本章涵盖以下内容:
+ **PyTorch深度学习框架概述**
+ **搭建深度学习所需的环境和工作空间**
+ **张量:深度学习中的基础数据结构**
+ **深度神经网络的训练机制**
+ **在GPU上训练模型**
-----
- [A.1 什么是 PyTorch](#a1-什么是-pytorch)
- [A.1.1 PyTorch 的三个核心组件](#a11-pytorch-的三个核心组件)
- [A.1.2 定义深度学习](#a12-定义深度学习)
- [A.1.3 安装 PyTorch](#a13-安装-pytorch)
- [A.2 理解张量](#a2-理解张量)
- [A.2.1 标量、向量、矩阵和张量](#a21-标量向量矩阵和张量)
- [A.2.2 张量数据类型](#a22-张量数据类型)
- [A.2.3 常用的 PyTorch 张量操作](#a23-常用的-pytorch-张量操作)
- [A.3 将模型视为计算图](#a3-将模型视为计算图)
- [A.4 轻松实现自动微分](#a4-轻松实现自动微分)
- [偏导数与梯度](#偏导数与梯度)
- [A.5 实现多层神经网络](#a5-实现多层神经网络)
- [A.6 设置高效的数据加载器](#a6-设置高效的数据加载器)
- [4.7 一个典型的训练循环](#47-一个典型的训练循环)
- [4.8 保存和加载模型](#48-保存和加载模型)
- [A.9 使用 GPU 优化训练性能](#a9-使用-gpu-优化训练性能)
- [9.1 PyTorch 在 GPU 设备上的计算](#91-pytorch-在-gpu-设备上的计算)
- [A.9.2 单 GPU 训练](#a92-单-gpu-训练)
- [A.9.3 使用多个 GPU 训练](#a93-使用多个-gpu-训练)
- [A.10 本章摘要](#a10-本章摘要)
-----
本章旨在帮助你掌握将深度学习应用于实践的必要技能和知识,并从零开始实现大语言模型(LLM)。
我们将介绍 PyTorch,一个流行的基于 Python 的深度学习库,它将作为本书后续章节的主要工具。本章还将指导你如何设置一个配备 PyTorch 和 GPU 支持的深度学习工作环境。
接下来,你将学习张量的基本概念以及它们在 PyTorch 中的应用。我们还将深入探讨 PyTorch 的自动微分引擎,这一功能使得我们能够便捷且高效地使用反向传播,这是神经网络训练中的关键环节。
请注意,本章旨在为深度学习初学者提供 PyTorch 入门知识。尽管本章会从基础开始讲解 PyTorch,但并不打算对 PyTorch 库进行全面介绍。相反,本章主要介绍我们将在本书中实现大语言模型所需的 PyTorch 基础知识。如果你已经熟悉深度学习,可以跳过本章,直接进入第 2 章,学习如何处理文本数据。
## A.1 什么是 PyTorch
PyTorch(https://pytorch.org/)是一个基于 Python 的开源深度学习库。根据 'Papers With Code'(https://paperswithcode.com/trends)这一平台的统计数据(`该平台的数据源来自于追踪和分析研究论文`),PyTorch 自 2019 年以来一直是研究领域中使用最广泛的深度学习库,且领先优势明显。根据 Kaggle 2022 年数据科学与机器学习调查(https://www.kaggle.com/c/kaggle-survey-2022),使用 PyTorch 的受访者者比例约为 40%,且这一比例每年持续增长。
PyTorch 之所以如此受欢迎,部分原因在于其用户友好的界面和高效性。然而,尽管它易于使用,但并未牺牲灵活性,依然为高级用户提供了调整模型底层细节以实现定制和优化的能力。简而言之,PyTorch 为许多实践者和研究人员提供了易用性与功能性之间的完美平衡。
在以下小节中,我们将介绍 PyTorch 所提供的主要功能。
### A.1.1 PyTorch 的三个核心组件
PyTorch 是一个功能全面的深度学习库,快速理解它的一种方法是从它的三个核心组件入手,在图 A.1 中对这三个组件进行了总结。
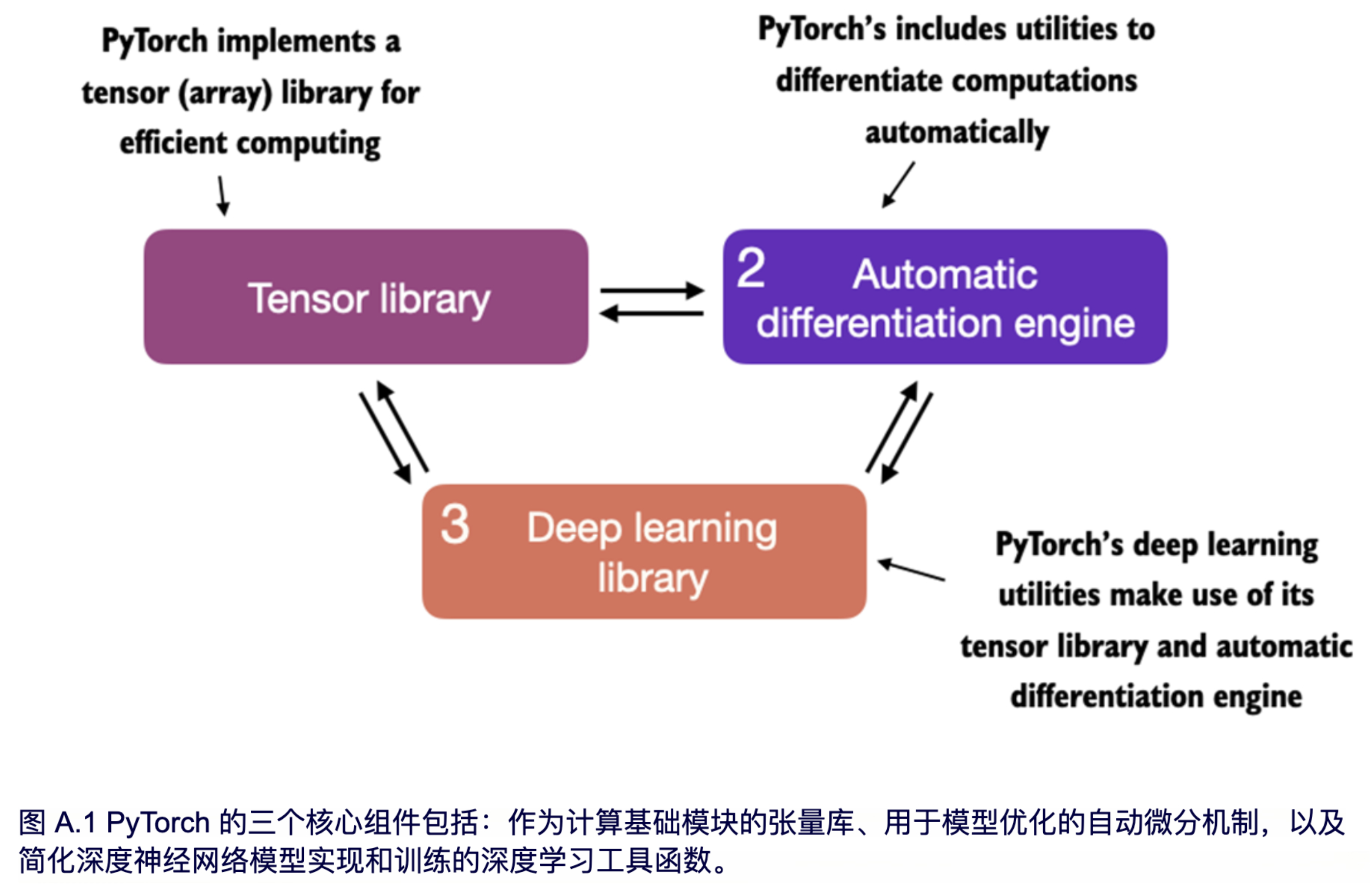 首先,PyTorch 是一个张量库,它在数组导向编程库 NumPy 的基础上扩展了功能,增加了对 GPU 加速计算的支持,从而实现了 CPU 和 GPU 之间的无缝切换。
其次,PyTorch 是一个自动微分引擎,也称为 autograd,它能够自动计算张量操作的梯度,从而简化反向传播过程和模型优化。
最后,PyTorch 是一个深度学习库,提供模块化、灵活和高效的构建模块(包括预训练模型、损失函数和优化器),用于设计和训练各种深度学习模型,同时满足研究人员和开发人员的需求。
在接下来的小节中,我们将首先定义深度学习的概念并介绍如何安装 PyTorch。随后,本章将详细讲解 PyTorch 的三个核心组件,并通过实际的代码示例进行演示。
### A.1.2 定义深度学习
大语言模型(LLM)经常在新闻中被称为人工智能(AI)模型。然而,正如第一章第 1 节(“什么是大语言模型?”)中所示,大语言模型也是一种深度神经网络,而 PyTorch 是一个深度学习库。听起来是不是有些混乱?让我们在继续之前,简要总结一下这些术语之间的关系。
人工智能的核心在于创建能够执行高级任务(所谓高级是指通常需要达到人类智能才能完成)的计算机系统。这些任务包括理解自然语言、识别模式和做决策(尽管已有显著进展,但AI仍远未实现这一层次的通用智能)。
机器学习是人工智能的一个子领域(如图 A.2 所示),其重点在于开发和改进学习算法。机器学习的核心思想是使计算机能够从数据中学习,并在无需编程的情况下进行预测或决策。这涉及到开发能够识别数据模式的算法,并通过更多的数据和反馈不断改进其性能。
首先,PyTorch 是一个张量库,它在数组导向编程库 NumPy 的基础上扩展了功能,增加了对 GPU 加速计算的支持,从而实现了 CPU 和 GPU 之间的无缝切换。
其次,PyTorch 是一个自动微分引擎,也称为 autograd,它能够自动计算张量操作的梯度,从而简化反向传播过程和模型优化。
最后,PyTorch 是一个深度学习库,提供模块化、灵活和高效的构建模块(包括预训练模型、损失函数和优化器),用于设计和训练各种深度学习模型,同时满足研究人员和开发人员的需求。
在接下来的小节中,我们将首先定义深度学习的概念并介绍如何安装 PyTorch。随后,本章将详细讲解 PyTorch 的三个核心组件,并通过实际的代码示例进行演示。
### A.1.2 定义深度学习
大语言模型(LLM)经常在新闻中被称为人工智能(AI)模型。然而,正如第一章第 1 节(“什么是大语言模型?”)中所示,大语言模型也是一种深度神经网络,而 PyTorch 是一个深度学习库。听起来是不是有些混乱?让我们在继续之前,简要总结一下这些术语之间的关系。
人工智能的核心在于创建能够执行高级任务(所谓高级是指通常需要达到人类智能才能完成)的计算机系统。这些任务包括理解自然语言、识别模式和做决策(尽管已有显著进展,但AI仍远未实现这一层次的通用智能)。
机器学习是人工智能的一个子领域(如图 A.2 所示),其重点在于开发和改进学习算法。机器学习的核心思想是使计算机能够从数据中学习,并在无需编程的情况下进行预测或决策。这涉及到开发能够识别数据模式的算法,并通过更多的数据和反馈不断改进其性能。
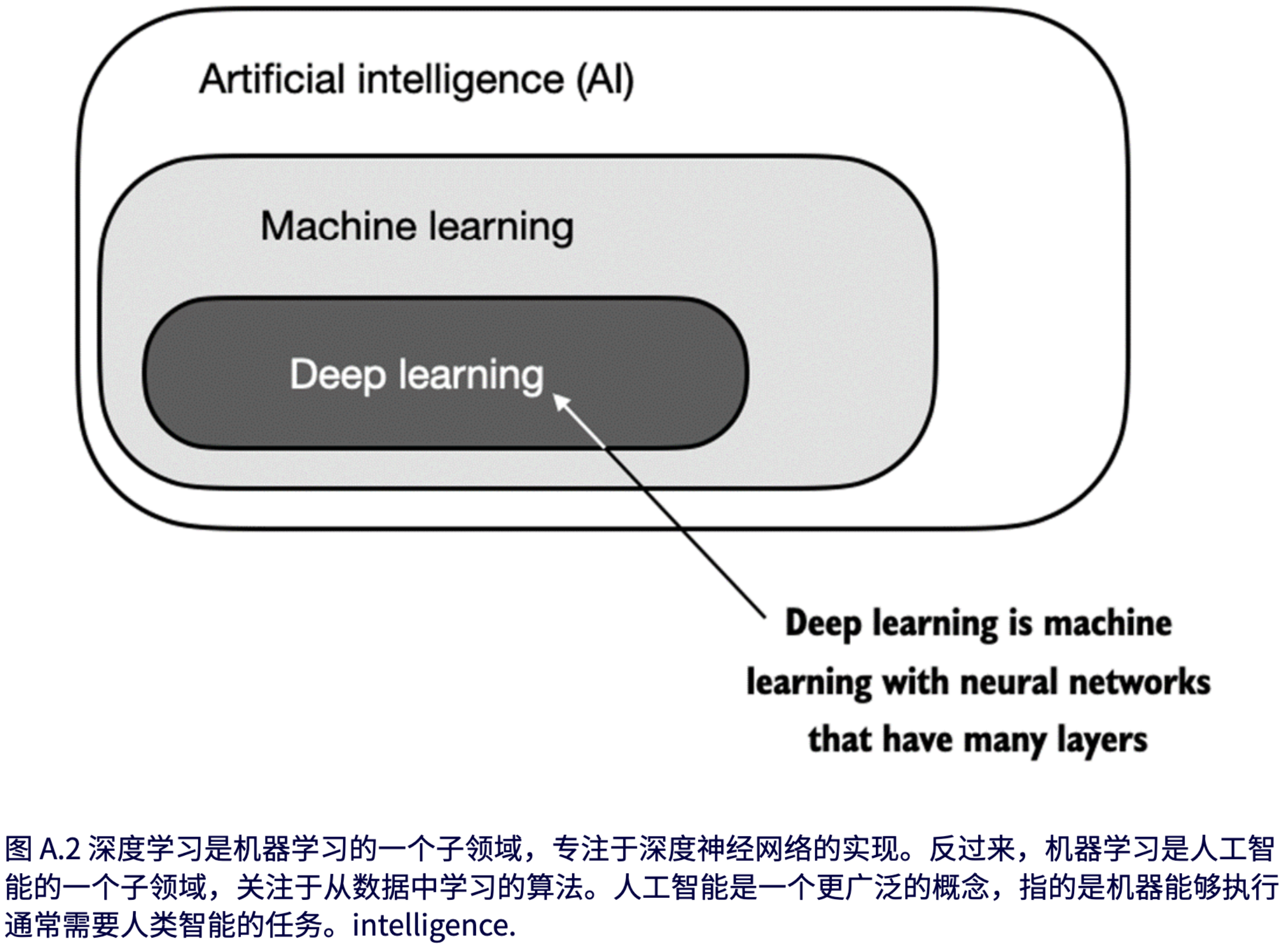 机器学习在人工智能的发展中一直扮演着至关重要的角色,推动了包括大语言模型(LLM)在内的许多的技术进步,例如在线零售商和流媒体服务使用的推荐系统、电子邮件垃圾邮件过滤、虚拟助手中的语音识别,甚至是自动驾驶汽车。机器学习的引入和发展极大地增强了人工智能的能力,使其能够超越严格的基于规则的系统,并适应新的输入或变化的环境。
深度学习是机器学习的一个子领域,专注于深度神经网络的训练和应用。这些深度神经网络最初的灵感来源于人脑的工作方式,特别是众多神经元之间的相互连接。深度学习中的“深度”指的是人工神经元或节点的多个隐藏层,这些隐藏层使其能够建模数据中复杂的非线性关系。
> [!TIP]
>
> **个人思考:** 没有了解过深度学习的同学可能很难理解这里的隐藏层。隐藏层其实就是深度神经网络中介于输入层和输出层之间的一层或多层节点(神经元)。它们在网络的训练过程中负责处理输入数据并提取其中的特征,帮助网络做出预测或分类。可以把隐藏层想象成是一个数据处理的“黑箱”,它根据输入的数据进行计算,生成一些新的信息,然后将这些信息传递给下一个层级,直到最终输出结果。
>
> 举个简单的图像分类神经网络的例子:
>
> 假设你想训练一个神经网络来判断一个图片是猫还是狗。
>
> 1. **输入层:** 这是网络的第一层,接收图片的原始像素数据(比如图片中每个点的颜色值)。每个像素值就相当于网络的一个“输入”。
>
> 2. **隐藏层:** 这里的神经元会对这些输入数据进行处理。例如,网络可能会从原始像素中提取出一些特征,如图片的边缘、颜色或纹理。每个隐藏层神经元负责从输入数据中提取一个特定的特征,多个隐藏层可能会在不同的抽象层次上提取出更复杂的特征(如形状、对象等)。比如,第一层隐藏层可能会提取出图像的边缘信息,而第二层隐藏层则可能会将边缘信息组合起来,识别出动物的轮廓。进一步的隐藏层可以开始识别更多高级特征,比如“耳朵”或“鼻子”。
> 2. **输出层:** 最后,经过所有隐藏层的处理,输出层会根据网络提取的特征做出判断,最终告诉你这张图片是猫还是狗。
>
> 从这个例子中可以看出,隐藏层其实就是负责提取数据的特征,而每一层隐藏层都会逐渐提取更高层次的特征,帮助网络更好地理解数据,例如,从原始的像素数据到形状、颜色,再到物体的具体内容。
与擅长简单模式识别的传统机器学习技术不同,深度学习尤其擅长处理非结构化数据,如图像、音频或文本,因此,深度学习特别适合用于大语言模型(LLM)。
下图 A.3 总结了机器学习和深度学习中典型的预测建模工作流程(也称为监督学习)。
机器学习在人工智能的发展中一直扮演着至关重要的角色,推动了包括大语言模型(LLM)在内的许多的技术进步,例如在线零售商和流媒体服务使用的推荐系统、电子邮件垃圾邮件过滤、虚拟助手中的语音识别,甚至是自动驾驶汽车。机器学习的引入和发展极大地增强了人工智能的能力,使其能够超越严格的基于规则的系统,并适应新的输入或变化的环境。
深度学习是机器学习的一个子领域,专注于深度神经网络的训练和应用。这些深度神经网络最初的灵感来源于人脑的工作方式,特别是众多神经元之间的相互连接。深度学习中的“深度”指的是人工神经元或节点的多个隐藏层,这些隐藏层使其能够建模数据中复杂的非线性关系。
> [!TIP]
>
> **个人思考:** 没有了解过深度学习的同学可能很难理解这里的隐藏层。隐藏层其实就是深度神经网络中介于输入层和输出层之间的一层或多层节点(神经元)。它们在网络的训练过程中负责处理输入数据并提取其中的特征,帮助网络做出预测或分类。可以把隐藏层想象成是一个数据处理的“黑箱”,它根据输入的数据进行计算,生成一些新的信息,然后将这些信息传递给下一个层级,直到最终输出结果。
>
> 举个简单的图像分类神经网络的例子:
>
> 假设你想训练一个神经网络来判断一个图片是猫还是狗。
>
> 1. **输入层:** 这是网络的第一层,接收图片的原始像素数据(比如图片中每个点的颜色值)。每个像素值就相当于网络的一个“输入”。
>
> 2. **隐藏层:** 这里的神经元会对这些输入数据进行处理。例如,网络可能会从原始像素中提取出一些特征,如图片的边缘、颜色或纹理。每个隐藏层神经元负责从输入数据中提取一个特定的特征,多个隐藏层可能会在不同的抽象层次上提取出更复杂的特征(如形状、对象等)。比如,第一层隐藏层可能会提取出图像的边缘信息,而第二层隐藏层则可能会将边缘信息组合起来,识别出动物的轮廓。进一步的隐藏层可以开始识别更多高级特征,比如“耳朵”或“鼻子”。
> 2. **输出层:** 最后,经过所有隐藏层的处理,输出层会根据网络提取的特征做出判断,最终告诉你这张图片是猫还是狗。
>
> 从这个例子中可以看出,隐藏层其实就是负责提取数据的特征,而每一层隐藏层都会逐渐提取更高层次的特征,帮助网络更好地理解数据,例如,从原始的像素数据到形状、颜色,再到物体的具体内容。
与擅长简单模式识别的传统机器学习技术不同,深度学习尤其擅长处理非结构化数据,如图像、音频或文本,因此,深度学习特别适合用于大语言模型(LLM)。
下图 A.3 总结了机器学习和深度学习中典型的预测建模工作流程(也称为监督学习)。
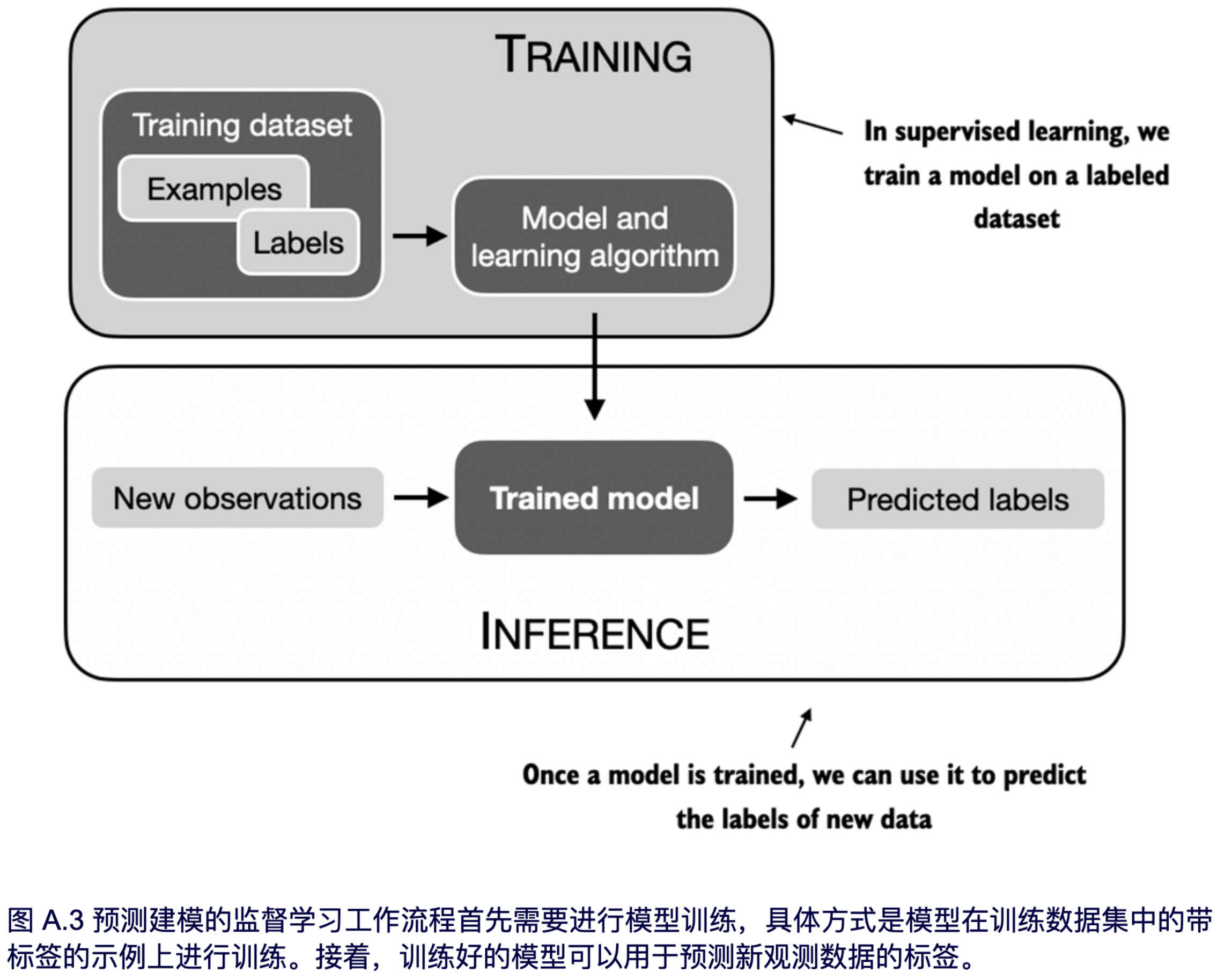 如上图所示,模型通过使用一种学习算法在包含示例及其对应标签的训练数据集上进行训练。例如,在电子邮件垃圾邮件分类器的案例中,训练数据集包含电子邮件及其由人工标注的垃圾邮件和非垃圾邮件标签。然后,训练好的模型可以用于新的观测数据(新的电子邮件),以预测它们未知的标签(垃圾邮件或非垃圾邮件)。
当然,我们还需要在训练和推理阶段之间增加模型评估,以确保模型在应用于实际场景之前满足我们的性能标准。
请注意,正如本书后面将要介绍的那样,如果我们将大语言模型(LLM)用于文本分类,那么训练和使用它的工作流程与图 A.3 中描述的工作流程类似。如果将 LLM 用于文本生成(这也是本书的主要重点),图 A.3 仍然适用。在这种情况下,预训练期间的标签可以从文本本身派生出来(第一章介绍的下一个词预测任务),LLM 将在推理过程中根据输入提示生成全新的文本(而不是预测标签)。
### A.1.3 安装 PyTorch
PyTorch 的安装方式与其他 Python 库或包类似。然而,由于 PyTorch 是一个包含 CPU 和 GPU 兼容代码的综合库,因此其安装可能需要额外的说明。
> [!NOTE]
>
> **PYTHON 版本**
>
> 许多科学计算库并不能立即支持最新版本的 Python。因此,在安装 PyTorch 时,建议使用比最新版本低一到两个版本的 Python。例如,如果 Python 的最新版本是 3.13,那么推荐使用 Python 3.10 或 3.11。
例如,PyTorch 有两个版本:一个只支持 CPU 计算的精简版,以及一个同时支持 CPU 和 GPU 计算的版本。如果你的机器有一个支持CUDA 的 GPU 可用于深度学习(理想情况下是 NVIDIA T4、RTX 2080 Ti 或更新的型号),我建议安装 GPU 版本。无论哪种情况,在命令行中安装 PyTorch 的默认命令如下:
``` bash
pip install torch
```
假设你的计算机支持兼容 CUDA 的 GPU,只要你正在使用的 Python 环境安装了必要的依赖项(如 pip),该命令将自动安装支持通过 CUDA 进行 GPU 加速的 PyTorch 版本。
> [!NOTE]
>
> **用于深度学习的 AMD GPU**
>
> 截至本书撰写之时,PyTorch 也已经通过 ROCm 添加了对 AMD GPU 的实验性支持。请访问 https://pytorch.org 查看更多说明。
然而,为了明确安装与 CUDA 兼容的 PyTorch 版本,通常最好指定你希望 PyTorch 兼容的 CUDA 版本。PyTorch 的官方网站 (https://pytorch.org) 提供了针对不同操作系统的、带有 CUDA 支持的 PyTorch 安装命令,如图 A.4 所示。
如上图所示,模型通过使用一种学习算法在包含示例及其对应标签的训练数据集上进行训练。例如,在电子邮件垃圾邮件分类器的案例中,训练数据集包含电子邮件及其由人工标注的垃圾邮件和非垃圾邮件标签。然后,训练好的模型可以用于新的观测数据(新的电子邮件),以预测它们未知的标签(垃圾邮件或非垃圾邮件)。
当然,我们还需要在训练和推理阶段之间增加模型评估,以确保模型在应用于实际场景之前满足我们的性能标准。
请注意,正如本书后面将要介绍的那样,如果我们将大语言模型(LLM)用于文本分类,那么训练和使用它的工作流程与图 A.3 中描述的工作流程类似。如果将 LLM 用于文本生成(这也是本书的主要重点),图 A.3 仍然适用。在这种情况下,预训练期间的标签可以从文本本身派生出来(第一章介绍的下一个词预测任务),LLM 将在推理过程中根据输入提示生成全新的文本(而不是预测标签)。
### A.1.3 安装 PyTorch
PyTorch 的安装方式与其他 Python 库或包类似。然而,由于 PyTorch 是一个包含 CPU 和 GPU 兼容代码的综合库,因此其安装可能需要额外的说明。
> [!NOTE]
>
> **PYTHON 版本**
>
> 许多科学计算库并不能立即支持最新版本的 Python。因此,在安装 PyTorch 时,建议使用比最新版本低一到两个版本的 Python。例如,如果 Python 的最新版本是 3.13,那么推荐使用 Python 3.10 或 3.11。
例如,PyTorch 有两个版本:一个只支持 CPU 计算的精简版,以及一个同时支持 CPU 和 GPU 计算的版本。如果你的机器有一个支持CUDA 的 GPU 可用于深度学习(理想情况下是 NVIDIA T4、RTX 2080 Ti 或更新的型号),我建议安装 GPU 版本。无论哪种情况,在命令行中安装 PyTorch 的默认命令如下:
``` bash
pip install torch
```
假设你的计算机支持兼容 CUDA 的 GPU,只要你正在使用的 Python 环境安装了必要的依赖项(如 pip),该命令将自动安装支持通过 CUDA 进行 GPU 加速的 PyTorch 版本。
> [!NOTE]
>
> **用于深度学习的 AMD GPU**
>
> 截至本书撰写之时,PyTorch 也已经通过 ROCm 添加了对 AMD GPU 的实验性支持。请访问 https://pytorch.org 查看更多说明。
然而,为了明确安装与 CUDA 兼容的 PyTorch 版本,通常最好指定你希望 PyTorch 兼容的 CUDA 版本。PyTorch 的官方网站 (https://pytorch.org) 提供了针对不同操作系统的、带有 CUDA 支持的 PyTorch 安装命令,如图 A.4 所示。
 (注意,图 A.4 中显示的命令也会安装 torchvision 和 torchaudio 库,这两个库对于本书是可选的。)
截至本书撰写之时,本书基于 PyTorch 2.0.1,因此建议使用以下安装命令来安装确切的版本,以保证与本书的兼容性:
``` python
pip install torch==2.0.1
```
然而,如前所述,考虑到你的操作系统,安装命令可能与上面显示的略有不同。因此,我建议你访问 https://pytorch.org 网站,并使用安装菜单(见图 A.4)选择适合你操作系统的安装命令,然后将该命令中的 `torch` 替换为 `torch==2.0.1`。
要检查 PyTorch 的版本,你可以在 PyTorch 中执行以下代码:
```python
import torch
torch.__version__
```
打印出的结果如下:
```python
'2.0.1'
```
> [!NOTE]
>
> **PYTORCH 和 TORCH**
>
> 请注意,Python 库之所以命名为 “torch”,主要是因为它是在 Torch 库的基础上进行延续并为 Python 进行了适配(因此得名 “PyTorch”)。名称 “torch” 承认该库的根源在于 Torch,这是一个广泛支持机器学习算法的科学计算框架,最初是使用 Lua 编程语言创建的。
如果你正在寻找关于设置你的 Python 环境或安装本书后续章节中使用的其他库的更多建议和说明,我建议你访问本书的补充 GitHub 仓库:https://github.com/rasbt/LLMs-from-scratch。
安装 PyTorch 之后,你可以通过在 Python 中运行以下代码来检查你的安装是否能够检测并且使用你电脑上的 NVIDIA 显卡:
```python
import torch
torch.cuda.is_available()
```
上述代码返回:
```python
True
```
如果命令返回 `True`,那就说明你的配置没问题了。如果命令返回 `False`,那可能是你的电脑没有兼容的显卡,或者 PyTorch 没有检测到它。虽然本书的前几章内容并不强制要求使用 GPU(主要出于教学目的),但它们可以显著加快与深度学习相关的计算速度。
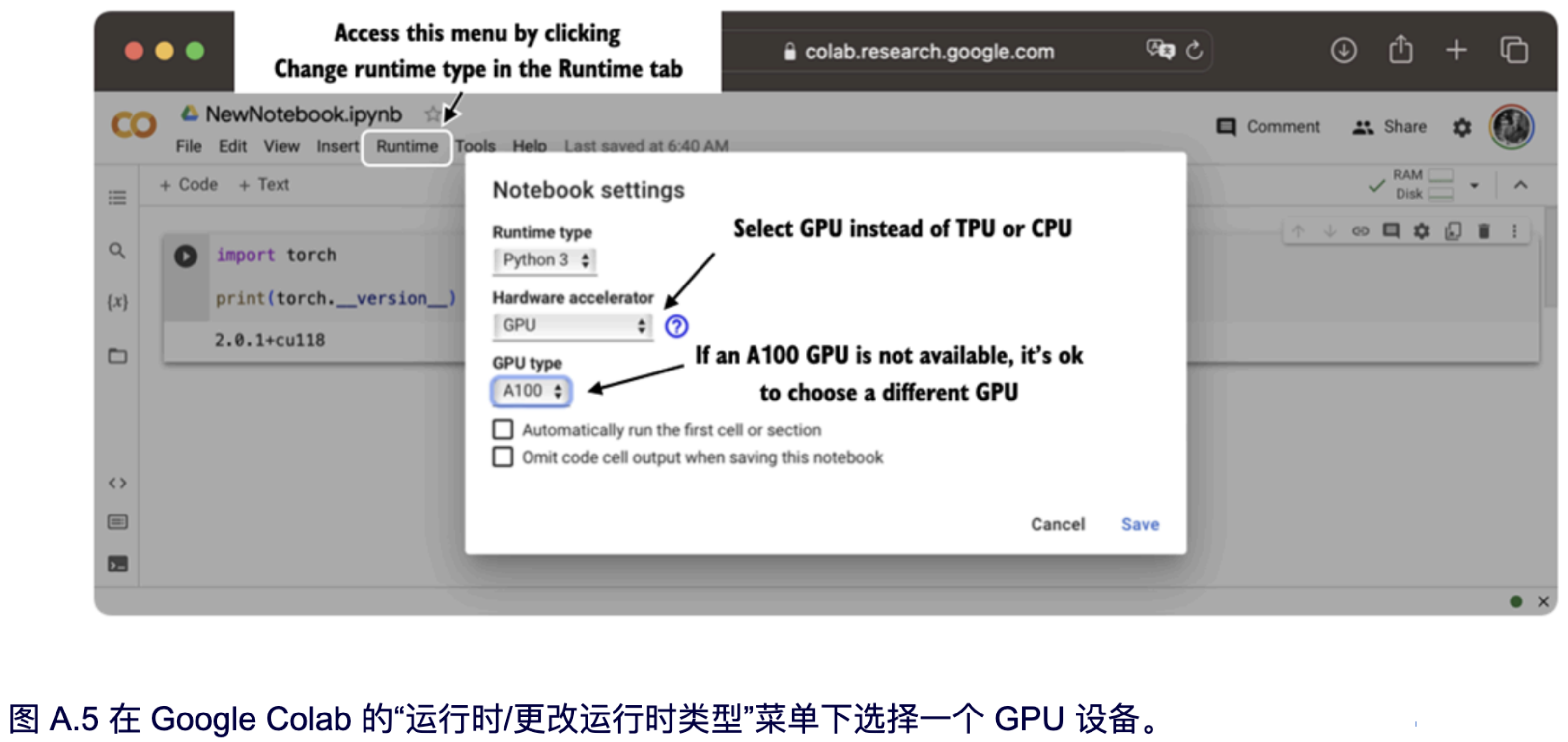
如果你没有 GPU,有一些云计算服务提供商可以按小时收费让你使用 GPU 进行计算。一个很受欢迎的、类似于 Jupyter Notebook 的环境是 Google Colab (https://colab.research.google.com),截至本书撰写之时,它提供有时限的 GPU 使用权限。通过“运行时”菜单,你可以选择使用 GPU,如图 A.5 的截图所示。
(注意,图 A.4 中显示的命令也会安装 torchvision 和 torchaudio 库,这两个库对于本书是可选的。)
截至本书撰写之时,本书基于 PyTorch 2.0.1,因此建议使用以下安装命令来安装确切的版本,以保证与本书的兼容性:
``` python
pip install torch==2.0.1
```
然而,如前所述,考虑到你的操作系统,安装命令可能与上面显示的略有不同。因此,我建议你访问 https://pytorch.org 网站,并使用安装菜单(见图 A.4)选择适合你操作系统的安装命令,然后将该命令中的 `torch` 替换为 `torch==2.0.1`。
