本章涵盖以下内容:
+ **探讨在神经网络中使用注意力机制的原因**
+ **介绍一个基本的自注意力框架,并逐步深入到改进的自注意力机制**
+ **实现一个因果注意力模块,使 LLM 能够一次生成一个token**
+ **使用 dropout 随机掩盖部分注意力权重,以减少过拟合**
在上一章中,你学习了如何准备输入文本以训练 LLM。这包括将文本拆分为单个单词和子词token,这些token可以被编码为向量表示,即所谓的嵌入,以供 LLM 使用。
在本章中,我们将关注 LLM 架构中的重要组成部分,即注意力机制,如图 3.1 所示。
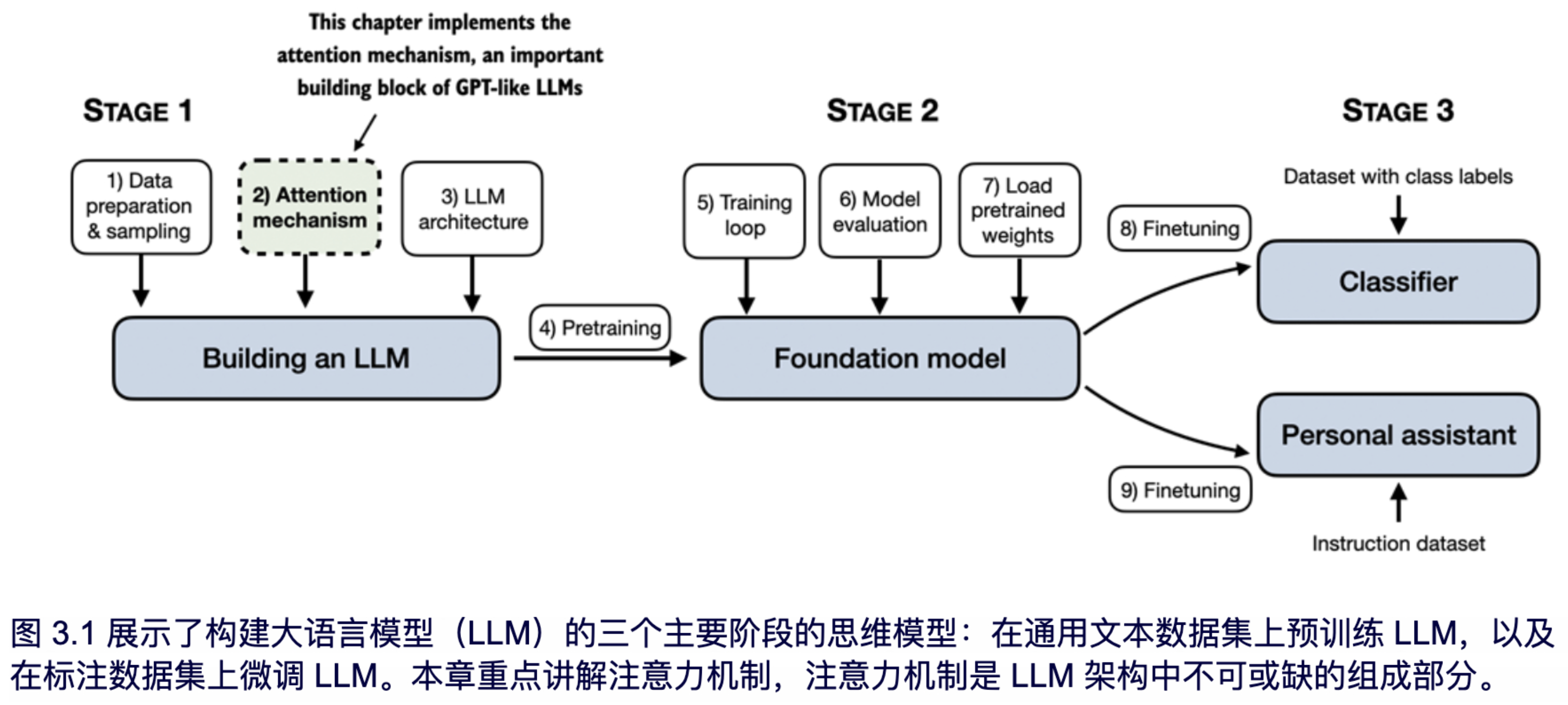 注意力机制是一个复杂的话题,因此我们将专门用一整章来讨论它。我们主要会将注意力机制独立来研究,关注其内部的工作原理。在下一章中,我们将编写环绕自注意力机制的 LLM 其他部分的代码,以便观察它的实际应用,并创建一个能够生成文本的模型。
本章中,我们将实现四种不同的注意力机制变体,如图 3.2 所示。
注意力机制是一个复杂的话题,因此我们将专门用一整章来讨论它。我们主要会将注意力机制独立来研究,关注其内部的工作原理。在下一章中,我们将编写环绕自注意力机制的 LLM 其他部分的代码,以便观察它的实际应用,并创建一个能够生成文本的模型。
本章中,我们将实现四种不同的注意力机制变体,如图 3.2 所示。
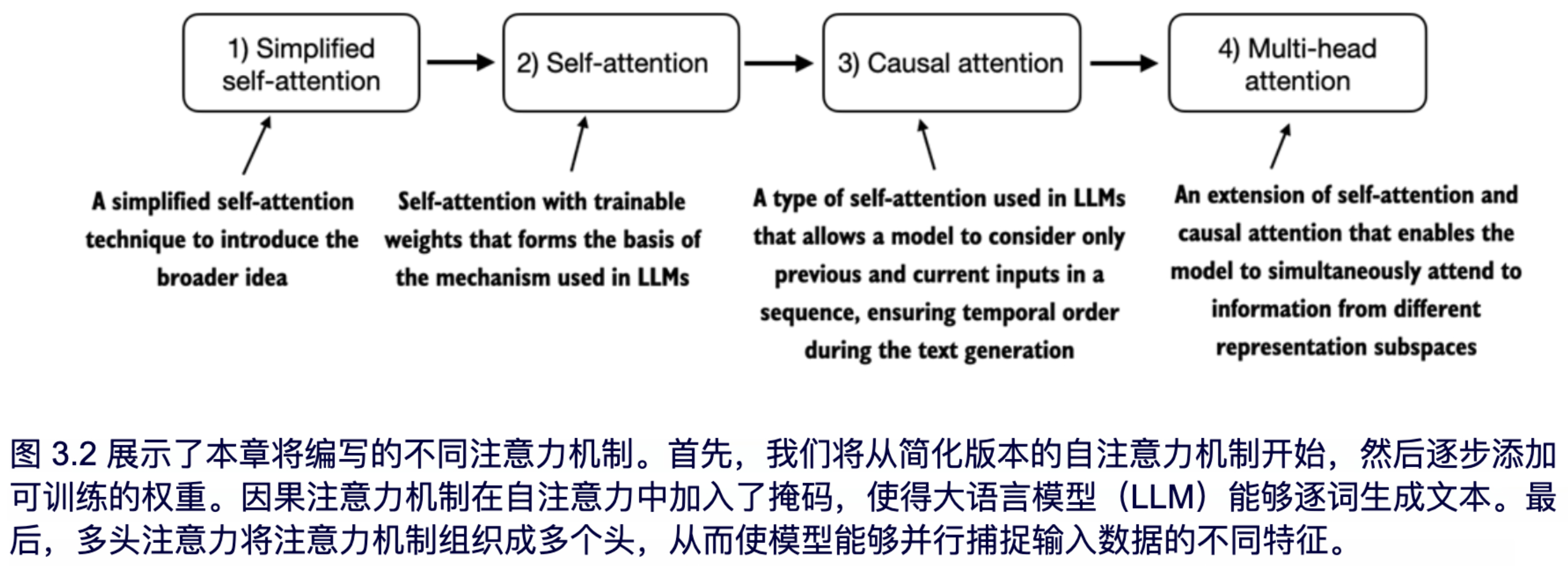 图 3.2 中展示的这些不同的注意力变体是逐步构建的,其目标是在本章末尾实现一个紧凑且高效的多头注意力机制实现,以便在下一章中可以将其整合到我们将编写的 LLM 架构中
## 3.1 长序列建模的问题
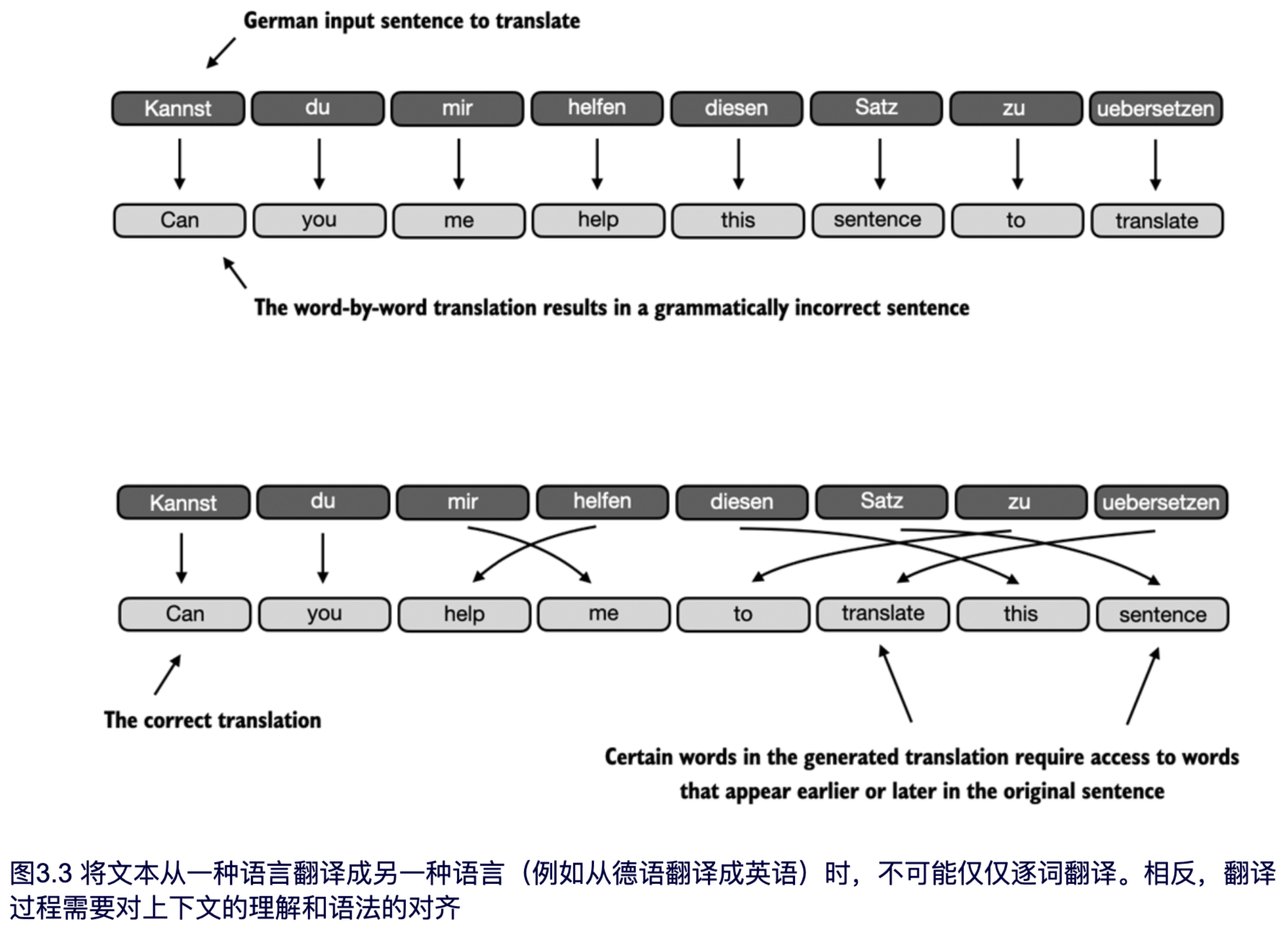
在深入了解自注意力机制之前(这是大语言模型的核心),让我们先探讨一下缺乏注意力机制的架构存在哪些问题(这些架构在大语言模型之前已经存在)。假设我们想要开发一个将一种语言翻译成另一种语言的翻译模型。如图 3.3 所示,我们无法简单地逐词翻译文本,因为源语言和目标语言的语法结构存在差异。
图 3.2 中展示的这些不同的注意力变体是逐步构建的,其目标是在本章末尾实现一个紧凑且高效的多头注意力机制实现,以便在下一章中可以将其整合到我们将编写的 LLM 架构中
## 3.1 长序列建模的问题
在深入了解自注意力机制之前(这是大语言模型的核心),让我们先探讨一下缺乏注意力机制的架构存在哪些问题(这些架构在大语言模型之前已经存在)。假设我们想要开发一个将一种语言翻译成另一种语言的翻译模型。如图 3.3 所示,我们无法简单地逐词翻译文本,因为源语言和目标语言的语法结构存在差异。
 为了解决逐词翻译的局限性,通常使用包含两个子模块的深度神经网络,即所谓的编码器(encoder)和解码器(decoder)。编码器的任务是先读取并处理整个文本,然后解码器生成翻译后的文本。
在第 1 章(1.4 节,使用 LLM 进行不同任务)介绍 Transformer 架构时,我们已经简要讨论过编码器-解码器网络。在 Transformer 出现之前,循环神经网络(RNN)是最流行的用于语言翻译的编码器-解码器架构。
**循环神经网络(RNN)**是一种神经网络类型,其中前一步的输出会作为当前步骤的输入,使其非常适合处理像文本这样的序列数据。如果您不熟悉 RNN 的工作原理,不必担心,您无需了解 RNN 的详细机制也可以参与这里的讨论;我们在这里的重点更多是编码器-解码器结构的总体概念。
在编码器-解码器 RNN 中,输入文本被输入到编码器中,编码器按顺序处理文本内容。在每个步骤中,编码器会更新其隐状态(即隐藏层的内部值),试图在最终的隐状态中捕捉整个输入句子的含义,如图 3.4 所示。然后,解码器使用该最终隐状态来开始逐词生成翻译句子。解码器在每一步也会更新其隐状态,用于携带生成下一个词所需的上下文信息。
为了解决逐词翻译的局限性,通常使用包含两个子模块的深度神经网络,即所谓的编码器(encoder)和解码器(decoder)。编码器的任务是先读取并处理整个文本,然后解码器生成翻译后的文本。
在第 1 章(1.4 节,使用 LLM 进行不同任务)介绍 Transformer 架构时,我们已经简要讨论过编码器-解码器网络。在 Transformer 出现之前,循环神经网络(RNN)是最流行的用于语言翻译的编码器-解码器架构。
**循环神经网络(RNN)**是一种神经网络类型,其中前一步的输出会作为当前步骤的输入,使其非常适合处理像文本这样的序列数据。如果您不熟悉 RNN 的工作原理,不必担心,您无需了解 RNN 的详细机制也可以参与这里的讨论;我们在这里的重点更多是编码器-解码器结构的总体概念。
在编码器-解码器 RNN 中,输入文本被输入到编码器中,编码器按顺序处理文本内容。在每个步骤中,编码器会更新其隐状态(即隐藏层的内部值),试图在最终的隐状态中捕捉整个输入句子的含义,如图 3.4 所示。然后,解码器使用该最终隐状态来开始逐词生成翻译句子。解码器在每一步也会更新其隐状态,用于携带生成下一个词所需的上下文信息。
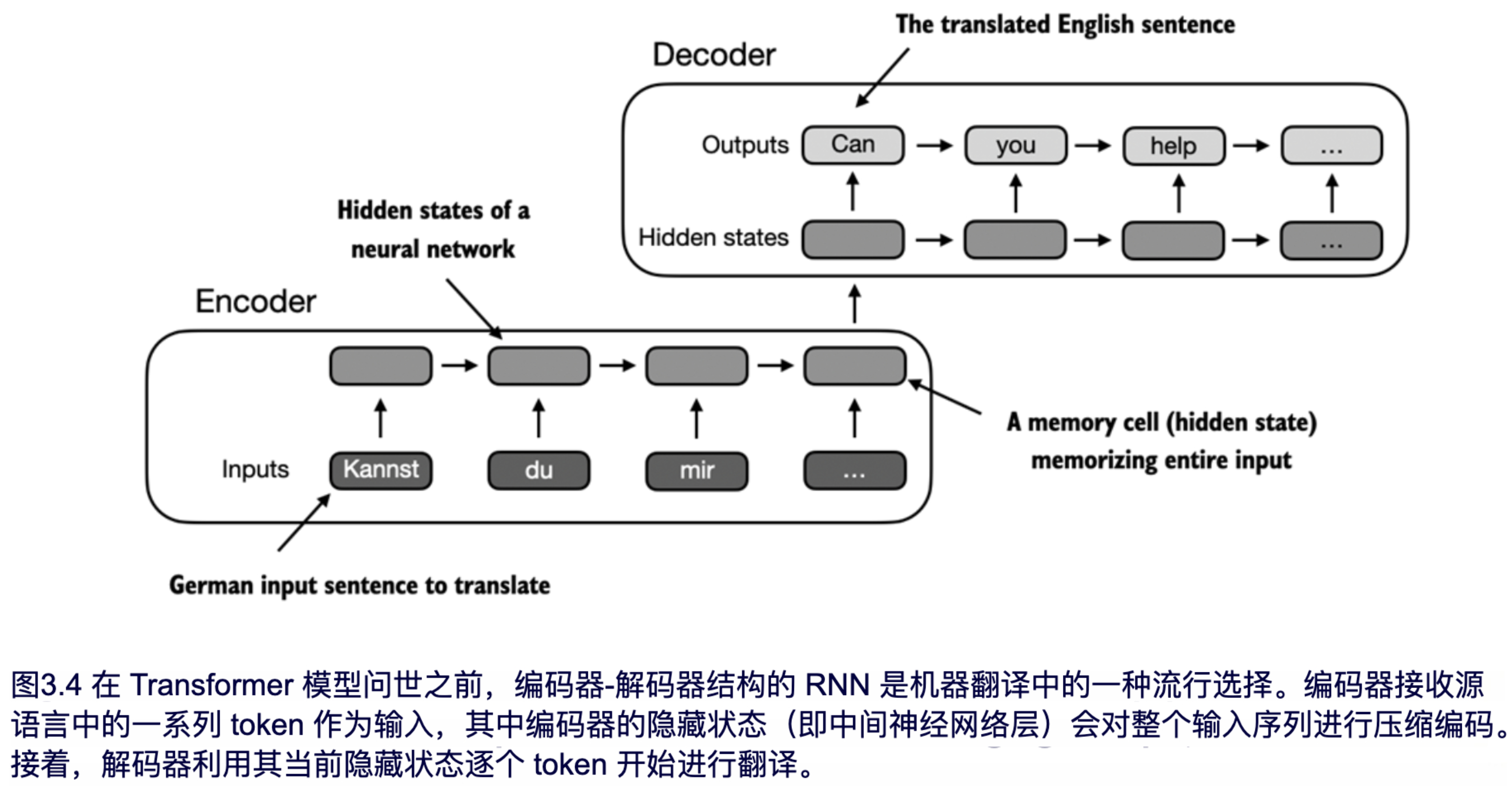 尽管我们不需要深入了解这些编码器-解码器结构 RNN 的内部工作原理,但关键思想在于,编码器部分将整个输入文本处理为一个隐藏状态(记忆单元)。解码器随后使用该隐藏状态生成输出。您可以将这个隐藏状态视为一个嵌入向量,这是我们在第 2 章中讨论的概念。
编码器-解码器结构的 RNN 的一个重大问题和限制在于,**在解码阶段 RNN 无法直接访问编码器的早期隐藏状态**。因此,它只能依赖当前隐藏状态来封装所有相关信息。这种设计可能导致上下文信息的丢失,特别是在依赖关系较长的复杂句子中,这一问题尤为突出。
对于不熟悉 RNN 的读者,不必深入理解或学习这种架构,因为本书中不会使用它。本节的重点是,编码器-解码器 RNN 存在一个缺点,这一缺点促使了注意力机制的设计。
> [!TIP]
>
> **个人思考:** 虽然本书没有涉及对RNN的过多讨论,但了解从RNN到注意力机制的技术变迁对于核心内容的理解至关重要。让我们通过一个具体的示例来理解这种技术变迁:
>
> 1. **RNN的局限性**
>
