URL:** llms-txt#chunk_compression_stats()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by chunk_columnstore_stats().
+
+Get chunk-specific statistics related to hypertable compression.
+All sizes are in bytes.
+
+This function shows the compressed size of chunks, computed when the
+`compress_chunk` is manually executed, or when a compression policy processes
+the chunk. An insert into a compressed chunk does not update the compressed
+sizes. For more information about how to compute chunk sizes, see the
+`chunks_detailed_size` section.
+
+Use `pg_size_pretty` get the output in a more human friendly format.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Name of the hypertable|
+
+|Column|Type|Description|
+|-|-|-|
+|`chunk_schema`|TEXT|Schema name of the chunk|
+|`chunk_name`|TEXT|Name of the chunk|
+|`compression_status`|TEXT|the current compression status of the chunk|
+|`before_compression_table_bytes`|BIGINT|Size of the heap before compression (NULL if currently uncompressed)|
+|`before_compression_index_bytes`|BIGINT|Size of all the indexes before compression (NULL if currently uncompressed)|
+|`before_compression_toast_bytes`|BIGINT|Size the TOAST table before compression (NULL if currently uncompressed)|
+|`before_compression_total_bytes`|BIGINT|Size of the entire chunk table (table+indexes+toast) before compression (NULL if currently uncompressed)|
+|`after_compression_table_bytes`|BIGINT|Size of the heap after compression (NULL if currently uncompressed)|
+|`after_compression_index_bytes`|BIGINT|Size of all the indexes after compression (NULL if currently uncompressed)|
+|`after_compression_toast_bytes`|BIGINT|Size the TOAST table after compression (NULL if currently uncompressed)|
+|`after_compression_total_bytes`|BIGINT|Size of the entire chunk table (table+indexes+toast) after compression (NULL if currently uncompressed)|
+|`node_name`|TEXT|nodes on which the chunk is located, applicable only to distributed hypertables|
+
+===== PAGE: https://docs.tigerdata.com/api/compression/add_compression_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM chunk_compression_stats('conditions')
+ ORDER BY chunk_name LIMIT 2;
+
+-[ RECORD 1 ]------------------+----------------------
+chunk_schema | _timescaledb_internal
+chunk_name | _hyper_1_1_chunk
+compression_status | Uncompressed
+before_compression_table_bytes |
+before_compression_index_bytes |
+before_compression_toast_bytes |
+before_compression_total_bytes |
+after_compression_table_bytes |
+after_compression_index_bytes |
+after_compression_toast_bytes |
+after_compression_total_bytes |
+node_name |
+-[ RECORD 2 ]------------------+----------------------
+chunk_schema | _timescaledb_internal
+chunk_name | _hyper_1_2_chunk
+compression_status | Compressed
+before_compression_table_bytes | 8192
+before_compression_index_bytes | 32768
+before_compression_toast_bytes | 0
+before_compression_total_bytes | 40960
+after_compression_table_bytes | 8192
+after_compression_index_bytes | 32768
+after_compression_toast_bytes | 8192
+after_compression_total_bytes | 49152
+node_name |
+```
+
+Example 2 (sql):
+```sql
+SELECT pg_size_pretty(after_compression_total_bytes) AS total
+ FROM chunk_compression_stats('conditions')
+ WHERE compression_status = 'Compressed';
+
+-[ RECORD 1 ]--+------
+total | 48 kB
+```
+
+---
+
+## Inefficient `compress_chunk_time_interval` configuration
+
+**URL:** llms-txt#inefficient-`compress_chunk_time_interval`-configuration
+
+When you configure `compress_chunk_time_interval` but do not set the primary dimension as the first column in `compress_orderby`, TimescaleDB decompresses chunks before merging. This makes merging less efficient. Set the primary dimension of the chunk as the first column in `compress_orderby` to improve efficiency.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/cloud-jdbc-authentication-support/ =====
+
+---
+
+## convert_to_rowstore()
+
+**URL:** llms-txt#convert_to_rowstore()
+
+**Contents:**
+- Samples
+- Arguments
+
+Manually convert a specific chunk in the hypertable columnstore to the rowstore.
+
+If you need to modify or add a lot of data to a chunk in the columnstore, best practice is to stop
+any [jobs][job] moving chunks to the columnstore, convert the chunk back to the rowstore, then modify the
+data. After the update, [convert the chunk to the columnstore][convert_to_columnstore] and restart the jobs.
+This workflow is especially useful if you need to backfill old data.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To modify or add a lot of data to a chunk:
+
+1. **Stop the jobs that are automatically adding chunks to the columnstore**
+
+Retrieve the list of jobs from the [timescaledb_information.jobs][informational-views] view
+ to find the job you need to [alter_job][alter_job].
+
+1. **Convert a chunk to update back to the rowstore**
+
+1. **Update the data in the chunk you added to the rowstore**
+
+Best practice is to structure your [INSERT][insert] statement to include appropriate
+ partition key values, such as the timestamp. TimescaleDB adds the data to the correct chunk:
+
+1. **Convert the updated chunks back to the columnstore**
+
+1. **Restart the jobs that are automatically converting chunks to the columnstore**
+
+| Name | Type | Default | Required | Description|
+|--|----------|---------|----------|-|
+|`chunk`| REGCLASS | - | ✖ | Name of the chunk to be moved to the rowstore. |
+|`if_compressed`| BOOLEAN | `true` | ✔ | Set to `false` so this job fails with an error rather than an warning if `chunk` is not in the columnstore |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/hypertable_columnstore_stats/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+1. **Convert a chunk to update back to the rowstore**
+```
+
+Example 2 (unknown):
+```unknown
+1. **Update the data in the chunk you added to the rowstore**
+
+ Best practice is to structure your [INSERT][insert] statement to include appropriate
+ partition key values, such as the timestamp. TimescaleDB adds the data to the correct chunk:
+```
+
+Example 3 (unknown):
+```unknown
+1. **Convert the updated chunks back to the columnstore**
+```
+
+Example 4 (unknown):
+```unknown
+1. **Restart the jobs that are automatically converting chunks to the columnstore**
+```
+
+---
+
+## About compression
+
+**URL:** llms-txt#about-compression
+
+**Contents:**
+- Key aspects of compression
+ - Ordering and segmenting.
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by hypercore.
+
+Compressing your time-series data allows you to reduce your chunk size by more
+than 90%. This saves on storage costs, and keeps your queries operating at
+lightning speed.
+
+When you enable compression, the data in your hypertable is compressed chunk by
+chunk. When the chunk is compressed, multiple records are grouped into a single
+row. The columns of this row hold an array-like structure that stores all the
+data. This means that instead of using lots of rows to store the data, it stores
+the same data in a single row. Because a single row takes up less disk space
+than many rows, it decreases the amount of disk space required, and can also
+speed up your queries.
+
+For example, if you had a table with data that looked a bit like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|12:00:01|A|SSD|70.11|13.4|
+|12:00:01|B|HDD|69.70|20.5|
+|12:00:02|A|SSD|70.12|13.2|
+|12:00:02|B|HDD|69.69|23.4|
+|12:00:03|A|SSD|70.14|13.0|
+|12:00:03|B|HDD|69.70|25.2|
+
+You can convert this to a single row in array form, like this:
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|-|
+|[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[SSD, HDD, SSD, HDD, SSD, HDD]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|[13.4, 20.5, 13.2, 23.4, 13.0, 25.2]|
+
+This section explains how to enable native compression, and then goes into
+detail on the most important settings for compression, to help you get the
+best possible compression ratio.
+
+## Key aspects of compression
+
+Every table has a different schema but they do share some commonalities that you need to think about.
+
+Consider the table `metrics` with the following attributes:
+
+|Column|Type|Collation|Nullable|Default|
+|-|-|-|-|-|
+ time|timestamp with time zone|| not null|
+ device_id| integer|| not null|
+ device_type| integer|| not null|
+ cpu| double precision|||
+ disk_io| double precision|||
+
+All hypertables have a primary dimension which is used to partition the table into chunks. The primary dimension is given when [the hypertable is created][hypertable-create-table]. In the example below, you can see a classic time-series use case with a `time` column as the primary dimension. In addition, there are two columns `cpu` and `disk_io` containing the values that are captured over time, and a column `device_id` for the device that captured the values.
+Columns can be used in a few different ways:
+- You can use values in a column as a lookup key, in the example above `device_id` is a typical example of such a column.
+- You can use a column for partitioning a table. This is typically a time column like `time` in the example above, but it is possible to partition the table using other types as well.
+- You can use a column as a filter to narrow down on what data you select. The column `device_type` is an example of where you can decide to look at, for example, only solid state drives (SSDs).
+The remaining columns are typically the values or metrics you are collecting. These are typically aggregated or presented in other ways. The columns `cpu` and `disk_io` are typical examples of such columns.
+
+= now() - ‘1 day’::interval;
+`} />
+
+When chunks are compressed in a hypertable, data stored in them is reorganized and stored in column-order rather than row-order. As a result, it is not possible to use the same uncompressed schema version of the chunk and a different schema must be created. This is automatically handled by TimescaleDB, but it has a few implications:
+The compression ratio and query performance is very dependent on the order and structure of the compressed data, so some considerations are needed when setting up compression.
+Indexes on the hypertable cannot always be used in the same manner for the compressed data.
+
+Indexes set on the hypertable are used only on chunks containing uncompressed
+data. TimescaleDB creates and uses custom indexes to incorporate the `segmentby`
+and `orderby` parameters during compression which are used when reading compressed data.
+More on this in the next section.
+
+Based on the previous schema, filtering of data should happen over a certain time period and analytics are done on device granularity. This pattern of data access lends itself to organizing the data layout suitable for compression.
+
+### Ordering and segmenting.
+
+Ordering the data will have a great impact on the compression ratio and performance of your queries. Rows that change over a dimension should be close to each other. Since we are mostly dealing with time-series data, time dimension is a great candidate. Most of the time data changes in a predictable fashion, following a certain trend. We can exploit this fact to encode the data so it takes less space to store. For example, if you order the records over time, they will get compressed in that order and subsequently also accessed in the same order.
+
+Using the following configuration setup on our example table:
+
+
+would produce the following data layout.
+
+|Timestamp|Device ID|Device Type|CPU|Disk IO|
+|-|-|-|-|
+|[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[SSD, HDD, SSD, HDD, SSD, HDD]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|[13.4, 20.5, 13.2, 23.4, 13.0, 25.2]|
+
+`time` column is used for ordering data, which makes filtering it using `time` column much more efficient.
+
+= '2024-03-01 00:00:00+01' and time < '2024-03-02 00:00:00+01';
+ avg
+--------------------
+ 0.4996848437842719
+(1 row)
+Time: 87,218 ms
+postgres=# ALTER TABLE metrics
+SET (
+ timescaledb.compress,
+ timescaledb.compress_segmentby = 'device_id',
+ timescaledb.compress_orderby='time'
+);
+ALTER TABLE
+Time: 6,607 ms
+postgres=# SELECT compress_chunk(c) FROM show_chunks('metrics') c;
+ compress_chunk
+----------------------------------------
+ _timescaledb_internal._hyper_2_4_chunk
+ _timescaledb_internal._hyper_2_5_chunk
+ _timescaledb_internal._hyper_2_6_chunk
+(3 rows)
+Time: 3070,626 ms (00:03,071)
+postgres=# select avg(cpu) from metrics where time >= '2024-03-01 00:00:00+01' and time < '2024-03-02 00:00:00+01';
+ avg
+------------------
+ 0.49968484378427
+(1 row)
+Time: 45,384 ms
+`} />
+
+This makes the time column a perfect candidate for ordering your data since the measurements evolve as time goes on. If you were to use that as your only compression setting, you would most likely get a good enough compression ratio to save a lot of storage. However, accessing the data effectively depends on your use case and your queries. With this setup, you would always have to access the data by using the time dimension and subsequently filter all the rows based on any other criteria.
+
+Segmenting the compressed data should be based on the way you access the data. Basically, you want to segment your data in such a way that you can make it easier for your queries to fetch the right data at the right time. That is to say, your queries should dictate how you segment the data so they can be optimized and yield even better query performance.
+
+For example, If you want to access a single device using a specific `device_id` value (either all records or maybe for a specific time range), you would need to filter all those records one by one during row access time. To get around this, you can use device_id column for segmenting. This would allow you to run analytical queries on compressed data much faster if you are looking for specific device IDs.
+
+Consider the following query:
+
+
+
+As you can see, the query does a lot of work based on the `device_id` identifier by grouping all its values together. We can use this fact to speed up these types of queries by setting
+up compression to segment the data around the values in this column.
+
+Using the following configuration setup on our example table:
+
+
+would produce the following data layout.
+
+|time|device_id|device_type|cpu|disk_io|energy_consumption|
+|---|---|---|---|---|---|
+|[12:00:02, 12:00:01]|1|[SSD,SSD]|[88.2, 88.6]|[20, 25]|[0.8, 0.85]|
+|[12:00:02, 12:00:01]|2|[HDD,HDD]|[300.5, 299.1]|[30, 40]|[0.9, 0.95]|
+|...|...|...|...|...|...|
+
+Segmenting column `device_id` is used for grouping data points together based on the value of that column. This makes accessing a specific device much more efficient.
+
+
+
+Number of rows that are compressed together in a single batch (like the ones we see above) is 1000.
+If your chunk does not contain enough data to create big enough batches, your compression ratio will be reduced.
+This needs to be taken into account when defining your compression settings.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/compression-design/ =====
+
+---
+
+## Temporary file size limit exceeded when converting chunks to the columnstore
+
+**URL:** llms-txt#temporary-file-size-limit-exceeded-when-converting-chunks-to-the-columnstore
+
+
+
+When you try to convert a chunk to the columnstore, especially if the chunk is very large, you
+could get this error. Compression operations write files to a new compressed
+chunk table, which is written in temporary memory. The maximum amount of
+temporary memory available is determined by the `temp_file_limit` parameter. You
+can work around this problem by adjusting the `temp_file_limit` and
+`maintenance_work_mem` parameters.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/slow-tiering-chunks/ =====
+
+---
+
+## hypertable_index_size()
+
+**URL:** llms-txt#hypertable_index_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get the disk space used by an index on a hypertable, including the
+disk space needed to provide the index on all chunks. The size is
+reported in bytes.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get size of a specific index on a hypertable.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`index_name`|REGCLASS|Name of the index on a hypertable|
+
+|Column|Type|Description|
+|-|-|-|
+|hypertable_index_size|BIGINT|Returns the disk space used by the index|
+
+NULL is returned if the function is executed on a non-hypertable relation.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/enable_chunk_skipping/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+\d conditions_table
+ Table "public.conditions_table"
+ Column | Type | Collation | Nullable | Default
+--------+--------------------------+-----------+----------+---------
+ time | timestamp with time zone | | not null |
+ device | integer | | |
+ volume | integer | | |
+Indexes:
+ "second_index" btree ("time")
+ "test_table_time_idx" btree ("time" DESC)
+ "third_index" btree ("time")
+
+SELECT hypertable_index_size('second_index');
+
+ hypertable_index_size
+-----------------------
+ 163840
+
+SELECT pg_size_pretty(hypertable_index_size('second_index'));
+
+ pg_size_pretty
+----------------
+ 160 kB
+```
+
+---
+
+## approximate_row_count()
+
+**URL:** llms-txt#approximate_row_count()
+
+**Contents:**
+ - Samples
+ - Required arguments
+
+Get approximate row count for hypertable, distributed hypertable, or regular Postgres table based on catalog estimates.
+This function supports tables with nested inheritance and declarative partitioning.
+
+The accuracy of `approximate_row_count` depends on the database having up-to-date statistics about the table or hypertable, which are updated by `VACUUM`, `ANALYZE`, and a few DDL commands. If you have auto-vacuum configured on your table or hypertable, or changes to the table are relatively infrequent, you might not need to explicitly `ANALYZE` your table as shown below. Otherwise, if your table statistics are too out-of-date, running this command updates your statistics and yields more accurate approximation results.
+
+Get the approximate row count for a single hypertable.
+
+### Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `relation` | REGCLASS | Hypertable or regular Postgres table to get row count for. |
+
+===== PAGE: https://docs.tigerdata.com/api/first/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ANALYZE conditions;
+
+SELECT * FROM approximate_row_count('conditions');
+```
+
+Example 2 (unknown):
+```unknown
+approximate_row_count
+----------------------
+ 240000
+```
+
+---
+
+## Improve hypertable and query performance
+
+**URL:** llms-txt#improve-hypertable-and-query-performance
+
+**Contents:**
+- Optimize hypertable chunk intervals
+- Enable chunk skipping
+ - How chunk skipping works
+ - When to enable chunk skipping
+ - Enable chunk skipping
+- Analyze your hypertables
+
+Hypertables are Postgres tables that help you improve insert and query performance by automatically partitioning
+your data by time. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range of time,
+and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and runs
+the query on it, instead of going through the entire table. This page shows you how to tune hypertables to increase
+performance even more.
+
+* [Optimize hypertable chunk intervals][chunk-intervals]: choose the optimum chunk size for your data
+* [Enable chunk skipping][chunk-skipping]: skip chunks on non-partitioning columns in hypertables when you query your data
+* [Analyze your hypertables][analyze-hypertables]: use Postgres `ANALYZE` to create the best query plan
+
+## Optimize hypertable chunk intervals
+
+Adjusting your hypertable chunk interval can improve performance in your database.
+
+1. **Choose an optimum chunk interval**
+
+Postgres builds the index on the fly during ingestion. That means that to build a new entry on the index,
+a significant portion of the index needs to be traversed during every row insertion. When the index does not fit
+into memory, it is constantly flushed to disk and read back. This wastes IO resources which would otherwise
+be used for writing the heap/WAL data to disk.
+
+The default chunk interval is 7 days. However, best practice is to set `chunk_interval` so that prior to processing,
+the indexes for chunks currently being ingested into fit within 25% of main memory. For example, on a system with 64
+GB of memory, if index growth is approximately 2 GB per day, a 1-week chunk interval is appropriate. If index growth is
+around 10 GB per day, use a 1-day interval.
+
+You set `chunk_interval` when you [create a hypertable][hypertable-create-table], or by calling
+[`set_chunk_time_interval`][chunk_interval] on an existing hypertable.
+
+In the following example you create a table called `conditions` that stores time values in the
+ `time` column and has chunks that store data for a `chunk_interval` of one day:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+1. **Check current setting for chunk intervals**
+
+Query the TimescaleDB catalog for a hypertable. For example:
+
+The result looks like:
+
+Time-based interval lengths are reported in microseconds.
+
+1. **Change the chunk interval length on an existing hypertable**
+
+To change the chunk interval on an already existing hypertable, call `set_chunk_time_interval`.
+
+The updated chunk interval only applies to new chunks. This means setting an overly long
+ interval might take a long time to correct. For example, if you set
+ `chunk_interval` to 1 year and start inserting data, you can no longer
+ shorten the chunk for that year. If you need to correct this situation, create a
+ new hypertable and migrate your data.
+
+While chunk turnover does not degrade performance, chunk creation
+ does take longer lock time than a normal `INSERT` operation into a chunk that has
+ already been created. This means that if multiple chunks are being created at
+ the same time, the transactions block each other until the first transaction is
+ completed.
+
+If you use expensive index types, such as some PostGIS geospatial indexes, take
+care to check the total size of the chunk and its index using
+[`chunks_detailed_size`][chunks_detailed_size].
+
+## Enable chunk skipping
+
+Early access: TimescaleDB v2.17.1
+
+One of the key purposes of hypertables is to make your analytical queries run with the lowest latency possible.
+When you execute a query on a hypertable, you do not parse the whole table; you only access the chunks necessary
+to satisfy the query. This works well when the `WHERE` clause of a query uses the column by which a hypertable is
+partitioned. For example, in a hypertable where every day of the year is a separate chunk, a query for September 1
+accesses only the chunk for that day.
+
+However, many queries use columns other than the partitioning one. For example, a satellite company might have a
+table with two columns: one for when data was gathered by a satellite and one for when it was added to the database.
+If you partition by the date of gathering, a query by the date of adding accesses all chunks in the hypertable and
+slows the performance.
+
+To improve query performance, TimescaleDB enables you to skip chunks on non-partitioning columns in hypertables.
+
+Chunk skipping only works on chunks converted to the columnstore **after** you `enable_chunk_skipping`.
+
+### How chunk skipping works
+
+You enable chunk skipping on a column in a hypertable. TimescaleDB tracks the minimum and maximum values for that
+column in each chunk. These ranges are stored in the start (inclusive) and end (exclusive) format in the `chunk_column_stats`
+catalog table. TimescaleDB uses these ranges for dynamic chunk exclusion when the `WHERE` clause of an SQL query
+specifies ranges on the column.
+
+
+
+You can enable chunk skipping on hypertables compressed into the columnstore for `smallint`, `int`, `bigint`, `serial`,
+`bigserial`, `date`, `timestamp`, or `timestamptz` type columns.
+
+### When to enable chunk skipping
+
+You can enable chunk skipping on as many columns as you need. However, best practice is to enable it on columns that
+are both:
+
+- Correlated, that is, related to the partitioning column in some way.
+- Referenced in the `WHERE` clauses of the queries.
+
+In the satellite example, the time of adding data to a database inevitably follows the time of gathering.
+Sequential IDs and the creation timestamp for both entities also increase synchronously. This means those two
+columns are correlated.
+
+For a more in-depth look on chunk skipping, see [our blog post](https://www.timescale.com/blog/boost-postgres-performance-by-7x-with-chunk-skipping-indexes).
+
+### Enable chunk skipping
+
+To enable chunk skipping on a column, call `enable_chunk_skipping` on a `hypertable` for a `column_name`. For example,
+the following query enables chunk skipping on the `order_id` column in the `orders` table:
+
+For more details on how to implement chunk skipping, see the [API Reference][api-reference].
+
+## Analyze your hypertables
+
+You can use the Postgres `ANALYZE` command to query all chunks in your
+hypertable. The statistics collected by the `ANALYZE` command are used by the
+Postgres planner to create the best query plan. For more information about the
+`ANALYZE` command, see the [Postgres documentation][pg-analyze].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/extensions/pgvector/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.chunk_interval='1 day'
+ );
+```
+
+Example 2 (sql):
+```sql
+SELECT *
+ FROM timescaledb_information.dimensions
+ WHERE hypertable_name = 'conditions';
+```
+
+Example 3 (sql):
+```sql
+hypertable_schema | hypertable_name | dimension_number | column_name | column_type | dimension_type | time_interval | integer_interval | integer_now_func | num_partitions
+ -------------------+-----------------+------------------+-------------+--------------------------+----------------+---------------+------------------+------------------+----------------
+ public | metrics | 1 | recorded | timestamp with time zone | Time | 1 day | | |
+```
+
+Example 4 (sql):
+```sql
+SELECT set_chunk_time_interval('conditions', INTERVAL '24 hours');
+```
+
+---
+
+## recompress_chunk()
+
+**URL:** llms-txt#recompress_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Troubleshooting
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by convert_to_columnstore().
+
+Recompresses a compressed chunk that had more data inserted after compression.
+
+You can also recompress chunks by
+[running the job associated with your compression policy][run-job].
+`recompress_chunk` gives you more fine-grained control by
+allowing you to target a specific chunk.
+
+`recompress_chunk` is deprecated since TimescaleDB v2.14 and will be removed in the future.
+The procedure is now a wrapper which calls [`compress_chunk`](https://docs.tigerdata.com/api/latest/compression/compress_chunk/)
+instead of it.
+
+`recompress_chunk` is implemented as an SQL procedure and not a function. Call
+the procedure with `CALL`. Don't use a `SELECT` statement.
+
+`recompress_chunk` only works on chunks that have previously been compressed. To compress a
+chunk for the first time, use [`compress_chunk`](https://docs.tigerdata.com/api/latest/compression/compress_chunk/).
+
+Recompress the chunk `timescaledb_internal._hyper_1_2_chunk`:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`chunk`|`REGCLASS`|The chunk to be recompressed. Must include the schema, for example `_timescaledb_internal`, if it is not in the search path.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`if_not_compressed`|`BOOLEAN`|If `true`, prints a notice instead of erroring if the chunk is already compressed. Defaults to `false`.|
+
+In TimescaleDB 2.6.0 and above, `recompress_chunk` is implemented as a procedure.
+Previously, it was implemented as a function. If you are upgrading to
+TimescaleDB 2.6.0 or above, the`recompress_chunk`
+function could cause an error. For example, trying to run `SELECT
+recompress_chunk(i.show_chunks, true) FROM...` gives the following error:
+
+To fix the error, use `CALL` instead of `SELECT`. You might also need to write a
+procedure to replace the full functionality in your `SELECT` statement. For
+example:
+
+===== PAGE: https://docs.tigerdata.com/api/_hyperfunctions/saturating_add_pos/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+recompress_chunk(
+ chunk REGCLASS,
+ if_not_compressed BOOLEAN = false
+)
+```
+
+Example 2 (sql):
+```sql
+CALL recompress_chunk('_timescaledb_internal._hyper_1_2_chunk');
+```
+
+Example 3 (sql):
+```sql
+ERROR: recompress_chunk(regclass, boolean) is a procedure
+```
+
+Example 4 (sql):
+```sql
+DO $$
+DECLARE chunk regclass;
+BEGIN
+ FOR chunk IN SELECT format('%I.%I', chunk_schema, chunk_name)::regclass
+ FROM timescaledb_information.chunks
+ WHERE is_compressed = true
+ LOOP
+ RAISE NOTICE 'Recompressing %', chunk::text;
+ CALL recompress_chunk(chunk, true);
+ END LOOP;
+END
+$$;
+```
+
+---
+
+## add_dimension()
+
+**URL:** llms-txt#add_dimension()
+
+**Contents:**
+- Samples
+ - Parallelizing queries across multiple data nodes
+ - Parallelizing disk I/O on a single node
+- Required arguments
+- Optional arguments
+- Returns
+
+This interface is deprecated since [TimescaleDB v2.13.0][rn-2130].
+
+For information about the supported hypertable interface, see [add_dimension()][add-dimension].
+
+Add an additional partitioning dimension to a TimescaleDB hypertable.
+The column selected as the dimension can either use interval
+partitioning (for example, for a second time partition) or hash partitioning.
+
+The `add_dimension` command can only be executed after a table has been
+converted to a hypertable (via `create_hypertable`), but must similarly
+be run only on an empty hypertable.
+
+**Space partitions**: Using space partitions is highly recommended
+for [distributed hypertables][distributed-hypertables] to achieve
+efficient scale-out performance. For [regular hypertables][regular-hypertables]
+that exist only on a single node, additional partitioning can be used
+for specialized use cases and not recommended for most users.
+
+Space partitions use hashing: Every distinct item is hashed to one of
+*N* buckets. Remember that we are already using (flexible) time
+intervals to manage chunk sizes; the main purpose of space
+partitioning is to enable parallelization across multiple
+data nodes (in the case of distributed hypertables) or
+across multiple disks within the same time interval
+(in the case of single-node deployments).
+
+First convert table `conditions` to hypertable with just time
+partitioning on column `time`, then add an additional partition key on `location` with four partitions:
+
+Convert table `conditions` to hypertable with time partitioning on `time` and
+space partitioning (2 partitions) on `location`, then add two additional dimensions.
+
+Now in a multi-node example for distributed hypertables with a cluster
+of one access node and two data nodes, configure the access node for
+access to the two data nodes. Then, convert table `conditions` to
+a distributed hypertable with just time partitioning on column `time`,
+and finally add a space partitioning dimension on `location`
+with two partitions (as the number of the attached data nodes).
+
+### Parallelizing queries across multiple data nodes
+
+In a distributed hypertable, space partitioning enables inserts to be
+parallelized across data nodes, even while the inserted rows share
+timestamps from the same time interval, and thus increases the ingest rate.
+Query performance also benefits by being able to parallelize queries
+across nodes, particularly when full or partial aggregations can be
+"pushed down" to data nodes (for example, as in the query
+`avg(temperature) FROM conditions GROUP BY hour, location`
+when using `location` as a space partition). Please see our
+[best practices about partitioning in distributed hypertables][distributed-hypertable-partitioning-best-practices]
+for more information.
+
+### Parallelizing disk I/O on a single node
+
+Parallel I/O can benefit in two scenarios: (a) two or more concurrent
+queries should be able to read from different disks in parallel, or
+(b) a single query should be able to use query parallelization to read
+from multiple disks in parallel.
+
+Thus, users looking for parallel I/O have two options:
+
+1. Use a RAID setup across multiple physical disks, and expose a
+single logical disk to the hypertable (that is, via a single tablespace).
+
+1. For each physical disk, add a separate tablespace to the
+database. TimescaleDB allows you to actually add multiple tablespaces
+to a *single* hypertable (although under the covers, a hypertable's
+chunks are spread across the tablespaces associated with that hypertable).
+
+We recommend a RAID setup when possible, as it supports both forms of
+parallelization described above (that is, separate queries to separate
+disks, single query to multiple disks in parallel). The multiple
+tablespace approach only supports the former. With a RAID setup,
+*no spatial partitioning is required*.
+
+That said, when using space partitions, we recommend using 1
+space partition per disk.
+
+TimescaleDB does *not* benefit from a very large number of space
+partitions (such as the number of unique items you expect in partition
+field). A very large number of such partitions leads both to poorer
+per-partition load balancing (the mapping of items to partitions using
+hashing), as well as much increased planning latency for some types of
+queries.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable to add the dimension to|
+|`column_name`|TEXT|Column to partition by|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`number_partitions`|INTEGER|Number of hash partitions to use on `column_name`. Must be > 0|
+|`chunk_time_interval`|INTERVAL|Interval that each chunk covers. Must be > 0|
+|`partitioning_func`|REGCLASS|The function to use for calculating a value's partition (see `create_hypertable` [instructions][create_hypertable])|
+|`if_not_exists`|BOOLEAN|Set to true to avoid throwing an error if a dimension for the column already exists. A notice is issued instead. Defaults to false|
+
+|Column|Type|Description|
+|-|-|-|
+|`dimension_id`|INTEGER|ID of the dimension in the TimescaleDB internal catalog|
+|`schema_name`|TEXT|Schema name of the hypertable|
+|`table_name`|TEXT|Table name of the hypertable|
+|`column_name`|TEXT|Column name of the column to partition by|
+|`created`|BOOLEAN|True if the dimension was added, false when `if_not_exists` is true and no dimension was added|
+
+When executing this function, either `number_partitions` or
+`chunk_time_interval` must be supplied, which dictates if the
+dimension uses hash or interval partitioning.
+
+The `chunk_time_interval` should be specified as follows:
+
+* If the column to be partitioned is a TIMESTAMP, TIMESTAMPTZ, or
+DATE, this length should be specified either as an INTERVAL type or
+an integer value in *microseconds*.
+
+* If the column is some other integer type, this length
+should be an integer that reflects
+the column's underlying semantics (for example, the
+`chunk_time_interval` should be given in milliseconds if this column
+is the number of milliseconds since the UNIX epoch).
+
+Supporting more than **one** additional dimension is currently
+ experimental. For any production environments, users are recommended
+ to use at most one "space" dimension.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/hypertable_approximate_detailed_size/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time');
+SELECT add_dimension('conditions', 'location', number_partitions => 4);
+```
+
+Example 2 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time', 'location', 2);
+SELECT add_dimension('conditions', 'time_received', chunk_time_interval => INTERVAL '1 day');
+SELECT add_dimension('conditions', 'device_id', number_partitions => 2);
+SELECT add_dimension('conditions', 'device_id', number_partitions => 2, if_not_exists => true);
+```
+
+Example 3 (sql):
+```sql
+SELECT add_data_node('dn1', host => 'dn1.example.com');
+SELECT add_data_node('dn2', host => 'dn2.example.com');
+SELECT create_distributed_hypertable('conditions', 'time');
+SELECT add_dimension('conditions', 'location', number_partitions => 2);
+```
+
+---
+
+## Hypertable retention policy isn't applying to continuous aggregates
+
+**URL:** llms-txt#hypertable-retention-policy-isn't-applying-to-continuous-aggregates
+
+
+
+A retention policy set on a hypertable does not apply to any continuous
+aggregates made from the hypertable. This allows you to set different retention
+periods for raw and summarized data. To apply a retention policy to a continuous
+aggregate, set the policy on the continuous aggregate itself.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/columnstore-backlog-ooms/ =====
+
+---
+
+## hypertable_columnstore_stats()
+
+**URL:** llms-txt#hypertable_columnstore_stats()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Retrieve compression statistics for the columnstore.
+
+For more information about using hypertables, including chunk size partitioning,
+see [hypertables][hypertable-docs].
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To retrieve compression statistics:
+
+- **Show the compression status of the `conditions` hypertable**:
+
+- **Use `pg_size_pretty` get the output in a more human friendly format**:
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable to show statistics for|
+
+|Column|Type|Description|
+|-|-|-|
+|`total_chunks`|BIGINT|The number of chunks used by the hypertable. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`number_compressed_chunks`|INTEGER|The number of chunks used by the hypertable that are currently compressed. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_table_bytes`|BIGINT|Size of the heap before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_index_bytes`|BIGINT|Size of all the indexes before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_toast_bytes`|BIGINT|Size the TOAST table before compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`before_compression_total_bytes`|BIGINT|Size of the entire table (`before_compression_table_bytes` + `before_compression_index_bytes` + `before_compression_toast_bytes`) before compression. Returns `NULL` if `compression_status` == `Uncompressed`.|
+|`after_compression_table_bytes`|BIGINT|Size of the heap after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_index_bytes`|BIGINT|Size of all the indexes after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_toast_bytes`|BIGINT|Size the TOAST table after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`after_compression_total_bytes`|BIGINT|Size of the entire table (`after_compression_table_bytes` + `after_compression_index_bytes `+ `after_compression_toast_bytes`) after compression. Returns `NULL` if `compression_status` == `Uncompressed`. |
+|`node_name`|TEXT|nodes on which the hypertable is located, applicable only to distributed hypertables. Returns `NULL` if `compression_status` == `Uncompressed`. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/remove_columnstore_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM hypertable_columnstore_stats('conditions');
+```
+
+Example 2 (sql):
+```sql
+-[ RECORD 1 ]------------------+------
+ total_chunks | 4
+ number_compressed_chunks | 1
+ before_compression_table_bytes | 8192
+ before_compression_index_bytes | 32768
+ before_compression_toast_bytes | 0
+ before_compression_total_bytes | 40960
+ after_compression_table_bytes | 8192
+ after_compression_index_bytes | 32768
+ after_compression_toast_bytes | 8192
+ after_compression_total_bytes | 49152
+ node_name |
+```
+
+Example 3 (sql):
+```sql
+SELECT pg_size_pretty(after_compression_total_bytes) as total
+ FROM hypertable_columnstore_stats('conditions');
+```
+
+Example 4 (sql):
+```sql
+-[ RECORD 1 ]--+------
+ total | 48 kB
+```
+
+---
+
+## Aggregate time-series data with time bucket
+
+**URL:** llms-txt#aggregate-time-series-data-with-time-bucket
+
+**Contents:**
+- Group data by time buckets and calculate a summary value
+- Group data by time buckets and show the end time of the bucket
+- Group data by time buckets and change the time range of the bucket
+- Calculate the time bucket of a single value
+
+The `time_bucket` function helps you group in a [hypertable][create-hypertable] so you can
+perform aggregate calculations over arbitrary time intervals. It is usually used
+in combination with `GROUP BY` for this purpose.
+
+This section shows examples of `time_bucket` use. To learn how time buckets
+work, see the [about time buckets section][time-buckets].
+
+## Group data by time buckets and calculate a summary value
+
+Group data into time buckets and calculate a summary value for a column. For
+example, calculate the average daily temperature in a table named
+`weather_conditions`. The table has a time column named `time` and a
+`temperature` column:
+
+The `time_bucket` function returns the start time of the bucket. In this
+example, the first bucket starts at midnight on November 15, 2016, and
+aggregates all the data from that day:
+
+## Group data by time buckets and show the end time of the bucket
+
+By default, the `time_bucket` column shows the start time of the bucket. If you
+prefer to show the end time, you can shift the displayed time using a
+mathematical operation on `time`.
+
+For example, you can calculate the minimum and maximum CPU usage for 5-minute
+intervals, and show the end of time of the interval. The example table is named
+`metrics`. It has a time column named `time` and a CPU usage column named `cpu`:
+
+The addition of `+ '5 min'` changes the displayed timestamp to the end of the
+bucket. It doesn't change the range of times spanned by the bucket.
+
+## Group data by time buckets and change the time range of the bucket
+
+To change the time range spanned by the buckets, use the `offset` parameter,
+which takes an `INTERVAL` argument. A positive offset shifts the start and end
+time of the buckets later. A negative offset shifts the start and end time of
+the buckets earlier.
+
+For example, you can calculate the average CPU usage for 5-hour intervals, and
+shift the start and end times of all buckets 1 hour later:
+
+## Calculate the time bucket of a single value
+
+Time buckets are usually used together with `GROUP BY` to aggregate data. But
+you can also run `time_bucket` on a single time value. This is useful for
+testing and learning, because you can see what bucket a value falls into.
+
+For example, to see the 1-week time bucket into which January 5, 2021 would
+fall, run:
+
+The function returns `2021-01-04 00:00:00`. The start time of the time bucket is
+the Monday of that week, at midnight.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/time-buckets/about-time-buckets/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT time_bucket('1 day', time) AS bucket,
+ avg(temperature) AS avg_temp
+FROM weather_conditions
+GROUP BY bucket
+ORDER BY bucket ASC;
+```
+
+Example 2 (sql):
+```sql
+bucket | avg_temp
+-----------------------+---------------------
+2016-11-15 00:00:00+00 | 68.3704391666665821
+2016-11-16 00:00:00+00 | 67.0816684374999347
+```
+
+Example 3 (sql):
+```sql
+SELECT time_bucket('5 min', time) + '5 min' AS bucket,
+ min(cpu),
+ max(cpu)
+FROM metrics
+GROUP BY bucket
+ORDER BY bucket DESC;
+```
+
+Example 4 (sql):
+```sql
+SELECT time_bucket('5 hours', time, '1 hour'::INTERVAL) AS bucket,
+ avg(cpu)
+FROM metrics
+GROUP BY bucket
+ORDER BY bucket DESC;
+```
+
+---
+
+## Integrate Debezium with Tiger Cloud
+
+**URL:** llms-txt#integrate-debezium-with-tiger-cloud
+
+**Contents:**
+- Prerequisites
+- Configure your database to work with Debezium
+- Configure Debezium to work with your database
+
+[Debezium][debezium] is an open-source distributed platform for change data capture (CDC).
+It enables you to capture changes in a self-hosted TimescaleDB instance and stream them to other systems in real time.
+
+Debezium can capture events about:
+
+- [Hypertables][hypertables]: captured events are rerouted from their chunk-specific topics to a single logical topic
+ named according to the following pattern: `..`
+- [Continuous aggregates][caggs]: captured events are rerouted from their chunk-specific topics to a single logical topic
+ named according to the following pattern: `..`
+- [Hypercore][hypercore]: If you enable hypercore, the Debezium TimescaleDB connector does not apply any special
+ processing to data in the columnstore. Compressed chunks are forwarded unchanged to the next downstream job in the
+ pipeline for further processing as needed. Typically, messages with compressed chunks are dropped, and are not
+ processed by subsequent jobs in the pipeline.
+
+This limitation only affects changes to chunks in the columnstore. Changes to data in the rowstore work correctly.
+
+This page explains how to capture changes in your database and stream them using Debezium on Apache Kafka.
+
+To follow the steps on this page:
+
+* Create a target [self-hosted TimescaleDB][enable-timescaledb] instance.
+
+- [Install Docker][install-docker] on your development machine.
+
+## Configure your database to work with Debezium
+
+To set up self-hosted TimescaleDB to communicate with Debezium:
+
+1. **Configure your self-hosted Postgres deployment**
+
+1. Open `postgresql.conf`.
+
+The Postgres configuration files are usually located in:
+
+- Docker: `/home/postgres/pgdata/data/`
+ - Linux: `/etc/postgresql//main/` or `/var/lib/pgsql//data/`
+ - MacOS: `/opt/homebrew/var/postgresql@/`
+ - Windows: `C:\Program Files\PostgreSQL\\data\`
+
+1. Enable logical replication.
+
+Modify the following settings in `postgresql.conf`:
+
+1. Open `pg_hba.conf` and enable host replication.
+
+To allow replication connections, add the following:
+
+This permission is for the `debezium` Postgres user running on a local or Docker deployment. For more about replication
+ permissions, see [Configuring Postgres to allow replication with the Debezium connector host][debezium-replication-permissions].
+
+1. **Connect to your self-hosted TimescaleDB instance**
+
+Use [`psql`][psql-connect].
+
+1. **Create a Debezium user in Postgres**
+
+Create a user with the `LOGIN` and `REPLICATION` permissions:
+
+1. **Enable a replication spot for Debezium**
+
+1. Create a table for Debezium to listen to:
+
+1. Turn the table into a hypertable:
+
+Debezium also works with [continuous aggregates][caggs].
+
+1. Create a publication and enable a replication slot:
+
+## Configure Debezium to work with your database
+
+Set up Kafka Connect server, plugins, drivers, and connectors:
+
+1. **Run Zookeeper in Docker**
+
+In another Terminal window, run the following command:
+
+ Check the output log to see that zookeeper is running.
+
+1. **Run Kafka in Docker**
+
+In another Terminal window, run the following command:
+
+ Check the output log to see that Kafka is running.
+
+1. **Run Kafka Connect in Docker**
+
+In another Terminal window, run the following command:
+
+ Check the output log to see that Kafka Connect is running.
+
+1. **Register the Debezium Postgres source connector**
+
+Update the `` for the `` you created in your self-hosted TimescaleDB instance in the following command.
+ Then run the command in another Terminal window:
+
+1. **Verify `timescaledb-source-connector` is included in the connector list**
+
+1. Check the tasks associated with `timescaledb-connector`:
+
+ You see something like:
+
+1. **Verify `timescaledb-connector` is running**
+
+1. Open the Terminal window running Kafka Connect. When the connector is active, you see something like the following:
+
+1. Watch the events in the accounts topic on your self-hosted TimescaleDB instance.
+
+In another Terminal instance, run the following command:
+
+You see the topics being streamed. For example:
+
+Debezium requires logical replication to be enabled. Currently, this is not enabled by default on Tiger Cloud services.
+We are working on enabling this feature as you read. As soon as it is live, these docs will be updated.
+
+And that is it, you have configured Debezium to interact with Tiger Data products.
+
+===== PAGE: https://docs.tigerdata.com/integrations/fivetran/ =====
+
+**Examples:**
+
+Example 1 (ini):
+```ini
+wal_level = logical
+ max_replication_slots = 10
+ max_wal_senders = 10
+```
+
+Example 2 (unknown):
+```unknown
+local replication debezium trust
+```
+
+Example 3 (sql):
+```sql
+CREATE ROLE debezium WITH LOGIN REPLICATION PASSWORD '';
+```
+
+Example 4 (sql):
+```sql
+CREATE TABLE accounts (created_at TIMESTAMPTZ DEFAULT NOW(),
+ name TEXT,
+ city TEXT);
+```
+
+---
+
+## add_retention_policy()
+
+**URL:** llms-txt#add_retention_policy()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Create a policy to drop chunks older than a given interval of a particular
+hypertable or continuous aggregate on a schedule in the background. For more
+information, see the [drop_chunks][drop_chunks] section. This implements a data
+retention policy and removes data on a schedule. Only one retention policy may
+exist per hypertable.
+
+When you create a retention policy on a hypertable with an integer based time column, you must set the
+[integer_now_func][set_integer_now_func] to match your data. If you are seeing `invalid value` issues when you
+call `add_retention_policy`, set `VERBOSITY verbose` to see the full context.
+
+- **Create a data retention policy to discard chunks greater than 6 months old**:
+
+When you call `drop_after`, the time data range present in the partitioning time column is used to select the target
+ chunks.
+
+- **Create a data retention policy with an integer-based time column**:
+
+- **Create a data retention policy to discard chunks created before 6 months**:
+
+When you call `drop_created_before`, chunks created 3 months ago are selected.
+
+| Name | Type | Default | Required | Description |
+|-|-|-|-|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|`relation`|REGCLASS|-|✔| Name of the hypertable or continuous aggregate to create the policy for |
+|`drop_after`|INTERVAL or INTEGER|-|✔| Chunks fully older than this interval when the policy is run are dropped.
You specify `drop_after` differently depending on the hypertable time column type: - TIMESTAMP, TIMESTAMPTZ, and DATE: use INTERVAL type
- Integer-based timestamps: use INTEGER type. You must set integer_now_func to match your data
|
+|`schedule_interval`|INTERVAL|`NULL`|✖| The interval between the finish time of the last execution and the next start. |
+|`initial_start`|TIMESTAMPTZ|`NULL`|✖| Time the policy is first run. If omitted, then the schedule interval is the interval between the finish time of the last execution and the next start. If provided, it serves as the origin with respect to which the next_start is calculated. |
+|`timezone`|TEXT|`NULL`|✖| A valid time zone. If `initial_start` is also specified, subsequent executions of the retention policy are aligned on its initial start. However, daylight savings time (DST) changes may shift this alignment. Set to a valid time zone if this is an issue you want to mitigate. If omitted, UTC bucketing is performed. |
+|`if_not_exists`|BOOLEAN|`false`|✖| Set to `true` to avoid an error if the `drop_chunks_policy` already exists. A notice is issued instead. |
+|`drop_created_before`|INTERVAL|`NULL`|✖| Chunks with creation time older than this cut-off point are dropped. The cut-off point is computed as `now() - drop_created_before`. Not supported for continuous aggregates yet. |
+
+You specify `drop_after` differently depending on the hypertable time column type:
+
+* TIMESTAMP, TIMESTAMPTZ, and DATE time columns: the time interval should be an INTERVAL type.
+* Integer-based timestamps: the time interval should be an integer type. You must set the [integer_now_func][set_integer_now_func].
+
+|Column|Type|Description|
+|-|-|-|
+|`job_id`|INTEGER|TimescaleDB background job ID created to implement this policy|
+
+===== PAGE: https://docs.tigerdata.com/api/data-retention/remove_retention_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_retention_policy('conditions', drop_after => INTERVAL '6 months');
+```
+
+Example 2 (sql):
+```sql
+SELECT add_retention_policy('conditions', drop_after => BIGINT '600000');
+```
+
+Example 3 (sql):
+```sql
+SELECT add_retention_policy('conditions', drop_created_before => INTERVAL '6 months');
+```
+
+---
+
+## Permission denied when changing ownership of tables and hypertables
+
+**URL:** llms-txt#permission-denied-when-changing-ownership-of-tables-and-hypertables
+
+
+
+You might see this error when using the `ALTER TABLE` command to change the
+ownership of tables or hypertables.
+
+This use of `ALTER TABLE` is blocked because the `tsdbadmin` user is not a
+superuser.
+
+To change table ownership, use the [`REASSIGN`][sql-reassign] command instead:
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/mst/transaction-wraparound/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+REASSIGN OWNED BY TO
+```
+
+---
+
+## timescaledb_information.chunk_compression_settings
+
+**URL:** llms-txt#timescaledb_information.chunk_compression_settings
+
+**Contents:**
+- Samples
+- Arguments
+
+Shows information about compression settings for each chunk that has compression enabled on it.
+
+Show compression settings for all chunks:
+
+Find all chunk compression settings for a specific hypertable:
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|`REGCLASS`|Hypertable which has compression enabled|
+|`chunk`|`REGCLASS`|Chunk which has compression enabled|
+|`segmentby`|`TEXT`|List of columns used for segmenting the compressed data|
+|`orderby`|`TEXT`| List of columns used for ordering compressed data along with ordering and NULL ordering information|
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/jobs/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM timescaledb_information.chunk_compression_settings'
+hypertable | measurements
+chunk | _timescaledb_internal._hyper_1_1_chunk
+segmentby |
+orderby | "time" DESC
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM timescaledb_information.chunk_compression_settings WHERE hypertable::TEXT LIKE 'metrics';
+hypertable | metrics
+chunk | _timescaledb_internal._hyper_2_3_chunk
+segmentby | metric_id
+orderby | "time"
+```
+
+---
+
+## set_integer_now_fun()
+
+**URL:** llms-txt#set_integer_now_fun()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Override the [`now()`](https://www.postgresql.org/docs/16/functions-datetime.html) date/time function used to
+set the current time in the integer `time` column in a hypertable. Many policies only apply to
+[chunks][chunks] of a certain age. `integer_now_func` determines the age of each chunk.
+
+The function you set as `integer_now_func` has no arguments. It must be either:
+
+- `IMMUTABLE`: Use when you execute the query each time rather than prepare it prior to execution. The value
+ for `integer_now_func` is computed before the plan is generated. This generates a significantly smaller
+ plan, especially if you have a lot of chunks.
+
+- `STABLE`: `integer_now_func` is evaluated just before query execution starts.
+ [chunk pruning](https://www.timescale.com/blog/optimizing-queries-timescaledb-hypertables-with-partitions-postgresql-6366873a995d) is executed at runtime. This generates a correct result, but may increase
+ planning time.
+
+`set_integer_now_func` does not work on tables where the `time` column type is `TIMESTAMP`, `TIMESTAMPTZ`, or
+`DATE`.
+
+Set the integer `now` function for a hypertable with a time column in [unix time](https://en.wikipedia.org/wiki/Unix_time).
+
+- `IMMUTABLE`: when you execute the query each time:
+
+- `STABLE`: for prepared statements:
+
+## Required arguments
+
+|Name|Type| Description |
+|-|-|-|
+|`main_table`|REGCLASS| The hypertable `integer_now_func` is used in. |
+|`integer_now_func`|REGPROC| A function that returns the current time set in each row in the `time` column in `main_table`.|
+
+## Optional arguments
+
+|Name|Type| Description|
+|-|-|-|
+|`replace_if_exists`|BOOLEAN| Set to `true` to override `integer_now_func` when you have previously set a custom function. Default is `false`. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/create_index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE OR REPLACE FUNCTION unix_now_immutable() returns BIGINT LANGUAGE SQL IMMUTABLE as $$ SELECT extract (epoch from now())::BIGINT $$;
+
+ SELECT set_integer_now_func('hypertable_name', 'unix_now_immutable');
+```
+
+Example 2 (sql):
+```sql
+CREATE OR REPLACE FUNCTION unix_now_stable() returns BIGINT LANGUAGE SQL STABLE AS $$ SELECT extract(epoch from now())::BIGINT $$;
+
+ SELECT set_integer_now_func('hypertable_name', 'unix_now_stable');
+```
+
+---
+
+## hypertable_approximate_detailed_size()
+
+**URL:** llms-txt#hypertable_approximate_detailed_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get detailed information about approximate disk space used by a hypertable or
+continuous aggregate, returning size information for the table
+itself, any indexes on the table, any toast tables, and the total
+size of all. All sizes are reported in bytes.
+
+When a continuous aggregate name is provided, the function
+transparently looks up the backing hypertable and returns its approximate
+size statistics instead.
+
+This function relies on the per backend caching using the in-built
+Postgres storage manager layer to compute the approximate size
+cheaply. The PG cache invalidation clears off the cached size for a
+chunk when DML happens into it. That size cache is thus able to get
+the latest size in a matter of minutes. Also, due to the backend
+caching, any long running session will only fetch latest data for new
+or modified chunks and can use the cached data (which is calculated
+afresh the first time around) effectively for older chunks. Thus it
+is recommended to use a single connected Postgres backend session to
+compute the approximate sizes of hypertables to get faster results.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get the approximate size information for a hypertable.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Hypertable or continuous aggregate to show detailed approximate size of. |
+
+|Column|Type|Description|
+|-|-|-|
+|table_bytes|BIGINT|Approximate disk space used by main_table (like `pg_relation_size(main_table)`)|
+|index_bytes|BIGINT|Approximate disk space used by indexes|
+|toast_bytes|BIGINT|Approximate disk space of toast tables|
+|total_bytes|BIGINT|Approximate total disk space used by the specified table, including all indexes and TOAST data|
+
+If executed on a relation that is not a hypertable, the function
+returns `NULL`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/set_integer_now_func/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM hypertable_approximate_detailed_size('hyper_table');
+ table_bytes | index_bytes | toast_bytes | total_bytes
+-------------+-------------+-------------+-------------
+ 8192 | 24576 | 32768 | 65536
+```
+
+---
+
+## hypertable_compression_stats()
+
+**URL:** llms-txt#hypertable_compression_stats()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by hypertable_columnstore_stats().
+
+Get statistics related to hypertable compression. All sizes are in bytes.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+For more information about compression, see the
+[compression section][compression-docs].
+
+Use `pg_size_pretty` get the output in a more human friendly format.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable to show statistics for|
+
+|Column|Type|Description|
+|-|-|-|
+|`total_chunks`|BIGINT|The number of chunks used by the hypertable|
+|`number_compressed_chunks`|BIGINT|The number of chunks used by the hypertable that are currently compressed|
+|`before_compression_table_bytes`|BIGINT|Size of the heap before compression|
+|`before_compression_index_bytes`|BIGINT|Size of all the indexes before compression|
+|`before_compression_toast_bytes`|BIGINT|Size the TOAST table before compression|
+|`before_compression_total_bytes`|BIGINT|Size of the entire table (table+indexes+toast) before compression|
+|`after_compression_table_bytes`|BIGINT|Size of the heap after compression|
+|`after_compression_index_bytes`|BIGINT|Size of all the indexes after compression|
+|`after_compression_toast_bytes`|BIGINT|Size the TOAST table after compression|
+|`after_compression_total_bytes`|BIGINT|Size of the entire table (table+indexes+toast) after compression|
+|`node_name`|TEXT|nodes on which the hypertable is located, applicable only to distributed hypertables|
+
+Returns show `NULL` if the data is currently uncompressed.
+
+===== PAGE: https://docs.tigerdata.com/api/compression/compress_chunk/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM hypertable_compression_stats('conditions');
+
+-[ RECORD 1 ]------------------+------
+total_chunks | 4
+number_compressed_chunks | 1
+before_compression_table_bytes | 8192
+before_compression_index_bytes | 32768
+before_compression_toast_bytes | 0
+before_compression_total_bytes | 40960
+after_compression_table_bytes | 8192
+after_compression_index_bytes | 32768
+after_compression_toast_bytes | 8192
+after_compression_total_bytes | 49152
+node_name |
+```
+
+Example 2 (sql):
+```sql
+SELECT pg_size_pretty(after_compression_total_bytes) as total
+ FROM hypertable_compression_stats('conditions');
+
+-[ RECORD 1 ]--+------
+total | 48 kB
+```
+
+---
+
+## Grow and shrink multi-node
+
+**URL:** llms-txt#grow-and-shrink-multi-node
+
+**Contents:**
+- See which data nodes are in use
+- Choose how many nodes to use for a distributed hypertable
+- Attach a new data node
+ - Attaching a new data node to a distributed hypertable
+- Move data between chunks Experimental
+- Remove a data node
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+When you are working within a multi-node environment, you might discover that
+you need more or fewer data nodes in your cluster over time. You can choose how
+many of the available nodes to use when creating a distributed hypertable. You
+can also add and remove data nodes from your cluster, and move data between
+chunks on data nodes as required to free up storage.
+
+## See which data nodes are in use
+
+You can check which data nodes are in use by a distributed hypertable, using
+this query. In this example, our distributed hypertable is called
+`conditions`:
+
+The result of this query looks like this:
+
+## Choose how many nodes to use for a distributed hypertable
+
+By default, when you create a distributed hypertable, it uses all available
+data nodes. To restrict it to specific nodes, pass the `data_nodes` argument to
+[`create_distributed_hypertable`][create_distributed_hypertable].
+
+## Attach a new data node
+
+When you add additional data nodes to a database, you need to add them to the
+distributed hypertable so that your database can use them.
+
+### Attaching a new data node to a distributed hypertable
+
+1. On the access node, at the `psql` prompt, add the data node:
+
+1. Attach the new data node to the distributed hypertable:
+
+When you attach a new data node, the partitioning configuration of the
+distributed hypertable is updated to account for the additional data node, and
+the number of hash partitions are automatically increased to match. You can
+prevent this happening by setting the function parameter `repartition` to
+`FALSE`.
+
+## Move data between chunks Experimental
+
+When you attach a new data node to a distributed hypertable, you can move
+existing data in your hypertable to the new node to free up storage on the
+existing nodes and make better use of the added capacity.
+
+The ability to move chunks between data nodes is an experimental feature that is
+under active development. We recommend that you do not use this feature in a
+production environment.
+
+Move data using this query:
+
+The move operation uses a number of transactions, which means that you cannot
+roll the transaction back automatically if something goes wrong. If a move
+operation fails, the failure is logged with an operation ID that you can use to
+clean up any state left on the involved nodes.
+
+Clean up after a failed move using this query. In this example, the operation ID
+of the failed move is `ts_copy_1_31`:
+
+## Remove a data node
+
+You can also remove data nodes from an existing distributed hypertable.
+
+You cannot remove a data node that still contains data for the distributed
+hypertable. Before you remove the data node, check that is has had all of its
+data deleted or moved, or that you have replicated the data on to other data
+nodes.
+
+Remove a data node using this query. In this example, our distributed hypertable
+is called `conditions`:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/multinode-timescaledb/multinode-administration/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT hypertable_name, data_nodes
+FROM timescaledb_information.hypertables
+WHERE hypertable_name = 'conditions';
+```
+
+Example 2 (sql):
+```sql
+hypertable_name | data_nodes
+-----------------+---------------------------------------
+conditions | {data_node_1,data_node_2,data_node_3}
+```
+
+Example 3 (sql):
+```sql
+SELECT add_data_node('node3', host => 'dn3.example.com');
+```
+
+Example 4 (sql):
+```sql
+SELECT attach_data_node('node3', hypertable => 'hypertable_name');
+```
+
+---
+
+## Energy time-series data tutorial - set up dataset
+
+**URL:** llms-txt#energy-time-series-data-tutorial---set-up-dataset
+
+**Contents:**
+- Prerequisites
+- Optimize time-series data in hypertables
+- Load energy consumption data
+- Create continuous aggregates
+- Connect Grafana to Tiger Cloud
+
+This tutorial uses the energy consumption data for over a year in a
+hypertable named `metrics`.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables in TimescaleDB that automatically partition your time-series data by time. Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range
+of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and
+runs the query on it, instead of going through the entire table.
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Because TimescaleDB is 100% Postgres, you can use all the standard Postgres tables, indexes, stored
+procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar
+to standard Postgres.
+
+1. To create a hypertable to store the energy consumption data, call [CREATE TABLE][hypertable-create-table].
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+## Load energy consumption data
+
+When you have your database set up, you can load the energy consumption data
+into the `metrics` hypertable.
+
+This is a large dataset, so it might take a long time, depending on your network
+connection.
+
+1. Download the dataset:
+
+[metrics.csv.gz](https://assets.timescale.com/docs/downloads/metrics.csv.gz)
+
+1. Use your file manager to decompress the downloaded dataset, and take a note
+ of the path to the `metrics.csv` file.
+
+1. At the psql prompt, copy the data from the `metrics.csv` file into
+ your hypertable. Make sure you point to the correct path, if it is not in
+ your current working directory:
+
+1. You can check that the data has been copied successfully with this command:
+
+You should get five records that look like this:
+
+## Create continuous aggregates
+
+In modern applications, data usually grows very quickly. This means that aggregating
+it into useful summaries can become very slow. If you are collecting data very frequently, you might want to aggregate your
+data into minutes or hours instead. For example, if an IoT device takes
+temperature readings every second, you might want to find the average temperature
+for each hour. Every time you run this query, the database needs to scan the
+entire table and recalculate the average. TimescaleDB makes aggregating data lightning fast, accurate, and easy with continuous aggregates.
+
+
+
+Continuous aggregates in TimescaleDB are a kind of hypertable that is refreshed automatically
+in the background as new data is added, or old data is modified. Changes to your
+dataset are tracked, and the hypertable behind the continuous aggregate is
+automatically updated in the background.
+
+Continuous aggregates have a much lower maintenance burden than regular Postgres materialized
+views, because the whole view is not created from scratch on each refresh. This
+means that you can get on with working your data instead of maintaining your
+database.
+
+Because continuous aggregates are based on hypertables, you can query them in exactly the same way as your other tables. This includes continuous aggregates in the rowstore, compressed into the [columnstore][hypercore],
+or [tiered to object storage][data-tiering]. You can even create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs], for an even more fine-tuned aggregation.
+
+[Real-time aggregation][real-time-aggregation] enables you to combine pre-aggregated data from the materialized view with the most recent raw data. This gives you up-to-date results on every query. In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+1. **Monitor energy consumption on a day-to-day basis**
+
+1. Create a continuous aggregate `kwh_day_by_day` for energy consumption:
+
+1. Add a refresh policy to keep `kwh_day_by_day` up-to-date:
+
+1. **Monitor energy consumption on an hourly basis**
+
+1. Create a continuous aggregate `kwh_hour_by_hour` for energy consumption:
+
+1. Add a refresh policy to keep the continuous aggregate up-to-date:
+
+1. **Analyze your data**
+
+Now you have made continuous aggregates, it could be a good idea to use them to perform analytics on your data.