要检查 PyTorch 的版本,你可以在 PyTorch 中执行以下代码:
```python
import torch
torch.__version__
```
打印出的结果如下:
```python
'2.0.1'
```
> [!NOTE]
>
> **PYTORCH 和 TORCH**
>
> 请注意,Python 库之所以命名为 “torch”,主要是因为它是在 Torch 库的基础上进行延续并为 Python 进行了适配(因此得名 “PyTorch”)。名称 “torch” 承认该库的根源在于 Torch,这是一个广泛支持机器学习算法的科学计算框架,最初是使用 Lua 编程语言创建的。
如果你正在寻找关于设置你的 Python 环境或安装本书后续章节中使用的其他库的更多建议和说明,我建议你访问本书的补充 GitHub 仓库:https://github.com/rasbt/LLMs-from-scratch。
安装 PyTorch 之后,你可以通过在 Python 中运行以下代码来检查你的安装是否能够检测并且使用你电脑上的 NVIDIA 显卡:
```python
import torch
torch.cuda.is_available()
```
上述代码返回:
```python
True
```
如果命令返回 `True`,那就说明你的配置没问题了。如果命令返回 `False`,那可能是你的电脑没有兼容的显卡,或者 PyTorch 没有检测到它。虽然本书的前几章内容并不强制要求使用 GPU(主要出于教学目的),但它们可以显著加快与深度学习相关的计算速度。
如果你没有 GPU,有一些云计算服务提供商可以按小时收费让你使用 GPU 进行计算。一个很受欢迎的、类似于 Jupyter Notebook 的环境是 Google Colab (https://colab.research.google.com),截至本书撰写之时,它提供有时限的 GPU 使用权限。通过“运行时”菜单,你可以选择使用 GPU,如图 A.5 的截图所示。
 > [!NOTE]
>
> **Apple Silicon 上的 PyTorch**
>
> 如果你有一台搭载 Apple Silicon 芯片(例如 M1、M2、M3 或更新型号)的苹果 Mac 电脑,你可以选择利用它的性能来加速 PyTorch 代码的执行。要使用你的 Apple Silicon 芯片来运行 PyTorch,你首先需要像之前一样安装 PyTorch。然后,要检查你的 Mac 是否支持通过其 Apple Silicon 芯片加速 PyTorch,你可以在 Python 中运行一个简单的代码片段:
>
> ```python
> print(torch.backends.mps.is_available())
> ```
>
> 如果它返回 `True`,那就意味着你的 Mac 电脑配备了可以用来加速 PyTorch 代码的 Apple Silicon 芯片。
> [!NOTE]
>
> **练习 A.1**
>
> 在你的电脑上安装并配置好 PyTorch。
> [!NOTE]
>
> **练习 A.2**
>
> 运行位于 https://github.com/rasbt/LLMs-from-scratch 的补充材料中第二章的代码,该代码会检查你的环境是否已正确设置。
## A.2 理解张量
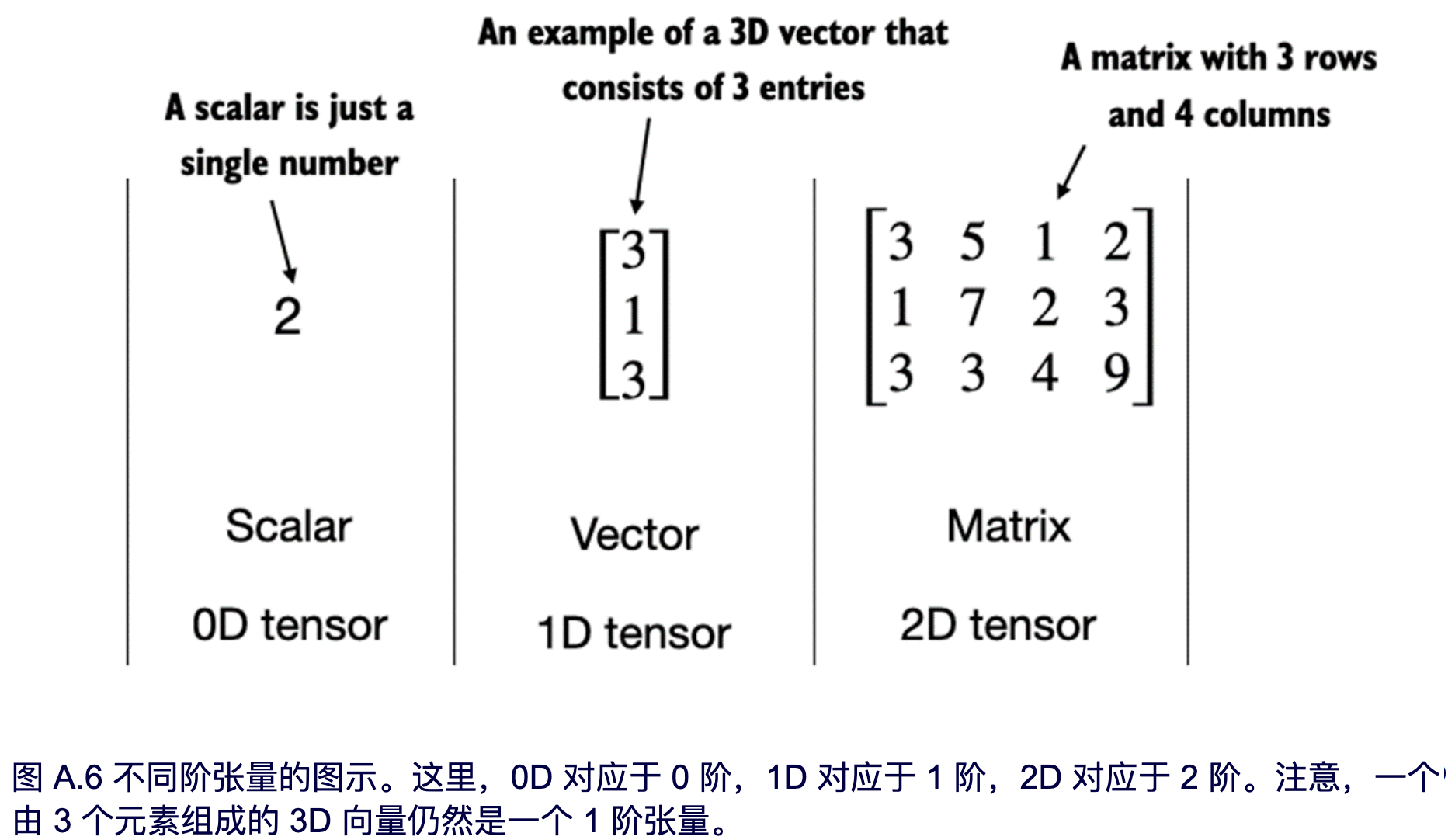
张量代表一个将向量和矩阵向更高维度的推广的数学概念。换句话说,张量是可以用它们的阶(或秩)来描述的数学对象,阶(或秩)表示了张量的维度数量。例如,一个标量(就是一个数字)是 0 阶张量,一个向量是 1 阶张量,一个矩阵是 2 阶张量,如图 A.6 所示。
> [!NOTE]
>
> **Apple Silicon 上的 PyTorch**
>
> 如果你有一台搭载 Apple Silicon 芯片(例如 M1、M2、M3 或更新型号)的苹果 Mac 电脑,你可以选择利用它的性能来加速 PyTorch 代码的执行。要使用你的 Apple Silicon 芯片来运行 PyTorch,你首先需要像之前一样安装 PyTorch。然后,要检查你的 Mac 是否支持通过其 Apple Silicon 芯片加速 PyTorch,你可以在 Python 中运行一个简单的代码片段:
>
> ```python
> print(torch.backends.mps.is_available())
> ```
>
> 如果它返回 `True`,那就意味着你的 Mac 电脑配备了可以用来加速 PyTorch 代码的 Apple Silicon 芯片。
> [!NOTE]
>
> **练习 A.1**
>
> 在你的电脑上安装并配置好 PyTorch。
> [!NOTE]
>
> **练习 A.2**
>
> 运行位于 https://github.com/rasbt/LLMs-from-scratch 的补充材料中第二章的代码,该代码会检查你的环境是否已正确设置。
## A.2 理解张量
张量代表一个将向量和矩阵向更高维度的推广的数学概念。换句话说,张量是可以用它们的阶(或秩)来描述的数学对象,阶(或秩)表示了张量的维度数量。例如,一个标量(就是一个数字)是 0 阶张量,一个向量是 1 阶张量,一个矩阵是 2 阶张量,如图 A.6 所示。
 从计算的角度来看,张量充当数据容器。例如,它们可以存储多维数据,其中每个维度代表一个不同的特征。张量库(例如 PyTorch)可以高效地创建、操作和计算这些多维数组。在这种情况下,张量库的作用类似于数组库。
PyTorch 张量与 NumPy 数组类似,但具有一些对深度学习来说很重要的额外特性。例如,PyTorch 添加了一个自动微分引擎,简化了梯度的计算,这将在后面的 2.4 节中讨论。PyTorch 张量还支持 GPU 计算,以加速深度神经网络的训练,我们将在后面的 2.8 节中讨论。
> [!NOTE]
>
> **PyTorch 拥有类似 NumPy 的 API**
>
> 正如接下来的章节所示,PyTorch 在其张量运算中采用了大部分 NumPy 数组 API 和语法。如果你不熟悉 NumPy ,可以通过我的文章《Python 科学计算:NumPy 和 Matplotlib 简介》(https://sebastianraschka.com/blog/2020/numpy-intro.html)快速了解最相关的概念。
接下来的小节将介绍 PyTorch 张量库的基本操作,展示如何创建简单的张量以及一些基本操作。
### A.2.1 标量、向量、矩阵和张量
如前所述,PyTorch 张量是用于存储类似数组结构的数据容器。标量是 0 维张量(例如,一个简单的数字),向量是 1 维张量,而矩阵是 2 维张量。对于更高维度的张量没有特定的术语,所以我们通常将 3 维张量称为 3D 张量,以此类推。
我们可以使用 `torch.tensor` 函数创建 PyTorch 的 `Tensor` 类的对象,如下所示:
``` python
# Listing A.1 Creating PyTorch tensors
import torch
tensor0d = torch.tensor(1) #A
tensor1d = torch.tensor([1, 2, 3]) #B
tensor2d = torch.tensor([[1, 2], [3, 4]]) #C
tensor3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) #D
#A 从 Python 整数创建一个 0 维张量(标量)
#B 从 Python 列表创建一个 1 维张量(向量)
#C 从嵌套的 Python 列表创建一个 2 维张量
#D 从嵌套的 Python 列表创建一个 3 维张量
```
### A.2.2 张量数据类型
在前一节中,我们从 Python 整数创建了张量。在这种情况下,PyTorch 采用了 Python 的默认 64 位整数类型。我们可以通过张量的 `.dtype` 属性来访问张量的数据类型:
``` python
tensor1d = torch.tensor([1, 2, 3])
print(tensor1d.dtype)
```
输出如下:
``` python
torch.int64
```
如果我们从 Python 浮点数创建张量,PyTorch 默认会创建具有 32 位精度的张量,如下所示:
```python
floatvec = torch.tensor([1.0, 2.0, 3.0])
print(floatvec.dtype)
```
输出如下:
```python
torch.float32
```
这种选择主要是基于精度和计算效率之间的平衡。对于大多数深度学习任务来说,32 位浮点数提供了足够的精度,同时比 64 位浮点数消耗更少的内存和计算资源。此外,GPU 架构针对 32 位计算进行了优化,使用这种数据类型可以显著加快模型训练和推理的速度。
此外,可以使用张量的 `.to` 方法轻松地更改精度。以下代码通过将一个 64 位整数张量转换为一个 32 位浮点张量来演示这一点:
```python
floatvec = tensor1d.to(torch.float32)
print(floatvec.dtype)
```
输出如下:
``` python
torch.float32
```
要了解更多关于 PyTorch 中可用的不同张量数据类型的信息,我建议查看官方文档:https://pytorch.org/docs/stable/tensors.html。
### A.2.3 常用的 PyTorch 张量操作
本书无法全面涵盖所有不同的 PyTorch 张量操作和命令,但我们会在本书中介绍相关操作时简要描述它们。
在我们继续学习下一节关于计算图概念的内容之前,下面列出了一些最基本的 PyTorch 张量操作。
我们已经介绍过使用 `torch.tensor()` 函数来创建新的张量。
```python
tensor2d = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(tensor2d)
```
结果如下:
```python
tensor([[1, 2, 3],
[4, 5, 6]])
```
此外,`.shape` 属性允许我们访问张量的形状:
```python
print(tensor2d.shape)
```
输出如下:
```python
torch.Size([2, 3])
```
如你所见,`.shape` 返回 `[2, 3]`,这意味着该张量有 2 行和 3 列。要将该张量重塑为一个 3 行 2 列的张量,我们可以使用 `.reshape` 方法:
```python
print(tensor2d.reshape(3, 2))
```
结果如下:
```python
tensor([[1, 2],
[3, 4],
[5, 6]])
```
然而,请注意,在 PyTorch 中,更常用的重塑张量的命令是 `.view()`:
```python
print(tensor2d.view(3, 2))
```
输出如下:
```python
tensor([[1, 2],
[3, 4],
[5, 6]])
```
与 `.reshape` 和 `.view` 类似,在很多情况下,PyTorch 为执行相同的计算提供了多种语法选项。这是因为 PyTorch 最初遵循了 Lua Torch 的原始语法约定,但后来应广大用户的要求,也添加了使其更类似于 NumPy 的语法。
接下来,我们可以使用 `.T` 来转置一个张量,这意味着沿着它的对角线翻转它。注意,这与重塑张量类似,你可以从下面的结果中看到:
```python
print(tensor2d.T)
```
输出如下:
```python
tensor([[1, 4],
[2, 5],
[3, 6]])
```
最后,在 PyTorch 中,常用的矩阵相乘的方法是 `.matmul`:
```python
print(tensor2d.matmul(tensor2d.T))
```
结果如下:
```python
tensor([[14, 32],
[32, 77]])
```
然而,我们也可以使用 `@` 运算符,它可以更简洁地完成同样的事情:
```python
print(tensor2d @ tensor2d.T)
```
输出如下:
```python
tensor([[14, 32],
[32, 77]])
```
如前所述,我们将在本书的后续内容中根据需要介绍其他操作。对于想要浏览 PyTorch 中所有不同张量操作的读者(提示:我们不会用到其中的大多数),我建议查看官方文档:https://pytorch.org/docs/stable/tensors.html。
## A.3 将模型视为计算图
在前一节中,我们介绍了 PyTorch 的三个主要组成部分之一,即其张量库。接下来介绍 PyTorch 的自动微分引擎,也称为 autograd。PyTorch 的 autograd 系统提供了自动计算动态计算图中梯度的功能。但在我们深入探讨下一节中梯度的计算之前,让我们先定义一下计算图的概念。
计算图是一个有向图,它允许我们表达和可视化数学表达式。在深度学习的背景下,计算图描绘了计算神经网络输出所需的计算序列——我们稍后将需要它来计算反向传播所需的梯度,反向传播是神经网络的主要训练算法。
让我们看一个具体的例子来解释计算图的概念。以下代码实现了一个简单逻辑回归分类器的前向传播(预测步骤),它可以被看作是一个单层神经网络,返回一个介于 0 和 1 之间的分数,在计算损失时,这个分数会与真实的类别标签(0 或 1)进行比较:
```python
# Listing A.2 A logistic regression forward pass
import torch.nn.functional as F #A
y = torch.tensor([1.0]) #B
x1 = torch.tensor([1.1]) #C
w1 = torch.tensor([2.2]) #D
b = torch.tensor([0.0]) #E
z = x1 * w1 + b #F
a = torch.sigmoid(z) #G
loss = F.binary_cross_entropy(a, y)
#A 这是 PyTorch 中常见的导入约定,用于避免代码行过长
#B 真实标签
#C 输入特征
#D 权重参数
#E 偏置单元
#F 网络输入
#G 激活与输出
```
如果你不完全理解上面代码中的所有内容,不用担心。这个例子的重点不是实现一个逻辑回归分类器,而是为了说明我们如何将一系列计算视为一个计算图,如图 A.7 所示。
从计算的角度来看,张量充当数据容器。例如,它们可以存储多维数据,其中每个维度代表一个不同的特征。张量库(例如 PyTorch)可以高效地创建、操作和计算这些多维数组。在这种情况下,张量库的作用类似于数组库。
PyTorch 张量与 NumPy 数组类似,但具有一些对深度学习来说很重要的额外特性。例如,PyTorch 添加了一个自动微分引擎,简化了梯度的计算,这将在后面的 2.4 节中讨论。PyTorch 张量还支持 GPU 计算,以加速深度神经网络的训练,我们将在后面的 2.8 节中讨论。
> [!NOTE]
>
> **PyTorch 拥有类似 NumPy 的 API**
>
> 正如接下来的章节所示,PyTorch 在其张量运算中采用了大部分 NumPy 数组 API 和语法。如果你不熟悉 NumPy ,可以通过我的文章《Python 科学计算:NumPy 和 Matplotlib 简介》(https://sebastianraschka.com/blog/2020/numpy-intro.html)快速了解最相关的概念。
接下来的小节将介绍 PyTorch 张量库的基本操作,展示如何创建简单的张量以及一些基本操作。
### A.2.1 标量、向量、矩阵和张量
如前所述,PyTorch 张量是用于存储类似数组结构的数据容器。标量是 0 维张量(例如,一个简单的数字),向量是 1 维张量,而矩阵是 2 维张量。对于更高维度的张量没有特定的术语,所以我们通常将 3 维张量称为 3D 张量,以此类推。
我们可以使用 `torch.tensor` 函数创建 PyTorch 的 `Tensor` 类的对象,如下所示:
``` python
# Listing A.1 Creating PyTorch tensors
import torch
tensor0d = torch.tensor(1) #A
tensor1d = torch.tensor([1, 2, 3]) #B
tensor2d = torch.tensor([[1, 2], [3, 4]]) #C
tensor3d = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) #D
#A 从 Python 整数创建一个 0 维张量(标量)
#B 从 Python 列表创建一个 1 维张量(向量)
#C 从嵌套的 Python 列表创建一个 2 维张量
#D 从嵌套的 Python 列表创建一个 3 维张量
```
### A.2.2 张量数据类型
在前一节中,我们从 Python 整数创建了张量。在这种情况下,PyTorch 采用了 Python 的默认 64 位整数类型。我们可以通过张量的 `.dtype` 属性来访问张量的数据类型:
``` python
tensor1d = torch.tensor([1, 2, 3])
print(tensor1d.dtype)
```
输出如下:
``` python
torch.int64
```
如果我们从 Python 浮点数创建张量,PyTorch 默认会创建具有 32 位精度的张量,如下所示:
```python
floatvec = torch.tensor([1.0, 2.0, 3.0])
print(floatvec.dtype)
```
输出如下:
```python
torch.float32
```
这种选择主要是基于精度和计算效率之间的平衡。对于大多数深度学习任务来说,32 位浮点数提供了足够的精度,同时比 64 位浮点数消耗更少的内存和计算资源。此外,GPU 架构针对 32 位计算进行了优化,使用这种数据类型可以显著加快模型训练和推理的速度。
此外,可以使用张量的 `.to` 方法轻松地更改精度。以下代码通过将一个 64 位整数张量转换为一个 32 位浮点张量来演示这一点:
```python
floatvec = tensor1d.to(torch.float32)
print(floatvec.dtype)
```
输出如下:
``` python
torch.float32
```
要了解更多关于 PyTorch 中可用的不同张量数据类型的信息,我建议查看官方文档:https://pytorch.org/docs/stable/tensors.html。
### A.2.3 常用的 PyTorch 张量操作
本书无法全面涵盖所有不同的 PyTorch 张量操作和命令,但我们会在本书中介绍相关操作时简要描述它们。
在我们继续学习下一节关于计算图概念的内容之前,下面列出了一些最基本的 PyTorch 张量操作。
我们已经介绍过使用 `torch.tensor()` 函数来创建新的张量。
```python
tensor2d = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(tensor2d)
```
结果如下:
```python
tensor([[1, 2, 3],
[4, 5, 6]])
```
此外,`.shape` 属性允许我们访问张量的形状:
```python
print(tensor2d.shape)
```
输出如下:
```python
torch.Size([2, 3])
```
如你所见,`.shape` 返回 `[2, 3]`,这意味着该张量有 2 行和 3 列。要将该张量重塑为一个 3 行 2 列的张量,我们可以使用 `.reshape` 方法:
```python
print(tensor2d.reshape(3, 2))
```
结果如下:
```python
tensor([[1, 2],
[3, 4],
[5, 6]])
```
然而,请注意,在 PyTorch 中,更常用的重塑张量的命令是 `.view()`:
```python
print(tensor2d.view(3, 2))
```
输出如下:
```python
tensor([[1, 2],
[3, 4],
[5, 6]])
```
与 `.reshape` 和 `.view` 类似,在很多情况下,PyTorch 为执行相同的计算提供了多种语法选项。这是因为 PyTorch 最初遵循了 Lua Torch 的原始语法约定,但后来应广大用户的要求,也添加了使其更类似于 NumPy 的语法。
接下来,我们可以使用 `.T` 来转置一个张量,这意味着沿着它的对角线翻转它。注意,这与重塑张量类似,你可以从下面的结果中看到:
```python
print(tensor2d.T)
```
输出如下:
```python
tensor([[1, 4],
[2, 5],
[3, 6]])
```
最后,在 PyTorch 中,常用的矩阵相乘的方法是 `.matmul`:
```python
print(tensor2d.matmul(tensor2d.T))
```
结果如下:
```python