> 假设我们有一个长句子:“The cat, who was sitting on the windowsill, jumped down because it saw a bird flying outside the window.”
>
> 假设任务是预测句子最后的内容,即要理解“it”指的是“the cat”而不是“the windowsill”或其他内容。对于 RNN 来说,这个任务是有难度的,原因如下:
>
> + **长距离依赖问题**:在 RNN 中,每个新输入的词会被依次传递到下一个时间步。随着句子长度增加,模型的隐状态会不断被更新,但早期信息(如“the cat”)会在层层传播中逐渐消失。因此,模型可能无法在“it”出现时有效地记住“the cat”是“it”的指代对象。
> + **梯度消失问题**:RNN 在反向传播中的梯度会随着时间步的增加逐渐减小,这种“梯度消失”使得模型很难在长句中保持信息的准确传播,从而难以捕捉到长距离的语义关联。
>
> 2. **注意力机制的解决方法**
>
> 为了弥补 RNN 的这些不足,**注意力机制**被引入。它的关键思想是**在处理每个词时,不仅依赖于最后的隐藏状态,而是允许模型直接关注序列中的所有词**。这样,即使是较远的词也能在模型计算当前词的语义时直接参与。
>
> 在上例中,注意力机制如何帮助模型理解“it”指代“the cat”呢?
>
> + **注意力机制的工作原理**:当模型处理“it”时,注意力机制会将“it”与整个句子中的其他词进行相似度计算,判断“it”应该关注哪些词。
> + 由于“the cat”与“it”在语义上更相关,注意力机制会为“the cat”分配较高的权重,而其他词(如“windowsill”或“down”)则获得较低的权重。
> + **信息的直接引用**:通过注意力机制,模型可以跳过中间步骤,直接将“it”与“the cat”关联,而不需要依赖所有的中间隐藏状态。
>
> 3. **示例中的注意力矩阵**
>
> 假设使用一个简单的注意力矩阵,模型在处理“it”时,给每个词的权重可能如下(至于如何计算这些权重值后文会详细介绍):
>
> | 词 | The | cat | who | was | sitting | ... | it | saw | bird | flying | ... | window |
> | -------- | ---- | ---- | ---- | ---- | ------- | ---- | ---- | ---- | ---- | ------ | ---- | ------ |
> | **权重** | 0.1 | 0.3 | 0.05 | 0.05 | 0.05 | ... | 0.4 | 0.05 | 0.02 | 0.01 | ... | 0.02 |
>
> 在这个注意力矩阵中,可以看到**“it”对“the cat”有较高的关注权重(0.3),而对其他词的关注权重较低**。这种直接的关注能力让模型能够高效捕捉长距离依赖关系,理解“it”与“the cat”的语义关联。
## 3.2 通过注意力机制捕捉数据依赖关系
在 Transformer 架构的大语言模型(LLM)出现之前,通常会使用循环神经网络(RNN)来完成语言建模任务,例如语言翻译。RNN 对于翻译短句表现良好,但在处理长文本时效果不佳,因为它们无法直接访问输入序列中的前面词语。
这一方法的一个主要缺陷在于,RNN 必须将整个编码后的输入信息存储在一个隐藏状态中,然后再将其传递给解码器,如上一节的图 3.4 所示。
因此,研究人员在 2014 年为 RNN 开发了所谓的 Bahdanau 注意力机制(该机制以论文的第一作者命名)。该机制对编码器-解码器 RNN 进行了改进,使得解码器在每个解码步骤可以选择性地访问输入序列的不同部分,如图 3.5 所示。
尽管我们不需要深入了解这些编码器-解码器结构 RNN 的内部工作原理,但关键思想在于,编码器部分将整个输入文本处理为一个隐藏状态(记忆单元)。解码器随后使用该隐藏状态生成输出。您可以将这个隐藏状态视为一个嵌入向量,这是我们在第 2 章中讨论的概念。
编码器-解码器结构的 RNN 的一个重大问题和限制在于,**在解码阶段 RNN 无法直接访问编码器的早期隐藏状态**。因此,它只能依赖当前隐藏状态来封装所有相关信息。这种设计可能导致上下文信息的丢失,特别是在依赖关系较长的复杂句子中,这一问题尤为突出。
对于不熟悉 RNN 的读者,不必深入理解或学习这种架构,因为本书中不会使用它。本节的重点是,编码器-解码器 RNN 存在一个缺点,这一缺点促使了注意力机制的设计。
> [!TIP]
>
> **个人思考:** 虽然本书没有涉及对RNN的过多讨论,但了解从RNN到注意力机制的技术变迁对于核心内容的理解至关重要。让我们通过一个具体的示例来理解这种技术变迁:
>
> 1. **RNN的局限性**
>
> 假设我们有一个长句子:“The cat, who was sitting on the windowsill, jumped down because it saw a bird flying outside the window.”
>
> 假设任务是预测句子最后的内容,即要理解“it”指的是“the cat”而不是“the windowsill”或其他内容。对于 RNN 来说,这个任务是有难度的,原因如下:
>
> + **长距离依赖问题**:在 RNN 中,每个新输入的词会被依次传递到下一个时间步。随着句子长度增加,模型的隐状态会不断被更新,但早期信息(如“the cat”)会在层层传播中逐渐消失。因此,模型可能无法在“it”出现时有效地记住“the cat”是“it”的指代对象。
> + **梯度消失问题**:RNN 在反向传播中的梯度会随着时间步的增加逐渐减小,这种“梯度消失”使得模型很难在长句中保持信息的准确传播,从而难以捕捉到长距离的语义关联。
>
> 2. **注意力机制的解决方法**
>
> 为了弥补 RNN 的这些不足,**注意力机制**被引入。它的关键思想是**在处理每个词时,不仅依赖于最后的隐藏状态,而是允许模型直接关注序列中的所有词**。这样,即使是较远的词也能在模型计算当前词的语义时直接参与。
>
> 在上例中,注意力机制如何帮助模型理解“it”指代“the cat”呢?