+ For example, to see how average energy consumption changes during weekdays over the last year, run the following query:
+
+You see something like:
+
+| day | ordinal | value |
+ | --- | ------- | ----- |
+ | Mon | 2 | 23.08078714975423 |
+ | Sun | 1 | 19.511430831944395 |
+ | Tue | 3 | 25.003118897837307 |
+ | Wed | 4 | 8.09300571759772 |
+
+## Connect Grafana to Tiger Cloud
+
+To visualize the results of your queries, enable Grafana to read the data in your service:
+
+1. **Log in to Grafana**
+
+In your browser, log in to either:
+ - Self-hosted Grafana: at `http://localhost:3000/`. The default credentials are `admin`, `admin`.
+ - Grafana Cloud: use the URL and credentials you set when you created your account.
+1. **Add your service as a data source**
+ 1. Open `Connections` > `Data sources`, then click `Add new data source`.
+ 1. Select `PostgreSQL` from the list.
+ 1. Configure the connection:
+ - `Host URL`, `Database name`, `Username`, and `Password`
+
+Configure using your [connection details][connection-info]. `Host URL` is in the format `:`.
+ - `TLS/SSL Mode`: select `require`.
+ - `PostgreSQL options`: enable `TimescaleDB`.
+ - Leave the default setting for all other fields.
+
+1. Click `Save & test`.
+
+Grafana checks that your details are set correctly.
+
+===== PAGE: https://docs.tigerdata.com/tutorials/energy-data/query-energy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE "metrics"(
+ created timestamp with time zone default now() not null,
+ type_id integer not null,
+ value double precision not null
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+ );
+```
+
+Example 2 (sql):
+```sql
+\COPY metrics FROM metrics.csv CSV;
+```
+
+Example 3 (sql):
+```sql
+SELECT * FROM metrics LIMIT 5;
+```
+
+Example 4 (sql):
+```sql
+created | type_id | value
+ -------------------------------+---------+-------
+ 2023-05-31 23:59:59.043264+00 | 13 | 1.78
+ 2023-05-31 23:59:59.042673+00 | 2 | 126
+ 2023-05-31 23:59:59.042667+00 | 11 | 1.79
+ 2023-05-31 23:59:59.042623+00 | 23 | 0.408
+ 2023-05-31 23:59:59.042603+00 | 12 | 0.96
+```
+
+---
+
+## create_hypertable()
+
+**URL:** llms-txt#create_hypertable()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+- Units
+
+This page describes the hypertable API supported prior to TimescaleDB v2.13. Best practice is to use the new
+[`create_hypertable`][api-create-hypertable] interface.
+
+Creates a TimescaleDB hypertable from a Postgres table (replacing the latter),
+partitioned on time and with the option to partition on one or more other
+columns. The Postgres table cannot be an already partitioned table
+(declarative partitioning or inheritance). In case of a non-empty table, it is
+possible to migrate the data during hypertable creation using the `migrate_data`
+option, although this might take a long time and has certain limitations when
+the table contains foreign key constraints (see below).
+
+After creation, all actions, such as `ALTER TABLE`, `SELECT`, etc., still work
+on the resulting hypertable.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Convert table `conditions` to hypertable with just time partitioning on column `time`:
+
+Convert table `conditions` to hypertable, setting `chunk_time_interval` to 24 hours.
+
+Convert table `conditions` to hypertable. Do not raise a warning
+if `conditions` is already a hypertable:
+
+Time partition table `measurements` on a composite column type `report` using a
+time partitioning function. Requires an immutable function that can convert the
+column value into a supported column value:
+
+Time partition table `events`, on a column type `jsonb` (`event`), which has
+a top level key (`started`) containing an ISO 8601 formatted timestamp:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`relation`|REGCLASS|Identifier of table to convert to hypertable.|
+|`time_column_name`|REGCLASS| Name of the column containing time values as well as the primary column to partition by.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`partitioning_column`|REGCLASS|Name of an additional column to partition by. If provided, the `number_partitions` argument must also be provided.|
+|`number_partitions`|INTEGER|Number of [hash partitions][hash-partitions] to use for `partitioning_column`. Must be > 0.|
+|`chunk_time_interval`|INTERVAL|Event time that each chunk covers. Must be > 0. Default is 7 days.|
+|`create_default_indexes`|BOOLEAN|Whether to create default indexes on time/partitioning columns. Default is TRUE.|
+|`if_not_exists`|BOOLEAN|Whether to print warning if table already converted to hypertable or raise exception. Default is FALSE.|
+|`partitioning_func`|REGCLASS|The function to use for calculating a value's partition.|
+|`associated_schema_name`|REGCLASS|Name of the schema for internal hypertable tables. Default is `_timescaledb_internal`.|
+|`associated_table_prefix`|TEXT|Prefix for internal hypertable chunk names. Default is `_hyper`.|
+|`migrate_data`|BOOLEAN|Set to TRUE to migrate any existing data from the `relation` table to chunks in the new hypertable. A non-empty table generates an error without this option. Large tables may take significant time to migrate. Defaults to FALSE.|
+|`time_partitioning_func`|REGCLASS| Function to convert incompatible primary time column values to compatible ones. The function must be `IMMUTABLE`.|
+|`replication_factor`|INTEGER|Replication factor to use with distributed hypertable. If not provided, value is determined by the `timescaledb.hypertable_replication_factor_default` GUC. |
+|`data_nodes`|ARRAY|This is the set of data nodes that are used for this table if it is distributed. This has no impact on non-distributed hypertables. If no data nodes are specified, a distributed hypertable uses all data nodes known by this instance.|
+|`distributed`|BOOLEAN|Set to TRUE to create distributed hypertable. If not provided, value is determined by the `timescaledb.hypertable_distributed_default` GUC. When creating a distributed hypertable, consider using [`create_distributed_hypertable`][create_distributed_hypertable] in place of `create_hypertable`. Default is NULL. |
+
+|Column|Type|Description|
+|-|-|-|
+|`hypertable_id`|INTEGER|ID of the hypertable in TimescaleDB.|
+|`schema_name`|TEXT|Schema name of the table converted to hypertable.|
+|`table_name`|TEXT|Table name of the table converted to hypertable.|
+|`created`|BOOLEAN|TRUE if the hypertable was created, FALSE when `if_not_exists` is true and no hypertable was created.|
+
+If you use `SELECT * FROM create_hypertable(...)` you get the return value
+formatted as a table with column headings.
+
+The use of the `migrate_data` argument to convert a non-empty table can
+lock the table for a significant amount of time, depending on how much data is
+in the table. It can also run into deadlock if foreign key constraints exist to
+other tables.
+
+When converting a normal SQL table to a hypertable, pay attention to how you handle
+constraints. A hypertable can contain foreign keys to normal SQL table columns,
+but the reverse is not allowed. UNIQUE and PRIMARY constraints must include the
+partitioning key.
+
+The deadlock is likely to happen when concurrent transactions simultaneously try
+to insert data into tables that are referenced in the foreign key constraints
+and into the converting table itself. The deadlock can be prevented by manually
+obtaining `SHARE ROW EXCLUSIVE` lock on the referenced tables before calling
+`create_hypertable` in the same transaction, see
+[Postgres documentation](https://www.postgresql.org/docs/current/sql-lock.html)
+for the syntax.
+
+The `time` column supports the following data types:
+
+|Description|Types|
+|-|-|
+|Timestamp| TIMESTAMP, TIMESTAMPTZ|
+|Date|DATE|
+|Integer|SMALLINT, INT, BIGINT|
+
+The type flexibility of the 'time' column allows the use of non-time-based
+values as the primary chunk partitioning column, as long as those values can
+increment.
+
+For incompatible data types (for example, `jsonb`) you can specify a function to
+the `time_partitioning_func` argument which can extract a compatible data type.
+
+The units of `chunk_time_interval` should be set as follows:
+
+* For time columns having timestamp or DATE types, the `chunk_time_interval`
+ should be specified either as an `interval` type or an integral value in
+ *microseconds*.
+* For integer types, the `chunk_time_interval` **must** be set explicitly, as
+ the database does not otherwise understand the semantics of what each
+ integer value represents (a second, millisecond, nanosecond, etc.). So if
+ your time column is the number of milliseconds since the UNIX epoch, and you
+ wish to have each chunk cover 1 day, you should specify
+ `chunk_time_interval => 86400000`.
+
+In case of hash partitioning (in other words, if `number_partitions` is greater
+than zero), it is possible to optionally specify a custom partitioning function.
+If no custom partitioning function is specified, the default partitioning
+function is used. The default partitioning function calls Postgres's internal
+hash function for the given type, if one exists. Thus, a custom partitioning
+function can be used for value types that do not have a native Postgres hash
+function. A partitioning function should take a single `anyelement` type
+argument and return a positive `integer` hash value. Note that this hash value
+is *not* a partition ID, but rather the inserted value's position in the
+dimension's key space, which is then divided across the partitions.
+
+The time column in `create_hypertable` must be defined as `NOT NULL`. If this is
+not already specified on table creation, `create_hypertable` automatically adds
+this constraint on the table when it is executed.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/set_chunk_time_interval/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time');
+```
+
+Example 2 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time', chunk_time_interval => 86400000000);
+SELECT create_hypertable('conditions', 'time', chunk_time_interval => INTERVAL '1 day');
+```
+
+Example 3 (sql):
+```sql
+SELECT create_hypertable('conditions', 'time', if_not_exists => TRUE);
+```
+
+Example 4 (sql):
+```sql
+CREATE TYPE report AS (reported timestamp with time zone, contents jsonb);
+
+CREATE FUNCTION report_reported(report)
+ RETURNS timestamptz
+ LANGUAGE SQL
+ IMMUTABLE AS
+ 'SELECT $1.reported';
+
+SELECT create_hypertable('measurements', 'report', time_partitioning_func => 'report_reported');
+```
+
+---
+
+## hypertable_approximate_size()
+
+**URL:** llms-txt#hypertable_approximate_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get the approximate total disk space used by a hypertable or continuous aggregate,
+that is, the sum of the size for the table itself including chunks,
+any indexes on the table, and any toast tables. The size is reported
+in bytes. This is equivalent to computing the sum of `total_bytes`
+column from the output of `hypertable_approximate_detailed_size` function.
+
+When a continuous aggregate name is provided, the function
+transparently looks up the backing hypertable and returns its statistics
+instead.
+
+This function relies on the per backend caching using the in-built
+Postgres storage manager layer to compute the approximate size
+cheaply. The PG cache invalidation clears off the cached size for a
+chunk when DML happens into it. That size cache is thus able to get
+the latest size in a matter of minutes. Also, due to the backend
+caching, any long running session will only fetch latest data for new
+or modified chunks and can use the cached data (which is calculated
+afresh the first time around) effectively for older chunks. Thus it
+is recommended to use a single connected Postgres backend session to
+compute the approximate sizes of hypertables to get faster results.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get the approximate size information for a hypertable.
+
+Get the approximate size information for all hypertables.
+
+Get the approximate size information for a continuous aggregate.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable or continuous aggregate to show size of.|
+
+|Name|Type|Description|
+|-|-|-|
+|hypertable_approximate_size|BIGINT|Total approximate disk space used by the specified hypertable, including all indexes and TOAST data|
+
+`NULL` is returned if the function is executed on a non-hypertable relation.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/split_chunk/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM hypertable_approximate_size('devices');
+ hypertable_approximate_size
+-----------------------------
+ 8192
+```
+
+Example 2 (sql):
+```sql
+SELECT hypertable_name, hypertable_approximate_size(format('%I.%I', hypertable_schema, hypertable_name)::regclass)
+ FROM timescaledb_information.hypertables;
+```
+
+Example 3 (sql):
+```sql
+SELECT hypertable_approximate_size('device_stats_15m');
+
+ hypertable_approximate_size
+-----------------------------
+ 8192
+```
+
+---
+
+## decompress_chunk()
+
+**URL:** llms-txt#decompress_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by convert_to_rowstore().
+
+Before decompressing chunks, stop any compression policy on the hypertable you
+are decompressing. You can use `SELECT alter_job(JOB_ID, scheduled => false);`
+to prevent scheduled execution.
+
+Decompress a single chunk:
+
+Decompress all compressed chunks in a hypertable named `metrics`:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+|`chunk_name`|`REGCLASS`|Name of the chunk to be decompressed.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+|`if_compressed`|`BOOLEAN`|Disabling this will make the function error out on chunks that are not compressed. Defaults to true.|
+
+|Column|Type|Description|
+|---|---|---|
+|`decompress_chunk`|`REGCLASS`|Name of the chunk that was decompressed.|
+
+===== PAGE: https://docs.tigerdata.com/api/compression/remove_compression_policy/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+Decompress all compressed chunks in a hypertable named `metrics`:
+```
+
+---
+
+## detach_chunk()
+
+**URL:** llms-txt#detach_chunk()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Separate a chunk from a [hypertable][hypertables-section].
+
+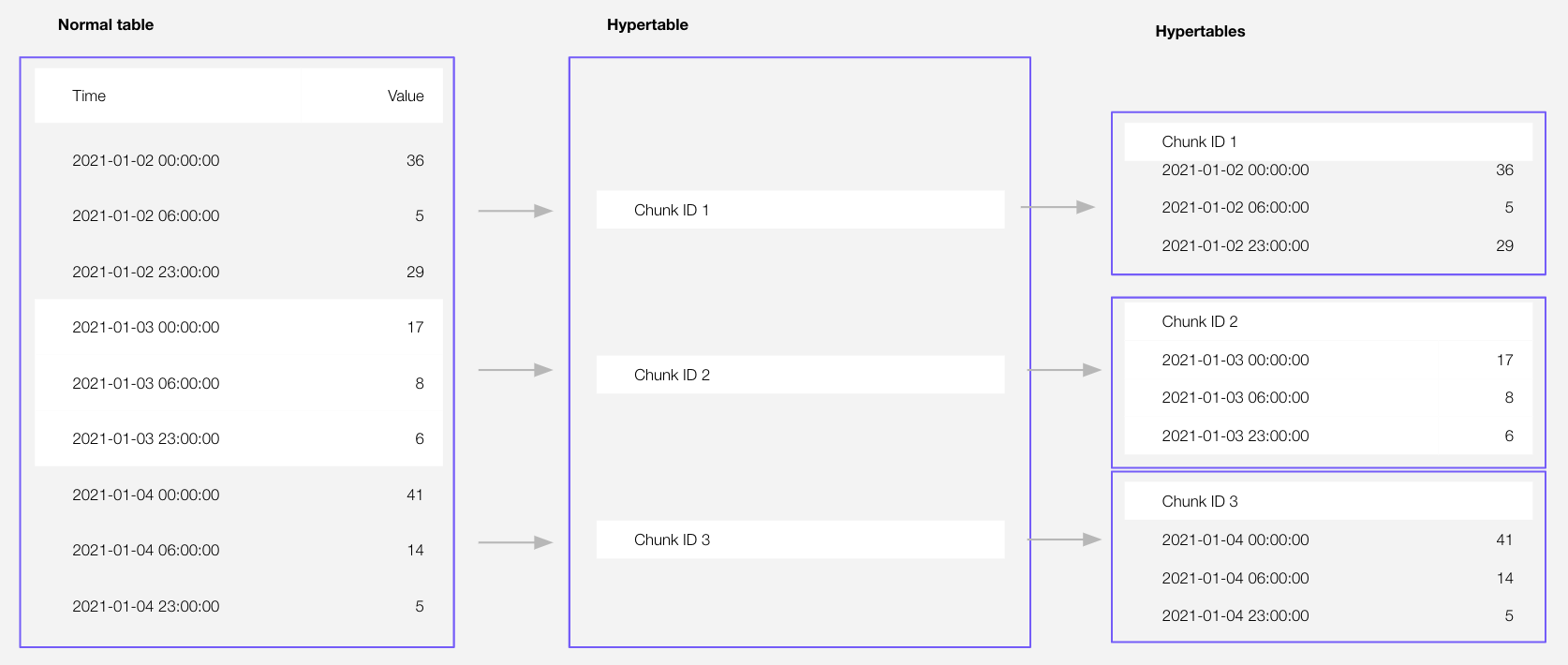
+
+`chunk` becomes a standalone hypertable with the same name and schema. All existing constraints and
+indexes on `chunk` are preserved after detaching. Foreign keys are dropped.
+
+In this initial release, you cannot detach a chunk that has been [converted to the columnstore][setup-hypercore].
+
+Since [TimescaleDB v2.21.0](https://github.com/timescale/timescaledb/releases/tag/2.21.0)
+
+Detach a chunk from a hypertable:
+
+|Name|Type| Description |
+|---|---|------------------------------|
+| `chunk` | REGCLASS | Name of the chunk to detach. |
+
+This function returns void.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/attach_tablespace/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL detach_chunk('_timescaledb_internal._hyper_1_2_chunk');
+```
+
+---
+
+## detach_data_node()
+
+**URL:** llms-txt#detach_data_node()
+
+**Contents:**
+- Required arguments
+- Optional arguments
+- Returns
+ - Errors
+- Sample usage
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Detach a data node from one hypertable or from all hypertables.
+
+Reasons for detaching a data node include:
+
+* A data node should no longer be used by a hypertable and needs to be
+removed from all hypertables that use it
+* You want to have fewer data nodes for a distributed hypertable to
+partition across
+
+## Required arguments
+
+| Name | Type|Description |
+|-------------|----|-------------------------------|
+| `node_name` | TEXT | Name of data node to detach from the distributed hypertable |
+
+## Optional arguments
+
+| Name | Type|Description |
+|---------------|---|-------------------------------------|
+| `hypertable` | REGCLASS | Name of the distributed hypertable where the data node should be detached. If NULL, the data node is detached from all hypertables. |
+| `if_attached` | BOOLEAN | Prevent error if the data node is not attached. Defaults to false. |
+| `force` | BOOLEAN | Force detach of the data node even if that means that the replication factor is reduced below what was set. Note that it is never allowed to reduce the replication factor below 1 since that would cause data loss. |
+| `repartition` | BOOLEAN | Make the number of hash partitions equal to the new number of data nodes (if such partitioning exists). This ensures that the remaining data nodes are used evenly. Defaults to true. |
+
+The number of hypertables the data node was detached from.
+
+Detaching a node is not permitted:
+
+* If it would result in data loss for the hypertable due to the data node
+containing chunks that are not replicated on other data nodes
+* If it would result in under-replicated chunks for the distributed hypertable
+(without the `force` argument)
+
+Replication is currently experimental, and not a supported feature
+
+Detaching a data node is under no circumstances possible if that would
+mean data loss for the hypertable. Nor is it possible to detach a data node,
+unless forced, if that would mean that the distributed hypertable would end
+up with under-replicated chunks.
+
+The only safe way to detach a data node is to first safely delete any
+data on it or replicate it to another data node.
+
+Detach data node `dn3` from `conditions`:
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/set_replication_factor/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT detach_data_node('dn3', 'conditions');
+```
+
+---
+
+## cleanup_copy_chunk_operation()
+
+**URL:** llms-txt#cleanup_copy_chunk_operation()
+
+**Contents:**
+- Required arguments
+- Sample usage
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+You can [copy][copy_chunk] or [move][move_chunk] a
+chunk to a new location within a multi-node environment. The
+operation happens over multiple transactions so, if it fails, it
+is manually cleaned up using this function. Without cleanup,
+the failed operation might hold a replication slot open, which in turn
+prevents storage from being reclaimed. The operation ID is logged in
+case of a failed copy or move operation and is required as input to
+the cleanup function.
+
+Experimental features could have bugs. They might not be backwards compatible,
+and could be removed in future releases. Use these features at your own risk, and
+do not use any experimental features in production.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`operation_id`|NAME|ID of the failed operation|
+
+Clean up a failed operation:
+
+Get a list of running copy or move operations:
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/create_distributed_restore_point/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL timescaledb_experimental.cleanup_copy_chunk_operation('ts_copy_1_31');
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM _timescaledb_catalog.chunk_copy_operation;
+```
+
+---
+
+## Enforce constraints with unique indexes
+
+**URL:** llms-txt#enforce-constraints-with-unique-indexes
+
+**Contents:**
+- Create a hypertable and add unique indexes
+- Create a hypertable from an existing table with unique indexes
+
+You use unique indexes on a hypertable to enforce [constraints][constraints]. If you have a primary key,
+you have a unique index. In Postgres, a primary key is a unique index with a `NOT NULL` constraint.
+
+You do not need to have a unique index on your hypertables. When you create a unique index,
+it must contain all the partitioning columns of the hypertable.
+
+## Create a hypertable and add unique indexes
+
+To create a unique index on a hypertable:
+
+1. **Determine the partitioning columns**
+
+Before you create a unique index, you need to determine which unique indexes are
+ allowed on your hypertable. Begin by identifying your partitioning columns.
+
+TimescaleDB traditionally uses the following columns to partition hypertables:
+
+* The `time` column used to create the hypertable. Every TimescaleDB hypertable
+ is partitioned by time.
+ * Any space-partitioning columns. Space partitions are optional and not
+ included in every hypertable.
+
+1. **Create a hypertable**
+
+Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes] on data in the columnstore, remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+ If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+1. **Create a unique index on the hypertable**
+
+When you create a unique index on a hypertable, it must contain all the partitioning columns. It may contain
+ other columns as well, and they may be arranged in any order. You cannot create a unique index without `time`,
+ because `time` is a partitioning column.
+
+- Create a unique index on `time` and `device_id` with a call to `CREATE UNIQUE INDEX`:
+
+- Create a unique index on `time`, `user_id`, and `device_id`.
+
+`device_id` is not a partitioning column, but this still works:
+
+This restriction is necessary to guarantee global uniqueness in the index.
+
+## Create a hypertable from an existing table with unique indexes
+
+If you create a unique index on a table before turning it into a hypertable, the
+same restrictions apply in reverse. You can only partition the table by columns
+in your unique index.
+
+1. **Create a relational table**
+
+1. **Create a unique index on the table**
+
+For example, on `device_id` and `time`:
+
+1. **Turn the table into a partitioned hypertable**
+
+- On `time` and `device_id`:
+
+You get an error if you try to turn the relational table into a hypertable partitioned by `time` and `user_id`.
+ This is because `user_id` is not part of the `UNIQUE INDEX`. To fix the error, add `user_id` to your unique index.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypertables/hypertable-crud/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE hypertable_example(
+ time TIMESTAMPTZ,
+ user_id BIGINT,
+ device_id BIGINT,
+ value FLOAT
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby = 'device_id',
+ tsdb.orderby = 'time DESC'
+ );
+```
+
+Example 2 (sql):
+```sql
+CREATE UNIQUE INDEX idx_deviceid_time
+ ON hypertable_example(device_id, time);
+```
+
+Example 3 (sql):
+```sql
+CREATE UNIQUE INDEX idx_userid_deviceid_time
+ ON hypertable_example(user_id, device_id, time);
+```
+
+Example 4 (sql):
+```sql
+CREATE TABLE another_hypertable_example(
+ time TIMESTAMPTZ,
+ user_id BIGINT,
+ device_id BIGINT,
+ value FLOAT
+ );
+```
+
+---
+
+## timescaledb_information.compression_settings
+
+**URL:** llms-txt#timescaledb_information.compression_settings
+
+**Contents:**
+- Samples
+- Available columns
+
+This view exists for backwards compatibility. The supported views to retrieve information about compression are:
+
+- [timescaledb_information.hypertable_compression_settings][hypertable_compression_settings]
+- [timescaledb_information.chunk_compression_settings][chunk_compression_settings].
+
+This section describes a feature that is deprecated. We strongly
+recommend that you do not use this feature in a production environment. If you
+need more information, [contact us](https://www.tigerdata.com/contact/).
+
+Get information about compression-related settings for hypertables.
+Each row of the view provides information about individual `orderby`
+and `segmentby` columns used by compression.
+
+How you use `segmentby` is the single most important thing for compression. It
+affects compresion rates, query performance, and what is compressed or
+decompressed by mutable compression.
+
+The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable_schema` | TEXT | Schema name of the hypertable |
+| `hypertable_name` | TEXT | Table name of the hypertable |
+| `attname` | TEXT | Name of the column used in the compression settings |
+| `segmentby_column_index` | SMALLINT | Position of attname in the compress_segmentby list |
+| `orderby_column_index` | SMALLINT | Position of attname in the compress_orderby list |
+| `orderby_asc` | BOOLEAN | True if this is used for order by ASC, False for order by DESC |
+| `orderby_nullsfirst` | BOOLEAN | True if nulls are ordered first for this column, False if nulls are ordered last|
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/dimensions/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE hypertab (a_col integer, b_col integer, c_col integer, d_col integer, e_col integer);
+SELECT table_name FROM create_hypertable('hypertab', by_range('a_col', 864000000));
+
+ALTER TABLE hypertab SET (timescaledb.compress, timescaledb.compress_segmentby = 'a_col,b_col',
+ timescaledb.compress_orderby = 'c_col desc, d_col asc nulls last');
+
+SELECT * FROM timescaledb_information.compression_settings WHERE hypertable_name = 'hypertab';
+
+-[ RECORD 1 ]----------+---------
+hypertable_schema | public
+hypertable_name | hypertab
+attname | a_col
+segmentby_column_index | 1
+orderby_column_index |
+orderby_asc |
+orderby_nullsfirst |
+-[ RECORD 2 ]----------+---------
+hypertable_schema | public
+hypertable_name | hypertab
+attname | b_col
+segmentby_column_index | 2
+orderby_column_index |
+orderby_asc |
+orderby_nullsfirst |
+-[ RECORD 3 ]----------+---------
+hypertable_schema | public
+hypertable_name | hypertab
+attname | c_col
+segmentby_column_index |
+orderby_column_index | 1
+orderby_asc | f
+orderby_nullsfirst | t
+-[ RECORD 4 ]----------+---------
+hypertable_schema | public
+hypertable_name | hypertab
+attname | d_col
+segmentby_column_index |
+orderby_column_index | 2
+orderby_asc | t
+orderby_nullsfirst | f
+```
+
+---
+
+## Hypertables
+
+**URL:** llms-txt#hypertables
+
+**Contents:**
+- Partition by time
+ - Time partitioning
+- Best practices for scaling and partitioning
+- Hypertable indexes
+- Partition by dimension
+
+Tiger Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables—Postgres tables that automatically partition your time-series data by time and optionally by other dimensions. When you run a query, Tiger Cloud identifies the correct partition, called chunk, and runs the query on it, instead of going through the entire table.
+
+
+
+Hypertables offer the following benefits:
+
+- **Efficient data management with [automated partitioning by time][chunk-size]**: Tiger Cloud splits your data into chunks that hold data from a specific time range. For example, one day or one week. You can configure this range to better suit your needs.
+
+- **Better performance with [strategic indexing][hypertable-indexes]**: an index on time in the descending order is automatically created when you create a hypertable. More indexes are created on the chunk level, to optimize performance. You can create additional indexes, including unique indexes, on the columns you need.
+
+- **Faster queries with [chunk skipping][chunk-skipping]**: Tiger Cloud skips the chunks that are irrelevant in the context of your query, dramatically reducing the time and resources needed to fetch results. Even more—you can enable chunk skipping on non-partitioning columns.
+
+- **Advanced data analysis with [hyperfunctions][hyperfunctions]**: Tiger Cloud enables you to efficiently process, aggregate, and analyze significant volumes of data while maintaining high performance.
+
+To top it all, there is no added complexity—you interact with hypertables in the same way as you would with regular Postgres tables. All the optimization magic happens behind the scenes.
+
+Inheritance is not supported for hypertables and may lead to unexpected behavior.
+
+Each hypertable is partitioned into child hypertables called chunks. Each chunk is assigned
+a range of time, and only contains data from that range.
+
+### Time partitioning
+
+Typically, you partition hypertables on columns that hold time values.
+[Best practice is to use `timestamptz`][timestamps-best-practice] column type. However, you can also partition on
+`date`, `integer`, `timestamp` and [UUIDv7][uuidv7_functions] types.
+
+By default, each hypertable chunk holds data for 7 days. You can change this to better suit your
+needs. For example, if you set `chunk_interval` to 1 day, each chunk stores data for a single day.
+
+TimescaleDB divides time into potential chunk ranges, based on the `chunk_interval`. Each hypertable chunk holds
+data for a specific time range only. When you insert data from a time range that doesn't yet have a chunk, TimescaleDB
+automatically creates a chunk to store it.
+
+In practice, this means that the start time of your earliest chunk does not
+necessarily equal the earliest timestamp in your hypertable. Instead, there
+might be a time gap between the start time and the earliest timestamp. This
+doesn't affect your usual interactions with your hypertable, but might affect
+the number of chunks you see when inspecting it.
+
+## Best practices for scaling and partitioning
+
+Best practices for maintaining a high performance when scaling include:
+
+- Limit the number of hypertables in your service; having tens of thousands of hypertables is not recommended.
+- Choose a strategic chunk size.
+
+Chunk size affects insert and query performance. You want a chunk small enough
+to fit into memory so you can insert and query recent data without
+reading from disk. However, having too many small and sparsely filled chunks can
+affect query planning time and compression. The more chunks in the system, the slower that process becomes, even more so
+when all those chunks are part of a single hypertable.
+
+Postgres builds the index on the fly during ingestion. That means that to build a new entry on the index,
+a significant portion of the index needs to be traversed during every row insertion. When the index does not fit
+into memory, it is constantly flushed to disk and read back. This wastes IO resources which would otherwise
+be used for writing the heap/WAL data to disk.
+
+The default chunk interval is 7 days. However, best practice is to set `chunk_interval` so that prior to processing,
+the indexes for chunks currently being ingested into fit within 25% of main memory. For example, on a system with 64
+GB of memory, if index growth is approximately 2 GB per day, a 1-week chunk interval is appropriate. If index growth is
+around 10 GB per day, use a 1-day interval.
+
+You set `chunk_interval` when you [create a hypertable][hypertable-create-table], or by calling
+[`set_chunk_time_interval`][chunk_interval] on an existing hypertable.
+
+For a detailed analysis of how to optimize your chunk sizes, see the
+[blog post on chunk time intervals][blog-chunk-time]. To learn how
+to view and set your chunk time intervals, see
+[Optimize hypertable chunk intervals][change-chunk-intervals].
+
+## Hypertable indexes
+
+By default, indexes are automatically created when you create a hypertable. The default index is on time, descending.
+You can prevent index creation by setting the `create_default_indexes` option to `false`.
+
+Hypertables have some restrictions on unique constraints and indexes. If you
+want a unique index on a hypertable, it must include all the partitioning
+columns for the table. To learn more, see
+[Enforce constraints with unique indexes on hypertables][hypertables-and-unique-indexes].
+
+You can prevent index creation by setting the `create_default_indexes` option to `false`.
+
+## Partition by dimension
+
+Partitioning on time is the most common use case for hypertable, but it may not be enough for your needs. For example,
+you may need to scan for the latest readings that match a certain condition without locking a critical hypertable.
+
+The use case for a partitioning dimension is a multi-tenant setup. You isolate the tenants using the `tenant_id` space
+partition. However, you must perform extensive testing to ensure this works as expected, and there is a strong risk of
+partition explosion.
+
+You add a partitioning dimension at the same time as you create the hypertable, when the table is empty. The good news
+is that although you select the number of partitions at creation time, as your data grows you can change the number of
+partitions later and improve query performance. Changing the number of partitions only affects chunks created after the
+change, not existing chunks. To set the number of partitions for a partitioning dimension, call `set_number_partitions`.
+For example:
+
+1. **Create the hypertable with the 1-day interval chunk interval**
+
+1. **Add a hash partition on a non-time column**
+
+Now use your hypertable as usual, but you can also ingest and query efficiently by the `device_id` column.
+
+1. **Change the number of partitions as you data grows**
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/hypercore/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions(
+ "time" timestamptz not null,
+ device_id integer,
+ temperature float
+ )
+ WITH(
+ timescaledb.hypertable,
+ timescaledb.partition_column='time',
+ timescaledb.chunk_interval='1 day'
+ );
+```
+
+Example 2 (sql):
+```sql
+select * from add_dimension('conditions', by_hash('device_id', 3));
+```
+
+Example 3 (sql):
+```sql
+select set_number_partitions('conditions', 5, 'device_id');
+```
+
+---
+
+## timescaledb_information.hypertable_compression_settings
+
+**URL:** llms-txt#timescaledb_information.hypertable_compression_settings
+
+**Contents:**
+- Samples
+- Arguments
+
+Shows information about compression settings for each hypertable chunk that has compression enabled on it.
+
+Show compression settings for all hypertables:
+
+Find compression settings for a specific hypertable:
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|`REGCLASS`|Hypertable which has compression enabled|
+|`chunk`|`REGCLASS`|Hypertable chunk which has compression enabled|
+|`segmentby`|`TEXT`|List of columns used for segmenting the compressed data|
+|`orderby`|`TEXT`| List of columns used for ordering compressed data along with ordering and NULL ordering information|
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/compression_settings/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_compression_settings;
+hypertable | measurements
+chunk | _timescaledb_internal._hyper_2_97_chunk
+segmentby |
+orderby | time DESC
+```
+
+Example 2 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_compression_settings WHERE hypertable::TEXT LIKE 'metrics';
+hypertable | metrics
+chunk | _timescaledb_internal._hyper_1_12_chunk
+segmentby | metric_id
+orderby | time DESC
+```
+
+---
+
+## move_chunk()
+
+**URL:** llms-txt#move_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+TimescaleDB allows you to move data and indexes to different tablespaces. This
+allows you to move data to more cost-effective storage as it ages.
+
+The `move_chunk` function acts like a combination of the
+[Postgres CLUSTER command][postgres-cluster] and
+[Postgres ALTER TABLE...SET TABLESPACE][postgres-altertable] commands. Unlike
+these Postgres commands, however, the `move_chunk` function uses lower lock
+levels so that the chunk and hypertable are able to be read for most of the
+process. This comes at a cost of slightly higher disk usage during the
+operation. For a more detailed discussion of this capability, see the
+documentation on [managing storage with tablespaces][manage-storage].
+
+You must be logged in as a super user, such as the `postgres` user,
+to use the `move_chunk()` call.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`chunk`|REGCLASS|Name of chunk to be moved|
+|`destination_tablespace`|NAME|Target tablespace for chunk being moved|
+|`index_destination_tablespace`|NAME|Target tablespace for index associated with the chunk you are moving|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`reorder_index`|REGCLASS|The name of the index (on either the hypertable or chunk) to order by|
+|`verbose`|BOOLEAN|Setting to true displays messages about the progress of the move_chunk command. Defaults to false.|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/hypertable_index_size/ =====
+
+---
+
+## Logical backup with pg_dump and pg_restore
+
+**URL:** llms-txt#logical-backup-with-pg_dump-and-pg_restore
+
+**Contents:**
+- Prerequisites
+- Back up and restore an entire database
+- Back up and restore individual hypertables
+
+You back up and restore each self-hosted Postgres database with TimescaleDB enabled using the native
+Postgres [`pg_dump`][pg_dump] and [`pg_restore`][pg_restore] commands. This also works for compressed hypertables,
+you don't have to decompress the chunks before you begin.
+
+If you are using `pg_dump` to backup regularly, make sure you keep
+track of the versions of Postgres and TimescaleDB you are running. For more
+information, see [Versions are mismatched when dumping and restoring a database][troubleshooting-version-mismatch].
+
+This page shows you how to:
+
+- [Back up and restore an entire database][backup-entire-database]
+- [Back up and restore individual hypertables][backup-individual-tables]
+
+You can also [upgrade between different versions of TimescaleDB][timescaledb-upgrade].
+
+- A source database to backup from, and a target database to restore to.
+- Install the `psql` and `pg_dump` Postgres client tools on your migration machine.
+
+## Back up and restore an entire database
+
+You backup and restore an entire database using `pg_dump` and `psql`.
+
+1. **Set your connection strings**
+
+These variables hold the connection information for the source database to backup from and
+ the target database to restore to:
+
+1. **Backup your database**
+
+You may see some errors while `pg_dump` is running. See [Troubleshooting self-hosted TimescaleDB][troubleshooting]
+ to check if they can be safely ignored.
+
+1. **Restore your database from the backup**
+
+1. Connect to your target database:
+
+1. Create a new database and enable TimescaleDB:
+
+1. Put your database in the right state for restoring:
+
+1. Restore the database:
+
+1. Return your database to normal operations:
+
+Do not use `pg_restore` with the `-j` option. This option does not correctly restore the
+ TimescaleDB catalogs.
+
+## Back up and restore individual hypertables
+
+`pg_dump` provides flags that allow you to specify tables or schemas
+to back up. However, using these flags means that the dump lacks necessary
+information that TimescaleDB requires to understand the relationship between
+them. Even if you explicitly specify both the hypertable and all of its
+constituent chunks, the dump would still not contain all the information it
+needs to recreate the hypertable on restore.
+
+To backup individual hypertables, backup the database schema, then backup only the tables
+you need. You also use this method to backup individual plain tables.
+
+1. **Set your connection strings**
+
+These variables hold the connection information for the source database to backup from and
+ the target database to restore to:
+
+1. **Backup the database schema and individual tables**
+
+1. Back up the hypertable schema:
+
+1. Backup hypertable data to a CSV file:
+
+For each hypertable to backup:
+
+1. **Restore the schema to the target database**
+
+1. **Restore hypertables from the backup**
+
+For each hypertable to backup:
+ 1. Recreate the hypertable:
+
+When you [create the new hypertable][create_hypertable], you do not need to use the
+ same parameters as existed in the source database. This
+ can provide a good opportunity for you to re-organize your hypertables if
+ you need to. For example, you can change the partitioning key, the number of
+ partitions, or the chunk interval sizes.
+
+1. Restore the data:
+
+The standard `COPY` command in Postgres is single threaded. If you have a
+ lot of data, you can speed up the copy using the [timescaledb-parallel-copy][parallel importer].
+
+Best practice is to backup and restore a database at a time. However, if you have superuser access to
+Postgres instance with TimescaleDB installed, you can use `pg_dumpall` to back up all Postgres databases in a
+cluster, including global objects that are common to all databases, namely database roles, tablespaces,
+and privilege grants. You restore the Postgres instance using `psql`. For more information, see the
+[Postgres documentation][postgres-docs].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/backup-and-restore/physical/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+export SOURCE=postgres://:@:/
+ export TARGET=postgres://:@:
+```
+
+Example 2 (bash):
+```bash
+pg_dump -d "source" \
+ -Fc -f .bak
+```
+
+Example 3 (bash):
+```bash
+psql -d "target"
+```
+
+Example 4 (sql):
+```sql
+CREATE DATABASE ;
+ \c
+ CREATE EXTENSION IF NOT EXISTS timescaledb;
+```
+
+---
+
+## CREATE INDEX (Transaction Per Chunk)
+
+**URL:** llms-txt#create-index-(transaction-per-chunk)
+
+**Contents:**
+- Samples
+
+This option extends [`CREATE INDEX`][postgres-createindex] with the ability to
+use a separate transaction for each chunk it creates an index on, instead of
+using a single transaction for the entire hypertable. This allows `INSERT`s, and
+other operations to be performed concurrently during most of the duration of the
+`CREATE INDEX` command. While the index is being created on an individual chunk,
+it functions as if a regular `CREATE INDEX` were called on that chunk, however
+other chunks are completely unblocked.
+
+This version of `CREATE INDEX` can be used as an alternative to
+`CREATE INDEX CONCURRENTLY`, which is not currently supported on hypertables.
+
+- Not supported for `CREATE UNIQUE INDEX`.
+- If the operation fails partway through, indexes might not be created on all
+hypertable chunks. If this occurs, the index on the root table of the hypertable
+is marked as invalid. You can check this by running `\d+` on the hypertable. The
+index still works, and is created on new chunks, but if you want to ensure all
+chunks have a copy of the index, drop and recreate it.
+
+You can also use the following query to find all invalid indexes:
+
+Create an anonymous index:
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/refresh_continuous_aggregate/ =====
+
+**Examples:**
+
+Example 1 (SQL):
+```SQL
+CREATE INDEX ... WITH (timescaledb.transaction_per_chunk, ...);
+```
+
+Example 2 (SQL):
+```SQL
+SELECT * FROM pg_index i WHERE i.indisvalid IS FALSE;
+```
+
+Example 3 (SQL):
+```SQL
+CREATE INDEX ON conditions(time, device_id)
+ WITH (timescaledb.transaction_per_chunk);
+```
+
+Example 4 (SQL):
+```SQL
+CREATE INDEX ON conditions USING brin(time, location)
+ WITH (timescaledb.transaction_per_chunk);
+```
+
+---
+
+## set_replication_factor()
+
+**URL:** llms-txt#set_replication_factor()
+
+**Contents:**
+- Required arguments
+ - Errors
+- Sample usage
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Sets the replication factor of a distributed hypertable to the given value.
+Changing the replication factor does not affect the number of replicas for existing chunks.
+Chunks created after changing the replication factor are replicated
+in accordance with new value of the replication factor. If the replication factor cannot be
+satisfied, since the amount of attached data nodes is less than new replication factor,
+the command aborts with an error.
+
+If existing chunks have less replicas than new value of the replication factor,
+the function prints a warning.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Distributed hypertable to update the replication factor for.|
+| `replication_factor` | INTEGER | The new value of the replication factor. Must be greater than 0, and smaller than or equal to the number of attached data nodes.|
+
+An error is given if:
+
+* `hypertable` is not a distributed hypertable.
+* `replication_factor` is less than `1`, which cannot be set on a distributed hypertable.
+* `replication_factor` is bigger than the number of attached data nodes.
+
+If a bigger replication factor is desired, it is necessary to attach more data nodes
+by using [attach_data_node][attach_data_node].
+
+Update the replication factor for a distributed hypertable to `2`:
+
+Example of the warning if any existing chunk of the distributed hypertable has less than 2 replicas:
+
+Example of providing too big of a replication factor for a hypertable with 2 attached data nodes:
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/delete_data_node/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT set_replication_factor('conditions', 2);
+```
+
+Example 2 (unknown):
+```unknown
+WARNING: hypertable "conditions" is under-replicated
+DETAIL: Some chunks have less than 2 replicas.
+```
+
+Example 3 (sql):
+```sql
+SELECT set_replication_factor('conditions', 3);
+ERROR: too big replication factor for hypertable "conditions"
+DETAIL: The hypertable has 2 data nodes attached, while the replication factor is 3.
+HINT: Decrease the replication factor or attach more data nodes to the hypertable.
+```
+
+---
+
+## About indexes
+
+**URL:** llms-txt#about-indexes
+
+Because looking up data can take a long time, especially if you have a lot of
+data in your hypertable, you can use an index to speed up read operations from
+non-compressed chunks in the rowstore (which use their [own columnar indexes][about-compression]).
+
+You can create an index on any combination of columns. To define an index as a `UNIQUE` or `PRIMARY KEY` index, it must include the partitioning column (this is usually the time column).
+
+Which column you choose to create your
+index on depends on what kind of data you have stored.
+When you create a hypertable, set the datatype for the `time` column as
+`timestamptz` and not `timestamp`.
+For more information, see [Postgres timestamp][postgresql-timestamp].
+
+While it is possible to add an index that does not include the `time` column,
+doing so results in very slow ingest speeds. For time-series data, indexing
+on the time column allows one index to be created per chunk.
+
+Consider a simple example with temperatures collected from two locations named
+`office` and `garage`:
+
+An index on `(location, time DESC)` is organized like this:
+
+An index on `(time DESC, location)` is organized like this:
+
+A good rule of thumb with indexes is to think in layers. Start by choosing the
+columns that you typically want to run equality operators on, such as
+`location = garage`. Then finish by choosing columns you want to use range
+operators on, such as `time > 0930`.
+
+As a more complex example, imagine you have a number of devices tracking
+1,000 different retail stores. You have 100 devices per store, and 5 different
+types of devices. All of these devices report metrics as `float` values, and you
+decide to store all the metrics in the same table, like this:
+
+When you create this table, an index is automatically generated on the time
+column, making it faster to query your data based on time.
+
+If you want to query your data on something other than time, you can create
+different indexes. For example, you might want to query data from the last month
+for just a given `device_id`. Or you could query all data for a single
+`store_id` for the last three months.
+
+You want to keep the index on time so that you can quickly filter for a given
+time range, and add another index on `device_id` and `store_id`. This creates a
+composite index. A composite index on `(store_id, device_id, time)` orders by
+`store_id` first. Each unique `store_id`, will then be sorted by `device_id` in
+order. And each entry with the same `store_id` and `device_id` are then ordered
+by `time`. To create this index, use this command:
+
+When you have this composite index on your hypertable, you can run a range of
+different queries. Here are some examples:
+
+This queries the portion of the list with a specific `store_id`. The index is
+effective for this query, but could be a bit bloated; an index on just
+`store_id` would probably be more efficient.
+
+This query is not effective, because it would need to scan multiple sections of
+the list. This is because the part of the list that contains data for
+`time > 10` for one device would be located in a different section than for a
+different device. In this case, consider building an index on `(store_id, time)`
+instead.
+
+The index in the example is useless for this query, because the data for
+`device M` is located in a completely different section of the list for each
+`store_id`.
+
+This is an accurate query for this index. It narrows down the list to a very
+specific portion.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/json/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+garage-0940
+garage-0930
+garage-0920
+garage-0910
+office-0930
+office-0920
+office-0910
+```
+
+Example 2 (sql):
+```sql
+0940-garage
+0930-garage
+0930-office
+0920-garage
+0920-office
+0910-garage
+0910-office
+```
+
+Example 3 (sql):
+```sql
+CREATE TABLE devices (
+ time timestamptz,
+ device_id int,
+ device_type int,
+ store_id int,
+ value float
+);
+```
+
+Example 4 (sql):
+```sql
+CREATE INDEX ON devices (store_id, device_id, time DESC);
+```
+
+---
+
+## User permissions do not allow chunks to be converted to columnstore or rowstore
+
+**URL:** llms-txt#user-permissions-do-not-allow-chunks-to-be-converted-to-columnstore-or-rowstore
+
+
+
+You might get this error if you attempt to compress a chunk into the columnstore, or decompress it back into rowstore with a non-privileged user
+account. To compress or decompress a chunk, your user account must have permissions that allow it to perform `CREATE INDEX` on the
+chunk. You can check the permissions of the current user with this command at
+the `psql` command prompt:
+
+To resolve this problem, grant your user account the appropriate privileges with
+this command:
+
+For more information about the `GRANT` command, see the
+[Postgres documentation][pg-grant].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/compression-inefficient-chunk-interval/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+\dn+
+```
+
+Example 2 (sql):
+```sql
+GRANT PRIVILEGES
+ ON TABLE
+ TO ;
+```
+
+---
+
+## Query data in distributed hypertables
+
+**URL:** llms-txt#query-data-in-distributed-hypertables
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+You can query a distributed hypertable just as you would query a standard
+hypertable or Postgres table. For more information, see the section on
+[writing data][write].
+
+Queries perform best when the access node can push transactions down to the data
+nodes. To ensure that the access node can push down transactions, check that the
+[`enable_partitionwise_aggregate`][enable_partitionwise_aggregate] setting is
+set to `on` for the access node. By default, it is `off`.
+
+If you want to use continuous aggregates on your distributed hypertable, see the
+[continuous aggregates][caggs] section for more information.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/distributed-hypertables/about-distributed-hypertables/ =====
+
+---
+
+## convert_to_columnstore()
+
+**URL:** llms-txt#convert_to_columnstore()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Manually convert a specific chunk in the hypertable rowstore to the columnstore.
+
+Although `convert_to_columnstore` gives you more fine-grained control, best practice is to use
+[`add_columnstore_policy`][add_columnstore_policy]. You can also add chunks to the columnstore at a specific time
+[running the job associated with your columnstore policy][run-job] manually.
+
+To move a chunk from the columnstore back to the rowstore, use [`convert_to_rowstore`][convert_to_rowstore].
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To convert a single chunk to columnstore:
+
+| Name | Type | Default | Required | Description |
+|----------------------|--|---------|--|----------------------------------------------------------------------------------------------------------------------------------------------------|
+| `chunk` | REGCLASS | - |✔| Name of the chunk to add to the columnstore. |
+| `if_not_columnstore` | BOOLEAN | `true` |✖| Set to `false` so this job fails with an error rather than a warning if `chunk` is already in the columnstore. |
+| `recompress` | BOOLEAN | `false` |✖| Set to `true` to add a chunk that had more data inserted after being added to the columnstore. |
+
+Calls to `convert_to_columnstore` return:
+
+| Column | Type | Description |
+|-------------------|--------------------|----------------------------------------------------------------------------------------------------|
+| `chunk name` or `table` | REGCLASS or String | The name of the chunk added to the columnstore, or a table-like result set with zero or more rows. |
+
+===== PAGE: https://docs.tigerdata.com/api/compression/decompress_chunk/ =====
+
+---
+
+## attach_chunk()
+
+**URL:** llms-txt#attach_chunk()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+Attach a hypertable as a chunk in another [hypertable][hypertables-section] at a given slice in a dimension.
+
+
+
+The schema, name, existing constraints, and indexes of `chunk` do not change, even
+if a constraint conflicts with a chunk constraint in `hypertable`.
+
+The `hypertable` you attach `chunk` to does not need to have the same dimension columns as the
+hypertable you previously [detached `chunk`][hypertable-detach-chunk] from.
+
+While attaching `chunk` to `hypertable`:
+- Dimension columns in `chunk` are set as `NOT NULL`.
+- Any foreign keys in `hypertable` are created in `chunk`.
+
+You cannot:
+- Attaching a chunk that is still attached to another hypertable. First call [detach_chunk][hypertable-detach-chunk].
+- Attaching foreign tables are not supported.
+
+Since [TimescaleDB v2.21.0](https://github.com/timescale/timescaledb/releases/tag/2.21.0)
+
+Attach a hypertable as a chunk in another hypertable for a specific slice in a dimension:
+
+|Name|Type| Description |
+|---|---|-----------------------------------------------------------------------------------------------------------------------------------------------|
+| `hypertable` | REGCLASS | Name of the hypertable to attach `chunk` to. |
+| `chunk` | REGCLASS | Name of the chunk to attach. |
+| `slices` | JSONB | The slice `chunk` will occupy in `hypertable`. `slices` cannot clash with the slice already occupied by an existing chunk in `hypertable`. |
+
+This function returns void.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/detach_tablespaces/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CALL attach_chunk('ht', '_timescaledb_internal._hyper_1_2_chunk', '{"device_id": [0, 1000]}');
+```
+
+---
+
+## compress_chunk()
+
+**URL:** llms-txt#compress_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by convert_to_columnstore().
+
+The `compress_chunk` function is used for synchronous compression (or recompression, if necessary) of
+a specific chunk. This is most often used instead of the
+[`add_compression_policy`][add_compression_policy] function, when a user
+wants more control over the scheduling of compression. For most users, we
+suggest using the policy framework instead.
+
+You can also compress chunks by
+[running the job associated with your compression policy][run-job].
+`compress_chunk` gives you more fine-grained control by
+allowing you to target a specific chunk that needs compressing.
+
+You can get a list of chunks belonging to a hypertable using the
+[`show_chunks` function](https://docs.tigerdata.com/api/latest/hypertable/show_chunks/).
+
+Compress a single chunk.
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `chunk_name` | REGCLASS | Name of the chunk to be compressed|
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `if_not_compressed` | BOOLEAN | Disabling this will make the function error out on chunks that are already compressed. Defaults to true.|
+
+|Column|Type|Description|
+|---|---|---|
+| `compress_chunk` | REGCLASS | Name of the chunk that was compressed|
+
+===== PAGE: https://docs.tigerdata.com/api/compression/chunk_compression_stats/ =====
+
+---
+
+## About distributed hypertables
+
+**URL:** llms-txt#about-distributed-hypertables
+
+**Contents:**
+- Architecture of a distributed hypertable
+- Space partitioning
+ - Closed and open dimensions for space partitioning
+ - Repartitioning distributed hypertables
+- Replicating distributed hypertables
+- Performance of distributed hypertables
+- Query push down
+ - Full push down
+ - Partial push down
+ - Limitations of query push down
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Distributed hypertables are hypertables that span multiple nodes. With
+distributed hypertables, you can scale your data storage across multiple
+machines. The database can also parallelize some inserts and queries.
+
+A distributed hypertable still acts as if it were a single table. You can work
+with one in the same way as working with a standard hypertable. To learn more
+about hypertables, see the [hypertables section][hypertables].
+
+Certain nuances can affect distributed hypertable performance. This section
+explains how distributed hypertables work, and what you need to consider before
+adopting one.
+
+## Architecture of a distributed hypertable
+
+Distributed hypertables are used with multi-node clusters. Each cluster has an
+access node and multiple data nodes. You connect to your database using the
+access node, and the data is stored on the data nodes. For more information
+about multi-node, see the [multi-node section][multi-node].
+
+You create a distributed hypertable on your access node. Its chunks are stored
+on the data nodes. When you insert data or run a query, the access node
+communicates with the relevant data nodes and pushes down any processing if it
+can.
+
+## Space partitioning
+
+Distributed hypertables are always partitioned by time, just like standard
+hypertables. But unlike standard hypertables, distributed hypertables should
+also be partitioned by space. This allows you to balance inserts and queries
+between data nodes, similar to traditional sharding. Without space partitioning,
+all data in the same time range would write to the same chunk on a single node.
+
+By default, TimescaleDB creates as many space partitions as there are data
+nodes. You can change this number, but having too many space partitions degrades
+performance. It increases planning time for some queries, and leads to poorer
+balancing when mapping items to partitions.
+
+Data is assigned to space partitions by hashing. Each hash bucket in the space
+dimension corresponds to a data node. One data node may hold many buckets, but
+each bucket may belong to only one node for each time interval.
+
+When space partitioning is on, 2 dimensions are used to divide data into chunks:
+the time dimension and the space dimension. You can specify the number of
+partitions along the space dimension. Data is assigned to a partition by hashing
+its value on that dimension.
+
+For example, say you use `device_id` as a space partitioning column. For each
+row, the value of the `device_id` column is hashed. Then the row is inserted
+into the correct partition for that hash value.
+
+![]() +
+### Closed and open dimensions for space partitioning
+
+Space partitioning dimensions can be open or closed. A closed dimension has a
+fixed number of partitions, and usually uses some hashing to match values to
+partitions. An open dimension does not have a fixed number of partitions, and
+usually has each chunk cover a certain range. In most cases the time dimension
+is open and the space dimension is closed.
+
+If you use the `create_hypertable` command to create your hypertable, then the
+space dimension is open, and there is no way to adjust this. To create a
+hypertable with a closed space dimension, create the hypertable with only the
+time dimension first. Then use the `add_dimension` command to explicitly add an
+open device. If you set the range to `1`, each device has its own chunks. This
+can help you work around some limitations of regular space dimensions, and is
+especially useful if you want to make some chunks readily available for
+exclusion.
+
+### Repartitioning distributed hypertables
+
+You can expand distributed hypertables by adding additional data nodes. If you
+now have fewer space partitions than data nodes, you need to increase the
+number of space partitions to make use of your new nodes. The new partitioning
+configuration only affects new chunks. In this diagram, an extra data node
+was added during the third time interval. The fourth time interval now includes
+four chunks, while the previous time intervals still include three:
+
+
+
+### Closed and open dimensions for space partitioning
+
+Space partitioning dimensions can be open or closed. A closed dimension has a
+fixed number of partitions, and usually uses some hashing to match values to
+partitions. An open dimension does not have a fixed number of partitions, and
+usually has each chunk cover a certain range. In most cases the time dimension
+is open and the space dimension is closed.
+
+If you use the `create_hypertable` command to create your hypertable, then the
+space dimension is open, and there is no way to adjust this. To create a
+hypertable with a closed space dimension, create the hypertable with only the
+time dimension first. Then use the `add_dimension` command to explicitly add an
+open device. If you set the range to `1`, each device has its own chunks. This
+can help you work around some limitations of regular space dimensions, and is
+especially useful if you want to make some chunks readily available for
+exclusion.
+
+### Repartitioning distributed hypertables
+
+You can expand distributed hypertables by adding additional data nodes. If you
+now have fewer space partitions than data nodes, you need to increase the
+number of space partitions to make use of your new nodes. The new partitioning
+configuration only affects new chunks. In this diagram, an extra data node
+was added during the third time interval. The fourth time interval now includes
+four chunks, while the previous time intervals still include three:
+
+![]() +
+This can affect queries that span the two different partitioning configurations.
+For more information, see the section on
+[limitations of query push down][limitations].
+
+## Replicating distributed hypertables
+
+To replicate distributed hypertables at the chunk level, configure the
+hypertables to write each chunk to multiple data nodes. This native replication
+ensures that a distributed hypertable is protected against data node failures
+and provides an alternative to fully replicating each data node using streaming
+replication to provide high availability. Only the data nodes are replicated
+using this method. The access node is not replicated.
+
+For more information about replication and high availability, see the
+[multi-node HA section][multi-node-ha].
+
+## Performance of distributed hypertables
+
+A distributed hypertable horizontally scales your data storage, so you're not
+limited by the storage of any single machine. It also increases performance for
+some queries.
+
+Whether, and by how much, your performance increases depends on your query
+patterns and data partitioning. Performance increases when the access node can
+push down query processing to data nodes. For example, if you query with a
+`GROUP BY` clause, and the data is partitioned by the `GROUP BY` column, the
+data nodes can perform the processing and send only the final results to the
+access node.
+
+If processing can't be done on the data nodes, the access node needs to pull in
+raw or partially processed data and do the processing locally. For more
+information, see the [limitations of pushing down
+queries][limitations-pushing-down].
+
+The access node can use a full or a partial method to push down queries.
+Computations that can be pushed down include sorts and groupings. Joins on data
+nodes aren't currently supported.
+
+To see how a query is pushed down to a data node, use `EXPLAIN VERBOSE` to
+inspect the query plan and the remote SQL statement sent to each data node.
+
+In the full push-down method, the access node offloads all computation to the
+data nodes. It receives final results from the data nodes and appends them. To
+fully push down an aggregate query, the `GROUP BY` clause must include either:
+
+* All the partitioning columns _or_
+* Only the first space-partitioning column
+
+For example, say that you want to calculate the `max` temperature for each
+location:
+
+If `location` is your only space partition, each data node can compute the
+maximum on its own subset of the data.
+
+### Partial push down
+
+In the partial push-down method, the access node offloads most of the
+computation to the data nodes. It receives partial results from the data nodes
+and calculates a final aggregate by combining the partials.
+
+For example, say that you want to calculate the `max` temperature across all
+locations. Each data node computes a local maximum, and the access node computes
+the final result by computing the maximum of all the local maximums:
+
+### Limitations of query push down
+
+Distributed hypertables get improved performance when they can push down queries
+to the data nodes. But the query planner might not be able to push down every
+query. Or it might only be able to partially push down a query. This can occur
+for several reasons:
+
+* You changed the partitioning configuration. For example, you added new data
+ nodes and increased the number of space partitions to match. This can cause
+ chunks for the same space value to be stored on different nodes. For
+ instance, say you partition by `device_id`. You start with 3 partitions, and
+ data for `device_B` is stored on node 3. You later increase to 4 partitions.
+ New chunks for `device_B` are now stored on node 4. If you query across the
+ repartitioning boundary, a final aggregate for `device_B` cannot be
+ calculated on node 3 or node 4 alone. Partially processed data must be sent
+ to the access node for final aggregation. The TimescaleDB query planner
+ dynamically detects such overlapping chunks and reverts to the appropriate
+ partial aggregation plan. This means that you can add data nodes and
+ repartition your data to achieve elasticity without worrying about query
+ results. In some cases, your query could be slightly less performant, but
+ this is rare and the affected chunks usually move quickly out of your
+ retention window.
+* The query includes [non-immutable functions][volatility] and expressions.
+ The function cannot be pushed down to the data node, because by definition,
+ it isn't guaranteed to have a consistent result across each node. An example
+ non-immutable function is [`random()`][random-func], which depends on the
+ current seed.
+* The query includes a job function. The access node assumes the
+ function doesn't exist on the data nodes, and doesn't push it down.
+
+TimescaleDB uses several optimizations to avoid these limitations, and push down
+as many queries as possible. For example, `now()` is a non-immutable function.
+The database converts it to a constant on the access node and pushes down the
+constant timestamp to the data nodes.
+
+## Combine distributed hypertables and standard hypertables
+
+You can use distributed hypertables in the same database as standard hypertables
+and standard Postgres tables. This mostly works the same way as having
+multiple standard tables, with a few differences. For example, if you `JOIN` a
+standard table and a distributed hypertable, the access node needs to fetch the
+raw data from the data nodes and perform the `JOIN` locally.
+
+All the limitations of regular hypertables also apply to distributed
+hypertables. In addition, the following limitations apply specifically
+to distributed hypertables:
+
+* Distributed scheduling of background jobs is not supported. Background jobs
+ created on an access node are scheduled and executed on this access node
+ without distributing the jobs to data nodes.
+* Continuous aggregates can aggregate data distributed across data nodes, but
+ the continuous aggregate itself must live on the access node. This could
+ create a limitation on how far you can scale your installation, but because
+ continuous aggregates are downsamples of the data, this does not usually
+ create a problem.
+* Reordering chunks is not supported.
+* Tablespaces cannot be attached to a distributed hypertable on the access
+ node. It is still possible to attach tablespaces on data nodes.
+* Roles and permissions are assumed to be consistent across the nodes of a
+ distributed database, but consistency is not enforced.
+* Joins on data nodes are not supported. Joining a distributed hypertable with
+ another table requires the other table to reside on the access node. This
+ also limits the performance of joins on distributed hypertables.