tensor([[14, 32],
[32, 77]])
```
然而,我们也可以使用 `@` 运算符,它可以更简洁地完成同样的事情:
```python
print(tensor2d @ tensor2d.T)
```
输出如下:
```python
tensor([[14, 32],
[32, 77]])
```
如前所述,我们将在本书的后续内容中根据需要介绍其他操作。对于想要浏览 PyTorch 中所有不同张量操作的读者(提示:我们不会用到其中的大多数),我建议查看官方文档:https://pytorch.org/docs/stable/tensors.html。
## A.3 将模型视为计算图
在前一节中,我们介绍了 PyTorch 的三个主要组成部分之一,即其张量库。接下来介绍 PyTorch 的自动微分引擎,也称为 autograd。PyTorch 的 autograd 系统提供了自动计算动态计算图中梯度的功能。但在我们深入探讨下一节中梯度的计算之前,让我们先定义一下计算图的概念。
计算图是一个有向图,它允许我们表达和可视化数学表达式。在深度学习的背景下,计算图描绘了计算神经网络输出所需的计算序列——我们稍后将需要它来计算反向传播所需的梯度,反向传播是神经网络的主要训练算法。
让我们看一个具体的例子来解释计算图的概念。以下代码实现了一个简单逻辑回归分类器的前向传播(预测步骤),它可以被看作是一个单层神经网络,返回一个介于 0 和 1 之间的分数,在计算损失时,这个分数会与真实的类别标签(0 或 1)进行比较:
```python
# Listing A.2 A logistic regression forward pass
import torch.nn.functional as F #A
y = torch.tensor([1.0]) #B
x1 = torch.tensor([1.1]) #C
w1 = torch.tensor([2.2]) #D
b = torch.tensor([0.0]) #E
z = x1 * w1 + b #F
a = torch.sigmoid(z) #G
loss = F.binary_cross_entropy(a, y)
#A 这是 PyTorch 中常见的导入约定,用于避免代码行过长
#B 真实标签
#C 输入特征
#D 权重参数
#E 偏置单元
#F 网络输入
#G 激活与输出
```
如果你不完全理解上面代码中的所有内容,不用担心。这个例子的重点不是实现一个逻辑回归分类器,而是为了说明我们如何将一系列计算视为一个计算图,如图 A.7 所示。
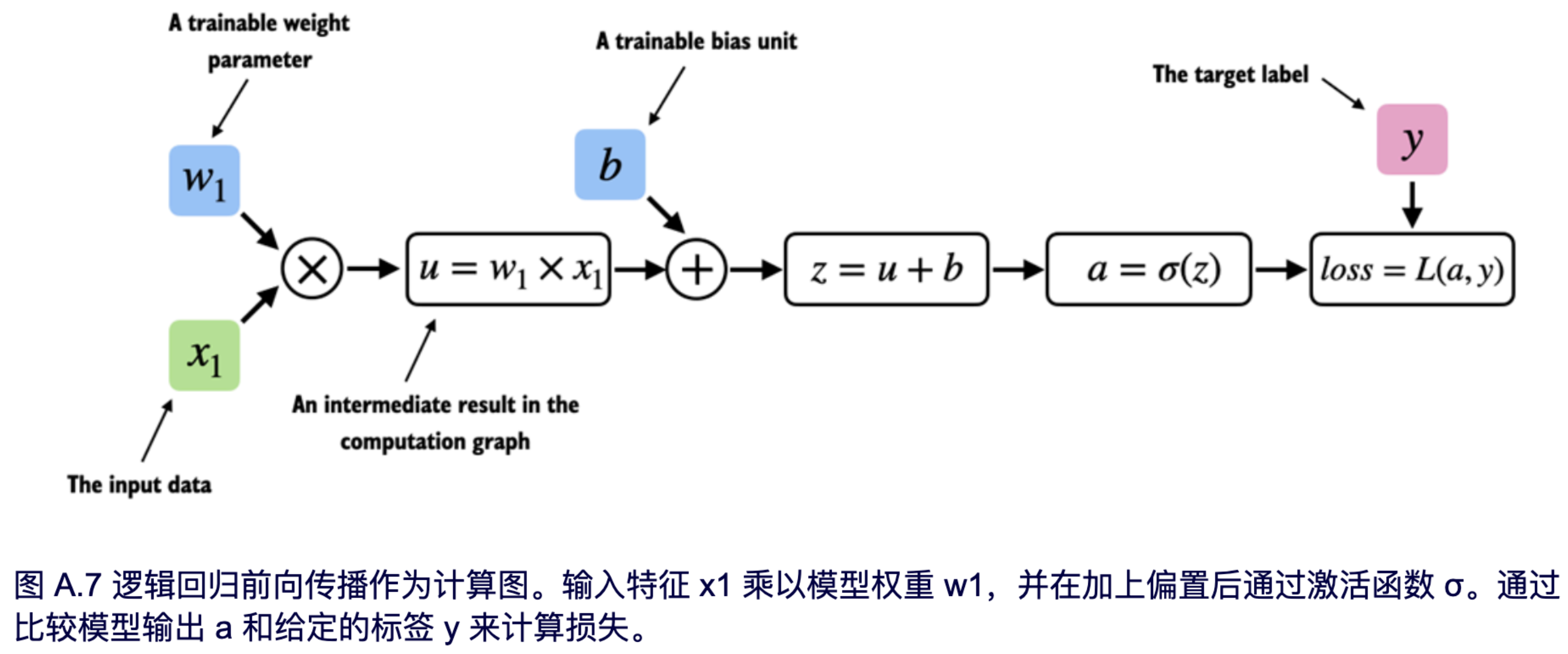 事实上,PyTorch 在后台构建了这样一个计算图,我们可以利用它来计算损失函数相对于模型参数(这里是 w1 和 b)的梯度,从而训练模型,这也是接下来章节的主题。
## A.4 轻松实现自动微分
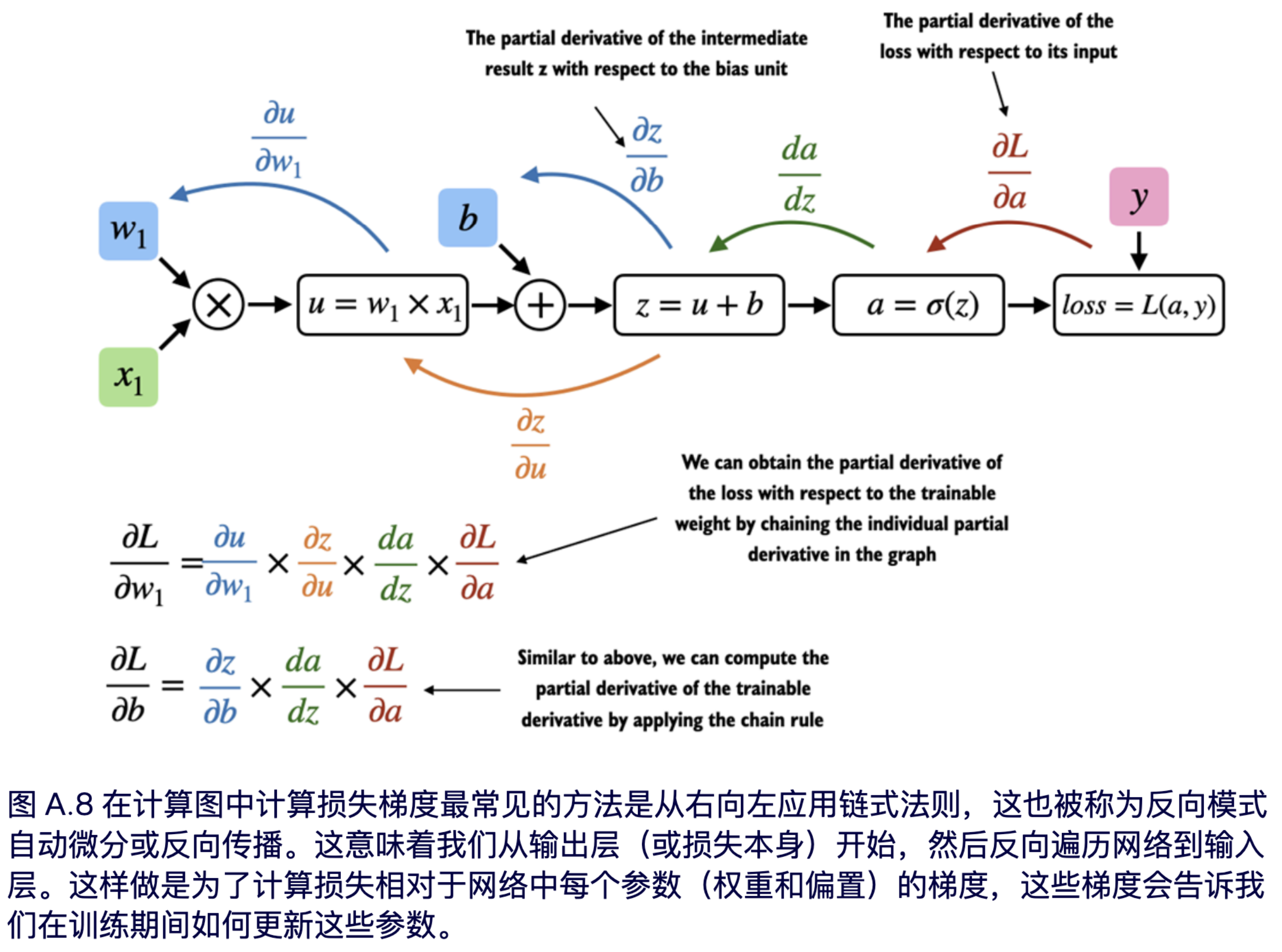
在上一节中,我们介绍了计算图的概念。如果在 PyTorch 中进行计算,默认情况下,PyTorch 通过构建计算图,并利用你设置的 `requires_grad=True` 标记,就能自动帮你计算出训练神经网络所需的关键信息——梯度,而反向传播就是利用这些梯度来更新模型参数,让模型变得更聪明。如图 A.8 所示。
事实上,PyTorch 在后台构建了这样一个计算图,我们可以利用它来计算损失函数相对于模型参数(这里是 w1 和 b)的梯度,从而训练模型,这也是接下来章节的主题。
## A.4 轻松实现自动微分
在上一节中,我们介绍了计算图的概念。如果在 PyTorch 中进行计算,默认情况下,PyTorch 通过构建计算图,并利用你设置的 `requires_grad=True` 标记,就能自动帮你计算出训练神经网络所需的关键信息——梯度,而反向传播就是利用这些梯度来更新模型参数,让模型变得更聪明。如图 A.8 所示。
 > [!TIP]
>
> **个人思考:** 这里说了一大串,核心其实就是 PyTorch 可以自动帮我们计算“变化率”(也就是梯度),而这个“变化率”对于训练神经网络非常重要。
>
> 更详细的解释一下:
>
> + **计算图是 PyTorch 在幕后做的事情:** 当你在 PyTorch 里进行一系列的数学计算时,它会在内部偷偷地记录下这些计算步骤,就像画一张流程图一样,这张流程图就叫做“计算图”。
> + **`requires_grad=True` 是一个开关:** 你可以告诉 PyTorch,对于某些参与计算的数字(更专业地说,是“张量”),你可能想知道它们是如何影响最终结果的。如果你这样做了(通过设置 `requires_grad=True`),PyTorch 就会特别留意这些数字,并在计算图中记录下相关的操作。
> + **梯度就是“变化率”:** “梯度”这个词听起来很专业,但你可以简单地理解为“变化率”。在神经网络中,我们想知道调整某个参数(比如权重)时,模型的输出会如何变化。梯度就告诉我们这种变化的快慢和方向。
> + **训练神经网络需要梯度:** 训练神经网络的目标是让模型的预测越来越准确。为了达到这个目标,我们需要不断地调整模型的参数。而如何调整参数呢?就需要用到梯度。
> + **反向传播是一种计算梯度的方法:** “反向传播”是训练神经网络最常用的方法。它本质上就是利用计算图和微积分中的“链式法则”来高效地计算出模型中所有参数的梯度。
### 偏导数与梯度
图 A.8 展示了偏导数,它衡量的是当函数的一个变量发生变化时,函数值的变化率。梯度是一个向量,它包含了多元函数(即输入包含多个变量的函数)的所有偏导数。
如果你不熟悉或者不记得微积分中的偏导数、梯度或链式法则,别担心。从高层次上来说,本书只需要知道链式法则是一种计算损失函数关于模型参数在计算图中的梯度的方法。这提供了更新每个参数所需的信息,以使其朝着最小化损失函数的方向变化。损失函数可以作为衡量模型性能的指标,而更新参数的方法通常是梯度下降。我们将在 2.7 节“一个典型的训练循环”中重新讨论在 PyTorch 中实现这个训练循环的计算过程。
那么,这一切是如何与我们之前提到的 PyTorch 库的第二个组成部分,即自动微分 (autograd) 引擎联系起来的呢?通过跟踪对张量执行的每一个操作,PyTorch 的 autograd 引擎在后台构建一个计算图。然后,通过调用 `grad` 函数,我们可以计算损失相对于模型参数 w1 的梯度,如下所示:
```python
# Listing A.3 Computing gradients via autograd
import torch.nn.functional as F
from torch.autograd import grad
y = torch.tensor([1.0])
x1 = torch.tensor([1.1])
w1 = torch.tensor([2.2], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
z = x1 * w1 + b
a = torch.sigmoid(z)
loss = F.binary_cross_entropy(a, y)
grad_L_w1 = grad(loss, w1, retain_graph=True) #A
grad_L_b = grad(loss, b, retain_graph=True)
#A 默认情况下,PyTorch 在计算完梯度后会销毁计算图以释放内存。然而,由于我们稍后将重用这个计算图,所以我们设置了 retain_graph=True,使其保留在内存中。
```
让我们来看看根据模型参数计算出的损失值:
```python
print(grad_L_w1)
print(grad_L_b)
```
输出如下:
```python
(tensor([-0.0898]),)
(tensor([-0.0817]),)
```
在上面,我们一直在“手动”使用 `grad` 函数,这对于实验、调试和演示概念很有用。但在实践中,PyTorch 提供了更高级别的工具来自动化这个过程。例如,我们可以在损失上调用 `.backward()`,PyTorch 将计算图中所有叶节点的梯度,这些梯度将存储在张量的 `.grad` 属性中:
```python
loss.backward()
print(w1.grad)
print(b.grad)
```
输出如下:
```python
(tensor([-0.0898]),)
(tensor([-0.0817]),)
```
如果本节信息量很大,并且你可能对微积分的概念感到不知所措,请不要担心。虽然这些微积分术语是为了解释 PyTorch 的 autograd 组件,但你只需要从本节中记住,PyTorch 会通过 `.backward` 方法为我们处理微积分——在本书中,我们不需要手动计算任何导数或梯度。
## A.5 实现多层神经网络
在之前的章节中,我们介绍了 PyTorch 的张量和自动微分组件。本节重点介绍如何通过 PyTorch 实现深度神经网络。
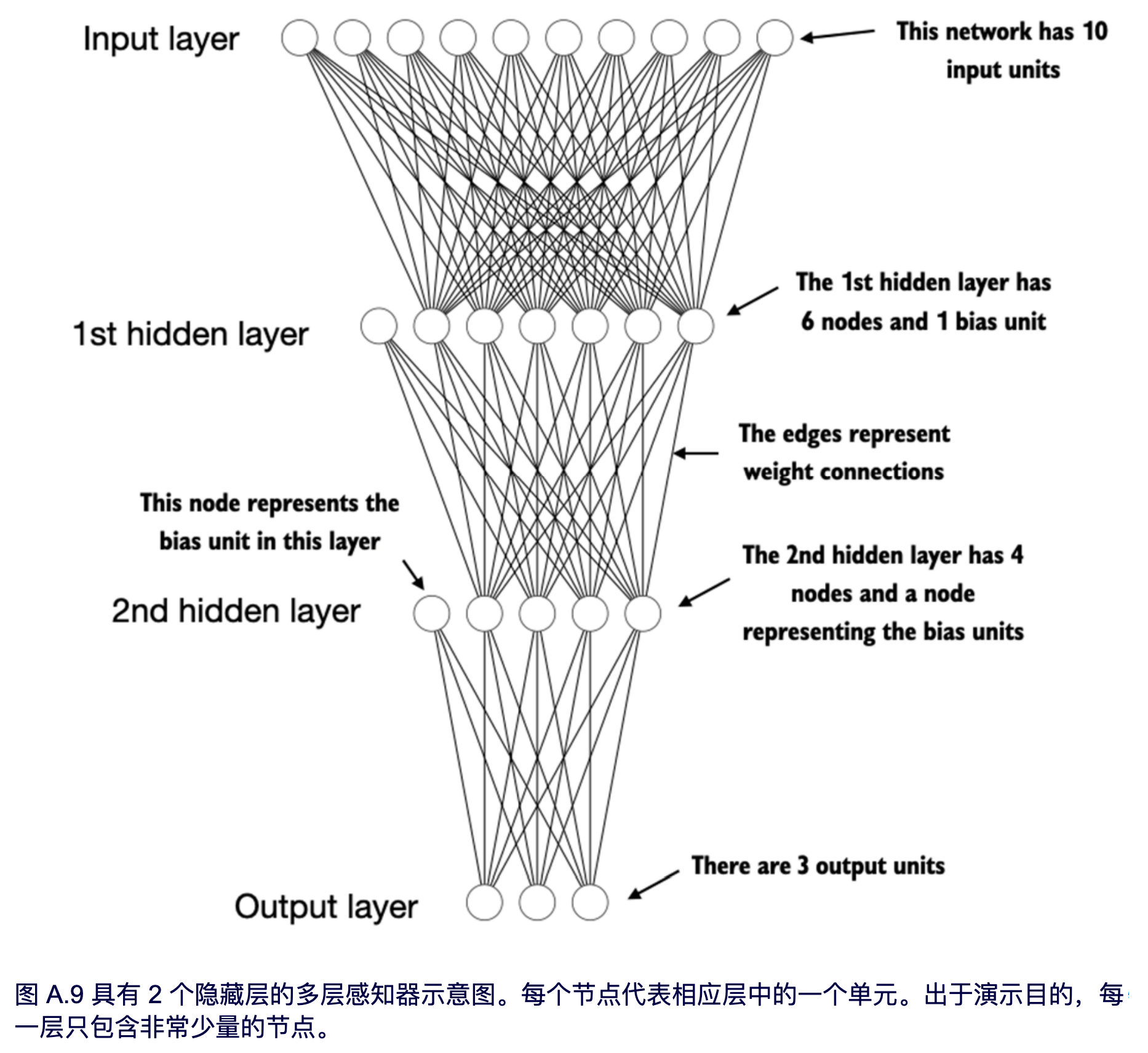
为了提供一个具体的例子,我们将重点介绍多层感知器,它是一种全连接神经网络,如图 A.9 所示。
> [!TIP]
>
> **个人思考:** 这里说了一大串,核心其实就是 PyTorch 可以自动帮我们计算“变化率”(也就是梯度),而这个“变化率”对于训练神经网络非常重要。
>
> 更详细的解释一下:
>
> + **计算图是 PyTorch 在幕后做的事情:** 当你在 PyTorch 里进行一系列的数学计算时,它会在内部偷偷地记录下这些计算步骤,就像画一张流程图一样,这张流程图就叫做“计算图”。
> + **`requires_grad=True` 是一个开关:** 你可以告诉 PyTorch,对于某些参与计算的数字(更专业地说,是“张量”),你可能想知道它们是如何影响最终结果的。如果你这样做了(通过设置 `requires_grad=True`),PyTorch 就会特别留意这些数字,并在计算图中记录下相关的操作。
> + **梯度就是“变化率”:** “梯度”这个词听起来很专业,但你可以简单地理解为“变化率”。在神经网络中,我们想知道调整某个参数(比如权重)时,模型的输出会如何变化。梯度就告诉我们这种变化的快慢和方向。
> + **训练神经网络需要梯度:** 训练神经网络的目标是让模型的预测越来越准确。为了达到这个目标,我们需要不断地调整模型的参数。而如何调整参数呢?就需要用到梯度。
> + **反向传播是一种计算梯度的方法:** “反向传播”是训练神经网络最常用的方法。它本质上就是利用计算图和微积分中的“链式法则”来高效地计算出模型中所有参数的梯度。
### 偏导数与梯度
图 A.8 展示了偏导数,它衡量的是当函数的一个变量发生变化时,函数值的变化率。梯度是一个向量,它包含了多元函数(即输入包含多个变量的函数)的所有偏导数。
如果你不熟悉或者不记得微积分中的偏导数、梯度或链式法则,别担心。从高层次上来说,本书只需要知道链式法则是一种计算损失函数关于模型参数在计算图中的梯度的方法。这提供了更新每个参数所需的信息,以使其朝着最小化损失函数的方向变化。损失函数可以作为衡量模型性能的指标,而更新参数的方法通常是梯度下降。我们将在 2.7 节“一个典型的训练循环”中重新讨论在 PyTorch 中实现这个训练循环的计算过程。
那么,这一切是如何与我们之前提到的 PyTorch 库的第二个组成部分,即自动微分 (autograd) 引擎联系起来的呢?通过跟踪对张量执行的每一个操作,PyTorch 的 autograd 引擎在后台构建一个计算图。然后,通过调用 `grad` 函数,我们可以计算损失相对于模型参数 w1 的梯度,如下所示:
```python
# Listing A.3 Computing gradients via autograd
import torch.nn.functional as F
from torch.autograd import grad
y = torch.tensor([1.0])
x1 = torch.tensor([1.1])
w1 = torch.tensor([2.2], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
z = x1 * w1 + b
a = torch.sigmoid(z)
loss = F.binary_cross_entropy(a, y)
grad_L_w1 = grad(loss, w1, retain_graph=True) #A
grad_L_b = grad(loss, b, retain_graph=True)
#A 默认情况下,PyTorch 在计算完梯度后会销毁计算图以释放内存。然而,由于我们稍后将重用这个计算图,所以我们设置了 retain_graph=True,使其保留在内存中。
```
让我们来看看根据模型参数计算出的损失值:
```python
print(grad_L_w1)
print(grad_L_b)
```
输出如下:
```python
(tensor([-0.0898]),)
(tensor([-0.0817]),)
```
在上面,我们一直在“手动”使用 `grad` 函数,这对于实验、调试和演示概念很有用。但在实践中,PyTorch 提供了更高级别的工具来自动化这个过程。例如,我们可以在损失上调用 `.backward()`,PyTorch 将计算图中所有叶节点的梯度,这些梯度将存储在张量的 `.grad` 属性中:
```python
loss.backward()
print(w1.grad)
print(b.grad)
```
输出如下:
```python
(tensor([-0.0898]),)
(tensor([-0.0817]),)
```
如果本节信息量很大,并且你可能对微积分的概念感到不知所措,请不要担心。虽然这些微积分术语是为了解释 PyTorch 的 autograd 组件,但你只需要从本节中记住,PyTorch 会通过 `.backward` 方法为我们处理微积分——在本书中,我们不需要手动计算任何导数或梯度。
## A.5 实现多层神经网络
在之前的章节中,我们介绍了 PyTorch 的张量和自动微分组件。本节重点介绍如何通过 PyTorch 实现深度神经网络。
为了提供一个具体的例子,我们将重点介绍多层感知器,它是一种全连接神经网络,如图 A.9 所示。
 在 PyTorch 中实现神经网络时,我们通常会继承 `torch.nn.Module` 类来定义我们自己的自定义网络架构。这个 `Module` 基类提供了许多功能,使得构建和训练模型更加容易。例如,它允许我们封装层和操作,并跟踪模型的参数。
在`torch.nn.Module`的子类中,我们在 `__init__` 构造函数中定义网络层,并在 `forward` 方法中指定它们如何交互。`forward` 方法描述了输入数据如何通过网络并组合成一个计算图。
相比之下,`backward` 方法(我们通常不需要自己实现)在训练期间用于计算损失函数相对于模型参数的梯度,正如我们将在 2.7 节“一个典型的训练循环”中看到的那样。
以下代码实现了一个经典的两层隐藏层的多层感知器,以说明 `Module` 类的典型用法:
```python
# Listing A.4 A multilayer perceptron with two hidden layers
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs): #A
super().__init__()
self.layers = torch.nn.Sequential(
# 1st hidden layer
torch.nn.Linear(num_inputs, 30), #B
torch.nn.ReLU(), #C
# 2nd hidden layer
torch.nn.Linear(30, 20), #D
torch.nn.ReLU(),
# output layer
torch.nn.Linear(20, num_outputs),
)
def forward(self, x):
logits = self.layers(x)
return logits #E
#A 将输入和输出的数量编码为变量很有用,这样可以为具有不同特征和类别数量的数据集重用相同的代码。
#B Linear 层将输入和输出节点的数量作为参数。
#C 非线性激活函数放置在隐藏层之间。
#D 一个隐藏层的输出节点数必须与下一个隐藏层的输入节点数相匹配。
#E 最后一层的输出被称为 logits。
```
然后,我们可以按如下方式实例化一个新的神经网络对象:
```python
model = NeuralNetwork(50, 3)
```
但在使用这个新的模型对象之前,通常需要打印模型来查看其结构的摘要:
```python
print(model)
```
输出如下:
```python
NeuralNetwork(
(layers): Sequential(
(0): Linear(in_features=50, out_features=30, bias=True)
(1): ReLU()
(2): Linear(in_features=30, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=3, bias=True)
)
)
```
请注意,在实现 `NeuralNetwork` 类时,我们使用了 `Sequential` 类。使用 `Sequential` 不是必需的,但如果我们有一系列想要按特定顺序执行的层(就像这里的情况一样),它可以使我们的工作更轻松。这样,在 `__init__` 构造函数中实例化 `self.layers = Sequential(...)` 之后,我们只需要调用 `self.layers`,而无需在 `NeuralNetwork` 的 `forward` 方法中单独调用每个层。
接下来,让我们检查一下这个模型的总的可训练参数数量:
```python
num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Total number of trainable model parameters:", num_params)
```
输出如下:
```python
Total number of trainable model parameters: 2213
```
请注意,每个 `requires_grad=True` 的参数都被认为是可训练参数,并且将在训练期间更新(更多内容请参见 2.7 节“一个典型的训练循环”)。
对于我们上面定义的具有两个隐藏层的神经网络模型,这些可训练参数包含在 `torch.nn.Linear` 层中。一个线性层将输入与权重矩阵相乘,并加上一个偏置向量。这有时也被称为前馈层或全连接层。
根据我们上面执行的 `print(model)` 调用,我们可以看到第一个 `Linear` 层位于 `layers` 属性的索引位置 0。我们可以按如下方式访问相应的权重参数矩阵:
```python
print(model.layers[0].weight)
```
输出如下:
```python
Parameter containing:
tensor([[ 0.1174, -0.1350, -0.1227, ..., 0.0275, -0.0520, -0.0192],
[-0.0169, 0.1265, 0.0255, ..., -0.1247, 0.1191, -0.0698],
[-0.0973, -0.0974, -0.0739, ..., -0.0068, -0.0892, 0.1070],
...,
[-0.0681, 0.1058, -0.0315, ..., -0.1081, -0.0290, -0.1374],
[-0.0159, 0.0587, -0.0916, ..., -0.1153, 0.0700, 0.0770],
[-0.1019, 0.1345, -0.0176, ..., 0.0114, -0.0559, -0.0088]],
requires_grad=True)
```
由于这是一个很大的矩阵,不会完整显示,让我们使用 `.shape` 属性来显示它的维度:
```python
print(model.layers[0].weight.shape)
```
结果如下:
```python
torch.Size([30, 50])
```
(同样,你可以通过 `model.layers[0].bias` 访问偏置向量。)
上面的权重矩阵是一个 30x50 的矩阵,我们可以看到 `requires_grad` 被设置为 `True`,这意味着它的条目是可训练的——这是 `torch.nn.Linear` 中权重和偏置的默认设置。
请注意,如果在你的计算机上执行上述代码,权重矩阵中的数字可能与上面显示的数字不同。这是因为模型权重是用小的随机数初始化的,每次我们实例化网络时,这些随机数都是不同的。在深度学习中,我们习惯于用小的随机数初始化模型权重,以打破训练期间的对称性——否则,在反向传播期间,节点将只执行相同的操作和更新,这将阻止网络学习从输入到输出的复杂映射。
然而,虽然我们想用随机数作为神经网络的初始权重,但有时候我们希望每次运行代码时,这些随机数都是一样的,这样方便我们做实验和调试。PyTorch 提供了一个方法来实现这个目标,我们可以通过使用 `manual_seed` 来为 PyTorch 的随机数生成器设置种子,从而使随机数初始化可复现:
```python
torch.manual_seed(123)
model = NeuralNetwork(50, 3)
print(model.layers[0].weight)
```
输出结果如下:
```python
Parameter containing:
tensor([[-0.0577, 0.0047, -0.0702, ..., 0.0222, 0.1260, 0.0865],
[ 0.0502, 0.0307, 0.0333, ..., 0.0951, 0.1134, -0.0297],
[ 0.1077, -0.1108, 0.0122, ..., 0.0108, -0.1049, -0.1063],
...,
[-0.0787, 0.1259, 0.0803, ..., 0.1218, 0.1303, -0.1351],
[ 0.1359, 0.0175, -0.0673, ..., 0.0674, 0.0676, 0.1058],
[ 0.0790, 0.1343, -0.0293, ..., 0.0344, -0.0971, -0.0509]],
requires_grad=True)
```
现在,在我们花了一些时间检查 `NeuralNetwork` 实例之后,让我们简要地看一下如何通过前向传播来使用它:
```python
torch.manual_seed(123)
X = torch.rand((1, 50))
out = model(X)
print(out)
```
这是前向传播的结果:
```python
tensor([[-0.1262, 0.1080, -0.1792]], grad_fn=)
```
在上面的代码中,我们生成了一个随机的训练样本 X 作为演示输入(请注意,我们的网络期望输入的是 50 维的特征向量),并将其输入到模型中,返回了三个分数。当我们调用 `model(x)` 时,它会自动执行模型的前向传播。
前向传播指的是从输入张量计算输出张量的过程。这包括将输入数据依次通过所有的神经网络层,从输入层开始,经过隐藏层,最终到达输出层。
以上返回的这三个数字对应于分配给每个输出节点的分数。请注意,输出张量还包含一个 `grad_fn` 值。
在这里,`grad_fn=` 代表计算图中用于计算变量的最后一个函数。具体来说,`grad_fn=` 意味着我们正在检查的张量是通过矩阵乘法和加法运算创建的。PyTorch 在反向传播期间计算梯度时会使用此信息。`grad_fn=` 的 `` 部分指定了执行的操作。在这种情况下,实际上是 `Addmm` 操作。`Addmm` 代表矩阵乘法 (`mm`) 之后进行加法 (`Add`)。
> [!TIP]
>
> **个人思考:** 这段描述需要稍微解释一下,特别是`grad_fn`,你可以把 `grad_fn` 想象成一个“标签”,它告诉我们这个数字(或者更专业地说,这个“张量”)是怎么来的。
>
> + **“怎么来的”很重要:** 在神经网络中,我们通过一系列的计算得到最终的输出。为了训练网络,我们需要知道如果我们稍微调整一下某个参数(比如权重),最终的输出会怎么变化。这就需要用到“梯度”。
> + **`grad_fn` 就是记录“怎么来的”的线索:** PyTorch 会记住每一步的计算过程。对于每一个产生的数字(张量),它都会记录下最后一步是用什么方法计算出来的。这个记录就是 `grad_fn`。
> + **`grad_fn=` (或者更正后的 `grad_fn=`) 的意思:** 这个特定的标签 `` 告诉我们,这个输出张量是通过一个叫做 `Addmm` 的操作得到的。你可以把 `Addmm` 简单理解为“先做矩阵乘法,再做加法”。这在神经网络的计算中是很常见的操作。
> + **PyTorch 用这个标签来做什么?** PyTorch 知道了每个数字是怎么算出来的,就能反过来计算“梯度”了。当我们想要训练神经网络时,PyTorch 会利用这些记录(也就是 `grad_fn`),使用一种叫做“反向传播”的方法,自动计算出我们需要调整哪些参数,以及应该朝哪个方向调整,才能让模型的预测更准确。
如果我们只是想使用一个网络而不进行训练或反向传播,例如,在训练后将其用于预测,构建用于反向传播的计算图可能会造成浪费,因为它会执行不必要的计算并消耗额外的内存。因此,当我们将模型用于推理(例如,进行预测)而不是训练时,最佳实践是使用 `torch.no_grad()` 上下文管理器,如下所示。这告诉 PyTorch 它不需要跟踪梯度,从而可以显著节省内存和计算资源。
```python
with torch.no_grad():
out = model(X)
print(out)
```
输出结果如下:
```python
tensor([[-0.1262, 0.1080, -0.1792]])
```
在 PyTorch 中,一种常见的做法是将模型编码成返回最后一层(logits)的输出,而不会将它们传递给非线性激活函数。这是因为
PyTorch 常用的损失函数将 softmax(或二元分类的sigmoid)运算与负对数似然损失组合在一个类中。这样做的原因是
出于数值效率和稳定性的考虑。因此,如果我们想计算预测的类别成员概率,则必须显式调用softmax函数:
```python
with torch.no_grad():
out = torch.softmax(model(X), dim=1)
print(out)
```
输出如下:
```python
tensor([[0.3113, 0.3934, 0.2952]])
```
现在这些值可以解释为总和为1的类别成员概率。对于这个随机输入,这些值大致相等,这对于一个未经训练的、随机初始化的模型来说是预期的。
在接下来的两节中,我们将学习如何设置一个高效的数据加载器并训练模型。
## A.6 设置高效的数据加载器
在上一节中,我们自定义了一个神经网络模型。在训练这个模型之前,我们需要简要地讨论一下如何在 PyTorch 中创建高效的数据加载器,以便在训练模型的过程中使用。PyTorch 中数据加载的总体思路如图 A.10 所示。
在 PyTorch 中实现神经网络时,我们通常会继承 `torch.nn.Module` 类来定义我们自己的自定义网络架构。这个 `Module` 基类提供了许多功能,使得构建和训练模型更加容易。例如,它允许我们封装层和操作,并跟踪模型的参数。
在`torch.nn.Module`的子类中,我们在 `__init__` 构造函数中定义网络层,并在 `forward` 方法中指定它们如何交互。`forward` 方法描述了输入数据如何通过网络并组合成一个计算图。
相比之下,`backward` 方法(我们通常不需要自己实现)在训练期间用于计算损失函数相对于模型参数的梯度,正如我们将在 2.7 节“一个典型的训练循环”中看到的那样。
以下代码实现了一个经典的两层隐藏层的多层感知器,以说明 `Module` 类的典型用法:
```python
# Listing A.4 A multilayer perceptron with two hidden layers
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs): #A
super().__init__()
self.layers = torch.nn.Sequential(
# 1st hidden layer
torch.nn.Linear(num_inputs, 30), #B
torch.nn.ReLU(), #C
# 2nd hidden layer
torch.nn.Linear(30, 20), #D
torch.nn.ReLU(),
# output layer
torch.nn.Linear(20, num_outputs),
)
def forward(self, x):
logits = self.layers(x)
return logits #E
#A 将输入和输出的数量编码为变量很有用,这样可以为具有不同特征和类别数量的数据集重用相同的代码。
#B Linear 层将输入和输出节点的数量作为参数。
#C 非线性激活函数放置在隐藏层之间。
#D 一个隐藏层的输出节点数必须与下一个隐藏层的输入节点数相匹配。
#E 最后一层的输出被称为 logits。
```
然后,我们可以按如下方式实例化一个新的神经网络对象:
```python
model = NeuralNetwork(50, 3)
```
但在使用这个新的模型对象之前,通常需要打印模型来查看其结构的摘要:
```python
print(model)
```
输出如下:
```python
NeuralNetwork(
(layers): Sequential(
(0): Linear(in_features=50, out_features=30, bias=True)
(1): ReLU()
(2): Linear(in_features=30, out_features=20, bias=True)
(3): ReLU()
(4): Linear(in_features=20, out_features=3, bias=True)
)
)
```
请注意,在实现 `NeuralNetwork` 类时,我们使用了 `Sequential` 类。使用 `Sequential` 不是必需的,但如果我们有一系列想要按特定顺序执行的层(就像这里的情况一样),它可以使我们的工作更轻松。这样,在 `__init__` 构造函数中实例化 `self.layers = Sequential(...)` 之后,我们只需要调用 `self.layers`,而无需在 `NeuralNetwork` 的 `forward` 方法中单独调用每个层。
接下来,让我们检查一下这个模型的总的可训练参数数量:
```python
num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Total number of trainable model parameters:", num_params)
```
输出如下:
```python
Total number of trainable model parameters: 2213
```
请注意,每个 `requires_grad=True` 的参数都被认为是可训练参数,并且将在训练期间更新(更多内容请参见 2.7 节“一个典型的训练循环”)。
对于我们上面定义的具有两个隐藏层的神经网络模型,这些可训练参数包含在 `torch.nn.Linear` 层中。一个线性层将输入与权重矩阵相乘,并加上一个偏置向量。这有时也被称为前馈层或全连接层。
根据我们上面执行的 `print(model)` 调用,我们可以看到第一个 `Linear` 层位于 `layers` 属性的索引位置 0。我们可以按如下方式访问相应的权重参数矩阵:
```python
print(model.layers[0].weight)
```
输出如下:
```python
Parameter containing:
tensor([[ 0.1174, -0.1350, -0.1227, ..., 0.0275, -0.0520, -0.0192],
[-0.0169, 0.1265, 0.0255, ..., -0.1247, 0.1191, -0.0698],
[-0.0973, -0.0974, -0.0739, ..., -0.0068, -0.0892, 0.1070],
...,
[-0.0681, 0.1058, -0.0315, ..., -0.1081, -0.0290, -0.1374],
[-0.0159, 0.0587, -0.0916, ..., -0.1153, 0.0700, 0.0770],
[-0.1019, 0.1345, -0.0176, ..., 0.0114, -0.0559, -0.0088]],
requires_grad=True)
```
由于这是一个很大的矩阵,不会完整显示,让我们使用 `.shape` 属性来显示它的维度:
```python
print(model.layers[0].weight.shape)
```
结果如下:
```python
torch.Size([30, 50])
```
(同样,你可以通过 `model.layers[0].bias` 访问偏置向量。)
上面的权重矩阵是一个 30x50 的矩阵,我们可以看到 `requires_grad` 被设置为 `True`,这意味着它的条目是可训练的——这是 `torch.nn.Linear` 中权重和偏置的默认设置。
请注意,如果在你的计算机上执行上述代码,权重矩阵中的数字可能与上面显示的数字不同。这是因为模型权重是用小的随机数初始化的,每次我们实例化网络时,这些随机数都是不同的。在深度学习中,我们习惯于用小的随机数初始化模型权重,以打破训练期间的对称性——否则,在反向传播期间,节点将只执行相同的操作和更新,这将阻止网络学习从输入到输出的复杂映射。
然而,虽然我们想用随机数作为神经网络的初始权重,但有时候我们希望每次运行代码时,这些随机数都是一样的,这样方便我们做实验和调试。PyTorch 提供了一个方法来实现这个目标,我们可以通过使用 `manual_seed` 来为 PyTorch 的随机数生成器设置种子,从而使随机数初始化可复现:
```python
torch.manual_seed(123)
model = NeuralNetwork(50, 3)
print(model.layers[0].weight)
```
输出结果如下:
```python
Parameter containing:
tensor([[-0.0577, 0.0047, -0.0702, ..., 0.0222, 0.1260, 0.0865],
[ 0.0502, 0.0307, 0.0333, ..., 0.0951, 0.1134, -0.0297],
[ 0.1077, -0.1108, 0.0122, ..., 0.0108, -0.1049, -0.1063],
...,
[-0.0787, 0.1259, 0.0803, ..., 0.1218, 0.1303, -0.1351],
[ 0.1359, 0.0175, -0.0673, ..., 0.0674, 0.0676, 0.1058],
[ 0.0790, 0.1343, -0.0293, ..., 0.0344, -0.0971, -0.0509]],
requires_grad=True)
```
现在,在我们花了一些时间检查 `NeuralNetwork` 实例之后,让我们简要地看一下如何通过前向传播来使用它:
```python
torch.manual_seed(123)
X = torch.rand((1, 50))
out = model(X)
print(out)
```
这是前向传播的结果:
```python
tensor([[-0.1262, 0.1080, -0.1792]], grad_fn=)
```
在上面的代码中,我们生成了一个随机的训练样本 X 作为演示输入(请注意,我们的网络期望输入的是 50 维的特征向量),并将其输入到模型中,返回了三个分数。当我们调用 `model(x)` 时,它会自动执行模型的前向传播。
前向传播指的是从输入张量计算输出张量的过程。这包括将输入数据依次通过所有的神经网络层,从输入层开始,经过隐藏层,最终到达输出层。
以上返回的这三个数字对应于分配给每个输出节点的分数。请注意,输出张量还包含一个 `grad_fn` 值。
在这里,`grad_fn=` 代表计算图中用于计算变量的最后一个函数。具体来说,`grad_fn=` 意味着我们正在检查的张量是通过矩阵乘法和加法运算创建的。PyTorch 在反向传播期间计算梯度时会使用此信息。`grad_fn=` 的 `` 部分指定了执行的操作。在这种情况下,实际上是 `Addmm` 操作。`Addmm` 代表矩阵乘法 (`mm`) 之后进行加法 (`Add`)。
> [!TIP]
>
> **个人思考:** 这段描述需要稍微解释一下,特别是`grad_fn`,你可以把 `grad_fn` 想象成一个“标签”,它告诉我们这个数字(或者更专业地说,这个“张量”)是怎么来的。
>
> + **“怎么来的”很重要:** 在神经网络中,我们通过一系列的计算得到最终的输出。为了训练网络,我们需要知道如果我们稍微调整一下某个参数(比如权重),最终的输出会怎么变化。这就需要用到“梯度”。
> + **`grad_fn` 就是记录“怎么来的”的线索:** PyTorch 会记住每一步的计算过程。对于每一个产生的数字(张量),它都会记录下最后一步是用什么方法计算出来的。这个记录就是 `grad_fn`。
> + **`grad_fn=` (或者更正后的 `grad_fn=`) 的意思:** 这个特定的标签 `` 告诉我们,这个输出张量是通过一个叫做 `Addmm` 的操作得到的。你可以把 `Addmm` 简单理解为“先做矩阵乘法,再做加法”。这在神经网络的计算中是很常见的操作。
> + **PyTorch 用这个标签来做什么?** PyTorch 知道了每个数字是怎么算出来的,就能反过来计算“梯度”了。当我们想要训练神经网络时,PyTorch 会利用这些记录(也就是 `grad_fn`),使用一种叫做“反向传播”的方法,自动计算出我们需要调整哪些参数,以及应该朝哪个方向调整,才能让模型的预测更准确。
如果我们只是想使用一个网络而不进行训练或反向传播,例如,在训练后将其用于预测,构建用于反向传播的计算图可能会造成浪费,因为它会执行不必要的计算并消耗额外的内存。因此,当我们将模型用于推理(例如,进行预测)而不是训练时,最佳实践是使用 `torch.no_grad()` 上下文管理器,如下所示。这告诉 PyTorch 它不需要跟踪梯度,从而可以显著节省内存和计算资源。
```python
with torch.no_grad():
out = model(X)
print(out)
```
输出结果如下:
```python
tensor([[-0.1262, 0.1080, -0.1792]])
```
在 PyTorch 中,一种常见的做法是将模型编码成返回最后一层(logits)的输出,而不会将它们传递给非线性激活函数。这是因为
PyTorch 常用的损失函数将 softmax(或二元分类的sigmoid)运算与负对数似然损失组合在一个类中。这样做的原因是
出于数值效率和稳定性的考虑。因此,如果我们想计算预测的类别成员概率,则必须显式调用softmax函数:
```python
with torch.no_grad():
out = torch.softmax(model(X), dim=1)
print(out)
```
输出如下:
```python
tensor([[0.3113, 0.3934, 0.2952]])
```
现在这些值可以解释为总和为1的类别成员概率。对于这个随机输入,这些值大致相等,这对于一个未经训练的、随机初始化的模型来说是预期的。
在接下来的两节中,我们将学习如何设置一个高效的数据加载器并训练模型。
## A.6 设置高效的数据加载器
在上一节中,我们自定义了一个神经网络模型。在训练这个模型之前,我们需要简要地讨论一下如何在 PyTorch 中创建高效的数据加载器,以便在训练模型的过程中使用。PyTorch 中数据加载的总体思路如图 A.10 所示。
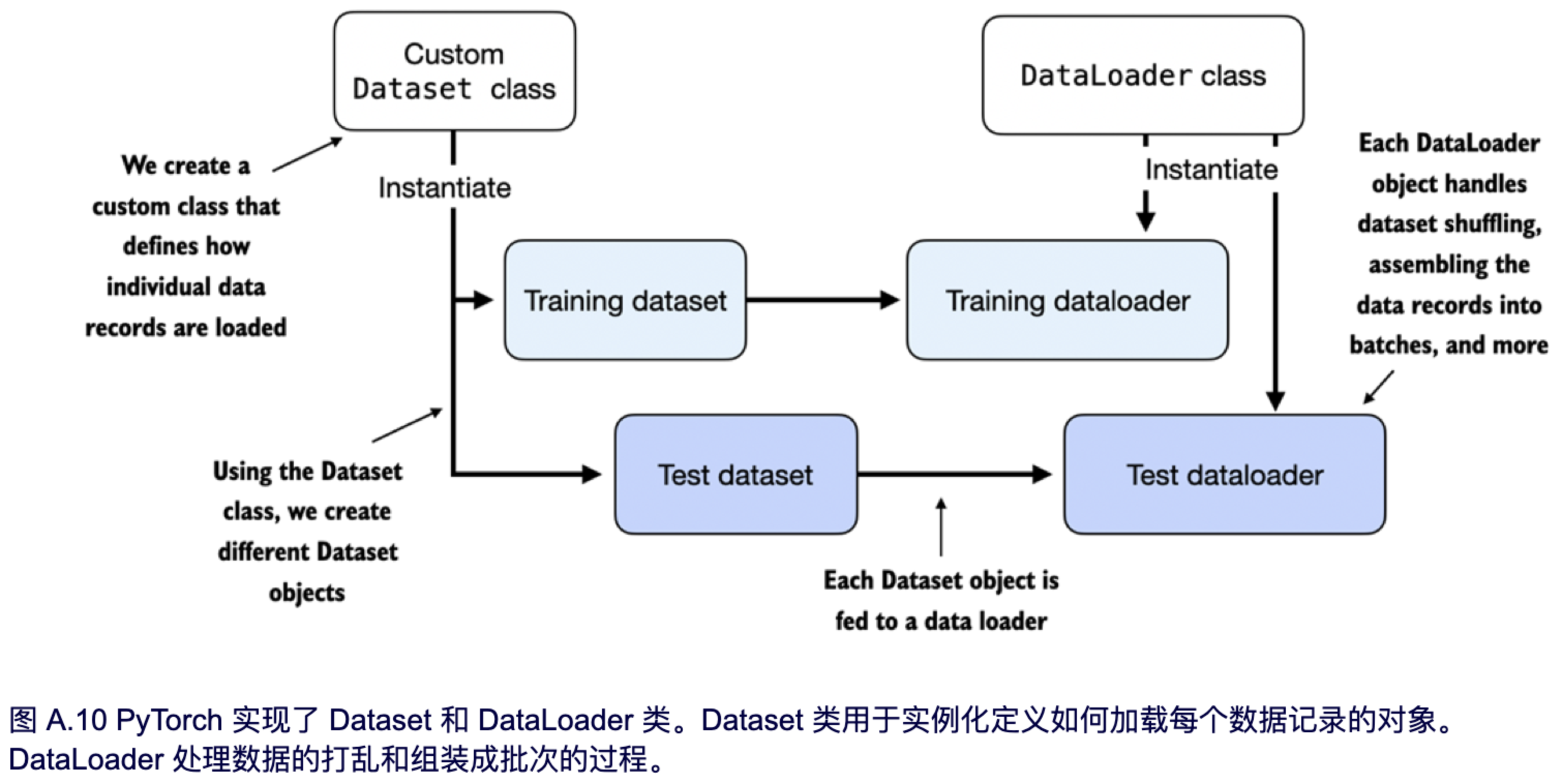 根据图 A.10 中的说明,在本节中,我们将实现一个自定义的 `Dataset` 类,接着使用它来创建训练数据集和测试数据集,最后用这些数据集来创建数据加载器。
让我们首先创建一个简单的玩具数据集,其中包含五个训练样本,每个样本有两个特征。伴随这些训练样本,我们还创建了一个包含相应类别标签的张量:其中三个样本属于类别 0,另外两个样本属于类别 1。此外,我们还创建了一个包含两个条目的测试集。创建此数据集的代码如下所示。
```python
# Listing A.5 Creating a small toy dataset
X_train = torch.tensor([
[-1.2, 3.1],
[-0.9, 2.9],
[-0.5, 2.6],
[2.3, -1.1],
[2.7, -1.5]
])
y_train = torch.tensor([0, 0, 0, 1, 1])
X_test = torch.tensor([
[-0.8, 2.8],
[2.6, -1.6],
])
y_test = torch.tensor([0, 1])
```
**类别标签编号** PyTorch 要求类别标签从 0 开始编号,并且最大的类别标签值不应超过输出节点数减 1(因为 Python 的索引计数从 0 开始)。因此,如果我们有类别标签 0、1、2、3 和 4,那么神经网络的输出层应该包含 5 个节点。
接下来,我们通过继承 PyTorch 的 `Dataset` 父类来创建一个自定义的数据集类 `ToyDataset`,如下所示。
```python
# Listing A.6 Defining a custom Dataset class
from torch.utils.data import Dataset
class ToyDataset(Dataset):
def __init__(self, X, y):
self.features = X
self.labels = y
def __getitem__(self, index): #A
one_x = self.features[index] #A