>
> + **注意力机制的工作原理**:当模型处理“it”时,注意力机制会将“it”与整个句子中的其他词进行相似度计算,判断“it”应该关注哪些词。
> + 由于“the cat”与“it”在语义上更相关,注意力机制会为“the cat”分配较高的权重,而其他词(如“windowsill”或“down”)则获得较低的权重。
> + **信息的直接引用**:通过注意力机制,模型可以跳过中间步骤,直接将“it”与“the cat”关联,而不需要依赖所有的中间隐藏状态。
>
> 3. **示例中的注意力矩阵**
>
> 假设使用一个简单的注意力矩阵,模型在处理“it”时,给每个词的权重可能如下(至于如何计算这些权重值后文会详细介绍):
>
> | 词 | The | cat | who | was | sitting | ... | it | saw | bird | flying | ... | window |
> | -------- | ---- | ---- | ---- | ---- | ------- | ---- | ---- | ---- | ---- | ------ | ---- | ------ |
> | **权重** | 0.1 | 0.3 | 0.05 | 0.05 | 0.05 | ... | 0.4 | 0.05 | 0.02 | 0.01 | ... | 0.02 |
>
> 在这个注意力矩阵中,可以看到**“it”对“the cat”有较高的关注权重(0.3),而对其他词的关注权重较低**。这种直接的关注能力让模型能够高效捕捉长距离依赖关系,理解“it”与“the cat”的语义关联。
## 3.2 通过注意力机制捕捉数据依赖关系
在 Transformer 架构的大语言模型(LLM)出现之前,通常会使用循环神经网络(RNN)来完成语言建模任务,例如语言翻译。RNN 对于翻译短句表现良好,但在处理长文本时效果不佳,因为它们无法直接访问输入序列中的前面词语。
这一方法的一个主要缺陷在于,RNN 必须将整个编码后的输入信息存储在一个隐藏状态中,然后再将其传递给解码器,如上一节的图 3.4 所示。
因此,研究人员在 2014 年为 RNN 开发了所谓的 Bahdanau 注意力机制(该机制以论文的第一作者命名)。该机制对编码器-解码器 RNN 进行了改进,使得解码器在每个解码步骤可以选择性地访问输入序列的不同部分,如图 3.5 所示。
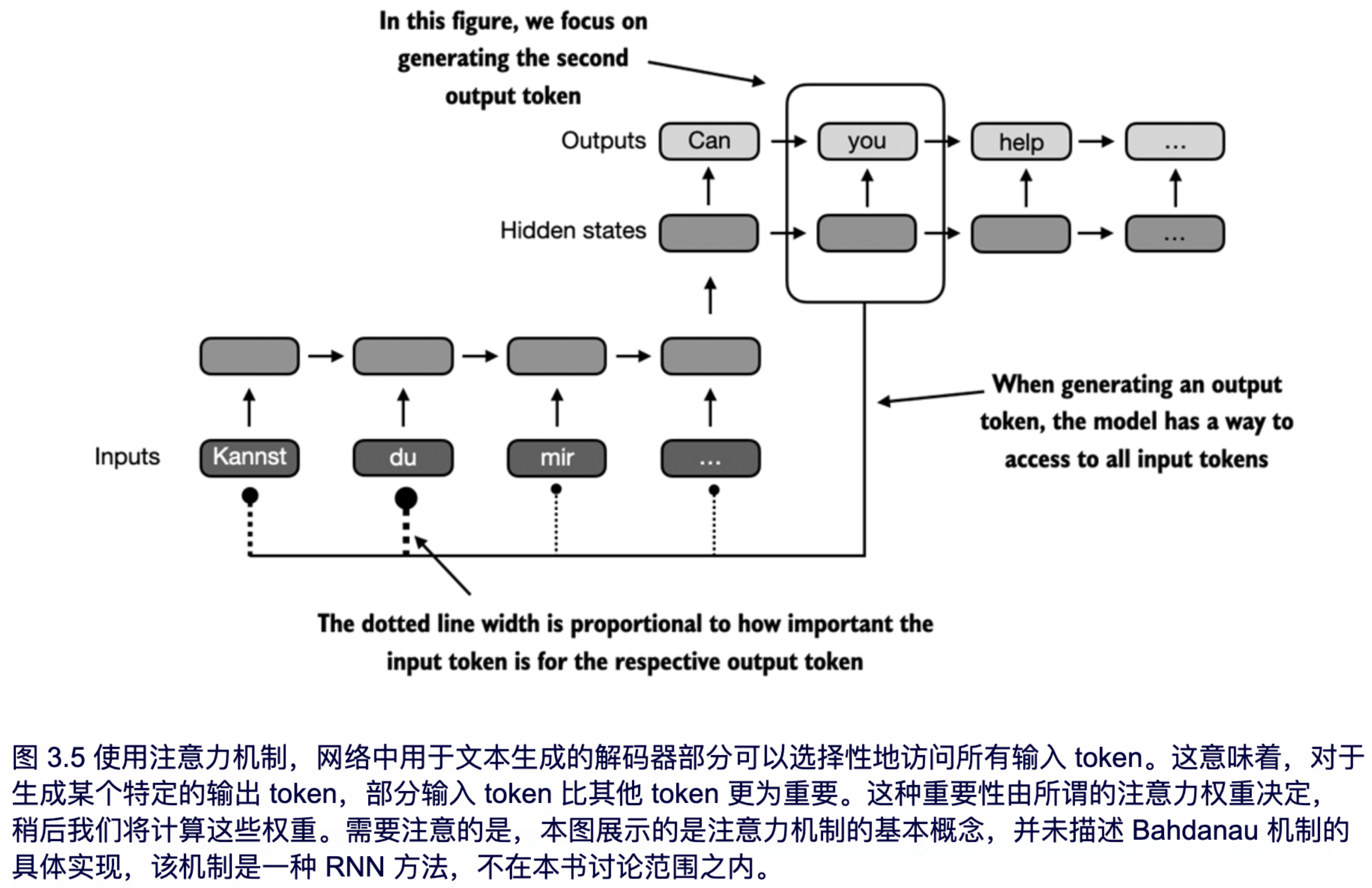 有趣的是,仅仅三年后,研究人员发现构建用于自然语言处理的深度神经网络并不需要 RNN 结构,并提出了基于自注意力机制的原始 Transformer 架构(在第 1 章中讨论),其灵感来自 Bahdanau 提出的注意力机制。
自注意力机制是一种允许输入序列中的每个位置在计算序列表示时关注同一序列中所有位置的机制。自注意力机制是基于Transformer架构的当代大语言模型(如GPT系列模型)的关键组成部分。
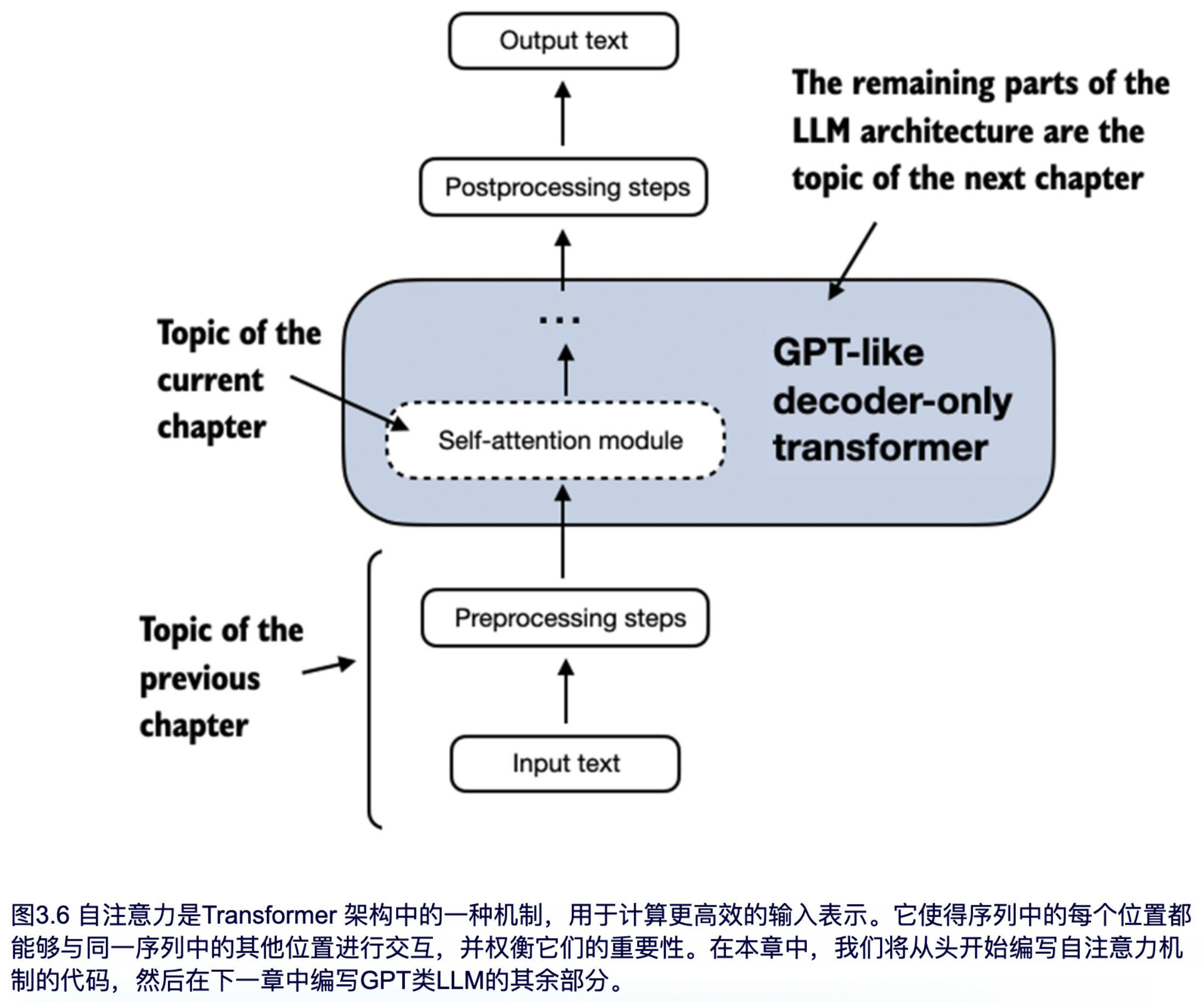
本章将重点讲解并实现 GPT 类模型中使用的自注意力机制,如图 3.6 所示。在下一章中,我们将继续编码 LLM 的其它部分。
有趣的是,仅仅三年后,研究人员发现构建用于自然语言处理的深度神经网络并不需要 RNN 结构,并提出了基于自注意力机制的原始 Transformer 架构(在第 1 章中讨论),其灵感来自 Bahdanau 提出的注意力机制。
自注意力机制是一种允许输入序列中的每个位置在计算序列表示时关注同一序列中所有位置的机制。自注意力机制是基于Transformer架构的当代大语言模型(如GPT系列模型)的关键组成部分。
本章将重点讲解并实现 GPT 类模型中使用的自注意力机制,如图 3.6 所示。在下一章中,我们将继续编码 LLM 的其它部分。
 ## 3.3 通过自注意力机制关注输入的不同部分
现在我们将深入了解自注意力机制的内部工作原理,并从零开始学习如何实现它。自注意力机制是基于 Transformer 架构的每一个大语言模型的核心。需要注意的是,这一部分内容可能需要大量的专注与投入(无双关含义),但一旦掌握了它的基本原理,你就攻克了本书及大语言模型实现中最困难的部分之一。
> [!NOTE]
>
> **“自我”在自注意力机制中的含义**
>
> 在自注意力机制中,“self”指的是该机制通过关联同一输入序列中的不同位置来计算注意力权重的能力。它评估并学习输入内部各部分之间的关系和依赖性,例如句子中的单词或图像中的像素。这与传统注意力机制不同,传统机制关注的是两个不同序列间的关系,例如序列到序列模型中,注意力可能存在于输入序列和输出序列之间,这一点在图 3.5 中有示例说明。
由于自注意力机制可能显得较为复杂,尤其是对于初次接触的读者,我们将在下一小节中首先介绍一个简化版的自注意力机制。随后,在第 3.4 节中,我们将实现带有可训练权重的自注意力机制,这种机制被用于大语言模型(LLM)中。
### 3.3.1 一种不含可训练权重的简单自注意力机制。
在本节中,我们实现了一个简化的自注意力机制版本,没有包含任何可训练的权重,如图 3.7 所示。本节的目标是先介绍自注意力机制中的一些关键概念,然后在 3.4 节引入可训练的权重。
## 3.3 通过自注意力机制关注输入的不同部分
现在我们将深入了解自注意力机制的内部工作原理,并从零开始学习如何实现它。自注意力机制是基于 Transformer 架构的每一个大语言模型的核心。需要注意的是,这一部分内容可能需要大量的专注与投入(无双关含义),但一旦掌握了它的基本原理,你就攻克了本书及大语言模型实现中最困难的部分之一。
> [!NOTE]
>
> **“自我”在自注意力机制中的含义**
>
> 在自注意力机制中,“self”指的是该机制通过关联同一输入序列中的不同位置来计算注意力权重的能力。它评估并学习输入内部各部分之间的关系和依赖性,例如句子中的单词或图像中的像素。这与传统注意力机制不同,传统机制关注的是两个不同序列间的关系,例如序列到序列模型中,注意力可能存在于输入序列和输出序列之间,这一点在图 3.5 中有示例说明。
由于自注意力机制可能显得较为复杂,尤其是对于初次接触的读者,我们将在下一小节中首先介绍一个简化版的自注意力机制。随后,在第 3.4 节中,我们将实现带有可训练权重的自注意力机制,这种机制被用于大语言模型(LLM)中。
### 3.3.1 一种不含可训练权重的简单自注意力机制。
在本节中,我们实现了一个简化的自注意力机制版本,没有包含任何可训练的权重,如图 3.7 所示。本节的目标是先介绍自注意力机制中的一些关键概念,然后在 3.4 节引入可训练的权重。
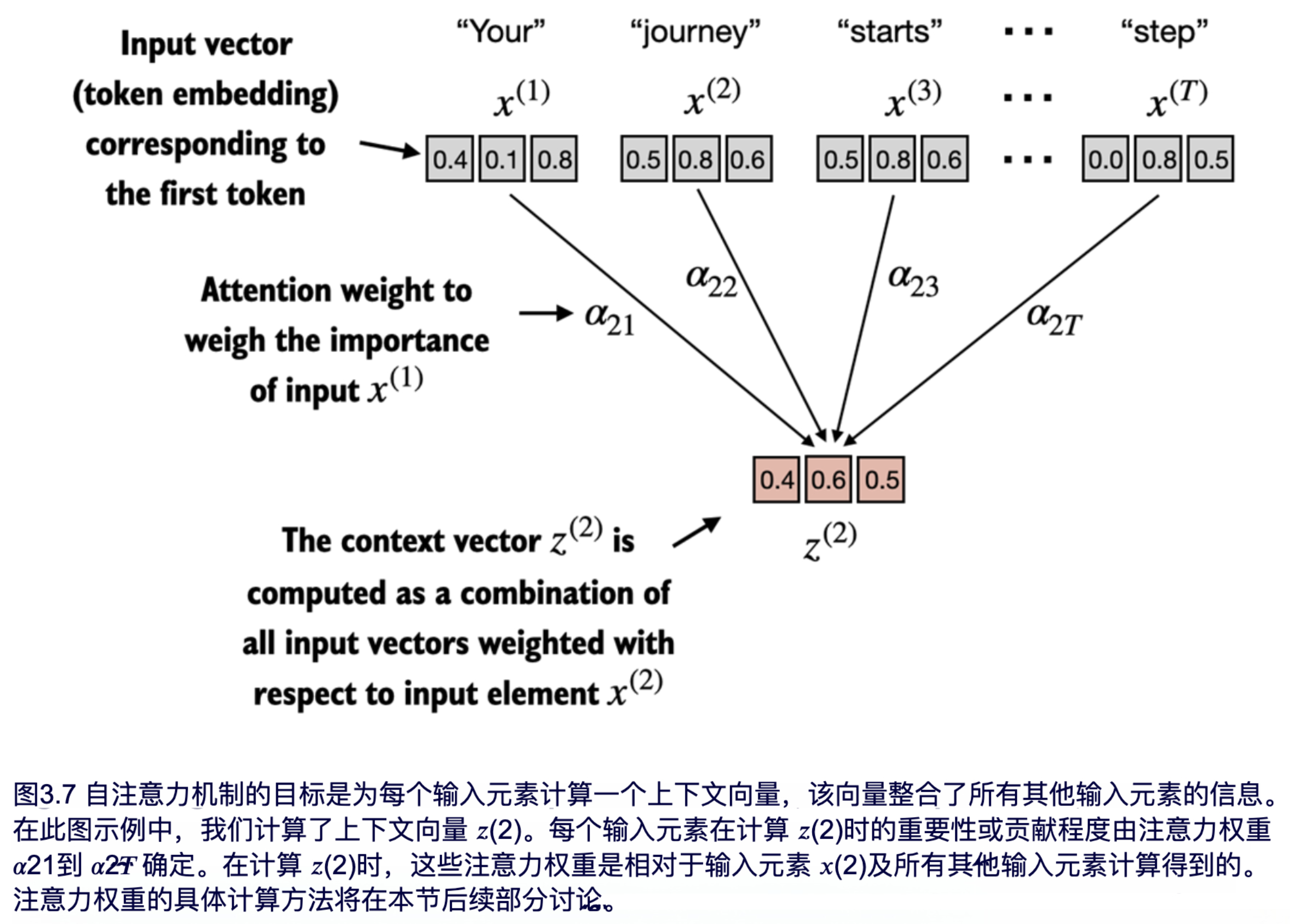 图 3.7 显示了一个输入序列,记作 x,由 T 个元素组成,表示为 x(1) 到 x(T)。该序列通常代表文本,例如一个句子,并且该文本已被转换为 token 嵌入,如第 2 章所述。
举例来说,假设输入文本为 “Your journey starts with one step”。在这个例子中,序列中的每个元素(如 `x(1)`)对应一个 `d` 维的嵌入向量,用于表示特定的 token,例如 “Your”。在图 3.7 中,这些输入向量显示为 3 维的嵌入向量。
在自注意力机制中,我们的目标是为输入序列中的每个元素 x(i) 计算其对应的上下文向量 z(i) 。上下文向量可以被解释为一种增强的嵌入向量。
为了说明这个概念,我们聚焦于第二个输入元素 x(2) 的嵌入向量(对应于词 "journey")以及相应的上下文向量 z(2),如图 3.7 底部所示。这个增强的上下文向量 z(2) 是一个嵌入向量,包含了关于 x(2) 以及所有其他输入元素 x(1) 到 x(T) 的信息。
在自注意力机制中,上下文向量起着关键作用。它们的目的是通过整合序列中所有其他元素的信息(如同一个句子中的其他词),为输入序列中的每个元素创建丰富的表示,正如图 3.7 所示。这对大语言模型至关重要,因为模型需要理解句子中各个词之间的关系和关联性。之后,我们将添加可训练的权重,以帮助大语言模型学习构建这些上下文向量,使其与生成下一个词的任务相关。
在本节中,我们实现了一个简化的自注意力机制,以逐步计算这些权重和生成的上下文向量。
请考虑以下输入句子,该句子已经根据第 2 章的讨论转换为三维向量表示。为了便于说明和展示,我们选择了较小的嵌入维度,以确保句子在页面上可以无换行地展示。
```python
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
```
实现自注意力机制的第一步是计算中间值 **ω**,即注意力得分,如图 3.8 所示。请注意,图 3.8 中前一层输入张量的值为截断版本,例如 0.87 因空间限制被截断为 0.8。在这个截断版本中,单词 "journey" 和 "starts" 的嵌入向量可能会由于随机因素而看起来相似。
图 3.7 显示了一个输入序列,记作 x,由 T 个元素组成,表示为 x(1) 到 x(T)。该序列通常代表文本,例如一个句子,并且该文本已被转换为 token 嵌入,如第 2 章所述。
举例来说,假设输入文本为 “Your journey starts with one step”。在这个例子中,序列中的每个元素(如 `x(1)`)对应一个 `d` 维的嵌入向量,用于表示特定的 token,例如 “Your”。在图 3.7 中,这些输入向量显示为 3 维的嵌入向量。