+* Tables referenced by foreign key constraints in a distributed hypertable
+ must be present on the access node and all data nodes. This applies also to
+ referenced values.
+* Parallel-aware scans and appends are not supported.
+* Distributed hypertables do not natively provide a consistent restore point
+ for backup and restore across nodes. Use the
+ [`create_distributed_restore_point`][create_distributed_restore_point]
+ command, and make sure you take care when you restore individual backups to
+ access and data nodes.
+* For native replication limitations, see the
+ [native replication section][native-replication].
+* User defined functions have to be manually installed on the data nodes so
+ that the function definition is available on both access and data nodes.
+ This is particularly relevant for functions that are registered with
+ `set_integer_now_func`.
+
+Note that these limitations concern usage from the access node. Some
+currently unsupported features might still work on individual data nodes,
+but such usage is neither tested nor officially supported. Future versions
+of TimescaleDB might remove some of these limitations.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/backup-and-restore/logical-backup/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT location, max(temperature)
+ FROM conditions
+ GROUP BY location;
+```
+
+Example 2 (sql):
+```sql
+SELECT max(temperature) FROM conditions;
+```
+
+---
+
+## reorder_chunk()
+
+**URL:** llms-txt#reorder_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Reorder a single chunk's heap to follow the order of an index. This function
+acts similarly to the [Postgres CLUSTER command][postgres-cluster] , however
+it uses lower lock levels so that, unlike with the CLUSTER command, the chunk
+and hypertable are able to be read for most of the process. It does use a bit
+more disk space during the operation.
+
+This command can be particularly useful when data is often queried in an order
+different from that in which it was originally inserted. For example, data is
+commonly inserted into a hypertable in loose time order (for example, many devices
+concurrently sending their current state), but one might typically query the
+hypertable about a _specific_ device. In such cases, reordering a chunk using an
+index on `(device_id, time)` can lead to significant performance improvement for
+these types of queries.
+
+One can call this function directly on individual chunks of a hypertable, but
+using [add_reorder_policy][add_reorder_policy] is often much more convenient.
+
+Reorder a chunk on an index:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `chunk` | REGCLASS | Name of the chunk to reorder. |
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `index` | REGCLASS | The name of the index (on either the hypertable or chunk) to order by.|
+| `verbose` | BOOLEAN | Setting to true displays messages about the progress of the reorder command. Defaults to false.|
+
+This function returns void.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/add_reorder_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT reorder_chunk('_timescaledb_internal._hyper_1_10_chunk', '_timescaledb_internal.conditions_device_id_time_idx');
+```
+
+---
+
+## create_distributed_hypertable()
+
+**URL:** llms-txt#create_distributed_hypertable()
+
+**Contents:**
+- Required arguments
+- Optional arguments
+- Returns
+- Sample usage
+ - Best practices
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Create a TimescaleDB hypertable distributed across a multinode environment.
+
+`create_distributed_hypertable()` replaces [`create_hypertable() (old interface)`][create-hypertable-old]. Distributed tables use the old API. The new generalized [`create_hypertable`][create-hypertable-new] API was introduced in TimescaleDB v2.13.
+
+## Required arguments
+
+|Name|Type| Description |
+|---|---|----------------------------------------------------------------------------------------------|
+| `relation` | REGCLASS | Identifier of the table you want to convert to a hypertable. |
+| `time_column_name` | TEXT | Name of the column that contains time values, as well as the primary column to partition by. |
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `partitioning_column` | TEXT | Name of an additional column to partition by. |
+| `number_partitions` | INTEGER | Number of hash partitions to use for `partitioning_column`. Must be > 0. Default is the number of `data_nodes`. |
+| `associated_schema_name` | TEXT | Name of the schema for internal hypertable tables. Default is `_timescaledb_internal`. |
+| `associated_table_prefix` | TEXT | Prefix for internal hypertable chunk names. Default is `_hyper`. |
+| `chunk_time_interval` | INTERVAL | Interval in event time that each chunk covers. Must be > 0. Default is 7 days. |
+| `create_default_indexes` | BOOLEAN | Boolean whether to create default indexes on time/partitioning columns. Default is TRUE. |
+| `if_not_exists` | BOOLEAN | Boolean whether to print warning if table already converted to hypertable or raise exception. Default is FALSE. |
+| `partitioning_func` | REGCLASS | The function to use for calculating a value's partition.|
+| `migrate_data` | BOOLEAN | Set to TRUE to migrate any existing data from the `relation` table to chunks in the new hypertable. A non-empty table generates an error without this option. Large tables may take significant time to migrate. Default is FALSE. |
+| `time_partitioning_func` | REGCLASS | Function to convert incompatible primary time column values to compatible ones. The function must be `IMMUTABLE`. |
+| `replication_factor` | INTEGER | The number of data nodes to which the same data is written to. This is done by creating chunk copies on this amount of data nodes. Must be >= 1; If not set, the default value is determined by the `timescaledb.hypertable_replication_factor_default` GUC. Read [the best practices][best-practices] before changing the default. |
+| `data_nodes` | ARRAY | The set of data nodes used for the distributed hypertable. If not present, defaults to all data nodes known by the access node (the node on which the distributed hypertable is created). |
+
+|Column|Type|Description|
+|---|---|---|
+| `hypertable_id` | INTEGER | ID of the hypertable in TimescaleDB. |
+| `schema_name` | TEXT | Schema name of the table converted to hypertable. |
+| `table_name` | TEXT | Table name of the table converted to hypertable. |
+| `created` | BOOLEAN | TRUE if the hypertable was created, FALSE when `if_not_exists` is TRUE and no hypertable was created. |
+
+Create a table `conditions` which is partitioned across data
+nodes by the 'location' column. Note that the number of space
+partitions is automatically equal to the number of data nodes assigned
+to this hypertable (all configured data nodes in this case, as
+`data_nodes` is not specified).
+
+Create a table `conditions` using a specific set of data nodes.
+
+* **Hash partitions**: Best practice for distributed hypertables is to enable [hash partitions](https://www.techopedia.com/definition/31996/hash-partitioning).
+ With hash partitions, incoming data is divided between the data nodes. Without hash partition, all
+ data for each time slice is written to a single data node.
+
+* **Time intervals**: Follow the guidelines for `chunk_time_interval` defined in [`create_hypertable`]
+ [create-hypertable-old].
+
+When you enable hash partitioning, the hypertable is evenly distributed across the data nodes. This
+ means you can set a larger time interval. For example, you ingest 10 GB of data per day shared over
+ five data nodes, each node has 64 GB of memory. If this is the only table being served by these data nodes, use a time interval of 1 week:
+
+If you do not enable hash partitioning, use the same `chunk_time_interval` settings as a non-distributed
+ instance. This is because all incoming data is handled by a single node.
+
+* **Replication factor**: `replication_factor` defines the number of data nodes a newly created chunk is
+ replicated in. For example, when you set `replication_factor` to `3`, each chunk exists on 3 separate
+ data nodes. Rows written to a chunk are inserted into all data notes in a two-phase commit protocol.
+
+If a data node fails or is removed, no data is lost. Writes succeed on the other data nodes. However, the
+ chunks on the lost data node are now under-replicated. When the failed data node becomes available, rebalance the chunks with a call to [copy_chunk][copy_chunk].
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/attach_data_node/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location');
+```
+
+Example 2 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location',
+ data_nodes => '{ "data_node_1", "data_node_2", "data_node_4", "data_node_7" }');
+```
+
+Example 3 (unknown):
+```unknown
+7 days * 10 GB 70
+ -------------------- == --- ~= 22% of main memory used for the most recent chunks
+ 5 data nodes * 64 GB 320
+```
+
+---
+
+## Manual compression
+
+**URL:** llms-txt#manual-compression
+
+**Contents:**
+ - Selecting chunks to compress
+ - Compressing chunks manually
+- Manually compress chunks in a single command
+- Roll up uncompressed chunks when compressing
+
+In most cases, an [automated compression policy][add_compression_policy] is sufficient to automatically compress your
+chunks. However, if you want more control, you can also use manual synchronous compression of specific chunks.
+
+Before you start, you need a list of chunks to compress. In this example, you
+use a hypertable called `example`, and compress chunks older than three days.
+
+### Selecting chunks to compress
+
+1. At the psql prompt, select all chunks in the table `example` that are older
+ than three days:
+
+1. This returns a list of chunks. Take note of the chunks' names:
+
+||show_chunks|
+ |---|---|
+ |1|_timescaledb_internal_hyper_1_2_chunk|
+ |2|_timescaledb_internal_hyper_1_3_chunk|
+
+When you are happy with the list of chunks, you can use the chunk names to
+manually compress each one.
+
+### Compressing chunks manually
+
+1. At the psql prompt, compress the chunk:
+
+1. Check the results of the compression with this command:
+
+The results show the chunks for the given hypertable, their compression
+ status, and some other statistics:
+
+|chunk_schema|chunk_name|compression_status|before_compression_table_bytes|before_compression_index_bytes|before_compression_toast_bytes|before_compression_total_bytes|after_compression_table_bytes|after_compression_index_bytes|after_compression_toast_bytes|after_compression_total_bytes|node_name|
+ |---|---|---|---|---|---|---|---|---|---|---|---|
+ |_timescaledb_internal|_hyper_1_1_chunk|Compressed|8192 bytes|16 kB|8192 bytes|32 kB|8192 bytes|16 kB|8192 bytes|32 kB||
+ |_timescaledb_internal|_hyper_1_20_chunk|Uncompressed||||||||||
+
+1. Repeat for all chunks you want to compress.
+
+## Manually compress chunks in a single command
+
+Alternatively, you can select the chunks and compress them in a single command
+by using the output of the `show_chunks` command to compress each one. For
+example, use this command to compress chunks between one and three weeks old
+if they are not already compressed:
+
+## Roll up uncompressed chunks when compressing
+
+In TimescaleDB v2.9 and later, you can roll up multiple uncompressed chunks into
+a previously compressed chunk as part of your compression procedure. This allows
+you to have much smaller uncompressed chunk intervals, which reduces the disk
+space used for uncompressed data. For example, if you have multiple smaller
+uncompressed chunks in your data, you can roll them up into a single compressed
+chunk.
+
+To roll up your uncompressed chunks into a compressed chunk, alter the compression
+settings to set the compress chunk time interval and run compression operations
+to roll up the chunks while compressing.
+
+The default setting of `compress_orderby` is `'time DESC'` (the descending or DESC command is used to sort the data returned in ascending order), which causes chunks to be re-compressed
+many times during the rollup, possibly leading to a steep performance penalty.
+Set `timescaledb.compress_orderby = 'time ASC'` to avoid this penalty.
+
+The time interval you choose must be a multiple of the uncompressed chunk
+interval. For example, if your uncompressed chunk interval is one week, your
+`` of the compressed chunk could be two weeks or six weeks, but
+not one month.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/about-compression/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT show_chunks('example', older_than => INTERVAL '3 days');
+```
+
+Example 2 (sql):
+```sql
+SELECT compress_chunk( '');
+```
+
+Example 3 (sql):
+```sql
+SELECT *
+ FROM chunk_compression_stats('example');
+```
+
+Example 4 (sql):
+```sql
+SELECT compress_chunk(i, if_not_compressed => true)
+ FROM show_chunks(
+ 'example',
+ now()::timestamp - INTERVAL '1 week',
+ now()::timestamp - INTERVAL '3 weeks'
+ ) i;
+```
+
+---
+
+## Materialized hypertables
+
+**URL:** llms-txt#materialized-hypertables
+
+**Contents:**
+- Discover the name of a materialized hypertable
+ - Discovering the name of a materialized hypertable
+
+Continuous aggregates take raw data from the original hypertable, aggregate it,
+and store the aggregated data in a materialization hypertable. You can modify
+this materialized hypertable in the same way as any other hypertable.
+
+## Discover the name of a materialized hypertable
+
+To change a materialized hypertable, you need to use its fully qualified
+name. To find the correct name, use the
+[timescaledb_information.continuous_aggregates view][api-continuous-aggregates-info]).
+You can then use the name to modify it in the same way as any other hypertable.
+
+### Discovering the name of a materialized hypertable
+
+1. At the `psql`prompt, query `timescaledb_information.continuous_aggregates`:
+
+1. Locate the name of the hypertable you want to adjust in the results of the
+ query. The results look like this:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/real-time-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT view_name, format('%I.%I', materialization_hypertable_schema,
+ materialization_hypertable_name) AS materialization_hypertable
+ FROM timescaledb_information.continuous_aggregates;
+```
+
+Example 2 (sql):
+```sql
+view_name | materialization_hypertable
+ ---------------------------+---------------------------------------------------
+ conditions_summary_hourly | _timescaledb_internal._materialized_hypertable_30
+ conditions_summary_daily | _timescaledb_internal._materialized_hypertable_31
+ (2 rows)
+```
+
+---
+
+## timescaledb_information.hypertable_columnstore_settings
+
+**URL:** llms-txt#timescaledb_information.hypertable_columnstore_settings
+
+**Contents:**
+- Samples
+- Returns
+
+Retrieve information about the settings for all hypertables in the columnstore.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To retrieve information about settings:
+
+- **Show columnstore settings for all hypertables**:
+
+- **Retrieve columnstore settings for a specific hypertable**:
+
+|Name|Type| Description |
+|-|-|-------------------------------------------------------------------------------------------|
+|`hypertable`|`REGCLASS`| A hypertable which has the [columnstore enabled][compression_alter-table].|
+|`segmentby`|`TEXT`| The list of columns used to segment data. |
+|`orderby`|`TEXT`| List of columns used to order the data, along with ordering and NULL ordering information. |
+|`compress_interval_length`|`TEXT`| Interval used for [rolling up chunks during compression][rollup-compression]. |
+|`index`| `TEXT` | The sparse index details. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/convert_to_columnstore/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_columnstore_settings;
+```
+
+Example 2 (sql):
+```sql
+hypertable | measurements
+ segmentby |
+ orderby | "time" DESC
+ compress_interval_length |
+```
+
+Example 3 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_columnstore_settings WHERE hypertable::TEXT LIKE 'metrics';
+```
+
+Example 4 (sql):
+```sql
+hypertable | metrics
+ segmentby | metric_id
+ orderby | "time"
+ compress_interval_length |
+```
+
+---
+
+## timescaledb_information.hypertables
+
+**URL:** llms-txt#timescaledb_information.hypertables
+
+**Contents:**
+- Samples
+- Available columns
+
+Get metadata information about hypertables.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get information about a hypertable.
+
+|Name|Type| Description |
+|-|-|-------------------------------------------------------------------|
+|`hypertable_schema`|TEXT| Schema name of the hypertable |
+|`hypertable_name`|TEXT| Table name of the hypertable |
+|`owner`|TEXT| Owner of the hypertable |
+|`num_dimensions`|SMALLINT| Number of dimensions |
+|`num_chunks`|BIGINT| Number of chunks |
+|`compression_enabled`|BOOLEAN| Is compression enabled on the hypertable? |
+|`is_distributed`|BOOLEAN| Sunsetted since TimescaleDB v2.14.0 Is the hypertable distributed? |
+|`replication_factor`|SMALLINT| Sunsetted since TimescaleDB v2.14.0 Replication factor for a distributed hypertable |
+|`data_nodes`|TEXT| Sunsetted since TimescaleDB v2.14.0 Nodes on which hypertable is distributed |
+|`tablespaces`|TEXT| Tablespaces attached to the hypertable |
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE metrics(time timestamptz, device int, temp float);
+SELECT create_hypertable('metrics','time');
+
+SELECT * from timescaledb_information.hypertables WHERE hypertable_name = 'metrics';
+
+-[ RECORD 1 ]-------+--------
+hypertable_schema | public
+hypertable_name | metrics
+owner | sven
+num_dimensions | 1
+num_chunks | 0
+compression_enabled | f
+tablespaces | NULL
+```
+
+---
+
+## enable_chunk_skipping()
+
+**URL:** llms-txt#enable_chunk_skipping()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+
+
+
+
+Early access: TimescaleDB v2.17.1
+
+Enable range statistics for a specific column in a **compressed** hypertable. This tracks a range of values for that column per chunk.
+Used for chunk skipping during query optimization and applies only to the chunks created after chunk skipping is enabled.
+
+Best practice is to enable range tracking on columns that are correlated to the
+partitioning column. In other words, enable tracking on secondary columns which are
+referenced in the `WHERE` clauses in your queries.
+
+TimescaleDB supports min/max range tracking for the `smallint`, `int`,
+`bigint`, `serial`, `bigserial`, `date`, `timestamp`, and `timestamptz` data types. The
+min/max ranges are calculated when a chunk belonging to
+this hypertable is compressed using the [compress_chunk][compress_chunk] function.
+The range is stored in start (inclusive) and end (exclusive) form in the
+`chunk_column_stats` catalog table.
+
+This way you store the min/max values for such columns in this catalog
+table at the per-chunk level. These min/max range values do
+not participate in partitioning of the data. These ranges are
+used for chunk skipping when the `WHERE` clause of an SQL query specifies
+ranges on the column.
+
+A [DROP COLUMN](https://www.postgresql.org/docs/current/sql-altertable.html#SQL-ALTERTABLE-DESC-DROP-COLUMN)
+on a column with statistics tracking enabled on it ends up removing all relevant entries
+from the catalog table.
+
+A [decompress_chunk][decompress_chunk] invocation on a compressed chunk resets its entries
+from the `chunk_column_stats` catalog table since now it's available for DML and the
+min/max range values can change on any further data manipulation in the chunk.
+
+By default, this feature is disabled. To enable chunk skipping, set `timescaledb.enable_chunk_skipping = on` in
+`postgresql.conf`. When you upgrade from a database instance that uses compression but does not support chunk
+skipping, you need to recompress the previously compressed chunks for chunk skipping to work.
+
+In this sample, you create the `conditions` hypertable with partitioning on the `time` column. You then specify and
+enable additional columns to track ranges for.
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+| Name | Type | Default | Required | Description |
+|-------------|------------------|---------|-|----------------------------------------|
+|`column_name`| `TEXT` | - | ✔ | Column to track range statistics for |
+|`hypertable`| `REGCLASS` | - | ✔ | Hypertable that the column belongs to |
+|`if_not_exists`| `BOOLEAN` | `false` | ✖ | Set to `true` so that a notice is sent when ranges are not being tracked for a column. By default, an error is thrown |
+
+|Column|Type|Description|
+|-|-|-|
+|`column_stats_id`|INTEGER|ID of the entry in the TimescaleDB internal catalog|
+|`enabled`|BOOLEAN|Returns `true` when tracking is enabled, `if_not_exists` is `true`, and when a new entry is not added|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/detach_tablespace/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+
+SELECT enable_chunk_skipping('conditions', 'device_id');
+```
+
+---
+
+## Time buckets
+
+**URL:** llms-txt#time-buckets
+
+Time buckets enable you to aggregate data in [hypertables][create-hypertable] by time interval. For example, you can
+group data into 5-minute, 1-hour, and 3-day buckets to calculate summary values.
+
+* [Learn how time buckets work][about-time-buckets]
+* [Use time buckets][use-time-buckets] to aggregate data
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/ =====
+
+---
+
+## Reindex hypertables to fix large indexes
+
+**URL:** llms-txt#reindex-hypertables-to-fix-large-indexes
+
+
+
+You might see this error if your hypertable indexes have become very large. To
+resolve the problem, reindex your hypertables with this command:
+
+For more information, see the [hypertable documentation][hypertables].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/compression-userperms/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+reindex table _timescaledb_internal._hyper_2_1523284_chunk
+```
+
+---
+
+## Compress continuous aggregates
+
+**URL:** llms-txt#compress-continuous-aggregates
+
+**Contents:**
+- Configure columnstore on continuous aggregates
+
+To save on storage costs, you use hypercore to downsample historical data stored in continuous aggregates. After you
+[enable columnstore][compression_continuous-aggregate] on a `MATERIALIZED VIEW`, you set a
+[columnstore policy][add_columnstore_policy]. This policy defines the intervals when chunks in a continuous aggregate
+are compressed as they are converted from the rowstore to the columnstore.
+
+Columnstore works in the same way on [hypertables and continuous aggregates][hypercore]. When you enable
+columnstore with no other options, your data is [segmented by][alter_materialized_view_arguments] the `groupby` columns
+in the continuous aggregate, and [ordered by][alter_materialized_view_arguments] the time column. [Real-time aggregation][real-time-aggregates]
+is disabled by default.
+
+Since [TimescaleDB v2.20.0](https://github.com/timescale/timescaledb/releases/tag/2.20.0) For the old API, see Compress continuous aggregates.
+
+## Configure columnstore on continuous aggregates
+
+For an [existing continuous aggregate][create-cagg]:
+
+1. **Enable columnstore on a continuous aggregate**
+
+To enable the columnstore compression on a continuous aggregate, set `timescaledb.enable_columnstore = true` when you alter the view:
+
+To disable the columnstore compression, set `timescaledb.enable_columnstore = false`:
+
+1. **Set columnstore policies on the continuous aggregate**
+
+Before you set up a columnstore policy on a continuous aggregate, you first set the [refresh policy][refresh-policy]. To
+ prevent refresh policies from failing, you set the columnstore policy interval so that actively
+ refreshed regions are not compressed. For example:
+
+1. **Set the refresh policy**
+
+1. **Set the columnstore policy**
+
+For this refresh policy, the `after` parameter must be greater than the value of
+ `start_offset` in the refresh policy:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/create-index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER MATERIALIZED VIEW set (timescaledb.enable_columnstore = true);
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('',
+ start_offset => INTERVAL '30 days',
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+Example 3 (sql):
+```sql
+CALL add_columnstore_policy('', after => INTERVAL '45 days');
+```
+
+---
+
+## About time buckets
+
+**URL:** llms-txt#about-time-buckets
+
+**Contents:**
+- How time bucketing works
+ - Origin
+ - Timezones
+
+Time bucketing is essential for real-time analytics. The [`time_bucket`][time_bucket] function enables you to aggregate data in a [hypertable][create-hypertable] into buckets of time. For example, 5 minutes, 1 hour, or 3 days.
+It's similar to Postgres's [`date_bin`][date_bin] function, but it gives you more
+flexibility in the bucket size and start time.
+
+You can use it to roll up data for analysis or downsampling. For example, you can calculate
+5-minute averages for a sensor reading over the last day. You can perform these
+rollups as needed, or pre-calculate them in [continuous aggregates][caggs].
+
+This section explains how time bucketing works. For examples of the
+`time_bucket` function, see the section on
+[Aggregate time-series data with `time_bucket`][use-time-buckets].
+
+## How time bucketing works
+
+Time bucketing groups data into time intervals. With `time_bucket`, the interval
+length can be any number of microseconds, milliseconds, seconds, minutes, hours,
+days, weeks, months, years, or centuries.
+
+The `time_bucket` function is usually used in combination with `GROUP BY` to
+aggregate data. For example, you can calculate the average, maximum, minimum, or
+sum of values within a bucket.
+
+
+
+This can affect queries that span the two different partitioning configurations.
+For more information, see the section on
+[limitations of query push down][limitations].
+
+## Replicating distributed hypertables
+
+To replicate distributed hypertables at the chunk level, configure the
+hypertables to write each chunk to multiple data nodes. This native replication
+ensures that a distributed hypertable is protected against data node failures
+and provides an alternative to fully replicating each data node using streaming
+replication to provide high availability. Only the data nodes are replicated
+using this method. The access node is not replicated.
+
+For more information about replication and high availability, see the
+[multi-node HA section][multi-node-ha].
+
+## Performance of distributed hypertables
+
+A distributed hypertable horizontally scales your data storage, so you're not
+limited by the storage of any single machine. It also increases performance for
+some queries.
+
+Whether, and by how much, your performance increases depends on your query
+patterns and data partitioning. Performance increases when the access node can
+push down query processing to data nodes. For example, if you query with a
+`GROUP BY` clause, and the data is partitioned by the `GROUP BY` column, the
+data nodes can perform the processing and send only the final results to the
+access node.
+
+If processing can't be done on the data nodes, the access node needs to pull in
+raw or partially processed data and do the processing locally. For more
+information, see the [limitations of pushing down
+queries][limitations-pushing-down].
+
+The access node can use a full or a partial method to push down queries.
+Computations that can be pushed down include sorts and groupings. Joins on data
+nodes aren't currently supported.
+
+To see how a query is pushed down to a data node, use `EXPLAIN VERBOSE` to
+inspect the query plan and the remote SQL statement sent to each data node.
+
+In the full push-down method, the access node offloads all computation to the
+data nodes. It receives final results from the data nodes and appends them. To
+fully push down an aggregate query, the `GROUP BY` clause must include either:
+
+* All the partitioning columns _or_
+* Only the first space-partitioning column
+
+For example, say that you want to calculate the `max` temperature for each
+location:
+
+If `location` is your only space partition, each data node can compute the
+maximum on its own subset of the data.
+
+### Partial push down
+
+In the partial push-down method, the access node offloads most of the
+computation to the data nodes. It receives partial results from the data nodes
+and calculates a final aggregate by combining the partials.
+
+For example, say that you want to calculate the `max` temperature across all
+locations. Each data node computes a local maximum, and the access node computes
+the final result by computing the maximum of all the local maximums:
+
+### Limitations of query push down
+
+Distributed hypertables get improved performance when they can push down queries
+to the data nodes. But the query planner might not be able to push down every
+query. Or it might only be able to partially push down a query. This can occur
+for several reasons:
+
+* You changed the partitioning configuration. For example, you added new data
+ nodes and increased the number of space partitions to match. This can cause
+ chunks for the same space value to be stored on different nodes. For
+ instance, say you partition by `device_id`. You start with 3 partitions, and
+ data for `device_B` is stored on node 3. You later increase to 4 partitions.
+ New chunks for `device_B` are now stored on node 4. If you query across the
+ repartitioning boundary, a final aggregate for `device_B` cannot be
+ calculated on node 3 or node 4 alone. Partially processed data must be sent
+ to the access node for final aggregation. The TimescaleDB query planner
+ dynamically detects such overlapping chunks and reverts to the appropriate
+ partial aggregation plan. This means that you can add data nodes and
+ repartition your data to achieve elasticity without worrying about query
+ results. In some cases, your query could be slightly less performant, but
+ this is rare and the affected chunks usually move quickly out of your
+ retention window.
+* The query includes [non-immutable functions][volatility] and expressions.
+ The function cannot be pushed down to the data node, because by definition,
+ it isn't guaranteed to have a consistent result across each node. An example
+ non-immutable function is [`random()`][random-func], which depends on the
+ current seed.
+* The query includes a job function. The access node assumes the
+ function doesn't exist on the data nodes, and doesn't push it down.
+
+TimescaleDB uses several optimizations to avoid these limitations, and push down
+as many queries as possible. For example, `now()` is a non-immutable function.
+The database converts it to a constant on the access node and pushes down the
+constant timestamp to the data nodes.
+
+## Combine distributed hypertables and standard hypertables
+
+You can use distributed hypertables in the same database as standard hypertables
+and standard Postgres tables. This mostly works the same way as having
+multiple standard tables, with a few differences. For example, if you `JOIN` a
+standard table and a distributed hypertable, the access node needs to fetch the
+raw data from the data nodes and perform the `JOIN` locally.
+
+All the limitations of regular hypertables also apply to distributed
+hypertables. In addition, the following limitations apply specifically
+to distributed hypertables:
+
+* Distributed scheduling of background jobs is not supported. Background jobs
+ created on an access node are scheduled and executed on this access node
+ without distributing the jobs to data nodes.
+* Continuous aggregates can aggregate data distributed across data nodes, but
+ the continuous aggregate itself must live on the access node. This could
+ create a limitation on how far you can scale your installation, but because
+ continuous aggregates are downsamples of the data, this does not usually
+ create a problem.
+* Reordering chunks is not supported.
+* Tablespaces cannot be attached to a distributed hypertable on the access
+ node. It is still possible to attach tablespaces on data nodes.
+* Roles and permissions are assumed to be consistent across the nodes of a
+ distributed database, but consistency is not enforced.
+* Joins on data nodes are not supported. Joining a distributed hypertable with
+ another table requires the other table to reside on the access node. This
+ also limits the performance of joins on distributed hypertables.
+* Tables referenced by foreign key constraints in a distributed hypertable
+ must be present on the access node and all data nodes. This applies also to
+ referenced values.
+* Parallel-aware scans and appends are not supported.
+* Distributed hypertables do not natively provide a consistent restore point
+ for backup and restore across nodes. Use the
+ [`create_distributed_restore_point`][create_distributed_restore_point]
+ command, and make sure you take care when you restore individual backups to
+ access and data nodes.
+* For native replication limitations, see the
+ [native replication section][native-replication].
+* User defined functions have to be manually installed on the data nodes so
+ that the function definition is available on both access and data nodes.
+ This is particularly relevant for functions that are registered with
+ `set_integer_now_func`.
+
+Note that these limitations concern usage from the access node. Some
+currently unsupported features might still work on individual data nodes,
+but such usage is neither tested nor officially supported. Future versions
+of TimescaleDB might remove some of these limitations.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/backup-and-restore/logical-backup/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT location, max(temperature)
+ FROM conditions
+ GROUP BY location;
+```
+
+Example 2 (sql):
+```sql
+SELECT max(temperature) FROM conditions;
+```
+
+---
+
+## reorder_chunk()
+
+**URL:** llms-txt#reorder_chunk()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+- Returns
+
+Reorder a single chunk's heap to follow the order of an index. This function
+acts similarly to the [Postgres CLUSTER command][postgres-cluster] , however
+it uses lower lock levels so that, unlike with the CLUSTER command, the chunk
+and hypertable are able to be read for most of the process. It does use a bit
+more disk space during the operation.
+
+This command can be particularly useful when data is often queried in an order
+different from that in which it was originally inserted. For example, data is
+commonly inserted into a hypertable in loose time order (for example, many devices
+concurrently sending their current state), but one might typically query the
+hypertable about a _specific_ device. In such cases, reordering a chunk using an
+index on `(device_id, time)` can lead to significant performance improvement for
+these types of queries.
+
+One can call this function directly on individual chunks of a hypertable, but
+using [add_reorder_policy][add_reorder_policy] is often much more convenient.
+
+Reorder a chunk on an index:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `chunk` | REGCLASS | Name of the chunk to reorder. |
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `index` | REGCLASS | The name of the index (on either the hypertable or chunk) to order by.|
+| `verbose` | BOOLEAN | Setting to true displays messages about the progress of the reorder command. Defaults to false.|
+
+This function returns void.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/add_reorder_policy/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT reorder_chunk('_timescaledb_internal._hyper_1_10_chunk', '_timescaledb_internal.conditions_device_id_time_idx');
+```
+
+---
+
+## create_distributed_hypertable()
+
+**URL:** llms-txt#create_distributed_hypertable()
+
+**Contents:**
+- Required arguments
+- Optional arguments
+- Returns
+- Sample usage
+ - Best practices
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Create a TimescaleDB hypertable distributed across a multinode environment.
+
+`create_distributed_hypertable()` replaces [`create_hypertable() (old interface)`][create-hypertable-old]. Distributed tables use the old API. The new generalized [`create_hypertable`][create-hypertable-new] API was introduced in TimescaleDB v2.13.
+
+## Required arguments
+
+|Name|Type| Description |
+|---|---|----------------------------------------------------------------------------------------------|
+| `relation` | REGCLASS | Identifier of the table you want to convert to a hypertable. |
+| `time_column_name` | TEXT | Name of the column that contains time values, as well as the primary column to partition by. |
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `partitioning_column` | TEXT | Name of an additional column to partition by. |
+| `number_partitions` | INTEGER | Number of hash partitions to use for `partitioning_column`. Must be > 0. Default is the number of `data_nodes`. |
+| `associated_schema_name` | TEXT | Name of the schema for internal hypertable tables. Default is `_timescaledb_internal`. |
+| `associated_table_prefix` | TEXT | Prefix for internal hypertable chunk names. Default is `_hyper`. |
+| `chunk_time_interval` | INTERVAL | Interval in event time that each chunk covers. Must be > 0. Default is 7 days. |
+| `create_default_indexes` | BOOLEAN | Boolean whether to create default indexes on time/partitioning columns. Default is TRUE. |
+| `if_not_exists` | BOOLEAN | Boolean whether to print warning if table already converted to hypertable or raise exception. Default is FALSE. |
+| `partitioning_func` | REGCLASS | The function to use for calculating a value's partition.|
+| `migrate_data` | BOOLEAN | Set to TRUE to migrate any existing data from the `relation` table to chunks in the new hypertable. A non-empty table generates an error without this option. Large tables may take significant time to migrate. Default is FALSE. |
+| `time_partitioning_func` | REGCLASS | Function to convert incompatible primary time column values to compatible ones. The function must be `IMMUTABLE`. |
+| `replication_factor` | INTEGER | The number of data nodes to which the same data is written to. This is done by creating chunk copies on this amount of data nodes. Must be >= 1; If not set, the default value is determined by the `timescaledb.hypertable_replication_factor_default` GUC. Read [the best practices][best-practices] before changing the default. |
+| `data_nodes` | ARRAY | The set of data nodes used for the distributed hypertable. If not present, defaults to all data nodes known by the access node (the node on which the distributed hypertable is created). |
+
+|Column|Type|Description|
+|---|---|---|
+| `hypertable_id` | INTEGER | ID of the hypertable in TimescaleDB. |
+| `schema_name` | TEXT | Schema name of the table converted to hypertable. |
+| `table_name` | TEXT | Table name of the table converted to hypertable. |
+| `created` | BOOLEAN | TRUE if the hypertable was created, FALSE when `if_not_exists` is TRUE and no hypertable was created. |
+
+Create a table `conditions` which is partitioned across data
+nodes by the 'location' column. Note that the number of space
+partitions is automatically equal to the number of data nodes assigned
+to this hypertable (all configured data nodes in this case, as
+`data_nodes` is not specified).
+
+Create a table `conditions` using a specific set of data nodes.
+
+* **Hash partitions**: Best practice for distributed hypertables is to enable [hash partitions](https://www.techopedia.com/definition/31996/hash-partitioning).
+ With hash partitions, incoming data is divided between the data nodes. Without hash partition, all
+ data for each time slice is written to a single data node.
+
+* **Time intervals**: Follow the guidelines for `chunk_time_interval` defined in [`create_hypertable`]
+ [create-hypertable-old].
+
+When you enable hash partitioning, the hypertable is evenly distributed across the data nodes. This
+ means you can set a larger time interval. For example, you ingest 10 GB of data per day shared over
+ five data nodes, each node has 64 GB of memory. If this is the only table being served by these data nodes, use a time interval of 1 week:
+
+If you do not enable hash partitioning, use the same `chunk_time_interval` settings as a non-distributed
+ instance. This is because all incoming data is handled by a single node.
+
+* **Replication factor**: `replication_factor` defines the number of data nodes a newly created chunk is
+ replicated in. For example, when you set `replication_factor` to `3`, each chunk exists on 3 separate
+ data nodes. Rows written to a chunk are inserted into all data notes in a two-phase commit protocol.
+
+If a data node fails or is removed, no data is lost. Writes succeed on the other data nodes. However, the
+ chunks on the lost data node are now under-replicated. When the failed data node becomes available, rebalance the chunks with a call to [copy_chunk][copy_chunk].
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/attach_data_node/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location');
+```
+
+Example 2 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location',
+ data_nodes => '{ "data_node_1", "data_node_2", "data_node_4", "data_node_7" }');
+```
+
+Example 3 (unknown):
+```unknown
+7 days * 10 GB 70
+ -------------------- == --- ~= 22% of main memory used for the most recent chunks
+ 5 data nodes * 64 GB 320
+```
+
+---
+
+## Manual compression
+
+**URL:** llms-txt#manual-compression
+
+**Contents:**
+ - Selecting chunks to compress
+ - Compressing chunks manually
+- Manually compress chunks in a single command
+- Roll up uncompressed chunks when compressing
+
+In most cases, an [automated compression policy][add_compression_policy] is sufficient to automatically compress your
+chunks. However, if you want more control, you can also use manual synchronous compression of specific chunks.
+
+Before you start, you need a list of chunks to compress. In this example, you
+use a hypertable called `example`, and compress chunks older than three days.
+
+### Selecting chunks to compress
+
+1. At the psql prompt, select all chunks in the table `example` that are older
+ than three days:
+
+1. This returns a list of chunks. Take note of the chunks' names:
+
+||show_chunks|
+ |---|---|
+ |1|_timescaledb_internal_hyper_1_2_chunk|
+ |2|_timescaledb_internal_hyper_1_3_chunk|
+
+When you are happy with the list of chunks, you can use the chunk names to
+manually compress each one.
+
+### Compressing chunks manually
+
+1. At the psql prompt, compress the chunk:
+
+1. Check the results of the compression with this command:
+
+The results show the chunks for the given hypertable, their compression
+ status, and some other statistics:
+
+|chunk_schema|chunk_name|compression_status|before_compression_table_bytes|before_compression_index_bytes|before_compression_toast_bytes|before_compression_total_bytes|after_compression_table_bytes|after_compression_index_bytes|after_compression_toast_bytes|after_compression_total_bytes|node_name|
+ |---|---|---|---|---|---|---|---|---|---|---|---|
+ |_timescaledb_internal|_hyper_1_1_chunk|Compressed|8192 bytes|16 kB|8192 bytes|32 kB|8192 bytes|16 kB|8192 bytes|32 kB||
+ |_timescaledb_internal|_hyper_1_20_chunk|Uncompressed||||||||||
+
+1. Repeat for all chunks you want to compress.
+
+## Manually compress chunks in a single command
+
+Alternatively, you can select the chunks and compress them in a single command
+by using the output of the `show_chunks` command to compress each one. For
+example, use this command to compress chunks between one and three weeks old
+if they are not already compressed:
+
+## Roll up uncompressed chunks when compressing
+
+In TimescaleDB v2.9 and later, you can roll up multiple uncompressed chunks into
+a previously compressed chunk as part of your compression procedure. This allows
+you to have much smaller uncompressed chunk intervals, which reduces the disk
+space used for uncompressed data. For example, if you have multiple smaller
+uncompressed chunks in your data, you can roll them up into a single compressed
+chunk.
+
+To roll up your uncompressed chunks into a compressed chunk, alter the compression
+settings to set the compress chunk time interval and run compression operations
+to roll up the chunks while compressing.
+
+The default setting of `compress_orderby` is `'time DESC'` (the descending or DESC command is used to sort the data returned in ascending order), which causes chunks to be re-compressed
+many times during the rollup, possibly leading to a steep performance penalty.
+Set `timescaledb.compress_orderby = 'time ASC'` to avoid this penalty.
+
+The time interval you choose must be a multiple of the uncompressed chunk
+interval. For example, if your uncompressed chunk interval is one week, your
+`` of the compressed chunk could be two weeks or six weeks, but
+not one month.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/compression/about-compression/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT show_chunks('example', older_than => INTERVAL '3 days');
+```
+
+Example 2 (sql):
+```sql
+SELECT compress_chunk( '');
+```
+
+Example 3 (sql):
+```sql
+SELECT *
+ FROM chunk_compression_stats('example');
+```
+
+Example 4 (sql):
+```sql
+SELECT compress_chunk(i, if_not_compressed => true)
+ FROM show_chunks(
+ 'example',
+ now()::timestamp - INTERVAL '1 week',
+ now()::timestamp - INTERVAL '3 weeks'
+ ) i;
+```
+
+---
+
+## Materialized hypertables
+
+**URL:** llms-txt#materialized-hypertables
+
+**Contents:**
+- Discover the name of a materialized hypertable
+ - Discovering the name of a materialized hypertable
+
+Continuous aggregates take raw data from the original hypertable, aggregate it,
+and store the aggregated data in a materialization hypertable. You can modify
+this materialized hypertable in the same way as any other hypertable.
+
+## Discover the name of a materialized hypertable
+
+To change a materialized hypertable, you need to use its fully qualified
+name. To find the correct name, use the
+[timescaledb_information.continuous_aggregates view][api-continuous-aggregates-info]).
+You can then use the name to modify it in the same way as any other hypertable.
+
+### Discovering the name of a materialized hypertable
+
+1. At the `psql`prompt, query `timescaledb_information.continuous_aggregates`:
+
+1. Locate the name of the hypertable you want to adjust in the results of the
+ query. The results look like this:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/real-time-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT view_name, format('%I.%I', materialization_hypertable_schema,
+ materialization_hypertable_name) AS materialization_hypertable
+ FROM timescaledb_information.continuous_aggregates;
+```
+
+Example 2 (sql):
+```sql
+view_name | materialization_hypertable
+ ---------------------------+---------------------------------------------------
+ conditions_summary_hourly | _timescaledb_internal._materialized_hypertable_30
+ conditions_summary_daily | _timescaledb_internal._materialized_hypertable_31
+ (2 rows)
+```
+
+---
+
+## timescaledb_information.hypertable_columnstore_settings
+
+**URL:** llms-txt#timescaledb_information.hypertable_columnstore_settings
+
+**Contents:**
+- Samples
+- Returns
+
+Retrieve information about the settings for all hypertables in the columnstore.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+To retrieve information about settings:
+
+- **Show columnstore settings for all hypertables**:
+
+- **Retrieve columnstore settings for a specific hypertable**:
+
+|Name|Type| Description |
+|-|-|-------------------------------------------------------------------------------------------|
+|`hypertable`|`REGCLASS`| A hypertable which has the [columnstore enabled][compression_alter-table].|
+|`segmentby`|`TEXT`| The list of columns used to segment data. |
+|`orderby`|`TEXT`| List of columns used to order the data, along with ordering and NULL ordering information. |
+|`compress_interval_length`|`TEXT`| Interval used for [rolling up chunks during compression][rollup-compression]. |
+|`index`| `TEXT` | The sparse index details. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/convert_to_columnstore/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_columnstore_settings;
+```
+
+Example 2 (sql):
+```sql
+hypertable | measurements
+ segmentby |
+ orderby | "time" DESC
+ compress_interval_length |
+```
+
+Example 3 (sql):
+```sql
+SELECT * FROM timescaledb_information.hypertable_columnstore_settings WHERE hypertable::TEXT LIKE 'metrics';
+```
+
+Example 4 (sql):
+```sql
+hypertable | metrics
+ segmentby | metric_id
+ orderby | "time"
+ compress_interval_length |
+```
+
+---
+
+## timescaledb_information.hypertables
+
+**URL:** llms-txt#timescaledb_information.hypertables
+
+**Contents:**
+- Samples
+- Available columns
+
+Get metadata information about hypertables.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get information about a hypertable.
+
+|Name|Type| Description |
+|-|-|-------------------------------------------------------------------|
+|`hypertable_schema`|TEXT| Schema name of the hypertable |
+|`hypertable_name`|TEXT| Table name of the hypertable |
+|`owner`|TEXT| Owner of the hypertable |
+|`num_dimensions`|SMALLINT| Number of dimensions |
+|`num_chunks`|BIGINT| Number of chunks |
+|`compression_enabled`|BOOLEAN| Is compression enabled on the hypertable? |
+|`is_distributed`|BOOLEAN| Sunsetted since TimescaleDB v2.14.0 Is the hypertable distributed? |
+|`replication_factor`|SMALLINT| Sunsetted since TimescaleDB v2.14.0 Replication factor for a distributed hypertable |
+|`data_nodes`|TEXT| Sunsetted since TimescaleDB v2.14.0 Nodes on which hypertable is distributed |
+|`tablespaces`|TEXT| Tablespaces attached to the hypertable |
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE metrics(time timestamptz, device int, temp float);
+SELECT create_hypertable('metrics','time');
+
+SELECT * from timescaledb_information.hypertables WHERE hypertable_name = 'metrics';
+
+-[ RECORD 1 ]-------+--------
+hypertable_schema | public
+hypertable_name | metrics
+owner | sven
+num_dimensions | 1
+num_chunks | 0
+compression_enabled | f
+tablespaces | NULL
+```
+
+---
+
+## enable_chunk_skipping()
+
+**URL:** llms-txt#enable_chunk_skipping()
+
+**Contents:**
+- Samples
+- Arguments
+- Returns
+
+
+
+
+
+Early access: TimescaleDB v2.17.1
+
+Enable range statistics for a specific column in a **compressed** hypertable. This tracks a range of values for that column per chunk.
+Used for chunk skipping during query optimization and applies only to the chunks created after chunk skipping is enabled.
+
+Best practice is to enable range tracking on columns that are correlated to the
+partitioning column. In other words, enable tracking on secondary columns which are
+referenced in the `WHERE` clauses in your queries.
+
+TimescaleDB supports min/max range tracking for the `smallint`, `int`,
+`bigint`, `serial`, `bigserial`, `date`, `timestamp`, and `timestamptz` data types. The
+min/max ranges are calculated when a chunk belonging to
+this hypertable is compressed using the [compress_chunk][compress_chunk] function.
+The range is stored in start (inclusive) and end (exclusive) form in the
+`chunk_column_stats` catalog table.
+
+This way you store the min/max values for such columns in this catalog
+table at the per-chunk level. These min/max range values do
+not participate in partitioning of the data. These ranges are
+used for chunk skipping when the `WHERE` clause of an SQL query specifies
+ranges on the column.
+
+A [DROP COLUMN](https://www.postgresql.org/docs/current/sql-altertable.html#SQL-ALTERTABLE-DESC-DROP-COLUMN)
+on a column with statistics tracking enabled on it ends up removing all relevant entries
+from the catalog table.
+
+A [decompress_chunk][decompress_chunk] invocation on a compressed chunk resets its entries
+from the `chunk_column_stats` catalog table since now it's available for DML and the
+min/max range values can change on any further data manipulation in the chunk.
+
+By default, this feature is disabled. To enable chunk skipping, set `timescaledb.enable_chunk_skipping = on` in
+`postgresql.conf`. When you upgrade from a database instance that uses compression but does not support chunk
+skipping, you need to recompress the previously compressed chunks for chunk skipping to work.
+
+In this sample, you create the `conditions` hypertable with partitioning on the `time` column. You then specify and
+enable additional columns to track ranges for.
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+| Name | Type | Default | Required | Description |
+|-------------|------------------|---------|-|----------------------------------------|
+|`column_name`| `TEXT` | - | ✔ | Column to track range statistics for |
+|`hypertable`| `REGCLASS` | - | ✔ | Hypertable that the column belongs to |
+|`if_not_exists`| `BOOLEAN` | `false` | ✖ | Set to `true` so that a notice is sent when ranges are not being tracked for a column. By default, an error is thrown |
+
+|Column|Type|Description|
+|-|-|-|
+|`column_stats_id`|INTEGER|ID of the entry in the TimescaleDB internal catalog|
+|`enabled`|BOOLEAN|Returns `true` when tracking is enabled, `if_not_exists` is `true`, and when a new entry is not added|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/detach_tablespace/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ NOT NULL,
+ location TEXT NOT NULL,
+ device TEXT NOT NULL,
+ temperature DOUBLE PRECISION NULL,
+ humidity DOUBLE PRECISION NULL
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+
+SELECT enable_chunk_skipping('conditions', 'device_id');
+```
+
+---
+
+## Time buckets
+
+**URL:** llms-txt#time-buckets
+
+Time buckets enable you to aggregate data in [hypertables][create-hypertable] by time interval. For example, you can
+group data into 5-minute, 1-hour, and 3-day buckets to calculate summary values.
+
+* [Learn how time buckets work][about-time-buckets]
+* [Use time buckets][use-time-buckets] to aggregate data
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/ =====
+
+---
+
+## Reindex hypertables to fix large indexes
+
+**URL:** llms-txt#reindex-hypertables-to-fix-large-indexes
+
+
+
+You might see this error if your hypertable indexes have become very large. To
+resolve the problem, reindex your hypertables with this command:
+
+For more information, see the [hypertable documentation][hypertables].
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/compression-userperms/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+reindex table _timescaledb_internal._hyper_2_1523284_chunk
+```
+
+---
+
+## Compress continuous aggregates
+
+**URL:** llms-txt#compress-continuous-aggregates
+
+**Contents:**
+- Configure columnstore on continuous aggregates
+
+To save on storage costs, you use hypercore to downsample historical data stored in continuous aggregates. After you
+[enable columnstore][compression_continuous-aggregate] on a `MATERIALIZED VIEW`, you set a
+[columnstore policy][add_columnstore_policy]. This policy defines the intervals when chunks in a continuous aggregate
+are compressed as they are converted from the rowstore to the columnstore.
+
+Columnstore works in the same way on [hypertables and continuous aggregates][hypercore]. When you enable
+columnstore with no other options, your data is [segmented by][alter_materialized_view_arguments] the `groupby` columns
+in the continuous aggregate, and [ordered by][alter_materialized_view_arguments] the time column. [Real-time aggregation][real-time-aggregates]
+is disabled by default.
+
+Since [TimescaleDB v2.20.0](https://github.com/timescale/timescaledb/releases/tag/2.20.0) For the old API, see Compress continuous aggregates.
+
+## Configure columnstore on continuous aggregates
+
+For an [existing continuous aggregate][create-cagg]:
+
+1. **Enable columnstore on a continuous aggregate**
+
+To enable the columnstore compression on a continuous aggregate, set `timescaledb.enable_columnstore = true` when you alter the view:
+
+To disable the columnstore compression, set `timescaledb.enable_columnstore = false`:
+
+1. **Set columnstore policies on the continuous aggregate**
+
+Before you set up a columnstore policy on a continuous aggregate, you first set the [refresh policy][refresh-policy]. To
+ prevent refresh policies from failing, you set the columnstore policy interval so that actively
+ refreshed regions are not compressed. For example:
+
+1. **Set the refresh policy**
+
+1. **Set the columnstore policy**
+
+For this refresh policy, the `after` parameter must be greater than the value of
+ `start_offset` in the refresh policy:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/create-index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER MATERIALIZED VIEW set (timescaledb.enable_columnstore = true);
+```
+
+Example 2 (sql):
+```sql
+SELECT add_continuous_aggregate_policy('',
+ start_offset => INTERVAL '30 days',
+ end_offset => INTERVAL '1 day',
+ schedule_interval => INTERVAL '1 hour');
+```
+
+Example 3 (sql):
+```sql
+CALL add_columnstore_policy('', after => INTERVAL '45 days');
+```
+
+---
+
+## About time buckets
+
+**URL:** llms-txt#about-time-buckets
+
+**Contents:**
+- How time bucketing works
+ - Origin
+ - Timezones
+
+Time bucketing is essential for real-time analytics. The [`time_bucket`][time_bucket] function enables you to aggregate data in a [hypertable][create-hypertable] into buckets of time. For example, 5 minutes, 1 hour, or 3 days.
+It's similar to Postgres's [`date_bin`][date_bin] function, but it gives you more
+flexibility in the bucket size and start time.
+
+You can use it to roll up data for analysis or downsampling. For example, you can calculate
+5-minute averages for a sensor reading over the last day. You can perform these
+rollups as needed, or pre-calculate them in [continuous aggregates][caggs].
+
+This section explains how time bucketing works. For examples of the
+`time_bucket` function, see the section on
+[Aggregate time-series data with `time_bucket`][use-time-buckets].
+
+## How time bucketing works
+
+Time bucketing groups data into time intervals. With `time_bucket`, the interval
+length can be any number of microseconds, milliseconds, seconds, minutes, hours,
+days, weeks, months, years, or centuries.
+
+The `time_bucket` function is usually used in combination with `GROUP BY` to
+aggregate data. For example, you can calculate the average, maximum, minimum, or
+sum of values within a bucket.
+
+![]() +
+The origin determines when time buckets start and end. By default, a time bucket
+doesn't start at the earliest timestamp in your data. There is often a more
+logical time. For example, you might collect your first data point at `00:37`,
+but you probably want your daily buckets to start at midnight. Similarly, you
+might collect your first data point on a Wednesday, but you might want your
+weekly buckets calculated from Sunday or Monday.
+
+Instead, time is divided into buckets based on intervals from the origin. The
+following diagram shows how, using the example of 2-week buckets. The first
+possible start date for a bucket is `origin`. The next possible start date for a
+bucket is `origin + bucket interval`. If your first timestamp does not fall
+exactly on a possible start date, the immediately preceding start date is used
+for the beginning of the bucket.
+
+
+
+The origin determines when time buckets start and end. By default, a time bucket
+doesn't start at the earliest timestamp in your data. There is often a more
+logical time. For example, you might collect your first data point at `00:37`,
+but you probably want your daily buckets to start at midnight. Similarly, you
+might collect your first data point on a Wednesday, but you might want your
+weekly buckets calculated from Sunday or Monday.
+
+Instead, time is divided into buckets based on intervals from the origin. The
+following diagram shows how, using the example of 2-week buckets. The first
+possible start date for a bucket is `origin`. The next possible start date for a
+bucket is `origin + bucket interval`. If your first timestamp does not fall
+exactly on a possible start date, the immediately preceding start date is used
+for the beginning of the bucket.
+
+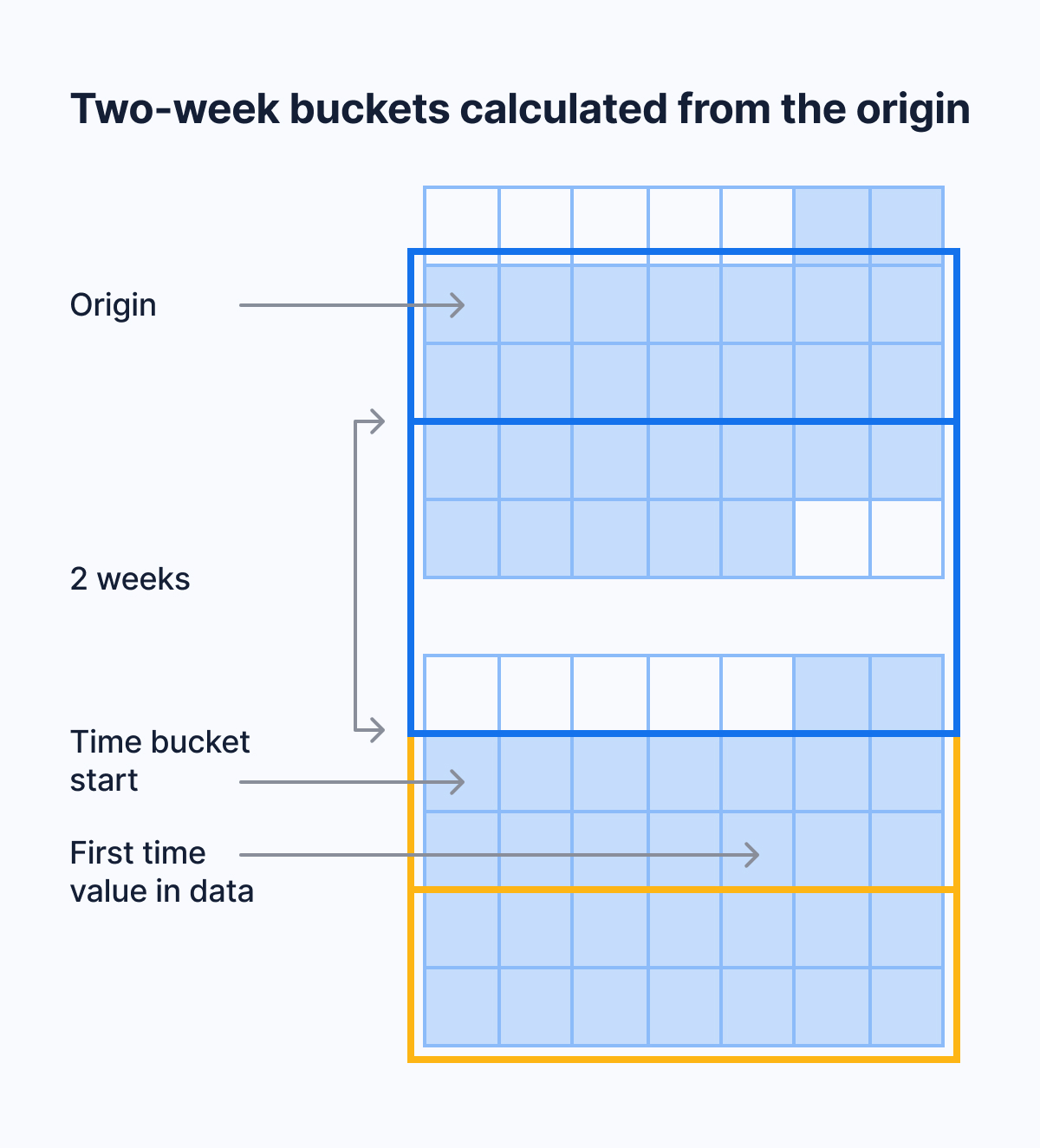 +
+For example, say that your data's earliest timestamp is April 24, 2020. If you
+bucket by an interval of two weeks, the first bucket doesn't start on April 24,
+which is a Friday. It also doesn't start on April 20, which is the immediately
+preceding Monday. It starts on April 13, because you can get to April 13, 2020,
+by counting in two-week increments from January 3, 2000, which is the default
+origin in this case.
+
+For intervals that don't include months or years, the default origin is January
+3, 2000. For month, year, or century intervals, the default origin is January 1,
+2000. For integer time values, the default origin is 0.
+
+These choices make the time ranges of time buckets more intuitive. Because
+January 3, 2000, is a Monday, weekly time buckets start on Monday. This is
+compliant with the ISO standard for calculating calendar weeks. Monthly and
+yearly time buckets use January 1, 2000, as an origin. This allows them to start
+on the first day of the calendar month or year.
+
+If you prefer another origin, you can set it yourself using the [`origin`
+parameter][origin]. For example, to start weeks on Sunday, set the origin to
+Sunday, January 2, 2000.
+
+The origin time depends on the data type of your time values.
+
+If you use `TIMESTAMP`, by default, bucket start times are aligned with
+`00:00:00`. Daily and weekly buckets start at `00:00:00`. Shorter buckets start
+at a time that you can get to by counting in bucket increments from `00:00:00`
+on the origin date.
+
+If you use `TIMESTAMPTZ`, by default, bucket start times are aligned with
+`00:00:00 UTC`. To align time buckets to another timezone, set the `timezone`
+parameter.
+
+===== PAGE: https://docs.tigerdata.com/mst/vpc-peering/vpc-peering-gcp/ =====
+
+---
+
+## About constraints
+
+**URL:** llms-txt#about-constraints
+
+Constraints are rules that apply to your database columns. This prevents you
+from entering invalid data into your database. When you create, change, or
+delete constraints on your hypertables, the constraints are propagated to the
+underlying chunks, and to any indexes.
+
+Hypertables support all standard Postgres constraint types. For foreign keys in particular, the following is supported:
+
+- Foreign key constraints from a hypertable referencing a regular table
+- Foreign key constraints from a regular table referencing a hypertable
+
+Foreign keys from a hypertable referencing another hypertable **are not supported**.
+
+For example, you can create a table that only allows positive device IDs, and
+non-null temperature readings. You can also check that time values for all
+devices are unique. To create this table, with the constraints, use this
+command:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+This example also references values in another `locations` table using a foreign
+key constraint.
+
+Time columns used for partitioning must not allow `NULL` values. A
+`NOT NULL` constraint is added by default to these columns if it doesn't already exist.
+
+For more information on how to manage constraints, see the
+[Postgres docs][postgres-createconstraint].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/about-indexing/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ
+ temp FLOAT NOT NULL,
+ device_id INTEGER CHECK (device_id > 0),
+ location INTEGER REFERENCES locations (id),
+ PRIMARY KEY(time, device_id)
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+```
+
+---
+
+## set_chunk_time_interval()
+
+**URL:** llms-txt#set_chunk_time_interval()
+
+**Contents:**
+- Samples
+- Arguments
+
+Sets the `chunk_time_interval` on a hypertable. The new interval is used
+when new chunks are created, and time intervals on existing chunks are
+not changed.
+
+For a TIMESTAMP column, set `chunk_time_interval` to 24 hours:
+
+For a time column expressed as the number of milliseconds since the
+UNIX epoch, set `chunk_time_interval` to 24 hours:
+
+| Name | Type | Default | Required | Description |
+|-------------|------------------|---------|----------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
+|`hypertable`|REGCLASS| - | ✔ | Hypertable or continuous aggregate to update interval for. |
+|`chunk_time_interval`|See note|- | ✔ | Event time that each new chunk covers. |
+|`dimension_name`|REGCLASS|- | ✖ | The name of the time dimension to set the number of partitions for. Only use `dimension_name` when your hypertable has multiple time dimensions. |
+
+If you change chunk time interval you may see a chunk that is smaller than the new interval. For example, if you
+have two 7-day chunks that cover 14 days, then change `chunk_time_interval` to 3 days, you may end up with a
+transition chunk covering one day. This happens because the start and end of the new chunk is calculated based on
+dividing the timeline by the `chunk_time_interval` starting at epoch 0. This leads to the following chunks
+[0, 3), [3, 6), [6, 9), [9, 12), [12, 15), [15, 18) and so on. The two 7-day chunks covered data up to day 14:
+[0, 7), [8, 14), so the 3-day chunk for [12, 15) is reduced to a one day chunk. The following chunk [15, 18) is
+created as a full 3 day chunk.
+
+The valid types for the `chunk_time_interval` depend on the type used for the
+hypertable `time` column:
+
+|`time` column type|`chunk_time_interval` type|Time unit|
+|-|-|-|
+|TIMESTAMP|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|TIMESTAMPTZ|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|DATE|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|SMALLINT|SMALLINT|The same time unit as the `time` column|
+|INT|INT|The same time unit as the `time` column|
+|BIGINT|BIGINT|The same time unit as the `time` column|
+
+For more information, see [hypertable partitioning][hypertable-partitioning].