one_y = self.labels[index] #A
return one_x, one_y #A
def __len__(self):
return self.labels.shape[0] #B
train_ds = ToyDataset(X_train, y_train)
test_ds = ToyDataset(X_test, y_test)
#A 用于检索单个数据记录及其对应标签的指令
#B 用于返回数据集总长度的指令
```
这个自定义的 `ToyDataset` 类的目的是用它来实例化一个 PyTorch `DataLoader`。但在我们进行这一步之前,让我们先简要地了解一下 `ToyDataset` 代码的总体结构。
在 PyTorch 中,自定义 `Dataset` 类的三个主要组成部分是 `__init__` 构造函数、`__getitem__` 方法和 `__len__` 方法,如上面的代码清单 A.6 所示。
在 `__init__` 方法中,我们设置了稍后可在 `__getitem__` 和 `__len__` 方法中访问的属性。这可以是文件路径、文件对象、数据库连接等等。由于我们创建的是一个存储在内存中的张量数据集,我们只是简单地将 X 和 y 赋值给这些属性,它们是我们的张量对象的占位符。
`__getitem__` 方法就是让你能够通过一个简单的数字(索引),从你的数据集中获取到你想要的单个数据样本(包括描述它的特征和它所属的类别)。这就像你在图书馆里,通过书的编号找到你想借阅的那本书一样。
最后,`__len__` 方法可以获取数据集长度。在这里,我们使用张量的 `.shape` 属性来返回特征数组的行数。对于训练数据集,我们有五行,我们可以通过以下方式进行双重检查:
```python
print(len(train_ds))
```
结果如下:
```python
5
```
现在我们已经为我们的数据集定义了一个 PyTorch `Dataset` 类,接着可以使用 PyTorch 的 `DataLoader` 类来从中采样数据,如下面的代码清单所示:
```python
# Listing A.7 Instantiating data loaders
from torch.utils.data import DataLoader
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_ds, #A
batch_size=2,
shuffle=True, #B
num_workers=0 #C
)
test_loader = DataLoader(
dataset=test_ds,
batch_size=2,
shuffle=False, #D
num_workers=0
)
#A 之前创建的 ToyDataset 实例作为数据加载器的输入。
#B 是否打乱数据
#C 后台进程的数量
#D 没有必要打乱测试数据
```
在实例化训练数据加载器之后,我们可以像下面所示的那样对其进行迭代。(对 `test_loader` 的迭代方式类似,但为了简洁起见,这里省略了。)
```python
for idx, (x, y) in enumerate(train_loader):
print(f"Batch {idx+1}:", x, y)
```
结果如下:
```python
Batch 1: tensor([[-1.2000, 3.1000],
[-0.5000, 2.6000]]) tensor([0, 0])
Batch 2: tensor([[ 2.3000, -1.1000],
[-0.9000, 2.9000]]) tensor([1, 0])
Batch 3: tensor([[ 2.7000, -1.5000]]) tensor([1])
```
如上面输出所示,`train_loader` 遍历训练数据集,每个训练样本仅访问一次,这被称为一个训练轮次(epoch)。由于我们在上面使用了 `torch.manual_seed(123)` 设置了随机数生成器的种子,你应该会得到与上面所示完全相同的训练样本打乱顺序(`训练集的shuffle设置为True,所以样本顺序会被打乱`)。然而,如果你第二次迭代数据集,你会发现打乱顺序会发生变化。这是为了防止深度神经网络在训练期间陷入重复的更新循环。
> [!TIP]
>
> **个人思考:** 这里为什么需要强调训练数据集需要打乱顺序。想象一下,如果你每次都按照完全相同的顺序给神经网络看数据,它可能会记住这个顺序,而不是真正学会数据里面的规律。就像你背课文一样,如果每次都从第一句开始背,你可能只是记住了句子的先后顺序,而不是真正理解了内容。
>
> 所以,为了让神经网络更好地学习,我们希望每次给它看数据的时候,数据的顺序都是随机的、不一样的。这样,神经网络就不能依赖数据的顺序来做判断,而是必须真正理解每个数据样本的特征,才能做出正确的预测。
>
> 简单来说,设置了随机数生成器的种子后,第一次的固定顺序是为了方便我们对比和调试,而之后每次都变化的随机顺序是为了让神经网络学得更好,更不容易“死记硬背”。
请注意,我们在上面指定了批大小为 2,但第三个批次只包含一个样本。这是因为我们有五个训练样本,而 5 不能被 2 整除。在实践中,在每个训练轮次的最后一个批次中包含一个明显较小的批次可能会扰乱训练过程中的收敛。为了防止这种情况,建议设置 `drop_last=True`,这将丢弃每个训练轮次的最后一个批次,如下所示:
```python
# Listing A.8 A training loader that drops the last batch
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=True,
num_workers=0,
drop_last=True
)
```
现在,再次迭代训练加载器,我们可以看到最后一个批次被省略了:
```python
for idx, (x, y) in enumerate(train_loader):
print(f"Batch {idx+1}:", x, y)
```
结果如下:
```python
Batch 1: tensor([[-0.9000, 2.9000],
[ 2.3000, -1.1000]]) tensor([0, 1])
Batch 2: tensor([[ 2.7000, -1.5000],
[-0.5000, 2.6000]]) tensor([1, 0])
```
最后,让我们讨论一下 `DataLoader` 中的 `num_workers=0` 这个设置。PyTorch `DataLoader` 函数中的这个参数对于并行化数据加载和预处理至关重要。当 `num_workers` 设置为 0 时,数据加载将在主进程中完成,而不是在单独的工作进程中。这看起来可能没什么问题,但当我们使用 GPU 训练更大的网络时,可能会导致模型训练速度显著下降。这是因为 CPU 除了专注于深度学习模型的处理外,还必须花费时间来加载和预处理数据。结果,GPU 可能会在等待 CPU 完成这些任务时处于空闲状态。相反,当 `num_workers` 设置为大于零的数字时,会启动多个工作进程来并行加载数据,从而使主进程可以专注于训练你的模型并更好地利用系统的资源,如图 A.11 所示。
根据图 A.10 中的说明,在本节中,我们将实现一个自定义的 `Dataset` 类,接着使用它来创建训练数据集和测试数据集,最后用这些数据集来创建数据加载器。
让我们首先创建一个简单的玩具数据集,其中包含五个训练样本,每个样本有两个特征。伴随这些训练样本,我们还创建了一个包含相应类别标签的张量:其中三个样本属于类别 0,另外两个样本属于类别 1。此外,我们还创建了一个包含两个条目的测试集。创建此数据集的代码如下所示。
```python
# Listing A.5 Creating a small toy dataset
X_train = torch.tensor([
[-1.2, 3.1],
[-0.9, 2.9],
[-0.5, 2.6],
[2.3, -1.1],
[2.7, -1.5]
])
y_train = torch.tensor([0, 0, 0, 1, 1])
X_test = torch.tensor([
[-0.8, 2.8],
[2.6, -1.6],
])
y_test = torch.tensor([0, 1])
```
**类别标签编号** PyTorch 要求类别标签从 0 开始编号,并且最大的类别标签值不应超过输出节点数减 1(因为 Python 的索引计数从 0 开始)。因此,如果我们有类别标签 0、1、2、3 和 4,那么神经网络的输出层应该包含 5 个节点。
接下来,我们通过继承 PyTorch 的 `Dataset` 父类来创建一个自定义的数据集类 `ToyDataset`,如下所示。
```python
# Listing A.6 Defining a custom Dataset class
from torch.utils.data import Dataset
class ToyDataset(Dataset):
def __init__(self, X, y):
self.features = X
self.labels = y
def __getitem__(self, index): #A
one_x = self.features[index] #A
one_y = self.labels[index] #A
return one_x, one_y #A
def __len__(self):
return self.labels.shape[0] #B
train_ds = ToyDataset(X_train, y_train)
test_ds = ToyDataset(X_test, y_test)
#A 用于检索单个数据记录及其对应标签的指令
#B 用于返回数据集总长度的指令
```
这个自定义的 `ToyDataset` 类的目的是用它来实例化一个 PyTorch `DataLoader`。但在我们进行这一步之前,让我们先简要地了解一下 `ToyDataset` 代码的总体结构。
在 PyTorch 中,自定义 `Dataset` 类的三个主要组成部分是 `__init__` 构造函数、`__getitem__` 方法和 `__len__` 方法,如上面的代码清单 A.6 所示。
在 `__init__` 方法中,我们设置了稍后可在 `__getitem__` 和 `__len__` 方法中访问的属性。这可以是文件路径、文件对象、数据库连接等等。由于我们创建的是一个存储在内存中的张量数据集,我们只是简单地将 X 和 y 赋值给这些属性,它们是我们的张量对象的占位符。
`__getitem__` 方法就是让你能够通过一个简单的数字(索引),从你的数据集中获取到你想要的单个数据样本(包括描述它的特征和它所属的类别)。这就像你在图书馆里,通过书的编号找到你想借阅的那本书一样。
最后,`__len__` 方法可以获取数据集长度。在这里,我们使用张量的 `.shape` 属性来返回特征数组的行数。对于训练数据集,我们有五行,我们可以通过以下方式进行双重检查:
```python
print(len(train_ds))
```
结果如下:
```python
5
```
现在我们已经为我们的数据集定义了一个 PyTorch `Dataset` 类,接着可以使用 PyTorch 的 `DataLoader` 类来从中采样数据,如下面的代码清单所示:
```python
# Listing A.7 Instantiating data loaders
from torch.utils.data import DataLoader
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_ds, #A
batch_size=2,
shuffle=True, #B
num_workers=0 #C
)
test_loader = DataLoader(
dataset=test_ds,
batch_size=2,
shuffle=False, #D
num_workers=0
)
#A 之前创建的 ToyDataset 实例作为数据加载器的输入。
#B 是否打乱数据
#C 后台进程的数量
#D 没有必要打乱测试数据
```
在实例化训练数据加载器之后,我们可以像下面所示的那样对其进行迭代。(对 `test_loader` 的迭代方式类似,但为了简洁起见,这里省略了。)
```python
for idx, (x, y) in enumerate(train_loader):
print(f"Batch {idx+1}:", x, y)
```
结果如下:
```python
Batch 1: tensor([[-1.2000, 3.1000],
[-0.5000, 2.6000]]) tensor([0, 0])
Batch 2: tensor([[ 2.3000, -1.1000],
[-0.9000, 2.9000]]) tensor([1, 0])
Batch 3: tensor([[ 2.7000, -1.5000]]) tensor([1])
```
如上面输出所示,`train_loader` 遍历训练数据集,每个训练样本仅访问一次,这被称为一个训练轮次(epoch)。由于我们在上面使用了 `torch.manual_seed(123)` 设置了随机数生成器的种子,你应该会得到与上面所示完全相同的训练样本打乱顺序(`训练集的shuffle设置为True,所以样本顺序会被打乱`)。然而,如果你第二次迭代数据集,你会发现打乱顺序会发生变化。这是为了防止深度神经网络在训练期间陷入重复的更新循环。
> [!TIP]
>
> **个人思考:** 这里为什么需要强调训练数据集需要打乱顺序。想象一下,如果你每次都按照完全相同的顺序给神经网络看数据,它可能会记住这个顺序,而不是真正学会数据里面的规律。就像你背课文一样,如果每次都从第一句开始背,你可能只是记住了句子的先后顺序,而不是真正理解了内容。
>
> 所以,为了让神经网络更好地学习,我们希望每次给它看数据的时候,数据的顺序都是随机的、不一样的。这样,神经网络就不能依赖数据的顺序来做判断,而是必须真正理解每个数据样本的特征,才能做出正确的预测。
>
> 简单来说,设置了随机数生成器的种子后,第一次的固定顺序是为了方便我们对比和调试,而之后每次都变化的随机顺序是为了让神经网络学得更好,更不容易“死记硬背”。
请注意,我们在上面指定了批大小为 2,但第三个批次只包含一个样本。这是因为我们有五个训练样本,而 5 不能被 2 整除。在实践中,在每个训练轮次的最后一个批次中包含一个明显较小的批次可能会扰乱训练过程中的收敛。为了防止这种情况,建议设置 `drop_last=True`,这将丢弃每个训练轮次的最后一个批次,如下所示:
```python
# Listing A.8 A training loader that drops the last batch
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=True,
num_workers=0,
drop_last=True
)
```
现在,再次迭代训练加载器,我们可以看到最后一个批次被省略了:
```python
for idx, (x, y) in enumerate(train_loader):
print(f"Batch {idx+1}:", x, y)
```
结果如下:
```python
Batch 1: tensor([[-0.9000, 2.9000],
[ 2.3000, -1.1000]]) tensor([0, 1])
Batch 2: tensor([[ 2.7000, -1.5000],
[-0.5000, 2.6000]]) tensor([1, 0])
```
最后,让我们讨论一下 `DataLoader` 中的 `num_workers=0` 这个设置。PyTorch `DataLoader` 函数中的这个参数对于并行化数据加载和预处理至关重要。当 `num_workers` 设置为 0 时,数据加载将在主进程中完成,而不是在单独的工作进程中。这看起来可能没什么问题,但当我们使用 GPU 训练更大的网络时,可能会导致模型训练速度显著下降。这是因为 CPU 除了专注于深度学习模型的处理外,还必须花费时间来加载和预处理数据。结果,GPU 可能会在等待 CPU 完成这些任务时处于空闲状态。相反,当 `num_workers` 设置为大于零的数字时,会启动多个工作进程来并行加载数据,从而使主进程可以专注于训练你的模型并更好地利用系统的资源,如图 A.11 所示。
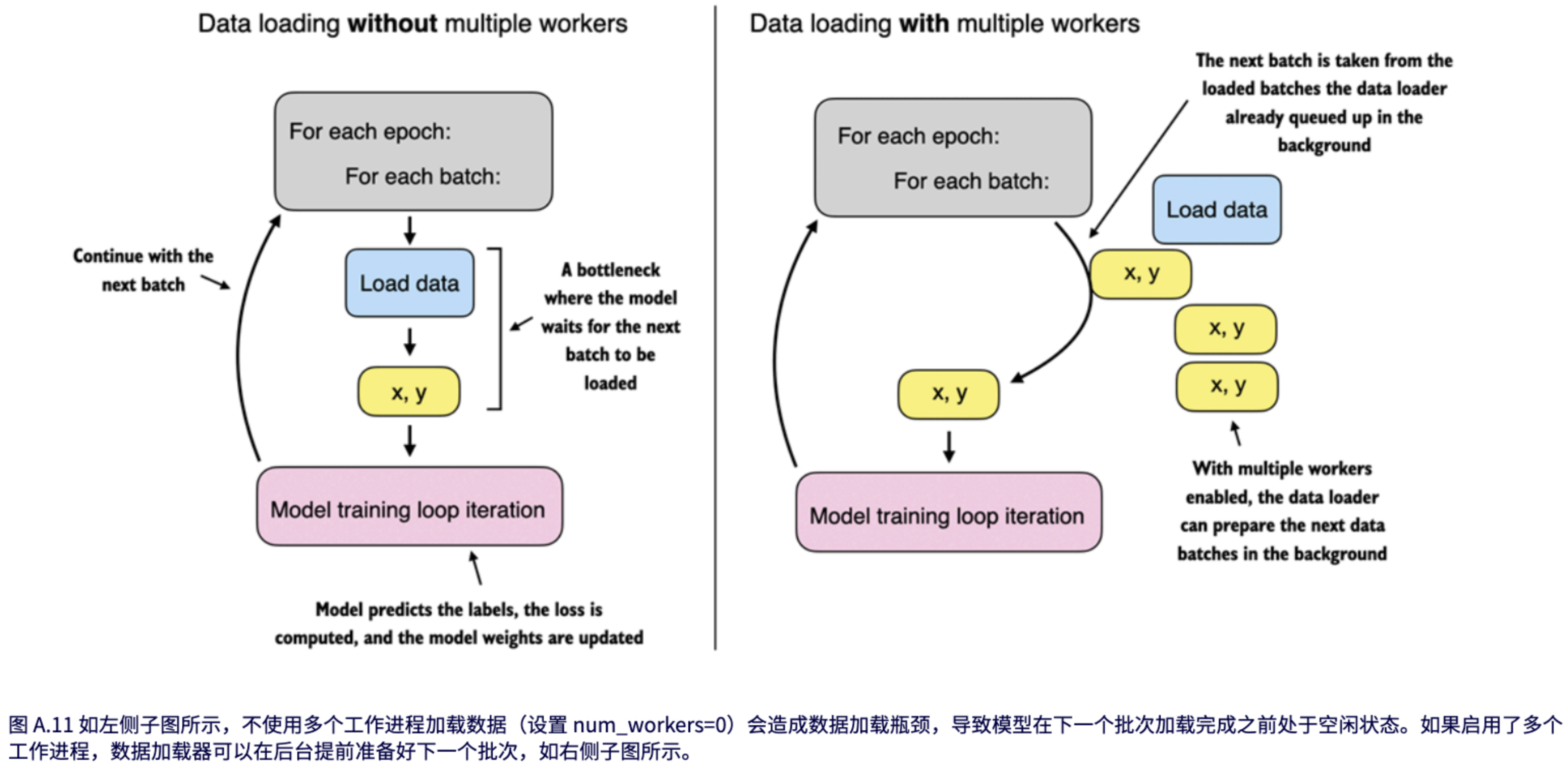 然而,如果我们处理的是非常小的数据集,那么将 `num_workers` 设置为 1 或更大的值可能没有必要,因为总的训练时间可能只需要几分之一秒。相反,如果你处理的是非常小的数据集或者像 Jupyter 笔记本这样的交互式环境,增加 `num_workers` 可能不会带来任何明显的加速。事实上,它们甚至可能导致一些问题。一个潜在的问题是启动多个工作进程的开销,当你的数据集很小时,这个开销可能比实际的数据加载时间还要长。
此外,对于 Jupyter 笔记本,将 `num_workers` 设置为大于 0 的值有时会导致不同进程之间资源共享的问题,从而引发错误或笔记本崩溃。因此,理解这种权衡并在设置 `num_workers` 参数时做出明智的决定至关重要。如果使用得当,它可以是一个有益的工具,但应该根据你的具体数据集大小和计算环境进行调整,以获得最佳结果。
根据我的经验,对于许多真实世界的数据集,将 `num_workers` 设置为 4 通常可以获得最佳性能,但最佳设置取决于你的硬件以及在 `Dataset` 类中定义的用于加载训练样本的代码。
## 4.7 一个典型的训练循环
到目前为止,我们已经讨论了训练神经网络的所有必要条件:PyTorch 的张量库、自动梯度(autograd)、模块 API(Module API)和高效的数据加载器。现在,让我们将所有这些要素结合起来,并在上一节创建的玩具数据集上训练一个神经网络。训练代码如下面的代码清单 A.9 所示。
```python
# Listing A.9 Neural network training in PyTorch
import torch.nn.functional as F
torch.manual_seed(123)
model = NeuralNetwork(num_inputs=2, num_outputs=2) #A
optimizer = torch.optim.SGD(model.parameters(), lr=0.5) #B
num_epochs = 3
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, labels) in enumerate(train_loader):
logits = model(features)
loss = F.cross_entropy(logits, labels)
optimizer.zero_grad() #C
loss.backward() #D
optimizer.step() #E
### LOGGING
print(f"Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batch {batch_idx:03d}/{len(train_loader):03d}"
f" | Train Loss: {loss:.2f}")
model.eval()
# Optional model evaluation
#A 上一节的数据集包含 2 个特征和 2 个类别
#B 我们让优化器知道需要优化哪些参数
#C 将上一轮的梯度设置为零,以防止意外的梯度累积
#D 计算损失函数相对于模型参数的梯度
#E 优化器使用梯度来更新模型参数
```
运行上面清单 A.9 中的代码会产生以下输出:
```python
Epoch: 001/003 | Batch 000/002 | Train Loss: 0.75
Epoch: 001/003 | Batch 001/002 | Train Loss: 0.65
Epoch: 002/003 | Batch 000/002 | Train Loss: 0.44
Epoch: 002/003 | Batch 001/002 | Trainl Loss: 0.13
Epoch: 003/003 | Batch 000/002 | Train Loss: 0.03
Epoch: 003/003 | Batch 001/002 | Train Loss: 0.00
```
正如我们所见,训练损失值在 3 个轮次后降至零,这表明模型在训练集上收敛了。然而,在我们评估模型的预测之前,让我们先回顾一下前面代码清单中的一些细节。
首先,请注意我们初始化了一个具有两个输入和两个输出的模型。这是因为上一节的玩具数据集包含两个输入特征和两个需要预测的类别标签。我们使用了随机梯度下降(SGD)优化器,学习率(lr)设置为 0.5。学习率是一个超参数,这意味着它是一个可调整的设置,我们需要通过观察损失来实验确定。理想情况下,我们希望选择一个学习率,使得损失在一定数量的轮次后收敛——轮次的数量是另一个需要选择的超参数。
> [!NOTE]
>
> **练习 A.3**
>
> 在本节开头介绍的神经网络有多少个参数?