在自注意力机制中,我们的目标是为输入序列中的每个元素 x(i) 计算其对应的上下文向量 z(i) 。上下文向量可以被解释为一种增强的嵌入向量。
为了说明这个概念,我们聚焦于第二个输入元素 x(2) 的嵌入向量(对应于词 "journey")以及相应的上下文向量 z(2),如图 3.7 底部所示。这个增强的上下文向量 z(2) 是一个嵌入向量,包含了关于 x(2) 以及所有其他输入元素 x(1) 到 x(T) 的信息。
在自注意力机制中,上下文向量起着关键作用。它们的目的是通过整合序列中所有其他元素的信息(如同一个句子中的其他词),为输入序列中的每个元素创建丰富的表示,正如图 3.7 所示。这对大语言模型至关重要,因为模型需要理解句子中各个词之间的关系和关联性。之后,我们将添加可训练的权重,以帮助大语言模型学习构建这些上下文向量,使其与生成下一个词的任务相关。
在本节中,我们实现了一个简化的自注意力机制,以逐步计算这些权重和生成的上下文向量。
请考虑以下输入句子,该句子已经根据第 2 章的讨论转换为三维向量表示。为了便于说明和展示,我们选择了较小的嵌入维度,以确保句子在页面上可以无换行地展示。
```python
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
```
实现自注意力机制的第一步是计算中间值 **ω**,即注意力得分,如图 3.8 所示。请注意,图 3.8 中前一层输入张量的值为截断版本,例如 0.87 因空间限制被截断为 0.8。在这个截断版本中,单词 "journey" 和 "starts" 的嵌入向量可能会由于随机因素而看起来相似。
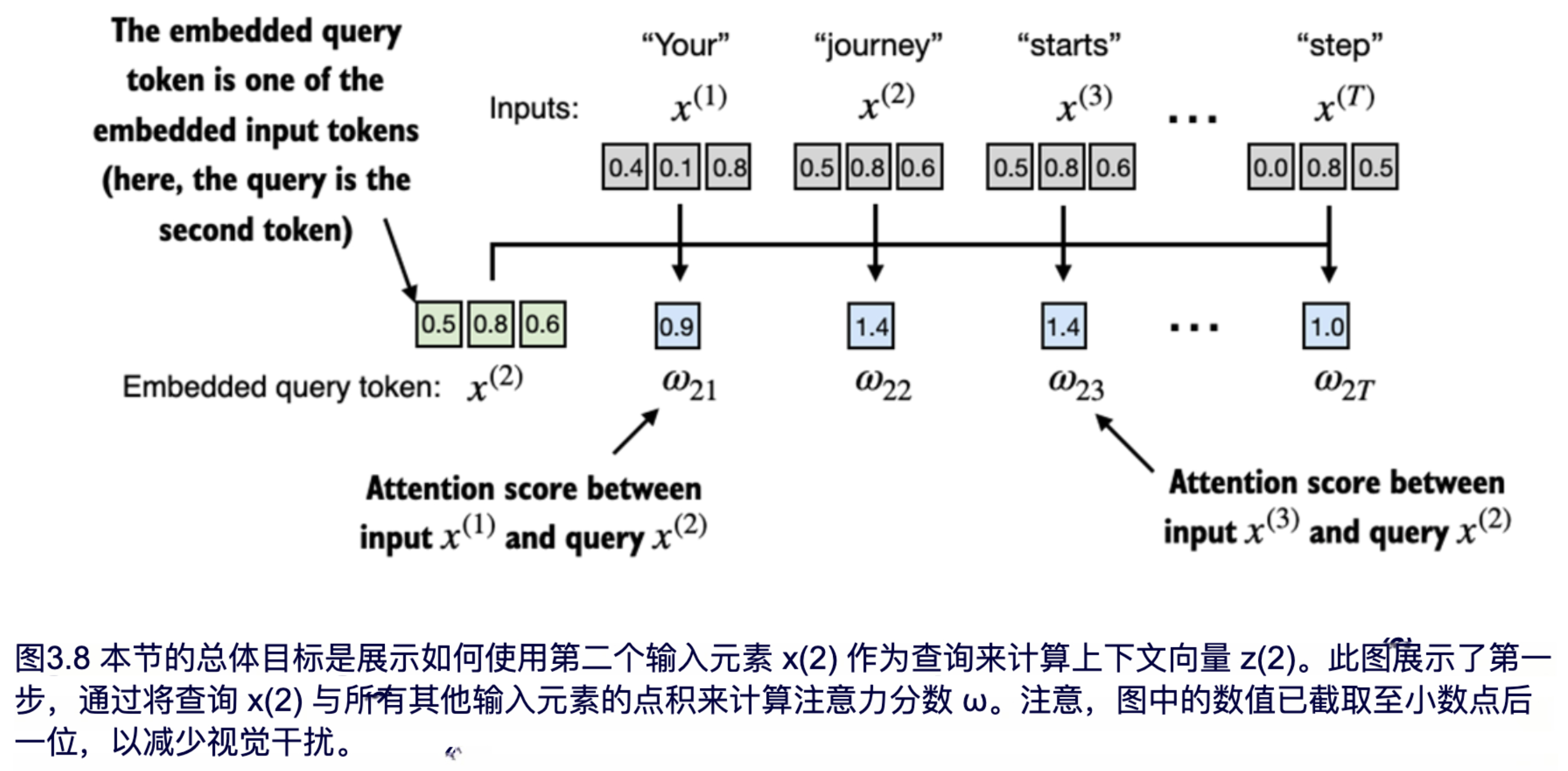 图 3.8 说明了如何计算查询 token 与每个输入 token 之间的中间注意力得分。我们通过计算查询 token x(2)x(2)x(2) 与每个其他输入 token 的点积来确定这些得分。
```python
query = inputs[1] #A
attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores_2[i] = torch.dot(x_i, query)
print(attn_scores_2)
#A 第二个输入 token 用作查询向量
```
> [!TIP]
>
> **个人思考:** 这里对于注意力得分的计算描述的比较笼统,仅仅说明了将当前的输入Token向量与其它Token的向量进行点积运算计算注意力得分,实际上,每个输入Token会先通过权重矩阵W分别计算出它的Q、K、V三个向量,这三个向量的定义如下:
>
> + **Q向量(查询向量)**:查询向量代表了这个词在寻找相关信息时提出的问题
> + **K向量(键向量)**:键向量代表了一个单词的特征,或者说是这个单词如何"展示"自己,以便其它单词可以与它进行匹配
> + **V向量(值向量)**:值向量携带的是这个单词的具体信息,也就是当一个单词被"注意到"时,它提供给关注者的内容
>
> **更通俗的理解:** 想象我们在图书馆寻找一本书(`Q向量`),我们知道要找的主题(`Q向量`),于是查询目录(`K向量`),目录告诉我哪本书涉及这个主题,最终我找到这本书并阅读内容(`V向量`),获取了我需要的信息。
>
> 具体生成Q、K、V向量的方式主要通过线性变换:
>
> ```python
> Q1 = W_Q * (E1 + Pos1)
> K1 = W_K * (E1 + Pos1)
> V1 = W_V * (E1 + Pos1)
> ```
>
> 依次类推,为所有token生成`Q`,`K`,`V`向量,其中`W_Q`,`W_K`和`W_V`是Transformer训练出的权重(每一层不同)
>
> 针对每一个目标token,Transformer会计算它的 `Q向量` 与其它所有的token的 `K向量` 的点积,以确定每个词对当前词的重要性(即注意力分数)
>
> 假如有句子:“The cat drank the milk because it was hungry”
>
> 例如对于词 `cat` 的 `Q向量 Q_cat`,模型会计算:
>
> + `score_cat_the = Q_cat · K_the` --- 与`the`的语义相关度
> + `score_cat_drank = Q_cat · K_drank` --- 与 `drank` 的语义相关度
> + `score_cat_it = Q_cat · K_it` --- 与 `it` 的语义相关度
> + 依此类推,得到`cat`与句子中其它所有token的注意力分数 `[score_cat_the、score_cat_drank、socre_cat_it、……]`
计算得到的注意力得分如下:
```
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
```
> [!NOTE]
>
> **理解点积**
>
> 点积运算本质上是一种将两个向量按元素相乘后再求和的简洁方式,我们可以如下演示:
>
> ```python
> res = 0.
> for idx, element in enumerate(inputs[0]):
> res += inputs[0][idx] * query[idx]
> print(res)
> print(torch.dot(inputs[0], query))
> ```
>
> 输出结果确认,逐元素相乘的和与点积的结果相同。
>
> ```
> tensor(0.9544)
> tensor(0.9544)
> ```
>
> 除了将点积运算视为结合两个向量并产生标量结果的数学工具之外,点积也是一种相似度的衡量方法,因为它量化了两个向量的对齐程度:较高的点积值表示向量之间有更高的对齐程度或相似度。在自注意力机制的背景下,点积决定了序列中元素之间的关注程度:点积值越高,两个元素之间的相似度和注意力得分就越高。
如图 3.9 所示,接下来,我们对先前计算的每个注意力分数进行归一化。
图 3.8 说明了如何计算查询 token 与每个输入 token 之间的中间注意力得分。我们通过计算查询 token x(2)x(2)x(2) 与每个其他输入 token 的点积来确定这些得分。
```python
query = inputs[1] #A
attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores_2[i] = torch.dot(x_i, query)
print(attn_scores_2)
#A 第二个输入 token 用作查询向量
```
> [!TIP]
>
> **个人思考:** 这里对于注意力得分的计算描述的比较笼统,仅仅说明了将当前的输入Token向量与其它Token的向量进行点积运算计算注意力得分,实际上,每个输入Token会先通过权重矩阵W分别计算出它的Q、K、V三个向量,这三个向量的定义如下:
>
> + **Q向量(查询向量)**:查询向量代表了这个词在寻找相关信息时提出的问题
> + **K向量(键向量)**:键向量代表了一个单词的特征,或者说是这个单词如何"展示"自己,以便其它单词可以与它进行匹配
> + **V向量(值向量)**:值向量携带的是这个单词的具体信息,也就是当一个单词被"注意到"时,它提供给关注者的内容
>
> **更通俗的理解:** 想象我们在图书馆寻找一本书(`Q向量`),我们知道要找的主题(`Q向量`),于是查询目录(`K向量`),目录告诉我哪本书涉及这个主题,最终我找到这本书并阅读内容(`V向量`),获取了我需要的信息。
>
> 具体生成Q、K、V向量的方式主要通过线性变换:
>
> ```python
> Q1 = W_Q * (E1 + Pos1)
> K1 = W_K * (E1 + Pos1)
> V1 = W_V * (E1 + Pos1)
> ```
>
> 依次类推,为所有token生成`Q`,`K`,`V`向量,其中`W_Q`,`W_K`和`W_V`是Transformer训练出的权重(每一层不同)
>
> 针对每一个目标token,Transformer会计算它的 `Q向量` 与其它所有的token的 `K向量` 的点积,以确定每个词对当前词的重要性(即注意力分数)
>
> 假如有句子:“The cat drank the milk because it was hungry”
>
> 例如对于词 `cat` 的 `Q向量 Q_cat`,模型会计算:
>
> + `score_cat_the = Q_cat · K_the` --- 与`the`的语义相关度
> + `score_cat_drank = Q_cat · K_drank` --- 与 `drank` 的语义相关度
> + `score_cat_it = Q_cat · K_it` --- 与 `it` 的语义相关度
> + 依此类推,得到`cat`与句子中其它所有token的注意力分数 `[score_cat_the、score_cat_drank、socre_cat_it、……]`
计算得到的注意力得分如下:
```
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
```
> [!NOTE]
>
> **理解点积**
>
> 点积运算本质上是一种将两个向量按元素相乘后再求和的简洁方式,我们可以如下演示:
>
> ```python
> res = 0.