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/show_tablespaces/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT set_chunk_time_interval('conditions', INTERVAL '24 hours');
+SELECT set_chunk_time_interval('conditions', 86400000000);
+```
+
+Example 2 (sql):
+```sql
+SELECT set_chunk_time_interval('conditions', 86400000);
+```
+
+---
+
+## drop_chunks()
+
+**URL:** llms-txt#drop_chunks()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Removes data chunks whose time range falls completely before (or
+after) a specified time. Shows a list of the chunks that were
+dropped, in the same style as the `show_chunks` [function][show_chunks].
+
+Chunks are constrained by a start and end time and the start time is
+always before the end time. A chunk is dropped if its end time is
+older than the `older_than` timestamp or, if `newer_than` is given,
+its start time is newer than the `newer_than` timestamp.
+
+Note that, because chunks are removed if and only if their time range
+falls fully before (or after) the specified timestamp, the remaining
+data may still contain timestamps that are before (or after) the
+specified one.
+
+Chunks can only be dropped based on their time intervals. They cannot be dropped
+based on a hash partition.
+
+Drop all chunks from hypertable `conditions` older than 3 months:
+
+Drop all chunks from hypertable `conditions` created before 3 months:
+
+Drop all chunks more than 3 months in the future from hypertable
+`conditions`. This is useful for correcting data ingested with
+incorrect clocks:
+
+Drop all chunks from hypertable `conditions` before 2017:
+
+Drop all chunks from hypertable `conditions` before 2017, where time
+column is given in milliseconds from the UNIX epoch:
+
+Drop all chunks older than 3 months ago and newer than 4 months ago from hypertable `conditions`:
+
+Drop all chunks created 3 months ago and created 4 months before from hypertable `conditions`:
+
+Drop all chunks older than 3 months ago across all hypertables:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`relation`|REGCLASS|Hypertable or continuous aggregate from which to drop chunks.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`older_than`|ANY|Specification of cut-off point where any chunks older than this timestamp should be removed.|
+|`newer_than`|ANY|Specification of cut-off point where any chunks newer than this timestamp should be removed.|
+|`verbose`|BOOLEAN|Setting to true displays messages about the progress of the reorder command. Defaults to false.|
+|`created_before`|ANY|Specification of cut-off point where any chunks created before this timestamp should be removed.|
+|`created_after`|ANY|Specification of cut-off point where any chunks created after this timestamp should be removed.|
+
+The `older_than` and `newer_than` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ older_than` and similarly `now() - newer_than`. An error is
+ returned if an INTERVAL is supplied and the time column is not one
+ of a `TIMESTAMP`, `TIMESTAMPTZ`, or `DATE`.
+
+* **timestamp, date, or integer type:** The cut-off point is
+ explicitly given as a `TIMESTAMP` / `TIMESTAMPTZ` / `DATE` or as a
+ `SMALLINT` / `INT` / `BIGINT`. The choice of timestamp or integer
+ must follow the type of the hypertable's time column.
+
+The `created_before` and `created_after` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ created_before` and similarly `now() - created_after`. This uses
+ the chunk creation time relative to the current time for the filtering.
+
+* **timestamp, date, or integer type:** The cut-off point is
+ explicitly given as a `TIMESTAMP` / `TIMESTAMPTZ` / `DATE` or as a
+ `SMALLINT` / `INT` / `BIGINT`. The choice of integer value
+ must follow the type of the hypertable's partitioning column. Otherwise
+ the chunk creation time is used for the filtering.
+
+When using just an interval type, the function assumes that
+you are removing things _in the past_. If you want to remove data
+in the future, for example to delete erroneous entries, use a timestamp.
+
+When both `older_than` and `newer_than` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `newer_than => 4 months` and `older_than => 3
+months` drops all chunks between 3 and 4 months old.
+Similarly, specifying `newer_than => '2017-01-01'` and `older_than
+=> '2017-02-01'` drops all chunks between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+When both `created_before` and `created_after` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `created_after` => 4 months` and `created_before`=> 3
+months` drops all chunks created between 3 and 4 months from now.
+Similarly, specifying `created_after`=> '2017-01-01'` and `created_before`
+=> '2017-02-01'` drops all chunks created between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+The `created_before`/`created_after` parameters cannot be used together with
+`older_than`/`newer_than`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/detach_chunk/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT drop_chunks('conditions', INTERVAL '3 months');
+```
+
+Example 2 (sql):
+```sql
+drop_chunks
+----------------------------------------
+ _timescaledb_internal._hyper_3_5_chunk
+ _timescaledb_internal._hyper_3_6_chunk
+ _timescaledb_internal._hyper_3_7_chunk
+ _timescaledb_internal._hyper_3_8_chunk
+ _timescaledb_internal._hyper_3_9_chunk
+(5 rows)
+```
+
+Example 3 (sql):
+```sql
+SELECT drop_chunks('conditions', created_before => now() - INTERVAL '3 months');
+```
+
+Example 4 (sql):
+```sql
+SELECT drop_chunks('conditions', newer_than => now() + interval '3 months');
+```
+
+---
+
+## add_compression_policy()
+
+**URL:** llms-txt#add_compression_policy()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by add_columnstore_policy().
+
+Allows you to set a policy by which the system compresses a chunk
+automatically in the background after it reaches a given age.
+
+Compression policies can only be created on hypertables or continuous aggregates
+that already have compression enabled. To set `timescaledb.compress` and other
+configuration parameters for hypertables, use the
+[`ALTER TABLE`][compression_alter-table]
+command. To enable compression on continuous aggregates, use the
+[`ALTER MATERIALIZED VIEW`][compression_continuous-aggregate]
+command. To view the policies that you set or the policies that already exist,
+see [informational views][informational-views].
+
+Add a policy to compress chunks older than 60 days on the `cpu` hypertable.
+
+Add a policy to compress chunks created 3 months before on the 'cpu' hypertable.
+
+Note above that when `compress_after` is used then the time data range
+present in the partitioning time column is used to select the target
+chunks. Whereas, when `compress_created_before` is used then the chunks
+which were created 3 months ago are selected.
+
+Add a compress chunks policy to a hypertable with an integer-based time column:
+
+Add a policy to compress chunks of a continuous aggregate called `cpu_weekly`, that are
+older than eight weeks:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Name of the hypertable or continuous aggregate|
+|`compress_after`|INTERVAL or INTEGER|The age after which the policy job compresses chunks. `compress_after` is calculated relative to the current time, so chunks containing data older than `now - {compress_after}::interval` are compressed. This argument is mutually exclusive with `compress_created_before`.|
+|`compress_created_before`|INTERVAL|Chunks with creation time older than this cut-off point are compressed. The cut-off point is computed as `now() - compress_created_before`. Defaults to `NULL`. Not supported for continuous aggregates yet. This argument is mutually exclusive with `compress_after`. |
+
+The `compress_after` parameter should be specified differently depending
+on the type of the time column of the hypertable or continuous aggregate:
+
+* For hypertables with TIMESTAMP, TIMESTAMPTZ, and DATE time columns: the time
+ interval should be an INTERVAL type.
+* For hypertables with integer-based timestamps: the time interval should be
+ an integer type (this requires the [integer_now_func][set_integer_now_func]
+ to be set).
+
+## Optional arguments
+
+
+
+|Name|Type|Description|
+|-|-|-|
+|`schedule_interval`|INTERVAL|The interval between the finish time of the last execution and the next start. Defaults to 12 hours for hyper tables with a `chunk_interval` >= 1 day and `chunk_interval / 2` for all other hypertables.|
+|`initial_start`|TIMESTAMPTZ|Time the policy is first run. Defaults to NULL. If omitted, then the schedule interval is the interval from the finish time of the last execution to the next start. If provided, it serves as the origin with respect to which the next_start is calculated |
+|`timezone`|TEXT|A valid time zone. If `initial_start` is also specified, subsequent executions of the compression policy are aligned on its initial start. However, daylight savings time (DST) changes may shift this alignment. Set to a valid time zone if this is an issue you want to mitigate. If omitted, UTC bucketing is performed. Defaults to `NULL`.|
+|`if_not_exists`|BOOLEAN|Setting to `true` causes the command to fail with a warning instead of an error if a compression policy already exists on the hypertable. Defaults to false.|
+
+
+
+
+===== PAGE: https://docs.tigerdata.com/api/compression/recompress_chunk/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+Add a policy to compress chunks created 3 months before on the 'cpu' hypertable.
+```
+
+Example 2 (unknown):
+```unknown
+Note above that when `compress_after` is used then the time data range
+present in the partitioning time column is used to select the target
+chunks. Whereas, when `compress_created_before` is used then the chunks
+which were created 3 months ago are selected.
+
+Add a compress chunks policy to a hypertable with an integer-based time column:
+```
+
+Example 3 (unknown):
+```unknown
+Add a policy to compress chunks of a continuous aggregate called `cpu_weekly`, that are
+older than eight weeks:
+```
+
+---
+
+## Distributed hypertables
+
+**URL:** llms-txt#distributed-hypertables
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Distributed hypertables are hypertables that span multiple nodes. With
+distributed hypertables, you can scale your data storage across multiple
+machines and benefit from parallelized processing for some queries.
+
+Many features of distributed hypertables work the same way as standard
+hypertables. To learn how hypertables work in general, see the
+[hypertables][hypertables] section.
+
+* [Learn about distributed hypertables][about-distributed-hypertables] for
+ multi-node databases
+* [Create a distributed hypertable][create]
+* [Insert data][insert] into distributed hypertables
+* [Query data][query] in distributed hypertables
+* [Alter and drop][alter-drop] distributed hypertables
+* [Create foreign keys][foreign-keys] on distributed hypertables
+* [Set triggers][triggers] on distributed hypertables
+
+===== PAGE: https://docs.tigerdata.com/mst/about-mst/ =====
+
+---
+
+## Manually drop chunks
+
+**URL:** llms-txt#manually-drop-chunks
+
+**Contents:**
+- Drop chunks older than a certain date
+- Drop chunks between 2 dates
+- Drop chunks in the future
+
+Drop chunks manually by time value. For example, drop chunks containing data
+older than 30 days.
+
+Dropping chunks manually is a one-time operation. To automatically drop chunks
+as they age, set up a
+[data retention policy](https://docs.tigerdata.com/use-timescale/latest/data-retention/create-a-retention-policy/).
+
+## Drop chunks older than a certain date
+
+To drop chunks older than a certain date, use the [`drop_chunks`][drop_chunks]
+function. Provide the name of the hypertable to drop chunks from, and a time
+interval beyond which to drop chunks.
+
+For example, to drop chunks with data older than 24 hours:
+
+## Drop chunks between 2 dates
+
+You can also drop chunks between 2 dates. For example, drop chunks with data
+between 3 and 4 months old.
+
+Supply a second `INTERVAL` argument for the `newer_than` cutoff:
+
+## Drop chunks in the future
+
+You can also drop chunks in the future, for example, to correct data with the
+wrong timestamp. To drop all chunks that are more than 3 months in the
+future, from a hypertable called `conditions`:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/data-retention/data-retention-with-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT drop_chunks('conditions', INTERVAL '24 hours');
+```
+
+Example 2 (sql):
+```sql
+SELECT drop_chunks(
+ 'conditions',
+ older_than => INTERVAL '3 months',
+ newer_than => INTERVAL '4 months'
+)
+```
+
+Example 3 (sql):
+```sql
+SELECT drop_chunks(
+ 'conditions',
+ newer_than => now() + INTERVAL '3 months'
+);
+```
+
+---
+
+## timescaledb_information.chunks
+
+**URL:** llms-txt#timescaledb_information.chunks
+
+**Contents:**
+- Samples
+- Available columns
+
+Get metadata about the chunks of hypertables.
+
+This view shows metadata for the chunk's primary time-based dimension.
+For information about a hypertable's secondary dimensions,
+the [dimensions view][dimensions] should be used instead.
+
+If the chunk's primary dimension is of a time datatype, `range_start` and
+`range_end` are set. Otherwise, if the primary dimension type is integer based,
+`range_start_integer` and `range_end_integer` are set.
+
+Get information about the chunks of a hypertable.
+
+Dimension builder `by_range` was introduced in TimescaleDB 2.13.
+The `chunk_creation_time` metadata was introduced in TimescaleDB 2.13.
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable_schema` | TEXT | Schema name of the hypertable |
+| `hypertable_name` | TEXT | Table name of the hypertable |
+| `chunk_schema` | TEXT | Schema name of the chunk |
+| `chunk_name` | TEXT | Name of the chunk |
+| `primary_dimension` | TEXT | Name of the column that is the primary dimension|
+| `primary_dimension_type` | REGTYPE | Type of the column that is the primary dimension|
+| `range_start` | TIMESTAMP WITH TIME ZONE | Start of the range for the chunk's dimension |
+| `range_end` | TIMESTAMP WITH TIME ZONE | End of the range for the chunk's dimension |
+| `range_start_integer` | BIGINT | Start of the range for the chunk's dimension, if the dimension type is integer based |
+| `range_end_integer` | BIGINT | End of the range for the chunk's dimension, if the dimension type is integer based |
+| `is_compressed` | BOOLEAN | Is the data in the chunk compressed?
+
+For example, say that your data's earliest timestamp is April 24, 2020. If you
+bucket by an interval of two weeks, the first bucket doesn't start on April 24,
+which is a Friday. It also doesn't start on April 20, which is the immediately
+preceding Monday. It starts on April 13, because you can get to April 13, 2020,
+by counting in two-week increments from January 3, 2000, which is the default
+origin in this case.
+
+For intervals that don't include months or years, the default origin is January
+3, 2000. For month, year, or century intervals, the default origin is January 1,
+2000. For integer time values, the default origin is 0.
+
+These choices make the time ranges of time buckets more intuitive. Because
+January 3, 2000, is a Monday, weekly time buckets start on Monday. This is
+compliant with the ISO standard for calculating calendar weeks. Monthly and
+yearly time buckets use January 1, 2000, as an origin. This allows them to start
+on the first day of the calendar month or year.
+
+If you prefer another origin, you can set it yourself using the [`origin`
+parameter][origin]. For example, to start weeks on Sunday, set the origin to
+Sunday, January 2, 2000.
+
+The origin time depends on the data type of your time values.
+
+If you use `TIMESTAMP`, by default, bucket start times are aligned with
+`00:00:00`. Daily and weekly buckets start at `00:00:00`. Shorter buckets start
+at a time that you can get to by counting in bucket increments from `00:00:00`
+on the origin date.
+
+If you use `TIMESTAMPTZ`, by default, bucket start times are aligned with
+`00:00:00 UTC`. To align time buckets to another timezone, set the `timezone`
+parameter.
+
+===== PAGE: https://docs.tigerdata.com/mst/vpc-peering/vpc-peering-gcp/ =====
+
+---
+
+## About constraints
+
+**URL:** llms-txt#about-constraints
+
+Constraints are rules that apply to your database columns. This prevents you
+from entering invalid data into your database. When you create, change, or
+delete constraints on your hypertables, the constraints are propagated to the
+underlying chunks, and to any indexes.
+
+Hypertables support all standard Postgres constraint types. For foreign keys in particular, the following is supported:
+
+- Foreign key constraints from a hypertable referencing a regular table
+- Foreign key constraints from a regular table referencing a hypertable
+
+Foreign keys from a hypertable referencing another hypertable **are not supported**.
+
+For example, you can create a table that only allows positive device IDs, and
+non-null temperature readings. You can also check that time values for all
+devices are unique. To create this table, with the constraints, use this
+command:
+
+If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+This example also references values in another `locations` table using a foreign
+key constraint.
+
+Time columns used for partitioning must not allow `NULL` values. A
+`NOT NULL` constraint is added by default to these columns if it doesn't already exist.
+
+For more information on how to manage constraints, see the
+[Postgres docs][postgres-createconstraint].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/about-indexing/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLE conditions (
+ time TIMESTAMPTZ
+ temp FLOAT NOT NULL,
+ device_id INTEGER CHECK (device_id > 0),
+ location INTEGER REFERENCES locations (id),
+ PRIMARY KEY(time, device_id)
+) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time'
+);
+```
+
+---
+
+## set_chunk_time_interval()
+
+**URL:** llms-txt#set_chunk_time_interval()
+
+**Contents:**
+- Samples
+- Arguments
+
+Sets the `chunk_time_interval` on a hypertable. The new interval is used
+when new chunks are created, and time intervals on existing chunks are
+not changed.
+
+For a TIMESTAMP column, set `chunk_time_interval` to 24 hours:
+
+For a time column expressed as the number of milliseconds since the
+UNIX epoch, set `chunk_time_interval` to 24 hours:
+
+| Name | Type | Default | Required | Description |
+|-------------|------------------|---------|----------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------|
+|`hypertable`|REGCLASS| - | ✔ | Hypertable or continuous aggregate to update interval for. |
+|`chunk_time_interval`|See note|- | ✔ | Event time that each new chunk covers. |
+|`dimension_name`|REGCLASS|- | ✖ | The name of the time dimension to set the number of partitions for. Only use `dimension_name` when your hypertable has multiple time dimensions. |
+
+If you change chunk time interval you may see a chunk that is smaller than the new interval. For example, if you
+have two 7-day chunks that cover 14 days, then change `chunk_time_interval` to 3 days, you may end up with a
+transition chunk covering one day. This happens because the start and end of the new chunk is calculated based on
+dividing the timeline by the `chunk_time_interval` starting at epoch 0. This leads to the following chunks
+[0, 3), [3, 6), [6, 9), [9, 12), [12, 15), [15, 18) and so on. The two 7-day chunks covered data up to day 14:
+[0, 7), [8, 14), so the 3-day chunk for [12, 15) is reduced to a one day chunk. The following chunk [15, 18) is
+created as a full 3 day chunk.
+
+The valid types for the `chunk_time_interval` depend on the type used for the
+hypertable `time` column:
+
+|`time` column type|`chunk_time_interval` type|Time unit|
+|-|-|-|
+|TIMESTAMP|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|TIMESTAMPTZ|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|DATE|INTERVAL|days, hours, minutes, etc|
+||INTEGER or BIGINT|microseconds|
+|SMALLINT|SMALLINT|The same time unit as the `time` column|
+|INT|INT|The same time unit as the `time` column|
+|BIGINT|BIGINT|The same time unit as the `time` column|
+
+For more information, see [hypertable partitioning][hypertable-partitioning].
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/show_tablespaces/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT set_chunk_time_interval('conditions', INTERVAL '24 hours');
+SELECT set_chunk_time_interval('conditions', 86400000000);
+```
+
+Example 2 (sql):
+```sql
+SELECT set_chunk_time_interval('conditions', 86400000);
+```
+
+---
+
+## drop_chunks()
+
+**URL:** llms-txt#drop_chunks()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Removes data chunks whose time range falls completely before (or
+after) a specified time. Shows a list of the chunks that were
+dropped, in the same style as the `show_chunks` [function][show_chunks].
+
+Chunks are constrained by a start and end time and the start time is
+always before the end time. A chunk is dropped if its end time is
+older than the `older_than` timestamp or, if `newer_than` is given,
+its start time is newer than the `newer_than` timestamp.
+
+Note that, because chunks are removed if and only if their time range
+falls fully before (or after) the specified timestamp, the remaining
+data may still contain timestamps that are before (or after) the
+specified one.
+
+Chunks can only be dropped based on their time intervals. They cannot be dropped
+based on a hash partition.
+
+Drop all chunks from hypertable `conditions` older than 3 months:
+
+Drop all chunks from hypertable `conditions` created before 3 months:
+
+Drop all chunks more than 3 months in the future from hypertable
+`conditions`. This is useful for correcting data ingested with
+incorrect clocks:
+
+Drop all chunks from hypertable `conditions` before 2017:
+
+Drop all chunks from hypertable `conditions` before 2017, where time
+column is given in milliseconds from the UNIX epoch:
+
+Drop all chunks older than 3 months ago and newer than 4 months ago from hypertable `conditions`:
+
+Drop all chunks created 3 months ago and created 4 months before from hypertable `conditions`:
+
+Drop all chunks older than 3 months ago across all hypertables:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`relation`|REGCLASS|Hypertable or continuous aggregate from which to drop chunks.|
+
+## Optional arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`older_than`|ANY|Specification of cut-off point where any chunks older than this timestamp should be removed.|
+|`newer_than`|ANY|Specification of cut-off point where any chunks newer than this timestamp should be removed.|
+|`verbose`|BOOLEAN|Setting to true displays messages about the progress of the reorder command. Defaults to false.|
+|`created_before`|ANY|Specification of cut-off point where any chunks created before this timestamp should be removed.|
+|`created_after`|ANY|Specification of cut-off point where any chunks created after this timestamp should be removed.|
+
+The `older_than` and `newer_than` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ older_than` and similarly `now() - newer_than`. An error is
+ returned if an INTERVAL is supplied and the time column is not one
+ of a `TIMESTAMP`, `TIMESTAMPTZ`, or `DATE`.
+
+* **timestamp, date, or integer type:** The cut-off point is
+ explicitly given as a `TIMESTAMP` / `TIMESTAMPTZ` / `DATE` or as a
+ `SMALLINT` / `INT` / `BIGINT`. The choice of timestamp or integer
+ must follow the type of the hypertable's time column.
+
+The `created_before` and `created_after` parameters can be specified in two ways:
+
+* **interval type:** The cut-off point is computed as `now() -
+ created_before` and similarly `now() - created_after`. This uses
+ the chunk creation time relative to the current time for the filtering.
+
+* **timestamp, date, or integer type:** The cut-off point is
+ explicitly given as a `TIMESTAMP` / `TIMESTAMPTZ` / `DATE` or as a
+ `SMALLINT` / `INT` / `BIGINT`. The choice of integer value
+ must follow the type of the hypertable's partitioning column. Otherwise
+ the chunk creation time is used for the filtering.
+
+When using just an interval type, the function assumes that
+you are removing things _in the past_. If you want to remove data
+in the future, for example to delete erroneous entries, use a timestamp.
+
+When both `older_than` and `newer_than` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `newer_than => 4 months` and `older_than => 3
+months` drops all chunks between 3 and 4 months old.
+Similarly, specifying `newer_than => '2017-01-01'` and `older_than
+=> '2017-02-01'` drops all chunks between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+When both `created_before` and `created_after` arguments are used, the
+function returns the intersection of the resulting two ranges. For
+example, specifying `created_after` => 4 months` and `created_before`=> 3
+months` drops all chunks created between 3 and 4 months from now.
+Similarly, specifying `created_after`=> '2017-01-01'` and `created_before`
+=> '2017-02-01'` drops all chunks created between '2017-01-01' and
+'2017-02-01'. Specifying parameters that do not result in an
+overlapping intersection between two ranges results in an error.
+
+The `created_before`/`created_after` parameters cannot be used together with
+`older_than`/`newer_than`.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/detach_chunk/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT drop_chunks('conditions', INTERVAL '3 months');
+```
+
+Example 2 (sql):
+```sql
+drop_chunks
+----------------------------------------
+ _timescaledb_internal._hyper_3_5_chunk
+ _timescaledb_internal._hyper_3_6_chunk
+ _timescaledb_internal._hyper_3_7_chunk
+ _timescaledb_internal._hyper_3_8_chunk
+ _timescaledb_internal._hyper_3_9_chunk
+(5 rows)
+```
+
+Example 3 (sql):
+```sql
+SELECT drop_chunks('conditions', created_before => now() - INTERVAL '3 months');
+```
+
+Example 4 (sql):
+```sql
+SELECT drop_chunks('conditions', newer_than => now() + interval '3 months');
+```
+
+---
+
+## add_compression_policy()
+
+**URL:** llms-txt#add_compression_policy()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Old API since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0) Replaced by add_columnstore_policy().
+
+Allows you to set a policy by which the system compresses a chunk
+automatically in the background after it reaches a given age.
+
+Compression policies can only be created on hypertables or continuous aggregates
+that already have compression enabled. To set `timescaledb.compress` and other
+configuration parameters for hypertables, use the
+[`ALTER TABLE`][compression_alter-table]
+command. To enable compression on continuous aggregates, use the
+[`ALTER MATERIALIZED VIEW`][compression_continuous-aggregate]
+command. To view the policies that you set or the policies that already exist,
+see [informational views][informational-views].
+
+Add a policy to compress chunks older than 60 days on the `cpu` hypertable.
+
+Add a policy to compress chunks created 3 months before on the 'cpu' hypertable.
+
+Note above that when `compress_after` is used then the time data range
+present in the partitioning time column is used to select the target
+chunks. Whereas, when `compress_created_before` is used then the chunks
+which were created 3 months ago are selected.
+
+Add a compress chunks policy to a hypertable with an integer-based time column:
+
+Add a policy to compress chunks of a continuous aggregate called `cpu_weekly`, that are
+older than eight weeks:
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Name of the hypertable or continuous aggregate|
+|`compress_after`|INTERVAL or INTEGER|The age after which the policy job compresses chunks. `compress_after` is calculated relative to the current time, so chunks containing data older than `now - {compress_after}::interval` are compressed. This argument is mutually exclusive with `compress_created_before`.|
+|`compress_created_before`|INTERVAL|Chunks with creation time older than this cut-off point are compressed. The cut-off point is computed as `now() - compress_created_before`. Defaults to `NULL`. Not supported for continuous aggregates yet. This argument is mutually exclusive with `compress_after`. |
+
+The `compress_after` parameter should be specified differently depending
+on the type of the time column of the hypertable or continuous aggregate:
+
+* For hypertables with TIMESTAMP, TIMESTAMPTZ, and DATE time columns: the time
+ interval should be an INTERVAL type.
+* For hypertables with integer-based timestamps: the time interval should be
+ an integer type (this requires the [integer_now_func][set_integer_now_func]
+ to be set).
+
+## Optional arguments
+
+
+
+|Name|Type|Description|
+|-|-|-|
+|`schedule_interval`|INTERVAL|The interval between the finish time of the last execution and the next start. Defaults to 12 hours for hyper tables with a `chunk_interval` >= 1 day and `chunk_interval / 2` for all other hypertables.|
+|`initial_start`|TIMESTAMPTZ|Time the policy is first run. Defaults to NULL. If omitted, then the schedule interval is the interval from the finish time of the last execution to the next start. If provided, it serves as the origin with respect to which the next_start is calculated |
+|`timezone`|TEXT|A valid time zone. If `initial_start` is also specified, subsequent executions of the compression policy are aligned on its initial start. However, daylight savings time (DST) changes may shift this alignment. Set to a valid time zone if this is an issue you want to mitigate. If omitted, UTC bucketing is performed. Defaults to `NULL`.|
+|`if_not_exists`|BOOLEAN|Setting to `true` causes the command to fail with a warning instead of an error if a compression policy already exists on the hypertable. Defaults to false.|
+
+
+
+
+===== PAGE: https://docs.tigerdata.com/api/compression/recompress_chunk/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+Add a policy to compress chunks created 3 months before on the 'cpu' hypertable.
+```
+
+Example 2 (unknown):
+```unknown
+Note above that when `compress_after` is used then the time data range
+present in the partitioning time column is used to select the target
+chunks. Whereas, when `compress_created_before` is used then the chunks
+which were created 3 months ago are selected.
+
+Add a compress chunks policy to a hypertable with an integer-based time column:
+```
+
+Example 3 (unknown):
+```unknown
+Add a policy to compress chunks of a continuous aggregate called `cpu_weekly`, that are
+older than eight weeks:
+```
+
+---
+
+## Distributed hypertables
+
+**URL:** llms-txt#distributed-hypertables
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Distributed hypertables are hypertables that span multiple nodes. With
+distributed hypertables, you can scale your data storage across multiple
+machines and benefit from parallelized processing for some queries.
+
+Many features of distributed hypertables work the same way as standard
+hypertables. To learn how hypertables work in general, see the
+[hypertables][hypertables] section.
+
+* [Learn about distributed hypertables][about-distributed-hypertables] for
+ multi-node databases
+* [Create a distributed hypertable][create]
+* [Insert data][insert] into distributed hypertables
+* [Query data][query] in distributed hypertables
+* [Alter and drop][alter-drop] distributed hypertables
+* [Create foreign keys][foreign-keys] on distributed hypertables
+* [Set triggers][triggers] on distributed hypertables
+
+===== PAGE: https://docs.tigerdata.com/mst/about-mst/ =====
+
+---
+
+## Manually drop chunks
+
+**URL:** llms-txt#manually-drop-chunks
+
+**Contents:**
+- Drop chunks older than a certain date
+- Drop chunks between 2 dates
+- Drop chunks in the future
+
+Drop chunks manually by time value. For example, drop chunks containing data
+older than 30 days.
+
+Dropping chunks manually is a one-time operation. To automatically drop chunks
+as they age, set up a
+[data retention policy](https://docs.tigerdata.com/use-timescale/latest/data-retention/create-a-retention-policy/).
+
+## Drop chunks older than a certain date
+
+To drop chunks older than a certain date, use the [`drop_chunks`][drop_chunks]
+function. Provide the name of the hypertable to drop chunks from, and a time
+interval beyond which to drop chunks.
+
+For example, to drop chunks with data older than 24 hours:
+
+## Drop chunks between 2 dates
+
+You can also drop chunks between 2 dates. For example, drop chunks with data
+between 3 and 4 months old.
+
+Supply a second `INTERVAL` argument for the `newer_than` cutoff:
+
+## Drop chunks in the future
+
+You can also drop chunks in the future, for example, to correct data with the
+wrong timestamp. To drop all chunks that are more than 3 months in the
+future, from a hypertable called `conditions`:
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/data-retention/data-retention-with-continuous-aggregates/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT drop_chunks('conditions', INTERVAL '24 hours');
+```
+
+Example 2 (sql):
+```sql
+SELECT drop_chunks(
+ 'conditions',
+ older_than => INTERVAL '3 months',
+ newer_than => INTERVAL '4 months'
+)
+```
+
+Example 3 (sql):
+```sql
+SELECT drop_chunks(
+ 'conditions',
+ newer_than => now() + INTERVAL '3 months'
+);
+```
+
+---
+
+## timescaledb_information.chunks
+
+**URL:** llms-txt#timescaledb_information.chunks
+
+**Contents:**
+- Samples
+- Available columns
+
+Get metadata about the chunks of hypertables.
+
+This view shows metadata for the chunk's primary time-based dimension.
+For information about a hypertable's secondary dimensions,
+the [dimensions view][dimensions] should be used instead.
+
+If the chunk's primary dimension is of a time datatype, `range_start` and
+`range_end` are set. Otherwise, if the primary dimension type is integer based,
+`range_start_integer` and `range_end_integer` are set.
+
+Get information about the chunks of a hypertable.
+
+Dimension builder `by_range` was introduced in TimescaleDB 2.13.
+The `chunk_creation_time` metadata was introduced in TimescaleDB 2.13.
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable_schema` | TEXT | Schema name of the hypertable |
+| `hypertable_name` | TEXT | Table name of the hypertable |
+| `chunk_schema` | TEXT | Schema name of the chunk |
+| `chunk_name` | TEXT | Name of the chunk |
+| `primary_dimension` | TEXT | Name of the column that is the primary dimension|
+| `primary_dimension_type` | REGTYPE | Type of the column that is the primary dimension|
+| `range_start` | TIMESTAMP WITH TIME ZONE | Start of the range for the chunk's dimension |
+| `range_end` | TIMESTAMP WITH TIME ZONE | End of the range for the chunk's dimension |
+| `range_start_integer` | BIGINT | Start of the range for the chunk's dimension, if the dimension type is integer based |
+| `range_end_integer` | BIGINT | End of the range for the chunk's dimension, if the dimension type is integer based |
+| `is_compressed` | BOOLEAN | Is the data in the chunk compressed?
Note that for distributed hypertables, this is the cached compression status of the chunk on the access node. The cached status on the access node and data node is not in sync in some scenarios. For example, if a user compresses or decompresses the chunk on the data node instead of the access node, or sets up compression policies directly on data nodes.
Use `chunk_compression_stats()` function to get real-time compression status for distributed chunks.|
+| `chunk_tablespace` | TEXT | Tablespace used by the chunk|
+| `data_nodes` | ARRAY | Nodes on which the chunk is replicated. This is applicable only to chunks for distributed hypertables |
+| `chunk_creation_time` | TIMESTAMP WITH TIME ZONE | The time when this chunk was created for data addition |
+
+===== PAGE: https://docs.tigerdata.com/api/informational-views/data_nodes/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE TABLESPACE tablespace1 location '/usr/local/pgsql/data1';
+
+CREATE TABLE hyper_int (a_col integer, b_col integer, c integer);
+SELECT table_name from create_hypertable('hyper_int', by_range('a_col', 10));
+CREATE OR REPLACE FUNCTION integer_now_hyper_int() returns int LANGUAGE SQL STABLE as $$ SELECT coalesce(max(a_col), 0) FROM hyper_int $$;
+SELECT set_integer_now_func('hyper_int', 'integer_now_hyper_int');
+
+INSERT INTO hyper_int SELECT generate_series(1,5,1), 10, 50;
+
+SELECT attach_tablespace('tablespace1', 'hyper_int');
+INSERT INTO hyper_int VALUES( 25 , 14 , 20), ( 25, 15, 20), (25, 16, 20);
+
+SELECT * FROM timescaledb_information.chunks WHERE hypertable_name = 'hyper_int';
+
+-[ RECORD 1 ]----------+----------------------
+hypertable_schema | public
+hypertable_name | hyper_int
+chunk_schema | _timescaledb_internal
+chunk_name | _hyper_7_10_chunk
+primary_dimension | a_col
+primary_dimension_type | integer
+range_start |
+range_end |
+range_start_integer | 0
+range_end_integer | 10
+is_compressed | f
+chunk_tablespace |
+data_nodes |
+-[ RECORD 2 ]----------+----------------------
+hypertable_schema | public
+hypertable_name | hyper_int
+chunk_schema | _timescaledb_internal
+chunk_name | _hyper_7_11_chunk
+primary_dimension | a_col
+primary_dimension_type | integer
+range_start |
+range_end |
+range_start_integer | 20
+range_end_integer | 30
+is_compressed | f
+chunk_tablespace | tablespace1
+data_nodes |
+```
+
+---
+
+## Delete data
+
+**URL:** llms-txt#delete-data
+
+**Contents:**
+- Delete data with DELETE command
+- Delete data by dropping chunks
+
+You can delete data from a hypertable using a standard
+[`DELETE`][postgres-delete] SQL command. If you want to delete old data once it
+reaches a certain age, you can also drop entire chunks or set up a data
+retention policy.
+
+## Delete data with DELETE command
+
+To delete data from a table, use the syntax `DELETE FROM ...`. In this example,
+data is deleted from the table `conditions`, if the row's `temperature` or
+`humidity` is below a certain level:
+
+If you delete a lot of data, run
+[`VACUUM`](https://www.postgresql.org/docs/current/sql-vacuum.html) or
+`VACUUM FULL` to reclaim storage from the deleted or obsolete rows.
+
+## Delete data by dropping chunks
+
+TimescaleDB allows you to delete data by age, by dropping chunks from a
+hypertable. You can do so either manually or by data retention policy.
+
+To learn more, see the [data retention section][data-retention].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/write-data/update/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+DELETE FROM conditions WHERE temperature < 35 OR humidity < 60;
+```
+
+---
+
+## attach_tablespace()
+
+**URL:** llms-txt#attach_tablespace()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Attach a tablespace to a hypertable and use it to store chunks. A
+[tablespace][postgres-tablespaces] is a directory on the filesystem
+that allows control over where individual tables and indexes are
+stored on the filesystem. A common use case is to create a tablespace
+for a particular storage disk, allowing tables to be stored
+there. To learn more, see the [Postgres documentation on
+tablespaces][postgres-tablespaces].
+
+TimescaleDB can manage a set of tablespaces for each hypertable,
+automatically spreading chunks across the set of tablespaces attached
+to a hypertable. If a hypertable is hash partitioned, TimescaleDB
+tries to place chunks that belong to the same partition in the same
+tablespace. Changing the set of tablespaces attached to a hypertable
+may also change the placement behavior. A hypertable with no attached
+tablespaces has its chunks placed in the database's default
+tablespace.
+
+Attach the tablespace `disk1` to the hypertable `conditions`:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `tablespace` | TEXT | Name of the tablespace to attach.|
+| `hypertable` | REGCLASS | Hypertable to attach the tablespace to.|
+
+Tablespaces need to be [created][postgres-createtablespace] before
+being attached to a hypertable. Once created, tablespaces can be
+attached to multiple hypertables simultaneously to share the
+underlying disk storage. Associating a regular table with a tablespace
+using the `TABLESPACE` option to `CREATE TABLE`, prior to calling
+`create_hypertable`, has the same effect as calling
+`attach_tablespace` immediately following `create_hypertable`.
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `if_not_attached` | BOOLEAN |Set to true to avoid throwing an error if the tablespace is already attached to the table. A notice is issued instead. Defaults to false. |
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/hypertable_size/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT attach_tablespace('disk1', 'conditions');
+SELECT attach_tablespace('disk2', 'conditions', if_not_attached => true);
+```
+
+---
+
+## Use triggers on distributed hypertables
+
+**URL:** llms-txt#use-triggers-on-distributed-hypertables
+
+**Contents:**
+- Create a trigger on a distributed hypertable
+ - Creating a trigger on a distributed hypertable
+- Avoid processing a trigger multiple times
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Triggers on distributed hypertables work in much the same way as triggers on
+standard hypertables, and have the same limitations. But there are some
+differences due to the data being distributed across multiple nodes:
+
+* Row-level triggers fire on the data node where the row is inserted. The
+ triggers must fire where the data is stored, because `BEFORE` and `AFTER`
+ row triggers need access to the stored data. The chunks on the access node
+ do not contain any data, so they have no triggers.
+* Statement-level triggers fire once on each affected node, including the
+ access node. For example, if a distributed hypertable includes 3 data nodes,
+ inserting 2 rows of data executes a statement-level trigger on the access
+ node and either 1 or 2 data nodes, depending on whether the rows go to the
+ same or different nodes.
+* A replication factor greater than 1 further causes
+ the trigger to fire on multiple nodes. Each replica node fires the trigger.
+
+## Create a trigger on a distributed hypertable
+
+Create a trigger on a distributed hypertable by using [`CREATE
+TRIGGER`][create-trigger] as usual. The trigger, and the function it executes,
+is automatically created on each data node. If the trigger function references
+any other functions or objects, they need to be present on all nodes before you
+create the trigger.
+
+### Creating a trigger on a distributed hypertable
+
+1. If your trigger needs to reference another function or object, use
+ [`distributed_exec`][distributed_exec] to create the function or object on
+ all nodes.
+1. Create the trigger function on the access node. This example creates a dummy
+ trigger that raises the notice 'trigger fired':
+
+1. Create the trigger itself on the access node. This example causes the
+ trigger to fire whenever a row is inserted into the hypertable `hyper`. Note
+ that you don't need to manually create the trigger on the data nodes. This is
+ done automatically for you.
+
+## Avoid processing a trigger multiple times
+
+If you have a statement-level trigger, or a replication factor greater than 1,
+the trigger fires multiple times. To avoid repetitive firing, you can set the
+trigger function to check which data node it is executing on.
+
+For example, write a trigger function that raises a different notice on the
+access node compared to a data node:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/distributed-hypertables/query/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+CREATE OR REPLACE FUNCTION my_trigger_func()
+ RETURNS TRIGGER LANGUAGE PLPGSQL AS
+ body$
+ BEGIN
+ RAISE NOTICE 'trigger fired';
+ RETURN NEW;
+ END
+ body$;
+```
+
+Example 2 (sql):
+```sql
+CREATE TRIGGER my_trigger
+ AFTER INSERT ON hyper
+ FOR EACH ROW
+ EXECUTE FUNCTION my_trigger_func();
+```
+
+Example 3 (sql):
+```sql
+CREATE OR REPLACE FUNCTION my_trigger_func()
+ RETURNS TRIGGER LANGUAGE PLPGSQL AS
+body$
+DECLARE
+ is_access_node boolean;
+BEGIN
+ SELECT is_distributed INTO is_access_node
+ FROM timescaledb_information.hypertables
+ WHERE hypertable_name =
+ AND hypertable_schema = ;
+
+ IF is_access_node THEN
+ RAISE NOTICE 'trigger fired on the access node';
+ ELSE
+ RAISE NOTICE 'trigger fired on a data node';
+ END IF;
+
+ RETURN NEW;
+END
+body$;
+```
+
+---
+
+## remove_columnstore_policy()
+
+**URL:** llms-txt#remove_columnstore_policy()
+
+**Contents:**
+- Samples
+- Arguments
+
+Remove a columnstore policy from a hypertable or continuous aggregate.
+
+To restart automatic chunk migration to the columnstore, you need to call
+[add_columnstore_policy][add_columnstore_policy] again.
+
+Since [TimescaleDB v2.18.0](https://github.com/timescale/timescaledb/releases/tag/2.18.0)
+
+You see the columnstore policies in the [informational views][informational-views].
+
+- **Remove the columnstore policy from the `cpu` table**:
+
+- **Remove the columnstore policy from the `cpu_weekly` continuous aggregate**:
+
+| Name | Type | Default | Required | Description |
+|--|--|--|--|-|
+|`hypertable`|REGCLASS|-|✔| Name of the hypertable or continuous aggregate to remove the policy from|
+| `if_exists` | BOOLEAN | `false` |✖| Set to `true` so this job fails with a warning rather than an error if a columnstore policy does not exist on `hypertable` |
+
+===== PAGE: https://docs.tigerdata.com/api/hypercore/chunk_columnstore_settings/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+- **Remove the columnstore policy from the `cpu_weekly` continuous aggregate**:
+```
+
+---
+
+## Slow tiering of chunks
+
+**URL:** llms-txt#slow-tiering-of-chunks
+
+
+
+Chunks are tiered asynchronously. Chunks are selected to be tiered to the object storage tier one at a time ordered by their enqueue time.
+
+To see the chunks waiting to be tiered query the `timescaledb_osm.chunks_queued_for_tiering` view
+
+Processing all the chunks in the queue may take considerable time if a large quantity of data is being migrated to the object storage tier.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/index/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+select count(*) from timescaledb_osm.chunks_queued_for_tiering
+```
+
+---
+
+## set_number_partitions()
+
+**URL:** llms-txt#set_number_partitions()
+
+**Contents:**
+- Required arguments
+- Optional arguments
+- Sample usage
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Sets the number of partitions (slices) of a space dimension on a
+hypertable. The new partitioning only affects new chunks.
+
+## Required arguments
+
+| Name | Type | Description |
+| --- | --- | --- |
+| `hypertable`| REGCLASS | Hypertable to update the number of partitions for.|
+| `number_partitions` | INTEGER | The new number of partitions for the dimension. Must be greater than 0 and less than 32,768. |
+
+## Optional arguments
+
+| Name | Type | Description |
+| --- | --- | --- |
+| `dimension_name` | REGCLASS | The name of the space dimension to set the number of partitions for. |
+
+The `dimension_name` needs to be explicitly specified only if the
+hypertable has more than one space dimension. An error is thrown
+otherwise.
+
+For a table with a single space dimension:
+
+For a table with more than one space dimension:
+
+===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/add_data_node/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT set_number_partitions('conditions', 2);
+```
+
+Example 2 (sql):
+```sql
+SELECT set_number_partitions('conditions', 2, 'device_id');
+```
+
+---
+
+## Information views
+
+**URL:** llms-txt#information-views
+
+TimescaleDB makes complex database features like partitioning and data retention
+easy to use with our comprehensive APIs. TimescaleDB works hard to provide
+detailed information about the state of your data, hypertables, chunks, and any
+jobs or policies you have in place.
+
+These views provide the data and statistics you need to keep track of your
+database.
+
+===== PAGE: https://docs.tigerdata.com/api/configuration/ =====
+
+---
+
+## Real-time aggregates
+
+**URL:** llms-txt#real-time-aggregates
+
+**Contents:**
+- Use real-time aggregates
+- Real-time aggregates and refreshing historical data
+
+Rapidly growing data means you need more control over what to aggregate and how to aggregate it. With this in mind, Tiger Data equips you with tools for more fine-tuned data analysis.
+
+By default, continuous aggregates do not include the most recent data chunk from the
+underlying hypertable. Real-time aggregates, however, use the aggregated data **and** add the
+most recent raw data to it. This provides accurate and up-to-date results, without
+needing to aggregate data as it is being written.
+
+In TimescaleDB v2.13 and later, real-time aggregates are **DISABLED** by default. In earlier versions, real-time aggregates are **ENABLED** by default; when you create a continuous aggregate, queries to that view include the results from the most recent raw data.
+
+For more detail on the comparison between continuous and real-time aggregates,
+see our [real-time aggregate blog post][blog-rtaggs].
+
+## Use real-time aggregates
+
+You can enable and disable real-time aggregation by setting the
+`materialized_only` parameter when you create or alter the view.
+
+1. Enable real-time aggregation for an existing continuous aggregate:
+
+1. Disable real-time aggregation:
+
+## Real-time aggregates and refreshing historical data
+
+Real-time aggregates automatically add the most recent data when you query your
+continuous aggregate. In other words, they include data _more recent than_ your
+last materialized bucket.
+
+If you add new _historical_ data to an already-materialized bucket, it won't be
+reflected in a real-time aggregate. You should wait for the next scheduled
+refresh, or manually refresh by calling `refresh_continuous_aggregate`. You can
+think of real-time aggregates as being eventually consistent for historical
+data.
+
+For more information, see the [troubleshooting section][troubleshooting].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/continuous-aggregates/create-a-continuous-aggregate/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER MATERIALIZED VIEW table_name set (timescaledb.materialized_only = false);
+```
+
+Example 2 (sql):
+```sql
+ALTER MATERIALIZED VIEW table_name set (timescaledb.materialized_only = true);
+```
+
+---
+
+## detach_tablespace()
+
+**URL:** llms-txt#detach_tablespace()
+
+**Contents:**
+- Samples
+- Required arguments
+- Optional arguments
+
+Detach a tablespace from one or more hypertables. This _only_ means
+that _new_ chunks are not placed on the detached tablespace. This
+is useful, for instance, when a tablespace is running low on disk
+space and one would like to prevent new chunks from being created in
+the tablespace. The detached tablespace itself and any existing chunks
+with data on it remains unchanged and continue to work as
+before, including being available for queries. Note that newly
+inserted data rows may still be inserted into an existing chunk on the
+detached tablespace since existing data is not cleared from a detached
+tablespace. A detached tablespace can be reattached if desired to once
+again be considered for chunk placement.
+
+Detach the tablespace `disk1` from the hypertable `conditions`:
+
+Detach the tablespace `disk1` from all hypertables that the current
+user has permissions for:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `tablespace` | TEXT | Tablespace to detach.|
+
+When giving only the tablespace name as argument, the given tablespace
+is detached from all hypertables that the current role has the
+appropriate permissions for. Therefore, without proper permissions,
+the tablespace may still receive new chunks after this command
+is issued.
+
+## Optional arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Hypertable to detach a the tablespace from.|
+| `if_attached` | BOOLEAN | Set to true to avoid throwing an error if the tablespace is not attached to the given table. A notice is issued instead. Defaults to false. |
+
+When specifying a specific hypertable, the tablespace is only
+detached from the given hypertable and thus may remain attached to
+other hypertables.
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/chunks_detailed_size/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT detach_tablespace('disk1', 'conditions');
+SELECT detach_tablespace('disk2', 'conditions', if_attached => true);
+```
+
+Example 2 (sql):
+```sql
+SELECT detach_tablespace('disk1');
+```
+
+---
+
+## About tablespaces
+
+**URL:** llms-txt#about-tablespaces
+
+**Contents:**
+- How hypertable chunks are assigned tablespaces
+
+Tablespaces are used to determine the physical location of the tables and
+indexes in your database. In most cases, you want to use faster storage to store
+data that is accessed frequently, and slower storage for data that is accessed
+less often.
+
+Hypertables consist of a number of chunks, and each chunk can be located in a
+specific tablespace. This allows you to grow your hypertables across many disks.
+When you create a new chunk, a tablespace is automatically selected to store the
+chunk's data.
+
+You can attach and detach tablespaces on a hypertable. When a disk runs
+out of space, you can [detach][detach_tablespace] the full tablespace from the
+hypertable, and than [attach][attach_tablespace] a tablespace associated with a
+new disk. To see the tablespaces for you hypertable, use the
+[`show_tablespaces`][show_tablespaces]
+command.
+
+## How hypertable chunks are assigned tablespaces
+
+A hypertable can be partitioned in multiple dimensions, but only one of the
+dimensions is used to determine the tablespace assigned to a particular
+hypertable chunk. If a hypertable has one or more hash-partitioned, or space,
+dimensions, it uses the first hash-partitioned dimension. Otherwise, it uses the
+first time dimension.
+
+This strategy ensures that hash-partitioned hypertables have chunks co-located
+according to hash partition, as long as the list of tablespaces attached to the
+hypertable remains the same. Modulo calculation is used to pick a tablespace, so
+there can be more partitions than tablespaces. For example, if there are two
+tablespaces, partition number three uses the first tablespace.
+
+Hypertables that are only time-partitioned add new partitions continuously, and
+therefore have chunks assigned to tablespaces in a way similar to round-robin.
+
+It is possible to attach more tablespaces than there are partitions for the
+hypertable. In this case, some tablespaces remain unused until others are detached
+or additional partitions are added. This is especially true for hash-partitioned
+tables.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/about-schemas/ =====
+
+---
+
+## Altering and updating table schemas
+
+**URL:** llms-txt#altering-and-updating-table-schemas
+
+To modify the schema of an existing hypertable, you can use the `ALTER TABLE`
+command. When you change the hypertable schema, the changes are also propagated
+to each underlying chunk.
+
+While you can change the schema of an existing hypertable, you cannot change
+the schema of a continuous aggregate. For continuous aggregates, the only
+permissible changes are renaming a view, setting a schema, changing the owner,
+and adjusting other parameters.
+
+For example, to add a new column called `address` to a table called `distributors`:
+
+This creates the new column, with all existing entries recording `NULL` for the
+new column.
+
+Changing the schema can, in some cases, consume a lot of resources. This is
+especially true if it requires underlying data to be rewritten. If you want to
+check your schema change before you apply it, you can use a `CHECK` constraint,
+like this:
+
+This scans the table to verify that existing rows meet the constraint, but does
+not require a table rewrite.
+
+For more information, see the
+[Postgres ALTER TABLE documentation][postgres-alter-table].
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/schema-management/about-constraints/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+ALTER TABLE distributors
+ ADD COLUMN address varchar(30);
+```
+
+Example 2 (sql):
+```sql
+ALTER TABLE distributors
+ ADD CONSTRAINT zipchk
+ CHECK (char_length(zipcode) = 5);
+```
+
+---
+
+## detach_tablespaces()
+
+**URL:** llms-txt#detach_tablespaces()
+
+**Contents:**
+- Samples
+- Required arguments
+
+Detach all tablespaces from a hypertable. After issuing this command
+on a hypertable, it no longer has any tablespaces attached to
+it. New chunks are instead placed in the database's default
+tablespace.
+
+Detach all tablespaces from the hypertable `conditions`:
+
+## Required arguments
+
+|Name|Type|Description|
+|---|---|---|
+| `hypertable` | REGCLASS | Hypertable to detach a the tablespace from.|
+
+===== PAGE: https://docs.tigerdata.com/api/hypertable/create_hypertable/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT detach_tablespaces('conditions');
+```
+
+---
+
+## hypertable_size()
+
+**URL:** llms-txt#hypertable_size()
+
+**Contents:**
+- Samples
+- Required arguments
+- Returns
+
+Get the total disk space used by a hypertable or continuous aggregate,
+that is, the sum of the size for the table itself including chunks,
+any indexes on the table, and any toast tables. The size is reported
+in bytes. This is equivalent to computing the sum of `total_bytes`
+column from the output of `hypertable_detailed_size` function.
+
+When a continuous aggregate name is provided, the function
+transparently looks up the backing hypertable and returns its statistics
+instead.
+
+For more information about using hypertables, including chunk size partitioning,
+see the [hypertable section][hypertable-docs].
+
+Get the size information for a hypertable.
+
+Get the size information for all hypertables.
+
+Get the size information for a continuous aggregate.
+
+## Required arguments
+
+|Name|Type|Description|
+|-|-|-|
+|`hypertable`|REGCLASS|Hypertable or continuous aggregate to show size of.|
+
+|Name|Type|Description|
+|-|-|-|
+|hypertable_size|BIGINT|Total disk space used by the specified hypertable, including all indexes and TOAST data|
+
+`NULL` is returned if the function is executed on a non-hypertable relation.
+
+===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/alter_policies/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT hypertable_size('devices');
+
+ hypertable_size
+-----------------
+ 73728
+```
+
+Example 2 (sql):
+```sql
+SELECT hypertable_name, hypertable_size(format('%I.%I', hypertable_schema, hypertable_name)::regclass)
+ FROM timescaledb_information.hypertables;
+```
+
+Example 3 (sql):
+```sql
+SELECT hypertable_size('device_stats_15m');
+
+ hypertable_size
+-----------------
+ 73728
+```
+
+---
diff --git a/skills/timescaledb/references/index.md b/skills/timescaledb/references/index.md
new file mode 100644
index 0000000..27237af
--- /dev/null
+++ b/skills/timescaledb/references/index.md
@@ -0,0 +1,47 @@
+# Timescaledb Documentation Index
+
+## Categories
+
+### Api
+**File:** `api.md`
+**Pages:** 100
+
+### Compression
+**File:** `compression.md`
+**Pages:** 19
+
+### Continuous Aggregates
+**File:** `continuous_aggregates.md`
+**Pages:** 21
+
+### Getting Started
+**File:** `getting_started.md`
+**Pages:** 3
+
+### Hyperfunctions
+**File:** `hyperfunctions.md`
+**Pages:** 34
+
+### Hypertables
+**File:** `hypertables.md`
+**Pages:** 103
+
+### Installation
+**File:** `installation.md`
+**Pages:** 37
+
+### Other
+**File:** `other.md`
+**Pages:** 248
+
+### Performance
+**File:** `performance.md`
+**Pages:** 2
+
+### Time Buckets
+**File:** `time_buckets.md`
+**Pages:** 16
+
+### Tutorials
+**File:** `tutorials.md`
+**Pages:** 12
diff --git a/skills/timescaledb/references/installation.md b/skills/timescaledb/references/installation.md
new file mode 100644
index 0000000..a38d453
--- /dev/null
+++ b/skills/timescaledb/references/installation.md
@@ -0,0 +1,4019 @@
+# Timescaledb - Installation
+
+**Pages:** 37
+
+---
+
+## Install TimescaleDB on Kubernetes
+
+**URL:** llms-txt#install-timescaledb-on-kubernetes
+
+**Contents:**
+- Prerequisites
+- Integrate TimescaleDB in a Kubernetes cluster
+- Install with Postgres Kubernetes operators
+
+You can run TimescaleDB inside Kubernetes using the TimescaleDB Docker container images.
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+To follow the steps on this page:
+
+- Install [self-managed Kubernetes][kubernetes-install] or sign up for a Kubernetes [Turnkey Cloud Solution][kubernetes-managed].
+- Install [kubectl][kubectl] for command-line interaction with your cluster.
+
+## Integrate TimescaleDB in a Kubernetes cluster
+
+Running TimescaleDB on Kubernetes is similar to running Postgres. This procedure outlines the steps for a non-distributed system.
+
+To connect your Kubernetes cluster to self-hosted TimescaleDB running in the cluster:
+
+1. **Create a default namespace for Tiger Data components**
+
+1. Create the Tiger Data namespace:
+
+1. Set this namespace as the default for your session:
+
+For more information, see [Kubernetes Namespaces][kubernetes-namespace].
+
+1. **Set up a persistent volume claim (PVC) storage**
+
+To manually set up a persistent volume and claim for self-hosted Kubernetes, run the following command:
+
+1. **Deploy TimescaleDB as a StatefulSet**
+
+By default, the [TimescaleDB Docker image][timescale-docker-image] you are installing on Kubernetes uses the
+ default Postgres database, user and password. To deploy TimescaleDB on Kubernetes, run the following command:
+
+1. **Allow applications to connect by exposing TimescaleDB within Kubernetes**
+
+1. **Create a Kubernetes secret to store the database credentials**
+
+1. **Deploy an application that connects to TimescaleDB**
+
+1. **Test the database connection**
+
+1. Create and run a pod to verify database connectivity using your [connection details][connection-info] saved in `timescale-secret`:
+
+1. Launch the Postgres interactive shell within the created `test-pod`:
+
+You see the Postgres interactive terminal.
+
+## Install with Postgres Kubernetes operators
+
+You can also use Postgres Kubernetes operators to simplify installation, configuration, and life cycle. The operators which our community members have
+told us work well are:
+
+- [StackGres][stackgres] (includes TimescaleDB images)
+- [Postgres Operator (Patroni)][patroni]
+- [PGO][pgo]
+- [CloudNativePG][cnpg]
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-source/ =====
+
+**Examples:**
+
+Example 1 (shell):
+```shell
+kubectl create namespace timescale
+```
+
+Example 2 (shell):
+```shell
+kubectl config set-context --current --namespace=timescale
+```
+
+Example 3 (yaml):
+```yaml
+kubectl apply -f - <\bin`.
+
+1. **Install TimescaleDB**
+
+1. Unzip the [TimescaleDB installer][supported-platforms] to ``, that is, your selected directory.
+
+Best practice is to use the latest version.
+
+1. In `\timescaledb`, right-click `setup.exe`, then choose `Run as Administrator`.
+
+1. Complete the installation wizard.
+
+If you see an error like `could not load library "C:/Program Files/PostgreSQL/17/lib/timescaledb-2.17.2.dll": The specified module could not be found.`, use
+ [Dependencies][dependencies] to ensure that your system can find the compatible DLLs for this release of TimescaleDB.
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+Run the `timescaledb-tune` script included in the `timescaledb-tools` package with TimescaleDB. For more
+ information, see [configuration][config].
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+## Add the TimescaleDB extension to your database
+
+For improved performance, you enable TimescaleDB on each database on your self-hosted Postgres instance.
+This section shows you how to enable TimescaleDB for a new database in Postgres using `psql` from the command line.
+
+1. **Connect to a database on your Postgres instance**
+
+In Postgres, the default user and database are both `postgres`. To use a
+ different database, set `` to the name of that database:
+
+1. **Add TimescaleDB to the database**
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press q to exit the list of extensions.
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+## Supported platforms
+
+The latest TimescaleDB releases for Postgres are:
+
+[Postgres 17: TimescaleDB release](https://github.com/timescale/timescaledb/releases/download/2.21.2/timescaledb-postgresql-17-windows-amd64.zip)
+
+[Postgres 16: TimescaleDB release](https://github.com/timescale/timescaledb/releases/download/2.21.2/timescaledb-postgresql-16-windows-amd64.zip)
+
+[Postgres 15: TimescaleDB release](https://github.com/timescale/timescaledb/releases/download/2.21.2/timescaledb-postgresql-15-windows-amd64.zip)
+
+You can deploy TimescaleDB on the following systems:
+
+| Operation system | Version |
+|---------------------------------------------|------------|
+| Microsoft Windows | 10, 11 |
+| Microsoft Windows Server | 2019, 2020 |
+
+For release information, see the [GitHub releases page][gh-releases] and the [release notes][release-notes].
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-cloud-image/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo -u postgres psql
+```
+
+Example 2 (bash):
+```bash
+\password postgres
+```
+
+Example 3 (bash):
+```bash
+psql -d "postgres://:@:/"
+```
+
+Example 4 (sql):
+```sql
+CREATE EXTENSION IF NOT EXISTS timescaledb;
+```
+
+---
+
+## TimescaleDB API reference
+
+**URL:** llms-txt#timescaledb-api-reference
+
+**Contents:**
+- APIReference
+
+TimescaleDB provides many SQL functions and views to help you interact with and
+manage your data. See a full list below or search by keyword to find reference
+documentation for a specific API.
+
+Refer to the installation documentation for detailed setup instructions.
+
+===== PAGE: https://docs.tigerdata.com/api/rollup/ =====
+
+---
+
+## Upgrade TimescaleDB
+
+**URL:** llms-txt#upgrade-timescaledb
+
+A major upgrade is when you update from TimescaleDB `X.` to `Y.`.
+A minor upgrade is when you update from TimescaleDB `.x`, to TimescaleDB `.y`.
+You upgrade your self-hosted TimescaleDB installation in-place.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+This section shows you how to:
+
+* Upgrade self-hosted TimescaleDB to a new [minor version][upgrade-minor].
+* Upgrade self-hosted TimescaleDB to a new [major version][upgrade-major].
+* Upgrade self-hosted TimescaleDB running in a [Docker container][upgrade-docker] to a new minor version.
+* Upgrade [Postgres][upgrade-pg] to a new version.
+* Downgrade self-hosted TimescaleDB to the [previous minor version][downgrade].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/uninstall/ =====
+
+---
+
+## Ongoing physical backups with Docker & WAL-E
+
+**URL:** llms-txt#ongoing-physical-backups-with-docker-&-wal-e
+
+**Contents:**
+- Run the TimescaleDB container in Docker
+ - Running the TimescaleDB container in Docker
+- Perform the backup using the WAL-E sidecar
+ - Performing the backup using the WAL-E sidecar
+- Recovery
+ - Restoring database files from backup
+ - Relaunch the recovered database
+
+When you run TimescaleDB in a containerized environment, you can use
+[continuous archiving][pg archiving] with a [WAL-E][wale official] container.