在实践中,我们通常会使用第三个数据集,即所谓的验证数据集,来寻找最佳的超参数设置。验证数据集与测试集类似。不过,为了避免评估结果产生偏差,测试集我们只希望使用一次。而验证集,我们通常会多次使用它来调整模型的设置。
我们还引入了名为 `model.train()` 和 `model.eval()` 的新设置。顾名思义,这些设置用于将模型置于训练模式和评估模式。对于在训练和推理期间行为不同的组件(例如 dropout 或批归一化层),这是必要的。由于我们的 `NeuralNetwork` 类中没有 dropout 或其他受这些设置影响的组件,因此在上面的代码中使用 `model.train()` 和 `model.eval()` 是多余的。然而,作为最佳实践,无论如何都应该包含它们,以避免在我们更改模型架构或重用代码来训练不同的模型时出现意外行为。
如前所述,我们将 logits 直接传递给 `cross_entropy` 损失函数,它会在内部应用 softmax 函数以提高效率和数值稳定性。然后,调用 `loss.backward()` 将计算 PyTorch 在后台构建的计算图中的梯度。`optimizer.step()` 方法将使用这些梯度来更新模型参数,以最小化损失。对于 SGD 优化器来说,这意味着将梯度乘以学习率,然后将缩放后的负梯度加到参数上。
> [!TIP]
>
> **个人思考:** 这段话翻译起来比较拗口,我用大白话来重新解读一下,这段话主要讲了神经网络是如何通过学习来改进自己的“预测能力”的几个关键步骤:
>
> 1. **“裁判”打分:** 想象一下,我们训练神经网络就像教一个小孩子做题。首先,我们给它一道题(输入数据),它会给出一个答案(logits)。然后,我们需要一个“裁判”(损失函数)来判断它答得怎么样,打一个分数。分数越高(loss越大),说明它答得越离谱;分数越低(loss越小),说明它答得越好。`cross_entropy` 损失函数就像这样一个“裁判”,它会根据神经网络的输出和正确的答案,给出一个“错误程度”的评分。它还会偷偷地帮我们把神经网络给出的“原始分数”(logits)转换成更像“可能性”的分数(通过内部的 softmax 函数)。
> 2. **“指路人”指方向:** 接下来,我们需要知道怎么才能让“裁判”打的分数越来越低,也就是让神经网络的答案越来越准确。`loss.backward()` 这个命令就像一个“指路人”,它会告诉我们,如果我们稍微调整一下神经网络内部的“设置”(模型参数),这个“错误程度”的分数会怎么变化。它会告诉我们应该朝着哪个方向调整这些“设置”,才能让分数降低。这些“方向”就是我们说的“梯度”。
> 3. **“修理工”调参数:** 最后,我们需要一个“修理工”(优化器)来根据“指路人”给出的方向,真正地去调整神经网络内部的“设置”(模型参数)。`optimizer.step()` 这个命令就是让“修理工”按照“指路人”的指示,对模型的参数进行微小的调整,目的是让“错误程度”的分数越来越小。
> 4. **SGD 优化器的具体做法:** 对于我们这里用到的 SGD 优化器,它的调整方法很简单:它会把“指路人”给出的“方向”(梯度)乘以一个“学习率”(learning rate),这个“学习率”决定了每次调整的幅度有多大。然后,它会朝着让错误减少的方向(梯度的反方向)稍微调整一下模型的参数。
>
> 这么解释不知道各位读者能否明白。
**防止不希望的梯度累积** 在每个更新轮次中包含一个 `optimizer.zero_grad()` 调用来将梯度重置为零非常重要。否则,梯度会累积,这可能是不希望发生的情况。
> [!TIP]
>
> **个人思考:** 为什么避免梯度累积很重要?想象一下,你正在教一个小孩子画画,你想教他画一个圆。
>
> 1. **每一轮你给他看一张图片,告诉他哪里画得不对,需要怎么改(这就是计算梯度)。** 比如,你说:“这里有点扁,应该往右边挪一点。”
> 2. **如果你不擦掉之前的修改痕迹,** 那么下一轮你给他看另一张圆的图片,告诉他新的修改意见(新的梯度),比如:“这里太大了,应该缩小一点。”
> 3. **问题就来了:** 如果你不擦掉上次“往右边挪一点”的痕迹,这次又让他“缩小一点”,他可能会感到困惑,不知道到底应该怎么改。之前的修改意见可能会和这次的修改意见“混在一起”,导致他画出来的圆越来越奇怪。
>
> **`optimizer.zero_grad()` 就相当于你在每一轮教他画画之前,都把之前的修改痕迹擦干净。** 这样,他每次听到的修改意见都是针对当前这张图片的,不会受到之前图片的影响。回到神经网络中,**`optimizer.zero_grad()` 的作用就是在每一轮开始时,把上一轮积累的“修改意见”清空,** 确保模型参数的每一次更新都是基于当前这批数据计算出来的梯度,而不是之前数据的“残留影响”。
在我们训练完模型之后,我们可以使用它来进行预测,如下所示:
```python
model.eval()
with torch.no_grad():
outputs = model(X_train)
print(outputs)
```
输出如下:
```python
tensor([[ 2.8569, -4.1618],
[ 2.5382, -3.7548],
[ 2.0944, -3.1820],
[-1.4814, 1.4816],
[-1.7176, 1.7342]])
```
为了获得类别成员概率,我们可以使用 PyTorch 的 softmax 函数,如下所示:
```python
torch.set_printoptions(sci_mode=False)
probas = torch.softmax(outputs, dim=1)
print(probas)
```
输出如下:
```python
tensor([[ 0.9991, 0.0009],
[ 0.9982, 0.0018],
[ 0.9949, 0.0051],
[ 0.0491, 0.9509],
[ 0.0307, 0.9693]])
```
让我们来看一下以上输出的第一行。第一个值(列)表示该训练样本有 99.91% 的概率属于类别 0,以及 0.09% 的概率属于类别 1。(这里的 `set_printoptions` 用于使输出更易于阅读。)
我们可以使用 PyTorch 的 `argmax` 函数将这些概率值转换为类别标签预测,如果我们设置 `dim=1`,它将返回每一行中最高值的索引位置(设置 `dim=0` 则会返回每一列中的最高值):
```python
predictions = torch.argmax(probas, dim=1)
print(predictions)
```
打印如下:
```python
tensor([0, 0, 0, 1, 1])
```
注意,无需计算 softmax 概率即可获得类别标签。我们也可以直接对 logits(输出)应用 `argmax` 函数:
```python
predictions = torch.argmax(outputs, dim=1)
print(predictions)
```
输出如下:
```python
tensor([0, 0, 0, 1, 1])
```
在上面,我们计算了训练数据集的预测标签。由于训练数据集相对较小,我们可以通过肉眼将其与真实的训练标签进行比较,发现模型的准确率为100% 。我们可以使用 `==` 比较运算符来再次核实这一点:
```python
predictions == y_train
```
结果如下:
```python
tensor([True, True, True, True, True])
```
使用 `torch.sum`,我们可以按如下方式计算出正确预测的数量:
```python
torch.sum(predictions == y_train)
```
结果为:
```
5
```
由于该数据集包含 5 个训练样本,我们有 5 个预测结果是正确的,这等于 5/5 × 100% = 100% 的预测准确率。
然而,为了让预测准确率的计算更加通用,我们可以实现一个 `compute_accuracy` 函数,如下面的代码清单所示。
```python
# Listing A.10 A function to compute the prediction accuracy
def compute_accuracy(model, dataloader):
model = model.eval()
correct = 0.0
total_examples = 0
for idx, (features, labels) in enumerate(dataloader):
with torch.no_grad():
logits = model(features)
predictions = torch.argmax(logits, dim=1)
compare = labels == predictions #A
correct += torch.sum(compare) #B
total_examples += len(compare)
return (correct / total_examples).item() #C
#A 这会返回一个由 True/False 值组成的张量,取决于标签是否匹配
#B sum 操作会计算 True 值的数量
#C 这是正确预测的比例,一个介于 0 和 1 之间的值。并且 .item() 返回张量的值作为 Python 浮点数。
```
注意,`compute_accuracy` 函数的内部实现与我们之前将 logits 转换为类别标签时使用的方法类似。
接着,我们可以将该函数应用于训练数据,如下所示:
```python
print(compute_accuracy(model, train_loader))
```
输出如下:
```python
1.0
```
同样,我们可以将该函数应用于测试集,如下所示:
```python
>>> print(compute_accuracy(model, test_loader))
```
输出如下:
```python
1.0
```
在本节中,我们学习了如何使用 PyTorch 训练神经网络。接下来,让我们看看如何在训练后保存和恢复模型。
## 4.8 保存和加载模型
在上一节中,我们成功地训练了一个模型。现在让我们看看如何保存已训练好的模型以便以后重用。
这是在 PyTorch 中保存和加载模型的推荐方法:
```python
torch.save(model.state_dict(), "model.pth")
```
模型的 `state_dict` 是一个 Python 字典对象,它将模型中的每一层映射到其可训练的参数(权重和偏置)。注意,“model.pth” 是保存在磁盘上的模型文件名。我们可以随意命名和设置文件扩展名;然而,`.pth` 和 `.pt` 是最常见的约定。
一旦我们保存了模型,我们就可以像下面这样从磁盘恢复它:
```python
model = NeuralNetwork(2, 2)
model.load_state_dict(torch.load("model.pth"))
```
`torch.load("model.pth")` 函数读取文件 “model.pth” 并重建包含模型参数的 Python 字典对象,同时, `model.load_state_dict()` 将这些参数应用于模型,从而有效地恢复其保存时的学习状态。
注意,如果你在保存模型的同一个会话中执行此代码,那么上面的 `model = NeuralNetwork(2, 2)` 这行代码严格来说并不是必需的。然而,我在这里包含了这行代码,是为了说明我们需要在内存中有一个模型实例才能应用已保存的参数。在这里,`NeuralNetwork(2, 2)` 的架构需要与原始保存的模型完全匹配。
现在,我们已经具备了使用 PyTorch 实现大语言模型的能力。不过,在我入下一章节之前,最后一节将向你展示如何使用一个或多个 GPU(如果可用)更快地训练 PyTorch 模型。
## A.9 使用 GPU 优化训练性能
在本章的最后一节中,我们将学习如何利用 GPU 来加速深度神经网络的训练,相比于普通的 CPU,GPU 可以显著提升训练速度。首先,我们将介绍 PyTorch 中 GPU 计算背后的主要概念。然后,我们将在一个 GPU 上训练一个模型。最后,我们将探讨使用多个 GPU 进行分布式训练。
### 9.1 PyTorch 在 GPU 设备上的计算
正如你将看到的,仅需修改三行代码,就可以将 2.7 节中的训练循环代码运行在 GPU 上。
在我们进行修改之前,理解 PyTorch 中 GPU 计算背后的主要概念至关重要。首先,我们需要介绍“设备”的概念。在 PyTorch 中,“设备”是指计算发生和数据存储的地方。CPU 和 GPU 就是设备的例子。一个 PyTorch 张量驻留在某个设备上,并且其上的所有操作都在同一个设备上执行。
让我们看看这在实际中是如何运作的。假设你已经按照 2.1.3 节“安装 PyTorch”中的说明安装了与 GPU 兼容的 PyTorch 版本,我们可以通过以下代码再次确认我们的运行时环境是否支持 GPU 计算:
```python
print(torch.cuda.is_available())
```
结果如下:
```python
True
```
现在,假设我们有两个张量,我们可以按如下方式j将它们相加——这个计算默认情况下将在 CPU 上执行:
```python
tensor_1 = torch.tensor([1., 2., 3.])
tensor_2 = torch.tensor([4., 5., 6.])
print(tensor_1 + tensor_2)
```
输出结果如下:
```python
tensor([5., 7., 9.])
```
现在我们可以使用 `.to()` 方法将这些张量转移到 GPU 上,并在那里执行加法操作:
```python
tensor_1 = tensor_1.to("cuda")
tensor_2 = tensor_2.to("cuda")
print(tensor_1 + tensor_2)
```
输出结果如下:
```python
tensor([5., 7., 9.], device='cuda:0')
```
请注意,生成的张量现在包含了设备信息,`device='cuda:0'`,这意味着这些张量位于第一个 GPU 上。如果你的机器装有多个 GPU,你可以选择指定要将张量转移到哪个 GPU 上。你可以通过在传输命令中指定设备 ID 来做到这一点。例如,你可以使用 `.to("cuda:0")`、`.to("cuda:1")` 等等。
然而,需要注意的是,所有参与运算的张量必须位于同一个设备上。否则,计算将会失败,如下所示,其中一个张量位于 CPU 上,而另一个位于 GPU 上:
```python
tensor_1 = tensor_1.to("cpu")
print(tensor_1 + tensor_2)
```
结果如下:
```python
RuntimeError Traceback (most recent call last)
in
然而,如果我们处理的是非常小的数据集,那么将 `num_workers` 设置为 1 或更大的值可能没有必要,因为总的训练时间可能只需要几分之一秒。相反,如果你处理的是非常小的数据集或者像 Jupyter 笔记本这样的交互式环境,增加 `num_workers` 可能不会带来任何明显的加速。事实上,它们甚至可能导致一些问题。一个潜在的问题是启动多个工作进程的开销,当你的数据集很小时,这个开销可能比实际的数据加载时间还要长。
此外,对于 Jupyter 笔记本,将 `num_workers` 设置为大于 0 的值有时会导致不同进程之间资源共享的问题,从而引发错误或笔记本崩溃。因此,理解这种权衡并在设置 `num_workers` 参数时做出明智的决定至关重要。如果使用得当,它可以是一个有益的工具,但应该根据你的具体数据集大小和计算环境进行调整,以获得最佳结果。
根据我的经验,对于许多真实世界的数据集,将 `num_workers` 设置为 4 通常可以获得最佳性能,但最佳设置取决于你的硬件以及在 `Dataset` 类中定义的用于加载训练样本的代码。
## 4.7 一个典型的训练循环
到目前为止,我们已经讨论了训练神经网络的所有必要条件:PyTorch 的张量库、自动梯度(autograd)、模块 API(Module API)和高效的数据加载器。现在,让我们将所有这些要素结合起来,并在上一节创建的玩具数据集上训练一个神经网络。训练代码如下面的代码清单 A.9 所示。
```python
# Listing A.9 Neural network training in PyTorch
import torch.nn.functional as F
torch.manual_seed(123)
model = NeuralNetwork(num_inputs=2, num_outputs=2) #A
optimizer = torch.optim.SGD(model.parameters(), lr=0.5) #B
num_epochs = 3
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, labels) in enumerate(train_loader):
logits = model(features)
loss = F.cross_entropy(logits, labels)
optimizer.zero_grad() #C
loss.backward() #D
optimizer.step() #E
### LOGGING
print(f"Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batch {batch_idx:03d}/{len(train_loader):03d}"
f" | Train Loss: {loss:.2f}")
model.eval()
# Optional model evaluation
#A 上一节的数据集包含 2 个特征和 2 个类别
#B 我们让优化器知道需要优化哪些参数
#C 将上一轮的梯度设置为零,以防止意外的梯度累积
#D 计算损失函数相对于模型参数的梯度
#E 优化器使用梯度来更新模型参数
```
运行上面清单 A.9 中的代码会产生以下输出:
```python
Epoch: 001/003 | Batch 000/002 | Train Loss: 0.75
Epoch: 001/003 | Batch 001/002 | Train Loss: 0.65
Epoch: 002/003 | Batch 000/002 | Train Loss: 0.44
Epoch: 002/003 | Batch 001/002 | Trainl Loss: 0.13
Epoch: 003/003 | Batch 000/002 | Train Loss: 0.03
Epoch: 003/003 | Batch 001/002 | Train Loss: 0.00
```
正如我们所见,训练损失值在 3 个轮次后降至零,这表明模型在训练集上收敛了。然而,在我们评估模型的预测之前,让我们先回顾一下前面代码清单中的一些细节。
首先,请注意我们初始化了一个具有两个输入和两个输出的模型。这是因为上一节的玩具数据集包含两个输入特征和两个需要预测的类别标签。我们使用了随机梯度下降(SGD)优化器,学习率(lr)设置为 0.5。学习率是一个超参数,这意味着它是一个可调整的设置,我们需要通过观察损失来实验确定。理想情况下,我们希望选择一个学习率,使得损失在一定数量的轮次后收敛——轮次的数量是另一个需要选择的超参数。
> [!NOTE]
>
> **练习 A.3**
>
> 在本节开头介绍的神经网络有多少个参数?