> for idx, element in enumerate(inputs[0]):
> res += inputs[0][idx] * query[idx]
> print(res)
> print(torch.dot(inputs[0], query))
> ```
>
> 输出结果确认,逐元素相乘的和与点积的结果相同。
>
> ```
> tensor(0.9544)
> tensor(0.9544)
> ```
>
> 除了将点积运算视为结合两个向量并产生标量结果的数学工具之外,点积也是一种相似度的衡量方法,因为它量化了两个向量的对齐程度:较高的点积值表示向量之间有更高的对齐程度或相似度。在自注意力机制的背景下,点积决定了序列中元素之间的关注程度:点积值越高,两个元素之间的相似度和注意力得分就越高。
如图 3.9 所示,接下来,我们对先前计算的每个注意力分数进行归一化。
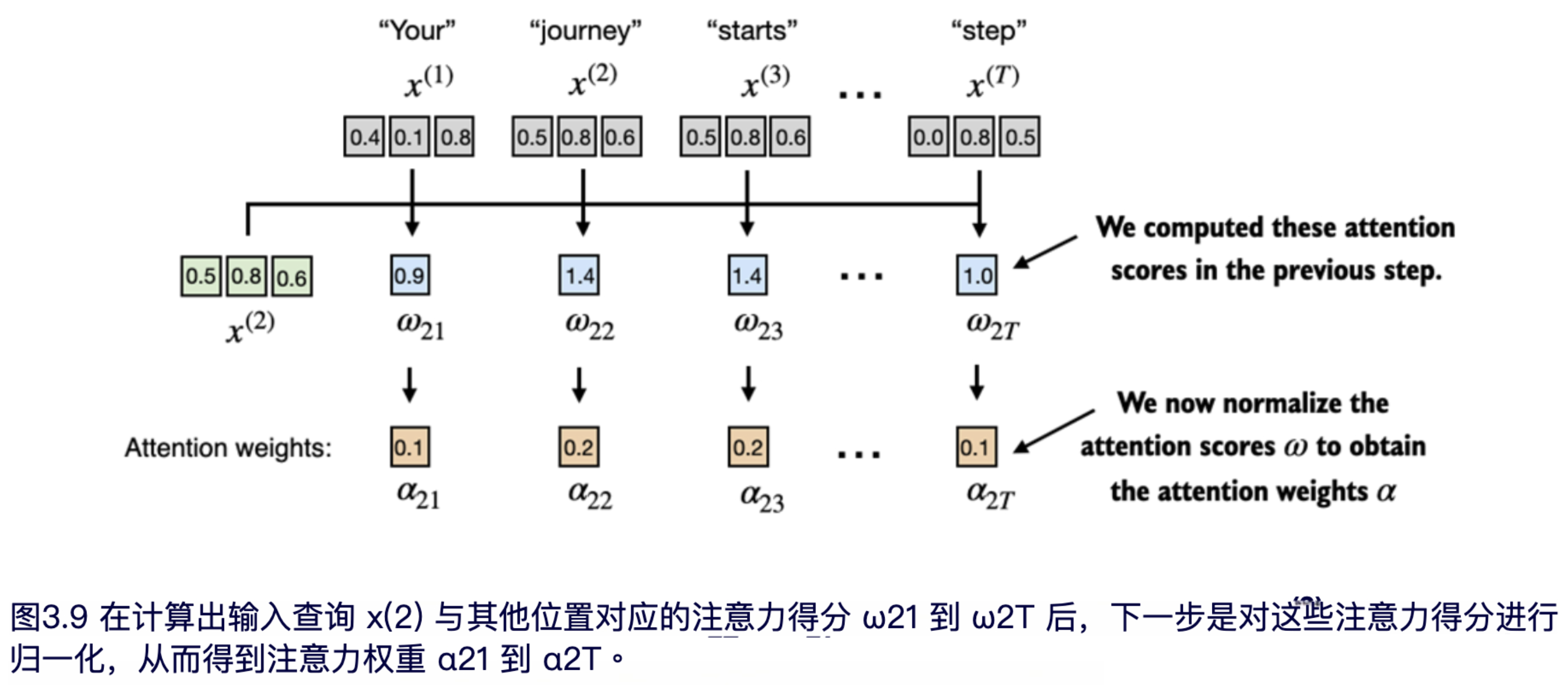 图3.9中所示的归一化的主要目的是使注意力权重之和为 1。这种归一化是一种有助于解释和保持LLM训练稳定性的惯例。以下是一种实现此归一化步骤的简单方法:
```python
attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()
print("Attention weights:", attn_weights_2_tmp)
print("Sum:", attn_weights_2_tmp.sum())
```
如输出所示,现在注意力权重的总和为 1:
```
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)
```
在实践中,更常见且更推荐使用 softmax 函数来进行归一化。这种方法更擅长处理极端值,并且在训练过程中提供了更有利的梯度特性。以下是用于归一化注意力分数的 softmax 函数的基础实现。
```python
def softmax_naive(x):
return torch.exp(x) / torch.exp(x).sum(dim=0)
attn_weights_2_naive = softmax_naive(attn_scores_2)
print("Attention weights:", attn_weights_2_naive)
print("Sum:", attn_weights_2_naive.sum())
```
从输出中可以看到,softmax 函数可以实现注意力权重的归一化,使它们的总和为 1:
```
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
```
此外,softmax 函数确保注意力权重始终为正值。这使得输出可以被解释为概率或相对重要性,其中较高的权重表示更重要。
注意,这种简单的 softmax 实现(softmax_naive)在处理较大或较小的输入值时,可能会遇到数值不稳定性问题,例如上溢或下溢。因此,实际操作中,建议使用 PyTorch 的 softmax 实现,它经过了充分的性能优化:
```python
attn_weights_2 = torch.softmax(attn_scores_2, dim=0)
print("Attention weights:", attn_weights_2)
print("Sum:", attn_weights_2.sum())
```
可以看到,它与我们之前实现的 `softmax_naive` 函数产生的结果相同。
```
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
```
> [!TIP]
>
> **个人思考:** 这里稍微延伸探讨一下`Softmax`, 它是一种常用的激活函数,尤其在神经网络的分类任务中被广泛使用。它的作用是将一个任意的实数向量转换为一个概率分布,且所有元素的概率之和为 1。下面通过例子来说明 softmax 的原理、好处,以及它在神经网络中的使用原因。
>
> 1. **Softmax 的原理**
>
> Softmax 函数的公式如下:
>
> $$ \text{softmax}\left(z_{i}\right)=\frac{e^{z_{i}}}{\sum_{j} e^{z_{j}}} $$
>
> 其中zi是输入的每个分数(即未激活的原始值),e 是自然对数的底。这个公式的作用是将输入向量中的每个元素转换为一个概率值,且所有值的和为 1。
>
> 2. **Softmax 的好处**
>
> + **归一化输出为概率**:Softmax 将输出转换为 0 到 1 之间的概率,且所有类别的概率之和为 1,方便解释结果。例如,在分类任务中,输出可以直接表示模型对各类别的信心。
> + **平滑和放大效果**:Softmax 不仅能归一化,还具有平滑和放大效果。较大的输入值会被放大,较小的输入值会被抑制,从而增强模型对最优类别的区分。
> + **支持多分类问题**:与 sigmoid 不同,Softmax 适用于多类别分类问题。它可以输出每个类别的概率,使得模型可以处理多分类任务。
>
> 3. **神经网络为什么喜欢使用 Softmax**
>
> 在神经网络中,特别是分类模型(如图像分类、文本分类)中,Softmax 层通常用作最后一层输出。原因包括:
>
> + **便于优化**:在分类任务中,Softmax 输出的概率分布可与真实的标签概率进行比较,从而计算交叉熵损失。交叉熵损失的梯度较为稳定,便于模型的优化。
> + **概率解释**:Softmax 输出可以解释为“模型对每个类别的信心”,使得输出直观可理解。
> + **与交叉熵的结合**:Softmax 与交叉熵损失函数结合效果特别好,可以直接将模型预测的概率分布与真实标签比较,从而更快收敛,效果更好。
现在我们已经计算出了归一化的注意力权重,接下来可以执行图 3.10 所示的最后一步:通过将嵌入后的输入 token x(i) 与相应的注意力权重相乘,再将所得向量求和,来计算上下文向量 z(2)。
图3.9中所示的归一化的主要目的是使注意力权重之和为 1。这种归一化是一种有助于解释和保持LLM训练稳定性的惯例。以下是一种实现此归一化步骤的简单方法:
```python
attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()
print("Attention weights:", attn_weights_2_tmp)
print("Sum:", attn_weights_2_tmp.sum())
```
如输出所示,现在注意力权重的总和为 1:
```
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)
```
在实践中,更常见且更推荐使用 softmax 函数来进行归一化。这种方法更擅长处理极端值,并且在训练过程中提供了更有利的梯度特性。以下是用于归一化注意力分数的 softmax 函数的基础实现。
```python
def softmax_naive(x):
return torch.exp(x) / torch.exp(x).sum(dim=0)
attn_weights_2_naive = softmax_naive(attn_scores_2)
print("Attention weights:", attn_weights_2_naive)
print("Sum:", attn_weights_2_naive.sum())
```
从输出中可以看到,softmax 函数可以实现注意力权重的归一化,使它们的总和为 1:
```
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
```
此外,softmax 函数确保注意力权重始终为正值。这使得输出可以被解释为概率或相对重要性,其中较高的权重表示更重要。
注意,这种简单的 softmax 实现(softmax_naive)在处理较大或较小的输入值时,可能会遇到数值不稳定性问题,例如上溢或下溢。因此,实际操作中,建议使用 PyTorch 的 softmax 实现,它经过了充分的性能优化:
```python
attn_weights_2 = torch.softmax(attn_scores_2, dim=0)
print("Attention weights:", attn_weights_2)
print("Sum:", attn_weights_2.sum())
```
可以看到,它与我们之前实现的 `softmax_naive` 函数产生的结果相同。
```
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
```
> [!TIP]
>
> **个人思考:** 这里稍微延伸探讨一下`Softmax`, 它是一种常用的激活函数,尤其在神经网络的分类任务中被广泛使用。它的作用是将一个任意的实数向量转换为一个概率分布,且所有元素的概率之和为 1。下面通过例子来说明 softmax 的原理、好处,以及它在神经网络中的使用原因。
>
> 1. **Softmax 的原理**
>
> Softmax 函数的公式如下:
>
> $$ \text{softmax}\left(z_{i}\right)=\frac{e^{z_{i}}}{\sum_{j} e^{z_{j}}} $$
>
> 其中zi是输入的每个分数(即未激活的原始值),e 是自然对数的底。这个公式的作用是将输入向量中的每个元素转换为一个概率值,且所有值的和为 1。
>
> 2. **Softmax 的好处**
>
> + **归一化输出为概率**:Softmax 将输出转换为 0 到 1 之间的概率,且所有类别的概率之和为 1,方便解释结果。例如,在分类任务中,输出可以直接表示模型对各类别的信心。
> + **平滑和放大效果**:Softmax 不仅能归一化,还具有平滑和放大效果。较大的输入值会被放大,较小的输入值会被抑制,从而增强模型对最优类别的区分。
> + **支持多分类问题**:与 sigmoid 不同,Softmax 适用于多类别分类问题。它可以输出每个类别的概率,使得模型可以处理多分类任务。
>
> 3. **神经网络为什么喜欢使用 Softmax**
>
> 在神经网络中,特别是分类模型(如图像分类、文本分类)中,Softmax 层通常用作最后一层输出。原因包括:
>
> + **便于优化**:在分类任务中,Softmax 输出的概率分布可与真实的标签概率进行比较,从而计算交叉熵损失。交叉熵损失的梯度较为稳定,便于模型的优化。
> + **概率解释**:Softmax 输出可以解释为“模型对每个类别的信心”,使得输出直观可理解。
> + **与交叉熵的结合**:Softmax 与交叉熵损失函数结合效果特别好,可以直接将模型预测的概率分布与真实标签比较,从而更快收敛,效果更好。
现在我们已经计算出了归一化的注意力权重,接下来可以执行图 3.10 所示的最后一步:通过将嵌入后的输入 token x(i) 与相应的注意力权重相乘,再将所得向量求和,来计算上下文向量 z(2)。