+These containers are sometimes referred to as sidecars, because they run
+alongside the main container. A [WAL-E sidecar image][wale image]
+works with TimescaleDB as well as regular Postgres. In this section, you
+can set up archiving to your local filesystem with a main TimescaleDB
+container called `timescaledb`, and a WAL-E sidecar called `wale`. When you are
+ready to implement this in your production deployment, you can adapt the
+instructions here to do archiving against cloud providers such as AWS S3, and
+run it in an orchestration framework such as Kubernetes.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+## Run the TimescaleDB container in Docker
+
+To make TimescaleDB use the WAL-E sidecar for archiving, the two containers need
+to share a network. To do this, you need to create a Docker network and then
+launch TimescaleDB with archiving turned on, using the newly created network.
+When you launch TimescaleDB, you need to explicitly set the location of the
+write-ahead log (`POSTGRES_INITDB_WALDIR`) and data directory (`PGDATA`) so that
+you can share them with the WAL-E sidecar. Both must reside in a Docker volume,
+by default a volume is created for `/var/lib/postgresql/data`. When you have
+started TimescaleDB, you can log in and create tables and data.
+
+This section describes a feature that is deprecated. We strongly
+recommend that you do not use this feature in a production environment. If you
+need more information, [contact us](https://www.tigerdata.com/contact/).
+
+### Running the TimescaleDB container in Docker
+
+1. Create the docker container:
+
+1. Launch TimescaleDB, with archiving turned on:
+
+1. Run TimescaleDB within Docker:
+
+## Perform the backup using the WAL-E sidecar
+
+The [WAL-E Docker image][wale image] runs a web endpoint that accepts WAL-E
+commands across an HTTP API. This allows Postgres to communicate with the
+WAL-E sidecar over the internal network to trigger archiving. You can also use
+the container to invoke WAL-E directly. The Docker image accepts standard WAL-E
+environment variables to configure the archiving backend, so you can issue
+commands from services such as AWS S3. For information about configuring, see
+the official [WAL-E documentation][wale official].
+
+To enable the WAL-E docker image to perform archiving, it needs to use the same
+network and data volumes as the TimescaleDB container. It also needs to know the
+location of the write-ahead log and data directories. You can pass all this
+information to WAL-E when you start it. In this example, the WAL-E image listens
+for commands on the `timescaledb-net` internal network at port 80, and writes
+backups to `~/backups` on the Docker host.
+
+### Performing the backup using the WAL-E sidecar
+
+1. Start the WAL-E container with the required information about the container.
+ In this example, the container is called `timescaledb-wale`:
+
+1. Start the backup:
+
+Alternatively, you can start the backup using the sidecar's HTTP endpoint.
+ This requires exposing the sidecar's port 80 on the Docker host by mapping
+ it to an open port. In this example, it is mapped to port 8080:
+
+You should do base backups at regular intervals daily, to minimize
+the amount of WAL-E replay, and to make recoveries faster. To make new base
+backups, re-trigger a base backup as shown here, either manually or on a
+schedule. If you run TimescaleDB on Kubernetes, there is built-in support for
+scheduling cron jobs that can invoke base backups using the WAL-E container's
+HTTP API.
+
+To recover the database instance from the backup archive, create a new TimescaleDB
+container, and restore the database and configuration files from the base
+backup. Then you can relaunch the sidecar and the database.
+
+### Restoring database files from backup
+
+1. Create the docker container:
+
+1. Restore the database files from the base backup:
+
+1. Recreate the configuration files. These are backed up from the original
+ database instance:
+
+1. Create a `recovery.conf` file that tells Postgres how to recover:
+
+When you have recovered the data and the configuration files, and have created a
+recovery configuration file, you can relaunch the sidecar. You might need to
+remove the old one first. When you relaunch the sidecar, it replays the last WAL
+segments that might be missing from the base backup. The you can relaunch the
+database, and check that recovery was successful.
+
+### Relaunch the recovered database
+
+1. Relaunch the WAL-E sidecar:
+
+1. Relaunch the TimescaleDB docker container:
+
+1. Verify that the database started up and recovered successfully:
+
+Don't worry if you see some archive recovery errors in the log at this
+ stage. This happens because the recovery is not completely finalized until
+ no more files can be found in the archive. See the Postgres documentation
+ on [continuous archiving][pg archiving] for more information.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/uninstall/uninstall-timescaledb/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+docker network create timescaledb-net
+```
+
+Example 2 (bash):
+```bash
+docker run \
+ --name timescaledb \
+ --network timescaledb-net \
+ -e POSTGRES_PASSWORD=insecure \
+ -e POSTGRES_INITDB_WALDIR=/var/lib/postgresql/data/pg_wal \
+ -e PGDATA=/var/lib/postgresql/data/pg_data \
+ timescale/timescaledb:latest-pg10 postgres \
+ -cwal_level=archive \
+ -carchive_mode=on \
+ -carchive_command="/usr/bin/wget wale/wal-push/%f -O -" \
+ -carchive_timeout=600 \
+ -ccheckpoint_timeout=700 \
+ -cmax_wal_senders=1
+```
+
+Example 3 (bash):
+```bash
+docker exec -it timescaledb psql -U postgres
+```
+
+Example 4 (bash):
+```bash
+docker run \
+ --name wale \
+ --network timescaledb-net \
+ --volumes-from timescaledb \
+ -v ~/backups:/backups \
+ -e WALE_LOG_DESTINATION=stderr \
+ -e PGWAL=/var/lib/postgresql/data/pg_wal \
+ -e PGDATA=/var/lib/postgresql/data/pg_data \
+ -e PGHOST=timescaledb \
+ -e PGPASSWORD=insecure \
+ -e PGUSER=postgres \
+ -e WALE_FILE_PREFIX=file://localhost/backups \
+ timescale/timescaledb-wale:latest
+```
+
+---
+
+## Install TimescaleDB on Docker
+
+**URL:** llms-txt#install-timescaledb-on-docker
+
+**Contents:**
+ - Prerequisites
+- Install and configure TimescaleDB on Postgres
+- More Docker options
+- View logs in Docker
+- More Docker options
+- View logs in Docker
+- Where to next
+
+TimescaleDB is a [Postgres extension](https://www.postgresql.org/docs/current/external-extensions.html) for
+time series and demanding workloads that ingest and query high volumes of data. You can install a TimescaleDB
+instance on any local system from a pre-built Docker container.
+
+This section shows you how to
+[Install and configure TimescaleDB on Postgres](#install-and-configure-timescaledb-on-postgresql).
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+To run, and connect to a Postgres installation on Docker, you need to install:
+
+- [Docker][docker-install]
+- [psql][install-psql]
+
+## Install and configure TimescaleDB on Postgres
+
+This section shows you how to install the latest version of Postgres and
+TimescaleDB on a [supported platform](#supported-platforms) using containers supplied by Tiger Data.
+
+1. **Run the TimescaleDB Docker image**
+
+The [TimescaleDB HA](https://hub.docker.com/r/timescale/timescaledb-ha) Docker image offers the most complete
+ TimescaleDB experience. It uses [Ubuntu][ubuntu], includes
+ [TimescaleDB Toolkit](https://github.com/timescale/timescaledb-toolkit), and support for PostGIS and Patroni.
+
+To install the latest release based on Postgres 17:
+
+TimescaleDB is pre-created in the default Postgres database and is added by default to any new database you create in this image.
+
+1. **Run the container**
+
+Replace `` with the path to the folder you want to keep your data in the following command.
+
+If you are running multiple container instances, change the port each Docker instance runs on.
+
+On UNIX-based systems, Docker modifies Linux IP tables to bind the container. If your system uses Linux Uncomplicated Firewall (UFW), Docker may
+ [override your UFW port binding settings][override-binding]. To prevent this, add `DOCKER_OPTS="--iptables=false"` to `/etc/default/docker`.
+
+1. **Connect to a database on your Postgres instance**
+
+The default user and database are both `postgres`. You set the password in `POSTGRES_PASSWORD` in the previous step. The default command to connect to Postgres is:
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press `q` to exit the list of extensions.
+
+## More Docker options
+
+If you want to access the container from the host but avoid exposing it to the
+outside world, you can bind to `127.0.0.1` instead of the public interface, using this command:
+
+If you don't want to install `psql` and other Postgres client tools locally,
+or if you are using a Microsoft Windows host system, you can connect using the
+version of `psql` that is bundled within the container with this command:
+
+When you install TimescaleDB using a Docker container, the Postgres settings
+are inherited from the container. In most cases, you do not need to adjust them.
+However, if you need to change a setting, you can add `-c setting=value` to your
+Docker `run` command. For more information, see the
+[Docker documentation][docker-postgres].
+
+The link provided in these instructions is for the latest version of TimescaleDB
+on Postgres 17. To find other Docker tags you can use, see the [Dockerhub repository][dockerhub].
+
+## View logs in Docker
+
+If you have TimescaleDB installed in a Docker container, you can view your logs
+using Docker, instead of looking in `/var/lib/logs` or `/var/logs`. For more
+information, see the [Docker documentation on logs][docker-logs].
+
+1. **Run the TimescaleDB Docker image**
+
+The light-weight [TimescaleDB](https://hub.docker.com/r/timescale/timescaledb) Docker image uses [Alpine][alpine] and does not contain [TimescaleDB Toolkit](https://github.com/timescale/timescaledb-toolkit) or support for PostGIS and Patroni.
+
+To install the latest release based on Postgres 17:
+
+TimescaleDB is pre-created in the default Postgres database and added by default to any new database you create in this image.
+
+1. **Run the container**
+
+If you are running multiple container instances, change the port each Docker instance runs on.
+
+On UNIX-based systems, Docker modifies Linux IP tables to bind the container. If your system uses Linux Uncomplicated Firewall (UFW), Docker may [override your UFW port binding settings][override-binding]. To prevent this, add `DOCKER_OPTS="--iptables=false"` to `/etc/default/docker`.
+
+1. **Connect to a database on your Postgres instance**
+
+The default user and database are both `postgres`. You set the password in `POSTGRES_PASSWORD` in the previous step. The default command to connect to Postgres in this image is:
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press `q` to exit the list of extensions.
+
+## More Docker options
+
+If you want to access the container from the host but avoid exposing it to the
+outside world, you can bind to `127.0.0.1` instead of the public interface, using this command:
+
+If you don't want to install `psql` and other Postgres client tools locally,
+or if you are using a Microsoft Windows host system, you can connect using the
+version of `psql` that is bundled within the container with this command:
+
+Existing containers can be stopped using `docker stop` and started again with
+`docker start` while retaining their volumes and data. When you create a new
+container using the `docker run` command, by default you also create a new data
+volume. When you remove a Docker container with `docker rm`, the data volume
+persists on disk until you explicitly delete it. You can use the `docker volume
+ls` command to list existing docker volumes. If you want to store the data from
+your Docker container in a host directory, or you want to run the Docker image
+on top of an existing data directory, you can specify the directory to mount a
+data volume using the `-v` flag:
+
+When you install TimescaleDB using a Docker container, the Postgres settings
+are inherited from the container. In most cases, you do not need to adjust them.
+However, if you need to change a setting, you can add `-c setting=value` to your
+Docker `run` command. For more information, see the
+[Docker documentation][docker-postgres].
+
+The link provided in these instructions is for the latest version of TimescaleDB
+on Postgres 16. To find other Docker tags you can use, see the [Dockerhub repository][dockerhub].
+
+## View logs in Docker
+
+If you have TimescaleDB installed in a Docker container, you can view your logs
+using Docker, instead of looking in `/var/log`. For more
+information, see the [Docker documentation on logs][docker-logs].
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/replication-and-ha/configure-replication/ =====
+
+**Examples:**
+
+Example 1 (unknown):
+```unknown
+docker pull timescale/timescaledb-ha:pg17
+```
+
+Example 2 (unknown):
+```unknown
+docker run -d --name timescaledb -p 5432:5432 -v :/pgdata -e PGDATA=/pgdata -e POSTGRES_PASSWORD=password timescale/timescaledb-ha:pg17
+```
+
+Example 3 (bash):
+```bash
+psql -d "postgres://postgres:password@localhost/postgres"
+```
+
+Example 4 (sql):
+```sql
+\dx
+```
+
+---
+
+## Physical backups
+
+**URL:** llms-txt#physical-backups
+
+For full instance physical backups (which are especially useful for starting up
+new [replicas][replication-tutorial]), [`pg_basebackup`][postgres-pg_basebackup]
+works with all TimescaleDB installation types. You can also use any of several
+external backup and restore managers such as [`pg_backrest`][pg-backrest], or [`barman`][pg-barman]. For ongoing physical backups, you can use
+[`wal-e`][wale], although this method is now deprecated. These tools all allow
+you to take online, physical backups of your entire instance, and many offer
+incremental backups and other automation options.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/backup-and-restore/docker-and-wale/ =====
+
+---
+
+## Can't access file "timescaledb" after installation
+
+**URL:** llms-txt#can't-access-file-"timescaledb"-after-installation
+
+
+
+If your Postgres logs have this error preventing it from starting up,
+you should double check that the TimescaleDB files have been installed
+to the correct location. Our installation methods use `pg_config` to
+get Postgres's location. However if you have multiple versions of
+Postgres installed on the same machine, the location `pg_config`
+points to may not be for the version you expect. To check which
+version TimescaleDB used:
+
+If that is the correct version, double check that the installation path is
+the one you'd expect. For example, for Postgres 11.0 installed via
+Homebrew on macOS it should be `/usr/local/Cellar/postgresql/11.0/bin`:
+
+If either of those steps is not the version you are expecting, you need
+to either (a) uninstall the incorrect version of Postgres if you can or
+(b) update your `PATH` environmental variable to have the correct
+path of `pg_config` listed first, that is, by prepending the full path:
+
+Then, reinstall TimescaleDB and it should find the correct installation
+path.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/self-hosted/update-error-third-party-tool/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+$ pg_config --version
+PostgreSQL 12.3
+```
+
+Example 2 (bash):
+```bash
+$ pg_config --bindir
+/usr/local/Cellar/postgresql/11.0/bin
+```
+
+Example 3 (bash):
+```bash
+export PATH = /usr/local/Cellar/postgresql/11.0/bin:$PATH
+```
+
+---
+
+## Install TimescaleDB on macOS
+
+**URL:** llms-txt#install-timescaledb-on-macos
+
+**Contents:**
+ - Prerequisites
+- Install and configure TimescaleDB on Postgres
+- Add the TimescaleDB extension to your database
+- Supported platforms
+- Where to next
+
+TimescaleDB is a [Postgres extension](https://www.postgresql.org/docs/current/external-extensions.html) for
+time series and demanding workloads that ingest and query high volumes of data. You can host TimescaleDB on
+macOS device.
+
+This section shows you how to:
+
+* [Install and configure TimescaleDB on Postgres](#install-and-configure-timescaledb-on-postgresql) - set up
+ a self-hosted Postgres instance to efficiently run TimescaleDB.
+* [Add the TimescaleDB extension to your database](#add-the-timescaledb-extension-to-your-database) - enable TimescaleDB
+ features and performance improvements on a database.
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+To install TimescaleDB on your MacOS device, you need:
+
+* [Postgres][install-postgresql]: for the latest functionality, install Postgres v16
+
+If you have already installed Postgres using a method other than Homebrew or MacPorts, you may encounter errors
+following these install instructions. Best practice is to full remove any existing Postgres
+installations before you begin.
+
+To keep your current Postgres installation, [Install from source][install-from-source].
+
+## Install and configure TimescaleDB on Postgres
+
+This section shows you how to install the latest version of Postgres and
+TimescaleDB on a [supported platform](#supported-platforms) using the packages supplied by Tiger Data.
+
+1. Install Homebrew, if you don't already have it:
+
+For more information about Homebrew, including installation instructions,
+ see the [Homebrew documentation][homebrew].
+1. At the command prompt, add the TimescaleDB Homebrew tap:
+
+1. Install TimescaleDB and psql:
+
+1. Update your path to include psql.
+
+On Intel chips, the symbolic link is added to `/usr/local/bin`. On Apple
+ Silicon, the symbolic link is added to `/opt/homebrew/bin`.
+
+1. Run the `timescaledb-tune` script to configure your database:
+
+1. Change to the directory where the setup script is located. It is typically,
+ located at `/opt/homebrew/Cellar/timescaledb//bin/`, where
+ `` is the version of `timescaledb` that you installed:
+
+1. Run the setup script to complete installation.
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. Install MacPorts by downloading and running the package installer.
+
+For more information about MacPorts, including installation instructions,
+ see the [MacPorts documentation][macports].
+1. Install TimescaleDB and psql:
+
+To view the files installed, run:
+
+MacPorts does not install the `timescaledb-tools` package or run the `timescaledb-tune`
+ script. For more information about tuning your database, see the [TimescaleDB tuning tool][timescale-tuner].
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+## Add the TimescaleDB extension to your database
+
+For improved performance, you enable TimescaleDB on each database on your self-hosted Postgres instance.
+This section shows you how to enable TimescaleDB for a new database in Postgres using `psql` from the command line.
+
+1. **Connect to a database on your Postgres instance**
+
+In Postgres, the default user and database are both `postgres`. To use a
+ different database, set `` to the name of that database:
+
+1. **Add TimescaleDB to the database**
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press q to exit the list of extensions.
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+## Supported platforms
+
+You can deploy TimescaleDB on the following systems:
+
+| Operation system | Version |
+|-------------------------------|----------------------------------|
+| macOS | From 10.15 Catalina to 14 Sonoma |
+
+For the latest functionality, install MacOS 14 Sonoma.
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-kubernetes/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
+```
+
+Example 2 (bash):
+```bash
+brew tap timescale/tap
+```
+
+Example 3 (bash):
+```bash
+brew install timescaledb libpq
+```
+
+Example 4 (bash):
+```bash
+brew link --force libpq
+```
+
+---
+
+## Install TimescaleDB from source
+
+**URL:** llms-txt#install-timescaledb-from-source
+
+**Contents:**
+ - Prerequisites
+- Install and configure TimescaleDB on Postgres
+- Add the TimescaleDB extension to your database
+- Where to next
+
+TimescaleDB is a [Postgres extension](https://www.postgresql.org/docs/current/external-extensions.html) for
+time series and demanding workloads that ingest and query high volumes of data. You can install a TimescaleDB
+instance on any local system, from source.
+
+This section shows you how to:
+
+* [Install and configure TimescaleDB on Postgres](#install-and-configure-timescaledb-on-postgres) - set up
+ a self-hosted Postgres instance to efficiently run TimescaleDB1.
+* [Add the TimescaleDB extension to your database](#add-the-timescaledb-extension-to-your-database) - enable TimescaleDB features and
+ performance improvements on a database.
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+To install TimescaleDB from source, you need the following on your developer environment:
+
+Install a [supported version of Postgres][compatibility-matrix] using the [Postgres installation instructions][postgres-download].
+
+We recommend not using TimescaleDB with Postgres 17.1, 16.5, 15.9, 14.14, 13.17, 12.21.
+ These minor versions [introduced a breaking binary interface change][postgres-breaking-change] that,
+ once identified, was reverted in subsequent minor Postgres versions 17.2, 16.6, 15.10, 14.15, 13.18, and 12.22.
+ When you build from source, best practice is to build with Postgres 17.2, 16.6, etc and higher.
+ Users of [Tiger Cloud](https://console.cloud.timescale.com/) and Platform packages built and
+ distributed by Tiger Data are unaffected.
+
+* [CMake version 3.11 or later][cmake-download]
+ * C language compiler for your operating system, such as `gcc` or `clang`.
+
+If you are using a Microsoft Windows system, you can install Visual Studio 2015
+ or later instead of CMake and a C language compiler. Ensure you install the
+ Visual Studio components for CMake and Git when you run the installer.
+
+## Install and configure TimescaleDB on Postgres
+
+This section shows you how to install the latest version of Postgres and
+TimescaleDB on a supported platform using source supplied by Tiger Data.
+
+1. **Install the latest Postgres source**
+
+1. At the command prompt, clone the TimescaleDB GitHub repository:
+
+1. Change into the cloned directory:
+
+1. Checkout the latest release. You can find the latest release tag on
+ our [Releases page][gh-releases]:
+
+This command produces an error that you are now in `detached head` state. It
+ is expected behavior, and it occurs because you have checked out a tag, and
+ not a branch. Continue with the steps in this procedure as normal.
+
+1. **Build the source**
+
+1. Bootstrap the build system:
+
+
+
+For installation on Microsoft Windows, you might need to add the `pg_config`
+ and `cmake` file locations to your path. In the Windows Search tool, search
+ for `system environment variables`. The path for `pg_config` should be
+ `C:\Program Files\PostgreSQL\\bin`. The path for `cmake` is within
+ the Visual Studio directory.
+
+1. Build the extension:
+
+
+
+1. **Install TimescaleDB**
+
+
+
+1. **Configure Postgres**
+
+If you have more than one version of Postgres installed, TimescaleDB can only
+ be associated with one of them. The TimescaleDB build scripts use `pg_config` to
+ find out where Postgres stores its extension files, so you can use `pg_config`
+ to find out which Postgres installation TimescaleDB is using.
+
+1. Locate the `postgresql.conf` configuration file:
+
+1. Open the `postgresql.conf` file and update `shared_preload_libraries` to:
+
+If you use other preloaded libraries, make sure they are comma separated.
+
+1. Tune your Postgres instance for TimescaleDB
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. Restart the Postgres instance:
+
+
+
+1. **Set the user password**
+
+1. Log in to Postgres as `postgres`
+
+You are in the psql shell.
+
+1. Set the password for `postgres`
+
+When you have set the password, type `\q` to exit psql.
+
+## Add the TimescaleDB extension to your database
+
+For improved performance, you enable TimescaleDB on each database on your self-hosted Postgres instance.
+This section shows you how to enable TimescaleDB for a new database in Postgres using `psql` from the command line.
+
+1. **Connect to a database on your Postgres instance**
+
+In Postgres, the default user and database are both `postgres`. To use a
+ different database, set `` to the name of that database:
+
+1. **Add TimescaleDB to the database**
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press q to exit the list of extensions.
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-linux/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+git clone https://github.com/timescale/timescaledb
+```
+
+Example 2 (bash):
+```bash
+cd timescaledb
+```
+
+Example 3 (bash):
+```bash
+git checkout 2.17.2
+```
+
+Example 4 (bash):
+```bash
+./bootstrap
+```
+
+---
+
+## Integrate Tableau and Tiger
+
+**URL:** llms-txt#integrate-tableau-and-tiger
+
+**Contents:**
+- Prerequisites
+- Add your Tiger Cloud service as a virtual connection
+
+[Tableau][tableau] is a popular analytics platform that helps you gain greater intelligence about your business. You can use it to visualize
+data stored in Tiger Cloud.
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Tableau Server][tableau-server] or sign up for [Tableau Cloud][tableau-cloud].
+
+## Add your Tiger Cloud service as a virtual connection
+
+To connect the data in your Tiger Cloud service to Tableau:
+
+1. **Log in to Tableau**
+ - Tableau Cloud: [sign in][tableau-login], then click `Explore` and select a project.
+ - Tableau Desktop: sign in, then open a workbook.
+
+1. **Configure Tableau to connect to your Tiger Cloud service**
+ 1. Add a new data source:
+ - Tableau Cloud: click `New` > `Virtual Connection`.
+ - Tableau Desktop: click `Data` > `New Data Source`.
+ 1. Search for and select `PostgreSQL`.
+
+For Tableau Desktop download the driver and restart Tableau.
+ 1. Configure the connection:
+ - `Server`, `Port`, `Database`, `Username`, `Password`: configure using your [connection details][connection-info].
+ - `Require SSL`: tick the checkbox.
+
+1. **Click `Sign In` and connect Tableau to your service**
+
+You have successfully integrated Tableau with Tiger Cloud.
+
+===== PAGE: https://docs.tigerdata.com/integrations/apache-kafka/ =====
+
+---
+
+## High availability with multi-node
+
+**URL:** llms-txt#high-availability-with-multi-node
+
+**Contents:**
+- Native replication
+ - Automation
+ - Configuring native replication
+ - Node failures
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+A multi-node installation of TimescaleDB can be made highly available
+by setting up one or more standbys for each node in the cluster, or by
+natively replicating data at the chunk level.
+
+Using standby nodes relies on streaming replication and you set it up
+in a similar way to [configuring single-node HA][single-ha], although the
+configuration needs to be applied to each node independently.
+
+To replicate data at the chunk level, you can use the built-in
+capabilities of multi-node TimescaleDB to avoid having to
+replicate entire data nodes. The access node still relies on a
+streaming replication standby, but the data nodes need no additional
+configuration. Instead, the existing pool of data nodes share
+responsibility to host chunk replicas and handle node failures.
+
+There are advantages and disadvantages to each approach.
+Setting up standbys for each node in the cluster ensures that
+standbys are identical at the instance level, and this is a tried
+and tested method to provide high availability. However, it also
+requires more setting up and maintenance for the mirror cluster.
+
+Native replication typically requires less resources, nodes, and
+configuration, and takes advantage of built-in capabilities, such as
+adding and removing data nodes, and different replication factors on
+each distributed hypertable. However, only chunks are replicated on
+the data nodes.
+
+The rest of this section discusses native replication. To set up
+standbys for each node, follow the instructions for [single node
+HA][single-ha].
+
+## Native replication
+
+Native replication is a set of capabilities and APIs that allow you to
+build a highly available multi-node TimescaleDB installation. At the
+core of native replication is the ability to write copies of a chunk
+to multiple data nodes in order to have alternative _chunk replicas_
+in case of a data node failure. If one data node fails, its chunks
+should be available on at least one other data node. If a data node is
+permanently lost, a new data node can be added to the cluster, and
+lost chunk replicas can be re-replicated from other data nodes to
+reach the number of desired chunk replicas.
+
+Native replication in TimescaleDB is under development and
+currently lacks functionality for a complete high-availability
+solution. Some functionality described in this section is still
+experimental. For production environments, we recommend setting up
+standbys for each node in a multi-node cluster.
+
+Similar to how high-availability configurations for single-node
+Postgres uses a system like Patroni for automatically handling
+fail-over, native replication requires an external entity to
+orchestrate fail-over, chunk re-replication, and data node
+management. This orchestration is _not_ provided by default in
+TimescaleDB and therefore needs to be implemented separately. The
+sections below describe how to enable native replication and the steps
+involved to implement high availability in case of node failures.
+
+### Configuring native replication
+
+The first step to enable native replication is to configure a standby
+for the access node. This process is identical to setting up a [single
+node standby][single-ha].
+
+The next step is to enable native replication on a distributed
+hypertable. Native replication is governed by the
+`replication_factor`, which determines how many data nodes a chunk is
+replicated to. This setting is configured separately for each
+hypertable, which means the same database can have some distributed
+hypertables that are replicated and others that are not.
+
+By default, the replication factor is set to `1`, so there is no
+native replication. You can increase this number when you create the
+hypertable. For example, to replicate the data across a total of three
+data nodes:
+
+Alternatively, you can use the
+[`set_replication_factor`][set_replication_factor] call to change the
+replication factor on an existing distributed hypertable. Note,
+however, that only new chunks are replicated according to the
+updated replication factor. Existing chunks need to be re-replicated
+by copying those chunks to new data nodes (see the [node
+failures section](#node-failures) below).
+
+When native replication is enabled, the replication happens whenever
+you write data to the table. On every `INSERT` and `COPY` call, each
+row of the data is written to multiple data nodes. This means that you
+don't need to do any extra steps to have newly ingested data
+replicated. When you query replicated data, the query planner only
+includes one replica of each chunk in the query plan.
+
+When a data node fails, inserts that attempt to write to the failed
+node result in an error. This is to preserve data consistency in
+case the data node becomes available again. You can use the
+[`alter_data_node`][alter_data_node] call to mark a failed data node
+as unavailable by running this query:
+
+Setting `available => false` means that the data node is no longer
+used for reads and writes queries.
+
+To fail over reads, the [`alter_data_node`][alter_data_node] call finds
+all the chunks for which the unavailable data node is the primary query
+target and fails over to a chunk replica on another data node.
+However, if some chunks do not have a replica to fail over to, a warning
+is raised. Reads continue to fail for chunks that do not have a chunk
+replica on any other data nodes.
+
+To fail over writes, any activity that intends to write to the failed
+node marks the involved chunk as stale for the specific failed
+node by changing the metadata on the access node. This is only done
+for natively replicated chunks. This allows you to continue to write
+to other chunk replicas on other data nodes while the failed node has
+been marked as unavailable. Writes continue to fail for chunks that do
+not have a chunk replica on any other data nodes. Also note that chunks
+on the failed node which do not get written into are not affected.
+
+When you mark a chunk as stale, the chunk becomes under-replicated.
+When the failed data node becomes available then such chunks can be
+re-balanced using the [`copy_chunk`][copy_chunk] API.
+
+If waiting for the data node to come back is not an option, either because
+it takes too long or the node is permanently failed, one can delete it instead.
+To be able to delete a data node, all of its chunks must have at least one
+replica on other data nodes. For example:
+
+Use the `force` option when you delete the data node if the deletion
+means that the cluster no longer achieves the desired replication
+factor. This would be the normal case unless the data node has no
+chunks or the distributed hypertable has more chunk replicas than the
+configured replication factor.
+
+You cannot force the deletion of a data node if it would mean that a multi-node
+cluster permanently loses data.
+
+When you have successfully removed a failed data node, or marked a
+failed data node unavailable, some data chunks might lack replicas but
+queries and inserts work as normal again. However, the cluster stays in
+a vulnerable state until all chunks are fully replicated.
+
+When you have restored a failed data node or marked it available again, you can
+see the chunks that need to be replicated with this query:
+
+
+
+The output from this query looks like this:
+
+With the information from the chunk replication status view, an
+under-replicated chunk can be copied to a new node to ensure the chunk
+has the sufficient number of replicas. For example:
+
+
+
+>
+When you restore chunk replication, the operation uses more than one transaction. This means that it cannot be automatically rolled back. If you cancel the operation before it is completed, an operation ID for the copy is logged. You can use this operation ID to clean up any state left by the cancelled operation. For example:
+
+
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/multinode-timescaledb/multinode-setup/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT create_distributed_hypertable('conditions', 'time', 'location',
+ replication_factor => 3);
+```
+
+Example 2 (sql):
+```sql
+SELECT alter_data_node('data_node_2', available => false);
+```
+
+Example 3 (sql):
+```sql
+SELECT delete_data_node('data_node_2', force => true);
+WARNING: distributed hypertable "conditions" is under-replicated
+```
+
+Example 4 (sql):
+```sql
+SELECT chunk_schema, chunk_name, replica_nodes, non_replica_nodes
+FROM timescaledb_experimental.chunk_replication_status
+WHERE hypertable_name = 'conditions' AND num_replicas < desired_num_replicas;
+```
+
+---
+
+## Upload a file into your service using the terminal
+
+**URL:** llms-txt#upload-a-file-into-your-service-using-the-terminal
+
+**Contents:**
+- Prerequisites
+- Import data into your service
+- Prerequisites
+- Import data into your service
+- Prerequisites
+- Import data into your service
+
+This page shows you how to upload CSV, MySQL, and Parquet files from a source machine into your service using the terminal.
+
+The CSV file format is widely used for data migration. This page shows you how to import data into your Tiger Cloud service from a CSV file using the terminal.
+
+To follow the procedure on this page you need to:
+
+* Create a [target Tiger Cloud service][create-service].
+
+This procedure also works for [self-hosted TimescaleDB][enable-timescaledb].
+
+- Install [Go](https://go.dev/doc/install) v1.13 or later
+
+- Install [timescaledb-parallel-copy][install-parallel-copy]
+
+[timescaledb-parallel-copy][parallel importer] improves performance for large datasets by parallelizing the import
+ process. It also preserves row order and uses a round-robin approach to optimize memory management and disk operations.
+
+To verify your installation, run `timescaledb-parallel-copy --version`.
+
+- Ensure that the time column in the CSV file uses the `TIMESTAMPZ` data type.
+
+For faster data transfer, best practice is that your target service and the system
+running the data import are in the same region.
+
+## Import data into your service
+
+To import data from a CSV file:
+
+1. **Set up your service connection string**
+
+This variable holds the connection information for the target Tiger Cloud service.
+
+In the terminal on the source machine, set the following:
+
+See where to [find your connection details][connection-info].
+
+1. **Create a [hypertable][hypertable-docs] to hold your data**
+
+Create a hypertable with a schema that is compatible with the data in your parquet file. For example, if your parquet file contains the columns `ts`, `location`, and `temperature` with types`TIMESTAMP`, `STRING`, and `DOUBLE`:
+
+- TimescaleDB v2.20 and above:
+
+sql
+ psql target -c "CREATE TABLE ( \
+ ts TIMESTAMPTZ NOT NULL, \
+ location TEXT NOT NULL, \
+ temperature DOUBLE PRECISION NULL \
+ );"
+ sql
+ psql target -c "SELECT create_hypertable('', by_range(''))"
+ bash
+ timescaledb-parallel-copy \
+ --connection target \
+ --table \
+ --file .csv \
+ --workers \
+ --reporting-period 30s
+ bash
+ psql target
+ \c
+ \COPY FROM .csv CSV"
+ bash
+export TARGET=postgres://tsdbadmin:@:/tsdb?sslmode=require
+bash
+ SOURCE="mysql://:@:/?sslmode=require"
+ docker
+ docker run -it ghcr.io/dimitri/pgloader:latest pgloader
+ --no-ssl-cert-verification \
+ "source" \
+ "target"
+ bash
+export TARGET=postgres://tsdbadmin:@:/tsdb?sslmode=require
+sql
+ psql target -c "CREATE TABLE ( \
+ ts TIMESTAMPTZ NOT NULL, \
+ location TEXT NOT NULL, \
+ temperature DOUBLE PRECISION NULL \
+ ) WITH (timescaledb.hypertable, timescaledb.partition_column = 'ts');"
+
+- TimescaleDB v2.19.3 and below:
+
+1. Create a new regular table:
+
+1. Convert the empty table to a hypertable:
+
+In the following command, replace `` with the name of the table you just created, and `` with the partitioning column in ``.
+
+1. **Set up a DuckDB connection to your service**
+
+1. In a terminal on the source machine with your Parquet files, start a new DuckDB interactive session:
+
+1. Connect to your service in your DuckDB session:
+
+`target` is the connection string you used to connect to your service using psql.
+
+1. **Import data from Parquet to your service**
+
+1. In DuckDB, upload the table data to your service
+
+ Where:
+
+- ``: the hypertable you created to import data to
+ - ``: the Parquet file to import data from
+
+1. Exit the DuckDB session:
+
+1. **Verify the data was imported correctly into your service**
+
+In your `psql` session, view the data in ``:
+
+And that is it, you have imported your data from a Parquet file to your Tiger Cloud service.
+
+===== PAGE: https://docs.tigerdata.com/migrate/pg-dump-and-restore/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+export TARGET=postgres://tsdbadmin:@:/tsdb?sslmode=require
+```
+
+Example 2 (sql):
+```sql
+psql target -c "CREATE TABLE ( \
+ ts TIMESTAMPTZ NOT NULL, \
+ location TEXT NOT NULL, \
+ temperature DOUBLE PRECISION NULL \
+ ) WITH (timescaledb.hypertable, timescaledb.partition_column = 'ts');"
+
+ - TimescaleDB v2.19.3 and below:
+
+ 1. Create a new regular table:
+```
+
+Example 3 (unknown):
+```unknown
+1. Convert the empty table to a hypertable:
+
+ In the following command, replace `` with the name of the table you just created, and `` with the partitioning column in ``.
+```
+
+Example 4 (unknown):
+```unknown
+1. **Import your data**
+
+ In the folder containing your CSV files, either:
+
+ - Use [timescaledb-parallel-copy][install-parallel-copy]:
+```
+
+---
+
+## Distributed hypertables ( Sunsetted v2.14.x )
+
+**URL:** llms-txt#distributed-hypertables-(-sunsetted-v2.14.x-)
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+Distributed hypertables are an extension of regular hypertables, available when
+using a [multi-node installation][getting-started-multi-node] of TimescaleDB.
+Distributed hypertables provide the ability to store data chunks across multiple
+data nodes for better scale-out performance.
+
+Most management APIs used with regular hypertable chunks also work with distributed
+hypertables as documented in this section. There are a number of APIs for
+specifically dealing with data nodes and a special API for executing SQL commands
+on data nodes.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/ =====
+
+---
+
+## TimescaleDB configuration and tuning
+
+**URL:** llms-txt#timescaledb-configuration-and-tuning
+
+**Contents:**
+- Query Planning and Execution
+ - `timescaledb.enable_chunkwise_aggregation (bool)`
+ - `timescaledb.vectorized_aggregation (bool)`
+ - `timescaledb.enable_merge_on_cagg_refresh (bool)`
+- Policies
+ - `timescaledb.max_background_workers (int)`
+- Tiger Cloud service tuning
+ - `timescaledb.disable_load (bool)`
+- Administration
+ - `timescaledb.restoring (bool)`
+
+Just as you can tune settings in Postgres, TimescaleDB provides a number of configuration
+settings that may be useful to your specific installation and performance needs. These can
+also be set within the `postgresql.conf` file or as command-line parameters
+when starting Postgres.
+
+## Query Planning and Execution
+
+### `timescaledb.enable_chunkwise_aggregation (bool)`
+If enabled, aggregations are converted into partial aggregations during query
+planning. The first part of the aggregation is executed on a per-chunk basis.
+Then, these partial results are combined and finalized. Splitting aggregations
+decreases the size of the created hash tables and increases data locality, which
+speeds up queries.
+
+### `timescaledb.vectorized_aggregation (bool)`
+Enables or disables the vectorized optimizations in the query executor. For
+example, the `sum()` aggregation function on compressed chunks can be optimized
+in this way.
+
+### `timescaledb.enable_merge_on_cagg_refresh (bool)`
+
+Set to `ON` to dramatically decrease the amount of data written on a continuous aggregate
+in the presence of a small number of changes, reduce the i/o cost of refreshing a
+[continuous aggregate][continuous-aggregates], and generate fewer Write-Ahead Logs (WAL). Only works for continuous aggregates that don't have compression enabled.
+
+Please refer to the [Grand Unified Configuration (GUC) parameters][gucs] for a complete list.
+
+### `timescaledb.max_background_workers (int)`
+
+Max background worker processes allocated to TimescaleDB. Set to at least 1 +
+the number of databases loaded with the TimescaleDB extension in a Postgres instance. Default value is 16.
+
+## Tiger Cloud service tuning
+
+### `timescaledb.disable_load (bool)`
+Disable the loading of the actual extension
+
+### `timescaledb.restoring (bool)`
+
+Set TimescaleDB in restoring mode. It is disabled by default.
+
+### `timescaledb.license (string)`
+
+Change access to features based on the TimescaleDB license in use. For example,
+setting `timescaledb.license` to `apache` limits TimescaleDB to features that
+are implemented under the Apache 2 license. The default value is `timescale`,
+which allows access to all features.
+
+### `timescaledb.telemetry_level (enum)`
+
+Telemetry settings level. Level used to determine which telemetry to
+send. Can be set to `off` or `basic`. Defaults to `basic`.
+
+### `timescaledb.last_tuned (string)`
+
+Records last time `timescaledb-tune` ran.
+
+### `timescaledb.last_tuned_version (string)`
+
+Version of `timescaledb-tune` used to tune when it runs.
+
+===== PAGE: https://docs.tigerdata.com/api/configuration/gucs/ =====
+
+---
+
+## Additional tooling
+
+**URL:** llms-txt#additional-tooling
+
+Get the most from TimescaleDB with open source tools that help you perform
+common tasks.
+
+* Automatically configure your TimescaleDB instance with
+ [`timescaledb-tune`][tstune]
+* Install [TimescaleDB Toolkit][tstoolkit] to access more hyperfunctions and
+ function pipelines
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/upgrades/ =====
+
+---
+
+## Migrate your Postgres database to self-hosted TimescaleDB
+
+**URL:** llms-txt#migrate-your-postgres-database-to-self-hosted-timescaledb
+
+**Contents:**
+- Choose a migration method
+- Migrate an active database
+
+You can migrate your existing Postgres database to self-hosted TimescaleDB.
+
+There are several methods for migrating your data:
+
+* If the database you want to migrate is smaller than 100 GB,
+ [migrate your entire database at once][migrate-entire]:
+ This method directly transfers all data and schemas, including
+ Timescale-specific features. Your hypertables, continuous aggregates, and
+ policies are automatically available in the new self-hosted TimescaleDB instance.
+* For databases larger than 100GB,
+ [migrate your schema and data separately][migrate-separately]: With this
+ method, you migrate your tables one by one for easier failure recovery. If
+ migration fails mid-way, you can restart from the failure point rather than
+ from the beginning. However, Timescale-specific features won't be
+ automatically migrated. Follow the instructions to restore your hypertables,
+ continuous aggregates, and policies.
+* If you need to move data from Postgres tables into hypertables within an
+ existing self-hosted TimescaleDB instance,
+ [migrate within the same database][migrate-same-db]: This method assumes that
+ you have TimescaleDB set up in the same database instance as your existing table.
+* If you have data in an InfluxDB database,
+ [migrate using Outflux][outflux]:
+ Outflux pipes exported data directly to your self-hosted TimescaleDB instance, and manages schema
+ discovery, validation, and creation. Outflux works with earlier versions of
+ InfluxDB. It does not work with InfluxDB version 2 and later.
+
+## Choose a migration method
+
+Which method you choose depends on your database size, network upload and
+download speeds, existing continuous aggregates, and tolerance for failure
+recovery.
+
+If you are migrating from an Amazon RDS service, Amazon charges for the amount
+of data transferred out of the service. You could be charged by Amazon for all
+data egressed, even if the migration fails.
+
+If your database is smaller than 100 GB, choose to migrate your entire
+database at once. You can also migrate larger databases using this method, but
+the copying process must keep running, potentially over days or weeks. If the
+copy is interrupted, the process needs to be restarted. If you think an
+interruption in the copy is possible, choose to migrate your schema and data
+separately instead.
+
+Migrating your schema and data separately does not retain continuous aggregates
+calculated using already-deleted data. For example, if you delete raw data after
+a month but retain downsampled data in a continuous aggregate for a year, the
+continuous aggregate loses any data older than a month upon migration. If you
+must keep continuous aggregates calculated using deleted data, migrate your
+entire database at once regardless of database size.
+
+If you aren't sure which method to use, try copying the entire database at once
+to estimate the time required. If the time estimate is very long, stop the
+migration and switch to the other method.
+
+## Migrate an active database
+
+If your database is actively ingesting data, take precautions to ensure that
+your self-hosted TimescaleDB instance contains the data that is ingested while the migration
+is happening. Begin by running ingest in parallel on the source and target
+databases. This ensures that the newest data is written to both databases. Then
+backfill your data with one of the two migration methods.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/manage-storage/ =====
+
+---
+
+## Configuration with Docker
+
+**URL:** llms-txt#configuration-with-docker
+
+**Contents:**
+- Edit the Postgres configuration file inside Docker
+ - Editing the Postgres configuration file inside Docker
+- Setting parameters at the command prompt
+
+If you are running TimescaleDB in a [Docker container][docker], there are two
+different ways to modify your Postgres configuration. You can edit the
+Postgres configuration file inside the Docker container, or you can set
+parameters at the command prompt.
+
+## Edit the Postgres configuration file inside Docker
+
+You can start the Dockert container, and then use a text editor to edit the
+Postgres configuration file directly. The configuration file requires one
+parameter per line. Blank lines are ignored, and you can use a `#` symbol at the
+beginning of a line to denote a comment.
+
+### Editing the Postgres configuration file inside Docker
+
+1. Start your Docker instance:
+
+1. Open the configuration file in `Vi` editor or your preferred text editor.
+
+1. Restart the container to reload the configuration:
+
+## Setting parameters at the command prompt
+
+If you don't want to open the configuration file to make changes, you can also
+set parameters directly from the command prompt inside your Docker container,
+using the `-c` option. For example:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/configuration/configuration/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+docker start timescaledb
+```
+
+Example 2 (bash):
+```bash
+docker exec -i -t timescaledb /bin/bash
+```
+
+Example 3 (bash):
+```bash
+vi /var/lib/postgresql/data/postgresql.conf
+```
+
+Example 4 (bash):
+```bash
+docker restart timescaledb
+```
+
+---
+
+## Integrate Prometheus with Tiger
+
+**URL:** llms-txt#integrate-prometheus-with-tiger
+
+**Contents:**
+- Prerequisites
+- Export Tiger Cloud service telemetry to Prometheus
+
+[Prometheus][prometheus] is an open-source monitoring system with a dimensional data model, flexible query language, and a modern alerting approach.
+
+This page shows you how to export your service telemetry to Prometheus:
+
+- For Tiger Cloud, using a dedicated Prometheus exporter in Tiger Cloud Console.
+- For self-hosted TimescaleDB, using [Postgres Exporter][postgresql-exporter].
+
+To follow the steps on this page:
+
+- [Download and run Prometheus][install-prometheus].
+- For Tiger Cloud:
+
+Create a target [Tiger Cloud service][create-service] with the time-series and analytics capability enabled.
+- For self-hosted TimescaleDB:
+ - Create a target [self-hosted TimescaleDB][enable-timescaledb] instance. You need your [connection details][connection-info].
+ - [Install Postgres Exporter][install-exporter].
+ To reduce latency and potential data transfer costs, install Prometheus and Postgres Exporter on a machine in the same AWS region as your Tiger Cloud service.
+
+## Export Tiger Cloud service telemetry to Prometheus
+
+To export your data, do the following:
+
+To export metrics from a Tiger Cloud service, you create a dedicated Prometheus exporter in Tiger Cloud Console, attach it to your service, then configure Prometheus to scrape metrics using the exposed URL. The Prometheus exporter exposes the metrics related to the Tiger Cloud service like CPU, memory, and storage. To scrape other metrics, use Postgres Exporter as described for self-hosted TimescaleDB. The Prometheus exporter is available for [Scale and Enterprise][pricing-plan-features] pricing plans.
+
+1. **Create a Prometheus exporter**
+
+1. In [Tiger Cloud Console][open-console], click `Exporters` > `+ New exporter`.
+
+1. Select `Metrics` for data type and `Prometheus` for provider.
+
+
+
+1. Choose the region for the exporter. Only services in the same project and region can be attached to this exporter.
+
+1. Name your exporter.
+
+1. Change the auto-generated Prometheus credentials, if needed. See [official documentation][prometheus-authentication] on basic authentication in Prometheus.
+
+1. **Attach the exporter to a service**
+
+1. Select a service, then click `Operations` > `Exporters`.
+
+1. Select the exporter in the drop-down, then click `Attach exporter`.
+
+
+
+The exporter is now attached to your service. To unattach it, click the trash icon in the exporter list.
+
+
+
+1. **Configure the Prometheus scrape target**
+
+1. Select your service, then click `Operations` > `Exporters` and click the information icon next to the exporter. You see the exporter details.
+
+
+
+1. Copy the exporter URL.
+
+1. In your Prometheus installation, update `prometheus.yml` to point to the exporter URL as a scrape target:
+
+See the [Prometheus documentation][scrape-targets] for details on configuring scrape targets.
+
+You can now monitor your service metrics. Use the following metrics to check the service is running correctly:
+
+* `timescale.cloud.system.cpu.usage.millicores`
+ * `timescale.cloud.system.cpu.total.millicores`
+ * `timescale.cloud.system.memory.usage.bytes`
+ * `timescale.cloud.system.memory.total.bytes`
+ * `timescale.cloud.system.disk.usage.bytes`
+ * `timescale.cloud.system.disk.total.bytes`
+
+Additionally, use the following tags to filter your results.
+
+|Tag|Example variable| Description |
+ |-|-|----------------------------|
+ |`host`|`us-east-1.timescale.cloud`| |
+ |`project-id`|| |
+ |`service-id`|| |
+ |`region`|`us-east-1`| AWS region |
+ |`role`|`replica` or `primary`| For service with replicas |
+
+To export metrics from self-hosted TimescaleDB, you import telemetry data about your database to Postgres Exporter, then configure Prometheus to scrape metrics from it. Postgres Exporter exposes metrics that you define, excluding the system metrics.
+
+1. **Create a user to access telemetry data about your database**
+
+1. Connect to your database in [`psql`][psql] using your [connection details][connection-info].
+
+1. Create a user named `monitoring` with a secure password:
+
+1. Grant the `pg_read_all_stats` permission to the `monitoring` user:
+
+1. **Import telemetry data about your database to Postgres Exporter**
+
+1. Connect Postgres Exporter to your database:
+
+Use your [connection details][connection-info] to import telemetry data about your database. You connect as
+ the `monitoring` user:
+
+- Local installation:
+
+ - Docker:
+
+1. Check the metrics for your database in the Prometheus format:
+
+Navigate to `http://:9187/metrics`.
+
+1. **Configure Prometheus to scrape metrics**
+
+1. In your Prometheus installation, update `prometheus.yml` to point to your Postgres Exporter instance as a scrape
+ target. In the following example, you replace `` with the hostname or IP address of the PostgreSQL
+ Exporter.
+
+If `prometheus.yml` has not been created during installation, create it manually. If you are using Docker, you can
+ find the IPAddress in `Inspect` > `Networks` for the container running Postgres Exporter.
+
+1. Restart Prometheus.
+
+1. Check the Prometheus UI at `http://:9090/targets` and `http://:9090/tsdb-status`.
+
+You see the Postgres Exporter target and the metrics scraped from it.
+
+You can further [visualize your data][grafana-prometheus] with Grafana. Use the
+[Grafana Postgres dashboard][postgresql-exporter-dashboard] or [create a custom dashboard][grafana] that suits your needs.
+
+===== PAGE: https://docs.tigerdata.com/integrations/psql/ =====
+
+**Examples:**
+
+Example 1 (yml):
+```yml
+scrape_configs:
+ - job_name: "timescaledb-exporter"
+ scheme: https
+ static_configs:
+ - targets: ["my-exporter-url"]
+ basic_auth:
+ username: "user"
+ password: "pass"
+```
+
+Example 2 (sql):
+```sql
+CREATE USER monitoring WITH PASSWORD '';
+```
+
+Example 3 (sql):
+```sql
+GRANT pg_read_all_stats to monitoring;
+```
+
+Example 4 (shell):
+```shell
+export DATA_SOURCE_NAME="postgres://:@:/?sslmode="
+ ./postgres_exporter
+```
+
+---
+
+## Upgrade TimescaleDB running in Docker
+
+**URL:** llms-txt#upgrade-timescaledb-running-in-docker
+
+**Contents:**
+- Determine the mount point type
+- Upgrade TimescaleDB within Docker
+
+If you originally installed TimescaleDB using Docker, you can upgrade from within the Docker
+container. This allows you to upgrade to the latest TimescaleDB version while retaining your data.
+
+The `timescale/timescaledb-ha*` images have the files necessary to run previous versions. Patch releases
+only contain bugfixes so should always be safe. Non-patch releases may rarely require some extra steps.
+These steps are mentioned in the [release notes][relnotes] for the version of TimescaleDB
+that you are upgrading to.
+
+After you upgrade the docker image, you run `ALTER EXTENSION` for all databases using TimescaleDB.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+The examples in this page use a Docker instance called `timescaledb`. If you
+have given your Docker instance a different name, replace it when you issue the
+commands.
+
+## Determine the mount point type
+
+When you start your upgraded Docker container, you need to be able to point the
+new Docker image to the location that contains the data from your previous
+version. To do this, you need to work out where the current mount point is. The
+current mount point varies depending on whether your container is using volume
+mounts, or bind mounts.
+
+1. Find the mount type used by your Docker container:
+
+This returns either `volume` or `bind`.
+
+1. Note the volume or bind used by your container:
+
+Docker returns the ``. You see something like this:
+
+Docker returns the ``. You see something like this:
+
+You use this value when you perform the upgrade.
+
+## Upgrade TimescaleDB within Docker
+
+To upgrade TimescaleDB within Docker, you need to download the upgraded image,
+stop the old container, and launch the new container pointing to your existing
+data.
+
+1. **Pull the latest TimescaleDB image**
+
+This command pulls the latest version of TimescaleDB running on Postgres 17:
+
+If you're using another version of Postgres, look for the relevant tag in the [TimescaleDB HA](https://hub.docker.com/r/timescale/timescaledb-ha/tags) repository on Docker Hub.
+
+1. **Stop the old container, and remove it**
+
+1. **Launch a new container with the upgraded Docker image**
+
+Launch based on your mount point type:
+
+1. **Connect to the upgraded instance using `psql` with the `-X` flag**
+
+1. **At the psql prompt, use the `ALTER` command to upgrade the extension**
+
+The [TimescaleDB Toolkit][toolkit] extension is packaged with TimescaleDB HA, it includes additional
+hyperfunctions to help you with queries and data analysis.
+
+If you have multiple databases, update each database separately.
+
+1. **Pull the latest TimescaleDB image**
+
+This command pulls the latest version of TimescaleDB running on Postgres 17.
+
+If you're using another version of Postgres, look for the relevant tag in the [TimescaleDB light](https://hub.docker.com/r/timescale/timescaledb) repository on Docker Hub.
+
+1. **Stop the old container, and remove it**
+
+1. **Launch a new container with the upgraded Docker image**
+
+Launch based on your mount point type:
+
+1. **Connect to the upgraded instance using `psql` with the `-X` flag**
+
+1. **At the psql prompt, use the `ALTER` command to upgrade the extension**
+
+If you have multiple databases, you need to update each database separately.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/upgrades/major-upgrade/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+docker inspect timescaledb --format='{{range .Mounts }}{{.Type}}{{end}}'
+```
+
+Example 2 (bash):
+```bash
+docker inspect timescaledb --format='{{range .Mounts }}{{.Name}}{{end}}'
+```
+
+Example 3 (unknown):
+```unknown
+069ba64815f0c26783b81a5f0ca813227fde8491f429cf77ed9a5ae3536c0b2c
+```
+
+Example 4 (bash):
+```bash
+docker inspect timescaledb --format='{{range .Mounts }}{{.Source}}{{end}}'
+```
+
+---
+
+## Export metrics to Prometheus
+
+**URL:** llms-txt#export-metrics-to-prometheus
+
+**Contents:**
+- Prerequisites
+- Export Tiger Cloud service telemetry to Prometheus
+
+[Prometheus][prometheus] is an open-source monitoring system with a dimensional data model, flexible query language, and a modern alerting approach.
+
+This page shows you how to export your service telemetry to Prometheus:
+
+- For Tiger Cloud, using a dedicated Prometheus exporter in Tiger Cloud Console.
+- For self-hosted TimescaleDB, using [Postgres Exporter][postgresql-exporter].
+
+To follow the steps on this page:
+
+- [Download and run Prometheus][install-prometheus].
+- For Tiger Cloud:
+
+Create a target [Tiger Cloud service][create-service] with the time-series and analytics capability enabled.
+- For self-hosted TimescaleDB:
+ - Create a target [self-hosted TimescaleDB][enable-timescaledb] instance. You need your [connection details][connection-info].
+ - [Install Postgres Exporter][install-exporter].
+ To reduce latency and potential data transfer costs, install Prometheus and Postgres Exporter on a machine in the same AWS region as your Tiger Cloud service.
+
+## Export Tiger Cloud service telemetry to Prometheus
+
+To export your data, do the following:
+
+To export metrics from a Tiger Cloud service, you create a dedicated Prometheus exporter in Tiger Cloud Console, attach it to your service, then configure Prometheus to scrape metrics using the exposed URL. The Prometheus exporter exposes the metrics related to the Tiger Cloud service like CPU, memory, and storage. To scrape other metrics, use Postgres Exporter as described for self-hosted TimescaleDB. The Prometheus exporter is available for [Scale and Enterprise][pricing-plan-features] pricing plans.
+
+1. **Create a Prometheus exporter**
+
+1. In [Tiger Cloud Console][open-console], click `Exporters` > `+ New exporter`.
+
+1. Select `Metrics` for data type and `Prometheus` for provider.
+
+
+
+1. Choose the region for the exporter. Only services in the same project and region can be attached to this exporter.
+
+1. Name your exporter.
+
+1. Change the auto-generated Prometheus credentials, if needed. See [official documentation][prometheus-authentication] on basic authentication in Prometheus.
+
+1. **Attach the exporter to a service**
+
+1. Select a service, then click `Operations` > `Exporters`.
+
+1. Select the exporter in the drop-down, then click `Attach exporter`.
+
+
+
+The exporter is now attached to your service. To unattach it, click the trash icon in the exporter list.
+
+
+
+1. **Configure the Prometheus scrape target**
+
+1. Select your service, then click `Operations` > `Exporters` and click the information icon next to the exporter. You see the exporter details.
+
+
+
+1. Copy the exporter URL.
+
+1. In your Prometheus installation, update `prometheus.yml` to point to the exporter URL as a scrape target:
+
+See the [Prometheus documentation][scrape-targets] for details on configuring scrape targets.
+
+You can now monitor your service metrics. Use the following metrics to check the service is running correctly:
+
+* `timescale.cloud.system.cpu.usage.millicores`
+ * `timescale.cloud.system.cpu.total.millicores`
+ * `timescale.cloud.system.memory.usage.bytes`
+ * `timescale.cloud.system.memory.total.bytes`
+ * `timescale.cloud.system.disk.usage.bytes`
+ * `timescale.cloud.system.disk.total.bytes`
+
+Additionally, use the following tags to filter your results.
+
+|Tag|Example variable| Description |
+ |-|-|----------------------------|
+ |`host`|`us-east-1.timescale.cloud`| |
+ |`project-id`|| |
+ |`service-id`|| |
+ |`region`|`us-east-1`| AWS region |
+ |`role`|`replica` or `primary`| For service with replicas |
+
+To export metrics from self-hosted TimescaleDB, you import telemetry data about your database to Postgres Exporter, then configure Prometheus to scrape metrics from it. Postgres Exporter exposes metrics that you define, excluding the system metrics.
+
+1. **Create a user to access telemetry data about your database**
+
+1. Connect to your database in [`psql`][psql] using your [connection details][connection-info].
+
+1. Create a user named `monitoring` with a secure password:
+
+1. Grant the `pg_read_all_stats` permission to the `monitoring` user:
+
+1. **Import telemetry data about your database to Postgres Exporter**
+
+1. Connect Postgres Exporter to your database:
+
+Use your [connection details][connection-info] to import telemetry data about your database. You connect as
+ the `monitoring` user:
+
+- Local installation:
+
+ - Docker:
+
+1. Check the metrics for your database in the Prometheus format:
+
+Navigate to `http://:9187/metrics`.
+
+1. **Configure Prometheus to scrape metrics**
+
+1. In your Prometheus installation, update `prometheus.yml` to point to your Postgres Exporter instance as a scrape
+ target. In the following example, you replace `` with the hostname or IP address of the PostgreSQL
+ Exporter.
+
+If `prometheus.yml` has not been created during installation, create it manually. If you are using Docker, you can
+ find the IPAddress in `Inspect` > `Networks` for the container running Postgres Exporter.
+
+1. Restart Prometheus.
+
+1. Check the Prometheus UI at `http://:9090/targets` and `http://:9090/tsdb-status`.
+
+You see the Postgres Exporter target and the metrics scraped from it.
+
+You can further [visualize your data][grafana-prometheus] with Grafana. Use the
+[Grafana Postgres dashboard][postgresql-exporter-dashboard] or [create a custom dashboard][grafana] that suits your needs.
+
+===== PAGE: https://docs.tigerdata.com/use-timescale/metrics-logging/monitoring/ =====
+
+**Examples:**
+
+Example 1 (yml):
+```yml
+scrape_configs:
+ - job_name: "timescaledb-exporter"
+ scheme: https
+ static_configs:
+ - targets: ["my-exporter-url"]
+ basic_auth:
+ username: "user"
+ password: "pass"
+```
+
+Example 2 (sql):
+```sql
+CREATE USER monitoring WITH PASSWORD '';
+```
+
+Example 3 (sql):
+```sql
+GRANT pg_read_all_stats to monitoring;
+```
+
+Example 4 (shell):
+```shell
+export DATA_SOURCE_NAME="postgres://:@:/?sslmode="
+ ./postgres_exporter
+```
+
+---
+
+## Install and update TimescaleDB Toolkit
+
+**URL:** llms-txt#install-and-update-timescaledb-toolkit
+
+**Contents:**
+- Prerequisites
+- Install TimescaleDB Toolkit
+- Update TimescaleDB Toolkit
+- Prerequisites
+- Install TimescaleDB Toolkit
+- Update TimescaleDB Toolkit
+- Prerequisites
+- Install TimescaleDB Toolkit
+- Update TimescaleDB Toolkit
+- Prerequisites
+
+Some hyperfunctions are included by default in TimescaleDB. For additional
+hyperfunctions, you need to install the TimescaleDB Toolkit Postgres
+extension.
+
+If you're using [Tiger Cloud][cloud], the TimescaleDB Toolkit is already installed. If you're hosting the TimescaleDB extension on your self-hosted database, you can install Toolkit by:
+
+* Using the TimescaleDB high-availability Docker image
+* Using a package manager such as `yum`, `apt`, or `brew` on platforms where
+ pre-built binaries are available
+* Building from source. For more information, see the [Toolkit developer documentation][toolkit-gh-docs]
+
+To follow this procedure:
+
+- [Install TimescaleDB][debian-install].