在实践中,我们通常会使用第三个数据集,即所谓的验证数据集,来寻找最佳的超参数设置。验证数据集与测试集类似。不过,为了避免评估结果产生偏差,测试集我们只希望使用一次。而验证集,我们通常会多次使用它来调整模型的设置。
我们还引入了名为 `model.train()` 和 `model.eval()` 的新设置。顾名思义,这些设置用于将模型置于训练模式和评估模式。对于在训练和推理期间行为不同的组件(例如 dropout 或批归一化层),这是必要的。由于我们的 `NeuralNetwork` 类中没有 dropout 或其他受这些设置影响的组件,因此在上面的代码中使用 `model.train()` 和 `model.eval()` 是多余的。然而,作为最佳实践,无论如何都应该包含它们,以避免在我们更改模型架构或重用代码来训练不同的模型时出现意外行为。
如前所述,我们将 logits 直接传递给 `cross_entropy` 损失函数,它会在内部应用 softmax 函数以提高效率和数值稳定性。然后,调用 `loss.backward()` 将计算 PyTorch 在后台构建的计算图中的梯度。`optimizer.step()` 方法将使用这些梯度来更新模型参数,以最小化损失。对于 SGD 优化器来说,这意味着将梯度乘以学习率,然后将缩放后的负梯度加到参数上。
> [!TIP]
>
> **个人思考:** 这段话翻译起来比较拗口,我用大白话来重新解读一下,这段话主要讲了神经网络是如何通过学习来改进自己的“预测能力”的几个关键步骤:
>
> 1. **“裁判”打分:** 想象一下,我们训练神经网络就像教一个小孩子做题。首先,我们给它一道题(输入数据),它会给出一个答案(logits)。然后,我们需要一个“裁判”(损失函数)来判断它答得怎么样,打一个分数。分数越高(loss越大),说明它答得越离谱;分数越低(loss越小),说明它答得越好。`cross_entropy` 损失函数就像这样一个“裁判”,它会根据神经网络的输出和正确的答案,给出一个“错误程度”的评分。它还会偷偷地帮我们把神经网络给出的“原始分数”(logits)转换成更像“可能性”的分数(通过内部的 softmax 函数)。
> 2. **“指路人”指方向:** 接下来,我们需要知道怎么才能让“裁判”打的分数越来越低,也就是让神经网络的答案越来越准确。`loss.backward()` 这个命令就像一个“指路人”,它会告诉我们,如果我们稍微调整一下神经网络内部的“设置”(模型参数),这个“错误程度”的分数会怎么变化。它会告诉我们应该朝着哪个方向调整这些“设置”,才能让分数降低。这些“方向”就是我们说的“梯度”。
> 3. **“修理工”调参数:** 最后,我们需要一个“修理工”(优化器)来根据“指路人”给出的方向,真正地去调整神经网络内部的“设置”(模型参数)。`optimizer.step()` 这个命令就是让“修理工”按照“指路人”的指示,对模型的参数进行微小的调整,目的是让“错误程度”的分数越来越小。
> 4. **SGD 优化器的具体做法:** 对于我们这里用到的 SGD 优化器,它的调整方法很简单:它会把“指路人”给出的“方向”(梯度)乘以一个“学习率”(learning rate),这个“学习率”决定了每次调整的幅度有多大。然后,它会朝着让错误减少的方向(梯度的反方向)稍微调整一下模型的参数。
>
> 这么解释不知道各位读者能否明白。
**防止不希望的梯度累积** 在每个更新轮次中包含一个 `optimizer.zero_grad()` 调用来将梯度重置为零非常重要。否则,梯度会累积,这可能是不希望发生的情况。
> [!TIP]
>
> **个人思考:** 为什么避免梯度累积很重要?想象一下,你正在教一个小孩子画画,你想教他画一个圆。
>
> 1. **每一轮你给他看一张图片,告诉他哪里画得不对,需要怎么改(这就是计算梯度)。** 比如,你说:“这里有点扁,应该往右边挪一点。”
> 2. **如果你不擦掉之前的修改痕迹,** 那么下一轮你给他看另一张圆的图片,告诉他新的修改意见(新的梯度),比如:“这里太大了,应该缩小一点。”
> 3. **问题就来了:** 如果你不擦掉上次“往右边挪一点”的痕迹,这次又让他“缩小一点”,他可能会感到困惑,不知道到底应该怎么改。之前的修改意见可能会和这次的修改意见“混在一起”,导致他画出来的圆越来越奇怪。
>
> **`optimizer.zero_grad()` 就相当于你在每一轮教他画画之前,都把之前的修改痕迹擦干净。** 这样,他每次听到的修改意见都是针对当前这张图片的,不会受到之前图片的影响。回到神经网络中,**`optimizer.zero_grad()` 的作用就是在每一轮开始时,把上一轮积累的“修改意见”清空,** 确保模型参数的每一次更新都是基于当前这批数据计算出来的梯度,而不是之前数据的“残留影响”。
在我们训练完模型之后,我们可以使用它来进行预测,如下所示:
```python
model.eval()
with torch.no_grad():
outputs = model(X_train)
print(outputs)
```
输出如下:
```python
tensor([[ 2.8569, -4.1618],
[ 2.5382, -3.7548],
[ 2.0944, -3.1820],
[-1.4814, 1.4816],
[-1.7176, 1.7342]])
```
为了获得类别成员概率,我们可以使用 PyTorch 的 softmax 函数,如下所示:
```python
torch.set_printoptions(sci_mode=False)
probas = torch.softmax(outputs, dim=1)
print(probas)
```
输出如下:
```python
tensor([[ 0.9991, 0.0009],
[ 0.9982, 0.0018],
[ 0.9949, 0.0051],
[ 0.0491, 0.9509],
[ 0.0307, 0.9693]])
```
让我们来看一下以上输出的第一行。第一个值(列)表示该训练样本有 99.91% 的概率属于类别 0,以及 0.09% 的概率属于类别 1。(这里的 `set_printoptions` 用于使输出更易于阅读。)
我们可以使用 PyTorch 的 `argmax` 函数将这些概率值转换为类别标签预测,如果我们设置 `dim=1`,它将返回每一行中最高值的索引位置(设置 `dim=0` 则会返回每一列中的最高值):
```python
predictions = torch.argmax(probas, dim=1)
print(predictions)
```
打印如下:
```python
tensor([0, 0, 0, 1, 1])
```
注意,无需计算 softmax 概率即可获得类别标签。我们也可以直接对 logits(输出)应用 `argmax` 函数:
```python
predictions = torch.argmax(outputs, dim=1)
print(predictions)
```
输出如下:
```python
tensor([0, 0, 0, 1, 1])
```
在上面,我们计算了训练数据集的预测标签。由于训练数据集相对较小,我们可以通过肉眼将其与真实的训练标签进行比较,发现模型的准确率为100% 。我们可以使用 `==` 比较运算符来再次核实这一点:
```python
predictions == y_train
```
结果如下:
```python
tensor([True, True, True, True, True])
```
使用 `torch.sum`,我们可以按如下方式计算出正确预测的数量:
```python
torch.sum(predictions == y_train)
```
结果为:
```
5
```
由于该数据集包含 5 个训练样本,我们有 5 个预测结果是正确的,这等于 5/5 × 100% = 100% 的预测准确率。
然而,为了让预测准确率的计算更加通用,我们可以实现一个 `compute_accuracy` 函数,如下面的代码清单所示。
```python
# Listing A.10 A function to compute the prediction accuracy
def compute_accuracy(model, dataloader):
model = model.eval()
correct = 0.0
total_examples = 0
for idx, (features, labels) in enumerate(dataloader):
with torch.no_grad():
logits = model(features)
predictions = torch.argmax(logits, dim=1)
compare = labels == predictions #A
correct += torch.sum(compare) #B
total_examples += len(compare)
return (correct / total_examples).item() #C
#A 这会返回一个由 True/False 值组成的张量,取决于标签是否匹配
#B sum 操作会计算 True 值的数量
#C 这是正确预测的比例,一个介于 0 和 1 之间的值。并且 .item() 返回张量的值作为 Python 浮点数。
```
注意,`compute_accuracy` 函数的内部实现与我们之前将 logits 转换为类别标签时使用的方法类似。
接着,我们可以将该函数应用于训练数据,如下所示:
```python
print(compute_accuracy(model, train_loader))
```
输出如下:
```python
1.0
```
同样,我们可以将该函数应用于测试集,如下所示:
```python
>>> print(compute_accuracy(model, test_loader))
```
输出如下:
```python
1.0
```
在本节中,我们学习了如何使用 PyTorch 训练神经网络。接下来,让我们看看如何在训练后保存和恢复模型。
## 4.8 保存和加载模型
在上一节中,我们成功地训练了一个模型。现在让我们看看如何保存已训练好的模型以便以后重用。
这是在 PyTorch 中保存和加载模型的推荐方法:
```python
torch.save(model.state_dict(), "model.pth")
```
模型的 `state_dict` 是一个 Python 字典对象,它将模型中的每一层映射到其可训练的参数(权重和偏置)。注意,“model.pth” 是保存在磁盘上的模型文件名。我们可以随意命名和设置文件扩展名;然而,`.pth` 和 `.pt` 是最常见的约定。
一旦我们保存了模型,我们就可以像下面这样从磁盘恢复它:
```python
model = NeuralNetwork(2, 2)
model.load_state_dict(torch.load("model.pth"))
```
`torch.load("model.pth")` 函数读取文件 “model.pth” 并重建包含模型参数的 Python 字典对象,同时, `model.load_state_dict()` 将这些参数应用于模型,从而有效地恢复其保存时的学习状态。
注意,如果你在保存模型的同一个会话中执行此代码,那么上面的 `model = NeuralNetwork(2, 2)` 这行代码严格来说并不是必需的。然而,我在这里包含了这行代码,是为了说明我们需要在内存中有一个模型实例才能应用已保存的参数。在这里,`NeuralNetwork(2, 2)` 的架构需要与原始保存的模型完全匹配。
现在,我们已经具备了使用 PyTorch 实现大语言模型的能力。不过,在我入下一章节之前,最后一节将向你展示如何使用一个或多个 GPU(如果可用)更快地训练 PyTorch 模型。
## A.9 使用 GPU 优化训练性能
在本章的最后一节中,我们将学习如何利用 GPU 来加速深度神经网络的训练,相比于普通的 CPU,GPU 可以显著提升训练速度。首先,我们将介绍 PyTorch 中 GPU 计算背后的主要概念。然后,我们将在一个 GPU 上训练一个模型。最后,我们将探讨使用多个 GPU 进行分布式训练。
### 9.1 PyTorch 在 GPU 设备上的计算
正如你将看到的,仅需修改三行代码,就可以将 2.7 节中的训练循环代码运行在 GPU 上。
在我们进行修改之前,理解 PyTorch 中 GPU 计算背后的主要概念至关重要。首先,我们需要介绍“设备”的概念。在 PyTorch 中,“设备”是指计算发生和数据存储的地方。CPU 和 GPU 就是设备的例子。一个 PyTorch 张量驻留在某个设备上,并且其上的所有操作都在同一个设备上执行。
让我们看看这在实际中是如何运作的。假设你已经按照 2.1.3 节“安装 PyTorch”中的说明安装了与 GPU 兼容的 PyTorch 版本,我们可以通过以下代码再次确认我们的运行时环境是否支持 GPU 计算:
```python
print(torch.cuda.is_available())
```
结果如下:
```python
True
```
现在,假设我们有两个张量,我们可以按如下方式j将它们相加——这个计算默认情况下将在 CPU 上执行:
```python
tensor_1 = torch.tensor([1., 2., 3.])
tensor_2 = torch.tensor([4., 5., 6.])
print(tensor_1 + tensor_2)
```
输出结果如下:
```python
tensor([5., 7., 9.])
```
现在我们可以使用 `.to()` 方法将这些张量转移到 GPU 上,并在那里执行加法操作:
```python
tensor_1 = tensor_1.to("cuda")
tensor_2 = tensor_2.to("cuda")
print(tensor_1 + tensor_2)
```
输出结果如下:
```python
tensor([5., 7., 9.], device='cuda:0')
```
请注意,生成的张量现在包含了设备信息,`device='cuda:0'`,这意味着这些张量位于第一个 GPU 上。如果你的机器装有多个 GPU,你可以选择指定要将张量转移到哪个 GPU 上。你可以通过在传输命令中指定设备 ID 来做到这一点。例如,你可以使用 `.to("cuda:0")`、`.to("cuda:1")` 等等。
然而,需要注意的是,所有参与运算的张量必须位于同一个设备上。否则,计算将会失败,如下所示,其中一个张量位于 CPU 上,而另一个位于 GPU 上:
```python
tensor_1 = tensor_1.to("cpu")
print(tensor_1 + tensor_2)
```
结果如下:
```python
RuntimeError Traceback (most recent call last)
in ()
1 tensor_1 = tensor_1.to("cpu")
----> 2 print(tensor_1 + tensor_2)
RuntimeError: Expected all tensors to be on the same device, but found at least two
devices, cuda:0 and cpu!
```
在本节中,我们了解到在 PyTorch 上进行 GPU 计算是相对简单的。我们所需要做的就是将张量转移到同一个 GPU 设备上,PyTorch 会处理其余的事情。掌握了这些信息,我们现在可以在 GPU 上训练上一节中的神经网络了。
### A.9.2 单 GPU 训练
现在我们已经熟悉了如何将张量传输到 GPU ,我们可以修改训练循环(参见第 2.7 节“典型的训练循环”),使其在 GPU 上运行。这只需要修改三行代码,如下面的代码清单 A.11 所示。
```python
# Listing A.11 A training loop on a GPU
torch.manual_seed(123)
model = NeuralNetwork(num_inputs=2, num_outputs=2)
device = torch.device("cuda") #A
model = model.to(device) #B
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
num_epochs = 3
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, labels) in enumerate(train_loader):
features, labels = features.to(device), labels.to(device) #C
logits = model(features)
loss = F.cross_entropy(logits, labels) # Loss function
optimizer.zero_grad()
loss.backward()
optimizer.step()
### LOGGING
print(f"Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batch {batch_idx:03d}/{len(train_loader):03d}"
f" | Train/Val Loss: {loss:.2f}")
model.eval()
# Optional model evaluation
#A 定义一个设备变量,默认设置为 GPU。
#B 将模型转移到 GPU 上。
#C 将数据转移到 GPU 上。
```
运行上面的代码将输出以下内容,类似于之前在 2.7 节中在 CPU 上获得的结果:
```python
Epoch: 001/003 | Batch 000/002 | Train/Val Loss: 0.75
Epoch: 001/003 | Batch 001/002 | Train/Val Loss: 0.65
Epoch: 002/003 | Batch 000/002 | Train/Val Loss: 0.44
Epoch: 002/003 | Batch 001/002 | Train/Val Loss: 0.13
Epoch: 003/003 | Batch 000/002 | Train/Val Loss: 0.03
Epoch: 003/003 | Batch 001/002 | Train/Val Loss: 0.00
```
我们也可以使用 `.to("cuda")` 来代替 `device = torch.device("cuda")`。正如我们在 2.9.1 节中看到的,将张量转移到 GPU,这两种方法效果一样,但使用 `"cuda"` 更简洁。我们还可以将该语句修改为如下形式,这样如果 GPU 不可用,相同的代码也可以在 CPU 上执行,这通常被认为是共享 PyTorch 代码时的最佳实践:
```python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
```
对于上面修改后的训练循环,我们可能不会看到速度提升,因为存在从 CPU 到 GPU 的内存传输开销。然而,在训练深度神经网络,特别是大语言模型时,我们可以期待显著的速度提升。
正如本节所述,在 PyTorch 中使用单个 GPU 训练模型是相对容易的。接下来,让我们介绍另一个概念:在多个 GPU 上训练模型。
> [!NOTE]
>
> **PyTorch 在 macOS 上**
>
> 如果你需要在配备 Apple 芯片(例如 M1、M2、M3 或更新型号)的 Apple Mac 上训练,你可以将代码从:
>
> ```python
> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
> ```
>
> 变更为:
>
> ```python
> device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
> ```
>
> 从而充分利用 GPU 芯片的性能。
> [!NOTE]
>
> **练习 A.4**
>
> 比较在 CPU 上和 GPU 上进行矩阵乘法的运行时长。在什么矩阵尺寸下,你会开始看到在 GPU 上进行的矩阵乘法比在 CPU 上更快?提示:我建议在 Jupyter 中使用 `%timeit` 命令来比较运行时长。例如,给定矩阵 `a` 和 `b`,在新笔记本单元格中运行命令 `%timeit a @ b`。
### A.9.3 使用多个 GPU 训练
在本节中,我们将简要介绍分布式训练的概念。分布式训练是指将模型训练过程分散到多个 GPU 和机器上进行。
为什么我们需要这样做呢?这是因为在单个 GPU 或机器上训练模型可能非常耗时。通过将训练过程分布到多台机器上,每台机器可能配备多个 GPU,可以显著缩短训练时间。这在模型开发的实验阶段尤其重要,因为可能需要多次训练迭代来微调模型参数和架构。
> [!NOTE]
>
> **多 GPU 计算是可选的** 对于本书而言,不需要拥有或使用多个 GPU。本节的目的是为那些对 PyTorch 中多 GPU 计算如何工作感兴趣的读者提供信息。
在本节中,我们将介绍分布式训练最基本的情况:PyTorch 的 DistributedDataParallel (DDP) 策略。DDP 通过将输入数据拆分到可用的设备上并同时处理这些数据子集来实现并行计算。
这是如何工作的呢?PyTorch 在每个 GPU 上启动一个独立的进程,每个进程都会接收并保存模型的副本——这些副本在训练过程中会保持同步。为了说明这一点,假设我们有两个想要用来训练神经网络的 GPU,如图 A.12 所示。
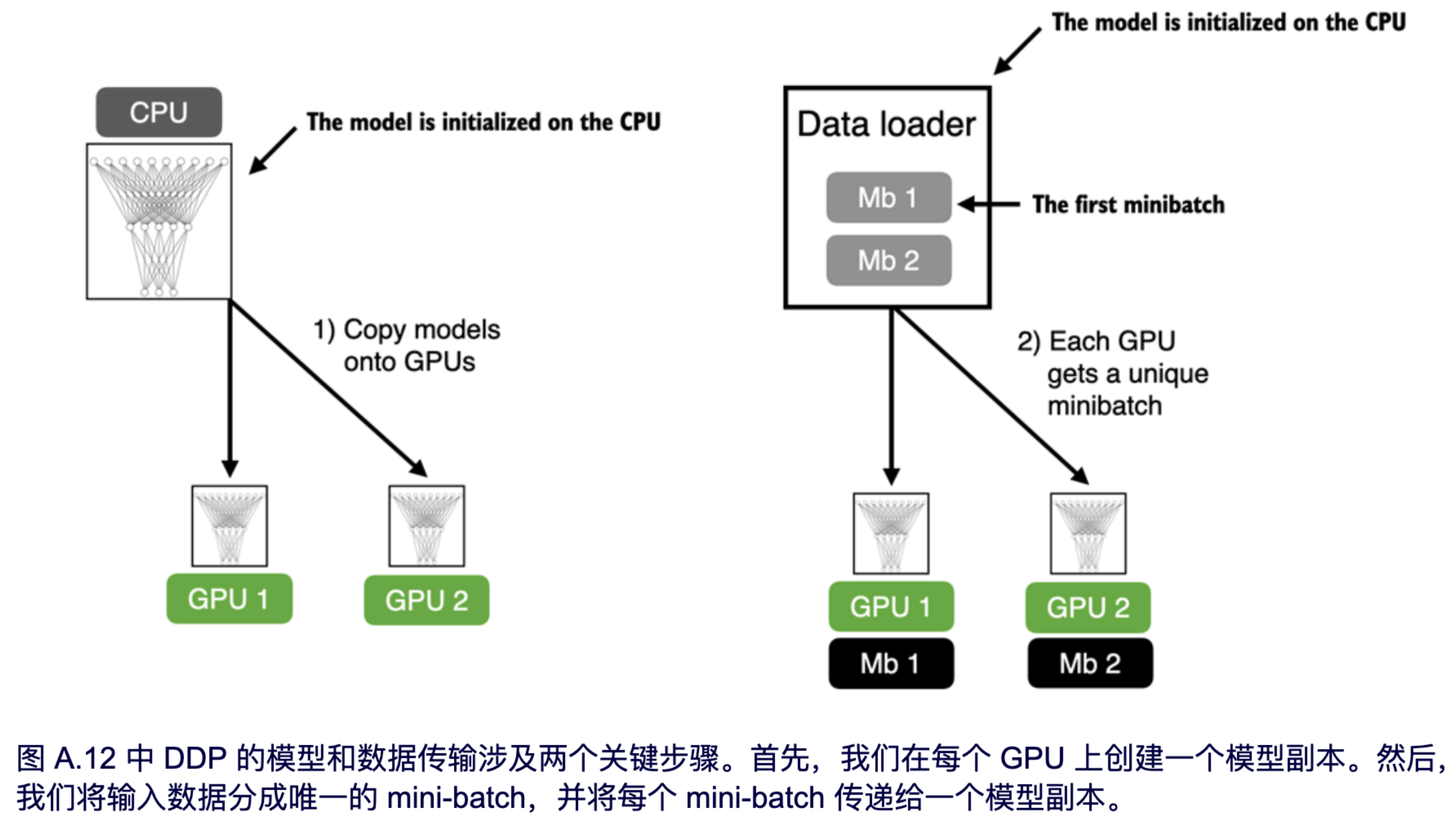 如上图所示,两个 GPU 中的每一个都将接收到模型的一个副本。然后,在每个训练迭代中,每个模型都将从数据加载器接收到一个小批量(或称为批次)。我们可以使用 `DistributedSampler` 来确保在使用 DDP 时,每个 GPU 都将接收到不同的、不重叠的批次。
由于每个模型副本都会看到不同的训练数据样本,因此模型副本将返回不同的 logits 作为输出,并在反向传播期间计算不同的梯度。然后,这些梯度在训练期间被平均和同步,以更新模型。这样,我们确保模型不会发散,如图 A.13 所示。
> [!TIP]
>
> **个人思考:** 这里的描述太笼统,老规矩,我还是通过日常生活类比的方式来说明这里的机制。
>
> 想象一下,你有一个非常大的学习任务(训练一个神经网络),一个人做起来会非常慢。现在你有了两(或更多)个帮手(GPU)。
>
> 分布式训练就像一个团队的合作过程:
>
> 1. **复制模型,分发任务:** 就像给每个帮手都发了一份完整的学习资料(模型的副本)。
> 2. **分配不同的学习内容:** 把需要学习的大量数据分成很多小份(不同的批次),然后每个帮手都拿到不一样的小份去学习,确保他们学到的东西不完全重复。这就像给每个帮手分配了不同的习题。
> 3. **独立学习,得出经验:** 每个帮手都根据自己拿到的小份数据进行学习,算出自己的“经验”(logits 和梯度)。这就像每个帮手独立完成自己的习题,得出自己的答案和解题思路。
> 4. **汇总经验,共同进步:** 学习结束后,所有的帮手会把自己学到的“经验”(梯度)拿出来一起讨论,取长补短,求平均值,然后用这个平均的“经验”去更新他们手上的学习资料(模型)。这就像大家一起对答案,找出最好的解题方法,然后更新自己的知识。
> 5. **止跑偏,保持一致:** 通过这种“汇总经验,共同进步”的方式,可以确保每个帮手都在朝着同一个目标学习,不会因为学习的数据不一样而导致理解偏差(模型不会发散)。这就像确保所有帮手都在学习同一个科目的内容,而不是各自学不同的东西。
>
> 简单来说,多 GPU 训练就像是让多个“学生”(GPU)同时学习不同的“教材”(数据),然后定期交流“学习心得”(梯度),最终让每个“学生”都掌握相同的知识(更新后的模型)。
如上图所示,两个 GPU 中的每一个都将接收到模型的一个副本。然后,在每个训练迭代中,每个模型都将从数据加载器接收到一个小批量(或称为批次)。我们可以使用 `DistributedSampler` 来确保在使用 DDP 时,每个 GPU 都将接收到不同的、不重叠的批次。
由于每个模型副本都会看到不同的训练数据样本,因此模型副本将返回不同的 logits 作为输出,并在反向传播期间计算不同的梯度。然后,这些梯度在训练期间被平均和同步,以更新模型。这样,我们确保模型不会发散,如图 A.13 所示。
> [!TIP]
>
> **个人思考:** 这里的描述太笼统,老规矩,我还是通过日常生活类比的方式来说明这里的机制。
>
> 想象一下,你有一个非常大的学习任务(训练一个神经网络),一个人做起来会非常慢。现在你有了两(或更多)个帮手(GPU)。
>
> 分布式训练就像一个团队的合作过程:
>
> 1. **复制模型,分发任务:** 就像给每个帮手都发了一份完整的学习资料(模型的副本)。
> 2. **分配不同的学习内容:** 把需要学习的大量数据分成很多小份(不同的批次),然后每个帮手都拿到不一样的小份去学习,确保他们学到的东西不完全重复。这就像给每个帮手分配了不同的习题。
> 3. **独立学习,得出经验:** 每个帮手都根据自己拿到的小份数据进行学习,算出自己的“经验”(logits 和梯度)。这就像每个帮手独立完成自己的习题,得出自己的答案和解题思路。
> 4. **汇总经验,共同进步:** 学习结束后,所有的帮手会把自己学到的“经验”(梯度)拿出来一起讨论,取长补短,求平均值,然后用这个平均的“经验”去更新他们手上的学习资料(模型)。这就像大家一起对答案,找出最好的解题方法,然后更新自己的知识。
> 5. **止跑偏,保持一致:** 通过这种“汇总经验,共同进步”的方式,可以确保每个帮手都在朝着同一个目标学习,不会因为学习的数据不一样而导致理解偏差(模型不会发散)。这就像确保所有帮手都在学习同一个科目的内容,而不是各自学不同的东西。
>
> 简单来说,多 GPU 训练就像是让多个“学生”(GPU)同时学习不同的“教材”(数据),然后定期交流“学习心得”(梯度),最终让每个“学生”都掌握相同的知识(更新后的模型)。
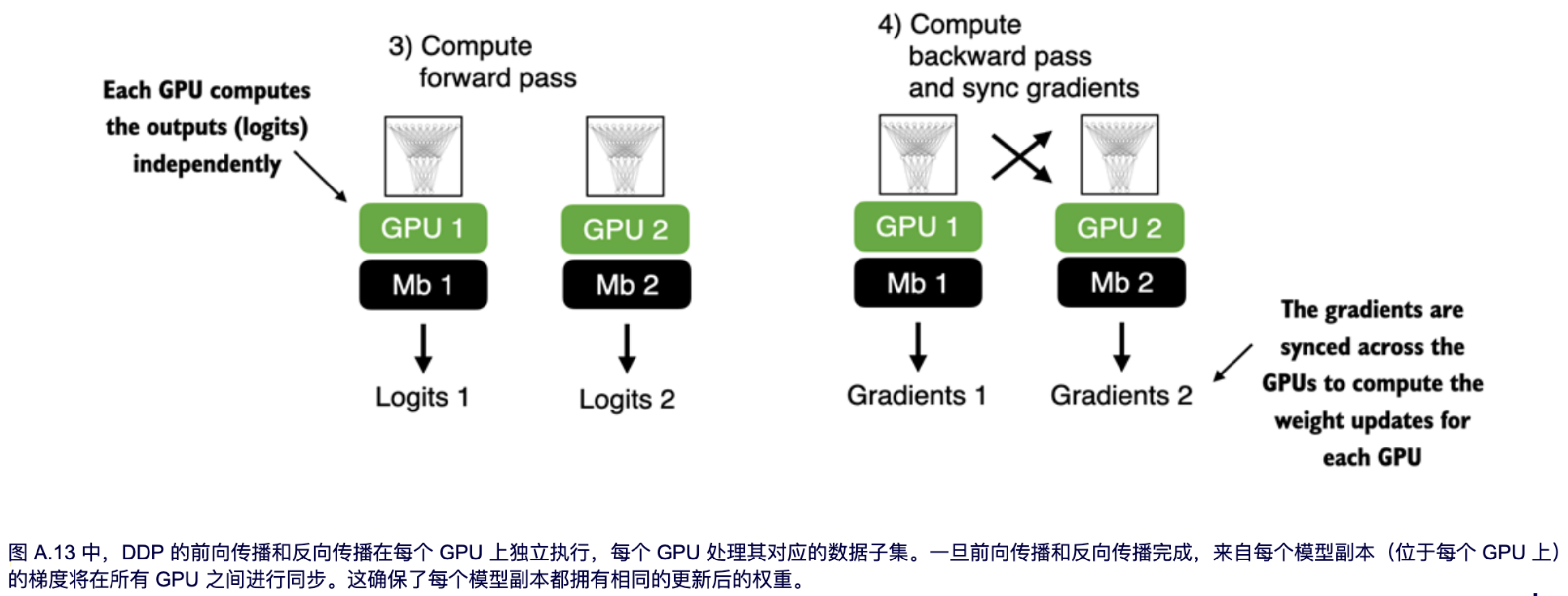 使用 DDP 的好处是,与单个 GPU 相比,它可以显著提高处理数据集的速度。除去使用 DDP 带来的设备之间微小的通信开销,理论上,使用两个 GPU 可以将一个训练 epoch 的处理时间缩短一半,而使用一个 GPU 则需要更长的时间。这种时间效率随着 GPU 数量的增加而提高,如果我们有八个 GPU,就可以将一个 epoch 的处理速度提高八倍,以此类推。
> [!NOTE]
>
> **交互式环境中的多 GPU 计算** DDP 在交互式 Python 环境(如 Jupyter notebooks)中无法正常工作,因为这些环境处理多进程的方式与独立的 Python 脚本不同。因此,以下代码应该作为脚本执行,而不是在像 Jupyter 这样的笔记本界面中执行。这是因为 DDP 需要启动多个进程,并且每个进程都应该有自己的 Python 解释器实例。
现在让我们看看这在实践中是如何运作的。为了简洁起见,我们将只关注之前代码中需要为 DDP 训练进行调整的核心部分。然而,对于那些想在自己的多 GPU 机器或他们选择的云实例上运行代码的读者,建议使用本书 GitHub 仓库中提供的独立脚本,地址是 https://github.com/rasbt/LLMs-from-scratch。
首先,我们将导入一些额外的子模块、类和函数,用于 PyTorch 的分布式训练,如下面的代码清单 A.13 所示。
```python
# Listing A.12 PyTorch utilities for distributed training
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
```
在我们深入研究如何更改代码可以使训练与 DDP 兼容之前,让我们先简要介绍一下这些新导入的实用程序的原理和用法,这些实用程序需要与 `DistributedDataParallel` 类一起使用。
PyTorch 的 `multiprocessing` 子模块包含诸如 `multiprocessing.spawn` 这样的函数,我们将使用它来启动多个进程,并并行地将一个函数应用于多个输入。我们将使用它为每个 GPU 启动一个训练进程。
如果我们为训练启动多个进程,我们将需要一种方法来在这些不同的进程之间分配数据集。为此,我们将使用 `DistributedSampler`。
`init_process_group` 和 `destroy_process_group` 用于初始化和退出分布式训练模块。`init_process_group` 函数应该在训练脚本的开始处被调用,以便为分布式设置中的每个进程初始化一个进程组,而 `destroy_process_group` 应该在训练脚本的结束处被调用,以销毁给定的进程组并释放其资源。
下面的代码清单 A.13 展示了如何使用这些新组件来实现我们之前实现的 `NeuralNetwork` 模型的 DDP 训练。
```python
# Listing A.13 Model training with DistributedDataParallel strategy
def ddp_setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost" #A
os.environ["MASTER_PORT"] = "12345" #B
init_process_group(
backend="nccl", #C
rank=rank, #D
world_size=world_size #E
)
torch.cuda.set_device(rank) #F
def prepare_dataset():
...