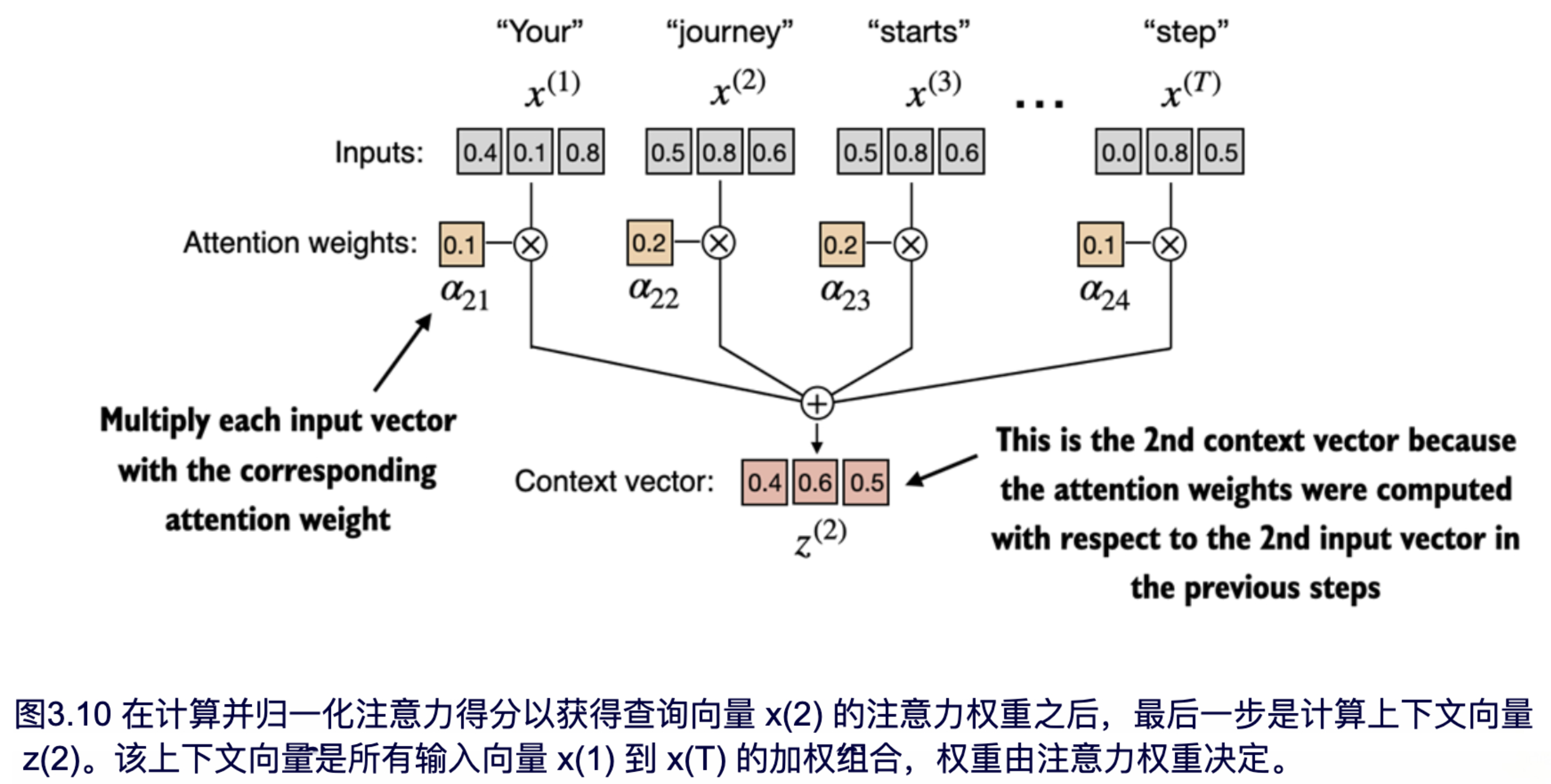 如图 3.10 所示,上下文向量 z(2) 是通过所有输入向量的加权和计算得到的。这一过程涉及将每个输入向量与其对应的注意力权重相乘:
```python
query = inputs[1] # 2nd input token is the query
context_vec_2 = torch.zeros(query.shape)
for i,x_i in enumerate(inputs):
context_vec_2 += attn_weights_2[i]*x_i
print(context_vec_2)
```
结算结果如下:
```
tensor([0.4419, 0.6515, 0.5683])
```
在接下来的部分,我们将把串行计算上下文向量的过程优化为并行计算所有输入token的上下文向量。
### 3.2 为所有输入的 token 计算注意力权重
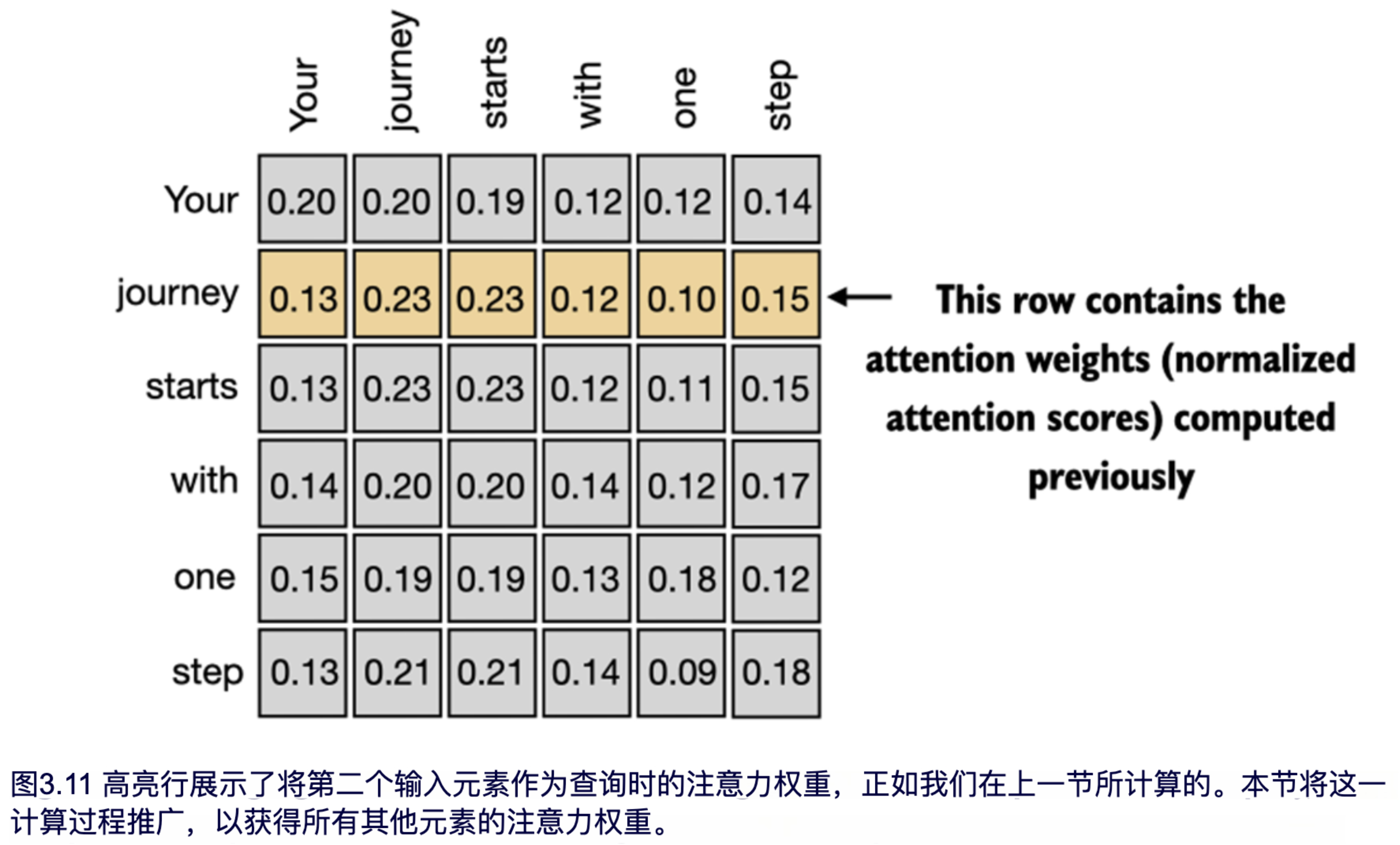
在前一节中,我们计算了第二个输入元素的注意力权重和上下文向量,如图 3.11 中的高亮行所示。现在,我们将扩展该计算,以对所有输入计算注意力权重和上下文向量。
如图 3.10 所示,上下文向量 z(2) 是通过所有输入向量的加权和计算得到的。这一过程涉及将每个输入向量与其对应的注意力权重相乘:
```python
query = inputs[1] # 2nd input token is the query
context_vec_2 = torch.zeros(query.shape)
for i,x_i in enumerate(inputs):
context_vec_2 += attn_weights_2[i]*x_i
print(context_vec_2)
```
结算结果如下:
```
tensor([0.4419, 0.6515, 0.5683])
```
在接下来的部分,我们将把串行计算上下文向量的过程优化为并行计算所有输入token的上下文向量。
### 3.2 为所有输入的 token 计算注意力权重
在前一节中,我们计算了第二个输入元素的注意力权重和上下文向量,如图 3.11 中的高亮行所示。现在,我们将扩展该计算,以对所有输入计算注意力权重和上下文向量。
 我们沿用之前的三个步骤(如图 3.12 所示),只是对代码做了一些修改,用于计算所有的上下文向量,而不仅仅是第二个上下文向量 z(2)。
我们沿用之前的三个步骤(如图 3.12 所示),只是对代码做了一些修改,用于计算所有的上下文向量,而不仅仅是第二个上下文向量 z(2)。
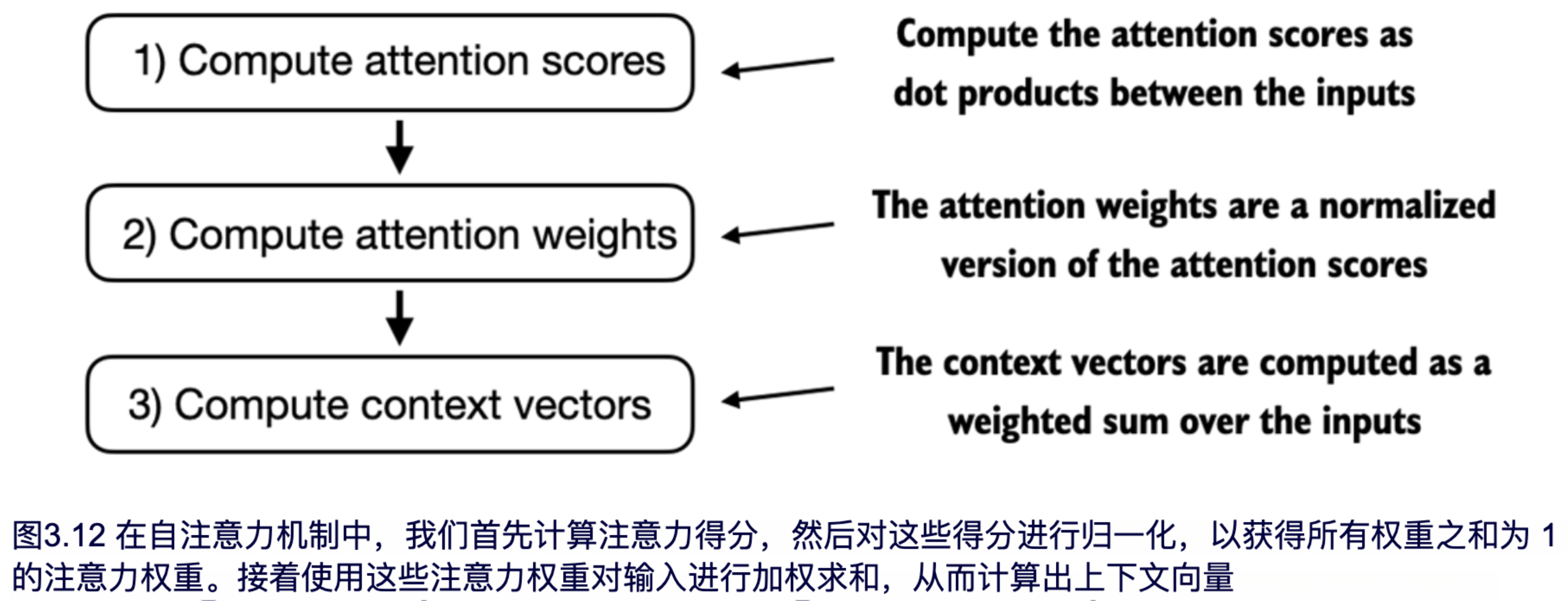 如图 3.12 所示,在第 1 步中,我们添加了一个额外的 for 循环,用于计算所有输入对之间的点积。
```python
attn_scores = torch.empty(6, 6)
for i, x_i in enumerate(inputs):
for j, x_j in enumerate(inputs):
attn_scores[i, j] = torch.dot(x_i, x_j)
print(attn_scores)
```
计算得到的注意力分数集合如下:
```
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
```
以上张量中的每个元素都表示每对输入之间的注意力得分,正如图 3.11 中所示。请注意,图 3.11 中的值已进行了归一化,因此它们与以上张量中的未经归一化的注意力得分不同。我们稍后会处理归一化。
在上述代码中,我们使用了 Python 中的 for 循环来计算所有输入对的注意力得分。然而,for 循环通常较慢,我们可以通过矩阵乘法实现相同的结果。
```python
attn_scores = inputs @ inputs.T
print(attn_scores)
```
我们可以直观地确认结果与之前一致:
```
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
```
接下来开始执行步骤 2(如图 3.12 所示),我们现在对每一行进行归一化处理,使得每一行的值之和为 1。
```python
attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)
```
执行上述代码返回的注意力权重张量与图 3.10 中显示的数值一致:
```
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])
```
在使用 PyTorch 时,像 `torch.softmax` 这样的函数中的 `dim` 参数指定了将在输入张量中的哪个维度上进行归一化计算。通过设置 `dim=-1`,我们指示 `softmax` 函数沿着 `attn_scores` 张量的最后一个维度进行归一化操作。如果 `attn_scores` 是一个二维张量(例如,形状为 `[行数, 列数]`),则 `dim=-1` 将沿列方向进行归一化,使得每一行的值(沿列方向求和)之和等于 1。
在继续执行第 3 步(即图 3.12 所示的最后一步)之前,我们先简单验证一下每一行的总和是否确实为 1:
```python
row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
print("Row 2 sum:", row_2_sum)
print("All row sums:", attn_weights.sum(dim=-1))
```
结果如下:
```
Row 2 sum: 1.0
All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
```
在第三步也是最后一步中,我们使用这些注意力权重通过矩阵乘法的方式来并行计算所有的上下文向量:
```python
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
```
可以看到,计算输出的张量中,每一行包含一个三维的上下文向量:
```
tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])
```
我们可以通过将第二行与之前在第 3.3.1 节中计算的上下文向量 z(2) 进行对比,来再次确认代码的正确性。
```python
print("Previous 2nd context vector:", context_vec_2)
```
根据结果,我们可以看到之前计算的 context_vec_2 与以上张量的第二行完全一致:
```
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])
```
以上内容完成了对简单自注意力机制的代码演示。在接下来的部分,我们将添加可训练的权重,使大语言模型能够从数据中学习并提升其在特定任务上的性能。
## 3.4 实现带有可训练权重的自注意力机制
在本节中,我们正在实现一种在原始 Transformer 架构、GPT 模型以及大多数其他流行的大语言模型中使用的自注意力机制。这种自注意力机制也被称为缩放点积注意力。图 3.13 提供了一个思维模型,展示了这种自注意力机制是如何应用在在大语言模型的架构设计中。
如图 3.12 所示,在第 1 步中,我们添加了一个额外的 for 循环,用于计算所有输入对之间的点积。
```python
attn_scores = torch.empty(6, 6)
for i, x_i in enumerate(inputs):
for j, x_j in enumerate(inputs):
attn_scores[i, j] = torch.dot(x_i, x_j)
print(attn_scores)
```
计算得到的注意力分数集合如下:
```
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
```
以上张量中的每个元素都表示每对输入之间的注意力得分,正如图 3.11 中所示。请注意,图 3.11 中的值已进行了归一化,因此它们与以上张量中的未经归一化的注意力得分不同。我们稍后会处理归一化。
在上述代码中,我们使用了 Python 中的 for 循环来计算所有输入对的注意力得分。然而,for 循环通常较慢,我们可以通过矩阵乘法实现相同的结果。
```python
attn_scores = inputs @ inputs.T
print(attn_scores)
```
我们可以直观地确认结果与之前一致:
```
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
```
接下来开始执行步骤 2(如图 3.12 所示),我们现在对每一行进行归一化处理,使得每一行的值之和为 1。
```python
attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)
```
执行上述代码返回的注意力权重张量与图 3.10 中显示的数值一致:
```
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])
```
在使用 PyTorch 时,像 `torch.softmax` 这样的函数中的 `dim` 参数指定了将在输入张量中的哪个维度上进行归一化计算。通过设置 `dim=-1`,我们指示 `softmax` 函数沿着 `attn_scores` 张量的最后一个维度进行归一化操作。如果 `attn_scores` 是一个二维张量(例如,形状为 `[行数, 列数]`),则 `dim=-1` 将沿列方向进行归一化,使得每一行的值(沿列方向求和)之和等于 1。
在继续执行第 3 步(即图 3.12 所示的最后一步)之前,我们先简单验证一下每一行的总和是否确实为 1:
```python
row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
print("Row 2 sum:", row_2_sum)
print("All row sums:", attn_weights.sum(dim=-1))
```
结果如下:
```
Row 2 sum: 1.0
All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
```
在第三步也是最后一步中,我们使用这些注意力权重通过矩阵乘法的方式来并行计算所有的上下文向量:
```python
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
```
可以看到,计算输出的张量中,每一行包含一个三维的上下文向量:
```
tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])