+- Add the TimescaleDB repository and the GPG key.
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `apt` package manager.
+
+1. Update your local repository list:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+To follow this procedure:
+
+- [Install TimescaleDB][debian-install].
+- Add the TimescaleDB repository and the GPG key.
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `apt` package manager.
+
+1. Update your local repository list:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+To follow this procedure:
+
+- [Install TimescaleDB][red-hat-install].
+- Create a TimescaleDB repository in your `yum` `repo.d` directory.
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `yum` package manager.
+
+1. Set up the repository:
+
+1. Update your local repository list:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+To follow this procedure:
+
+- [Install TimescaleDB][red-hat-install].
+- Create a TimescaleDB repository in your `yum` `repo.d` directory.
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `yum` package manager.
+
+1. Set up the repository:
+
+1. Update your local repository list:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+## Install TimescaleDB Toolkit
+
+Best practice for Toolkit installation is to use the
+[TimescaleDB Docker image](https://github.com/timescale/timescaledb-docker-ha).
+To get Toolkit, use the high availability image, `timescaledb-ha`:
+
+For more information on running TimescaleDB using Docker, see
+[Install TimescaleDB from a Docker container][docker-install].
+
+## Update TimescaleDB Toolkit
+
+To get the latest version of Toolkit, [update][update-docker] the TimescaleDB HA docker image.
+
+To follow this procedure:
+
+- [Install TimescaleDB][macos-install].
+
+## Install TimescaleDB Toolkit
+
+These instructions use the `brew` package manager. For more information on
+installing or using Homebrew, see [the `brew` homepage][brew-install].
+
+1. Tap the Tiger Data formula repository, which also contains formulae for
+ TimescaleDB and `timescaledb-tune`.
+
+1. Update your local brew installation:
+
+1. Install TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use Toolkit.
+1. Create the Toolkit extension in the database:
+
+## Update TimescaleDB Toolkit
+
+Update Toolkit by installing the latest version and running `ALTER EXTENSION`.
+
+1. Update your local repository list:
+
+1. Install the latest version of TimescaleDB Toolkit:
+
+1. [Connect to the database][connect] where you want to use the new version of Toolkit.
+1. Update the Toolkit extension in the database:
+
+For some Toolkit versions, you might need to disconnect and reconnect active
+ sessions.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/tooling/about-timescaledb-tune/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo apt update
+```
+
+Example 2 (bash):
+```bash
+sudo apt install timescaledb-toolkit-postgresql-17
+```
+
+Example 3 (sql):
+```sql
+CREATE EXTENSION timescaledb_toolkit;
+```
+
+Example 4 (bash):
+```bash
+apt update
+```
+
+---
+
+## Install self-hosted TimescaleDB
+
+**URL:** llms-txt#install-self-hosted-timescaledb
+
+**Contents:**
+- Installation
+
+Refer to the installation documentation for detailed setup instructions.
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-docker/ =====
+
+---
+
+## Configure replication
+
+**URL:** llms-txt#configure-replication
+
+**Contents:**
+- Configure the primary database
+ - Configuring the primary database
+- Configure replication parameters
+ - Configuring replication parameters
+- Create replication slots
+ - Creating replication slots
+- Configure host-based authentication parameters
+ - Configuring host-based authentication parameters
+- Create a base backup on the replica
+ - Creating a base backup on the replica
+
+This section outlines how to set up asynchronous streaming replication on one or
+more database replicas.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+Before you begin, make sure you have at least two separate instances of
+TimescaleDB running. If you installed TimescaleDB using a Docker container, use
+a [Postgres entry point script][docker-postgres-scripts] to run the
+configuration. For more advanced examples, see the
+[TimescaleDB Helm Charts repository][timescale-streamrep-helm].
+
+To configure replication on self-hosted TimescaleDB, you need to perform these
+procedures:
+
+1. [Configure the primary database][configure-primary-db]
+1. [Configure replication parameters][configure-params]
+1. [Create replication slots][create-replication-slots]
+1. [Configure host-based authentication parameters][configure-pghba]
+1. [Create a base backup on the replica][create-base-backup]
+1. [Configure replication and recovery settings][configure-replication]
+1. [Verify that the replica is working][verify-replica]
+
+## Configure the primary database
+
+To configure the primary database, you need a Postgres user with a role that
+allows it to initialize streaming replication. This is the user each replica
+uses to stream from the primary database.
+
+### Configuring the primary database
+
+1. On the primary database, as a user with superuser privileges, such as the
+ `postgres` user, set the password encryption level to `scram-sha-256`:
+
+1. Create a new user called `repuser`:
+
+The [scram-sha-256](https://www.postgresql.org/docs/current/sasl-authentication.html#SASL-SCRAM-SHA-256) encryption level is the most secure
+password-based authentication available in Postgres. It is only available in Postgres 10 and later.
+
+## Configure replication parameters
+
+There are several replication settings that need to be added or edited in the
+`postgresql.conf` configuration file.
+
+### Configuring replication parameters
+
+1. Set the `synchronous_commit` parameter to `off`.
+1. Set the `max_wal_senders` parameter to the total number of concurrent
+ connections from replicas or backup clients. As a minimum, this should equal
+ the number of replicas you intend to have.
+1. Set the `wal_level` parameter to the amount of information written to the
+ Postgres write-ahead log (WAL). For replication to work, there needs to be
+ enough data in the WAL to support archiving and replication. The default
+ value is usually appropriate.
+1. Set the `max_replication_slots` parameter to the total number of replication
+ slots the primary database can support.
+1. Set the `listen_addresses` parameter to the address of the primary database.
+ Do not leave this parameter as the local loopback address, because the
+ remote replicas must be able to connect to the primary to stream the WAL.
+1. Restart Postgres to pick up the changes. This must be done before you
+ create replication slots.
+
+The most common streaming replication use case is asynchronous replication with
+one or more replicas. In this example, the WAL is streamed to the replica, but
+the primary server does not wait for confirmation that the WAL has been written
+to disk on either the primary or the replica. This is the most performant
+replication configuration, but it does carry the risk of a small amount of data
+loss in the event of a system failure. It also makes no guarantees that the
+replica is fully up to date with the primary, which could cause inconsistencies
+between read queries on the primary and the replica. The example configuration
+for this use case:
+
+If you need stronger consistency on the replicas, or if your query load is heavy
+enough to cause significant lag between the primary and replica nodes in
+asynchronous mode, consider a synchronous replication configuration instead. For
+more information about the different replication modes, see the
+[replication modes section][replication-modes].
+
+## Create replication slots
+
+When you have configured `postgresql.conf` and restarted Postgres, you can
+create a [replication slot][postgres-rslots-docs] for each replica. Replication
+slots ensure that the primary does not delete segments from the WAL until they
+have been received by the replicas. This is important in case a replica goes
+down for an extended time. The primary needs to verify that a WAL segment has
+been consumed by a replica, so that it can safely delete data. You can use
+[archiving][postgres-archive-docs] for this purpose, but replication slots
+provide the strongest protection for streaming replication.
+
+### Creating replication slots
+
+1. At the `psql` slot, create the first replication slot. The name of the slot
+ is arbitrary. In this example, it is called `replica_1_slot`:
+
+1. Repeat for each required replication slot.
+
+## Configure host-based authentication parameters
+
+There are several replication settings that need to be added or edited to the
+`pg_hba.conf` configuration file. In this example, the settings restrict
+replication connections to traffic coming from `REPLICATION_HOST_IP` as the
+Postgres user `repuser` with a valid password. `REPLICATION_HOST_IP` can
+initiate streaming replication from that machine without additional credentials.
+You can change the `address` and `method` values to match your security and
+network settings.
+
+For more information about `pg_hba.conf`, see the
+[`pg_hba` documentation][pg-hba-docs].
+
+### Configuring host-based authentication parameters
+
+1. Open the `pg_hba.conf` configuration file and add or edit this line:
+
+1. Restart Postgres to pick up the changes.
+
+## Create a base backup on the replica
+
+Replicas work by streaming the primary server's WAL log and replaying its
+transactions in Postgres recovery mode. To do this, the replica needs to be in
+a state where it can replay the log. You can do this by restoring the replica
+from a base backup of the primary instance.
+
+### Creating a base backup on the replica
+
+1. Stop Postgres services.
+1. If the replica database already contains data, delete it before you run the
+ backup, by removing the Postgres data directory:
+
+If you don't know the location of the data directory, find it with the
+ `show data_directory;` command.
+1. Restore from the base backup, using the IP address of the primary database
+ and the replication username:
+
+The -W flag prompts you for a password. If you are using this command in an
+ automated setup, you might need to use a [pgpass file][pgpass-file].
+1. When the backup is complete, create a
+ [standby.signal][postgres-recovery-docs] file in your data directory. When
+ Postgres finds a `standby.signal` file in its data directory, it starts in
+ recovery mode and streams the WAL through the replication protocol:
+
+## Configure replication and recovery settings
+
+When you have successfully created a base backup and a `standby.signal` file, you
+can configure the replication and recovery settings.
+
+## Configuring replication and recovery settings
+
+1. In the replica's `postgresql.conf` file, add details for communicating with the
+ primary server. If you are using streaming replication, the
+ `application_name` in `primary_conninfo` should be the same as the name used
+ in the primary's `synchronous_standby_names` settings:
+
+1. Add details to mirror the configuration of the primary database. If you are
+ using asynchronous replication, use these settings:
+
+The `hot_standby` parameter must be set to `on` to allow read-only queries
+ on the replica. In Postgres 10 and later, this setting is `on` by default.
+1. Restart Postgres to pick up the changes.
+
+## Verify that the replica is working
+
+At this point, your replica should be fully synchronized with the primary
+database and prepared to stream from it. You can verify that it is working
+properly by checking the logs on the replica, which should look like this:
+
+Any client can perform reads on the replica. You can verify this by running
+inserts, updates, or other modifications to your data on the primary database,
+and then querying the replica to ensure they have been properly copied over.
+
+In most cases, asynchronous streaming replication is sufficient. However, you
+might require greater consistency between the primary and replicas, especially
+if you have a heavy workload. Under heavy workloads, replicas can lag far behind
+the primary, providing stale data to clients reading from the replicas.
+Additionally, in cases where any data loss is fatal, asynchronous replication
+might not provide enough of a durability guarantee. The Postgres
+[`synchronous_commit`][postgres-synchronous-commit-docs] feature has several
+options with varying consistency and performance tradeoffs.
+
+In the `postgresql.conf` file, set the `synchronous_commit` parameter to:
+
+* `on`: This is the default value. The server does not return `success` until
+ the WAL transaction has been written to disk on the primary and any
+ replicas.
+* `off`: The server returns `success` when the WAL transaction has been sent
+ to the operating system to write to the WAL on disk on the primary, but
+ does not wait for the operating system to actually write it. This can cause
+ a small amount of data loss if the server crashes when some data has not
+ been written, but it does not result in data corruption. Turning
+ `synchronous_commit` off is a well-known Postgres optimization for
+ workloads that can withstand some data loss in the event of a system crash.
+* `local`: Enforces `on` behavior only on the primary server.
+* `remote_write`: The database returns `success` to a client when the WAL
+ record has been sent to the operating system for writing to the WAL on the
+ replicas, but before confirmation that the record has actually been
+ persisted to disk. This is similar to asynchronous commit, except it waits
+ for the replicas as well as the primary. In practice, the extra wait time
+ incurred waiting for the replicas significantly decreases replication lag.
+* `remote_apply`: Requires confirmation that the WAL records have been written
+ to the WAL and applied to the databases on all replicas. This provides the
+ strongest consistency of any of the `synchronous_commit` options. In this
+ mode, replicas always reflect the latest state of the primary, and
+ replication lag is nearly non-existent.
+
+If `synchronous_standby_names` is empty, the settings `on`, `remote_apply`,
+`remote_write` and `local` all provide the same synchronization level, and
+transaction commits wait for the local flush to disk.
+
+This matrix shows the level of consistency provided by each mode:
+
+|Mode|WAL Sent to OS (Primary)|WAL Persisted (Primary)|WAL Sent to OS (Primary & Replicas)|WAL Persisted (Primary & Replicas)|Transaction Applied (Primary & Replicas)|
+|-|-|-|-|-|-|
+|Off|✅|❌|❌|❌|❌|
+|Local|✅|✅|❌|❌|❌|
+|Remote Write|✅|✅|✅|❌|❌|
+|On|✅|✅|✅|✅|❌|
+|Remote Apply|✅|✅|✅|✅|✅|
+
+The `synchronous_standby_names` setting is a complementary setting to
+`synchronous_commit`. It lists the names of all replicas the primary database
+supports for synchronous replication, and configures how the primary database
+waits for them. The `synchronous_standby_names` setting supports these formats:
+
+* `FIRST num_sync (replica_name_1, replica_name_2)`: This waits for
+ confirmation from the first `num_sync` replicas before returning `success`.
+ The list of `replica_names` determines the relative priority of
+ the replicas. Replica names are determined by the `application_name` setting
+ on the replicas.
+* `ANY num_sync (replica_name_1, replica_name_2)`: This waits for confirmation
+ from `num_sync` replicas in the provided list, regardless of their priority
+ or position in the list. This is works as a quorum function.
+
+Synchronous replication modes force the primary to wait until all required
+replicas have written the WAL, or applied the database transaction, depending on
+the `synchronous_commit` level. This could cause the primary to hang
+indefinitely if a required replica crashes. When the replica reconnects, it
+replays any of the WAL it needs to catch up. Only then is the primary able to
+resume writes. To mitigate this, provision more than the amount of nodes
+required under the `synchronous_standby_names` setting and list them in the
+`FIRST` or `ANY` clauses. This allows the primary to move forward as long as a
+quorum of replicas have written the most recent WAL transaction. Replicas that
+were out of service are able to reconnect and replay the missed WAL transactions
+asynchronously.
+
+## Replication diagnostics
+
+The Postgres [pg_stat_replication][postgres-pg-stat-replication-docs] view
+provides information about each replica. This view is particularly useful for
+calculating replication lag, which measures how far behind the primary the
+current state of the replica is. The `replay_lag` field gives a measure of the
+seconds between the most recent WAL transaction on the primary, and the last
+reported database commit on the replica. Coupled with `write_lag` and
+`flush_lag`, this provides insight into how far behind the replica is. The
+`*_lsn` fields also provide helpful information. They allow you to compare WAL locations between
+the primary and the replicas. The `state` field is useful for determining
+exactly what each replica is currently doing; the available modes are `startup`,
+`catchup`, `streaming`, `backup`, and `stopping`.
+
+To see the data, on the primary database, run this command:
+
+The output looks like this:
+
+Postgres provides some failover functionality, where the replica is promoted
+to primary in the event of a failure. This is provided using the
+[pg_ctl][pgctl-docs] command or the `trigger_file`. However, Postgres does
+not provide support for automatic failover. For more information, see the
+[Postgres failover documentation][failover-docs]. If you require a
+configurable high availability solution with automatic failover functionality,
+check out [Patroni][patroni-github].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/replication-and-ha/about-ha/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SET password_encryption = 'scram-sha-256';
+```
+
+Example 2 (sql):
+```sql
+CREATE ROLE repuser WITH REPLICATION PASSWORD '' LOGIN;
+```
+
+Example 3 (yaml):
+```yaml
+listen_addresses = '*'
+wal_level = replica
+max_wal_senders = 2
+max_replication_slots = 2
+synchronous_commit = off
+```
+
+Example 4 (sql):
+```sql
+SELECT * FROM pg_create_physical_replication_slot('replica_1_slot', true);
+```
+
+---
+
+## Integrate Kubernetes with Tiger
+
+**URL:** llms-txt#integrate-kubernetes-with-tiger
+
+**Contents:**
+- Prerequisites
+- Integrate TimescaleDB in a Kubernetes cluster
+
+[Kubernetes][kubernetes] is an open-source container orchestration system that automates the deployment, scaling, and management of containerized applications. You can connect Kubernetes to Tiger Cloud, and deploy TimescaleDB within your Kubernetes clusters.
+
+This guide explains how to connect a Kubernetes cluster to Tiger Cloud, configure persistent storage, and deploy TimescaleDB in your kubernetes cluster.
+
+To follow the steps on this page:
+
+- Install [self-managed Kubernetes][kubernetes-install] or sign up for a Kubernetes [Turnkey Cloud Solution][kubernetes-managed].
+- Install [kubectl][kubectl] for command-line interaction with your cluster.
+
+## Integrate TimescaleDB in a Kubernetes cluster
+
+To connect your Kubernetes cluster to your Tiger Cloud service:
+
+1. **Create a default namespace for your Tiger Cloud components**
+
+1. Create a namespace:
+
+1. Set this namespace as the default for your session:
+
+For more information, see [Kubernetes Namespaces][kubernetes-namespace].
+
+1. **Create a Kubernetes secret that stores your Tiger Cloud service credentials**
+
+Update the following command with your [connection details][connection-info], then run it:
+
+1. **Configure network access to Tiger Cloud**
+
+- **Managed Kubernetes**: outbound connections to external databases like Tiger Cloud work by default.
+ Make sure your cluster’s security group or firewall rules allow outbound traffic to Tiger Cloud IP.
+
+- **Self-hosted Kubernetes**: If your cluster is behind a firewall or running on-premise, you may need to allow
+ egress traffic to Tiger Cloud. Test connectivity using your [connection details][connection-info]:
+
+If the connection fails, check your firewall rules.
+
+1. **Create a Kubernetes deployment that can access your Tiger Cloud**
+
+Run the following command to apply the deployment:
+
+1. **Test the connection**
+
+1. Create and run a pod that uses the [connection details][connection-info] you added to `timescale-secret` in
+ the `timescale` namespace:
+
+2. Launch a psql shell in the `test-pod` you just created:
+
+You start a `psql` session connected to your Tiger Cloud service.
+
+Running TimescaleDB on Kubernetes is similar to running Postgres. This procedure outlines the steps for a non-distributed system.
+
+To connect your Kubernetes cluster to self-hosted TimescaleDB running in the cluster:
+
+1. **Create a default namespace for Tiger Data components**
+
+1. Create the Tiger Data namespace:
+
+1. Set this namespace as the default for your session:
+
+For more information, see [Kubernetes Namespaces][kubernetes-namespace].
+
+1. **Set up a persistent volume claim (PVC) storage**
+
+To manually set up a persistent volume and claim for self-hosted Kubernetes, run the following command:
+
+1. **Deploy TimescaleDB as a StatefulSet**
+
+By default, the [TimescaleDB Docker image][timescale-docker-image] you are installing on Kubernetes uses the
+ default Postgres database, user and password. To deploy TimescaleDB on Kubernetes, run the following command:
+
+1. **Allow applications to connect by exposing TimescaleDB within Kubernetes**
+
+1. **Create a Kubernetes secret to store the database credentials**
+
+1. **Deploy an application that connects to TimescaleDB**
+
+1. **Test the database connection**
+
+1. Create and run a pod to verify database connectivity using your [connection details][connection-info] saved in `timescale-secret`:
+
+1. Launch the Postgres interactive shell within the created `test-pod`:
+
+You see the Postgres interactive terminal.
+
+You have successfully integrated Kubernetes with Tiger Cloud.
+
+===== PAGE: https://docs.tigerdata.com/integrations/prometheus/ =====
+
+**Examples:**
+
+Example 1 (shell):
+```shell
+kubectl create namespace timescale
+```
+
+Example 2 (shell):
+```shell
+kubectl config set-context --current --namespace=timescale
+```
+
+Example 3 (shell):
+```shell
+kubectl create secret generic timescale-secret \
+ --from-literal=PGHOST= \
+ --from-literal=PGPORT= \
+ --from-literal=PGDATABASE= \
+ --from-literal=PGUSER= \
+ --from-literal=PGPASSWORD=
+```
+
+Example 4 (shell):
+```shell
+nc -zv
+```
+
+---
+
+## About timescaledb-tune
+
+**URL:** llms-txt#about-timescaledb-tune
+
+**Contents:**
+- Install timescaledb-tune
+- Tune your database with timescaledb-tune
+
+Get better performance by tuning your TimescaleDB database to match your system
+resources and Postgres version. `timescaledb-tune` is an open source command
+line tool that analyzes and adjusts your database settings.
+
+## Install timescaledb-tune
+
+`timescaledb-tune` is packaged with binary releases of TimescaleDB. If you
+installed TimescaleDB from any binary release, including Docker, you already
+have access. For more install instructions, see the
+[GitHub repository][github-tstune].
+
+## Tune your database with timescaledb-tune
+
+Run `timescaledb-tune` from the command line. The tool analyzes your
+`postgresql.conf` file to provide recommendations for memory, parallelism,
+write-ahead log, and other settings. These changes are written to your
+`postgresql.conf`. They take effect on the next restart.
+
+1. At the command line, run `timescaledb-tune`. To accept all recommendations
+ automatically, include the `--yes` flag.
+
+1. If you didn't use the `--yes` flag, respond to each prompt to accept or
+ reject the recommendations.
+1. The changes are written to your `postgresql.conf`.
+
+For detailed instructions and other options, see the documentation in the
+[Github repository](https://github.com/timescale/timescaledb-tune).
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-windows/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+timescaledb-tune
+```
+
+---
+
+## Manual Postgres configuration and tuning
+
+**URL:** llms-txt#manual-postgres-configuration-and-tuning
+
+**Contents:**
+- Edit the Postgres configuration file
+- Setting parameters at the command prompt
+
+If you prefer to tune settings yourself, or for settings not covered by
+`timescaledb-tune`, you can manually configure your installation using the
+Postgres configuration file.
+
+For some common configuration settings you might want to adjust, see the
+[about-configuration][about-configuration] page.
+
+For more information about the Postgres configuration page, see the
+[Postgres documentation][pg-config].
+
+## Edit the Postgres configuration file
+
+The location of the Postgres configuration file depends on your operating
+system and installation.
+
+1. **Find the location of the config file for your Postgres instance**
+ 1. Connect to your database:
+
+ 1. Retrieve the database file location from the database internal configuration.
+
+ Postgres returns the path to your configuration file. For example:
+
+1. **Open the config file, then [edit your Postgres configuration][pg-config]**
+
+1. **Save your updated configuration**
+
+When you have saved the changes you make to the configuration file, the new configuration is
+ not applied immediately. The configuration file is automatically reloaded when the server
+ receives a `SIGHUP` signal. To manually reload the file, use the `pg_ctl` command.
+
+## Setting parameters at the command prompt
+
+If you don't want to open the configuration file to make changes, you can also
+set parameters directly from the command prompt, using the `postgres` command.
+For example:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/tooling/install-toolkit/ =====
+
+**Examples:**
+
+Example 1 (shell):
+```shell
+psql -d "postgres://:@:/"
+```
+
+Example 2 (sql):
+```sql
+SHOW config_file;
+```
+
+Example 3 (sql):
+```sql
+--------------------------------------------
+ /home/postgres/pgdata/data/postgresql.conf
+ (1 row)
+```
+
+Example 4 (shell):
+```shell
+vi /home/postgres/pgdata/data/postgresql.conf
+```
+
+---
+
+## Install TimescaleDB from cloud image
+
+**URL:** llms-txt#install-timescaledb-from-cloud-image
+
+**Contents:**
+- Installing TimescaleDB from a pre-build cloud image
+- Set up the TimescaleDB extension
+- Where to next
+
+You can install TimescaleDB on a cloud hosting provider,
+from a pre-built, publicly available machine image. These instructions show you
+how to use a pre-built Amazon machine image (AMI), on Amazon Web Services (AWS).
+
+The currently available pre-built cloud image is:
+
+* Ubuntu 20.04 Amazon EBS-backed AMI
+
+The TimescaleDB AMI uses Elastic Block Store (EBS) attached volumes. This allows
+you to store image snapshots, dynamic IOPS configuration, and provides some
+protection of your data if the EC2 instance goes down. Choose an EC2 instance
+type that is optimized for EBS attached volumes. For information on choosing the
+right EBS optimized EC2 instance type, see the AWS
+[instance configuration documentation][aws-instance-config].
+
+This section shows how to use the AMI from within the AWS EC2 dashboard.
+However, you can also use the AMI to build an instance using tools like
+Cloudformation, Terraform, the AWS CLI, or any other AWS deployment tool that
+supports public AMIs.
+
+## Installing TimescaleDB from a pre-build cloud image
+
+1. Make sure you have an [Amazon Web Services account][aws-signup], and are
+ signed in to [your EC2 dashboard][aws-dashboard].
+1. Navigate to `Images → AMIs`.
+1. In the search bar, change the search to `Public images` and type _Timescale_
+ search term to find all available TimescaleDB images.
+1. Select the image you want to use, and click `Launch instance from image`.
+  +
+After you have completed the installation, connect to your instance and
+configure your database. For information about connecting to the instance, see
+the AWS [accessing instance documentation][aws-connect]. The easiest way to
+configure your database is to run the `timescaledb-tune` script, which is included
+with the `timescaledb-tools` package. For more information, see the
+[configuration][config] section.
+
+After running the `timescaledb-tune` script, you need to restart the Postgres
+service for the configuration changes to take effect. To restart the service,
+run `sudo systemctl restart postgresql.service`.
+
+## Set up the TimescaleDB extension
+
+When you have Postgres and TimescaleDB installed, connect to your instance and
+set up the TimescaleDB extension.
+
+1. On your instance, at the command prompt, connect to the Postgres
+ instance as the `postgres` superuser:
+
+1. At the prompt, create an empty database. For example, to create a database
+ called `tsdb`:
+
+1. Connect to the database you created:
+
+1. Add the TimescaleDB extension:
+
+You can check that the TimescaleDB extension is installed by using the `\dx`
+command at the command prompt. It looks like this:
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-macos/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo -u postgres psql
+```
+
+Example 2 (sql):
+```sql
+CREATE database tsdb;
+```
+
+Example 3 (sql):
+```sql
+\c tsdb
+```
+
+Example 4 (sql):
+```sql
+CREATE EXTENSION IF NOT EXISTS timescaledb;
+```
+
+---
+
+## About upgrades
+
+**URL:** llms-txt#about-upgrades
+
+**Contents:**
+- Plan your upgrade
+- Check your version
+
+A major upgrade is when you upgrade from one major version of TimescaleDB, to
+the next major version. For example, when you upgrade from TimescaleDB 1
+to TimescaleDB 2.
+
+A minor upgrade is when you upgrade within your current major version of
+TimescaleDB. For example, when you upgrade from TimescaleDB 2.5 to
+TimescaleDB 2.6.
+
+If you originally installed TimescaleDB using Docker, you can upgrade from
+within the Docker container. For more information, and instructions, see the
+[Upgrading with Docker section][upgrade-docker].
+
+When you upgrade the `timescaledb` extension, the experimental schema is removed
+by default. To use experimental features after an upgrade, you need to add the
+experimental schema again.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+- Install the Postgres client tools on your migration machine. This includes `psql`, and `pg_dump`.
+- Read [the release notes][relnotes] for the version of TimescaleDB that you are upgrading to.
+- [Perform a backup][backup] of your database. While TimescaleDB
+ upgrades are performed in-place, upgrading is an intrusive operation. Always
+ make sure you have a backup on hand, and that the backup is readable in the
+ case of disaster.
+
+If you use the TimescaleDB Toolkit, ensure the `timescaledb_toolkit` extension is on
+version 1.6.0, then upgrade the `timescaledb` extension. If required, you
+can then later upgrade the `timescaledb_toolkit` extension to the most
+recent version.
+
+## Check your version
+
+You can check which version of TimescaleDB you are running, at the psql command
+prompt. Use this to check which version you are running before you begin your
+upgrade, and again after your upgrade is complete:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/upgrades/upgrade-pg/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+\dx timescaledb
+
+ Name | Version | Schema | Description
+-------------+---------+------------+---------------------------------------------------------------------
+ timescaledb | x.y.z | public | Enables scalable inserts and complex queries for time-series data
+(1 row)
+```
+
+---
+
+## Install TimescaleDB on Linux
+
+**URL:** llms-txt#install-timescaledb-on-linux
+
+**Contents:**
+- Install and configure TimescaleDB on Postgres
+- Add the TimescaleDB extension to your database
+- Supported platforms
+- Where to next
+
+TimescaleDB is a [Postgres extension](https://www.postgresql.org/docs/current/external-extensions.html) for
+time series and demanding workloads that ingest and query high volumes of data.
+
+This section shows you how to:
+
+* [Install and configure TimescaleDB on Postgres](#install-and-configure-timescaledb-on-postgresql) - set up
+ a self-hosted Postgres instance to efficiently run TimescaleDB.
+* [Add the TimescaleDB extension to your database](#add-the-timescaledb-extension-to-your-database) - enable TimescaleDB
+ features and performance improvements on a database.
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+## Install and configure TimescaleDB on Postgres
+
+This section shows you how to install the latest version of Postgres and
+TimescaleDB on a [supported platform](#supported-platforms) using the packages supplied by Tiger Data.
+
+If you have previously installed Postgres without a package manager, you may encounter errors
+following these install instructions. Best practice is to fully remove any existing Postgres
+installations before you begin.
+
+To keep your current Postgres installation, [Install from source][install-from-source].
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+1. **Add the TimescaleDB package**
+
+1. **Install the TimescaleDB GPG key**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To install a specific TimescaleDB [release][releases-page], set the version. For example:
+
+`sudo apt-get install timescaledb-2-postgresql-14='2.6.0*' timescaledb-2-loader-postgresql-14='2.6.0*'`
+
+Older versions of TimescaleDB may not support all the OS versions listed on this page.
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+By default, this script is included with the `timescaledb-tools` package when you install TimescaleDB. Use the prompts to tune your development or production environment. For more information on manual configuration, see [Configuration][config]. If you have an issue, run `sudo apt install timescaledb-tools`.
+
+1. **Restart Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+1. **Install the TimescaleDB GPG key**
+
+For Ubuntu 21.10 and earlier use the following command:
+
+`wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo apt-key add -`
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To install a specific TimescaleDB [release][releases-page], set the version. For example:
+
+`sudo apt-get install timescaledb-2-postgresql-14='2.6.0*' timescaledb-2-loader-postgresql-14='2.6.0*'`
+
+Older versions of TimescaleDB may not support all the OS versions listed on this page.
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+By default, this script is included with the `timescaledb-tools` package when you install TimescaleDB. Use the prompts to tune your development or production environment. For more information on manual configuration, see [Configuration][config]. If you have an issue, run `sudo apt install timescaledb-tools`.
+
+1. **Restart Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+Tiger Data supports Rocky Linux 8 and 9 on amd64 only.
+
+1. **Update your local repository list**
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Disable the built-in PostgreSQL module**
+
+This is for Rocky Linux 9 only.
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+ArchLinux packages are built by the community.
+
+1. **Install the latest Postgres and TimescaleDB packages**
+
+1. **Initalize your Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB. For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+Job jobbed, you have installed Postgres and TimescaleDB.
+
+## Add the TimescaleDB extension to your database
+
+For improved performance, you enable TimescaleDB on each database on your self-hosted Postgres instance.
+This section shows you how to enable TimescaleDB for a new database in Postgres using `psql` from the command line.
+
+1. **Connect to a database on your Postgres instance**
+
+In Postgres, the default user and database are both `postgres`. To use a
+ different database, set `` to the name of that database:
+
+1. **Add TimescaleDB to the database**
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press q to exit the list of extensions.
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+## Supported platforms
+
+You can deploy TimescaleDB on the following systems:
+
+| Operation system | Version |
+|---------------------------------|-----------------------------------------------------------------------|
+| Debian | 13 Trixe, 12 Bookworm, 11 Bullseye |
+| Ubuntu | 24.04 Noble Numbat, 22.04 LTS Jammy Jellyfish |
+| Red Hat Enterprise | Linux 9, Linux 8 |
+| Fedora | Fedora 35, Fedora 34, Fedora 33 |
+| Rocky Linux | Rocky Linux 9 (x86_64), Rocky Linux 8 |
+| ArchLinux (community-supported) | Check the [available packages][archlinux-packages] |
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/self-hosted/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo apt install gnupg postgresql-common apt-transport-https lsb-release wget
+```
+
+Example 2 (bash):
+```bash
+sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
+```
+
+Example 3 (bash):
+```bash
+echo "deb https://packagecloud.io/timescale/timescaledb/debian/ $(lsb_release -c -s) main" | sudo tee /etc/apt/sources.list.d/timescaledb.list
+```
+
+Example 4 (bash):
+```bash
+wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/timescaledb.gpg
+```
+
+---
+
+## Set up multi-node on self-hosted TimescaleDB
+
+**URL:** llms-txt#set-up-multi-node-on-self-hosted-timescaledb
+
+**Contents:**
+- Set up multi-node on self-hosted TimescaleDB
+ - Setting up multi-node on self-hosted TimescaleDB
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+To set up multi-node on a self-hosted TimescaleDB instance, you need:
+
+* A Postgres instance to act as an access node (AN)
+* One or more Postgres instances to act as data nodes (DN)
+* TimescaleDB [installed][install] and [set up][setup] on all nodes
+* Access to a superuser role, such as `postgres`, on all nodes
+
+The access and data nodes must begin as individual TimescaleDB instances.
+They should be hosts with a running Postgres server and a loaded TimescaleDB
+extension. For more information about installing self-hosted TimescaleDB
+instances, see the [installation instructions][install]. Additionally, you
+can configure [high availability with multi-node][multi-node-ha] to
+increase redundancy and resilience.
+
+The multi-node TimescaleDB architecture consists of an access node (AN) which
+stores metadata for the distributed hypertable and performs query planning
+across the cluster, and a set of data nodes (DNs) which store subsets of the
+distributed hypertable dataset and execute queries locally. For more information
+about the multi-node architecture, see [about multi-node][about-multi-node].
+
+If you intend to use continuous aggregates in your multi-node environment, check
+the additional considerations in the [continuous aggregates][caggs] section.
+
+## Set up multi-node on self-hosted TimescaleDB
+
+When you have installed TimescaleDB on the access node and as many data nodes as
+you require, you can set up multi-node and create a distributed hypertable.
+
+Before you begin, make sure you have considered what partitioning method you
+want to use for your multi-node cluster. For more information about multi-node
+and architecture, see the
+[About multi-node section](https://docs.tigerdata.com/self-hosted/latest/multinode-timescaledb/about-multinode/).
+
+### Setting up multi-node on self-hosted TimescaleDB
+
+1. On the access node (AN), run this command and provide the hostname of the
+ first data node (DN1) you want to add:
+
+1. Repeat for all other data nodes:
+
+1. On the access node, create the distributed hypertable with your chosen
+ partitioning. In this example, the distributed hypertable is called
+ `example`, and it is partitioned on `time` and `location`:
+
+1. Insert some data into the hypertable. For example:
+
+When you have set up your multi-node installation, you can configure your
+cluster. For more information, see the [configuration section][configuration].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/multinode-timescaledb/multinode-auth/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_data_node('dn1', 'dn1.example.com')
+```
+
+Example 2 (sql):
+```sql
+SELECT add_data_node('dn2', 'dn2.example.com')
+ SELECT add_data_node('dn3', 'dn3.example.com')
+```
+
+Example 3 (sql):
+```sql
+SELECT create_distributed_hypertable('example', 'time', 'location');
+```
+
+Example 4 (sql):
+```sql
+INSERT INTO example VALUES ('2020-12-14 13:45', 1, '1.2.3.4');
+```
+
+---
+
+## TimescaleDB tuning tool
+
+**URL:** llms-txt#timescaledb-tuning-tool
+
+To help make configuring TimescaleDB a little easier, you can use the [`timescaledb-tune`][tstune]
+tool. This tool handles setting the most common parameters to good values based
+on your system. It accounts for memory, CPU, and Postgres version.
+`timescaledb-tune` is packaged with the TimescaleDB binary releases as a
+dependency, so if you installed TimescaleDB from a binary release (including
+Docker), you should already have access to the tool. Alternatively, you can use
+the `go install` command to install it:
+
+The `timescaledb-tune` tool reads your system's `postgresql.conf` file and
+offers interactive suggestions for your settings. Here is an example of the tool
+running:
+
+When you have answered the questions, the changes are written to your
+`postgresql.conf` and take effect when you next restart.
+
+If you are starting on a fresh instance and don't want to approve each group of
+changes, you can automatically accept and append the suggestions to the end of
+your `postgresql.conf` by using some additional flags when you run the tool:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/configuration/postgres-config/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+go install github.com/timescale/timescaledb-tune/cmd/timescaledb-tune@latest
+```
+
+Example 2 (bash):
+```bash
+Using postgresql.conf at this path:
+/usr/local/var/postgres/postgresql.conf
+
+Is this correct? [(y)es/(n)o]: y
+Writing backup to:
+/var/folders/cr/example/T/timescaledb_tune.backup202101071520
+
+shared_preload_libraries needs to be updated
+Current:
+#shared_preload_libraries = 'timescaledb'
+Recommended:
+shared_preload_libraries = 'timescaledb'
+Is this okay? [(y)es/(n)o]: y
+success: shared_preload_libraries will be updated
+
+Tune memory/parallelism/WAL and other settings? [(y)es/(n)o]: y
+Recommendations based on 8.00 GB of available memory and 4 CPUs for PostgreSQL 12
+
+Memory settings recommendations
+Current:
+shared_buffers = 128MB
+#effective_cache_size = 4GB
+#maintenance_work_mem = 64MB
+#work_mem = 4MB
+Recommended:
+shared_buffers = 2GB
+effective_cache_size = 6GB
+maintenance_work_mem = 1GB
+work_mem = 26214kB
+Is this okay? [(y)es/(s)kip/(q)uit]:
+```
+
+Example 3 (bash):
+```bash
+timescaledb-tune --quiet --yes --dry-run >> /path/to/postgresql.conf
+```
+
+---
+
+## Self-hosted TimescaleDB
+
+**URL:** llms-txt#self-hosted-timescaledb
+
+TimescaleDB is an extension for Postgres that enables time-series workloads,
+increasing ingest, query, storage and analytics performance.
+
+Best practice is to run TimescaleDB in a [Tiger Cloud service](https://console.cloud.timescale.com/signup), but if you want to
+self-host you can run TimescaleDB yourself.
+Deploy a Tiger Cloud service. We tune your database for performance and handle scalability, high availability, backups and management so you can relax.
+
+Self-hosted TimescaleDB is community supported. For additional help
+check out the friendly [Tiger Data community][community].
+
+If you'd prefer to pay for support then check out our [self-managed support][support].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/configuration/about-configuration/ =====
+
+---
+
+## Install or upgrade of TimescaleDB Toolkit fails
+
+**URL:** llms-txt#install-or-upgrade-of-timescaledb-toolkit-fails
+
+**Contents:**
+ - Troubleshooting TimescaleDB Toolkit setup
+
+
+
+In some cases, when you create the TimescaleDB Toolkit extension, or upgrade it
+with the `ALTER EXTENSION timescaledb_toolkit UPDATE` command, it might fail
+with the above error.
+
+This occurs if the list of available extensions does not include the version you
+are trying to upgrade to, and it can occur if the package was not installed
+correctly in the first place. To correct the problem, install the upgrade
+package, restart Postgres, verify the version, and then attempt the update
+again.
+
+### Troubleshooting TimescaleDB Toolkit setup
+
+1. If you're installing Toolkit from a package, check your package manager's
+ local repository list. Make sure the TimescaleDB repository is available and
+ contains Toolkit. For instructions on adding the TimescaleDB repository, see
+ the installation guides:
+ * [Linux installation guide][linux-install]
+1. Update your local repository list with `apt update` or `yum update`.
+1. Restart your Postgres service.
+1. Check that the right version of Toolkit is among your available extensions:
+
+The result should look like this:
+
+1. Retry `CREATE EXTENSION` or `ALTER EXTENSION`.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/self-hosted/pg_dump-permission-denied/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM pg_available_extensions
+ WHERE name = 'timescaledb_toolkit';
+```
+
+Example 2 (bash):
+```bash
+-[ RECORD 1 ]-----+--------------------------------------------------------------------------------------
+ name | timescaledb_toolkit
+ default_version | 1.6.0
+ installed_version | 1.6.0
+ comment | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
+```
+
+---
diff --git a/skills/timescaledb/references/llms-full.md b/skills/timescaledb/references/llms-full.md
new file mode 100644
index 0000000..a926860
--- /dev/null
+++ b/skills/timescaledb/references/llms-full.md
@@ -0,0 +1,79540 @@
+===== PAGE: https://docs.tigerdata.com/getting-started/try-key-features-timescale-products/ =====
+
+# Try the key features in Tiger Data products
+
+
+
+Tiger Cloud offers managed database services that provide a stable and reliable environment for your
+applications.
+
+Each Tiger Cloud service is a single optimised Postgres instance extended with innovations such as TimescaleDB in the database
+engine, in a cloud infrastructure that delivers speed without sacrifice. A radically faster Postgres for transactional,
+analytical, and agentic workloads at scale.
+
+Tiger Cloud scales Postgres to ingest and query vast amounts of live data. Tiger Cloud
+provides a range of features and optimizations that supercharge your queries while keeping the
+costs down. For example:
+* The hypercore row-columnar engine in TimescaleDB makes queries up to 350x faster, ingests 44% faster, and reduces
+ storage by 90%.
+* Tiered storage in Tiger Cloud seamlessly moves your data from high performance storage for frequently accessed data to
+ low cost bottomless storage for rarely accessed data.
+
+The following figure shows how TimescaleDB optimizes your data for superfast real-time analytics:
+
+
+
+This page shows you how to rapidly implement the features in Tiger Cloud that enable you to
+ingest and query data faster while keeping the costs low.
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Optimize time-series data in hypertables with hypercore
+
+Time-series data represents the way a system, process, or behavior changes over time. Hypertables are Postgres tables
+that help you improve insert and query performance by automatically partitioning your data by time. Each hypertable
+is made up of child tables called chunks. Each chunk is assigned a range of time, and only
+contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and runs the query on
+it, instead of going through the entire table. You can also tune hypertables to increase performance even more.
+
+
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Hypertables exist alongside regular Postgres tables.
+You use regular Postgres tables for relational data, and interact with hypertables
+and regular Postgres tables in the same way.
+
+This section shows you how to create regular tables and hypertables, and import
+relational and time-series data from external files.
+
+1. **Import some time-series data into hypertables**
+
+ 1. Unzip [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip) to a ``.
+
+ This test dataset contains:
+ - Second-by-second data for the most-traded crypto-assets. This time-series data is best suited for
+ optimization in a [hypertable][hypertables-section].
+ - A list of asset symbols and company names. This is best suited for a regular relational table.
+
+ To import up to 100 GB of data directly from your current Postgres-based database,
+ [migrate with downtime][migrate-with-downtime] using native Postgres tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by Tiger Data. To add data from non-Postgres data
+ sources, see [Import and ingest data][data-ingest].
+
+ 1. Upload data into a hypertable:
+
+ To more fully understand how to create a hypertable, how hypertables work, and how to optimize them for
+ performance by tuning chunk intervals and enabling chunk skipping, see
+ [the hypertables documentation][hypertables-section].
+
+
+
+
+
+ The Tiger Cloud Console data upload creates hypertables and relational tables from the data you are uploading:
+ 1. In [Tiger Cloud Console][portal-ops-mode], select the service to add data to, then click `Actions` > `Import data` > `Upload .CSV`.
+ 1. Click to browse, or drag and drop `/tutorial_sample_tick.csv` to upload.
+ 1. Leave the default settings for the delimiter, skipping the header, and creating a new table.
+ 1. In `Table`, provide `crypto_ticks` as the new table name.
+ 1. Enable `hypertable partition` for the `time` column and click `Process CSV file`.
+
+ The upload wizard creates a hypertable containing the data from the CSV file.
+ 1. When the data is uploaded, close `Upload .CSV`.
+
+ If you want to have a quick look at your data, press `Run` .
+ 1. Repeat the process with `/tutorial_sample_assets.csv` and rename to `crypto_assets`.
+
+ There is no time-series data in this table, so you don't see the `hypertable partition` option.
+
+
+
+
+
+ 1. In Terminal, navigate to `` and connect to your service.
+ ```bash
+ psql -d "postgres://:@:/"
+ ```
+ You use your [connection details][connection-info] to fill in this Postgres connection string.
+
+ 2. Create tables for the data to import:
+
+ - For the time-series data:
+
+ 1. In your sql client, create a hypertable:
+
+ Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes], remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+ ```sql
+ CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby = 'symbol'
+ );
+ ```
+
+ If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+ - For the relational data:
+
+ In your sql client, create a normal Postgres table:
+ ```sql
+ CREATE TABLE crypto_assets (
+ symbol TEXT NOT NULL,
+ name TEXT NOT NULL
+ );
+ ```
+ 1. Speed up data ingestion:
+
+ When you set `timescaledb.enable_direct_compress_copy` your data gets compressed in memory during ingestion with `COPY` statements.
+By writing the compressed batches immediately in the columnstore, the IO footprint is significantly lower.
+Also, the [columnstore policy][add_columnstore_policy] you set is less important, `INSERT` already produces compressed chunks.
+
+
+
+Please note that this feature is a **tech preview** and not production-ready.
+Using this feature could lead to regressed query performance and/or storage ratio, if the ingested batches are not
+correctly ordered or are of too high cardinality.
+
+
+
+To enable in-memory data compression during ingestion:
+
+```sql
+SET timescaledb.enable_direct_compress_copy=on;
+```
+
+**Important facts**
+- High cardinality use cases do not produce good batches and lead to degreaded query performance.
+- The columnstore is optimized to store 1000 records per batch, which is the optimal format for ingestion per segment by.
+- WAL records are written for the compressed batches rather than the individual tuples.
+- Currently only `COPY` is support, `INSERT` will eventually follow.
+- Best results are achieved for batch ingestion with 1000 records or more, upper boundary is 10.000 records.
+- Continous Aggregates are **not** supported at the moment.
+
+ 3. Upload the dataset to your service:
+
+ ```sql
+ \COPY crypto_ticks from './tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
+ ```
+
+ ```sql
+ \COPY crypto_assets from './tutorial_sample_assets.csv' DELIMITER ',' CSV HEADER;
+ ```
+
+
+
+
+
+1. **Have a quick look at your data**
+
+ You query hypertables in exactly the same way as you would a relational Postgres table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [Tiger Cloud Console][portal-data-mode] for all your Tiger Cloud services. This feature is not available under the Free pricing plan.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [Tiger Cloud Console][portal-ops-mode] for a Tiger Cloud service.
+ - **psql**: easily run queries on your Tiger Cloud services or self-hosted TimescaleDB deployment from Terminal.
+
+
+
+## Enhance query performance for analytics
+
+Hypercore is the TimescaleDB hybrid row-columnar storage engine, designed specifically for real-time
+analytics and
+powered by time-series data. The advantage of hypercore is its ability to seamlessly switch between row-oriented and
+column-oriented storage. This flexibility enables TimescaleDB to deliver the best of both worlds, solving the key
+challenges in real-time analytics.
+
+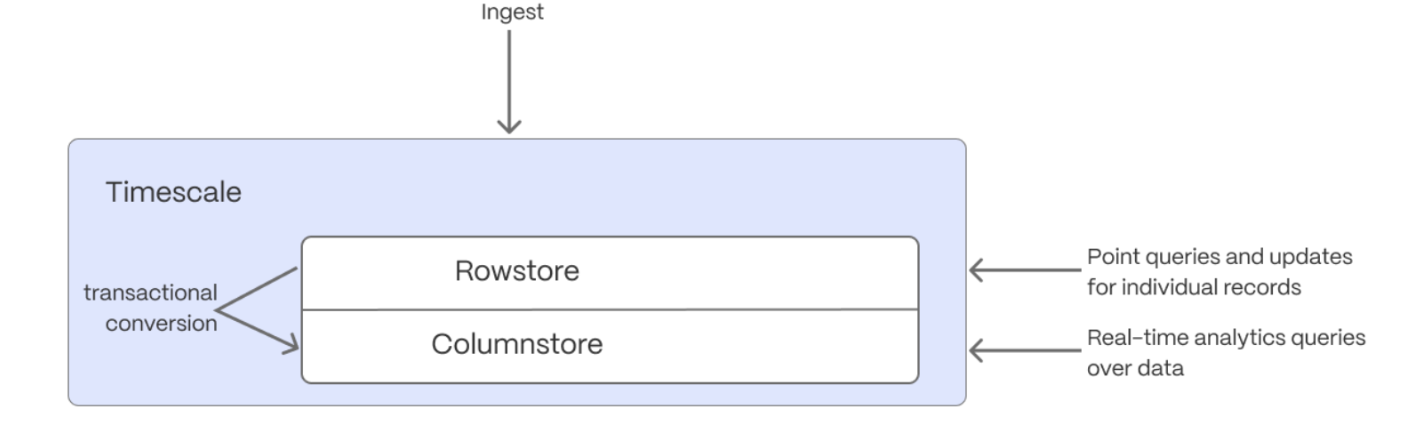
+
+When TimescaleDB converts chunks from the rowstore to the columnstore, multiple records are grouped into a single row.
+The columns of this row hold an array-like structure that stores all the data. Because a single row takes up less disk
+space, you can reduce your chunk size by up to 98%, and can also speed up your queries. This helps you save on storage costs,
+and keeps your queries operating at lightning speed.
+
+hypercore is enabled by default when you call [CREATE TABLE][hypertable-create-table]. Best practice is to compress
+data that is no longer needed for highest performance queries, but is still accessed regularly in the columnstore.
+For example, yesterday's market data.
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+ For example, yesterday's data:
+ ``` sql
+ CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
+ ```
+ If you have not configured a `segmentby` column, TimescaleDB chooses one for you based on the data in your
+ hypertable. For more information on how to tune your hypertables for the best performance, see
+ [efficient queries][secondary-indexes].
+
+1. **View your data space saving**
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than
+ 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved, click `Explorer` > `public` > `crypto_ticks`.
+
+ 
+
+## Write fast and efficient analytical queries
+
+Aggregation is a way of combing data to get insights from it. Average, sum, and count are all
+examples of simple aggregates. However, with large amounts of data, aggregation slows things down, quickly.
+Continuous aggregates are a kind of hypertable that is refreshed automatically in
+the background as new data is added, or old data is modified. Changes to your dataset are tracked,
+and the hypertable behind the continuous aggregate is automatically updated in the background.
+
+
+
+You create continuous aggregates on uncompressed data in high-performance storage. They continue to work
+on [data in the columnstore][test-drive-enable-compression]
+and [rarely accessed data in tiered storage][test-drive-tiered-storage]. You can even
+create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+
+You use time buckets to create a continuous aggregate. Time buckets aggregate data in hypertables by time
+interval. For example, a 5-minute, 1-hour, or 3-day bucket. The data grouped in a time bucket uses a single
+timestamp. Continuous aggregates minimize the number of records that you need to look up to perform your
+query.
+
+This section shows you how to run fast analytical queries using time buckets and continuous aggregate in
+Tiger Cloud Console. You can also do this using psql.
+
+
+
+
+
+This feature is not available under the Free pricing plan.
+
+1. **Connect to your service**
+
+ In [Tiger Cloud Console][portal-data-mode], select your service in the connection drop-down in the top right.
+
+1. **Create a continuous aggregate**
+
+ For a continuous aggregate, data grouped using a time bucket is stored in a
+ Postgres `MATERIALIZED VIEW` in a hypertable. `timescaledb.continuous` ensures that this data
+ is always up to date.
+ In data mode, use the following code to create a continuous aggregate on the real-time data in
+ the `crypto_ticks` table:
+
+ ```sql
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS day,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM crypto_ticks srt
+ GROUP BY day, symbol;
+ ```
+
+ This continuous aggregate creates the [candlestick chart][charts] data you use to visualize
+ the price change of an asset.
+
+1. **Create a policy to refresh the view every hour**
+
+ ```sql
+ SELECT add_continuous_aggregate_policy('assets_candlestick_daily',
+ start_offset => INTERVAL '3 weeks',
+ end_offset => INTERVAL '24 hours',
+ schedule_interval => INTERVAL '3 hours');
+ ```
+
+1. **Have a quick look at your data**
+
+ You query continuous aggregates exactly the same way as your other tables. To query the `assets_candlestick_daily`
+ continuous aggregate for all assets:
+
+
+
+
+
+
+
+1. **In [Tiger Cloud Console][portal-ops-mode], select the service you uploaded data to**
+1. **Click `Explorer` > `Continuous Aggregates` > `Create a Continuous Aggregate` next to the `crypto_ticks` hypertable**
+1. **Create a view called `assets_candlestick_daily` on the `time` column with an interval of `1 day`, then click `Next step`**
+ 
+1. **Update the view SQL with the following functions, then click `Run`**
+ ```sql
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS bucket,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM "public"."crypto_ticks" srt
+ GROUP BY bucket, symbol;
+ ```
+1. **When the view is created, click `Next step`**
+1. **Define a refresh policy with the following values:**
+ - `How far back do you want to materialize?`: `3 weeks`
+ - `What recent data to exclude?`: `24 hours`
+ - `How often do you want the job to run?`: `3 hours`
+1. **Click `Next step`, then click `Run`**
+
+Tiger Cloud creates the continuous aggregate and displays the aggregate ID in Tiger Cloud Console. Click `DONE` to close the wizard.
+
+
+
+
+
+To see the change in terms of query time and data returned between a regular query and
+a continuous aggregate, run the query part of the continuous aggregate
+( `SELECT ...GROUP BY day, symbol;` ) and compare the results.
+
+## Slash storage charges
+
+
+
+In the previous sections, you used continuous aggregates to make fast analytical queries, and
+hypercore to reduce storage costs on frequently accessed data. To reduce storage costs even more,
+you create tiering policies to move rarely accessed data to the object store. The object store is
+low-cost bottomless data storage built on Amazon S3. However, no matter the tier, you can
+[query your data when you need][querying-tiered-data]. Tiger Cloud seamlessly accesses the correct storage
+tier and generates the response.
+
+
+
+To set up data tiering:
+
+1. **Enable data tiering**
+
+ 1. In [Tiger Cloud Console][portal-ops-mode], select the service to modify.
+
+ 1. In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`.
+
+ 
+
+ When tiered storage is enabled, you see the amount of data in the tiered object storage.
+
+1. **Set the time interval when data is tiered**
+
+ In Tiger Cloud Console, click `Data` to switch to the data mode, then enable data tiering on a hypertable with the following query:
+ ```sql
+ SELECT add_tiering_policy('assets_candlestick_daily', INTERVAL '3 weeks');
+ ```
+
+1. **Query tiered data**
+
+ You enable reads from tiered data for each query, for a session or for all future
+ sessions. To run a single query on tiered data:
+
+ 1. Enable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = true
+ ```
+ 1. Query the data:
+ ```sql
+ SELECT * FROM crypto_ticks srt LIMIT 10
+ ```
+ 1. Disable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = false;
+ ```
+ For more information, see [Querying tiered data][querying-tiered-data].
+
+## Reduce the risk of downtime and data loss
+
+
+
+By default, all Tiger Cloud services have rapid recovery enabled. However, if your app has very low tolerance
+for downtime, Tiger Cloud offers high-availability replicas. HA replicas are exact, up-to-date copies
+of your database hosted in multiple AWS availability zones (AZ) within the same region as your primary node.
+HA replicas automatically take over operations if the original primary data node becomes unavailable.
+The primary node streams its write-ahead log (WAL) to the replicas to minimize the chances of
+data loss during failover.
+
+1. In [Tiger Cloud Console][cloud-login], select the service to enable replication for.
+1. Click `Operations`, then select `High availability`.
+1. Choose your replication strategy, then click `Change configuration`.
+
+ 
+
+1. In `Change high availability configuration`, click `Change config`.
+
+For more information, see [High availability][high-availability].
+
+What next? See the [use case tutorials][tutorials], interact with the data in your Tiger Cloud service using
+[your favorite programming language][connect-with-code], integrate your Tiger Cloud service with a range of
+[third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive into [the API][use-the-api].
+
+
+===== PAGE: https://docs.tigerdata.com/getting-started/start-coding-with-timescale/ =====
+
+# Start coding with Tiger Data
+
+
+
+Easily integrate your app with Tiger Cloud or self-hosted TimescaleDB. Use your favorite programming language to connect to your
+Tiger Cloud service, create and manage hypertables, then ingest and query data.
+
+
+
+
+
+# "Quick Start: Ruby and TimescaleDB"
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Rails][rails-guide].
+
+## Connect a Rails app to your service
+
+Every Tiger Cloud service is a 100% Postgres database hosted in Tiger Cloud with
+Tiger Data extensions such as TimescaleDB. You connect to your Tiger Cloud service
+from a standard Rails app configured for Postgres.
+
+1. **Create a new Rails app configured for Postgres**
+
+ Rails creates and bundles your app, then installs the standard Postgres Gems.
+
+ ```bash
+ rails new my_app -d=postgresql
+ cd my_app
+ ```
+
+1. **Install the TimescaleDB gem**
+
+ 1. Open `Gemfile`, add the following line, then save your changes:
+
+ ```ruby
+ gem 'timescaledb'
+ ```
+
+ 1. In Terminal, run the following command:
+
+ ```bash
+ bundle install
+ ```
+
+1. **Connect your app to your Tiger Cloud service**
+
+ 1. In `/config/database.yml` update the configuration to read securely connect to your Tiger Cloud service
+ by adding `url: <%= ENV['DATABASE_URL'] %>` to the default configuration:
+
+ ```yaml
+ default: &default
+ adapter: postgresql
+ encoding: unicode
+ pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
+ url: <%= ENV['DATABASE_URL'] %>
+ ```
+
+ 1. Set the environment variable for `DATABASE_URL` to the value of `Service URL` from
+ your [connection details][connection-info]
+ ```bash
+ export DATABASE_URL="value of Service URL"
+ ```
+
+ 1. Create the database:
+ - **Tiger Cloud**: nothing to do. The database is part of your Tiger Cloud service.
+ - **Self-hosted TimescaleDB**, create the database for the project:
+
+ ```bash
+ rails db:create
+ ```
+
+ 1. Run migrations:
+
+ ```bash
+ rails db:migrate
+ ```
+
+ 1. Verify the connection from your app to your Tiger Cloud service:
+
+ ```bash
+ echo "\dx" | rails dbconsole
+ ```
+
+ The result shows the list of extensions in your Tiger Cloud service
+
+ | Name | Version | Schema | Description |
+ | -- | -- | -- | -- |
+ | pg_buffercache | 1.5 | public | examine the shared buffer cache|
+ | pg_stat_statements | 1.11 | public | track planning and execution statistics of all SQL statements executed|
+ | plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language|
+ | postgres_fdw | 1.1 | public | foreign-data wrapper for remote Postgres servers|
+ | timescaledb | 2.18.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)|
+ | timescaledb_toolkit | 1.19.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities|
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables designed to simplify and accelerate data analysis. Anything
+you can do with regular Postgres tables, you can do with hypertables - but much faster and more conveniently.
+
+In this section, you use the helpers in the TimescaleDB gem to create and manage a [hypertable][about-hypertables].
+
+1. **Generate a migration to create the page loads table**
+
+ ```bash
+ rails generate migration create_page_loads
+ ```
+
+ This creates the `/db/migrate/_create_page_loads.rb` migration file.
+
+1. **Add hypertable options**
+
+ Replace the contents of `/db/migrate/_create_page_loads.rb`
+ with the following:
+
+ ```ruby
+ class CreatePageLoads < ActiveRecord::Migration[8.0]
+ def change
+ hypertable_options = {
+ time_column: 'created_at',
+ chunk_time_interval: '1 day',
+ compress_segmentby: 'path',
+ compress_orderby: 'created_at',
+ compress_after: '7 days',
+ drop_after: '30 days'
+ }
+
+ create_table :page_loads, id: false, primary_key: [:created_at, :user_agent, :path], hypertable: hypertable_options do |t|
+ t.timestamptz :created_at, null: false
+ t.string :user_agent
+ t.string :path
+ t.float :performance
+ end
+ end
+ end
+ ```
+
+ The `id` column is not included in the table. This is because TimescaleDB requires that any `UNIQUE` or `PRIMARY KEY`
+ indexes on the table include all partitioning columns. In this case, this is the time column. A new
+ Rails model includes a `PRIMARY KEY` index for id by default: either remove the column or make sure that the index
+ includes time as part of a "composite key."
+
+ For more information, check the Roby docs around [composite primary keys][rails-compostite-primary-keys].
+
+1. **Create a `PageLoad` model**
+
+ Create a new file called `/app/models/page_load.rb` and add the following code:
+
+ ```ruby
+ class PageLoad < ApplicationRecord
+ extend Timescaledb::ActsAsHypertable
+ include Timescaledb::ContinuousAggregatesHelper
+
+ acts_as_hypertable time_column: "created_at",
+ segment_by: "path",
+ value_column: "performance"
+
+ scope :chrome_users, -> { where("user_agent LIKE ?", "%Chrome%") }
+ scope :firefox_users, -> { where("user_agent LIKE ?", "%Firefox%") }
+ scope :safari_users, -> { where("user_agent LIKE ?", "%Safari%") }
+
+ scope :performance_stats, -> {
+ select("stats_agg(#{value_column}) as stats_agg")
+ }
+
+ scope :slow_requests, -> { where("performance > ?", 1.0) }
+ scope :fast_requests, -> { where("performance < ?", 0.1) }
+
+ continuous_aggregates scopes: [:performance_stats],
+ timeframes: [:minute, :hour, :day],
+ refresh_policy: {
+ minute: {
+ start_offset: '3 minute',
+ end_offset: '1 minute',
+ schedule_interval: '1 minute'
+ },
+ hour: {
+ start_offset: '3 hours',
+ end_offset: '1 hour',
+ schedule_interval: '1 minute'
+ },
+ day: {
+ start_offset: '3 day',
+ end_offset: '1 day',
+ schedule_interval: '1 minute'
+ }
+ }
+ end
+ ```
+
+1. **Run the migration**
+
+ ```bash
+ rails db:migrate
+ ```
+
+## Insert data your service
+
+The TimescaleDB gem provides efficient ways to insert data into hypertables. This section
+shows you how to ingest test data into your hypertable.