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=False, #G
pin_memory=True, #H
drop_last=True,
sampler=DistributedSampler(train_ds) #I
)
return train_loader, test_loader
def main(rank, world_size, num_epochs): #J
ddp_setup(rank, world_size)
train_loader, test_loader = prepare_dataset()
model = NeuralNetwork(num_inputs=2, num_outputs=2)
model.to(rank)
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
model = DDP(model, device_ids=[rank])
for epoch in range(num_epochs):
for features, labels in train_loader:
features, labels = features.to(rank), labels.to(rank) #K
...
print(f"[GPU{rank}] Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batchsize {labels.shape[0]:03d}"
f" | Train/Val Loss: {loss:.2f}")
model.eval()
train_acc = compute_accuracy(model, train_loader, device=rank)
print(f"[GPU{rank}] Training accuracy", train_acc)
test_acc = compute_accuracy(model, test_loader, device=rank)
print(f"[GPU{rank}] Test accuracy", test_acc)
destroy_process_group() #L
if __name__ == "__main__":
print("Number of GPUs available:", torch.cuda.device_count())
torch.manual_seed(123)
num_epochs = 3
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, num_epochs), nprocs=world_size) #M
#A 主节点的地址
#B 机器上的任意空闲端口
#C nccl 代表 NVIDIA 集体通信库。
#D rank 指的是我们想要使用的 GPU 的索引。
#E world_size 是要使用的 GPU 的数量。
#F 设置当前 GPU 设备,张量将分配到该设备上,并且操作将在该设备上执行。
#G DistributedSampler 现在负责数据的洗牌。
#H 在 GPU 上训练时启用更快的内存传输。
#I 将数据集分割成每个进程(GPU)独有的、不重叠的子集。
#J 运行模型训练的主函数
#K rank 是 GPU 的 ID。
#L 清理资源分配。
#M 使用多个进程启动主函数,其中 nprocs=world_size 表示每个 GPU 一个进程。
```
在我们运行上述代码之前,先对其工作原理进行总结,作为上述注释的补充。我们在底部有一个 `if __name__ == "__main__":` 的子句,其中包含当我们把代码作为 Python 脚本运行而不是作为模块导入时执行的代码。这段代码首先使用 `torch.cuda.device_count()` 打印可用 GPU 的数量,设置一个随机种子以保证结果的可重复性,然后使用 PyTorch 的 `multiprocesses.spawn` 函数启动新的进程。在这里,`spawn` 函数为每个 GPU 启动一个进程,通过设置 `nproces=world_size` 来实现,其中 `world_size` 是可用 GPU 的数量。此`spawn`函数在main函数中被调用,并通过`args`提供一些额外参数。请注意,`main` 函数还有一个 `rank` 参数,我们并没有在 `mp.spawn()` 的调用中包含它。这是因为`rank`(指的是我们用作 GPU ID 的进程 ID)已经被自动传递了。
`main` 函数通过我们定义的另一个函数 `ddp_setup` 设置分布式环境,加载训练集和测试集,设置模型,并执行训练。与 2.12 节中的单 GPU 训练相比,我们现在通过 `.to(rank)` 将模型和数据转移到目标设备,其中 `rank` 用于指代 GPU 设备 ID。此外,我们通过 DDP 封装模型,这使得在训练期间不同 GPU 之间的梯度能够同步。训练结束后,当我们评估模型时,我们使用 `destroy_process_group()` 来干净地退出分布式训练并释放已分配的资源。
之前我们提到过,每个 GPU 将接收到训练数据的一个不同子样本。为了确保这一点,我们在训练数据加载器中设置 `sampler=DistributedSampler(train_ds)`。
要讨论的最后一个函数是 `ddp_setup`。它设置主节点的地址和端口,以便不同进程之间进行通信,使用 NCCL 后端(专为 GPU 之间的通信设计)初始化进程组,并设置 rank(进程标识符)和 world size(进程总数)。最后,它指定与当前模型训练进程 rank 相对应的 GPU 设备。
**在多 GPU 机器上选择可用的 GPU**
如果你希望在一台多 GPU 机器上限制用于训练的 GPU 数量,最简单的方法是使用 `CUDA_VISIBLE_DEVICES` 环境变量。为了说明这一点,假设你的机器有多个 GPU,而你只想使用索引为 0 的 GPU。你可以通过在终端中运行以下命令来执行代码,而不是直接运行 `python some_script.py`:
```python
CUDA_VISIBLE_DEVICES=0 python some_script.py
```
或者,如果你的机器有四个 GPU,而你只想使用第一个和第三个 GPU,你可以使用:
```python
CUDA_VISIBLE_DEVICES=0,2 python some_script.py
```
以这种方式设置 `CUDA_VISIBLE_DEVICES` 是一种简单而有效的方法来管理 GPU 的分配,而无需修改你的 PyTorch 脚本。
现在让我们从终端将代码作为脚本启动,看看它在实践中是如何工作的:
```python
python ch02-DDP-script.py
```
请注意,它应该可以在单 GPU 和多 GPU 机器上工作。如果我们在一块 GPU 上运行这段代码,我们应该会看到以下输出:
```python
PyTorch version: 2.0.1+cu117
CUDA available: True
Number of GPUs available: 1
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.62
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.32
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.11
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.07
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.02
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.03
[GPU0] Training accuracy 1.0
[GPU0] Test accuracy 1.0
```
代码的输出看起来与 2.9.2 节中的输出类似,这是一个很好的健全性检查。
现在,如果我们在一台配备两块 GPU 的机器上运行相同的命令和代码,我们应该会看到以下内容:
```python
PyTorch version: 2.0.1+cu117
CUDA available: True
Number of GPUs available: 2
[GPU1] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.60
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.59
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.16
[GPU1] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.17
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.05
[GPU1] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.05
[GPU1] Training accuracy 1.0
[GPU0] Training accuracy 1.0
[GPU1] Test accuracy 1.0
[GPU0] Test accuracy 1.0
```
正如预期的那样,我们可以看到一些批次在第一个 GPU (GPU0) 上处理,而另一些在第二个 GPU (GPU1) 上处理。然而,在打印训练和测试准确率时,我们看到了重复的输出行。这是因为每个进程(换句话说,每个 GPU)都独立地打印测试准确率。由于 DDP 将模型复制到每个 GPU 上,并且每个进程都独立运行,因此,如果你的测试循环中有打印语句,每个进程都会执行它,从而导致重复的输出行。
如果这让你感到困扰,你可以使用每个进程的 rank 来控制你的打印语句,从而解决这个问题。
```python
if rank == 0: # only print in the first process
print("Test accuracy: ", accuracy)
```
总而言之,这就是通过 DDP 进行分布式训练的工作方式。如果你对更多细节感兴趣,我建议查看官方 API 文档:https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html。
> [!NOTE]
>
> **多 GPU 训练的替代 PyTorch API**
>
> 如果你更喜欢在 PyTorch 中使用多个 GPU 的更直接方法,你也可以考虑使用附加 API,例如开源的 Fabric 库,我曾在《加速 PyTorch 模型训练:使用混合精度和全分片数据并行》这篇文章中介绍过它,链接是 https://magazine.sebastianraschka.com/p/accelerating-pytorch-modeltraining。
## A.10 本章摘要
+ PyTorch 是一个开源库,它由三个核心组件构成:一个张量库,自动微分函数,以及深度学习实用工具。
+ PyTorch 的张量库类似于 NumPy 等数组库。
+ 在 PyTorch 中,张量是类似于数组的数据结构,用于表示标量、向量、矩阵和更高维度的数组。
+ PyTorch 张量可以在 CPU 上执行,但 PyTorch 张量格式的一个主要优势是其 GPU 支持,可以加速计算。
+ PyTorch 中的自动微分 (autograd) 功能使我们能够方便地使用反向传播训练神经网络,而无需手动推导梯度。
+ PyTorch 中的深度学习实用工具为创建自定义深度神经网络提供了构建模块。
+ PyTorch 包含 Dataset 和 DataLoader 类,用于设置高效的数据加载管道。
+ 在 CPU 或单个 GPU 上训练模型是最简单的。
+ 如果可以使用多个 GPU,那么使用 DistributedDataParallel 是 PyTorch 中加速训练的最简单方法。
使用 DDP 的好处是,与单个 GPU 相比,它可以显著提高处理数据集的速度。除去使用 DDP 带来的设备之间微小的通信开销,理论上,使用两个 GPU 可以将一个训练 epoch 的处理时间缩短一半,而使用一个 GPU 则需要更长的时间。这种时间效率随着 GPU 数量的增加而提高,如果我们有八个 GPU,就可以将一个 epoch 的处理速度提高八倍,以此类推。
> [!NOTE]
>
> **交互式环境中的多 GPU 计算** DDP 在交互式 Python 环境(如 Jupyter notebooks)中无法正常工作,因为这些环境处理多进程的方式与独立的 Python 脚本不同。因此,以下代码应该作为脚本执行,而不是在像 Jupyter 这样的笔记本界面中执行。这是因为 DDP 需要启动多个进程,并且每个进程都应该有自己的 Python 解释器实例。
现在让我们看看这在实践中是如何运作的。为了简洁起见,我们将只关注之前代码中需要为 DDP 训练进行调整的核心部分。然而,对于那些想在自己的多 GPU 机器或他们选择的云实例上运行代码的读者,建议使用本书 GitHub 仓库中提供的独立脚本,地址是 https://github.com/rasbt/LLMs-from-scratch。
首先,我们将导入一些额外的子模块、类和函数,用于 PyTorch 的分布式训练,如下面的代码清单 A.13 所示。
```python
# Listing A.12 PyTorch utilities for distributed training
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
```
在我们深入研究如何更改代码可以使训练与 DDP 兼容之前,让我们先简要介绍一下这些新导入的实用程序的原理和用法,这些实用程序需要与 `DistributedDataParallel` 类一起使用。
PyTorch 的 `multiprocessing` 子模块包含诸如 `multiprocessing.spawn` 这样的函数,我们将使用它来启动多个进程,并并行地将一个函数应用于多个输入。我们将使用它为每个 GPU 启动一个训练进程。
如果我们为训练启动多个进程,我们将需要一种方法来在这些不同的进程之间分配数据集。为此,我们将使用 `DistributedSampler`。
`init_process_group` 和 `destroy_process_group` 用于初始化和退出分布式训练模块。`init_process_group` 函数应该在训练脚本的开始处被调用,以便为分布式设置中的每个进程初始化一个进程组,而 `destroy_process_group` 应该在训练脚本的结束处被调用,以销毁给定的进程组并释放其资源。
下面的代码清单 A.13 展示了如何使用这些新组件来实现我们之前实现的 `NeuralNetwork` 模型的 DDP 训练。
```python
# Listing A.13 Model training with DistributedDataParallel strategy
def ddp_setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost" #A
os.environ["MASTER_PORT"] = "12345" #B
init_process_group(
backend="nccl", #C
rank=rank, #D
world_size=world_size #E
)
torch.cuda.set_device(rank) #F
def prepare_dataset():
...
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=False, #G
pin_memory=True, #H
drop_last=True,
sampler=DistributedSampler(train_ds) #I
)
return train_loader, test_loader
def main(rank, world_size, num_epochs): #J
ddp_setup(rank, world_size)
train_loader, test_loader = prepare_dataset()
model = NeuralNetwork(num_inputs=2, num_outputs=2)
model.to(rank)
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
model = DDP(model, device_ids=[rank])
for epoch in range(num_epochs):
for features, labels in train_loader:
features, labels = features.to(rank), labels.to(rank) #K
...
print(f"[GPU{rank}] Epoch: {epoch+1:03d}/{num_epochs:03d}"
f" | Batchsize {labels.shape[0]:03d}"
f" | Train/Val Loss: {loss:.2f}")
model.eval()
train_acc = compute_accuracy(model, train_loader, device=rank)
print(f"[GPU{rank}] Training accuracy", train_acc)
test_acc = compute_accuracy(model, test_loader, device=rank)
print(f"[GPU{rank}] Test accuracy", test_acc)
destroy_process_group() #L
if __name__ == "__main__":
print("Number of GPUs available:", torch.cuda.device_count())
torch.manual_seed(123)
num_epochs = 3
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, num_epochs), nprocs=world_size) #M
#A 主节点的地址
#B 机器上的任意空闲端口
#C nccl 代表 NVIDIA 集体通信库。
#D rank 指的是我们想要使用的 GPU 的索引。
#E world_size 是要使用的 GPU 的数量。
#F 设置当前 GPU 设备,张量将分配到该设备上,并且操作将在该设备上执行。
#G DistributedSampler 现在负责数据的洗牌。
#H 在 GPU 上训练时启用更快的内存传输。
#I 将数据集分割成每个进程(GPU)独有的、不重叠的子集。
#J 运行模型训练的主函数
#K rank 是 GPU 的 ID。
#L 清理资源分配。
#M 使用多个进程启动主函数,其中 nprocs=world_size 表示每个 GPU 一个进程。
```
在我们运行上述代码之前,先对其工作原理进行总结,作为上述注释的补充。我们在底部有一个 `if __name__ == "__main__":` 的子句,其中包含当我们把代码作为 Python 脚本运行而不是作为模块导入时执行的代码。这段代码首先使用 `torch.cuda.device_count()` 打印可用 GPU 的数量,设置一个随机种子以保证结果的可重复性,然后使用 PyTorch 的 `multiprocesses.spawn` 函数启动新的进程。在这里,`spawn` 函数为每个 GPU 启动一个进程,通过设置 `nproces=world_size` 来实现,其中 `world_size` 是可用 GPU 的数量。此`spawn`函数在main函数中被调用,并通过`args`提供一些额外参数。请注意,`main` 函数还有一个 `rank` 参数,我们并没有在 `mp.spawn()` 的调用中包含它。这是因为`rank`(指的是我们用作 GPU ID 的进程 ID)已经被自动传递了。
`main` 函数通过我们定义的另一个函数 `ddp_setup` 设置分布式环境,加载训练集和测试集,设置模型,并执行训练。与 2.12 节中的单 GPU 训练相比,我们现在通过 `.to(rank)` 将模型和数据转移到目标设备,其中 `rank` 用于指代 GPU 设备 ID。此外,我们通过 DDP 封装模型,这使得在训练期间不同 GPU 之间的梯度能够同步。训练结束后,当我们评估模型时,我们使用 `destroy_process_group()` 来干净地退出分布式训练并释放已分配的资源。
之前我们提到过,每个 GPU 将接收到训练数据的一个不同子样本。为了确保这一点,我们在训练数据加载器中设置 `sampler=DistributedSampler(train_ds)`。
要讨论的最后一个函数是 `ddp_setup`。它设置主节点的地址和端口,以便不同进程之间进行通信,使用 NCCL 后端(专为 GPU 之间的通信设计)初始化进程组,并设置 rank(进程标识符)和 world size(进程总数)。最后,它指定与当前模型训练进程 rank 相对应的 GPU 设备。
**在多 GPU 机器上选择可用的 GPU**
如果你希望在一台多 GPU 机器上限制用于训练的 GPU 数量,最简单的方法是使用 `CUDA_VISIBLE_DEVICES` 环境变量。为了说明这一点,假设你的机器有多个 GPU,而你只想使用索引为 0 的 GPU。你可以通过在终端中运行以下命令来执行代码,而不是直接运行 `python some_script.py`:
```python
CUDA_VISIBLE_DEVICES=0 python some_script.py
```
或者,如果你的机器有四个 GPU,而你只想使用第一个和第三个 GPU,你可以使用:
```python
CUDA_VISIBLE_DEVICES=0,2 python some_script.py
```
以这种方式设置 `CUDA_VISIBLE_DEVICES` 是一种简单而有效的方法来管理 GPU 的分配,而无需修改你的 PyTorch 脚本。
现在让我们从终端将代码作为脚本启动,看看它在实践中是如何工作的:
```python
python ch02-DDP-script.py
```
请注意,它应该可以在单 GPU 和多 GPU 机器上工作。如果我们在一块 GPU 上运行这段代码,我们应该会看到以下输出:
```python
PyTorch version: 2.0.1+cu117
CUDA available: True
Number of GPUs available: 1
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.62
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.32
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.11
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.07
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.02
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.03
[GPU0] Training accuracy 1.0
[GPU0] Test accuracy 1.0
```
代码的输出看起来与 2.9.2 节中的输出类似,这是一个很好的健全性检查。
现在,如果我们在一台配备两块 GPU 的机器上运行相同的命令和代码,我们应该会看到以下内容:
```python
PyTorch version: 2.0.1+cu117
CUDA available: True
Number of GPUs available: 2
[GPU1] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.60
[GPU0] Epoch: 001/003 | Batchsize 002 | Train/Val Loss: 0.59
[GPU0] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.16
[GPU1] Epoch: 002/003 | Batchsize 002 | Train/Val Loss: 0.17
[GPU0] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.05
[GPU1] Epoch: 003/003 | Batchsize 002 | Train/Val Loss: 0.05
[GPU1] Training accuracy 1.0
[GPU0] Training accuracy 1.0
[GPU1] Test accuracy 1.0
[GPU0] Test accuracy 1.0
```
正如预期的那样,我们可以看到一些批次在第一个 GPU (GPU0) 上处理,而另一些在第二个 GPU (GPU1) 上处理。然而,在打印训练和测试准确率时,我们看到了重复的输出行。这是因为每个进程(换句话说,每个 GPU)都独立地打印测试准确率。由于 DDP 将模型复制到每个 GPU 上,并且每个进程都独立运行,因此,如果你的测试循环中有打印语句,每个进程都会执行它,从而导致重复的输出行。
如果这让你感到困扰,你可以使用每个进程的 rank 来控制你的打印语句,从而解决这个问题。
```python
if rank == 0: # only print in the first process
print("Test accuracy: ", accuracy)
```
总而言之,这就是通过 DDP 进行分布式训练的工作方式。如果你对更多细节感兴趣,我建议查看官方 API 文档:https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html。
> [!NOTE]
>
> **多 GPU 训练的替代 PyTorch API**
>
> 如果你更喜欢在 PyTorch 中使用多个 GPU 的更直接方法,你也可以考虑使用附加 API,例如开源的 Fabric 库,我曾在《加速 PyTorch 模型训练:使用混合精度和全分片数据并行》这篇文章中介绍过它,链接是 https://magazine.sebastianraschka.com/p/accelerating-pytorch-modeltraining。
## A.10 本章摘要
+ PyTorch 是一个开源库,它由三个核心组件构成:一个张量库,自动微分函数,以及深度学习实用工具。
+ PyTorch 的张量库类似于 NumPy 等数组库。
+ 在 PyTorch 中,张量是类似于数组的数据结构,用于表示标量、向量、矩阵和更高维度的数组。
+ PyTorch 张量可以在 CPU 上执行,但 PyTorch 张量格式的一个主要优势是其 GPU 支持,可以加速计算。
+ PyTorch 中的自动微分 (autograd) 功能使我们能够方便地使用反向传播训练神经网络,而无需手动推导梯度。
+ PyTorch 中的深度学习实用工具为创建自定义深度神经网络提供了构建模块。
+ PyTorch 包含 Dataset 和 DataLoader 类,用于设置高效的数据加载管道。
+ 在 CPU 或单个 GPU 上训练模型是最简单的。
+ 如果可以使用多个 GPU,那么使用 DistributedDataParallel 是 PyTorch 中加速训练的最简单方法。
|