```
我们可以通过将第二行与之前在第 3.3.1 节中计算的上下文向量 z(2) 进行对比,来再次确认代码的正确性。
```python
print("Previous 2nd context vector:", context_vec_2)
```
根据结果,我们可以看到之前计算的 context_vec_2 与以上张量的第二行完全一致:
```
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])
```
以上内容完成了对简单自注意力机制的代码演示。在接下来的部分,我们将添加可训练的权重,使大语言模型能够从数据中学习并提升其在特定任务上的性能。
## 3.4 实现带有可训练权重的自注意力机制
在本节中,我们正在实现一种在原始 Transformer 架构、GPT 模型以及大多数其他流行的大语言模型中使用的自注意力机制。这种自注意力机制也被称为缩放点积注意力。图 3.13 提供了一个思维模型,展示了这种自注意力机制是如何应用在在大语言模型的架构设计中。
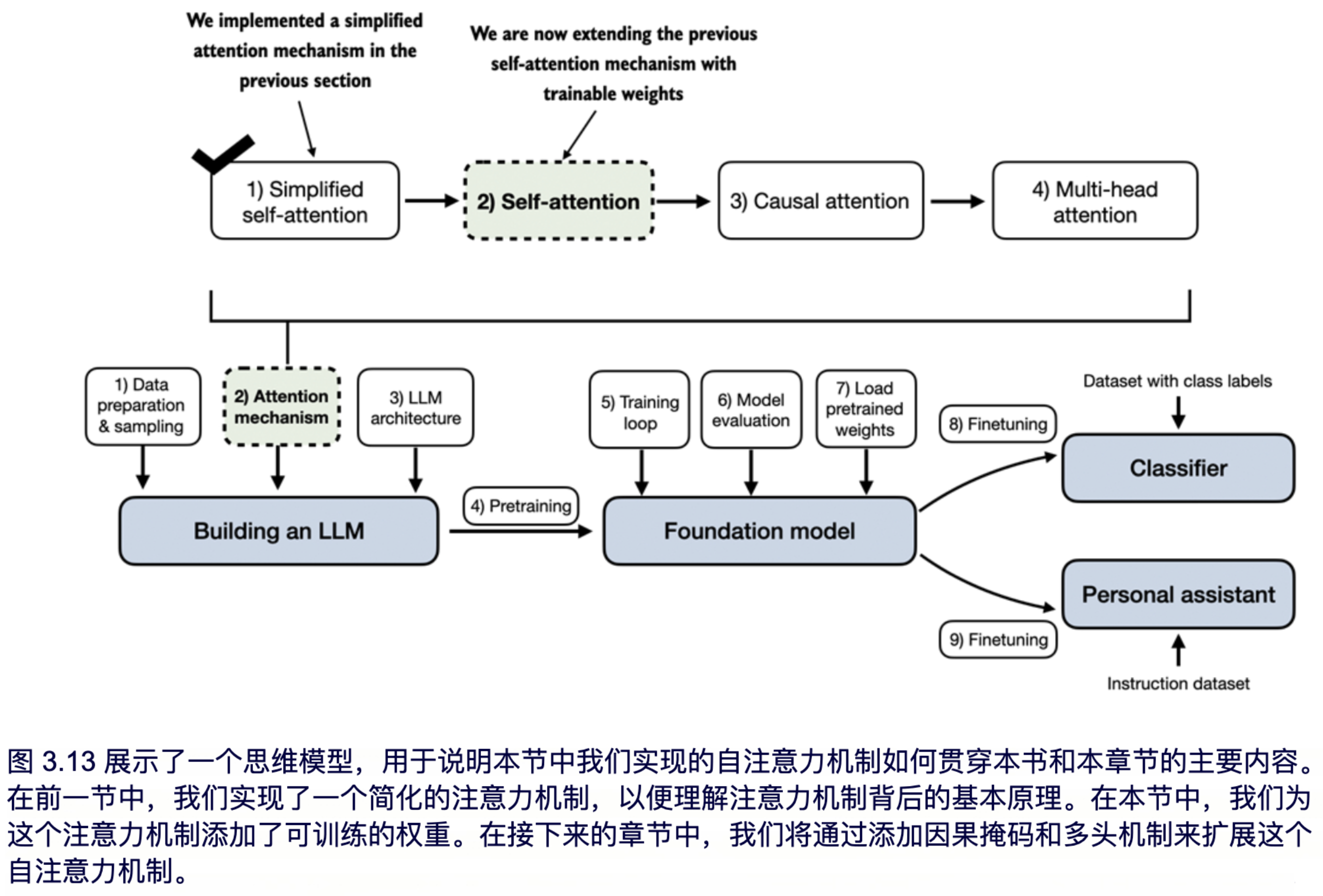 如图 3.13 所示,带有可训练权重的自注意力机制是基于之前简化自注意力机制的改进:我们希望计算某个特定输入元素的嵌入向量的加权和来作为上下文向量。您将看到,与我们在 3.3 节中编码的基本自注意力机制相比,只有细微的差别。
最显著的区别在于引入了在模型训练过程中不断更新的权重矩阵。这些可训练的权重矩阵至关重要,它们使模型(特别是模型内部的注意力模块)能够学习生成“优质”的上下文向量。(请注意,我们将在第五章训练大语言模型。)
我们将通过两个小节来深入讲解自注意力机制。首先,我们会像之前一样,逐步编写该机制的代码。然后,我们会将代码整理成一个紧凑的 Python 类,以便在第 4 章编写的大型语言模型(LLM)架构中使用。
### 3.4.1 逐步计算注意力权重
我们通过引入三个可训练的权重矩阵:Wq、Wk 和 Wv 来逐步实现自注意力机制。这三个矩阵用于将嵌入后的输入 token x(i) 映射为查询向量、键向量和值向量,如图 3.14 所示。
如图 3.13 所示,带有可训练权重的自注意力机制是基于之前简化自注意力机制的改进:我们希望计算某个特定输入元素的嵌入向量的加权和来作为上下文向量。您将看到,与我们在 3.3 节中编码的基本自注意力机制相比,只有细微的差别。
最显著的区别在于引入了在模型训练过程中不断更新的权重矩阵。这些可训练的权重矩阵至关重要,它们使模型(特别是模型内部的注意力模块)能够学习生成“优质”的上下文向量。(请注意,我们将在第五章训练大语言模型。)
我们将通过两个小节来深入讲解自注意力机制。首先,我们会像之前一样,逐步编写该机制的代码。然后,我们会将代码整理成一个紧凑的 Python 类,以便在第 4 章编写的大型语言模型(LLM)架构中使用。
### 3.4.1 逐步计算注意力权重
我们通过引入三个可训练的权重矩阵:Wq、Wk 和 Wv 来逐步实现自注意力机制。这三个矩阵用于将嵌入后的输入 token x(i) 映射为查询向量、键向量和值向量,如图 3.14 所示。
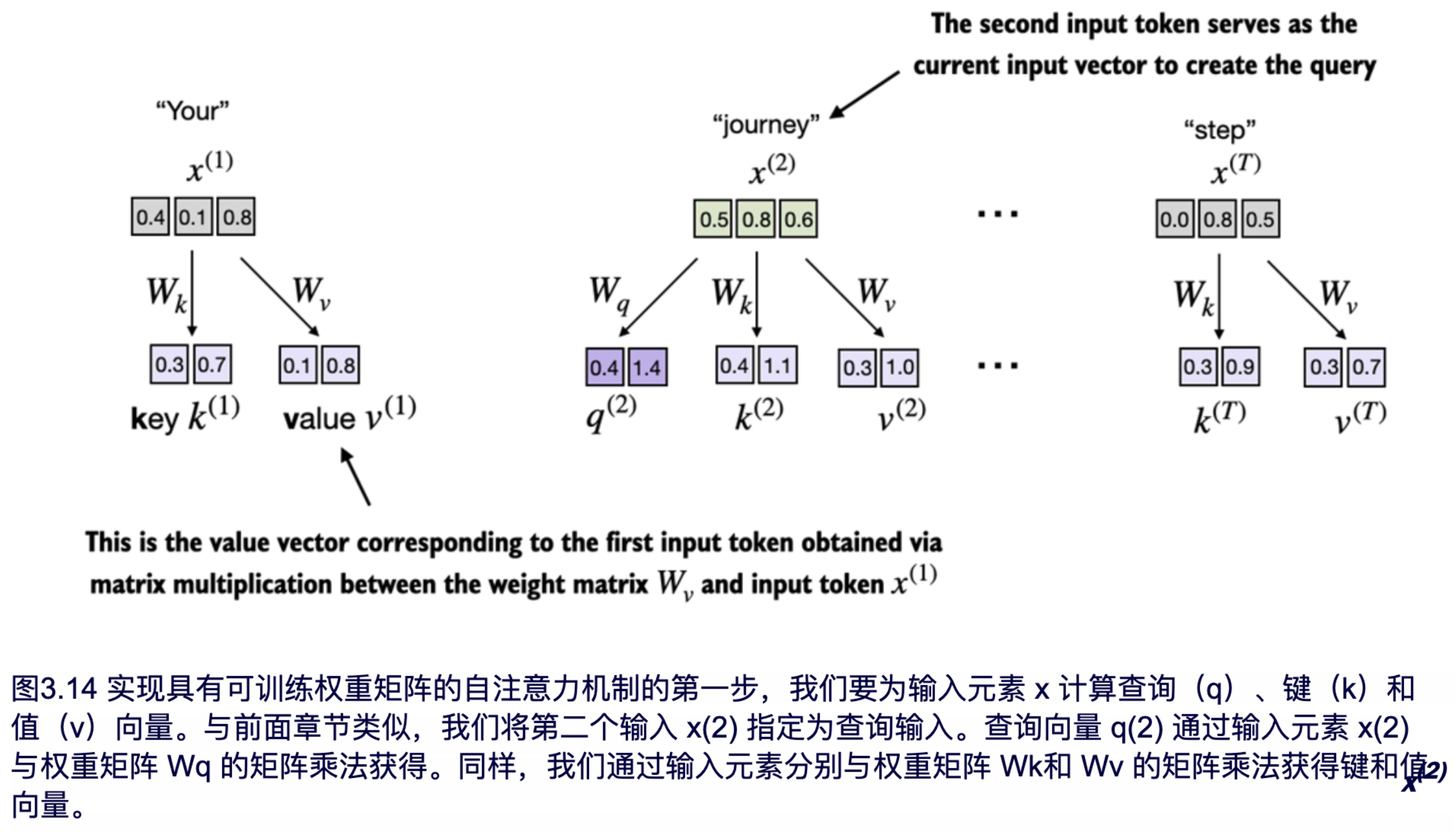 在第 3.3.1 节中,我们将第二个输入元素 x(2) 定义为查询(query),通过计算简化的注意力权重来得到上下文向量 z(2)。随后,在第 3.3.2 节中,我们将这一过程推广到整个输入句子 "Your journey starts with one step",为这六个词的输入句子计算所有的上下文向量 z(1) 到 z(T)。
同样地,为了便于说明,我们将先计算一个上下文向量 z(2)。接下来,我们将修改代码以计算所有的上下文向量。让我们从定义一些变量开始:
```python
x_2 = inputs[1] #A
d_in = inputs.shape[1] #B
d_out = 2 #C
#A 第二个输入元素
#B 输入维度, d_in=3
#C 输出维度, d_out=2
```
请注意,在 GPT 类模型中,输入维度和输出维度通常是相同的。不过,为了便于说明和更清楚地展示计算过程,我们在此选择了不同的输入(d_in=3)和输出(d_out=2)维度。
接下来,我们初始化图3.14中所示的三个权重矩阵Wq、Wk和Wv:
```python
torch.manual_seed(123)
W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
```
请注意,这里我们将 `requires_grad` 设置为 `False`,以便在输出结果中减少不必要的信息,使演示更加清晰。但如果要将这些权重矩阵用于模型训练,则需要将 `requires_grad` 设置为 `True`,以便在模型训练过程中更新这些矩阵。
接下来,我们计算之前在图 3.14 中展示的 query、key 和 value 向量:
```python
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)
```
以上代码的输出是一个二维向量,因为我们将对应的输出权重矩阵的列数通过 `d_out` 参数设置为 2:
```
tensor([0.4306, 1.4551])
```
> [!NOTE]
>
> **权重参数 VS 注意力权重**
>
> 请注意,在权重矩阵 W 中,术语“权重”是“权重参数”的缩写,指的是神经网络在训练过程中被优化的数值参数。这与注意力权重不同,注意力权重用于确定上下文向量对输入文本的不同部分的依赖程度,即神经网络对输入不同部分的关注程度。
>
> 总之,权重参数是神经网络的基本学习系数,用于定义网络层之间的连接关系,而注意力权重则是根据上下文动态生成的特定值,用于衡量不同词语或位置在当前上下文中的重要性。
尽管我们当前的目标仅仅是计算一个上下文向量 z(2),但仍然需要获取所有输入元素的 key 和 value 向量,因为它们参与了与查询向量 q(2) 一起计算注意力权重的过程,如图 3.14 所示。
我们可以通过矩阵乘法获取所有元素的key和value向量:
```python
keys = inputs @ W_key
values = inputs @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
```
从输出结果可以看出,我们成功地将 6 个输入 token 从 3 维嵌入空间投影到 2 维嵌入空间:
```
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
```
接下来的第二步是计算注意力得分,如图 3.15 所示。
在第 3.3.1 节中,我们将第二个输入元素 x(2) 定义为查询(query),通过计算简化的注意力权重来得到上下文向量 z(2)。随后,在第 3.3.2 节中,我们将这一过程推广到整个输入句子 "Your journey starts with one step",为这六个词的输入句子计算所有的上下文向量 z(1) 到 z(T)。
同样地,为了便于说明,我们将先计算一个上下文向量 z(2)。接下来,我们将修改代码以计算所有的上下文向量。让我们从定义一些变量开始:
```python
x_2 = inputs[1] #A
d_in = inputs.shape[1] #B
d_out = 2 #C
#A 第二个输入元素
#B 输入维度, d_in=3
#C 输出维度, d_out=2
```
请注意,在 GPT 类模型中,输入维度和输出维度通常是相同的。不过,为了便于说明和更清楚地展示计算过程,我们在此选择了不同的输入(d_in=3)和输出(d_out=2)维度。
接下来,我们初始化图3.14中所示的三个权重矩阵Wq、Wk和Wv:
```python
torch.manual_seed(123)
W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
```
请注意,这里我们将 `requires_grad` 设置为 `False`,以便在输出结果中减少不必要的信息,使演示更加清晰。但如果要将这些权重矩阵用于模型训练,则需要将 `requires_grad` 设置为 `True`,以便在模型训练过程中更新这些矩阵。
接下来,我们计算之前在图 3.14 中展示的 query、key 和 value 向量:
```python
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)
```
以上代码的输出是一个二维向量,因为我们将对应的输出权重矩阵的列数通过 `d_out` 参数设置为 2:
```
tensor([0.4306, 1.4551])
```
> [!NOTE]
>
> **权重参数 VS 注意力权重**
>
> 请注意,在权重矩阵 W 中,术语“权重”是“权重参数”的缩写,指的是神经网络在训练过程中被优化的数值参数。这与注意力权重不同,注意力权重用于确定上下文向量对输入文本的不同部分的依赖程度,即神经网络对输入不同部分的关注程度。
>
> 总之,权重参数是神经网络的基本学习系数,用于定义网络层之间的连接关系,而注意力权重则是根据上下文动态生成的特定值,用于衡量不同词语或位置在当前上下文中的重要性。
尽管我们当前的目标仅仅是计算一个上下文向量 z(2),但仍然需要获取所有输入元素的 key 和 value 向量,因为它们参与了与查询向量 q(2) 一起计算注意力权重的过程,如图 3.14 所示。
我们可以通过矩阵乘法获取所有元素的key和value向量:
```python
keys = inputs @ W_key
values = inputs @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
```
从输出结果可以看出,我们成功地将 6 个输入 token 从 3 维嵌入空间投影到 2 维嵌入空间:
```
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
```
接下来的第二步是计算注意力得分,如图 3.15 所示。
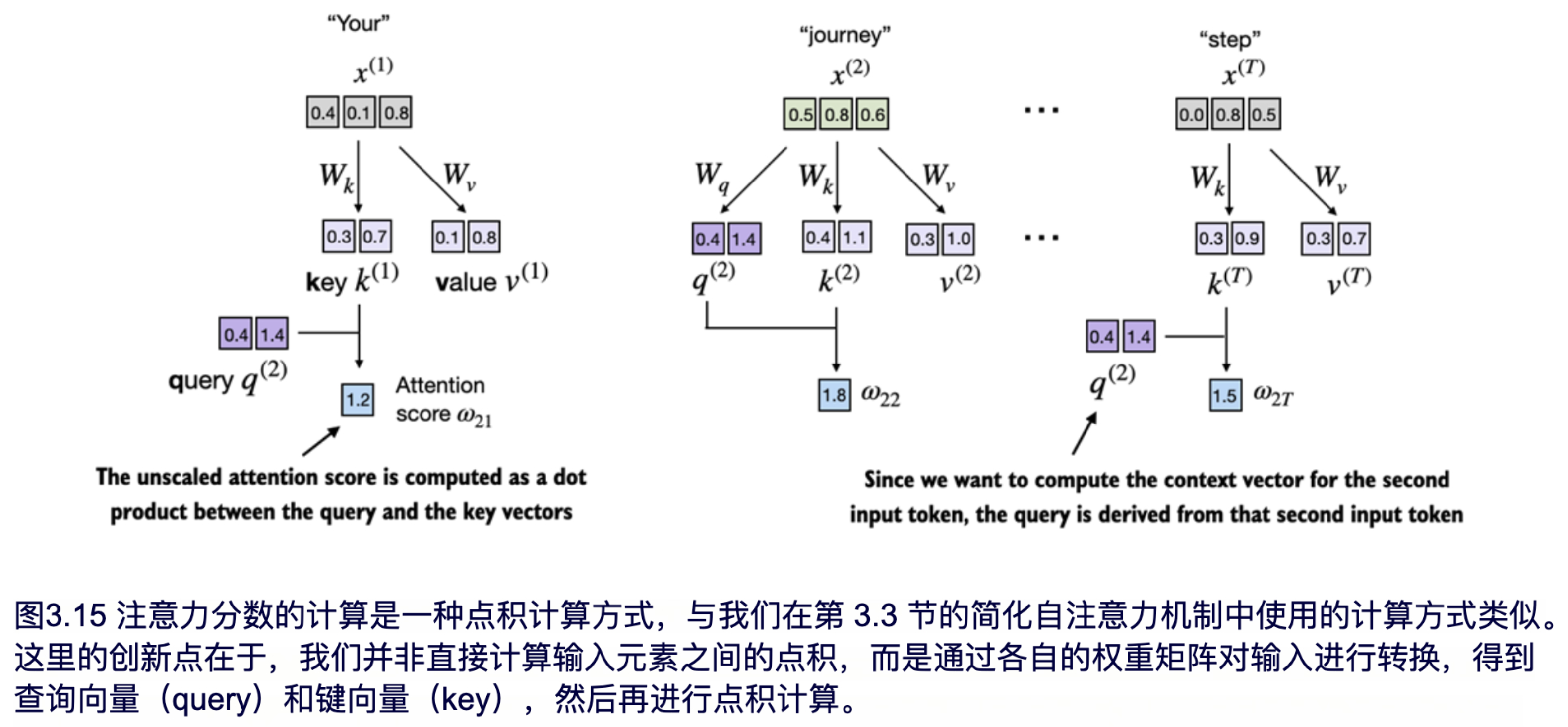 首先,我们计算注意力得分ω22 :
```python
keys_2 = keys[1] #A
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
#A 请牢记在Python中索引从0开始
```
由此得到以下未经归一化的注意力得分:
```
tensor(1.8524)
```
> [!TIP]
>
> **个人思考:** 之前一直有一个疑惑,相同的两个词在不同句子中语义相关度可能完全不同,那么它们的注意力得分是如何做到在不同的上下文中分数不一样的。例如考虑以下两个句子:
>
> + 句子1:"The cat drank the milk because it was hungry."