+
+1. **Create a controller to handle page loads**
+
+ Create a new file called `/app/controllers/application_controller.rb` and add the following code:
+
+ ```ruby
+ class ApplicationController < ActionController::Base
+ around_action :track_page_load
+
+ private
+
+ def track_page_load
+ start_time = Time.current
+ yield
+ end_time = Time.current
+
+ PageLoad.create(
+ path: request.path,
+ user_agent: request.user_agent,
+ performance: (end_time - start_time)
+ )
+ end
+ end
+ ```
+
+1. **Generate some test data**
+
+ Use `bin/console` to join a Rails console session and run the following code
+ to define some random page load access data:
+
+ ```ruby
+ def generate_sample_page_loads(total: 1000)
+ time = 1.month.ago
+ paths = %w[/ /about /contact /products /blog]
+ browsers = [
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:89.0) Gecko/20100101 Firefox/89.0",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
+ ]
+
+ total.times.map do
+ time = time + rand(60).seconds
+ {
+ path: paths.sample,
+ user_agent: browsers.sample,
+ performance: rand(0.1..2.0),
+ created_at: time,
+ updated_at: time
+ }
+ end
+ end
+ ```
+
+1. **Insert the generated data into your Tiger Cloud service**
+
+ ```bash
+ PageLoad.insert_all(generate_sample_page_loads, returning: false)
+ ```
+
+1. **Validate the test data in your Tiger Cloud service**
+
+ ```bash
+ PageLoad.count
+ PageLoad.first
+ ```
+
+## Reference
+
+This section lists the most common tasks you might perform with the TimescaleDB gem.
+
+### Query scopes
+
+The TimescaleDB gem provides several convenient scopes for querying your time-series data.
+
+
+- Built-in time-based scopes:
+
+ ```ruby
+ PageLoad.last_hour.count
+ PageLoad.today.count
+ PageLoad.this_week.count
+ PageLoad.this_month.count
+ ```
+
+- Browser-specific scopes:
+
+ ```ruby
+ PageLoad.chrome_users.last_hour.count
+ PageLoad.firefox_users.last_hour.count
+ PageLoad.safari_users.last_hour.count
+
+ PageLoad.slow_requests.last_hour.count
+ PageLoad.fast_requests.last_hour.count
+ ```
+
+- Query continuous aggregates:
+
+ This query fetches the average and standard deviation from the performance stats for the `/products` path over the last day.
+
+ ```ruby
+ PageLoad::PerformanceStatsPerMinute.last_hour
+ PageLoad::PerformanceStatsPerHour.last_day
+ PageLoad::PerformanceStatsPerDay.last_month
+
+ stats = PageLoad::PerformanceStatsPerHour.last_day.where(path: '/products').select("average(stats_agg) as average, stddev(stats_agg) as stddev").first
+ puts "Average: #{stats.average}"
+ puts "Standard Deviation: #{stats.stddev}"
+ ```
+
+### TimescaleDB features
+
+The TimescaleDB gem provides utility methods to access hypertable and chunk information. Every model that uses
+the `acts_as_hypertable` method has access to these methods.
+
+
+#### Access hypertable and chunk information
+
+- View chunk or hypertable information:
+
+ ```ruby
+ PageLoad.chunks.count
+ PageLoad.hypertable.detailed_size
+ ```
+
+- Compress/Decompress chunks:
+
+ ```ruby
+ PageLoad.chunks.uncompressed.first.compress! # Compress the first uncompressed chunk
+ PageLoad.chunks.compressed.first.decompress! # Decompress the oldest chunk
+ PageLoad.hypertable.compression_stats # View compression stats
+
+ ```
+
+#### Access hypertable stats
+
+You collect hypertable stats using methods that provide insights into your hypertable's structure, size, and compression
+status:
+
+- Get basic hypertable information:
+
+ ```ruby
+ hypertable = PageLoad.hypertable
+ hypertable.hypertable_name # The name of your hypertable
+ hypertable.schema_name # The schema where the hypertable is located
+ ```
+
+- Get detailed size information:
+
+ ```ruby
+ hypertable.detailed_size # Get detailed size information for the hypertable
+ hypertable.compression_stats # Get compression statistics
+ hypertable.chunks_detailed_size # Get chunk information
+ hypertable.approximate_row_count # Get approximate row count
+ hypertable.dimensions.map(&:column_name) # Get dimension information
+ hypertable.continuous_aggregates.map(&:view_name) # Get continuous aggregate view names
+ ```
+
+#### Continuous aggregates
+
+The `continuous_aggregates` method generates a class for each continuous aggregate.
+
+- Get all the continuous aggregate classes:
+
+ ```ruby
+ PageLoad.descendants # Get all continuous aggregate classes
+ ```
+
+- Manually refresh a continuous aggregate:
+
+ ```ruby
+ PageLoad.refresh_aggregates
+ ```
+
+- Create or drop a continuous aggregate:
+
+ Create or drop all the continuous aggregates in the proper order to build them hierarchically. See more about how it
+ works in this [blog post][ruby-blog-post].
+
+ ```ruby
+ PageLoad.create_continuous_aggregates
+ PageLoad.drop_continuous_aggregates
+ ```
+
+
+
+
+## Next steps
+
+Now that you have integrated the ruby gem into your app:
+
+* Learn more about the [TimescaleDB gem](https://github.com/timescale/timescaledb-ruby).
+* Check out the [official docs](https://timescale.github.io/timescaledb-ruby/).
+* Follow the [LTTB][LTTB], [Open AI long-term storage][open-ai-tutorial], and [candlesticks][candlesticks] tutorials.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the `psycopg2` library.
+
+ For more information, see the [psycopg2 documentation][psycopg2-docs].
+* Create a [Python virtual environment][virtual-env]. [](#)
+
+## Connect to TimescaleDB
+
+In this section, you create a connection to TimescaleDB using the `psycopg2`
+library. This library is one of the most popular Postgres libraries for
+Python. It allows you to execute raw SQL queries efficiently and safely, and
+prevents common attacks such as SQL injection.
+
+1. Import the psycogpg2 library:
+
+ ```python
+ import psycopg2
+ ```
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for `psycopg2`.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable as a
+ [libpq connection string][pg-libpq-string], using this format:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ ```
+
+ If you're using a hosted version of TimescaleDB, or generally require an SSL
+ connection, use this version instead:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname?sslmode=require"
+ ```
+
+ Alternatively you can specify each parameter in the connection string as follows
+
+ ```python
+ CONNECTION = "dbname=tsdb user=tsdbadmin password=secret host=host.com port=5432 sslmode=require"
+ ```
+
+
+
+ This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+
+
+1. Use the `psycopg2` [connect function][psycopg2-connect] to create a new
+ database session and create a new [cursor object][psycopg2-cursor] to
+ interact with the database.
+
+ In your `main` function, add these lines:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ with psycopg2.connect(CONNECTION) as conn:
+ cursor = conn.cursor()
+ # use the cursor to interact with your database
+ # cursor.execute("SELECT * FROM table")
+ ```
+
+ Alternatively, you can create a connection object and pass the object
+ around as needed, like opening a cursor to perform database operations:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ conn = psycopg2.connect(CONNECTION)
+ cursor = conn.cursor()
+ # use the cursor to interact with your database
+ cursor.execute("SELECT 'hello world'")
+ print(cursor.fetchone())
+ ```
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+ ```python
+ query_create_sensors_table = """CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type VARCHAR(50),
+ location VARCHAR(50)
+ );
+ """
+ ```
+
+1. Open a cursor, execute the query you created in the previous step, and
+ commit the query to make the changes persistent. Afterward, close the cursor
+ to clean up:
+
+ ```python
+ cursor = conn.cursor()
+ # see definition in Step 1
+ cursor.execute(query_create_sensors_table)
+ conn.commit()
+ cursor.close()
+ ```
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a string variable that contains the `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+ ```python
+ # create sensor data hypertable
+ query_create_sensordata_table = """CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id)
+ );
+ """
+ ```
+
+2. Formulate a `SELECT` statement that converts the `sensor_data` table to a
+ hypertable. You must specify the table name to convert to a hypertable, and
+ the name of the time column as the two arguments. For more information, see
+ the [`create_hypertable` docs][create-hypertable-docs]:
+
+ ```python
+ query_create_sensordata_hypertable = "SELECT create_hypertable('sensor_data', by_range('time'));"
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+3. Open a cursor with the connection, execute the statements from the previous
+ steps, commit your changes, and close the cursor:
+
+ ```python
+ cursor = conn.cursor()
+ cursor.execute(query_create_sensordata_table)
+ cursor.execute(query_create_sensordata_hypertable)
+ # commit changes to the database to make changes persistent
+ conn.commit()
+ cursor.close()
+ ```
+
+## Insert rows of data
+
+You can insert data into your hypertables in several different ways. In this
+section, you can use `psycopg2` with prepared statements, or you can use
+`pgcopy` for a faster insert.
+
+1. This example inserts a list of tuples, or relational data, called `sensors`,
+ into the relational table named `sensors`. Open a cursor with a connection
+ to the database, use prepared statements to formulate the `INSERT` SQL
+ statement, and then execute that statement:
+
+ ```python
+ sensors = [('a', 'floor'), ('a', 'ceiling'), ('b', 'floor'), ('b', 'ceiling')]
+ cursor = conn.cursor()
+ for sensor in sensors:
+ try:
+ cursor.execute("INSERT INTO sensors (type, location) VALUES (%s, %s);",
+ (sensor[0], sensor[1]))
+ except (Exception, psycopg2.Error) as error:
+ print(error.pgerror)
+ conn.commit()
+ ```
+
+1. [](#)Alternatively, you can pass variables to the `cursor.execute`
+ function and separate the formulation of the SQL statement, `SQL`, from the
+ data being passed with it into the prepared statement, `data`:
+
+ ```python
+ SQL = "INSERT INTO sensors (type, location) VALUES (%s, %s);"
+ sensors = [('a', 'floor'), ('a', 'ceiling'), ('b', 'floor'), ('b', 'ceiling')]
+ cursor = conn.cursor()
+ for sensor in sensors:
+ try:
+ data = (sensor[0], sensor[1])
+ cursor.execute(SQL, data)
+ except (Exception, psycopg2.Error) as error:
+ print(error.pgerror)
+ conn.commit()
+ ```
+
+If you choose to use `pgcopy` instead, install the `pgcopy` package
+[using pip][pgcopy-install], and then add this line to your list of
+`import` statements:
+
+```python
+from pgcopy import CopyManager
+```
+
+1. Generate some random sensor data using the `generate_series` function
+ provided by Postgres. This example inserts a total of 480 rows of data (4
+ readings, every 5 minutes, for 24 hours). In your application, this would be
+ the query that saves your time-series data into the hypertable:
+
+ ```python
+ # for sensors with ids 1-4
+ for id in range(1, 4, 1):
+ data = (id,)
+ # create random data
+ simulate_query = """SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ %s as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu;
+ """
+ cursor.execute(simulate_query, data)
+ values = cursor.fetchall()
+ ```
+
+1. Define the column names of the table you want to insert data into. This
+ example uses the `sensor_data` hypertable created earlier. This hypertable
+ consists of columns named `time`, `sensor_id`, `temperature` and `cpu`. The
+ column names are defined in a list of strings called `cols`:
+
+ ```python
+ cols = ['time', 'sensor_id', 'temperature', 'cpu']
+ ```
+
+1. Create an instance of the `pgcopy` CopyManager, `mgr`, and pass the
+ connection variable, hypertable name, and list of column names. Then use the
+ `copy` function of the CopyManager to insert the data into the database
+ quickly using `pgcopy`.
+
+ ```python
+ mgr = CopyManager(conn, 'sensor_data', cols)
+ mgr.copy(values)
+ ```
+
+1. Commit to persist changes:
+
+ ```python
+ conn.commit()
+ ```
+
+1. [](#)The full sample code to insert data into TimescaleDB using
+ `pgcopy`, using the example of sensor data from four sensors:
+
+ ```python
+ # insert using pgcopy
+ def fast_insert(conn):
+ cursor = conn.cursor()
+
+ # for sensors with ids 1-4
+ for id in range(1, 4, 1):
+ data = (id,)
+ # create random data
+ simulate_query = """SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ %s as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu;
+ """
+ cursor.execute(simulate_query, data)
+ values = cursor.fetchall()
+
+ # column names of the table you're inserting into
+ cols = ['time', 'sensor_id', 'temperature', 'cpu']
+
+ # create copy manager with the target table and insert
+ mgr = CopyManager(conn, 'sensor_data', cols)
+ mgr.copy(values)
+
+ # commit after all sensor data is inserted
+ # could also commit after each sensor insert is done
+ conn.commit()
+ ```
+
+1. [](#)You can also check if the insertion worked:
+
+ ```python
+ cursor.execute("SELECT * FROM sensor_data LIMIT 5;")
+ print(cursor.fetchall())
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database.
+
+The first procedure shows a simple `SELECT *` query. For more complex queries,
+you can use prepared statements to ensure queries are executed safely against
+the database.
+
+For more information about properly using placeholders in `psycopg2`, see the
+[basic module usage document][psycopg2-docs-basics].
+For more information about how to execute more complex queries in `psycopg2`,
+see the [psycopg2 documentation][psycopg2-docs-basics].
+
+### Execute a query
+
+1. Define the SQL query you'd like to run on the database. This example is a
+ simple `SELECT` statement querying each row from the previously created
+ `sensor_data` table.
+
+ ```python
+ query = "SELECT * FROM sensor_data;"
+ ```
+
+1. Open a cursor from the existing database connection, `conn`, and then execute
+ the query you defined:
+
+ ```python
+ cursor = conn.cursor()
+ query = "SELECT * FROM sensor_data;"
+ cursor.execute(query)
+ ```
+
+1. To access all resulting rows returned by your query, use one of `pyscopg2`'s
+ [results retrieval methods][results-retrieval-methods],
+ such as `fetchall()` or `fetchmany()`. This example prints the results of
+ the query, row by row. Note that the result of `fetchall()` is a list of
+ tuples, so you can handle them accordingly:
+
+ ```python
+ cursor = conn.cursor()
+ query = "SELECT * FROM sensor_data;"
+ cursor.execute(query)
+ for row in cursor.fetchall():
+ print(row)
+ cursor.close()
+ ```
+
+1. [](#)If you want a list of dictionaries instead, you can define the
+ cursor using [`DictCursor`][dictcursor-docs]:
+
+ ```python
+ cursor = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
+ ```
+
+ Using this cursor, `cursor.fetchall()` returns a list of dictionary-like objects.
+
+For more complex queries, you can use prepared statements to ensure queries are
+executed safely against the database.
+
+### Execute queries using prepared statements
+
+1. Write the query using prepared statements:
+
+ ```python
+ # query with placeholders
+ cursor = conn.cursor()
+ query = """
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = %s AND sensors.type = %s
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ """
+ location = "floor"
+ sensor_type = "a"
+ data = (location, sensor_type)
+ cursor.execute(query, data)
+ results = cursor.fetchall()
+ ```
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Node.js][node-install].
+* Install the Node.js package manager [npm][npm-install].
+
+## Connect to TimescaleDB
+
+In this section, you create a connection to TimescaleDB with a common Node.js
+ORM (object relational mapper) called [Sequelize][sequelize-info].
+
+1. At the command prompt, initialize a new Node.js app:
+
+ ```bash
+ npm init -y
+ ```
+
+ This creates a `package.json` file in your directory, which contains all
+ of the dependencies for your project. It looks something like this:
+
+ ```json
+ {
+ "name": "node-sample",
+ "version": "1.0.0",
+ "description": "",
+ "main": "index.js",
+ "scripts": {
+ "test": "echo \"Error: no test specified\" && exit 1"
+ },
+ "keywords": [],
+ "author": "",
+ "license": "ISC"
+ }
+ ```
+
+1. Install Express.js:
+
+ ```bash
+ npm install express
+ ```
+
+1. Create a simple web page to check the connection. Create a new file called
+ `index.js`, with this content:
+
+ ```java
+ const express = require('express')
+ const app = express()
+ const port = 3000;
+
+ app.use(express.json());
+ app.get('/', (req, res) => res.send('Hello World!'))
+ app.listen(port, () => console.log(`Example app listening at http://localhost:${port}`))
+ ```
+
+1. Test your connection by starting the application:
+
+ ```bash
+ node index.js
+ ```
+
+ In your web browser, navigate to `http://localhost:3000`. If the connection
+ is successful, it shows "Hello World!"
+
+1. Add Sequelize to your project:
+
+ ```bash
+ npm install sequelize sequelize-cli pg pg-hstore
+ ```
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for Sequelize.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+ ```java
+ 'postgres://:@:/'
+ ```
+
+1. Open the `index.js` file you created. Require Sequelize in the application,
+ and declare the connection string:
+
+ ```java
+ const Sequelize = require('sequelize')
+ const sequelize = new Sequelize('postgres://:@:/',
+ {
+ dialect: 'postgres',
+ protocol: 'postgres',
+ dialectOptions: {
+ ssl: {
+ require: true,
+ rejectUnauthorized: false
+ }
+ }
+ })
+ ```
+
+ Make sure you add the SSL settings in the `dialectOptions` sections. You
+ can't connect to TimescaleDB using SSL without them.
+
+1. You can test the connection by adding these lines to `index.js` after the
+ `app.get` statement:
+
+ ```java
+ sequelize.authenticate().then(() => {
+ console.log('Connection has been established successfully.');
+ }).catch(err => {
+ console.error('Unable to connect to the database:', err);
+ });
+ ```
+
+ Start the application on the command line:
+
+ ```bash
+ node index.js
+ ```
+
+ If the connection is successful, you'll get output like this:
+
+ ```bash
+ Example app listening at http://localhost:3000
+ Executing (default): SELECT 1+1 AS result
+ Connection has been established successfully.
+ ```
+
+## Create a relational table
+
+In this section, you create a relational table called `page_loads`.
+
+1. Use the Sequelize command line tool to create a table and model called `page_loads`:
+
+ ```bash
+ npx sequelize model:generate --name page_loads \
+ --attributes userAgent:string,time:date
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ New model was created at .
+ New migration was created at .
+ ```
+
+1. Edit the migration file so that it sets up a migration key:
+
+ ```java
+ 'use strict';
+ module.exports = {
+ up: async (queryInterface, Sequelize) => {
+ await queryInterface.createTable('page_loads', {
+ userAgent: {
+ primaryKey: true,
+ type: Sequelize.STRING
+ },
+ time: {
+ primaryKey: true,
+ type: Sequelize.DATE
+ }
+ });
+ },
+ down: async (queryInterface, Sequelize) => {
+ await queryInterface.dropTable('page_loads');
+ }
+ };
+ ```
+
+1. Migrate the change and make sure that it is reflected in the database:
+
+ ```bash
+ npx sequelize db:migrate
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ Loaded configuration file "config/config.json".
+ Using environment "development".
+ == 20200528195725-create-page-loads: migrating =======
+ == 20200528195725-create-page-loads: migrated (0.443s)
+ ```
+
+1. Create the `PageLoads` model in your code. In the `index.js` file, above the
+ `app.use` statement, add these lines:
+
+ ```java
+ let PageLoads = sequelize.define('page_loads', {
+ userAgent: {type: Sequelize.STRING, primaryKey: true },
+ time: {type: Sequelize.DATE, primaryKey: true }
+ }, { timestamps: false });
+ ```
+
+1. Instantiate a `PageLoads` object and save it to the database.
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a migration to modify the `page_loads` relational table, and change
+ it to a hypertable by first running the following command:
+
+ ```bash
+ npx sequelize migration:generate --name add_hypertable
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ migrations folder at already exists.
+ New migration was created at /20200601202912-add_hypertable.js .
+ ```
+
+1. In the `migrations` folder, there is now a new file. Open the
+ file, and add this content:
+
+ ```js
+ 'use strict';
+
+ module.exports = {
+ up: (queryInterface, Sequelize) => {
+ return queryInterface.sequelize.query("SELECT create_hypertable('page_loads', by_range('time'));");
+ },
+
+ down: (queryInterface, Sequelize) => {
+ }
+ };
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. At the command prompt, run the migration command:
+
+ ```bash
+ npx sequelize db:migrate
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ Loaded configuration file "config/config.json".
+ Using environment "development".
+ == 20200601202912-add_hypertable: migrating =======
+ == 20200601202912-add_hypertable: migrated (0.426s)
+ ```
+
+## Insert rows of data
+
+This section covers how to insert data into your hypertables.
+
+1. In the `index.js` file, modify the `/` route to get the `user-agent` from
+ the request object (`req`) and the current timestamp. Then, call the
+ `create` method on `PageLoads` model, supplying the user agent and timestamp
+ parameters. The `create` call executes an `INSERT` on the database:
+
+ ```java
+ app.get('/', async (req, res) => {
+ // get the user agent and current time
+ const userAgent = req.get('user-agent');
+ const time = new Date().getTime();
+
+ try {
+ // insert the record
+ await PageLoads.create({
+ userAgent, time
+ });
+
+ // send response
+ res.send('Inserted!');
+ } catch (e) {
+ console.log('Error inserting data', e)
+ }
+ })
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database. In this
+example, every time the page is reloaded, all information currently in the table
+is displayed.
+
+1. Modify the `/` route in the `index.js` file to call the Sequelize `findAll`
+ function and retrieve all data from the `page_loads` table using the
+ `PageLoads` model:
+
+ ```java
+ app.get('/', async (req, res) => {
+ // get the user agent and current time
+ const userAgent = req.get('user-agent');
+ const time = new Date().getTime();
+
+ try {
+ // insert the record
+ await PageLoads.create({
+ userAgent, time
+ });
+
+ // now display everything in the table
+ const messages = await PageLoads.findAll();
+ res.send(messages);
+ } catch (e) {
+ console.log('Error inserting data', e)
+ }
+ })
+ ```
+
+Now, when you reload the page, you should see all of the rows currently in the
+`page_loads` table.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+- Install [Go][golang-install].
+- Install the [PGX driver for Go][pgx-driver-github].
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to Tiger Cloud using the PGX driver.
+PGX is a toolkit designed to help Go developers work directly with Postgres.
+You can use it to help your Go application interact directly with TimescaleDB.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for PGX.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port number
+ * database name
+
+1. Compose your connection string variable as a
+ [libpq connection string][libpq-docs], using this format:
+
+ ```go
+ connStr := "postgres://username:password@host:port/dbname"
+ ```
+
+ If you're using a hosted version of TimescaleDB, or if you need an SSL
+ connection, use this format instead:
+
+ ```go
+ connStr := "postgres://username:password@host:port/dbname?sslmode=require"
+ ```
+
+1. [](#)You can check that you're connected to your database with this
+ hello world program:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5"
+ )
+
+ //connect to database using a single connection
+ func main() {
+ /***********************************************/
+ /* Single Connection to TimescaleDB/ PostgreSQL */
+ /***********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ conn, err := pgx.Connect(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer conn.Close(ctx)
+
+ //run a simple query to check our connection
+ var greeting string
+ err = conn.QueryRow(ctx, "select 'Hello, Timescale!'").Scan(&greeting)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println(greeting)
+ }
+
+ ```
+
+ If you'd like to specify your connection string as an environment variable,
+ you can use this syntax to access it in place of the `connStr` variable:
+
+ ```go
+ os.Getenv("DATABASE_CONNECTION_STRING")
+ ```
+
+Alternatively, you can connect to TimescaleDB using a connection pool.
+Connection pooling is useful to conserve computing resources, and can also
+result in faster database queries:
+
+1. To create a connection pool that can be used for concurrent connections to
+ your database, use the `pgxpool.New()` function instead of
+ `pgx.Connect()`. Also note that this script imports
+ `github.com/jackc/pgx/v5/pgxpool`, instead of `pgx/v5` which was used to
+ create a single connection:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ //run a simple query to check our connection
+ var greeting string
+ err = dbpool.QueryRow(ctx, "select 'Hello, Tiger Data (but concurrently)'").Scan(&greeting)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println(greeting)
+ }
+ ```
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string that contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns for ID,
+ type, and location:
+
+ ```go
+ queryCreateTable := `CREATE TABLE sensors (id SERIAL PRIMARY KEY, type VARCHAR(50), location VARCHAR(50));`
+ ```
+
+1. Execute the `CREATE TABLE` statement with the `Exec()` function on the
+ `dbpool` object, using the arguments of the current context and the
+ statement string you created:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Create relational table */
+ /********************************************/
+
+ //Create relational table called sensors
+ queryCreateTable := `CREATE TABLE sensors (id SERIAL PRIMARY KEY, type VARCHAR(50), location VARCHAR(50));`
+ _, err = dbpool.Exec(ctx, queryCreateTable)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to create SENSORS table: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully created relational table SENSORS")
+ }
+ ```
+
+## Generate a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a variable for the `CREATE TABLE SQL` statement for your hypertable.
+ Notice how the hypertable has the compulsory time column:
+
+ ```go
+ queryCreateTable := `CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id));
+ `
+ ```
+
+1. Formulate the `SELECT` statement to convert the table into a hypertable. You
+ must specify the table name to convert to a hypertable, and its time column
+ name as the second argument. For more information, see the
+ [`create_hypertable` docs][create-hypertable-docs]:
+
+ ```go
+ queryCreateHypertable := `SELECT create_hypertable('sensor_data', by_range('time'));`
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. Execute the `CREATE TABLE` statement and `SELECT` statement which converts
+ the table into a hypertable. You can do this by calling the `Exec()`
+ function on the `dbpool` object, using the arguments of the current context,
+ and the `queryCreateTable` and `queryCreateHypertable` statement strings:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Create Hypertable */
+ /********************************************/
+ // Create hypertable of time-series data called sensor_data
+ queryCreateTable := `CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id));
+ `
+
+ queryCreateHypertable := `SELECT create_hypertable('sensor_data', by_range('time'));`
+
+ //execute statement
+ _, err = dbpool.Exec(ctx, queryCreateTable+queryCreateHypertable)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to create the `sensor_data` hypertable: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully created hypertable `sensor_data`")
+ }
+ ```
+
+## Insert rows of data
+
+You can insert rows into your database in a couple of different
+ways. Each of these example inserts the data from the two arrays, `sensorTypes` and
+`sensorLocations`, into the relational table named `sensors`.
+
+The first example inserts a single row of data at a time. The second example
+inserts multiple rows of data. The third example uses batch inserts to speed up
+the process.
+
+1. Open a connection pool to the database, then use the prepared statements to
+ formulate an `INSERT` SQL statement, and execute it:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* INSERT into relational table */
+ /********************************************/
+ //Insert data into relational table
+
+ // Slices of sample data to insert
+ // observation i has type sensorTypes[i] and location sensorLocations[i]
+ sensorTypes := []string{"a", "a", "b", "b"}
+ sensorLocations := []string{"floor", "ceiling", "floor", "ceiling"}
+
+ for i := range sensorTypes {
+ //INSERT statement in SQL
+ queryInsertMetadata := `INSERT INTO sensors (type, location) VALUES ($1, $2);`
+
+ //Execute INSERT command
+ _, err := dbpool.Exec(ctx, queryInsertMetadata, sensorTypes[i], sensorLocations[i])
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert data into database: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Printf("Inserted sensor (%s, %s) into database \n", sensorTypes[i], sensorLocations[i])
+ }
+ fmt.Println("Successfully inserted all sensors into database")
+ }
+ ```
+
+Instead of inserting a single row of data at a time, you can use this procedure
+to insert multiple rows of data, instead:
+
+1. This example uses Postgres to generate some sample time-series to insert
+ into the `sensor_data` hypertable. Define the SQL statement to generate the
+ data, called `queryDataGeneration`. Then use the `.Query()` function to
+ execute the statement and return the sample data. The data returned by the
+ query is stored in `results`, a slice of structs, which is then used as a
+ source to insert data into the hypertable:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+ }
+ ```
+
+1. Formulate an SQL insert statement for the `sensor_data` hypertable:
+
+ ```go
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+ ```
+
+1. Execute the SQL statement for each sample in the results slice:
+
+ ```go
+ //Insert contents of results slice into TimescaleDB
+ for i := range results {
+ var r result
+ r = results[i]
+ _, err := dbpool.Exec(ctx, queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert sample into TimescaleDB %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+ }
+ fmt.Println("Successfully inserted samples into sensor_data hypertable")
+ ```
+
+1. [](#)This example `main.go` generates sample data and inserts it into
+ the `sensor_data` hypertable:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ /********************************************/
+ /* Connect using Connection Pool */
+ /********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Insert data into hypertable */
+ /********************************************/
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+
+ //Insert contents of results slice into TimescaleDB
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+
+ //Insert contents of results slice into TimescaleDB
+ for i := range results {
+ var r result
+ r = results[i]
+ _, err := dbpool.Exec(ctx, queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert sample into TimescaleDB %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+ }
+ fmt.Println("Successfully inserted samples into sensor_data hypertable")
+ }
+ ```
+
+Inserting multiple rows of data using this method executes as many `insert`
+statements as there are samples to be inserted. This can make ingestion of data
+slow. To speed up ingestion, you can batch insert data instead.
+
+Here's a sample pattern for how to do so, using the sample data you generated in
+the previous procedure. It uses the pgx `Batch` object:
+
+1. This example batch inserts data into the database:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5"
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ /********************************************/
+ /* Connect using Connection Pool */
+ /********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ /*fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }*/
+
+ //Insert contents of results slice into TimescaleDB
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+
+ /********************************************/
+ /* Batch Insert into TimescaleDB */
+ /********************************************/
+ //create batch
+ batch := &pgx.Batch{}
+ //load insert statements into batch queue
+ for i := range results {
+ var r result
+ r = results[i]
+ batch.Queue(queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+ batch.Queue("select count(*) from sensor_data")
+
+ //send batch to connection pool
+ br := dbpool.SendBatch(ctx, batch)
+ //execute statements in batch queue
+ _, err = br.Exec()
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute statement in batch queue %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully batch inserted data")
+
+ //Compare length of results slice to size of table
+ fmt.Printf("size of results: %d\n", len(results))
+ //check size of table for number of rows inserted
+ // result of last SELECT statement
+ var rowsInserted int
+ err = br.QueryRow().Scan(&rowsInserted)
+ fmt.Printf("size of table: %d\n", rowsInserted)
+
+ err = br.Close()
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to closer batch %v\n", err)
+ os.Exit(1)
+ }
+ }
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database.
+
+1. Define the SQL query you'd like to run on the database. This example uses a
+ SQL query that combines time-series and relational data. It returns the
+ average CPU values for every 5 minute interval, for sensors located on
+ location `ceiling` and of type `a`:
+
+ ```go
+ // Formulate query in SQL
+ // Note the use of prepared statement placeholders $1 and $2
+ queryTimebucketFiveMin := `
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = $1 AND sensors.type = $2
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ `
+ ```
+
+1. Use the `.Query()` function to execute the query string. Make sure you
+ specify the relevant placeholders:
+
+ ```go
+ //Execute query on TimescaleDB
+ rows, err := dbpool.Query(ctx, queryTimebucketFiveMin, "ceiling", "a")
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute query %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully executed query")
+ ```
+
+1. Access the rows returned by `.Query()`. Create a struct with fields
+ representing the columns that you expect to be returned, then use the
+ `rows.Next()` function to iterate through the rows returned and fill
+ `results` with the array of structs. This uses the `rows.Scan()` function,
+ passing in pointers to the fields that you want to scan for results.
+
+ This example prints out the results returned from the query, but you might
+ want to use those results for some other purpose. Once you've scanned
+ through all the rows returned you can then use the results array however you
+ like.
+
+ ```go
+ //Do something with the results of query
+ // Struct for results
+ type result2 struct {
+ Bucket time.Time
+ Avg float64
+ }
+
+ // Print rows returned and fill up results slice for later use
+ var results []result2
+ for rows.Next() {
+ var r result2
+ err = rows.Scan(&r.Bucket, &r.Avg)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ fmt.Printf("Time bucket: %s | Avg: %f\n", &r.Bucket, r.Avg)
+ }
+
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // use results here…
+ ```
+
+1. [](#)This example program runs a query, and accesses the results of
+ that query:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Execute a query */
+ /********************************************/
+
+ // Formulate query in SQL
+ // Note the use of prepared statement placeholders $1 and $2
+ queryTimebucketFiveMin := `
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = $1 AND sensors.type = $2
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ `
+
+ //Execute query on TimescaleDB
+ rows, err := dbpool.Query(ctx, queryTimebucketFiveMin, "ceiling", "a")
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute query %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully executed query")
+
+ //Do something with the results of query
+ // Struct for results
+ type result2 struct {
+ Bucket time.Time
+ Avg float64
+ }
+
+ // Print rows returned and fill up results slice for later use
+ var results []result2
+ for rows.Next() {
+ var r result2
+ err = rows.Scan(&r.Bucket, &r.Avg)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ fmt.Printf("Time bucket: %s | Avg: %f\n", &r.Bucket, r.Avg)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+ }
+ ```
+
+## Next steps
+
+Now that you're able to connect, read, and write to a TimescaleDB instance from
+your Go application, be sure to check out these advanced TimescaleDB tutorials:
+
+* Refer to the [pgx documentation][pgx-docs] for more information about pgx.
+* Get up and running with TimescaleDB with the [Getting Started][getting-started]
+ tutorial.
+* Want fast inserts on CSV data? Check out
+ [TimescaleDB parallel copy][parallel-copy-tool], a tool for fast inserts,
+ written in Go.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the [Java Development Kit (JDK)][jdk].
+* Install the [PostgreSQL JDBC driver][pg-jdbc-driver].
+
+All code in this quick start is for Java 16 and later. If you are working
+with older JDK versions, use legacy coding techniques.
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to your service using an application in
+a single file. You can use any of your favorite build tools, including `gradle`
+or `maven`.
+
+1. Create a directory containing a text file called `Main.java`, with this content:
+
+ ```java
+ package com.timescale.java;
+
+ public class Main {
+
+ public static void main(String... args) {
+ System.out.println("Hello, World!");
+ }
+ }
+ ```
+
+1. From the command line in the current directory, run the application:
+
+ ```bash
+ java Main.java
+ ```
+
+ If the command is successful, `Hello, World!` line output is printed
+ to your console.
+
+1. Import the PostgreSQL JDBC driver. If you are using a dependency manager,
+ include the [PostgreSQL JDBC Driver][pg-jdbc-driver-dependency] as a
+ dependency.
+
+1. Download the [JAR artifact of the JDBC Driver][pg-jdbc-driver-artifact] and
+ save it with the `Main.java` file.
+
+1. Import the `JDBC Driver` into the Java application and display a list of
+ available drivers for the check:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+
+ public class Main {
+
+ public static void main(String... args) {
+ DriverManager.drivers().forEach(System.out::println);
+ }
+ }
+ ```
+
+1. Run all the examples:
+
+ ```bash
+ java -cp *.jar Main.java
+ ```
+
+ If the command is successful, a string similar to
+ `org.postgresql.Driver@7f77e91b` is printed to your console. This means that you
+ are ready to connect to TimescaleDB from Java.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for JDBC.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+ ```java
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ ```
+
+ For more information about creating connection strings, see the [JDBC documentation][pg-jdbc-driver-conn-docs].
+
+
+
+ This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+
+ public class Main {
+
+ public static void main(String... args) throws SQLException {
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ var conn = DriverManager.getConnection(connUrl);
+ System.out.println(conn.getClientInfo());
+ }
+ }
+ ```
+
+1. Run the code:
+
+ ```bash
+ java -cp *.jar Main.java
+ ```
+
+ If the command is successful, a string similar to
+ `{ApplicationName=PostgreSQL JDBC Driver}` is printed to your console.
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+ ```sql
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ );
+ ```
+
+1. Create a statement, execute the query you created in the previous step, and
+ check that the table was created successfully:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+
+ public class Main {
+
+ public static void main(String... args) throws SQLException {
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ var conn = DriverManager.getConnection(connUrl);
+
+ var createSensorTableQuery = """
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ )
+ """;
+ try (var stmt = conn.createStatement()) {
+ stmt.execute(createSensorTableQuery);
+ }
+
+ var showAllTablesQuery = "SELECT tablename FROM pg_catalog.pg_tables WHERE schemaname = 'public'";
+ try (var stmt = conn.createStatement();
+ var rs = stmt.executeQuery(showAllTablesQuery)) {
+ System.out.println("Tables in the current database: ");
+ while (rs.next()) {
+ System.out.println(rs.getString("tablename"));
+ }
+ }
+ }
+ }
+ ```
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+ ```sql
+ CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER REFERENCES sensors (id),
+ value DOUBLE PRECISION
+ );
+ ```
+
+1. Create a statement, execute the query you created in the previous step:
+
+ ```sql
+ SELECT create_hypertable('sensor_data', by_range('time'));
+ ```
+
+
+
+ The `by_range` and `by_hash` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. Execute the two statements you created, and commit your changes to the
+ database:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.Connection;
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+ import java.util.List;
+
+ public class Main {
+
+ public static void main(String... args) {
+ final var connUrl = "jdbc:postgresql://:/?user=&password=";
+ try (var conn = DriverManager.getConnection(connUrl)) {
+ createSchema(conn);
+ insertData(conn);
+ } catch (SQLException ex) {
+ System.err.println(ex.getMessage());
+ }
+ }
+
+ private static void createSchema(final Connection conn) throws SQLException {
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("""
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ )
+ """);
+ }
+
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("""
+ CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER REFERENCES sensors (id),
+ value DOUBLE PRECISION
+ )
+ """);
+ }
+
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("SELECT create_hypertable('sensor_data', by_range('time'))");
+ }
+ }
+ }
+ ```
+
+## Insert data
+
+You can insert data into your hypertables in several different ways. In this
+section, you can insert single rows, or insert by batches of rows.
+
+1. Open a connection to the database, use prepared statements to formulate the
+ `INSERT` SQL statement, then execute the statement:
+
+ ```java
+ final List
+
+After you have completed the installation, connect to your instance and
+configure your database. For information about connecting to the instance, see
+the AWS [accessing instance documentation][aws-connect]. The easiest way to
+configure your database is to run the `timescaledb-tune` script, which is included
+with the `timescaledb-tools` package. For more information, see the
+[configuration][config] section.
+
+After running the `timescaledb-tune` script, you need to restart the Postgres
+service for the configuration changes to take effect. To restart the service,
+run `sudo systemctl restart postgresql.service`.
+
+## Set up the TimescaleDB extension
+
+When you have Postgres and TimescaleDB installed, connect to your instance and
+set up the TimescaleDB extension.
+
+1. On your instance, at the command prompt, connect to the Postgres
+ instance as the `postgres` superuser:
+
+1. At the prompt, create an empty database. For example, to create a database
+ called `tsdb`:
+
+1. Connect to the database you created:
+
+1. Add the TimescaleDB extension:
+
+You can check that the TimescaleDB extension is installed by using the `\dx`
+command at the command prompt. It looks like this:
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/installation-macos/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo -u postgres psql
+```
+
+Example 2 (sql):
+```sql
+CREATE database tsdb;
+```
+
+Example 3 (sql):
+```sql
+\c tsdb
+```
+
+Example 4 (sql):
+```sql
+CREATE EXTENSION IF NOT EXISTS timescaledb;
+```
+
+---
+
+## About upgrades
+
+**URL:** llms-txt#about-upgrades
+
+**Contents:**
+- Plan your upgrade
+- Check your version
+
+A major upgrade is when you upgrade from one major version of TimescaleDB, to
+the next major version. For example, when you upgrade from TimescaleDB 1
+to TimescaleDB 2.
+
+A minor upgrade is when you upgrade within your current major version of
+TimescaleDB. For example, when you upgrade from TimescaleDB 2.5 to
+TimescaleDB 2.6.
+
+If you originally installed TimescaleDB using Docker, you can upgrade from
+within the Docker container. For more information, and instructions, see the
+[Upgrading with Docker section][upgrade-docker].
+
+When you upgrade the `timescaledb` extension, the experimental schema is removed
+by default. To use experimental features after an upgrade, you need to add the
+experimental schema again.
+
+Tiger Cloud is a fully managed service with automatic backup and restore, high
+availability with replication, seamless scaling and resizing, and much more. You
+can try Tiger Cloud free for thirty days.
+
+- Install the Postgres client tools on your migration machine. This includes `psql`, and `pg_dump`.
+- Read [the release notes][relnotes] for the version of TimescaleDB that you are upgrading to.
+- [Perform a backup][backup] of your database. While TimescaleDB
+ upgrades are performed in-place, upgrading is an intrusive operation. Always
+ make sure you have a backup on hand, and that the backup is readable in the
+ case of disaster.
+
+If you use the TimescaleDB Toolkit, ensure the `timescaledb_toolkit` extension is on
+version 1.6.0, then upgrade the `timescaledb` extension. If required, you
+can then later upgrade the `timescaledb_toolkit` extension to the most
+recent version.
+
+## Check your version
+
+You can check which version of TimescaleDB you are running, at the psql command
+prompt. Use this to check which version you are running before you begin your
+upgrade, and again after your upgrade is complete:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/upgrades/upgrade-pg/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+\dx timescaledb
+
+ Name | Version | Schema | Description
+-------------+---------+------------+---------------------------------------------------------------------
+ timescaledb | x.y.z | public | Enables scalable inserts and complex queries for time-series data
+(1 row)
+```
+
+---
+
+## Install TimescaleDB on Linux
+
+**URL:** llms-txt#install-timescaledb-on-linux
+
+**Contents:**
+- Install and configure TimescaleDB on Postgres
+- Add the TimescaleDB extension to your database
+- Supported platforms
+- Where to next
+
+TimescaleDB is a [Postgres extension](https://www.postgresql.org/docs/current/external-extensions.html) for
+time series and demanding workloads that ingest and query high volumes of data.
+
+This section shows you how to:
+
+* [Install and configure TimescaleDB on Postgres](#install-and-configure-timescaledb-on-postgresql) - set up
+ a self-hosted Postgres instance to efficiently run TimescaleDB.
+* [Add the TimescaleDB extension to your database](#add-the-timescaledb-extension-to-your-database) - enable TimescaleDB
+ features and performance improvements on a database.
+
+The following instructions are for development and testing installations. For a production environment, we strongly recommend
+that you implement the following, many of which you can achieve using Postgres tooling:
+
+- Incremental backup and database snapshots, with efficient point-in-time recovery.
+- High availability replication, ideally with nodes across multiple availability zones.
+- Automatic failure detection with fast restarts, for both non-replicated and replicated deployments.
+- Asynchronous replicas for scaling reads when needed.
+- Connection poolers for scaling client connections.
+- Zero-down-time minor version and extension upgrades.
+- Forking workflows for major version upgrades and other feature testing.
+- Monitoring and observability.
+
+Deploying for production? With a Tiger Cloud service we tune your database for performance and handle scalability, high
+availability, backups, and management, so you can relax.
+
+## Install and configure TimescaleDB on Postgres
+
+This section shows you how to install the latest version of Postgres and
+TimescaleDB on a [supported platform](#supported-platforms) using the packages supplied by Tiger Data.
+
+If you have previously installed Postgres without a package manager, you may encounter errors
+following these install instructions. Best practice is to fully remove any existing Postgres
+installations before you begin.
+
+To keep your current Postgres installation, [Install from source][install-from-source].
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+1. **Add the TimescaleDB package**
+
+1. **Install the TimescaleDB GPG key**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To install a specific TimescaleDB [release][releases-page], set the version. For example:
+
+`sudo apt-get install timescaledb-2-postgresql-14='2.6.0*' timescaledb-2-loader-postgresql-14='2.6.0*'`
+
+Older versions of TimescaleDB may not support all the OS versions listed on this page.
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+By default, this script is included with the `timescaledb-tools` package when you install TimescaleDB. Use the prompts to tune your development or production environment. For more information on manual configuration, see [Configuration][config]. If you have an issue, run `sudo apt install timescaledb-tools`.
+
+1. **Restart Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Run the Postgres package setup script**
+
+1. **Install the TimescaleDB GPG key**
+
+For Ubuntu 21.10 and earlier use the following command:
+
+`wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo apt-key add -`
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To install a specific TimescaleDB [release][releases-page], set the version. For example:
+
+`sudo apt-get install timescaledb-2-postgresql-14='2.6.0*' timescaledb-2-loader-postgresql-14='2.6.0*'`
+
+Older versions of TimescaleDB may not support all the OS versions listed on this page.
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+By default, this script is included with the `timescaledb-tools` package when you install TimescaleDB. Use the prompts to tune your development or production environment. For more information on manual configuration, see [Configuration][config]. If you have an issue, run `sudo apt install timescaledb-tools`.
+
+1. **Restart Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Update your local repository list**
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+
+
+
+
+On Red Hat Enterprise Linux 8 and later, disable the built-in Postgres module:
+
+`sudo dnf -qy module disable postgresql`
+
+
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+Tiger Data supports Rocky Linux 8 and 9 on amd64 only.
+
+1. **Update your local repository list**
+
+1. **Install the latest Postgres packages**
+
+1. **Add the TimescaleDB repository**
+
+1. **Disable the built-in PostgreSQL module**
+
+This is for Rocky Linux 9 only.
+
+1. **Install TimescaleDB**
+
+To avoid errors, **do not** install TimescaleDB Apache 2 Edition and TimescaleDB Community Edition at the same time.
+
+1. **Initialize the Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB.
+ For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are now in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+ArchLinux packages are built by the community.
+
+1. **Install the latest Postgres and TimescaleDB packages**
+
+1. **Initalize your Postgres instance**
+
+1. **Tune your Postgres instance for TimescaleDB**
+
+This script is included with the `timescaledb-tools` package when you install TimescaleDB. For more information, see [configuration][config].
+
+1. **Enable and start Postgres**
+
+1. **Log in to Postgres as `postgres`**
+
+You are in the psql shell.
+
+1. **Set the password for `postgres`**
+
+When you have set the password, type `\q` to exit psql.
+
+Job jobbed, you have installed Postgres and TimescaleDB.
+
+## Add the TimescaleDB extension to your database
+
+For improved performance, you enable TimescaleDB on each database on your self-hosted Postgres instance.
+This section shows you how to enable TimescaleDB for a new database in Postgres using `psql` from the command line.
+
+1. **Connect to a database on your Postgres instance**
+
+In Postgres, the default user and database are both `postgres`. To use a
+ different database, set `` to the name of that database:
+
+1. **Add TimescaleDB to the database**
+
+1. **Check that TimescaleDB is installed**
+
+You see the list of installed extensions:
+
+Press q to exit the list of extensions.
+
+And that is it! You have TimescaleDB running on a database on a self-hosted instance of Postgres.
+
+## Supported platforms
+
+You can deploy TimescaleDB on the following systems:
+
+| Operation system | Version |
+|---------------------------------|-----------------------------------------------------------------------|
+| Debian | 13 Trixe, 12 Bookworm, 11 Bullseye |
+| Ubuntu | 24.04 Noble Numbat, 22.04 LTS Jammy Jellyfish |
+| Red Hat Enterprise | Linux 9, Linux 8 |
+| Fedora | Fedora 35, Fedora 34, Fedora 33 |
+| Rocky Linux | Rocky Linux 9 (x86_64), Rocky Linux 8 |
+| ArchLinux (community-supported) | Check the [available packages][archlinux-packages] |
+
+What next? [Try the key features offered by Tiger Data][try-timescale-features], see the [tutorials][tutorials],
+interact with the data in your Tiger Cloud service using [your favorite programming language][connect-with-code], integrate
+your Tiger Cloud service with a range of [third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive
+into the [API reference][use-the-api].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/install/self-hosted/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+sudo apt install gnupg postgresql-common apt-transport-https lsb-release wget
+```
+
+Example 2 (bash):
+```bash
+sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
+```
+
+Example 3 (bash):
+```bash
+echo "deb https://packagecloud.io/timescale/timescaledb/debian/ $(lsb_release -c -s) main" | sudo tee /etc/apt/sources.list.d/timescaledb.list
+```
+
+Example 4 (bash):
+```bash
+wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/timescaledb.gpg
+```
+
+---
+
+## Set up multi-node on self-hosted TimescaleDB
+
+**URL:** llms-txt#set-up-multi-node-on-self-hosted-timescaledb
+
+**Contents:**
+- Set up multi-node on self-hosted TimescaleDB
+ - Setting up multi-node on self-hosted TimescaleDB
+
+[Multi-node support is sunsetted][multi-node-deprecation].
+
+TimescaleDB v2.13 is the last release that includes multi-node support for Postgres
+versions 13, 14, and 15.
+
+To set up multi-node on a self-hosted TimescaleDB instance, you need:
+
+* A Postgres instance to act as an access node (AN)
+* One or more Postgres instances to act as data nodes (DN)
+* TimescaleDB [installed][install] and [set up][setup] on all nodes
+* Access to a superuser role, such as `postgres`, on all nodes
+
+The access and data nodes must begin as individual TimescaleDB instances.
+They should be hosts with a running Postgres server and a loaded TimescaleDB
+extension. For more information about installing self-hosted TimescaleDB
+instances, see the [installation instructions][install]. Additionally, you
+can configure [high availability with multi-node][multi-node-ha] to
+increase redundancy and resilience.
+
+The multi-node TimescaleDB architecture consists of an access node (AN) which
+stores metadata for the distributed hypertable and performs query planning
+across the cluster, and a set of data nodes (DNs) which store subsets of the
+distributed hypertable dataset and execute queries locally. For more information
+about the multi-node architecture, see [about multi-node][about-multi-node].
+
+If you intend to use continuous aggregates in your multi-node environment, check
+the additional considerations in the [continuous aggregates][caggs] section.
+
+## Set up multi-node on self-hosted TimescaleDB
+
+When you have installed TimescaleDB on the access node and as many data nodes as
+you require, you can set up multi-node and create a distributed hypertable.
+
+Before you begin, make sure you have considered what partitioning method you
+want to use for your multi-node cluster. For more information about multi-node
+and architecture, see the
+[About multi-node section](https://docs.tigerdata.com/self-hosted/latest/multinode-timescaledb/about-multinode/).
+
+### Setting up multi-node on self-hosted TimescaleDB
+
+1. On the access node (AN), run this command and provide the hostname of the
+ first data node (DN1) you want to add:
+
+1. Repeat for all other data nodes:
+
+1. On the access node, create the distributed hypertable with your chosen
+ partitioning. In this example, the distributed hypertable is called
+ `example`, and it is partitioned on `time` and `location`:
+
+1. Insert some data into the hypertable. For example:
+
+When you have set up your multi-node installation, you can configure your
+cluster. For more information, see the [configuration section][configuration].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/multinode-timescaledb/multinode-auth/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT add_data_node('dn1', 'dn1.example.com')
+```
+
+Example 2 (sql):
+```sql
+SELECT add_data_node('dn2', 'dn2.example.com')
+ SELECT add_data_node('dn3', 'dn3.example.com')
+```
+
+Example 3 (sql):
+```sql
+SELECT create_distributed_hypertable('example', 'time', 'location');
+```
+
+Example 4 (sql):
+```sql
+INSERT INTO example VALUES ('2020-12-14 13:45', 1, '1.2.3.4');
+```
+
+---
+
+## TimescaleDB tuning tool
+
+**URL:** llms-txt#timescaledb-tuning-tool
+
+To help make configuring TimescaleDB a little easier, you can use the [`timescaledb-tune`][tstune]
+tool. This tool handles setting the most common parameters to good values based
+on your system. It accounts for memory, CPU, and Postgres version.
+`timescaledb-tune` is packaged with the TimescaleDB binary releases as a
+dependency, so if you installed TimescaleDB from a binary release (including
+Docker), you should already have access to the tool. Alternatively, you can use
+the `go install` command to install it:
+
+The `timescaledb-tune` tool reads your system's `postgresql.conf` file and
+offers interactive suggestions for your settings. Here is an example of the tool
+running:
+
+When you have answered the questions, the changes are written to your
+`postgresql.conf` and take effect when you next restart.
+
+If you are starting on a fresh instance and don't want to approve each group of
+changes, you can automatically accept and append the suggestions to the end of
+your `postgresql.conf` by using some additional flags when you run the tool:
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/configuration/postgres-config/ =====
+
+**Examples:**
+
+Example 1 (bash):
+```bash
+go install github.com/timescale/timescaledb-tune/cmd/timescaledb-tune@latest
+```
+
+Example 2 (bash):
+```bash
+Using postgresql.conf at this path:
+/usr/local/var/postgres/postgresql.conf
+
+Is this correct? [(y)es/(n)o]: y
+Writing backup to:
+/var/folders/cr/example/T/timescaledb_tune.backup202101071520
+
+shared_preload_libraries needs to be updated
+Current:
+#shared_preload_libraries = 'timescaledb'
+Recommended:
+shared_preload_libraries = 'timescaledb'
+Is this okay? [(y)es/(n)o]: y
+success: shared_preload_libraries will be updated
+
+Tune memory/parallelism/WAL and other settings? [(y)es/(n)o]: y
+Recommendations based on 8.00 GB of available memory and 4 CPUs for PostgreSQL 12
+
+Memory settings recommendations
+Current:
+shared_buffers = 128MB
+#effective_cache_size = 4GB
+#maintenance_work_mem = 64MB
+#work_mem = 4MB
+Recommended:
+shared_buffers = 2GB
+effective_cache_size = 6GB
+maintenance_work_mem = 1GB
+work_mem = 26214kB
+Is this okay? [(y)es/(s)kip/(q)uit]:
+```
+
+Example 3 (bash):
+```bash
+timescaledb-tune --quiet --yes --dry-run >> /path/to/postgresql.conf
+```
+
+---
+
+## Self-hosted TimescaleDB
+
+**URL:** llms-txt#self-hosted-timescaledb
+
+TimescaleDB is an extension for Postgres that enables time-series workloads,
+increasing ingest, query, storage and analytics performance.
+
+Best practice is to run TimescaleDB in a [Tiger Cloud service](https://console.cloud.timescale.com/signup), but if you want to
+self-host you can run TimescaleDB yourself.
+Deploy a Tiger Cloud service. We tune your database for performance and handle scalability, high availability, backups and management so you can relax.
+
+Self-hosted TimescaleDB is community supported. For additional help
+check out the friendly [Tiger Data community][community].
+
+If you'd prefer to pay for support then check out our [self-managed support][support].
+
+===== PAGE: https://docs.tigerdata.com/self-hosted/configuration/about-configuration/ =====
+
+---
+
+## Install or upgrade of TimescaleDB Toolkit fails
+
+**URL:** llms-txt#install-or-upgrade-of-timescaledb-toolkit-fails
+
+**Contents:**
+ - Troubleshooting TimescaleDB Toolkit setup
+
+
+
+In some cases, when you create the TimescaleDB Toolkit extension, or upgrade it
+with the `ALTER EXTENSION timescaledb_toolkit UPDATE` command, it might fail
+with the above error.
+
+This occurs if the list of available extensions does not include the version you
+are trying to upgrade to, and it can occur if the package was not installed
+correctly in the first place. To correct the problem, install the upgrade
+package, restart Postgres, verify the version, and then attempt the update
+again.
+
+### Troubleshooting TimescaleDB Toolkit setup
+
+1. If you're installing Toolkit from a package, check your package manager's
+ local repository list. Make sure the TimescaleDB repository is available and
+ contains Toolkit. For instructions on adding the TimescaleDB repository, see
+ the installation guides:
+ * [Linux installation guide][linux-install]
+1. Update your local repository list with `apt update` or `yum update`.
+1. Restart your Postgres service.
+1. Check that the right version of Toolkit is among your available extensions:
+
+The result should look like this:
+
+1. Retry `CREATE EXTENSION` or `ALTER EXTENSION`.
+
+===== PAGE: https://docs.tigerdata.com/_troubleshooting/self-hosted/pg_dump-permission-denied/ =====
+
+**Examples:**
+
+Example 1 (sql):
+```sql
+SELECT * FROM pg_available_extensions
+ WHERE name = 'timescaledb_toolkit';
+```
+
+Example 2 (bash):
+```bash
+-[ RECORD 1 ]-----+--------------------------------------------------------------------------------------
+ name | timescaledb_toolkit
+ default_version | 1.6.0
+ installed_version | 1.6.0
+ comment | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities
+```
+
+---
diff --git a/skills/timescaledb/references/llms-full.md b/skills/timescaledb/references/llms-full.md
new file mode 100644
index 0000000..a926860
--- /dev/null
+++ b/skills/timescaledb/references/llms-full.md
@@ -0,0 +1,79540 @@
+===== PAGE: https://docs.tigerdata.com/getting-started/try-key-features-timescale-products/ =====
+
+# Try the key features in Tiger Data products
+
+
+
+Tiger Cloud offers managed database services that provide a stable and reliable environment for your
+applications.
+
+Each Tiger Cloud service is a single optimised Postgres instance extended with innovations such as TimescaleDB in the database
+engine, in a cloud infrastructure that delivers speed without sacrifice. A radically faster Postgres for transactional,
+analytical, and agentic workloads at scale.
+
+Tiger Cloud scales Postgres to ingest and query vast amounts of live data. Tiger Cloud
+provides a range of features and optimizations that supercharge your queries while keeping the
+costs down. For example:
+* The hypercore row-columnar engine in TimescaleDB makes queries up to 350x faster, ingests 44% faster, and reduces
+ storage by 90%.
+* Tiered storage in Tiger Cloud seamlessly moves your data from high performance storage for frequently accessed data to
+ low cost bottomless storage for rarely accessed data.
+
+The following figure shows how TimescaleDB optimizes your data for superfast real-time analytics:
+
+
+
+This page shows you how to rapidly implement the features in Tiger Cloud that enable you to
+ingest and query data faster while keeping the costs low.
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+## Optimize time-series data in hypertables with hypercore
+
+Time-series data represents the way a system, process, or behavior changes over time. Hypertables are Postgres tables
+that help you improve insert and query performance by automatically partitioning your data by time. Each hypertable
+is made up of child tables called chunks. Each chunk is assigned a range of time, and only
+contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and runs the query on
+it, instead of going through the entire table. You can also tune hypertables to increase performance even more.
+
+
+
+[Hypercore][hypercore] is the hybrid row-columnar storage engine in TimescaleDB used by hypertables. Traditional
+databases force a trade-off between fast inserts (row-based storage) and efficient analytics
+(columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing
+transactional capabilities.
+
+Hypercore dynamically stores data in the most efficient format for its lifecycle:
+
+* **Row-based storage for recent data**: the most recent chunk (and possibly more) is always stored in the rowstore,
+ ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a
+ writethrough for inserts and updates to columnar storage.
+* **Columnar storage for analytical performance**: chunks are automatically compressed into the columnstore, optimizing
+ storage efficiency and accelerating analytical queries.
+
+Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a
+flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
+
+Hypertables exist alongside regular Postgres tables.
+You use regular Postgres tables for relational data, and interact with hypertables
+and regular Postgres tables in the same way.
+
+This section shows you how to create regular tables and hypertables, and import
+relational and time-series data from external files.
+
+1. **Import some time-series data into hypertables**
+
+ 1. Unzip [crypto_sample.zip](https://assets.timescale.com/docs/downloads/candlestick/crypto_sample.zip) to a ``.
+
+ This test dataset contains:
+ - Second-by-second data for the most-traded crypto-assets. This time-series data is best suited for
+ optimization in a [hypertable][hypertables-section].
+ - A list of asset symbols and company names. This is best suited for a regular relational table.
+
+ To import up to 100 GB of data directly from your current Postgres-based database,
+ [migrate with downtime][migrate-with-downtime] using native Postgres tooling. To seamlessly import 100GB-10TB+
+ of data, use the [live migration][migrate-live] tooling supplied by Tiger Data. To add data from non-Postgres data
+ sources, see [Import and ingest data][data-ingest].
+
+ 1. Upload data into a hypertable:
+
+ To more fully understand how to create a hypertable, how hypertables work, and how to optimize them for
+ performance by tuning chunk intervals and enabling chunk skipping, see
+ [the hypertables documentation][hypertables-section].
+
+
+
+
+
+ The Tiger Cloud Console data upload creates hypertables and relational tables from the data you are uploading:
+ 1. In [Tiger Cloud Console][portal-ops-mode], select the service to add data to, then click `Actions` > `Import data` > `Upload .CSV`.
+ 1. Click to browse, or drag and drop `/tutorial_sample_tick.csv` to upload.
+ 1. Leave the default settings for the delimiter, skipping the header, and creating a new table.
+ 1. In `Table`, provide `crypto_ticks` as the new table name.
+ 1. Enable `hypertable partition` for the `time` column and click `Process CSV file`.
+
+ The upload wizard creates a hypertable containing the data from the CSV file.
+ 1. When the data is uploaded, close `Upload .CSV`.
+
+ If you want to have a quick look at your data, press `Run` .
+ 1. Repeat the process with `/tutorial_sample_assets.csv` and rename to `crypto_assets`.
+
+ There is no time-series data in this table, so you don't see the `hypertable partition` option.
+
+
+
+
+
+ 1. In Terminal, navigate to `` and connect to your service.
+ ```bash
+ psql -d "postgres://:@:/"
+ ```
+ You use your [connection details][connection-info] to fill in this Postgres connection string.
+
+ 2. Create tables for the data to import:
+
+ - For the time-series data:
+
+ 1. In your sql client, create a hypertable:
+
+ Create a [hypertable][hypertables-section] for your time-series data using [CREATE TABLE][hypertable-create-table].
+ For [efficient queries][secondary-indexes], remember to `segmentby` the column you will
+ use most often to filter your data. For example:
+
+ ```sql
+ CREATE TABLE crypto_ticks (
+ "time" TIMESTAMPTZ,
+ symbol TEXT,
+ price DOUBLE PRECISION,
+ day_volume NUMERIC
+ ) WITH (
+ tsdb.hypertable,
+ tsdb.partition_column='time',
+ tsdb.segmentby = 'symbol'
+ );
+ ```
+
+ If you are self-hosting TimescaleDB v2.19.3 and below, create a [Postgres relational table][pg-create-table],
+then convert it using [create_hypertable][create_hypertable]. You then enable hypercore with a call
+to [ALTER TABLE][alter_table_hypercore].
+
+ - For the relational data:
+
+ In your sql client, create a normal Postgres table:
+ ```sql
+ CREATE TABLE crypto_assets (
+ symbol TEXT NOT NULL,
+ name TEXT NOT NULL
+ );
+ ```
+ 1. Speed up data ingestion:
+
+ When you set `timescaledb.enable_direct_compress_copy` your data gets compressed in memory during ingestion with `COPY` statements.
+By writing the compressed batches immediately in the columnstore, the IO footprint is significantly lower.
+Also, the [columnstore policy][add_columnstore_policy] you set is less important, `INSERT` already produces compressed chunks.
+
+
+
+Please note that this feature is a **tech preview** and not production-ready.
+Using this feature could lead to regressed query performance and/or storage ratio, if the ingested batches are not
+correctly ordered or are of too high cardinality.
+
+
+
+To enable in-memory data compression during ingestion:
+
+```sql
+SET timescaledb.enable_direct_compress_copy=on;
+```
+
+**Important facts**
+- High cardinality use cases do not produce good batches and lead to degreaded query performance.
+- The columnstore is optimized to store 1000 records per batch, which is the optimal format for ingestion per segment by.
+- WAL records are written for the compressed batches rather than the individual tuples.
+- Currently only `COPY` is support, `INSERT` will eventually follow.
+- Best results are achieved for batch ingestion with 1000 records or more, upper boundary is 10.000 records.
+- Continous Aggregates are **not** supported at the moment.
+
+ 3. Upload the dataset to your service:
+
+ ```sql
+ \COPY crypto_ticks from './tutorial_sample_tick.csv' DELIMITER ',' CSV HEADER;
+ ```
+
+ ```sql
+ \COPY crypto_assets from './tutorial_sample_assets.csv' DELIMITER ',' CSV HEADER;
+ ```
+
+
+
+
+
+1. **Have a quick look at your data**
+
+ You query hypertables in exactly the same way as you would a relational Postgres table.
+ Use one of the following SQL editors to run a query and see the data you uploaded:
+ - **Data mode**: write queries, visualize data, and share your results in [Tiger Cloud Console][portal-data-mode] for all your Tiger Cloud services. This feature is not available under the Free pricing plan.
+ - **SQL editor**: write, fix, and organize SQL faster and more accurately in [Tiger Cloud Console][portal-ops-mode] for a Tiger Cloud service.
+ - **psql**: easily run queries on your Tiger Cloud services or self-hosted TimescaleDB deployment from Terminal.
+
+
+
+## Enhance query performance for analytics
+
+Hypercore is the TimescaleDB hybrid row-columnar storage engine, designed specifically for real-time
+analytics and
+powered by time-series data. The advantage of hypercore is its ability to seamlessly switch between row-oriented and
+column-oriented storage. This flexibility enables TimescaleDB to deliver the best of both worlds, solving the key
+challenges in real-time analytics.
+
+
+
+When TimescaleDB converts chunks from the rowstore to the columnstore, multiple records are grouped into a single row.
+The columns of this row hold an array-like structure that stores all the data. Because a single row takes up less disk
+space, you can reduce your chunk size by up to 98%, and can also speed up your queries. This helps you save on storage costs,
+and keeps your queries operating at lightning speed.
+
+hypercore is enabled by default when you call [CREATE TABLE][hypertable-create-table]. Best practice is to compress
+data that is no longer needed for highest performance queries, but is still accessed regularly in the columnstore.
+For example, yesterday's market data.
+
+1. **Add a policy to convert chunks to the columnstore at a specific time interval**
+
+ For example, yesterday's data:
+ ``` sql
+ CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '1d');
+ ```
+ If you have not configured a `segmentby` column, TimescaleDB chooses one for you based on the data in your
+ hypertable. For more information on how to tune your hypertables for the best performance, see
+ [efficient queries][secondary-indexes].
+
+1. **View your data space saving**
+
+ When you convert data to the columnstore, as well as being optimized for analytics, it is compressed by more than
+ 90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
+ saved, click `Explorer` > `public` > `crypto_ticks`.
+
+ 
+
+## Write fast and efficient analytical queries
+
+Aggregation is a way of combing data to get insights from it. Average, sum, and count are all
+examples of simple aggregates. However, with large amounts of data, aggregation slows things down, quickly.
+Continuous aggregates are a kind of hypertable that is refreshed automatically in
+the background as new data is added, or old data is modified. Changes to your dataset are tracked,
+and the hypertable behind the continuous aggregate is automatically updated in the background.
+
+
+
+You create continuous aggregates on uncompressed data in high-performance storage. They continue to work
+on [data in the columnstore][test-drive-enable-compression]
+and [rarely accessed data in tiered storage][test-drive-tiered-storage]. You can even
+create [continuous aggregates on top of your continuous aggregates][hierarchical-caggs].
+
+You use time buckets to create a continuous aggregate. Time buckets aggregate data in hypertables by time
+interval. For example, a 5-minute, 1-hour, or 3-day bucket. The data grouped in a time bucket uses a single
+timestamp. Continuous aggregates minimize the number of records that you need to look up to perform your
+query.
+
+This section shows you how to run fast analytical queries using time buckets and continuous aggregate in
+Tiger Cloud Console. You can also do this using psql.
+
+
+
+
+
+This feature is not available under the Free pricing plan.
+
+1. **Connect to your service**
+
+ In [Tiger Cloud Console][portal-data-mode], select your service in the connection drop-down in the top right.
+
+1. **Create a continuous aggregate**
+
+ For a continuous aggregate, data grouped using a time bucket is stored in a
+ Postgres `MATERIALIZED VIEW` in a hypertable. `timescaledb.continuous` ensures that this data
+ is always up to date.
+ In data mode, use the following code to create a continuous aggregate on the real-time data in
+ the `crypto_ticks` table:
+
+ ```sql
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS day,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM crypto_ticks srt
+ GROUP BY day, symbol;
+ ```
+
+ This continuous aggregate creates the [candlestick chart][charts] data you use to visualize
+ the price change of an asset.
+
+1. **Create a policy to refresh the view every hour**
+
+ ```sql
+ SELECT add_continuous_aggregate_policy('assets_candlestick_daily',
+ start_offset => INTERVAL '3 weeks',
+ end_offset => INTERVAL '24 hours',
+ schedule_interval => INTERVAL '3 hours');
+ ```
+
+1. **Have a quick look at your data**
+
+ You query continuous aggregates exactly the same way as your other tables. To query the `assets_candlestick_daily`
+ continuous aggregate for all assets:
+
+
+
+
+
+
+
+1. **In [Tiger Cloud Console][portal-ops-mode], select the service you uploaded data to**
+1. **Click `Explorer` > `Continuous Aggregates` > `Create a Continuous Aggregate` next to the `crypto_ticks` hypertable**
+1. **Create a view called `assets_candlestick_daily` on the `time` column with an interval of `1 day`, then click `Next step`**
+ 
+1. **Update the view SQL with the following functions, then click `Run`**
+ ```sql
+ CREATE MATERIALIZED VIEW assets_candlestick_daily
+ WITH (timescaledb.continuous) AS
+ SELECT
+ time_bucket('1 day', "time") AS bucket,
+ symbol,
+ max(price) AS high,
+ first(price, time) AS open,
+ last(price, time) AS close,
+ min(price) AS low
+ FROM "public"."crypto_ticks" srt
+ GROUP BY bucket, symbol;
+ ```
+1. **When the view is created, click `Next step`**
+1. **Define a refresh policy with the following values:**
+ - `How far back do you want to materialize?`: `3 weeks`
+ - `What recent data to exclude?`: `24 hours`
+ - `How often do you want the job to run?`: `3 hours`
+1. **Click `Next step`, then click `Run`**
+
+Tiger Cloud creates the continuous aggregate and displays the aggregate ID in Tiger Cloud Console. Click `DONE` to close the wizard.
+
+
+
+
+
+To see the change in terms of query time and data returned between a regular query and
+a continuous aggregate, run the query part of the continuous aggregate
+( `SELECT ...GROUP BY day, symbol;` ) and compare the results.
+
+## Slash storage charges
+
+
+
+In the previous sections, you used continuous aggregates to make fast analytical queries, and
+hypercore to reduce storage costs on frequently accessed data. To reduce storage costs even more,
+you create tiering policies to move rarely accessed data to the object store. The object store is
+low-cost bottomless data storage built on Amazon S3. However, no matter the tier, you can
+[query your data when you need][querying-tiered-data]. Tiger Cloud seamlessly accesses the correct storage
+tier and generates the response.
+
+
+
+To set up data tiering:
+
+1. **Enable data tiering**
+
+ 1. In [Tiger Cloud Console][portal-ops-mode], select the service to modify.
+
+ 1. In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`.
+
+ 
+
+ When tiered storage is enabled, you see the amount of data in the tiered object storage.
+
+1. **Set the time interval when data is tiered**
+
+ In Tiger Cloud Console, click `Data` to switch to the data mode, then enable data tiering on a hypertable with the following query:
+ ```sql
+ SELECT add_tiering_policy('assets_candlestick_daily', INTERVAL '3 weeks');
+ ```
+
+1. **Query tiered data**
+
+ You enable reads from tiered data for each query, for a session or for all future
+ sessions. To run a single query on tiered data:
+
+ 1. Enable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = true
+ ```
+ 1. Query the data:
+ ```sql
+ SELECT * FROM crypto_ticks srt LIMIT 10
+ ```
+ 1. Disable reads on tiered data:
+ ```sql
+ set timescaledb.enable_tiered_reads = false;
+ ```
+ For more information, see [Querying tiered data][querying-tiered-data].
+
+## Reduce the risk of downtime and data loss
+
+
+
+By default, all Tiger Cloud services have rapid recovery enabled. However, if your app has very low tolerance
+for downtime, Tiger Cloud offers high-availability replicas. HA replicas are exact, up-to-date copies
+of your database hosted in multiple AWS availability zones (AZ) within the same region as your primary node.
+HA replicas automatically take over operations if the original primary data node becomes unavailable.
+The primary node streams its write-ahead log (WAL) to the replicas to minimize the chances of
+data loss during failover.
+
+1. In [Tiger Cloud Console][cloud-login], select the service to enable replication for.
+1. Click `Operations`, then select `High availability`.
+1. Choose your replication strategy, then click `Change configuration`.
+
+ 
+
+1. In `Change high availability configuration`, click `Change config`.
+
+For more information, see [High availability][high-availability].
+
+What next? See the [use case tutorials][tutorials], interact with the data in your Tiger Cloud service using
+[your favorite programming language][connect-with-code], integrate your Tiger Cloud service with a range of
+[third-party tools][integrations], plain old [Use Tiger Data products][use-timescale], or dive into [the API][use-the-api].
+
+
+===== PAGE: https://docs.tigerdata.com/getting-started/start-coding-with-timescale/ =====
+
+# Start coding with Tiger Data
+
+
+
+Easily integrate your app with Tiger Cloud or self-hosted TimescaleDB. Use your favorite programming language to connect to your
+Tiger Cloud service, create and manage hypertables, then ingest and query data.
+
+
+
+
+
+# "Quick Start: Ruby and TimescaleDB"
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Rails][rails-guide].
+
+## Connect a Rails app to your service
+
+Every Tiger Cloud service is a 100% Postgres database hosted in Tiger Cloud with
+Tiger Data extensions such as TimescaleDB. You connect to your Tiger Cloud service
+from a standard Rails app configured for Postgres.
+
+1. **Create a new Rails app configured for Postgres**
+
+ Rails creates and bundles your app, then installs the standard Postgres Gems.
+
+ ```bash
+ rails new my_app -d=postgresql
+ cd my_app
+ ```
+
+1. **Install the TimescaleDB gem**
+
+ 1. Open `Gemfile`, add the following line, then save your changes:
+
+ ```ruby
+ gem 'timescaledb'
+ ```
+
+ 1. In Terminal, run the following command:
+
+ ```bash
+ bundle install
+ ```
+
+1. **Connect your app to your Tiger Cloud service**
+
+ 1. In `/config/database.yml` update the configuration to read securely connect to your Tiger Cloud service
+ by adding `url: <%= ENV['DATABASE_URL'] %>` to the default configuration:
+
+ ```yaml
+ default: &default
+ adapter: postgresql
+ encoding: unicode
+ pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
+ url: <%= ENV['DATABASE_URL'] %>
+ ```
+
+ 1. Set the environment variable for `DATABASE_URL` to the value of `Service URL` from
+ your [connection details][connection-info]
+ ```bash
+ export DATABASE_URL="value of Service URL"
+ ```
+
+ 1. Create the database:
+ - **Tiger Cloud**: nothing to do. The database is part of your Tiger Cloud service.
+ - **Self-hosted TimescaleDB**, create the database for the project:
+
+ ```bash
+ rails db:create
+ ```
+
+ 1. Run migrations:
+
+ ```bash
+ rails db:migrate
+ ```
+
+ 1. Verify the connection from your app to your Tiger Cloud service:
+
+ ```bash
+ echo "\dx" | rails dbconsole
+ ```
+
+ The result shows the list of extensions in your Tiger Cloud service
+
+ | Name | Version | Schema | Description |
+ | -- | -- | -- | -- |
+ | pg_buffercache | 1.5 | public | examine the shared buffer cache|
+ | pg_stat_statements | 1.11 | public | track planning and execution statistics of all SQL statements executed|
+ | plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language|
+ | postgres_fdw | 1.1 | public | foreign-data wrapper for remote Postgres servers|
+ | timescaledb | 2.18.1 | public | Enables scalable inserts and complex queries for time-series data (Community Edition)|
+ | timescaledb_toolkit | 1.19.0 | public | Library of analytical hyperfunctions, time-series pipelining, and other SQL utilities|
+
+## Optimize time-series data in hypertables
+
+Hypertables are Postgres tables designed to simplify and accelerate data analysis. Anything
+you can do with regular Postgres tables, you can do with hypertables - but much faster and more conveniently.
+
+In this section, you use the helpers in the TimescaleDB gem to create and manage a [hypertable][about-hypertables].
+
+1. **Generate a migration to create the page loads table**
+
+ ```bash
+ rails generate migration create_page_loads
+ ```
+
+ This creates the `/db/migrate/_create_page_loads.rb` migration file.
+
+1. **Add hypertable options**
+
+ Replace the contents of `/db/migrate/_create_page_loads.rb`
+ with the following:
+
+ ```ruby
+ class CreatePageLoads < ActiveRecord::Migration[8.0]
+ def change
+ hypertable_options = {
+ time_column: 'created_at',
+ chunk_time_interval: '1 day',
+ compress_segmentby: 'path',
+ compress_orderby: 'created_at',
+ compress_after: '7 days',
+ drop_after: '30 days'
+ }
+
+ create_table :page_loads, id: false, primary_key: [:created_at, :user_agent, :path], hypertable: hypertable_options do |t|
+ t.timestamptz :created_at, null: false
+ t.string :user_agent
+ t.string :path
+ t.float :performance
+ end
+ end
+ end
+ ```
+
+ The `id` column is not included in the table. This is because TimescaleDB requires that any `UNIQUE` or `PRIMARY KEY`
+ indexes on the table include all partitioning columns. In this case, this is the time column. A new
+ Rails model includes a `PRIMARY KEY` index for id by default: either remove the column or make sure that the index
+ includes time as part of a "composite key."
+
+ For more information, check the Roby docs around [composite primary keys][rails-compostite-primary-keys].
+
+1. **Create a `PageLoad` model**
+
+ Create a new file called `/app/models/page_load.rb` and add the following code:
+
+ ```ruby
+ class PageLoad < ApplicationRecord
+ extend Timescaledb::ActsAsHypertable
+ include Timescaledb::ContinuousAggregatesHelper
+
+ acts_as_hypertable time_column: "created_at",
+ segment_by: "path",
+ value_column: "performance"
+
+ scope :chrome_users, -> { where("user_agent LIKE ?", "%Chrome%") }
+ scope :firefox_users, -> { where("user_agent LIKE ?", "%Firefox%") }
+ scope :safari_users, -> { where("user_agent LIKE ?", "%Safari%") }
+
+ scope :performance_stats, -> {
+ select("stats_agg(#{value_column}) as stats_agg")
+ }
+
+ scope :slow_requests, -> { where("performance > ?", 1.0) }
+ scope :fast_requests, -> { where("performance < ?", 0.1) }
+
+ continuous_aggregates scopes: [:performance_stats],
+ timeframes: [:minute, :hour, :day],
+ refresh_policy: {
+ minute: {
+ start_offset: '3 minute',
+ end_offset: '1 minute',
+ schedule_interval: '1 minute'
+ },
+ hour: {
+ start_offset: '3 hours',
+ end_offset: '1 hour',
+ schedule_interval: '1 minute'
+ },
+ day: {
+ start_offset: '3 day',
+ end_offset: '1 day',
+ schedule_interval: '1 minute'
+ }
+ }
+ end
+ ```
+
+1. **Run the migration**
+
+ ```bash
+ rails db:migrate
+ ```
+
+## Insert data your service
+
+The TimescaleDB gem provides efficient ways to insert data into hypertables. This section
+shows you how to ingest test data into your hypertable.
+
+1. **Create a controller to handle page loads**
+
+ Create a new file called `/app/controllers/application_controller.rb` and add the following code:
+
+ ```ruby
+ class ApplicationController < ActionController::Base
+ around_action :track_page_load
+
+ private
+
+ def track_page_load
+ start_time = Time.current
+ yield
+ end_time = Time.current
+
+ PageLoad.create(
+ path: request.path,
+ user_agent: request.user_agent,
+ performance: (end_time - start_time)
+ )
+ end
+ end
+ ```
+
+1. **Generate some test data**
+
+ Use `bin/console` to join a Rails console session and run the following code
+ to define some random page load access data:
+
+ ```ruby
+ def generate_sample_page_loads(total: 1000)
+ time = 1.month.ago
+ paths = %w[/ /about /contact /products /blog]
+ browsers = [
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:89.0) Gecko/20100101 Firefox/89.0",
+ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
+ ]
+
+ total.times.map do
+ time = time + rand(60).seconds
+ {
+ path: paths.sample,
+ user_agent: browsers.sample,
+ performance: rand(0.1..2.0),
+ created_at: time,
+ updated_at: time
+ }
+ end
+ end
+ ```
+
+1. **Insert the generated data into your Tiger Cloud service**
+
+ ```bash
+ PageLoad.insert_all(generate_sample_page_loads, returning: false)
+ ```
+
+1. **Validate the test data in your Tiger Cloud service**
+
+ ```bash
+ PageLoad.count
+ PageLoad.first
+ ```
+
+## Reference
+
+This section lists the most common tasks you might perform with the TimescaleDB gem.
+
+### Query scopes
+
+The TimescaleDB gem provides several convenient scopes for querying your time-series data.
+
+
+- Built-in time-based scopes:
+
+ ```ruby
+ PageLoad.last_hour.count
+ PageLoad.today.count
+ PageLoad.this_week.count
+ PageLoad.this_month.count
+ ```
+
+- Browser-specific scopes:
+
+ ```ruby
+ PageLoad.chrome_users.last_hour.count
+ PageLoad.firefox_users.last_hour.count
+ PageLoad.safari_users.last_hour.count
+
+ PageLoad.slow_requests.last_hour.count
+ PageLoad.fast_requests.last_hour.count
+ ```
+
+- Query continuous aggregates:
+
+ This query fetches the average and standard deviation from the performance stats for the `/products` path over the last day.
+
+ ```ruby
+ PageLoad::PerformanceStatsPerMinute.last_hour
+ PageLoad::PerformanceStatsPerHour.last_day
+ PageLoad::PerformanceStatsPerDay.last_month
+
+ stats = PageLoad::PerformanceStatsPerHour.last_day.where(path: '/products').select("average(stats_agg) as average, stddev(stats_agg) as stddev").first
+ puts "Average: #{stats.average}"
+ puts "Standard Deviation: #{stats.stddev}"
+ ```
+
+### TimescaleDB features
+
+The TimescaleDB gem provides utility methods to access hypertable and chunk information. Every model that uses
+the `acts_as_hypertable` method has access to these methods.
+
+
+#### Access hypertable and chunk information
+
+- View chunk or hypertable information:
+
+ ```ruby
+ PageLoad.chunks.count
+ PageLoad.hypertable.detailed_size
+ ```
+
+- Compress/Decompress chunks:
+
+ ```ruby
+ PageLoad.chunks.uncompressed.first.compress! # Compress the first uncompressed chunk
+ PageLoad.chunks.compressed.first.decompress! # Decompress the oldest chunk
+ PageLoad.hypertable.compression_stats # View compression stats
+
+ ```
+
+#### Access hypertable stats
+
+You collect hypertable stats using methods that provide insights into your hypertable's structure, size, and compression
+status:
+
+- Get basic hypertable information:
+
+ ```ruby
+ hypertable = PageLoad.hypertable
+ hypertable.hypertable_name # The name of your hypertable
+ hypertable.schema_name # The schema where the hypertable is located
+ ```
+
+- Get detailed size information:
+
+ ```ruby
+ hypertable.detailed_size # Get detailed size information for the hypertable
+ hypertable.compression_stats # Get compression statistics
+ hypertable.chunks_detailed_size # Get chunk information
+ hypertable.approximate_row_count # Get approximate row count
+ hypertable.dimensions.map(&:column_name) # Get dimension information
+ hypertable.continuous_aggregates.map(&:view_name) # Get continuous aggregate view names
+ ```
+
+#### Continuous aggregates
+
+The `continuous_aggregates` method generates a class for each continuous aggregate.
+
+- Get all the continuous aggregate classes:
+
+ ```ruby
+ PageLoad.descendants # Get all continuous aggregate classes
+ ```
+
+- Manually refresh a continuous aggregate:
+
+ ```ruby
+ PageLoad.refresh_aggregates
+ ```
+
+- Create or drop a continuous aggregate:
+
+ Create or drop all the continuous aggregates in the proper order to build them hierarchically. See more about how it
+ works in this [blog post][ruby-blog-post].
+
+ ```ruby
+ PageLoad.create_continuous_aggregates
+ PageLoad.drop_continuous_aggregates
+ ```
+
+
+
+
+## Next steps
+
+Now that you have integrated the ruby gem into your app:
+
+* Learn more about the [TimescaleDB gem](https://github.com/timescale/timescaledb-ruby).
+* Check out the [official docs](https://timescale.github.io/timescaledb-ruby/).
+* Follow the [LTTB][LTTB], [Open AI long-term storage][open-ai-tutorial], and [candlesticks][candlesticks] tutorials.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the `psycopg2` library.
+
+ For more information, see the [psycopg2 documentation][psycopg2-docs].
+* Create a [Python virtual environment][virtual-env]. [](#)
+
+## Connect to TimescaleDB
+
+In this section, you create a connection to TimescaleDB using the `psycopg2`
+library. This library is one of the most popular Postgres libraries for
+Python. It allows you to execute raw SQL queries efficiently and safely, and
+prevents common attacks such as SQL injection.
+
+1. Import the psycogpg2 library:
+
+ ```python
+ import psycopg2
+ ```
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for `psycopg2`.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable as a
+ [libpq connection string][pg-libpq-string], using this format:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ ```
+
+ If you're using a hosted version of TimescaleDB, or generally require an SSL
+ connection, use this version instead:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname?sslmode=require"
+ ```
+
+ Alternatively you can specify each parameter in the connection string as follows
+
+ ```python
+ CONNECTION = "dbname=tsdb user=tsdbadmin password=secret host=host.com port=5432 sslmode=require"
+ ```
+
+
+
+ This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+
+
+1. Use the `psycopg2` [connect function][psycopg2-connect] to create a new
+ database session and create a new [cursor object][psycopg2-cursor] to
+ interact with the database.
+
+ In your `main` function, add these lines:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ with psycopg2.connect(CONNECTION) as conn:
+ cursor = conn.cursor()
+ # use the cursor to interact with your database
+ # cursor.execute("SELECT * FROM table")
+ ```
+
+ Alternatively, you can create a connection object and pass the object
+ around as needed, like opening a cursor to perform database operations:
+
+ ```python
+ CONNECTION = "postgres://username:password@host:port/dbname"
+ conn = psycopg2.connect(CONNECTION)
+ cursor = conn.cursor()
+ # use the cursor to interact with your database
+ cursor.execute("SELECT 'hello world'")
+ print(cursor.fetchone())
+ ```
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+ ```python
+ query_create_sensors_table = """CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type VARCHAR(50),
+ location VARCHAR(50)
+ );
+ """
+ ```
+
+1. Open a cursor, execute the query you created in the previous step, and
+ commit the query to make the changes persistent. Afterward, close the cursor
+ to clean up:
+
+ ```python
+ cursor = conn.cursor()
+ # see definition in Step 1
+ cursor.execute(query_create_sensors_table)
+ conn.commit()
+ cursor.close()
+ ```
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a string variable that contains the `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+ ```python
+ # create sensor data hypertable
+ query_create_sensordata_table = """CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id)
+ );
+ """
+ ```
+
+2. Formulate a `SELECT` statement that converts the `sensor_data` table to a
+ hypertable. You must specify the table name to convert to a hypertable, and
+ the name of the time column as the two arguments. For more information, see
+ the [`create_hypertable` docs][create-hypertable-docs]:
+
+ ```python
+ query_create_sensordata_hypertable = "SELECT create_hypertable('sensor_data', by_range('time'));"
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+3. Open a cursor with the connection, execute the statements from the previous
+ steps, commit your changes, and close the cursor:
+
+ ```python
+ cursor = conn.cursor()
+ cursor.execute(query_create_sensordata_table)
+ cursor.execute(query_create_sensordata_hypertable)
+ # commit changes to the database to make changes persistent
+ conn.commit()
+ cursor.close()
+ ```
+
+## Insert rows of data
+
+You can insert data into your hypertables in several different ways. In this
+section, you can use `psycopg2` with prepared statements, or you can use
+`pgcopy` for a faster insert.
+
+1. This example inserts a list of tuples, or relational data, called `sensors`,
+ into the relational table named `sensors`. Open a cursor with a connection
+ to the database, use prepared statements to formulate the `INSERT` SQL
+ statement, and then execute that statement:
+
+ ```python
+ sensors = [('a', 'floor'), ('a', 'ceiling'), ('b', 'floor'), ('b', 'ceiling')]
+ cursor = conn.cursor()
+ for sensor in sensors:
+ try:
+ cursor.execute("INSERT INTO sensors (type, location) VALUES (%s, %s);",
+ (sensor[0], sensor[1]))
+ except (Exception, psycopg2.Error) as error:
+ print(error.pgerror)
+ conn.commit()
+ ```
+
+1. [](#)Alternatively, you can pass variables to the `cursor.execute`
+ function and separate the formulation of the SQL statement, `SQL`, from the
+ data being passed with it into the prepared statement, `data`:
+
+ ```python
+ SQL = "INSERT INTO sensors (type, location) VALUES (%s, %s);"
+ sensors = [('a', 'floor'), ('a', 'ceiling'), ('b', 'floor'), ('b', 'ceiling')]
+ cursor = conn.cursor()
+ for sensor in sensors:
+ try:
+ data = (sensor[0], sensor[1])
+ cursor.execute(SQL, data)
+ except (Exception, psycopg2.Error) as error:
+ print(error.pgerror)
+ conn.commit()
+ ```
+
+If you choose to use `pgcopy` instead, install the `pgcopy` package
+[using pip][pgcopy-install], and then add this line to your list of
+`import` statements:
+
+```python
+from pgcopy import CopyManager
+```
+
+1. Generate some random sensor data using the `generate_series` function
+ provided by Postgres. This example inserts a total of 480 rows of data (4
+ readings, every 5 minutes, for 24 hours). In your application, this would be
+ the query that saves your time-series data into the hypertable:
+
+ ```python
+ # for sensors with ids 1-4
+ for id in range(1, 4, 1):
+ data = (id,)
+ # create random data
+ simulate_query = """SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ %s as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu;
+ """
+ cursor.execute(simulate_query, data)
+ values = cursor.fetchall()
+ ```
+
+1. Define the column names of the table you want to insert data into. This
+ example uses the `sensor_data` hypertable created earlier. This hypertable
+ consists of columns named `time`, `sensor_id`, `temperature` and `cpu`. The
+ column names are defined in a list of strings called `cols`:
+
+ ```python
+ cols = ['time', 'sensor_id', 'temperature', 'cpu']
+ ```
+
+1. Create an instance of the `pgcopy` CopyManager, `mgr`, and pass the
+ connection variable, hypertable name, and list of column names. Then use the
+ `copy` function of the CopyManager to insert the data into the database
+ quickly using `pgcopy`.
+
+ ```python
+ mgr = CopyManager(conn, 'sensor_data', cols)
+ mgr.copy(values)
+ ```
+
+1. Commit to persist changes:
+
+ ```python
+ conn.commit()
+ ```
+
+1. [](#)The full sample code to insert data into TimescaleDB using
+ `pgcopy`, using the example of sensor data from four sensors:
+
+ ```python
+ # insert using pgcopy
+ def fast_insert(conn):
+ cursor = conn.cursor()
+
+ # for sensors with ids 1-4
+ for id in range(1, 4, 1):
+ data = (id,)
+ # create random data
+ simulate_query = """SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ %s as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu;
+ """
+ cursor.execute(simulate_query, data)
+ values = cursor.fetchall()
+
+ # column names of the table you're inserting into
+ cols = ['time', 'sensor_id', 'temperature', 'cpu']
+
+ # create copy manager with the target table and insert
+ mgr = CopyManager(conn, 'sensor_data', cols)
+ mgr.copy(values)
+
+ # commit after all sensor data is inserted
+ # could also commit after each sensor insert is done
+ conn.commit()
+ ```
+
+1. [](#)You can also check if the insertion worked:
+
+ ```python
+ cursor.execute("SELECT * FROM sensor_data LIMIT 5;")
+ print(cursor.fetchall())
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database.
+
+The first procedure shows a simple `SELECT *` query. For more complex queries,
+you can use prepared statements to ensure queries are executed safely against
+the database.
+
+For more information about properly using placeholders in `psycopg2`, see the
+[basic module usage document][psycopg2-docs-basics].
+For more information about how to execute more complex queries in `psycopg2`,
+see the [psycopg2 documentation][psycopg2-docs-basics].
+
+### Execute a query
+
+1. Define the SQL query you'd like to run on the database. This example is a
+ simple `SELECT` statement querying each row from the previously created
+ `sensor_data` table.
+
+ ```python
+ query = "SELECT * FROM sensor_data;"
+ ```
+
+1. Open a cursor from the existing database connection, `conn`, and then execute
+ the query you defined:
+
+ ```python
+ cursor = conn.cursor()
+ query = "SELECT * FROM sensor_data;"
+ cursor.execute(query)
+ ```
+
+1. To access all resulting rows returned by your query, use one of `pyscopg2`'s
+ [results retrieval methods][results-retrieval-methods],
+ such as `fetchall()` or `fetchmany()`. This example prints the results of
+ the query, row by row. Note that the result of `fetchall()` is a list of
+ tuples, so you can handle them accordingly:
+
+ ```python
+ cursor = conn.cursor()
+ query = "SELECT * FROM sensor_data;"
+ cursor.execute(query)
+ for row in cursor.fetchall():
+ print(row)
+ cursor.close()
+ ```
+
+1. [](#)If you want a list of dictionaries instead, you can define the
+ cursor using [`DictCursor`][dictcursor-docs]:
+
+ ```python
+ cursor = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
+ ```
+
+ Using this cursor, `cursor.fetchall()` returns a list of dictionary-like objects.
+
+For more complex queries, you can use prepared statements to ensure queries are
+executed safely against the database.
+
+### Execute queries using prepared statements
+
+1. Write the query using prepared statements:
+
+ ```python
+ # query with placeholders
+ cursor = conn.cursor()
+ query = """
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = %s AND sensors.type = %s
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ """
+ location = "floor"
+ sensor_type = "a"
+ data = (location, sensor_type)
+ cursor.execute(query, data)
+ results = cursor.fetchall()
+ ```
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install [Node.js][node-install].
+* Install the Node.js package manager [npm][npm-install].
+
+## Connect to TimescaleDB
+
+In this section, you create a connection to TimescaleDB with a common Node.js
+ORM (object relational mapper) called [Sequelize][sequelize-info].
+
+1. At the command prompt, initialize a new Node.js app:
+
+ ```bash
+ npm init -y
+ ```
+
+ This creates a `package.json` file in your directory, which contains all
+ of the dependencies for your project. It looks something like this:
+
+ ```json
+ {
+ "name": "node-sample",
+ "version": "1.0.0",
+ "description": "",
+ "main": "index.js",
+ "scripts": {
+ "test": "echo \"Error: no test specified\" && exit 1"
+ },
+ "keywords": [],
+ "author": "",
+ "license": "ISC"
+ }
+ ```
+
+1. Install Express.js:
+
+ ```bash
+ npm install express
+ ```
+
+1. Create a simple web page to check the connection. Create a new file called
+ `index.js`, with this content:
+
+ ```java
+ const express = require('express')
+ const app = express()
+ const port = 3000;
+
+ app.use(express.json());
+ app.get('/', (req, res) => res.send('Hello World!'))
+ app.listen(port, () => console.log(`Example app listening at http://localhost:${port}`))
+ ```
+
+1. Test your connection by starting the application:
+
+ ```bash
+ node index.js
+ ```
+
+ In your web browser, navigate to `http://localhost:3000`. If the connection
+ is successful, it shows "Hello World!"
+
+1. Add Sequelize to your project:
+
+ ```bash
+ npm install sequelize sequelize-cli pg pg-hstore
+ ```
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for Sequelize.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+ ```java
+ 'postgres://:@:/'
+ ```
+
+1. Open the `index.js` file you created. Require Sequelize in the application,
+ and declare the connection string:
+
+ ```java
+ const Sequelize = require('sequelize')
+ const sequelize = new Sequelize('postgres://:@:/',
+ {
+ dialect: 'postgres',
+ protocol: 'postgres',
+ dialectOptions: {
+ ssl: {
+ require: true,
+ rejectUnauthorized: false
+ }
+ }
+ })
+ ```
+
+ Make sure you add the SSL settings in the `dialectOptions` sections. You
+ can't connect to TimescaleDB using SSL without them.
+
+1. You can test the connection by adding these lines to `index.js` after the
+ `app.get` statement:
+
+ ```java
+ sequelize.authenticate().then(() => {
+ console.log('Connection has been established successfully.');
+ }).catch(err => {
+ console.error('Unable to connect to the database:', err);
+ });
+ ```
+
+ Start the application on the command line:
+
+ ```bash
+ node index.js
+ ```
+
+ If the connection is successful, you'll get output like this:
+
+ ```bash
+ Example app listening at http://localhost:3000
+ Executing (default): SELECT 1+1 AS result
+ Connection has been established successfully.
+ ```
+
+## Create a relational table
+
+In this section, you create a relational table called `page_loads`.
+
+1. Use the Sequelize command line tool to create a table and model called `page_loads`:
+
+ ```bash
+ npx sequelize model:generate --name page_loads \
+ --attributes userAgent:string,time:date
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ New model was created at .
+ New migration was created at .
+ ```
+
+1. Edit the migration file so that it sets up a migration key:
+
+ ```java
+ 'use strict';
+ module.exports = {
+ up: async (queryInterface, Sequelize) => {
+ await queryInterface.createTable('page_loads', {
+ userAgent: {
+ primaryKey: true,
+ type: Sequelize.STRING
+ },
+ time: {
+ primaryKey: true,
+ type: Sequelize.DATE
+ }
+ });
+ },
+ down: async (queryInterface, Sequelize) => {
+ await queryInterface.dropTable('page_loads');
+ }
+ };
+ ```
+
+1. Migrate the change and make sure that it is reflected in the database:
+
+ ```bash
+ npx sequelize db:migrate
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ Loaded configuration file "config/config.json".
+ Using environment "development".
+ == 20200528195725-create-page-loads: migrating =======
+ == 20200528195725-create-page-loads: migrated (0.443s)
+ ```
+
+1. Create the `PageLoads` model in your code. In the `index.js` file, above the
+ `app.use` statement, add these lines:
+
+ ```java
+ let PageLoads = sequelize.define('page_loads', {
+ userAgent: {type: Sequelize.STRING, primaryKey: true },
+ time: {type: Sequelize.DATE, primaryKey: true }
+ }, { timestamps: false });
+ ```
+
+1. Instantiate a `PageLoads` object and save it to the database.
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a migration to modify the `page_loads` relational table, and change
+ it to a hypertable by first running the following command:
+
+ ```bash
+ npx sequelize migration:generate --name add_hypertable
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ migrations folder at already exists.
+ New migration was created at /20200601202912-add_hypertable.js .
+ ```
+
+1. In the `migrations` folder, there is now a new file. Open the
+ file, and add this content:
+
+ ```js
+ 'use strict';
+
+ module.exports = {
+ up: (queryInterface, Sequelize) => {
+ return queryInterface.sequelize.query("SELECT create_hypertable('page_loads', by_range('time'));");
+ },
+
+ down: (queryInterface, Sequelize) => {
+ }
+ };
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. At the command prompt, run the migration command:
+
+ ```bash
+ npx sequelize db:migrate
+ ```
+
+ The output looks similar to this:
+
+ ```bash
+ Sequelize CLI [Node: 12.16.2, CLI: 5.5.1, ORM: 5.21.11]
+
+ Loaded configuration file "config/config.json".
+ Using environment "development".
+ == 20200601202912-add_hypertable: migrating =======
+ == 20200601202912-add_hypertable: migrated (0.426s)
+ ```
+
+## Insert rows of data
+
+This section covers how to insert data into your hypertables.
+
+1. In the `index.js` file, modify the `/` route to get the `user-agent` from
+ the request object (`req`) and the current timestamp. Then, call the
+ `create` method on `PageLoads` model, supplying the user agent and timestamp
+ parameters. The `create` call executes an `INSERT` on the database:
+
+ ```java
+ app.get('/', async (req, res) => {
+ // get the user agent and current time
+ const userAgent = req.get('user-agent');
+ const time = new Date().getTime();
+
+ try {
+ // insert the record
+ await PageLoads.create({
+ userAgent, time
+ });
+
+ // send response
+ res.send('Inserted!');
+ } catch (e) {
+ console.log('Error inserting data', e)
+ }
+ })
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database. In this
+example, every time the page is reloaded, all information currently in the table
+is displayed.
+
+1. Modify the `/` route in the `index.js` file to call the Sequelize `findAll`
+ function and retrieve all data from the `page_loads` table using the
+ `PageLoads` model:
+
+ ```java
+ app.get('/', async (req, res) => {
+ // get the user agent and current time
+ const userAgent = req.get('user-agent');
+ const time = new Date().getTime();
+
+ try {
+ // insert the record
+ await PageLoads.create({
+ userAgent, time
+ });
+
+ // now display everything in the table
+ const messages = await PageLoads.findAll();
+ res.send(messages);
+ } catch (e) {
+ console.log('Error inserting data', e)
+ }
+ })
+ ```
+
+Now, when you reload the page, you should see all of the rows currently in the
+`page_loads` table.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+- Install [Go][golang-install].
+- Install the [PGX driver for Go][pgx-driver-github].
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to Tiger Cloud using the PGX driver.
+PGX is a toolkit designed to help Go developers work directly with Postgres.
+You can use it to help your Go application interact directly with TimescaleDB.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for PGX.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port number
+ * database name
+
+1. Compose your connection string variable as a
+ [libpq connection string][libpq-docs], using this format:
+
+ ```go
+ connStr := "postgres://username:password@host:port/dbname"
+ ```
+
+ If you're using a hosted version of TimescaleDB, or if you need an SSL
+ connection, use this format instead:
+
+ ```go
+ connStr := "postgres://username:password@host:port/dbname?sslmode=require"
+ ```
+
+1. [](#)You can check that you're connected to your database with this
+ hello world program:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5"
+ )
+
+ //connect to database using a single connection
+ func main() {
+ /***********************************************/
+ /* Single Connection to TimescaleDB/ PostgreSQL */
+ /***********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ conn, err := pgx.Connect(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer conn.Close(ctx)
+
+ //run a simple query to check our connection
+ var greeting string
+ err = conn.QueryRow(ctx, "select 'Hello, Timescale!'").Scan(&greeting)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println(greeting)
+ }
+
+ ```
+
+ If you'd like to specify your connection string as an environment variable,
+ you can use this syntax to access it in place of the `connStr` variable:
+
+ ```go
+ os.Getenv("DATABASE_CONNECTION_STRING")
+ ```
+
+Alternatively, you can connect to TimescaleDB using a connection pool.
+Connection pooling is useful to conserve computing resources, and can also
+result in faster database queries:
+
+1. To create a connection pool that can be used for concurrent connections to
+ your database, use the `pgxpool.New()` function instead of
+ `pgx.Connect()`. Also note that this script imports
+ `github.com/jackc/pgx/v5/pgxpool`, instead of `pgx/v5` which was used to
+ create a single connection:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ //run a simple query to check our connection
+ var greeting string
+ err = dbpool.QueryRow(ctx, "select 'Hello, Tiger Data (but concurrently)'").Scan(&greeting)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "QueryRow failed: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println(greeting)
+ }
+ ```
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string that contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns for ID,
+ type, and location:
+
+ ```go
+ queryCreateTable := `CREATE TABLE sensors (id SERIAL PRIMARY KEY, type VARCHAR(50), location VARCHAR(50));`
+ ```
+
+1. Execute the `CREATE TABLE` statement with the `Exec()` function on the
+ `dbpool` object, using the arguments of the current context and the
+ statement string you created:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Create relational table */
+ /********************************************/
+
+ //Create relational table called sensors
+ queryCreateTable := `CREATE TABLE sensors (id SERIAL PRIMARY KEY, type VARCHAR(50), location VARCHAR(50));`
+ _, err = dbpool.Exec(ctx, queryCreateTable)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to create SENSORS table: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully created relational table SENSORS")
+ }
+ ```
+
+## Generate a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a variable for the `CREATE TABLE SQL` statement for your hypertable.
+ Notice how the hypertable has the compulsory time column:
+
+ ```go
+ queryCreateTable := `CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id));
+ `
+ ```
+
+1. Formulate the `SELECT` statement to convert the table into a hypertable. You
+ must specify the table name to convert to a hypertable, and its time column
+ name as the second argument. For more information, see the
+ [`create_hypertable` docs][create-hypertable-docs]:
+
+ ```go
+ queryCreateHypertable := `SELECT create_hypertable('sensor_data', by_range('time'));`
+ ```
+
+
+
+ The `by_range` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. Execute the `CREATE TABLE` statement and `SELECT` statement which converts
+ the table into a hypertable. You can do this by calling the `Exec()`
+ function on the `dbpool` object, using the arguments of the current context,
+ and the `queryCreateTable` and `queryCreateHypertable` statement strings:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Create Hypertable */
+ /********************************************/
+ // Create hypertable of time-series data called sensor_data
+ queryCreateTable := `CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER,
+ temperature DOUBLE PRECISION,
+ cpu DOUBLE PRECISION,
+ FOREIGN KEY (sensor_id) REFERENCES sensors (id));
+ `
+
+ queryCreateHypertable := `SELECT create_hypertable('sensor_data', by_range('time'));`
+
+ //execute statement
+ _, err = dbpool.Exec(ctx, queryCreateTable+queryCreateHypertable)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to create the `sensor_data` hypertable: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully created hypertable `sensor_data`")
+ }
+ ```
+
+## Insert rows of data
+
+You can insert rows into your database in a couple of different
+ways. Each of these example inserts the data from the two arrays, `sensorTypes` and
+`sensorLocations`, into the relational table named `sensors`.
+
+The first example inserts a single row of data at a time. The second example
+inserts multiple rows of data. The third example uses batch inserts to speed up
+the process.
+
+1. Open a connection pool to the database, then use the prepared statements to
+ formulate an `INSERT` SQL statement, and execute it:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* INSERT into relational table */
+ /********************************************/
+ //Insert data into relational table
+
+ // Slices of sample data to insert
+ // observation i has type sensorTypes[i] and location sensorLocations[i]
+ sensorTypes := []string{"a", "a", "b", "b"}
+ sensorLocations := []string{"floor", "ceiling", "floor", "ceiling"}
+
+ for i := range sensorTypes {
+ //INSERT statement in SQL
+ queryInsertMetadata := `INSERT INTO sensors (type, location) VALUES ($1, $2);`
+
+ //Execute INSERT command
+ _, err := dbpool.Exec(ctx, queryInsertMetadata, sensorTypes[i], sensorLocations[i])
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert data into database: %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Printf("Inserted sensor (%s, %s) into database \n", sensorTypes[i], sensorLocations[i])
+ }
+ fmt.Println("Successfully inserted all sensors into database")
+ }
+ ```
+
+Instead of inserting a single row of data at a time, you can use this procedure
+to insert multiple rows of data, instead:
+
+1. This example uses Postgres to generate some sample time-series to insert
+ into the `sensor_data` hypertable. Define the SQL statement to generate the
+ data, called `queryDataGeneration`. Then use the `.Query()` function to
+ execute the statement and return the sample data. The data returned by the
+ query is stored in `results`, a slice of structs, which is then used as a
+ source to insert data into the hypertable:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+ }
+ ```
+
+1. Formulate an SQL insert statement for the `sensor_data` hypertable:
+
+ ```go
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+ ```
+
+1. Execute the SQL statement for each sample in the results slice:
+
+ ```go
+ //Insert contents of results slice into TimescaleDB
+ for i := range results {
+ var r result
+ r = results[i]
+ _, err := dbpool.Exec(ctx, queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert sample into TimescaleDB %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+ }
+ fmt.Println("Successfully inserted samples into sensor_data hypertable")
+ ```
+
+1. [](#)This example `main.go` generates sample data and inserts it into
+ the `sensor_data` hypertable:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ /********************************************/
+ /* Connect using Connection Pool */
+ /********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Insert data into hypertable */
+ /********************************************/
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+
+ //Insert contents of results slice into TimescaleDB
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+
+ //Insert contents of results slice into TimescaleDB
+ for i := range results {
+ var r result
+ r = results[i]
+ _, err := dbpool.Exec(ctx, queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to insert sample into TimescaleDB %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+ }
+ fmt.Println("Successfully inserted samples into sensor_data hypertable")
+ }
+ ```
+
+Inserting multiple rows of data using this method executes as many `insert`
+statements as there are samples to be inserted. This can make ingestion of data
+slow. To speed up ingestion, you can batch insert data instead.
+
+Here's a sample pattern for how to do so, using the sample data you generated in
+the previous procedure. It uses the pgx `Batch` object:
+
+1. This example batch inserts data into the database:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5"
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ /********************************************/
+ /* Connect using Connection Pool */
+ /********************************************/
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ // Generate data to insert
+
+ //SQL query to generate sample data
+ queryDataGeneration := `
+ SELECT generate_series(now() - interval '24 hour', now(), interval '5 minute') AS time,
+ floor(random() * (3) + 1)::int as sensor_id,
+ random()*100 AS temperature,
+ random() AS cpu
+ `
+
+ //Execute query to generate samples for sensor_data hypertable
+ rows, err := dbpool.Query(ctx, queryDataGeneration)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to generate sensor data: %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully generated sensor data")
+
+ //Store data generated in slice results
+ type result struct {
+ Time time.Time
+ SensorId int
+ Temperature float64
+ CPU float64
+ }
+ var results []result
+ for rows.Next() {
+ var r result
+ err = rows.Scan(&r.Time, &r.SensorId, &r.Temperature, &r.CPU)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // Check contents of results slice
+ /*fmt.Println("Contents of RESULTS slice")
+ for i := range results {
+ var r result
+ r = results[i]
+ fmt.Printf("Time: %s | ID: %d | Temperature: %f | CPU: %f |\n", &r.Time, r.SensorId, r.Temperature, r.CPU)
+ }*/
+
+ //Insert contents of results slice into TimescaleDB
+ //SQL query to generate sample data
+ queryInsertTimeseriesData := `
+ INSERT INTO sensor_data (time, sensor_id, temperature, cpu) VALUES ($1, $2, $3, $4);
+ `
+
+ /********************************************/
+ /* Batch Insert into TimescaleDB */
+ /********************************************/
+ //create batch
+ batch := &pgx.Batch{}
+ //load insert statements into batch queue
+ for i := range results {
+ var r result
+ r = results[i]
+ batch.Queue(queryInsertTimeseriesData, r.Time, r.SensorId, r.Temperature, r.CPU)
+ }
+ batch.Queue("select count(*) from sensor_data")
+
+ //send batch to connection pool
+ br := dbpool.SendBatch(ctx, batch)
+ //execute statements in batch queue
+ _, err = br.Exec()
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute statement in batch queue %v\n", err)
+ os.Exit(1)
+ }
+ fmt.Println("Successfully batch inserted data")
+
+ //Compare length of results slice to size of table
+ fmt.Printf("size of results: %d\n", len(results))
+ //check size of table for number of rows inserted
+ // result of last SELECT statement
+ var rowsInserted int
+ err = br.QueryRow().Scan(&rowsInserted)
+ fmt.Printf("size of table: %d\n", rowsInserted)
+
+ err = br.Close()
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to closer batch %v\n", err)
+ os.Exit(1)
+ }
+ }
+ ```
+
+## Execute a query
+
+This section covers how to execute queries against your database.
+
+1. Define the SQL query you'd like to run on the database. This example uses a
+ SQL query that combines time-series and relational data. It returns the
+ average CPU values for every 5 minute interval, for sensors located on
+ location `ceiling` and of type `a`:
+
+ ```go
+ // Formulate query in SQL
+ // Note the use of prepared statement placeholders $1 and $2
+ queryTimebucketFiveMin := `
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = $1 AND sensors.type = $2
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ `
+ ```
+
+1. Use the `.Query()` function to execute the query string. Make sure you
+ specify the relevant placeholders:
+
+ ```go
+ //Execute query on TimescaleDB
+ rows, err := dbpool.Query(ctx, queryTimebucketFiveMin, "ceiling", "a")
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute query %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully executed query")
+ ```
+
+1. Access the rows returned by `.Query()`. Create a struct with fields
+ representing the columns that you expect to be returned, then use the
+ `rows.Next()` function to iterate through the rows returned and fill
+ `results` with the array of structs. This uses the `rows.Scan()` function,
+ passing in pointers to the fields that you want to scan for results.
+
+ This example prints out the results returned from the query, but you might
+ want to use those results for some other purpose. Once you've scanned
+ through all the rows returned you can then use the results array however you
+ like.
+
+ ```go
+ //Do something with the results of query
+ // Struct for results
+ type result2 struct {
+ Bucket time.Time
+ Avg float64
+ }
+
+ // Print rows returned and fill up results slice for later use
+ var results []result2
+ for rows.Next() {
+ var r result2
+ err = rows.Scan(&r.Bucket, &r.Avg)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ fmt.Printf("Time bucket: %s | Avg: %f\n", &r.Bucket, r.Avg)
+ }
+
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+
+ // use results here…
+ ```
+
+1. [](#)This example program runs a query, and accesses the results of
+ that query:
+
+ ```go
+ package main
+
+ import (
+ "context"
+ "fmt"
+ "os"
+ "time"
+
+ "github.com/jackc/pgx/v5/pgxpool"
+ )
+
+ func main() {
+ ctx := context.Background()
+ connStr := "yourConnectionStringHere"
+ dbpool, err := pgxpool.New(ctx, connStr)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to connect to database: %v\n", err)
+ os.Exit(1)
+ }
+ defer dbpool.Close()
+
+ /********************************************/
+ /* Execute a query */
+ /********************************************/
+
+ // Formulate query in SQL
+ // Note the use of prepared statement placeholders $1 and $2
+ queryTimebucketFiveMin := `
+ SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu)
+ FROM sensor_data
+ JOIN sensors ON sensors.id = sensor_data.sensor_id
+ WHERE sensors.location = $1 AND sensors.type = $2
+ GROUP BY five_min
+ ORDER BY five_min DESC;
+ `
+
+ //Execute query on TimescaleDB
+ rows, err := dbpool.Query(ctx, queryTimebucketFiveMin, "ceiling", "a")
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to execute query %v\n", err)
+ os.Exit(1)
+ }
+ defer rows.Close()
+
+ fmt.Println("Successfully executed query")
+
+ //Do something with the results of query
+ // Struct for results
+ type result2 struct {
+ Bucket time.Time
+ Avg float64
+ }
+
+ // Print rows returned and fill up results slice for later use
+ var results []result2
+ for rows.Next() {
+ var r result2
+ err = rows.Scan(&r.Bucket, &r.Avg)
+ if err != nil {
+ fmt.Fprintf(os.Stderr, "Unable to scan %v\n", err)
+ os.Exit(1)
+ }
+ results = append(results, r)
+ fmt.Printf("Time bucket: %s | Avg: %f\n", &r.Bucket, r.Avg)
+ }
+ // Any errors encountered by rows.Next or rows.Scan are returned here
+ if rows.Err() != nil {
+ fmt.Fprintf(os.Stderr, "rows Error: %v\n", rows.Err())
+ os.Exit(1)
+ }
+ }
+ ```
+
+## Next steps
+
+Now that you're able to connect, read, and write to a TimescaleDB instance from
+your Go application, be sure to check out these advanced TimescaleDB tutorials:
+
+* Refer to the [pgx documentation][pgx-docs] for more information about pgx.
+* Get up and running with TimescaleDB with the [Getting Started][getting-started]
+ tutorial.
+* Want fast inserts on CSV data? Check out
+ [TimescaleDB parallel copy][parallel-copy-tool], a tool for fast inserts,
+ written in Go.
+
+
+
+
+## Prerequisites
+
+To follow the steps on this page:
+
+* Create a target [Tiger Cloud service][create-service] with the Real-time analytics capability.
+
+ You need [your connection details][connection-info]. This procedure also
+ works for [self-hosted TimescaleDB][enable-timescaledb].
+
+* Install the [Java Development Kit (JDK)][jdk].
+* Install the [PostgreSQL JDBC driver][pg-jdbc-driver].
+
+All code in this quick start is for Java 16 and later. If you are working
+with older JDK versions, use legacy coding techniques.
+
+## Connect to your Tiger Cloud service
+
+In this section, you create a connection to your service using an application in
+a single file. You can use any of your favorite build tools, including `gradle`
+or `maven`.
+
+1. Create a directory containing a text file called `Main.java`, with this content:
+
+ ```java
+ package com.timescale.java;
+
+ public class Main {
+
+ public static void main(String... args) {
+ System.out.println("Hello, World!");
+ }
+ }
+ ```
+
+1. From the command line in the current directory, run the application:
+
+ ```bash
+ java Main.java
+ ```
+
+ If the command is successful, `Hello, World!` line output is printed
+ to your console.
+
+1. Import the PostgreSQL JDBC driver. If you are using a dependency manager,
+ include the [PostgreSQL JDBC Driver][pg-jdbc-driver-dependency] as a
+ dependency.
+
+1. Download the [JAR artifact of the JDBC Driver][pg-jdbc-driver-artifact] and
+ save it with the `Main.java` file.
+
+1. Import the `JDBC Driver` into the Java application and display a list of
+ available drivers for the check:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+
+ public class Main {
+
+ public static void main(String... args) {
+ DriverManager.drivers().forEach(System.out::println);
+ }
+ }
+ ```
+
+1. Run all the examples:
+
+ ```bash
+ java -cp *.jar Main.java
+ ```
+
+ If the command is successful, a string similar to
+ `org.postgresql.Driver@7f77e91b` is printed to your console. This means that you
+ are ready to connect to TimescaleDB from Java.
+
+1. Locate your TimescaleDB credentials and use them to compose a connection
+ string for JDBC.
+
+ You'll need:
+
+ * password
+ * username
+ * host URL
+ * port
+ * database name
+
+1. Compose your connection string variable, using this format:
+
+ ```java
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ ```
+
+ For more information about creating connection strings, see the [JDBC documentation][pg-jdbc-driver-conn-docs].
+
+
+
+ This method of composing a connection string is for test or development
+ purposes only. For production, use environment variables for sensitive
+ details like your password, hostname, and port number.
+
+
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+
+ public class Main {
+
+ public static void main(String... args) throws SQLException {
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ var conn = DriverManager.getConnection(connUrl);
+ System.out.println(conn.getClientInfo());
+ }
+ }
+ ```
+
+1. Run the code:
+
+ ```bash
+ java -cp *.jar Main.java
+ ```
+
+ If the command is successful, a string similar to
+ `{ApplicationName=PostgreSQL JDBC Driver}` is printed to your console.
+
+## Create a relational table
+
+In this section, you create a table called `sensors` which holds the ID, type,
+and location of your fictional sensors. Additionally, you create a hypertable
+called `sensor_data` which holds the measurements of those sensors. The
+measurements contain the time, sensor_id, temperature reading, and CPU
+percentage of the sensors.
+
+1. Compose a string which contains the SQL statement to create a relational
+ table. This example creates a table called `sensors`, with columns `id`,
+ `type` and `location`:
+
+ ```sql
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ );
+ ```
+
+1. Create a statement, execute the query you created in the previous step, and
+ check that the table was created successfully:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+
+ public class Main {
+
+ public static void main(String... args) throws SQLException {
+ var connUrl = "jdbc:postgresql://:/?user=&password=";
+ var conn = DriverManager.getConnection(connUrl);
+
+ var createSensorTableQuery = """
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ )
+ """;
+ try (var stmt = conn.createStatement()) {
+ stmt.execute(createSensorTableQuery);
+ }
+
+ var showAllTablesQuery = "SELECT tablename FROM pg_catalog.pg_tables WHERE schemaname = 'public'";
+ try (var stmt = conn.createStatement();
+ var rs = stmt.executeQuery(showAllTablesQuery)) {
+ System.out.println("Tables in the current database: ");
+ while (rs.next()) {
+ System.out.println(rs.getString("tablename"));
+ }
+ }
+ }
+ }
+ ```
+
+## Create a hypertable
+
+When you have created the relational table, you can create a hypertable.
+Creating tables and indexes, altering tables, inserting data, selecting data,
+and most other tasks are executed on the hypertable.
+
+1. Create a `CREATE TABLE` SQL statement for
+ your hypertable. Notice how the hypertable has the compulsory time column:
+
+ ```sql
+ CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER REFERENCES sensors (id),
+ value DOUBLE PRECISION
+ );
+ ```
+
+1. Create a statement, execute the query you created in the previous step:
+
+ ```sql
+ SELECT create_hypertable('sensor_data', by_range('time'));
+ ```
+
+
+
+ The `by_range` and `by_hash` dimension builder is an addition to TimescaleDB 2.13.
+
+
+
+1. Execute the two statements you created, and commit your changes to the
+ database:
+
+ ```java
+ package com.timescale.java;
+
+ import java.sql.Connection;
+ import java.sql.DriverManager;
+ import java.sql.SQLException;
+ import java.util.List;
+
+ public class Main {
+
+ public static void main(String... args) {
+ final var connUrl = "jdbc:postgresql://:/?user=&password=";
+ try (var conn = DriverManager.getConnection(connUrl)) {
+ createSchema(conn);
+ insertData(conn);
+ } catch (SQLException ex) {
+ System.err.println(ex.getMessage());
+ }
+ }
+
+ private static void createSchema(final Connection conn) throws SQLException {
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("""
+ CREATE TABLE sensors (
+ id SERIAL PRIMARY KEY,
+ type TEXT NOT NULL,
+ location TEXT NOT NULL
+ )
+ """);
+ }
+
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("""
+ CREATE TABLE sensor_data (
+ time TIMESTAMPTZ NOT NULL,
+ sensor_id INTEGER REFERENCES sensors (id),
+ value DOUBLE PRECISION
+ )
+ """);
+ }
+
+ try (var stmt = conn.createStatement()) {
+ stmt.execute("SELECT create_hypertable('sensor_data', by_range('time'))");
+ }
+ }
+ }
+ ```
+
+## Insert data
+
+You can insert data into your hypertables in several different ways. In this
+section, you can insert single rows, or insert by batches of rows.
+
+1. Open a connection to the database, use prepared statements to formulate the
+ `INSERT` SQL statement, then execute the statement:
+
+ ```java
+ final List