> + 句子2:"The cat drank the milk because it was sweet."
>
> 很明显,在这两个句子中,`it`的指代不同,第一个句子中,`it`指代`cat`,而在第二个句子中,`it`指代`milk`。
>
> 根据一下注意力得分的公式(Qcat和Kit分别为`cat`和`it`的查询向量和键向量)可知,句子1中`score_cat_it`是要大于句子2中的`score_cat_it`,因为句子1中,`it`和`cat`的相关度更高,但是从公式中如何推断出实现呢?
>
> **score_cat_it = Qcat · Kit**
>
> 我们继续将公式拆解:
>
> **Qcat= Wq * (Ecat + Poscat)**
>
> **Kit = Wk * (Eit + Posit)**
>
> 其中 **Ecat**和**Eit**是这两个词的嵌入向量,表示该词的基本语义信息,在不同的上下文中是固定的,根据公式可知,要使最终算出的**score_cat_it**与上下文语义相关,最重要的是Wq 和Wk这两个权重参数应该能反映出不同上下文语义的相关性。在标准的自注意力机制中,W、K、V向量都是固定的,然而,由于 GPT 模型是由多层自注意力模块堆叠而成,每一层都会根据当前输入和上下文信息,动态调整查询、键和值向量的权重矩阵。因此,即使初始的词嵌入和权重矩阵是固定的,经过多层处理后,模型能够生成与当前上下文相关的 Q、K、V 向量权重矩阵,最终计算出的Q、K、V 向量也就能反映出上下文的语义了。GPT多层的实现的细节后文会详述。
我们可以再次通过矩阵乘法将其应用到所有注意力得分的计算:
```python
attn_scores_2 = query_2 @ keys.T # All attention scores for given query
print(attn_scores_2)
```
可以看到,输出中的第二个元素与我们之前计算的 `attn_score_22` 相同:
```
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
```
第三步是将注意力得分转换为注意力权重,如图 3.16 所示。
首先,我们计算注意力得分ω22 :
```python
keys_2 = keys[1] #A
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
#A 请牢记在Python中索引从0开始
```
由此得到以下未经归一化的注意力得分:
```
tensor(1.8524)
```
> [!TIP]
>
> **个人思考:** 之前一直有一个疑惑,相同的两个词在不同句子中语义相关度可能完全不同,那么它们的注意力得分是如何做到在不同的上下文中分数不一样的。例如考虑以下两个句子:
>
> + 句子1:"The cat drank the milk because it was hungry."
> + 句子2:"The cat drank the milk because it was sweet."
>
> 很明显,在这两个句子中,`it`的指代不同,第一个句子中,`it`指代`cat`,而在第二个句子中,`it`指代`milk`。
>
> 根据一下注意力得分的公式(Qcat和Kit分别为`cat`和`it`的查询向量和键向量)可知,句子1中`score_cat_it`是要大于句子2中的`score_cat_it`,因为句子1中,`it`和`cat`的相关度更高,但是从公式中如何推断出实现呢?
>
> **score_cat_it = Qcat · Kit**
>
> 我们继续将公式拆解:
>
> **Qcat= Wq * (Ecat + Poscat)**
>
> **Kit = Wk * (Eit + Posit)**
>
> 其中 **Ecat**和**Eit**是这两个词的嵌入向量,表示该词的基本语义信息,在不同的上下文中是固定的,根据公式可知,要使最终算出的**score_cat_it**与上下文语义相关,最重要的是Wq 和Wk这两个权重参数应该能反映出不同上下文语义的相关性。在标准的自注意力机制中,W、K、V向量都是固定的,然而,由于 GPT 模型是由多层自注意力模块堆叠而成,每一层都会根据当前输入和上下文信息,动态调整查询、键和值向量的权重矩阵。因此,即使初始的词嵌入和权重矩阵是固定的,经过多层处理后,模型能够生成与当前上下文相关的 Q、K、V 向量权重矩阵,最终计算出的Q、K、V 向量也就能反映出上下文的语义了。GPT多层的实现的细节后文会详述。
我们可以再次通过矩阵乘法将其应用到所有注意力得分的计算:
```python
attn_scores_2 = query_2 @ keys.T # All attention scores for given query
print(attn_scores_2)
```
可以看到,输出中的第二个元素与我们之前计算的 `attn_score_22` 相同:
```
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
```
第三步是将注意力得分转换为注意力权重,如图 3.16 所示。
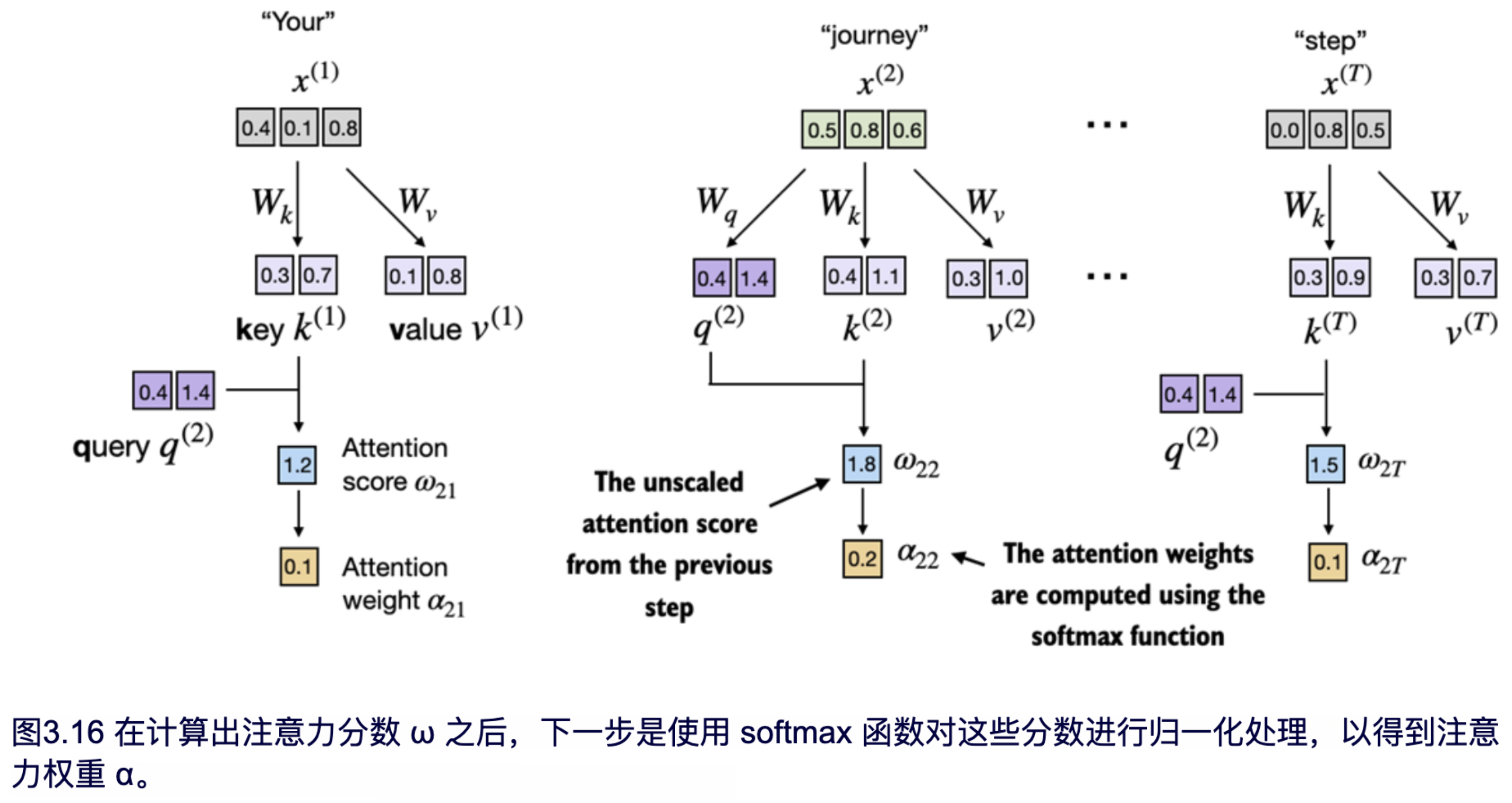 接下来,如图 3.16 所示,我们通过缩放注意力分数并使用前面提到的 softmax 函数来计算注意力权重。与之前的不同之处在于,现在我们通过将注意力分数除以`keys`嵌入维度的平方根来进行缩放(注意,取平方根在数学上等同于指数为 0.5 的运算)。
```python
d_k = keys.shape[-1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
```
结果如下:
```
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
```
> [!NOTE]
>
> **缩放点积注意力机制的原理**
>
> 对嵌入维度大小进行归一化的原因是为了避免出现小梯度,从而提高训练性能。例如,当嵌入维度增大时(在 GPT 类大型语言模型中通常超过一千),较大的点积在反向传播中应用 softmax 函数后,可能会导致非常小的梯度。随着点积的增大,softmax 函数的行为会更加类似于阶跃函数,导致梯度接近于零。这些小梯度可能会显著减慢学习速度,甚至导致训练停滞。
>
> 通过嵌入维度的平方根进行缩放,正是自注意力机制被称为‘缩放点积注意力’的原因。
> [!TIP]
>
> **个人思考:** 这里再稍微解释一下上述关于缩放点积注意力的机制。在自注意力机制中,查询向量(Query)与键向量(Key)之间的点积用于计算注意力权重。然而,当嵌入维度(embedding dimension)较大时,点积的结果可能会非常大。那么大的点积对接下来的计算有哪些具体影响呢?
>
> + **Softmax函数的特性**:在计算注意力权重时,点积结果会通过Softmax函数转换为概率分布。而Softmax函数对输入值的差异非常敏感,当输入值较大时,Softmax的输出会趋近于0或1,表现得类似于阶跃函数(step function)。
> + **梯度消失问题**:当Softmax的输出接近0或1时,其梯度会非常小,接近于零(可以通过3.3.1小节中提到的Softmax公式推断)。这意味着在反向传播过程中,梯度更新幅度会很小,导致模型学习速度减慢,甚至训练停滞。
>
> 为了解决上述问题,在计算点积后,将结果除以嵌入维度的平方根(即 $` \sqrt{dk<\/sub>} `$),其中 dk 是键向量的维度。这样可以将点积结果缩放到适当的范围,避免Softmax函数进入梯度平缓区,从而保持梯度的有效性,促进模型的正常训练。$`\sqrt{\$4}`$
>
>
接下来,如图 3.16 所示,我们通过缩放注意力分数并使用前面提到的 softmax 函数来计算注意力权重。与之前的不同之处在于,现在我们通过将注意力分数除以`keys`嵌入维度的平方根来进行缩放(注意,取平方根在数学上等同于指数为 0.5 的运算)。
```python
d_k = keys.shape[-1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
```
结果如下:
```
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
```
> [!NOTE]
>
> **缩放点积注意力机制的原理**
>
> 对嵌入维度大小进行归一化的原因是为了避免出现小梯度,从而提高训练性能。例如,当嵌入维度增大时(在 GPT 类大型语言模型中通常超过一千),较大的点积在反向传播中应用 softmax 函数后,可能会导致非常小的梯度。随着点积的增大,softmax 函数的行为会更加类似于阶跃函数,导致梯度接近于零。这些小梯度可能会显著减慢学习速度,甚至导致训练停滞。
>
> 通过嵌入维度的平方根进行缩放,正是自注意力机制被称为‘缩放点积注意力’的原因。
> [!TIP]
>
> **个人思考:** 这里再稍微解释一下上述关于缩放点积注意力的机制。在自注意力机制中,查询向量(Query)与键向量(Key)之间的点积用于计算注意力权重。然而,当嵌入维度(embedding dimension)较大时,点积的结果可能会非常大。那么大的点积对接下来的计算有哪些具体影响呢?
>
> + **Softmax函数的特性**:在计算注意力权重时,点积结果会通过Softmax函数转换为概率分布。而Softmax函数对输入值的差异非常敏感,当输入值较大时,Softmax的输出会趋近于0或1,表现得类似于阶跃函数(step function)。
> + **梯度消失问题**:当Softmax的输出接近0或1时,其梯度会非常小,接近于零(可以通过3.3.1小节中提到的Softmax公式推断)。这意味着在反向传播过程中,梯度更新幅度会很小,导致模型学习速度减慢,甚至训练停滞。
>
> 为了解决上述问题,在计算点积后,将结果除以嵌入维度的平方根(即 $` \sqrt{dk<\/sub>} `$),其中 dk 是键向量的维度。这样可以将点积结果缩放到适当的范围,避免Softmax函数进入梯度平缓区,从而保持梯度的有效性,促进模型的正常训练。$`\sqrt{\$4}`$
>
>